伍德里奇计量经济学第六版答案Chapter-3
伍德里奇《计量经济学导论》(第6版)复习笔记和课后习题详解OLS用于时间序列数据的其他问题

伍德里奇《计量经济学导论》(第6版)复习笔记和课后习题详解OLS用于时间序列数据的其他问题第11章OLS用于时间序列数据的其他问题11.1复习笔记考点一:平稳和弱相关时间序列★★★★1.时间序列的相关概念(见表11-1)表11-1时间序列的相关概念2.弱相关时间序列(1)弱相关对于一个平稳时间序列过程{x t:t=1,2,…},随着h的无限增大,若x t和x t+h“近乎独立”,则称为弱相关。
对于协方差平稳序列,如果x t和x t+h之间的相关系数随h的增大而趋近于0,则协方差平稳随机序列就是弱相关的。
本质上,弱相关时间序列取代了能使大数定律(LLN)和中心极限定理(CLT)成立的随机抽样假定。
(2)弱相关时间序列的例子(见表11-2)表11-2弱相关时间序列的例子考点二:OLS的渐近性质★★★★1.OLS的渐近性假设(见表11-3)表11-3OLS的渐近性假设2.OLS的渐近性质(见表11-4)表11-4OLS的渐进性质考点三:回归分析中使用高度持续性时间序列★★★★1.高度持续性时间序列(1)随机游走(见表11-5)表11-5随机游走(2)带漂移的随机游走带漂移的随机游走的形式为:y t=α0+y t-1+e t,t=1,2,…。
其中,e t(t=1,2,…)和y0满足随机游走模型的同样性质;参数α0被称为漂移项。
通过反复迭代,发现y t的期望值具有一种线性时间趋势:y t=α0t+e t+e t-1+…+e1+y0。
当y0=0时,E(y t)=α0t。
若α0>0,y t的期望值随时间而递增;若α0<0,则随时间而下降。
在t时期,对y t+h的最佳预测值等于y t加漂移项α0h。
y t的方差与纯粹随机游走情况下的方差完全相同。
带漂移随机游走是单位根过程的另一个例子,因为它是含截距的AR(1)模型中ρ1=1的特例:y t=α0+ρ1y t-1+e t。
2.高度持续性时间序列的变换(1)差分平稳过程I(1)弱相关过程,也被称为0阶单整或I(0),这种序列的均值已经满足标准的极限定理,在回归分析中使用时无须进行任何处理。
伍德里奇《计量经济学导论》(第6版)复习笔记和课后习题详解-第三篇(第13~15章)【圣才出品】

第三篇高级专题第13章跨时横截面的混合:简单面板数据方法13.1 复习笔记考点一:跨时独立横截面的混合★★★★★1.独立混合横截面数据的定义独立混合横截面数据是指在不同时点从一个大总体中随机抽样得到的随机样本。
这种数据的重要特征在于:都是由独立抽取的观测所构成的。
在保持其他条件不变时,该数据排除了不同观测误差项的相关性。
区别于单独的随机样本,当在不同时点上进行抽样时,样本的性质可能与时间相关,从而导致观测点不再是同分布的。
2.使用独立混合横截面的理由(见表13-1)表13-1 使用独立混合横截面的理由3.对跨时结构性变化的邹至庄检验(1)用邹至庄检验来检验多元回归函数在两组数据之间是否存在差别(见表13-2)表13-2 用邹至庄检验来检验多元回归函数在两组数据之间是否存在差别(2)对多个时期计算邹至庄检验统计量的办法①使用所有时期虚拟变量与一个(或几个、所有)解释变量的交互项,并检验这些交互项的联合显著性,一般总能检验斜率系数的恒定性。
②做一个容许不同时期有不同截距的混合回归来估计约束模型,得到SSR r。
然后,对T个时期都分别做一个回归,并得到相应的残差平方和,有:SSR ur=SSR1+SSR2+…+SSR T。
若有k个解释变量(不包括截距和时期虚拟变量)和T个时期,则需检验(T-1)k 个约束。
而无约束模型中有T+Tk个待估计参数。
所以,F检验的df为(T-1)k和n-T -Tk,其中n为总观测次数。
F统计量计算公式为:[(SSR r-SSR ur)/SSR ur][(n-T-Tk)/(Tk-k)]。
但该检验不能对异方差性保持稳健,为了得到异方差-稳健的检验,必须构造交互项并做一个混合回归。
4.利用混合横截面作政策分析(1)自然实验与真实实验当某些外生事件改变了个人、家庭、企业或城市运行的环境时,便产生了自然实验(准实验)。
一个自然实验总有一个不受政策变化影响的对照组和一个受政策变化影响的处理组。
伍德里奇《计量经济学导论》(第6版)复习笔记和课后习题详解-第一篇(第4~6章)【圣才出品】

考点五:对多个线性约束的检验:F 检验 ★★★★★
1.对排除性约束的检验 对排除性约束的检验是指检验一组自变量是否对因变量都没有影响,该检验不适用于不 同因变量的检验。F 统计量通常对检验一组变量的排除有用处,特别是当变量高度相关的时 候。 含有 k 个自变量的不受约束模型为:y=β0+β1x1+…+βkxk+u,其中参数有 k+1 个。 假设有 q 个排除性约束要检验,且这 q 个变量是自变量中的最后 q 个:xk-q+1,…,xk, 则受约束模型为:y=β0+β1x1+…+βk-qxk-q+u。 虚拟假设为 H0:βk-q+1=0,…,βk=0,对立假设是列出的参数至少有一个不为零。 定义 F 统计量为 F=[(SSRr-SSRur)/q]/[SSRur/(n-k-1)]。其中,SSRr 是受约束模型 的残差平方和,SSRur 是不受约束模型的残差平方和。由于 SSRr 不可能比 SSRur 小,所以 F 统计量总是非负的。q=dfr-dfur,即 q 是受约束模型与不受约束模型的自由度之差,也是 约束条件的个数。n-k-1=分母自由度=dfur,且 F 的分母恰好就是不受约束模型中σ2= Var(u)的一个无偏估计量。 假设 CLM 假定成立,在 H0 下 F 统计量服从自由度为(q,n-k-1)的 F 分布,即 F~ Fq,n-k-1。如果 F 值大于显著性水平下的临界值,则拒绝 H0 而支持 H1。当拒绝 H0 时,就 说,xk-q+1,…,xk 在适当的显著性水平上是联合统计显著的(或联合显著)。
∧
∧
∧
∧
注:β1,β2,…,βk 的任何线性组合也都符合正态分布,且βj 的任何一数检验:t 检验 ★★★★
1.总体回归函数 总体模型的形式为:y=β0+β1x1+…+βkxk+u。假定该模型满足 CLM 假定,βj 的 OLS 量是无偏的。
伍德里奇---计量经济学第6章部分计算机习题详解(STATA)
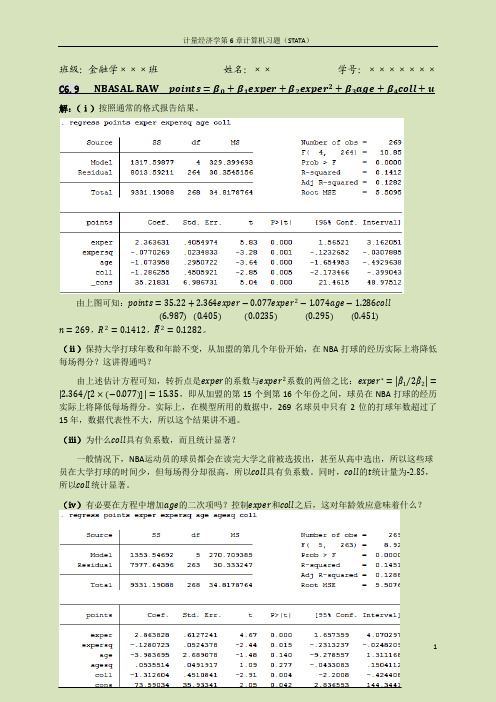
班级:金融学×××班姓名:××学号:×××××××C6.9 NBASAL.RAW points=β0+β1exper+β2exper2+β3age+β4coll+u 解:(ⅰ)按照通常的格式报告结果。
由上图可知:points=35.22+2.364exper−0.077exper2−1.074age−1.286coll6.9870.4050.02350.295 (0.451)n=269,R2=0.1412,R2=0.1282。
(ⅱ)保持大学打球年数和年龄不变,从加盟的第几个年份开始,在NBA打球的经历实际上将降低每场得分?这讲得通吗?由上述估计方程可知,转折点是exper的系数与exper2系数的两倍之比:exper∗= β12β2= 2.364[2×−0.077]=15.35,即从加盟的第15个到第16个年份之间,球员在NBA打球的经历实际上将降低每场得分。
实际上,在模型所用的数据中,269名球员中只有2位的打球年数超过了15年,数据代表性不大,所以这个结果讲不通。
(ⅲ)为什么coll具有负系数,而且统计显著?一般情况下,NBA运动员的球员都会在读完大学之前被选拔出,甚至从高中选出,所以这些球员在大学打球的时间少,但每场得分却很高,所以coll具有负系数。
同时,coll的t统计量为-2.85,所以coll统计显著。
(ⅳ)有必要在方程中增加age的二次项吗?控制exper和coll之后,这对年龄效应意味着什么?增加age的二次项后,原估计模型变成:points=73.59+2.864exper−0.128exper2−3.984age+0.054age2−1.313coll35.930.610.05 2.690.05 (0.45)n=269,R2=0.1451,R2=0.1288。
伍德里奇计量经济学导论第6版笔记和课后习题答案

第1章计量经济学的性质与经济数据1.1复习笔记考点一:计量经济学★1计量经济学的含义计量经济学,又称经济计量学,是由经济理论、统计学和数学结合而成的一门经济学的分支学科,其研究内容是分析经济现象中客观存在的数量关系。
2计量经济学模型(1)模型分类模型是对现实生活现象的描述和模拟。
根据描述和模拟办法的不同,对模型进行分类,如表1-1所示。
(2)数理经济模型和计量经济学模型的区别①研究内容不同数理经济模型的研究内容是经济现象各因素之间的理论关系,计量经济学模型的研究内容是经济现象各因素之间的定量关系。
②描述和模拟办法不同数理经济模型的描述和模拟办法主要是确定性的数学形式,计量经济学模型的描述和模拟办法主要是随机性的数学形式。
③位置和作用不同数理经济模型可用于对研究对象的初步研究,计量经济学模型可用于对研究对象的深入研究。
考点二:经济数据★★★1经济数据的结构(见表1-3)2面板数据与混合横截面数据的比较(见表1-4)考点三:因果关系和其他条件不变★★1因果关系因果关系是指一个变量的变动将引起另一个变量的变动,这是经济分析中的重要目标之计量分析虽然能发现变量之间的相关关系,但是如果想要解释因果关系,还要排除模型本身存在因果互逆的可能,否则很难让人信服。
2其他条件不变其他条件不变是指在经济分析中,保持所有的其他变量不变。
“其他条件不变”这一假设在因果分析中具有重要作用。
1.2课后习题详解一、习题1.假设让你指挥一项研究,以确定较小的班级规模是否会提高四年级学生的成绩。
(i)如果你能指挥你想做的任何实验,你想做些什么?请具体说明。
(ii)更现实地,假设你能搜集到某个州几千名四年级学生的观测数据。
你能得到它们四年级班级规模和四年级末的标准化考试分数。
你为什么预计班级规模与考试成绩成负相关关系?(iii)负相关关系一定意味着较小的班级规模会导致更好的成绩吗?请解释。
答:(i)假定能够随机的分配学生们去不同规模的班级,也就是说,在不考虑学生诸如能力和家庭背景等特征的前提下,每个学生被随机的分配到不同的班级。
伍德里奇《计量经济学导论》(第6版)复习笔记和课后习题详解-多元回归分析:推断【圣才出品】

伍德⾥奇《计量经济学导论》(第6版)复习笔记和课后习题详解-多元回归分析:推断【圣才出品】第4章多元回归分析:推断4.1复习笔记考点⼀:OLS估计量的抽样分布★★★1.假定MLR.6(正态性)假定总体误差项u独⽴于所有解释变量,且服从均值为零和⽅差为σ2的正态分布,即:u~Normal(0,σ2)。
对于横截⾯回归中的应⽤来说,假定MLR.1~MLR.6被称为经典线性模型假定。
假定下对应的模型称为经典线性模型(CLM)。
2.⽤中⼼极限定理(CLT)在样本量较⼤时,u近似服从于正态分布。
正态分布的近似效果取决于u中包含多少因素以及因素分布的差异。
但是CLT的前提假定是所有不可观测的因素都以独⽴可加的⽅式影响Y。
当u是关于不可观测因素的⼀个复杂函数时,CLT论证可能并不适⽤。
3.OLS估计量的正态抽样分布定理4.1(正态抽样分布):在CLM假定MLR.1~MLR.6下,以⾃变量的样本值为条件,有:∧βj~Normal(βj,Var(∧βj))。
将正态分布函数标准化可得:(∧βj-βj)/sd(∧βj)~Normal(0,1)。
注:∧β1,∧β2,…,∧βk的任何线性组合也都符合正态分布,且∧βj的任何⼀个⼦集也都具有⼀个联合正态分布。
考点⼆:单个总体参数检验:t检验★★★★1.总体回归函数总体模型的形式为:y=β0+β1x1+…+βk x k+u。
假定该模型满⾜CLM假定,βj的OLS 量是⽆偏的。
2.定理4.2:标准化估计量的t分布在CLM假定MLR.1~MLR.6下,(∧βj-βj)/se(∧βj)~t n-k-1,其中,k+1是总体模型中未知参数的个数(即k个斜率参数和截距β0)。
t统计量服从t分布⽽不是标准正态分布的原因是se(∧βj)中的常数σ已经被随机变量∧σ所取代。
t统计量的计算公式可写成标准正态随机变量(∧βj-βj)/sd(∧βj)与∧σ2/σ2的平⽅根之⽐,可以证明⼆者是独⽴的;⽽且(n-k-1)∧σ2/σ2~χ2n-k-1。
伍德里奇《计量经济学导论》(第6版)复习笔记和课后习题详解-第三篇(第16~19章)【圣才出品】
第16章联立方程模型16.1 复习笔记考点一:联立方程模型的性质★★当一个或多个解释变量与因变量联合被决定时,模型就会出现内生性问题。
联立方程模型是指从经济理论中推导出来的若干的相关的方程,联立起来就是一个模型,如凯恩斯的国民收入模型等。
联立方程的重要特征:(1)给定多个方程中的外生变量和误差项,所有的方程就决定了剩余的内生变量,因此任一方程的因变量和方程中的内生变量都是SEM的内生变量。
(2)模型中的外生变量的关键假设是与所有的误差项都不相关。
由于这些误差出现在结构方程中,所以它们是结构误差。
(3)SEM中的每个方程自身都应该有一个行为上的其他条件不变解释。
考点二:OLS中的联立性偏误★★★★1.约简型方程考虑两个方程的结构模型:y1=α1y2+β1z1+u1y2=α2y1+β2z2+u2专门估计第一个方程。
变量z1和z2都是外生的,所以每个都与u1和u2无关。
如果将式y1=α1y2+β1z1+u1的右边作为y1代入式y2=α2y1+β2z2+u2中,得到(1-α2α1)y2=α2β1z1+β2z2+α2u1+u2为了解出y2,需对参数做一个假定:α2α1≠1这个假定是否具有限制性则取决于应用。
如果上式的条件成立,y2可写成y2=π21z1+π22z2+v2其中,π21=α2β1/(1-α2α1)、π22=β2/(1-α2α1)和v2=(α2u1+u2)/(1-α2α),用外生变量和误差项表示y2的方程y2=π21z1+π22z2+v2是y2的约简型。
参数π21和π1被称为约简型参数,它们是结构方程中出现的结构型参数的非线性函数。
22约简型误差v2是结构型误差u1和u2的线性函数。
因为u1和u2都与z1和z2无关,所以v2也与z1和z2无关。
因此,可用OLS一致地估计π21和π22。
2.联立性偏误及其方向在约简型方程中,除非在特殊的假定之下,否则对方程y1=α1y2+β1z1+u1的OLS估计,将导致α1和β1的估计量有偏误和不一致。
伍德里奇《计量经济学导论》(第6版)复习笔记和课后习题详解-模型设定和数据问题的深入探讨【圣才出品】
第9章模型设定和数据问题的深入探讨9.1复习笔记考点一:函数形式设误检验(见表9-1)★★★★表9-1函数形式设误检验考点二:对无法观测解释变量使用代理变量★★★1.代理变量代理变量就是某种与分析中试图控制而又无法观测的变量相关的变量。
(1)遗漏变量问题的植入解假设在有3个自变量的模型中,其中有两个自变量是可以观测的,解释变量x3*观测不到:y=β0+β1x1+β2x2+β3x3*+u。
但有x3*的一个代理变量,即x3,有x3*=δ0+δ3x3+v3。
其中,x3*和x3正相关,所以δ3>0;截距δ0容许x3*和x3以不同的尺度来度量。
假设x3就是x3*,做y对x1,x2,x3的回归,从而利用x3得到β1和β2的无偏(或至少是一致)估计量。
在做OLS之前,只是用x3取代了x3*,所以称之为遗漏变量问题的植入解。
代理变量也可以以二值信息的形式出现。
(2)植入解能得到一致估计量所需的假定(见表9-2)表9-2植入解能得到一致估计量所需的假定2.用滞后因变量作为代理变量对于想要控制无法观测的因素,可以选择滞后因变量作为代理变量,这种方法适用于政策分析。
但是现期的差异很难用其他方法解释。
使用滞后被解释变量不是控制遗漏变量的唯一方法,但是这种方法适用于估计政策变量。
考点三:随机斜率模型★★★1.随机斜率模型的定义如果一个变量的偏效应取决于那些随着总体单位的不同而不同的无法观测因素,且只有一个解释变量x,就可以把这个一般模型写成:y i=a i+b i x i。
上式中的模型有时被称为随机系数模型或随机斜率模型。
对于上式模型,记a i=a+c i和b i=β+d i,则有E(c i)=0和E(d i)=0,代入模型得y i=a+βx i+u i,其中,u i=c i+d i x i。
2.保证OLS无偏(一致性)的条件(1)简单回归当u i=c i+d i x i时,无偏的充分条件就是E(c i|x i)=E(c i)=0和E(d i|x i)=E(d i)=0。
Wooldridge计量经济学答案
PREFACE
iii
SUGGESTED COURSE OUTLINES
iv
Chapter 1 The Nature of Econometrics and Economic Data
1
Chapter 2 The Simple Regression Model
5
Chapter 3 Multiple Regression Analysis: Estimation
15
Chapter 4 Multiple Regression Analysis: Inference
28
Chapter 5 Multiple Regression Analysis: OLS Asymptotics
39
Chapter 6 Multiple Regression Analysis: Further Issues
The solutions to the computer exercises were obtained using Stata, starting with version 4.0 and running through version 7.0. Nevertheless, almost all of the estimation methods covered in the text have been standardized, and different econometrics or statistical packages should give the same answers. There can be differences when applying more advanced techniques, as conventions sometimes differ on how to choose or estimate auxiliary parameters. (Examples include heteroskedasticity-robust standard errors, estimates of a random effects model, and corrections for sample selection bias.)
计量经济学Test-bank-questions-Chapter-3教学提纲
计量经济学T e s t-b a n k-q u e s t i o n s-C h a p t e r-3Multiple Choice Test Bank Questions No Feedback – Chapter 3 Correct answers denoted by an asterisk.1.Consider a standard normally distributed variable, a t-distributed variable with ddegrees of freedom, and an F-distributed variable with (1, d) degrees of freedom.Which of the following statements is FALSE?(a)The standard normal is a special case of the t-distribution, the square of which is aspecial case of the F-distribution.(b)* Since the three distributions are related, the 5% critical values from each will be thesame.(c)Asymptotically, a given test conducted using any of the three distributions will lead tothe same conclusion.(d)The normal and t- distributions are symmetric about zero while the F- takes onlypositive values.2. If our regression equation is y = Xβ+ u, where we have T observations and k regressors, what will be the dimension of βˆ using the standard matrix notation(a) T⨯k(b) T⨯ 1(c) * k⨯ 1(d) k⨯kQuestion 3 refers to the following regression estimated on 64 observations: y t = β1 + β2X2t + β3X3t + β4X4t + u t3. Which of the following null hypotheses could we test using an F-test?(i) β2 = 0(ii) β2 = 1 and β3 + β4 = 1(iii) β3β4 = 1(iv) β2 -β3 -β4 = 1(a) (i) and (ii) only(b) (ii) and (iv) only(c) (i), (ii), (iii) and (iv)(d)* (i), (ii), and (iv) onlyFor question 4, you are given the following data103 ,86.0,8.09.26.1)'(,4.39.14.19.1 8.01.24.11.23.1)'(21==⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡-=⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡--=-TsyX XXThe regression equation isy t = β1+ β2X2t + β3X3t + u tˆβ?4. Which of the following is the correct value for1(a) * 2.89(b) 1.30(c) 0.84ˆβ from the information given in the question (d) We cannot determine the value of15. Consider the following regression estimated using 84 observations:y t = β1 + β2X2t + β3X3t + β4X4t + u tSuppose that a researcher wishes to test the null hypothesis: β2 = 1 and β3 + β4 = 1. The TABULATED value of the F-distribution that we would compare the result of testing this hypothesis with at the 10% level would be approximately(a) 19.48(b) 2.76(c) * 2.37(d) 3.116.What is the relationship, if any, between t-distributed and F-distributed randomvariables?(a)A t-variate with z degrees of freedom is also an F(1, z)(b)* The square of a t-variate with z degrees of freedom is also an F(1, z)(c)A t-variate with z degrees of freedom is also an F(z, 1)(d)There is no relationship between the two distributions.7. Which one of the following statements must hold for EVERY CASE concerning the residual sums of squares for the restricted and unrestricted regressions?(a)URSS > RRSS(b)URSS ≥ RRSS(c)RRSS > URSS(d)* RRSS ≥ URSS8. Which one of the following is the most appropriate as a definition of R2 in the context that the term is usually used?(a)It is the proportion of the total variability of y that is explained by the model(b)* It is the proportion of the total variability of y about its mean value that is explainedby the model(c)It is the correlation between the fitted values and the residuals(d)It is the correlation between the fitted values and the mean.9. Suppose that the value of R2 for an estimated regression model is exactly one. Which of the following are true?(i)All of the data points must lie exactly on the line(ii) All of the residuals must be zero(iii) All of the variability of y about is mean have has been explained by the model (i) The fitted line will be horizontal with respect to all of the explanatory variables(a) (ii) and (iv) only(b) (i) and (iii) only(c) * (i), (ii), and (iii) only(i), (ii), (iii), and (iv)10. Consider the following two regressionst t t t u y x y +++=-13221βββt t t t u y x y +++=∆-13221γγγWhich of the following statements are true?(i) The RSS will be the same for the two models(ii) The R 2 will be the same for the two models(iii) The adjusted R 2 will be different for the two models(iv) The regression F -test will be the same for the two models(a) (ii) and (iv) only(b) * (i) and (iii) only(c) (i), (ii), and (iii) only(d) (i), (ii), (iii), and (iv).11. Which of the following are often considered disadvantages of the use of adjusted R 2 as a variable addition / variable deletion rule?(i) Adjusted R 2 always rises as more variables are added(ii) Adjusted R 2 often leads to large models with many marginally significant ormarginally insignificant variables(iii) Adjusted R 2 cannot be compared for models with different explanatory variables (iv) Adjusted R 2 cannot be compared for models with different explained variables.(a) * (ii) and (iv) only(b) (i) and (iii) only(c) (i), (ii), and (iii) only(d) (i), (ii), (iii), and (iv).。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
CHAPTER 3TEACHING NOTESFor undergraduates, I do not work through most of the derivations in this chapter, at least not in detail. Rather, I focus on interpreting the assumptions, which mostly concern the population. Other than random sampling, the only assumption that involves more than population considerations is the assumption about no perfect collinearity, where the possibility of perfect collinearity in the sample (even if it does not occur in the population) should be touched on. The more important issue is perfect collinearity in the population, but this is fairly easy to dispense with via examples. These come from my experiences with the kinds of model specification issues that beginners have trouble with.The comparison of simple and multiple regression estimates – based on the particular sample at hand, as opposed to their statistical properties – usually makes a strong impression. Sometimes I do not bother with the “partialling out” interpretation of multiple regression.As far as statistical properties, notice how I treat the problem of including an irrelevant variable: no separate derivation is needed, as the result follows form Theorem 3.1.I do like to derive the omitted variable bias in the simple case. This is not much more difficult than showing unbiasedness of OLS in the simple regression case under the first four Gauss-Markov assumptions. It is important to get the students thinking about this problem early on, and before too many additional (unnecessary) assumptions have been introduced.I have intentionally kept the discussion of multicollinearity to a minimum. This partly indicates my bias, but it also reflects reality. It is, of course, very important for students to understand the potential consequences of having highly correlated independent variables. But this is often beyond our control, except that we can ask less of our multiple regression analysis. If two or more explanatory variables are highly correlated in the sample, we should not expect to precisely estimate their ceteris paribus effects in the population.I find extensive t reatments of multicollinearity, where one “tests” or somehow “solves” the multicollinearity problem, to be misleading, at best. Even the organization of some texts gives the impression that imperfect collinearity is somehow a violation of the Gauss-Markov assumptions. In fact, they include multicollinearity in a chapter or part of the book devoted to “violation of the basic assumptions,” or something like that. I have noticed that master’s students who have had some undergraduate econometrics are often confused on the multicollinearity issue. It is very important that students not confuse multicollinearity among the included explanatory variables in a regression model with the bias caused by omitting an important variable.I do not prove the Gauss-Markov theorem. Instead, I emphasize its implications. Sometimes, and certainly for advanced beginners, I put a special case of Problem 3.12 on a midterm exam, where I make a particular choice for the function g(x). Rather than have the students directly comparethe variances, they should appeal to the Gauss-Markov theorem for the superiority of OLS over any other linear, unbiased estimator.SOLUTIONS TO PROBLEMS3.1 (i) hsperc is defined so that the smaller it is, the lower the student’s standing in high school . Everything else equal, the worse the student’s standing in high school, the lower is his/her expected college GPA.(ii) Just plug these values into the equation:colgpa = 1.392 - .0135(20) + .00148(1050) = 2.676.(iii) The difference between A and B is simply 140 times the coefficient on sat , because hsperc is the same for both students. So A is predicted to have a score .00148(140) ≈ .207 higher.(iv) With hsperc fixed, colgpa ∆ = .00148∆sat . Now, we want to find ∆sat such that colgpa ∆ = .5, so .5 = .00148(∆sat ) or ∆sat = .5/(.00148) ≈ 338. Perhaps not surprisingly, a large ceteris paribus difference in SAT score – almost two and one-half standard deviations – is needed to obtain a predicted difference in college GPA or a half a point.3.2 (i) Yes. Because of budget constraints, it makes sense that, the more siblings there are in a family, the less education any one child in the family has. To find the increase in the number of siblings that reduces predicted education by one year, we solve 1 = .094(∆sibs ), so ∆sibs = 1/.094 ≈ 10.6.(ii) Holding sibs and feduc fixed, one more year of mother’s education implies .131 years more of predicted education. So if a mother has four more years of education, her son is predicted to have about a half a year (.524) more years of education.(iii) Since the number of siblings is the same, but meduc and feduc are both different, the coefficients on meduc and feduc both need to be accounted for. The predicted difference in education between B and A is .131(4) + .210(4) = 1.364.3.3 (i) If adults trade off sleep for work, more work implies less sleep (other things equal), so 1β < 0.(ii) The signs of 2β and 3β are not obvious, at least to me. One could argue that more educated people like to get more out of life, and so, other things equal, they sleep less (2β < 0). The relationship between sleeping and age is more complicated than this model suggests, and economists are not in the best position to judge such things.(iii) Since totwrk is in minutes, we must convert five hours into minutes: ∆totwrk = 5(60) = 300. Then sleep is predicted to fall by .148(300) = 44.4 minutes. For a week, 45 minutes less sleep is not an overwhelming change.(iv) More education implies less predicted time sleeping, but the effect is quite small. If we assume the difference between college and high school is four years, the college graduate sleeps about 45 minutes less per week, other things equal.(v) Not surprisingly, the three explanatory variables explain only about 11.3% of the variation in sleep . One important factor in the error term is general health. Another is marital status, and whether the person has children. Health (however we measure that), marital status, and number and ages of children would generally be correlated with totwrk . (For example, less healthy people would tend to work less.)3.4 (i) A larger rank for a law school means that the school has less prestige; this lowers starting salaries. For example, a rank of 100 means there are 99 schools thought to be better.(ii) 1β > 0, 2β > 0. Both LSAT and GPA are measures of the quality of the entering class. No matter where better students attend law school, we expect them to earn more, on average. 3β, 4β > 0. The number of volumes in the law library and the tuition cost are both measures of the school quality. (Cost is less obvious than library volumes, but should reflect quality of the faculty, physical plant, and so on.)(iii) This is just the coefficient on GPA , multiplied by 100: 24.8%.(iv) This is an elasticity: a one percent increase in library volumes implies a .095% increase in predicted median starting salary, other things equal.(v) It is definitely better to attend a law school with a lower rank. If law school A has a ranking 20 less than law school B, the predicted difference in starting salary is 100(.0033)(20) =6.6% higher for law school A.3.5 (i) No. By definition, study + sleep + work + leisure = 168. Therefore, if we change study , we must change at least one of the other categories so that the sum is still 168.(ii) From part (i), we can write, say, study as a perfect linear function of the otherindependent variables: study = 168 - sleep - work - leisure . This holds for every observation, so MLR.3 violated.(iii) Simply drop one of the independent variables, say leisure :GPA = 0β + 1βstudy + 2βsleep + 3βwork + u .。