C4.5 分类决策树
数据挖掘中的数据分类算法综述

分析Technology AnalysisI G I T C W 技术136DIGITCW2021.021 决策树分类算法1.1 C 4.5分类算法的简介及分析C4.5分类算法在我国是应用相对较早的分类算法之一,并且应用非常广泛,所以为了确保其能够满足在对规模相对较大的数据集进行处理的过程中有更好的实用性能,对C4.5分类算法也进行了相应的改进。
C4.5分类算法是假如设一个训练集为T ,在对这个训练集建造相应的决策树的过程中,则可以根据In-formation Gain 值选择合理的分裂节点,并且根据分裂节点的具体属性和标准,可以将训练集分为多个子级,然后分别用不同的字母代替,每一个字母中所含有的元组的类别一致。
而分裂节点就成为了整个决策树的叶子节点,因而将会停止再进行分裂过程,对于不满足训练集中要求条件的其他子集来说,仍然需要按照以上方法继续进行分裂,直到子集所有的元组都属于一个类别,停止分裂流程。
决策树分类算法与统计方法和神经网络分类算法相比较具备以下优点:首先,通过决策树分类算法进行分类,出现的分类规则相对较容易理解,并且在决策树中由于每一个分支都对应不同的分类规则,所以在最终进行分类的过程中,能够说出一个更加便于了解的规则集。
其次,在使用决策树分类算法对数据挖掘中的数据进行相应的分类过程中,与其他分类方法相比,速率更快,效率更高。
最后,决策树分类算法还具有较高的准确度,从而确保在分类的过程中能够提高工作效率和工作质量。
决策树分类算法与其他分类算法相比,虽然具备很多优点,但是也存在一定的缺点,其缺点主要体现在以下几个方面:首先,在进行决策树的构造过程中,由于需要对数据集进行多次的排序和扫描,因此导致在实际工作过程中工作量相对较大,从而可能会使分类算法出现较低能效的问题。
其次,在使用C4.5进行数据集分类的过程中,由于只是用于驻留于内存的数据集进行使用,所以当出现规模相对较大或者不在内存的程序及数据即时无法进行运行和使用,因此,C4.5决策树分类算法具备一定的局限性。
2.决策树(DecisionTree)-ID3、C4.5、CART比较

2.决策树(DecisionTree)-ID3、C4.5、CART⽐较1. 前⾔上⽂介绍了决策树原理和算法,并且涉及了ID3,C4.5,CART3个决策树算法。
现在⼤部分都是⽤CART的分类树和回归树,这三个决策树算法是⼀个改进和补充的过程,⽐较它们之间的关系与区别,能够更好的理解决策时算法。
2. ID3算法2.1 ID3原理ID3算法就是⽤信息增益⼤⼩来判断当前节点应该⽤什么特征来构建决策树,⽤计算出的信息增益最⼤的特征来建⽴决策树的当前节点。
算法具体过程看2.2 ID3的不⾜ID3算法虽然提出了新思路,但是还是有很多值得改进的地⽅。
1. ID3没有考虑连续特征,⽐如长度,密度都是连续值,⽆法在ID3运⽤。
这⼤⼤限制了ID3的⽤途。
2. ID3采⽤信息增益⼤的特征优先建⽴决策树的节点。
很快就被⼈发现,在相同条件下,取值⽐较多的特征⽐取值少的特征信息增益⼤。
⽐如⼀个变量有2个值,各为1/2,另⼀个变量为3个值,各为1/3,其实他们都是完全不确定的变量,但是取3个值的⽐取2个值的信息增益⼤。
如果校正这个问题呢?3. ID3算法对于缺失值的情况没有做考虑4. 没有考虑过拟合的问题ID3 算法的作者昆兰基于上述不⾜,对ID3算法做了改进,这就是C4.5算法,也许你会问,为什么不叫ID4,ID5之类的名字呢?那是因为决策树太⽕爆,他的ID3⼀出来,别⼈⼆次创新,很快就占了ID4,ID5,所以他另辟蹊径,取名C4.0算法,后来的进化版为C4.5算法。
下⾯我们就来聊下C4.5算法3. C4.5算法3.1 C4.5对ID3的改进C4.5改进了上⾯ID3的4个问题,C4.5算法流程具体过程看1. 对于ID3不能处理连续特征,C4.5的思路是将连续的特征离散化。
⽐如m个样本的连续特征A有m个,从⼩到⼤排列为a1,a2,...,a m,则C4.5取相邻两样本值的平均数,⼀共取得m−1个划分点,其中第i个划分点Ti表⽰为:T i=a i+a i+12。
常见决策树分类算法都有哪些?

在机器学习中,有一个体系叫做决策树,决策树能够解决很多问题。
在决策树中,也有很多需要我们去学习的算法,要知道,在决策树中,每一个算法都是实用的算法,所以了解决策树中的算法对我们是有很大的帮助的。
在这篇文章中我们就给大家介绍一下关于决策树分类的算法,希望能够帮助大家更好地去理解决策树。
1.C4.5算法C4.5算法就是基于ID3算法的改进,这种算法主要包括的内容就是使用信息增益率替换了信息增益下降度作为属性选择的标准;在决策树构造的同时进行剪枝操作;避免了树的过度拟合情况;可以对不完整属性和连续型数据进行处理;使用k交叉验证降低了计算复杂度;针对数据构成形式,提升了算法的普适性等内容,这种算法是一个十分使用的算法。
2.CLS算法CLS算法就是最原始的决策树分类算法,基本流程是,从一棵空数出发,不断的从决策表选取属性加入数的生长过程中,直到决策树可以满足分类要求为止。
CLS算法存在的主要问题是在新增属性选取时有很大的随机性。
3.ID3算法ID3算法就是对CLS算法的最大改进是摒弃了属性选择的随机性,利用信息熵的下降速度作为属性选择的度量。
ID3是一种基于信息熵的决策树分类学习算法,以信息增益和信息熵,作为对象分类的衡量标准。
ID3算法结构简单、学习能力强、分类速度快适合大规模数据分类。
但同时由于信息增益的不稳定性,容易倾向于众数属性导致过度拟合,算法抗干扰能力差。
3.1.ID3算法的优缺点ID3算法的优点就是方法简单、计算量小、理论清晰、学习能力较强、比较适用于处理规模较大的学习问题。
缺点就是倾向于选择那些属性取值比较多的属性,在实际的应用中往往取值比较多的属性对分类没有太大价值、不能对连续属性进行处理、对噪声数据比较敏感、需计算每一个属性的信息增益值、计算代价较高。
3.2.ID3算法的核心思想根据样本子集属性取值的信息增益值的大小来选择决策属性,并根据该属性的不同取值生成决策树的分支,再对子集进行递归调用该方法,当所有子集的数据都只包含于同一个类别时结束。
机器学习总结(八)决策树ID3,C4.5算法,CART算法

机器学习总结(⼋)决策树ID3,C4.5算法,CART算法本⽂主要总结决策树中的ID3,C4.5和CART算法,各种算法的特点,并对⽐了各种算法的不同点。
决策树:是⼀种基本的分类和回归⽅法。
在分类问题中,是基于特征对实例进⾏分类。
既可以认为是if-then规则的集合,也可以认为是定义在特征空间和类空间上的条件概率分布。
决策树模型:决策树由结点和有向边组成。
结点⼀般有两种类型,⼀种是内部结点,⼀种是叶节点。
内部结点⼀般表⽰⼀个特征,⽽叶节点表⽰⼀个类。
当⽤决策树进⾏分类时,先从根节点开始,对实例的某⼀特征进⾏测试,根据测试结果,将实例分配到⼦结点。
⽽⼦结点这时就对应着该特征的⼀个取值。
如此递归对实例进⾏测试分配,直⾄达到叶结点,则该实例属于该叶节点的类。
决策树分类的主要算法有ID3,C4.5。
回归算法为CART算法,该算法既可以分类也可以进⾏回归。
(⼀)特征选择与信息增益准则特征选择在于选取对训练数据具有分类能⼒的特征,⽽且是分类能⼒越强越好,这样⼦就可以提⾼决策树的效率。
如果利⽤⼀个特征进⾏分类,分类的结果与随机分类的结果没有差异,那么这个特征是没有分类能⼒的。
那么⽤什么来判别⼀个特征的分类能⼒呢?那就是信息增益准则。
何为信息增益?⾸先,介绍信息论中熵的概念。
熵度量了随机变量的不确定性,越不确定的事物,它的熵就越⼤。
具体的,随机变量X的熵定义如下:条件熵H(Y|X)表⽰在已知随机变量X的条件下随机变量Y的不确定性,随机变量X给定的条件下随机变量Y的条件熵为H(Y|X),定义为X给定条件下Y的条件概率分布的熵对X的数学期望:信息增益表⽰在已知特征X的情况下,⽽使得Y的信息的不确定性减少的程度。
信息增益的定义式如下:g(D,A)表⽰特征A对训练集D的信息增益,其为集合D的经验熵H(D)与在特征A给定条件下D的经验条件熵H(D|A)之差。
⼀般熵与条件熵之差,称为互信息。
在决策树中,信息增益就等价于训练数据集中的类与特征的互信息。
C45算法

• 定理表明, 对连续属性A , 使得实例集合的平均类熵达 到最小值的T , 总是处于实例序列中两个相邻异类实例 之间。
整理ppt
14
(2)能够完成对连续属性的离散化处理
信息增益(Gain) :
G a ( V ) i H n ( C ) H ( C |V ) io n ( T ) i fo n v ( T )f
属性V的信息熵:
n
H(V) p(vi)log2(p(vi)) i1
n
i1
|Ti | |T|
log2||TTi ||
spli_t info(V)
整理ppt
政治成绩的信息增益为:
G ai(政 n 治成 I(r1 绩 ,r2,r3 ) ,r4)E(政治成绩 0.559
整理ppt
5
(1)用信息增益率代替信息增益来选择属性;
设T 为训练数据集,共有k 个类别,集合表示为 { C1 ,C2 , ⋯,Ck } , | Cj |为Cj 类的例子数, | T |为数据集T 的例子数。 选择一个属性V, 设它有n个互不重合的取值va ( 1≤a≤n) ,则T 被分为n个子集{ T1,T2⋯,Tn } , 这里 Ti 中的所有实例的取值均为vi。|Ti|为V =vi 的例子 数, |Cjv|是V =vi 的例子中,具有Cj 类别的例子数。
整理ppt
15
(2)能够完成对连续属性的离散化处理
当需要离散化的属性的属性值越多, 而所属类别越少 时, 性能提高越明显;
当出现最不理想情况, 即每个属性值对应一个类别, 改进算法运算次数与未改进算法相同, 不会降低算法 性能。
C4.5决策树
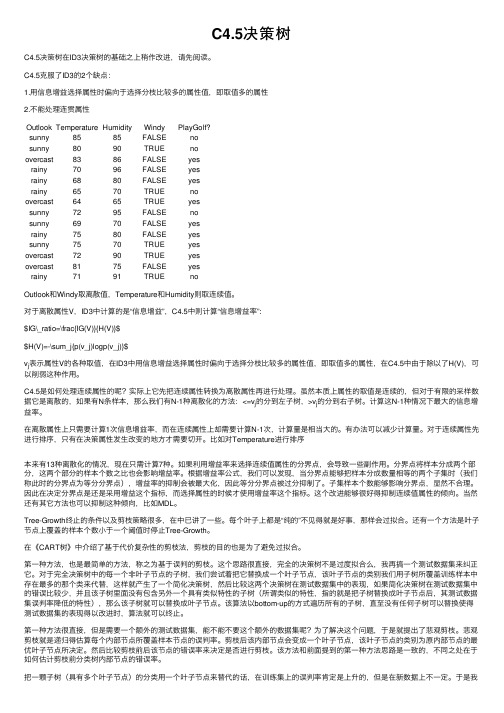
C4.5决策树C4.5决策树在ID3决策树的基础之上稍作改进,请先阅读。
C4.5克服了ID3的2个缺点:1.⽤信息增益选择属性时偏向于选择分枝⽐较多的属性值,即取值多的属性2.不能处理连贯属性Outlook Temperature Humidity Windy PlayGolf?sunny8585FALSE nosunny8090TRUE noovercast8386FALSE yesrainy7096FALSE yesrainy6880FALSE yesrainy6570TRUE noovercast6465TRUE yessunny7295FALSE nosunny6970FALSE yesrainy7580FALSE yessunny7570TRUE yesovercast7290TRUE yesovercast8175FALSE yesrainy7191TRUE noOutlook和Windy取离散值,Temperature和Humidity则取连续值。
对于离散属性V,ID3中计算的是“信息增益”,C4.5中则计算“信息增益率”:$IG\_ratio=\frac{IG(V)}{H(V)}$$H(V)=-\sum_j{p(v_j)logp(v_j)}$v j表⽰属性V的各种取值,在ID3中⽤信息增益选择属性时偏向于选择分枝⽐较多的属性值,即取值多的属性,在C4.5中由于除以了H(V),可以削弱这种作⽤。
C4.5是如何处理连续属性的呢?实际上它先把连续属性转换为离散属性再进⾏处理。
虽然本质上属性的取值是连续的,但对于有限的采样数据它是离散的,如果有N条样本,那么我们有N-1种离散化的⽅法:<=v j的分到左⼦树,>v j的分到右⼦树。
计算这N-1种情况下最⼤的信息增益率。
在离散属性上只需要计算1次信息增益率,⽽在连续属性上却需要计算N-1次,计算量是相当⼤的。
有办法可以减少计算量。
c4.5决策树原理

c4.5决策树原理C4.5(也称为C5.0)是一种经典的决策树算法,由Ross Quinlan于1993年提出。
它是一种用于机器学习和数据挖掘的强大工具,主要用于分类问题。
以下是C4.5决策树算法的原理概述:1. 信息熵和信息增益:C4.5使用信息熵和信息增益来构建决策树。
信息熵是对数据集的纯度度量,信息增益表示通过某个属性对数据集进行划分所带来的纯度提升。
C4.5的目标是选择信息增益最大的属性作为划分依据。
2. 决策树构建过程:2.1 选择最佳属性:•对每个属性计算信息增益。
•选择信息增益最大的属性作为当前节点的划分属性。
2.2 划分数据集:•使用选定的属性对数据集进行划分,生成子节点。
•对于每个子节点,递归执行上述过程,直到满足停止条件。
2.3 停止条件:•数据集已经纯净(属于同一类别)。
•到达树的最大深度。
•不再有可用属性进行划分。
3. 剪枝:C4.5在决策树构建完成后执行剪枝,以避免过度拟合。
剪枝的目标是去除一些不必要的叶子节点,提高模型的泛化性能。
4. 缺失值处理:C4.5能够处理缺失值,当在某个节点上某个属性的值缺失时,它会考虑所有可能的取值,并按照缺失值所占比例计算信息增益。
5. 数值型属性处理:对于数值型属性,C4.5采用二分法进行处理。
它通过在属性上选择一个阈值,将数据集分为两个子集,然后选择信息增益最大的阈值进行划分。
6. 实例加权:在C4.5中,每个样本都有一个权重,这个权重可以用于调整每个样本在信息增益计算中的贡献度。
7. 优缺点:7.1 优点:•生成的决策树易于理解和解释。
•能够处理混合属性类型。
•能够处理缺失值。
•具有较好的泛化性能。
7.2 缺点:•对噪声敏感。
•生成的树可能过于复杂,需要进行剪枝。
•处理大量数据时可能效率较低。
8. 应用领域:C4.5广泛应用于分类问题,例如医学诊断、金融风险评估、客户分类等领域。
9.C4.5决策树算法通过利用信息熵和信息增益来构建树结构,是一种强大的分类工具。
c4.5算法例题

c4.5算法例题C4.5(也称为J48)是一种用于决策树分类的经典算法。
它是ID3算法的改进版本,能够处理连续属性和缺失值,并使用信息增益比来选择最佳分裂属性。
下面是一个示例题目,展示了如何使用C4.5算法构建决策树。
假设我们有一个数据集,描述了一些动物的特征,并指示它们是否属于"哺乳动物"这一类别。
数据集的特征包括体温(连续值,单位为摄氏度)、鳞片覆盖(离散值,取值为"有"或"无")、生育类型(离散值,取值为"胎生"或"卵生")、是否有爪子(离散值,取值为"是"或"否")。
下面是一个简化的数据集示例:现在我们使用C4.5算法构建一个决策树来预测动物的类别。
首先,我们计算每个特征的信息增益比,并选择信息增益比最高的特征作为根节点。
在这个例子中,我们的目标是预测动物的类别,因此我们计算每个特征相对于类别的信息增益比。
1. 计算体温的信息增益比:-计算体温的信息增益。
-计算体温的分裂信息(使用离散化的方法,例如将体温分为几个范围)。
-计算体温的信息增益比。
2. 计算鳞片覆盖的信息增益比:-计算鳞片覆盖的信息增益。
-计算鳞片覆盖的分裂信息。
-计算鳞片覆盖的信息增益比。
3. 计算生育类型的信息增益比:-计算生育类型的信息增益。
-计算生育类型的分裂信息。
-计算生育类型的信息增益比。
4. 计算是否有爪子的信息增益比:-计算是否有爪子的信息增益。
-计算是否有爪子的分裂信息。
-计算是否有爪子的信息增益比。
选择信息增益比最高的特征作为根节点,并根据该特征的不同取值构建子节点。
重复这个过程,直到所有的数据都被正确分类或没有更多的特征可用为止。
这只是一个简化的例子,实际应用中可能涉及更多的特征和数据。
C4.5算法会自动选择最佳的特征和分裂点,以构建一个准确且具有解释性的决策树模型。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
C4.5是一系列用在机器学习和数据挖掘的分类问题中的算法。
它的目标是监督学习:给定一个数据集,其中的每一个元组都能用一组属性值来描述,每一个元组属于一个互斥的类别中的某一类。
C4.5的目标是通过学习,找到一个从属性值到类别的映射关系,并且这个映射能用于对新的类别未知的实体进行分类。
C4.5由J.Ross Quinlan在ID3的基础上提出的。
ID3算法用来构造决策树。
决策树是一种类似流程图的树结构,其中每个内部节点(非树叶节点)表示在一个属性上的测试,每个分枝代表一个测试输出,而每个树叶节点存放一个类标号。
一旦建立好了决策树,对于一个未给定类标号的元组,跟踪一条有根节点到叶节点的路径,该叶节点就存放着该元组的预测。
决策树的优势在于不需要任何领域知识或参数设置,适合于探测性的知识发现。
从ID3算法中衍生出了C4.5和CART两种算法,这两种算法在数据挖掘中都非常重要。
下图就是一棵典型的C4.5算法对数据集产生的决策树。
数据集如图1所示,它表示的是天气情况与去不去打高尔夫球之间的关系。
图1 数据集
图2 在数据集上通过C4.5生成的决策树
算法描述
C4.5并不一个算法,而是一组算法—C4.5,非剪枝C4.5和C4.5规则。
下图中的算法将给出C4.5的基本工作流程:
图3 C4.5算法流程
我们可能有疑问,一个元组本身有很多属性,我们怎么知道首先要对哪个属性进行判断,接下来要对哪个属性进行判断?换句话说,在图2中,我们怎么知道第一个要测试的属性是Outlook,而不是Windy?其实,能回答这些问题的一个概念就是属性选择度量。
属性选择度量
属性选择度量又称分裂规则,因为它们决定给定节点上的元组如何分裂。
属性选择度量提供了每个属性描述给定训练元组的秩评定,具有最好度量得分的属性被选作给定元组的分裂属性。
目前比较流行的属性选择度量有--信息增益、增益率和Gini指标。
先做一些假设,设D是类标记元组训练集,类标号属性具有m个不同值,m个不同类Ci(i=1,2,…,m),CiD是D中Ci类的元组的集合,|D|和|CiD|分别是D和CiD中的元组个数。
(1)信息增益
信息增益实际上是ID3算法中用来进行属性选择度量的。
它选择具有最高信息增益的属性来作为节点N的分裂属性。
该属性使结果划分中的元组分类所需信息量最小。
对D中的元组分类所需的期望信息为下式:
(1)
Info(D)又称为熵。
现在假定按照属性A划分D中的元组,且属性A将D划分成v个不同的类。
在该划分之后,为了得到准确的分类还需要的信息由下面的式子度量:
(2)
信息增益定义为原来的信息需求(即仅基于类比例)与新需求(即对A划分之后得到的)之间的差,即
(3)
我想很多人看到这个地方都觉得不是很好理解,所以我自己的研究了文献中关于这一块的描述,也对比了上面的三个公式,下面说说我自己的理解。
一般说来,对于一个具有多个属性的元组,用一个属性就将它们完全分开几乎不可能,否则的话,决策树的深度就只能是2了。
从这里可以看出,一旦我们选择一个属性A,假设将元组分成了两个部分A1和A2,由于A1和A2还可以用其它属性接着再分,所以又引出一个新的问题:接下来我们要选择哪个属性来分类?对D中元组分类所需的期望信息是Info(D) ,那么同理,当我们通过A将D划分成v个子集
Dj(j=1,2,…,v)之后,我们要对Dj的元组进行分类,需要的期望信息就是Info(Dj),而一共有v个类,所以对v个集合再分类,需要的信息就是公式(2)了。
由此可知,如果公式(2)越小,是不是意味着我们接下来对A分出来的几个集合再进行分类所需要的信息就越小?而对于给定的训练集,实际上Info(D)已经固定了,所以选择信息增益最大的属性作为分裂点。
但是,使用信息增益的话其实是有一个缺点,那就是它偏向于具有大量值的属性。
什么意思呢?就是说在训练集中,某个属性所取的不同值的个数越多,那么越有可能拿它来作为分裂属性。
例如一个训练集中有10个元组,对于某一个属相A,它分别取1-10这十个数,如果对A 进行分裂将会分成10个类,那么对于每一个类Info(Dj)=0,从而式(2)为0,该属性划分所得到的信息增益(3)最大,但是很显然,这种划分没有意义。
(2)信息增益率
正是基于此,ID3后面的C4.5采用了信息增益率这样一个概念。
信息增益率使用“分裂信息”值将信息增益规范化。
分类信息类似于
Info(D),定义如下:
(4)
这个值表示通过将训练数据集D划分成对应于属性A测试的v个输出的v个划分产生的信息。
信息增益率定义:
(5)
选择具有最大增益率的属性作为分裂属性。
(3)Gini指标
Gini指标在CART中使用。
Gini指标度量数据划分或训练元组集D 的不纯度,定义为:
(6)
其它特征
树剪枝
在决策树的创建时,由于数据中的噪声和离群点,许多分枝反映的是训练数据中的异常。
剪枝方法是用来处理这种过分拟合数据的问题。
通常剪枝方法都是使用统计度量,剪去最不可靠的分枝。
剪枝一般分两种方法:先剪枝和后剪枝。
先剪枝方法中通过提前停止树的构造(比如决定在某个节点不再分裂或划分训练元组的子集)而对树剪枝。
一旦停止,这个节点就变成树
叶,该树叶可能取它持有的子集最频繁的类作为自己的类。
先剪枝有很多方法,比如(1)当决策树达到一定的高度就停止决策树的生长;(2)到达此节点的实例具有相同的特征向量,而不必一定属于同一类,也可以停止生长(3)到达此节点的实例个数小于某个阈值的时候也可以停
止树的生长,不足之处是不能处理那些数据量比较小的特殊情况(4)
计算每次扩展对系统性能的增益,如果小于某个阈值就可以让它停止生长。
先剪枝有个缺点就是视野效果问题,也就是说在相同的标准下,也许当前扩展不能满足要求,但更进一步扩展又能满足要求。
这样会过早停止决策树的生长。
另一种更常用的方法是后剪枝,它由完全成长的树剪去子树而形成。
通过删除节点的分枝并用树叶来替换它。
树叶一般用子树中最频繁的类别来标记。
C4.5采用悲观剪枝法,它使用训练集生成决策树又用它来进行剪枝,不需要独立的剪枝集。
悲观剪枝法的基本思路是:设训练集生成的决策树是T,用T来分类训练集中的N的元组,设K为到达某个叶子节点的元组个数,其中分类错误地个数为J。
由于树T是由训练集生成的,是适合训练集的,因此J/K不能可信地估计错误率。
所以用(J+0.5)/K来表示。
设S为T的子树,其叶节点个数为L(s),为到达此子树的叶节点的元组个数总和,为此子树中被错误分类的元组个数之和。
在分类新的元组时,则其错误分类个数为,其标准错误表示为:。
当用此树分类训练集时,设E为分类错误个数,当下面的式子成立时,则删掉子树S,用叶节点代替,且S的子树不必再计算。