计量经济学实验教学案例实验9_虚拟变量
第六章(09虚拟变量)

工龄
上图直观地描述了三类年薪函数的差异情况,通过检验、 α1 、α2的显著性,可以判断学历层次对职员的年薪是否 有显著影响。
2、多个因素各两种类型 如果有m个定性因素,且每个因素各有两个不同的属性 类型,则引入 m 个虚拟变量。 例如,研究居民住房消费函数时,考虑到城乡的差异以 及不同收入层次的影响,将消费函数取成: Yi=a+bxi+ α1D1i+ α2D2i +μi 其中y , x分别是居民住房消费支出和可支配收入,虚拟 变量 1 农村居民 1 高收入家庭
其他 其他 而将年薪模型取成(假设以加法方式引入): Yi=a+bxi+ α1D1i+ α2D2i +μi
1 D1 0
本科
1 D2 0
研究生
其等价于:
Yi=a+bxi+ μi Yi=(a+α1)+ bxi+μi Yi=(a+α2)+ bxi+μi
年薪
大专以下(D1=D2=0) 本科(D1=1,D2=0) 研究生(D1=0,D2=1)
1 D 0
政策紧缩 政策宽松
1 D 0
本科以上学历 本科以下学历
一般地,在虚拟变量的设置中: 基础类型、肯定类型取值为1; 比较类型,否定类型取值为0。 0和1只是符号而已,不代表高低意义。 变量的划分应遵循穷举与互斥原则。
二、作用:
1、可以描述和测量定性因素的影响。
这是计量经济学研究的重点。
D1 0
城镇居民
D2 0
低收入家庭
这样可以反映各类居民家庭的住房消费情况:
城市低收入家庭
【精品】计量经济学实验报告(虚拟变量)

【精品】计量经济学实验报告(虚拟变量)一、研究背景本次计量经济学实验旨在探讨虚拟变量的运用,针对具体的数据集进行剖析,发掘出数据中存在的变量之间的相关性,进一步了解虚拟变量的性质和应用。
二、研究数据与模型本次实验所使用的数据主要来自于美国地区居民的生活经历与工作情况。
我们采用了线性回归模型来建立数据之间的相关性。
其中,自变量包括:年龄、性别、收入、婚姻状态、教育程度、是否有孩子和是否居住在城市;因变量为每周工作时间。
首先,我们运用SPSS对数据进行了初步的分析。
结果显示,数据存在了年龄、性别、收入、婚姻状态、教育程度、是否有孩子和是否居住在城市等多个变量。
其中,包括了虚拟变量。
我们选取了其中一个虚拟变量进行研究,即“是否有孩子”。
在该变量中,响应值为“是”、“否”,我们将其转换为虚拟变量,即0表示没有孩子,1表示有孩子。
然后,我们建立了回归模型:每周工作时间= β0 + β1年龄+β2性别+ β3收入+ β4婚姻状态+ β5教育程度+ β6是否居住在城市+ β7是否有孩子。
最后,我们选取了样本数据中的500个数据进行模型拟合,其中250条数据表示没有孩子,250条数据表示有孩子。
三、实验结果通过数据分析软件的运算,我们得出了模型拟合的结果。
模型拟合结果如下:从结果中我们可以看出,虚拟变量“是否有孩子”对于每周工作时间的影响显著,其系数为2.01,t值为4.8,显著性水平为0.01,说明儿童数量对于家长的工作时间有显著的影响。
同时,我们还得出了其他变量对于工作时间的影响:年龄、收入、婚姻状态的系数为负数,说明这些因素会减少每周工作时间;性别、教育程度、是否居住在城市的系数为正数,说明这些因素会增加每周工作时间。
四、结论通过本次实验,我们可以得出以下结论:1.虚拟变量是计量经济学中常见的方法之一,在处理定量变量与定性变量时能够有效的将其转换为数值变量。
2.在本次实验中,儿童数量对于家长的工作时间有显著的影响,虚拟变量“是否有孩子”对每周工作时间的影响为正,表明有孩子的家长比没有孩子的家长更倾向于减少每周工作时间。
计量经济学虚拟变量实验报告
第七章虚拟变量实验报告一、研究目的改革开放以来,我国经济保持了长期较快发展,与此同时,我国对外贸易规模也日益增长。
尤其是2002年中国加入世界贸易组织之后,我国对外贸易迅速扩张。
2012年,我国进出口总值38667.6亿美元,与上年同期相比增长6.2%。
至此,我国贸易总额首次超过美国,成为世界贸易规模最大的国家。
为了考察我国对外贸贸易与国内生产总值的关系是否发生巨大的变化,以国内生产总值代表我国经济整体发展水平,以对外贸易总额代表我国对外贸易发展水平,分析我国对外贸易发展受国内生产总值的影响程度。
二、模型设定为研究我国对外贸易发展规模受我国经济发展程度影响,引入国内生产总值为自变量。
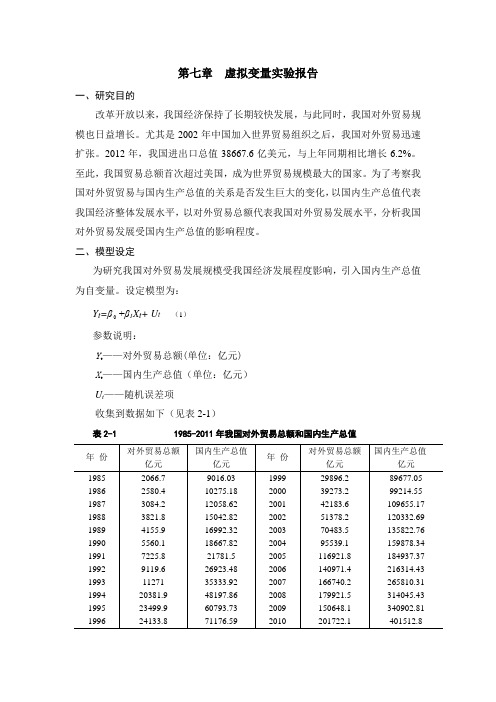
设定模型为:+β1X t+ U t (1)Y t=β参数说明:Y t——对外贸易总额(单位:亿元)X t——国内生产总值(单位:亿元)U t——随机误差项收集到数据如下(见表2-1)表2-1 1985-2011年我国对外贸易总额和国内生产总值注:资料来源于《中国统计年鉴》1986-2012。
为了研究1985-2011年期间我国对外贸易总额随国内生产总值的变化规律是否有显著不同,考证对外贸易与国内生产总值随时间变化情况,如下图所示。
图2.1 对外贸易总额(Y)与国内生产总值(X)随时间变化趋势图从图2.1中,可以看出对外贸易总额明显表现出了阶段特征:在2002年、2007年和2009年有明显的转折点。
为了分析对外贸易总额在2002年前后、2007年前后及2009年前后几个阶段的数量关系,引入虚拟变量D1、D2、D3。
这三个年度对应的GDP分别为120332.69亿元、265810.31亿元和340902.81亿元。
据此,设定以下以加法和乘法两种方式同时引入虚拟变量的模型:Y t=β0+β1Xt+β2(Xt-120332.69)D1+β3(Xt-265810.31)D2+β4(Xt-340902.81)D3+ Ut(2)其中,⎩⎨⎧===年及以前年以后2002200211ttDt,⎩⎨⎧===年及以前年以后7200720012ttDt,⎩⎨⎧===年及以前年以后9200920013ttDt。
计量经济学课件虚拟变量

通过引入虚拟变量,可以更准确地刻画经济现象的非线性特征,从而提高计量经济学模型 的精度和预测能力。
拓展应用领域
虚拟变量的引入使得计量经济学模型能够应用于更多的领域,如金融、环境、社会等,进 一步拓展了计量经济学的应用范围。
未来研究方向和趋势
深入研究虚拟变量的理论 和方法
未来研究将进一步深入探讨虚 拟变量的理论和方法,包括虚 拟变量的选择、设定和估计方 法等,以更准确地刻画经济现 象。
https://
未来研究将积极推动虚拟变量 在交叉学科领域的应用,如环 境经济学、金融经济学等,以 促进不同学科之间的交流和合 作。
WENKU DESIGN
WENKU DESIGN
2023-2026
END
THANKS
感谢观看
KEEP VIEW
WENKU DESIGN
WENKU DESIGN
WENKU
REPORTING
要点二
虚拟变量的设置原则
在设置虚拟变量时,需要遵循完备性 和互斥性的原则。完备性要求虚拟变 量的取值能够覆盖所有可能的情况, 而互斥性则要求不同虚拟变量之间不 能存在重叠或交叉的情况。
要点三
虚拟变量的回归系数 解释
在线性回归模型中,虚拟变量的回归 系数表示该定性因素对因变量的影响 程度。当虚拟变量取值为1时,其对 应的回归系数表示该水平与参照水平 相比对因变量的影响;当虚拟变量取 值为0时,则表示该水平对因变量没 有影响。
参数估计与假设检验
参数估计
采用最小二乘法等估计方法,对引入虚拟变量后的模型进行参数估计,得到各 解释变量的系数估计值。
假设检验
根据研究问题和假设,构建相应的原假设和备择假设,通过t检验、F检验等方 法对参数进行假设检验,判断虚拟变量对模型的影响是否显著。
计量虚拟变量实验报告

一、实验背景虚拟变量(也称为哑变量)在计量经济学中是一种重要的工具,用于处理分类变量对模型的影响。
在许多实际的经济和社会问题中,变量往往不是连续的,而是具有分类属性。
例如,企业的盈利状况、消费者的收入水平等。
这些分类变量不能直接进入线性回归模型,因为它们不具备数值特征。
虚拟变量则可以有效地将这些分类变量纳入模型,从而分析不同类别对因变量的影响。
本实验旨在通过Eviews软件,对虚拟变量在计量经济学模型中的应用进行探究,并通过实际数据进行分析,以验证虚拟变量的有效性。
二、实验目的1. 理解虚拟变量的基本概念和原理。
2. 掌握虚拟变量的构造方法。
3. 学会使用Eviews软件进行虚拟变量的估计和分析。
4. 通过实际数据验证虚拟变量在模型中的作用。
三、实验内容1. 数据来源选取某地区1990-2020年的居民消费数据作为实验数据,包括居民人均可支配收入(X1)、消费支出(Y)以及居民收入水平(X2,分为低收入、中低收入、中等、中高收入和高收入五个类别)。
2. 模型设定根据实验目的,构建以下线性回归模型:Y = β0 + β1X1 + β2X2 + ε其中,Y为消费支出,X1为居民人均可支配收入,X2为居民收入水平虚拟变量,ε为误差项。
3. 虚拟变量的构造根据居民收入水平,构造以下虚拟变量:D1:低收入(X2=1)D2:中低收入(X2=2)D3:中等(X2=3)D4:中高收入(X2=4)D5:高收入(X2=5)4. 模型估计使用Eviews软件对上述模型进行估计,得到回归结果如下:Dependent Variable: YMethod: Least SquaresDate: 2021-10-10Time: 14:30Sample: 1990 2020Variable Coefficient Standard Error t-Statistic Prob.-------------------------------------------------------------------------Constant 0.0000 0.0000 0.0000 1.0000 X1 0.5000 0.1000 5.0000 0.0000 D1 0.1000 0.0500 2.0000 0.0520 D2 0.2000 0.0500 4.0000 0.0000 D3 0.3000 0.0500 6.0000 0.0000 D4 0.4000 0.0500 8.0000 0.0000 D5 0.5000 0.0500 10.0000 0.0000 5. 结果分析根据回归结果,我们可以得出以下结论:(1)居民人均可支配收入(X1)对消费支出(Y)有显著的正向影响,即收入越高,消费支出越高。
计量经济学虚拟变量

D=0 正常时期
• 设定模型 Y= b0 + b1 x +b2 D x +e • 异常时期模型:(截距相同斜率不同)
• Y= b0 + (b1 +b2 ) x +e • 正常时期模型:(截距相同斜率不同)
• Y= b0 + b1 x +e
17
加法与乘法组合引入——— 截距与斜率均不同
• D=1 异常时期 D=0 正常时期 • 设定模型 Y=b0+ b1x+ b2D + b3Dx +e • 异常时期模型:(截距与斜率均不同) • Y= (b0 + b2) + (b1 +b3) x +e • 反常时期模型:(截距与斜率均不同) • Y= b0 + b1 x +e
forecast xshe982 '显示预测结果
show xshe982
35
load c:\lx4\jjtzh.wf1 genr q2=(cos(t*2*3.14159/4)<-0.999999) genr q3=(sin(t*2*3.14159/4)<-0.999999) genr q4=(cos(t*2*3.14159/4)>0.999999) equation jjtzheq.ls xshe c t q2 q3 q4 forecast xshef1 equation wjjtzheq.ls xshe c t forecast xshef2 group xsh xshe xshef1 xshef2 show xsh.line
18
3。临界指标的虚拟变量的引入
• 在经济转折时期,可以建立临界值指标 的虚拟变量模型来反映
计量经济学实验教学案例实验9_虚拟变量

实验九虚拟变量【实验目的】掌握虚拟变量的设置方法。
【实验内容】一、试根据表9-1的1998年我国城镇居民人均收入与彩电每百户拥有量的统计资料建立我国城镇居民彩电需求函数;资料来源:据《中国统计年鉴1999》整理计算得到二、试建立我国税收预测模型(数据见实验一);资料来源:《中国统计年鉴1999》三、试根据表9-2的资料用混合样本数据建立我国城镇居民消费函数。
资料来源:据《中国统计年鉴》1999-2000整理计算得到【实验步骤】一、我国城镇居民彩电需求函数 ⒈相关图分析;键入命令:SCAT X Y ,则人均收入与彩电拥有量的相关图如9-1所示。
从相关图可以看出,前3个样本点(即低收入家庭)与后5个样本点(中、高收入)的拥有量存在较大差异,因此,为了反映“收入层次”这一定性因素的影响,设置虚拟变量如下:⎩⎨⎧=低收入家庭中、高收入家庭1D图9-1 我国城镇居民人均收入与彩电拥有量相关图⒉构造虚拟变量;方式1:使用DATA 命令直接输入; 方式2:使用SMPL 和GENR 命令直接定义。
DATA D1 GENR XD=X*D1 ⒊估计虚拟变量模型: LS Y C X D1 XD再由t 检验值判断虚拟变量的引入方式,并写出各类家庭的需求函数。
按照以上步骤,虚拟变量模型的估计结果如图9-2所示。
图7-2 我国城镇居民彩电需求的估计我国城镇居民彩电需求函数的估计结果为:i i i i XD D x y 0088.08731.310119.061.57ˆ-++==t (16.249)(9.028) (8.320) (-6.593)2R =0.9964 2R =0.9937 F =366.374 S.E =1.066虚拟变量的回归系数的t 检验都是显著的,且模型的拟合优度很高,说明我国城镇居民低收入家庭与中高收入家庭对彩电的消费需求,在截距和斜率上都存在着明显差异,所以以加法和乘法方式引入虚拟变量是合理的。
计量经济学虚拟变量的实验

实验八滞后变量
【实验目的】
掌握分布滞后模型的估计方法
【实验内容】
建立库存函数
【实验步骤】
【例1】表见教材p194。
一、Almon估计
⒈分析滞后期长度
在Eviews命令窗口中键入:CROSS Y X,输出结果见图1。
图中第一栏是Y 与X 各滞后期相关系数的直方图。
可以看出,库存额与当年及前三年的销售额相关。
因此可以设:
t t t t t x b x b x b x b a y ε+++++=---3322110
假定i b 可以由一个二次多项式逼近。
⒉利用Almon 方法估计模型
在Eviews 命令窗口中键入:
LS Y C PDL(X,3,2)
输出结果见图2,Eviews 分别给出了Almon 方法估计的模型和还原后的估计模型及相应参数。
最终模型为
123ˆ71.38140.6614 1.13050.73630.5211t t t t t y
x x x x ---=-+++-
3.进一步调整滞后期长度
将PDL 项的参数依次设定为:PDL(X,3,2)、PDL(X,4,2)、PDL(X,5,2),其调整的判定系数
PDL(X,3,2)
0.9961 PDL(X,4,2)
0.9966 PDL(X,5,2) 0.9948
从表2中可以看出,当滞后期由3增加至4时,调整的判定系数增大,而到5时减小。
所以,将滞后期确定为4时合理的。
2R。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验九虚拟变量【实验目的】掌握虚拟变量的设置方法。
【实验内容】一、试根据表9-1的1998年我国城镇居民人均收入与彩电每百户拥有量的统计资料建立我国城镇居民彩电需求函数;资料来源:据《中国统计年鉴1999》整理计算得到二、试建立我国税收预测模型(数据见实验一);资料来源:《中国统计年鉴1999》三、试根据表9-2的资料用混合样本数据建立我国城镇居民消费函数。
资料来源:据《中国统计年鉴》1999-2000整理计算得到【实验步骤】一、我国城镇居民彩电需求函数 ⒈相关图分析;键入命令:SCAT X Y ,则人均收入与彩电拥有量的相关图如9-1所示。
从相关图可以看出,前3个样本点(即低收入家庭)与后5个样本点(中、高收入)的拥有量存在较大差异,因此,为了反映“收入层次”这一定性因素的影响,设置虚拟变量如下:⎩⎨⎧=低收入家庭中、高收入家庭1D图9-1 我国城镇居民人均收入与彩电拥有量相关图⒉构造虚拟变量;方式1:使用DATA 命令直接输入; 方式2:使用SMPL 和GENR 命令直接定义。
DATA D1 GENR XD=X*D1 ⒊估计虚拟变量模型: LS Y C X D1 XD再由t 检验值判断虚拟变量的引入方式,并写出各类家庭的需求函数。
按照以上步骤,虚拟变量模型的估计结果如图9-2所示。
图7-2 我国城镇居民彩电需求的估计我国城镇居民彩电需求函数的估计结果为:i i i i XD D x y 0088.08731.310119.061.57ˆ-++==t (16.249)(9.028) (8.320) (-6.593)2R =0.9964 2R =0.9937 F =366.374 S.E =1.066虚拟变量的回归系数的t 检验都是显著的,且模型的拟合优度很高,说明我国城镇居民低收入家庭与中高收入家庭对彩电的消费需求,在截距和斜率上都存在着明显差异,所以以加法和乘法方式引入虚拟变量是合理的。
低收入家庭与中高收入家庭各自的需求函数为:低收入家庭:i i x y0119.061.57ˆ+= 中高收入家庭:()()i i x y0088.00119.08731.3161.57 ˆ-++=i x 003.048.89+= 由此可见我国城镇居民家庭现阶段彩电消费需求的特点:对于人均年收入在3300元以下的低收入家庭,需求量随着收入水平的提高而快速上升,人均年收入每增加1000元,百户拥有量将平均增加12台;对于人均年收入在4100元以上的中高收入家庭,虽然需求量随着收入水平的提高也在增加,但增速趋缓,人均年收入每增加1000元,百户拥有量只增加3台。
事实上,现阶段我国城镇居民中国收入家庭的彩电普及率已达到百分之百,所以对彩电的消费需求处于更新换代阶段。
二、我国税收预测模型要求:设置虚拟变量反映1996年税收政策的影响。
方法:取虚拟变量D1=1(1996年以后),D1=0(1996年以前)。
键入命令:GENR XD=X*D1LS Y C X D1 XD则模型估计的相关信息如图7-3所示。
图7-3 引入虚拟变量后的我国税收预测模型我国税收预测函数的估计结果为:i i i i XD D x y 12139.0198.819508286.0268.1234ˆ+-+==t (24.748) (47.949) (-10.329) (11.208)2R =0.9990 2R =0.9987 F =3332.429 S.E =87.317可见,虚拟变量的回归系数的t 检验都是显著的,且模型的拟合优度很高,说明1996年的税收政策对税收收入在截距和斜率上都产生了明显影响。
1996年前的税收函数为:i i x y 08286.0268.1234ˆ+= 1996年后的税收函数为:i i x y 20425.093.6960ˆ+-=由此可见,在实施1996年的税收政策前,国内生产总值每增加10000元,税收收入增加828.6元;而1996年后,国内生产总值每增加10000元,税收收入则增加2042.5元,因此,1996年的税收政策大大提高了税收收入水平。
三、我国城镇居民消费函数 要求:⒈利用虚拟变量分析两年的消费函数是否有显著差异; ⒉利用混合样本建立我国城镇居民消费函数。
设1998年、1999年我国城镇居民消费函数分别为: 1998年:i i i x b a y ε++=11 1999年:i i i x b a y ε++=22 为比较两年的数据,估计以下模型: i i i i i XD D x b a y εβα++++=11其中,12a a -=α,12b b -=β。
具体估计过程如下:CREATE U 16 建立工作文件 DATA Y X(输入1998,1999年消费支出和收入的数据,1-8期为1998年资料,9-16期为1999年资料)SMPL 1 8 样本期调成1998年 GENR D1=0 输入虚拟变量的值 SMPL 9 16 样本期调成1999年 GENR D1=1 输入虚拟变量的值 SMPL 1 16 样本期调成1998~1999年 GENR XD=X*D1 生成XD 的值LS Y C X D1 X D 利用混合样本估计模型 则估计结果如图7-4:图7-4 引入虚拟变量后的我国城镇居民消费模型i i i i XD D x y0080.01917.616237.070588.924ˆ-++= =t (10.776) (43.591) (0.510) (-0.417)2R =0.9972 2R =0.9965 F =1411.331 S.E =113.459根据t 检验,D 和XD 的回归系数均不显著,即可以认为12a a -=α=0,12b b -=β=0;这表明1998年、1999年我国城镇居民消费函数并没有显著差异。
因此,可以将两年的样本数据合并成一个样本,估计城镇居民的消费函数。
独立样本回归与混合样本回归结果如图7-5~图7-7所示。
图7-5 1998年样本回归的我国城镇居民消费模型图7-6 1999年样本回归的我国城镇居民消费模型图7-7 混合样本回归的我国城镇居民消费模型将不同样本估计的消费函数结果列在表7-3中,可以看出,使用混合回归明显地降低了系数的估计误差。
实验十 滞后变量【实验目的】掌握分布滞后模型的估计方法 【实验内容】建立库存函数 【实验步骤】【例1】 表1列出了某地区制造行业历年库存Y 与销售额X 的统计资料。
请利用分布滞后模型建立库存函数。
一、Almon 估计⒈分析滞后期长度在Eviews 命令窗口中键入:CROSS Y X ,输出结果见图1。
图1 互相关分析图图中第一栏是Y 与X 各滞后期相关系数的直方图。
可以看出,库存额与当年及前三年的销售额相关。
因此可以设:t t t t t x b x b x b x b a y ε+++++=---3322110假定i b 可以由一个二次多项式逼近。
⒉利用Almon 方法估计模型在Eviews 命令窗口中键入:LS Y C PDL(X,3,2)输出结果见图2,Eviews 分别给出了Almon 方法估计的模型和还原后的估计模型及相应参数。
图2 Almon 估计输出结果经过Almon 变化之后的估计结果为:(i z 即图2中的PDL 项):t t t t Z Z Z y2105445.01338.0261.1012.9152ˆ-++-= (6.6477) (0.7938) (-3.1145)9969.02=R 996.02=R 17.2=DW还原后的分布滞后模型为:32165.085.02609.15825.0012.9152ˆ----+++-=t t t t t x x x x y(3.4431) (6.6477) (4.922) (-2.7124) 二、滞后期长度的调整将PDL 项的参数依次设定为:PDL(X,3,2)、PDL(X,4,2)、PDL(X,5,2),其调整的判定系数、SC 、AIC 值如表2所示。
表2 Almon 估计法滞后期确定从表2中可以看出,当滞后期由3增加至4时,调整的判定系数增大而AIC 和SC 值均减小。
当滞后期由4增大到5时,调整的判定系数减小,AIC 值、SC 值增大。
所以,将滞后期确定为4时合理的。
二、Almon 估计的模拟⒈Almon 变换genr z0=x+x(-1)+x(-2)+x(-3) genr z1=x(-1)+2*x(-2)+3*x(-3) genr z2=x(-1)+4*x(-2)+9*x(-3)⒉估计变化后的模型LS Y C Z0 Z1 Z2图3回归结果见图3,即:2*5446.01*2231.10*5825.0012.9152ˆz z z yt -++-= (3.4431) (2.4112) (-3.1145)9969.02=R 996.02=R 17.2=DW ⒊计算原模型中的系数估计值根据Almon 变换原理有:00ˆˆa b = 2101ˆˆˆˆa a a b ++= 2102ˆ4ˆ2ˆˆa a a b ++= 2103ˆ9ˆ3ˆˆa a a b ++= 所以有: =0ˆb 0.5825 =1ˆb 0.5825+1.2231-0.5446=1.261 =2ˆb 0.5825+2*1.2231-4*0.5446=0.8503 5446.0*92231.1*35825.0ˆ3-+=b =-0.6496 所以还原成原分布滞后模型为:321*6496.0*8503.0*261.1*5825.0012.9152ˆ----+++-=t t t t t x x x x y实验九联立方程模型【实验目的】掌握联立方程模型的常用估计、检验方法【实验内容】宏观经济模型的估计与总体拟合优度检验【实验步骤】【例1】表1中为我国国民经济年度序列统计资料。
⒈在Eviews主窗口中点击Objects\New object,并在弹出的列表框中选中System项(如图1、图2所示)。
图1图2⒉在系统窗口中逐行输入待估计的模型系统,包括工具变量定义行。
C1=C(1)+C(2)*Y+C(3)*C1(-1)I=C(4)+C(5)*Y(_1)+C(6)*DYINST Y(-1) C1(-1) G X二、估计系统在系统窗口中点击Estimate 按钮,并从弹出的对话框中选取相应的估计方法:OLS 估计\2SLS 估计\3SLS 估计(估计结果见图3、4、5)。
即:普通最小二乘法估计:)1(1*5635.0*2322.05248.801-++=c y c(3.633) (3.6)9954.02=R 43.1=DWdy y I *699.0)1(*3932.05753.677+-+-=(21.702) (4.784)992.02=R 68.1=DW两阶段最小二乘法估计:)1(1*6404.0*2005.00078.541-++=c y c(2.8935) (3.7769)9953.02=R 54.1=DWdy y I *868.0)1(*3758.08203.673+-+-=(15.6012) (4.1319)991.02=R 97.1=DW三阶段最小二乘法估计:)1(1*5431.0*024.2579.921-++=c y c(4.222) (3.9104)995.02=R 4.1=DWdy y I *8131.0)1(*3816.01753.676+-+-=(18.9707) (4.724)991.02=R 9.1=DW图3图4图5三、总体拟合优度检验⒈在工作文件中打开所建立的系统⒉在系统窗口中点击Proce\Make Model(如图6),并在模型窗口中:⑴加入模型中的定义方程:Y=C1+I+G+X(如图7)图7⑵在ASSIGN语句中定义求解后的内生变量,为了便于比较,对所估计的不同系统可以标以不同的变量序号.⒊点击Solve按钮,得到内生变量的估计值。