第28章 fluent并行处理sa
FLUENT中文全教程1-250

FLUENT教程赵玉新I、目录第一章、开始第二章、操作界面第三章、文件的读写第四章、单位系统第五章、读入和操作网格第六章、边界条件第七章、物理特性第八章、基本物理模型第九章、湍流模型第十章、辐射模型第十一章、化学输运与反应流第十二章、污染形成模型第十三章、相变模拟第十四章、多相流模型第十五章、动坐标系下的流动第十六章、解算器的使用第十七章、网格适应第十八章、数据显示与报告界面的产生第十九章、图形与可视化第二十章、Alphanumeric Reporting第二十一章、流场函数定义第二十二章、并行处理第二十三章、自定义函数第二十四章、参考向导第二十五章、索引(Bibliography)第二十六章、命令索引II、如何使用该教程概述本教程主要介绍了FLUENT的使用,其中附带了相关的算例,从而能够使每一位使用者在学习的同时积累相关的经验。
本教程大致分以下四个部分:第一部分包括介绍信息、用户界面信息、文件输入输出、单位系统、网格、边界条件以及物理特性。
第二和第三部分包含物理模型,解以及网格适应的信息。
第四部分包括界面的生成、后处理、图形报告、并行处理、自定义函数以及FLUENT所使用的流场函数与变量的定义。
下面是各章的简略概括第一部分:z开始使用:本章描述了FLUENT的计算能力以及它与其它程序的接口。
介绍了如何对具体的应用选择适当的解形式,并且概述了问题解决的大致步骤。
在本章中,我们给出了一个可以在你自己计算机上运行的简单的算例。
z使用界面:本章描述了用户界面、文本界面以及在线帮助的使用方法。
同时也提供了远程处理与批处理的一些方法。
(请参考关于特定的文本界面命令的在线帮助)z读写文件:本章描述了FLUENT可以读写的文件以及硬拷贝文件。
z单位系统:本章描述了如何使用FLUENT所提供的标准与自定义单位系统。
z读和操纵网格:本章描述了各种各样的计算网格来源,并解释了如何获取关于网格的诊断信息,以及通过尺度化(scale)、分区(partition)等方法对网格的修改。
fluent并行计算配置(曙光文档)

1.并行处理•Fluent支持并行计算,且提供检查和修改并行配置工具。
你可用一个专用并行机(如多处理器工作站)或通过工作平台的网络运行Fluent。
下面介绍Fluent并行计算的特点。
• 1.1 并行计算简介•Fluent并行计算就是利用多个计算节点(处理器)同时进行计算。
并行计算可将网格分割成多个子域,子域的数量是计算节点的整数倍(如8个子域可对应于1、2、4、8个计算节点)。
每个子域(或子域的集合)就会“居住”在不同的计算节点上。
它有可能是并行机的计算节点,或是运行在多个CPU工作平台上的程序,或是运行在用网络连接的不同工作平台(UNIX平台或是Windows平台)上的程序。
计算信息传输率的增加将导致并行计算效率的降低,因此在作并行计算时选择求解问题很重要•推荐运行并行Fluent的操作步骤如下:•开启平行求解器,选择计算节点数。
•读入case文件,让Fluent自动将网格分割为几个子域。
最好是在建立问题之后分割,因为这种分割和计算的模型有关(象非等形接触面、滑移网格、shell-conduction encapsulation的自适应)。
如果你的case文件中包含滑移网格,或是在计算过程中要对非等形接触面进行修改,那就得用串行求解器进行分割。
•还有其他的方法进行分割,如在串行或并行求解器上进行手工分割。
•仔细检查分割区域,如必要再重新分割,。
•进行计算。
•--------------------------------------------------------------•ID Hostname O.S. PID Mach ID HW ID Name •--------------------------------------------------------------•node-2 fili irix 16729 2 11 Fluent Node •node-1 bofur irix 16182 1 10 Fluent Node •host balin sunos 5845 0 7 Fluent Host •node-0* balin sunos 5864 0 -1 Fluent Node •O.S.指体系结构,PID是进程ID数,Mach ID是计算节点ID,HW ID 是交换机的标识符。
FLUENT并行计算操作步骤!!!
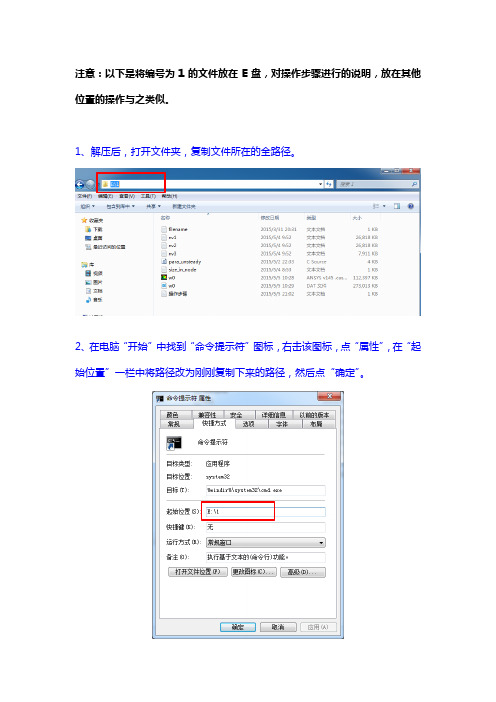
注意:以下是将编号为1的文件放在E盘,对操作步骤进行的说明,放在其他位置的操作与之类似。
1、解压后,打开文件夹,复制文件所在的全路径。
2、在电脑“开始”中找到“命令提示符”图标,右击该图标,点“属性”,在“起始位置”一栏中将路径改为刚刚复制下来的路径,然后点“确定”。
2、打开“命令提示符”窗口,可以看到显示的路径即为文件所在的路径,输入fluent 3d -t4(注意“fluent”、“3d”、“-t4”之间各有一个空格)后回车,即可打开fluent计算软件。
3、将case和data文件读入fluent,此过程中会出现error,点OK。
文件导入完成是下图这个样子。
4、设置自动保存路径:file>>write>>autosave,删掉file name下面的路径,点OK,路径即自动变成所需保存的路径。
5、编译:define>>user-defined>>functions>>compiled(如下图)>>add>>双击para_unsteady文件>>路径改为文件的全路径(例如:E:\1\libudf)>>build>>OK出现下图所示,即表示build成功,否则在路径后加上1(E:\1\libudf1),再次点击build,直至出现下图为止,点击load。
6、导入来流风速:define>>boundary conditions>>inlet>>velocity-inlet>>set>>点击velocity magnitude的第二个下拉框选择udf一项>>OK7、计算:solve>>iterate>>设置时间步长和计算的时间步数>>确认正确之后点击iterate进行计算。
fluent并行处理

5、编写hosts.txt文件,文件的格式在Fluentfluent 3d -t3 -pnet -cnf=hosts.txt -path\\computer1\fluent.inc
实际上本人认为第4条是很容易被忽略的,很多人在设置共享之后就不再管它,
那么到了最后就会发现Fluent无法为另外一台计算机分配任务。呵呵
系统配置:winnt,win2000操作系统,每台主机只有一个CPU,Fluent6.1,每台主机有自己的IP地址,安装好TCP/IP协议
1、 Fluent安装光盘上找到RSHD.exe这个文件。(注意,必须使用Fluent公司提供的这个远程控制软件)
2、用管理员的身份登陆计算机,拷贝该软件到系统盘的winnt目录下,在MS-DOS方式下执行 RSHD -install。
3、配置RSHD。WINNT系统下:控制面板-〉服务-〉RSH Daemon, 双击之,
在Logon里面输入用户名/密码。(一般情况下,为了您的计算机的安全,请不要使用具有管理员权限的用户名和口令。)您可以在开始-〉程序-〉管理工具
-〉用户管理器 里面设定,给guest权限就可以了。
Win2000系统下:控制面板-〉管理工具-〉服务-〉RSH Daemon,以下同于NT的操作。
完成上述操作后,请启动RSH服务。
4、资源管理器里面将Fluent的安装目录设置为共享。注意:这个时候要分别从其他的计算机登陆到本机这个被共享的目录。这个步骤一定不可缺少。
同样所有的计算机上的Fluent的安装目录都要被设置为共享,然后分别登陆.....
(完整版)《FLUENT中文手册(简化版)》

FLUENT中文手册(简化版)本手册介绍FLUENT的使用方法,并附带了相关的算例。
下面是本教程各部分各章节的简略概括。
第一部分:☐开始使用:描述了FLUENT的计算能力以及它与其它程序的接口。
介绍了如何对具体的应用选择适当的解形式,并且概述了问题解决的大致步骤。
在本章中给出了一个简单的算例。
☐使用界面:描述用户界面、文本界面以及在线帮助的使用方法,还有远程处理与批处理的一些方法。
☐读写文件:描述了FLUENT可以读写的文件以及硬拷贝文件。
☐单位系统:描述了如何使用FLUENT所提供的标准与自定义单位系统。
☐使用网格:描述了各种计算网格来源,并解释了如何获取关于网格的诊断信息,以及通过尺度化(scale)、分区(partition)等方法对网格的修改。
还描述了非一致(nonconformal)网格的使用.☐边界条件:描述了FLUENT所提供的各种类型边界条件和源项,如何使用它们,如何定义它们等☐物理特性:描述了如何定义流体的物理特性与方程。
FLUENT采用这些信息来处理你的输入信息。
第二部分:☐基本物理模型:描述了计算流动和传热所用的物理模型(包括自然对流、周期流、热传导、swirling、旋转流、可压流、无粘流以及时间相关流)及其使用方法,还有自定义标量的信息。
☐湍流模型:描述了FLUENT的湍流模型以及使用条件。
☐辐射模型:描述了FLUENT的热辐射模型以及使用条件。
☐化学组分输运和反应流:描述了化学组分输运和反应流的模型及其使用方法,并详细叙述了prePDF 的使用方法。
☐污染形成模型:描述了NOx和烟尘的形成的模型,以及这些模型的使用方法。
第三部分:☐相变模拟:描述了FLUENT的相变模型及其使用方法。
☐离散相变模型:描述了FLUENT的离散相变模型及其使用方法。
☐多相流模型:描述了FLUENT的多相流模型及其使用方法。
☐移动坐标系下的流动:描述单一旋转坐标系、多重移动坐标系、以及滑动网格的使用方法。
Fluent单机多核并行计算设置方法

Fluent单机多核并行计算设置方法字体: 小中大| 打印发表于: 2009-3-25 12:15 作者: sprophet 来源: 流体中文网现在计算机配置不断提高,双核、四核已经很常见,我将我的经验和大家共享,实现fluent 的单机双核并行计算,提高计算速度,希望对大家有所帮助。
1. 安装C:\Fluent.Inc\ntbin\ntx86\rshd.exe运行——cmd——cd C:\Fluent.Inc\ntbin\ntx86\——rshd –install2. 我的电脑——右键——管理——服务——RSHD demon——启动——属性——登录——此帐户——浏览:选择用户名和密码。
点击应用。
3. C:\Fluent.Inc\fluent\launcher\launcher.exe4. fluent launcher 1.1 对话框。
设置:Fluent.inc path: C:\fluent.incversion:3d or 2dnumber of process: 2,4,8….Architechture: ntx86MPI types: mpich2然后点击launch,运行并行计算。
我双核并行计算,计算速度大概提高60-80%左右。
[本帖最后由sprophet 于2009-3-25 04:28 编辑]我也来说两句查看全部回复最新回复•fanfan260 (2009-11-20 21:03:21)不好意思,想请问一下,为什么我在设置的时候找不到Architechture: ntx86和MPI types: mpich2另外,在第2部中的浏览:选择用户名和密码,想问一下啊这个用户名和密码是选择什么的用户名和密码?•xqcumt (2010-5-16 15:42:37)我安装在d盘了,rshd安装出了点问题,将它拷贝到c盘windous的systerm32文件夹下,运行cmd,输入rshd -install,装好了。
Fluent 并行计算(中文)
CFD环境下利用Fluent软件求解气体动力学问题时进行并行计算的可能性注切博塔廖夫数学和力学研究所,喀山国立大学,喀山,俄罗斯2008年8月25日收录摘要:本文主要得到了一种不可压缩气体流动场的研究结果,该流气体动场位于一种多孔结构的周期性元素中,这个多孔结构由一些半径相同的球体组成。
这些研究是基于使用Fluent软件对Navier–Stokes 方程进行的求解。
同时本文对使用并行计算可加快求解过程的可能性进行了论证,并且给出了在周期性元素中,压强差改变后的计算结果。
使并行计算得以实现的多处理器计算机最近开始应用于科学和工程领域的计算。
并行计算促进了一次相当大的进步,其应用领域之一就是流体力学三维问题的解决。
许多研究者使用通用的商业CFD软件,该软件提供了快速且方便的复杂领域三维问题的解决方法。
当前的CFD软件包旨在求解Navier–Stokes方程,这个方程描绘了空间任意区域的流动状况,该软件包拥有进行并行处理的可能性。
本文的目的是检测气体动力学三维问题的求解方法,该方法是在并行处理模式下依靠多处理器计算机使用Fluent软件进行计算得到的。
下面计算多孔结构中不可压缩气体的流动问题,该多孔结构由一些紧密排列的球体组成。
在筛选理论中,不同球体排列出的结构广泛应用于多孔介质模型。
使用多孔元素使得实现过滤进程和阶段分割变得可能,这些也应用在飞行器工程当中。
对多孔结构中的小雷诺系数区域内水动力流动的描述,按照规则,在斯托克斯近似下不考虑流体运动方程中的惯性因素。
同时在多孔介质镇南关流动速度可能较大,斯托克斯近似将不能描绘真实的流动模型。
在这个例子中,全Navier–Stokes方程的求解应该被应用。
在不同球体排列组成的结构中,考虑流体运动方程中惯性因素的流动已在一些地方进行理论和实验研究。
问题陈述在多孔结构的三维周期性元素中,我们分析一种不可压缩气体的流动,这种多孔结构由一些直径相等的球体紧密排列而成,他的中心在规则网格的节点上。
FLUENT并行设置
FLUENT并行设置的设置并行计算的启动界面如图所示。
通过选择processing options下的parallel(Local Machine)选项,可以激活并行计算。
注意到激活了并行计算后,Option中多出了一个use remote Linux node项,对于其它计算节点为Linux的情况,可以勾选此选项并进行相关设置。
1、Number of Processes此处设定使用的计算机数量。
只是针对本地计算机,设置的是要使用的计算机核心数量。
此处不能设置分布式计算。
若本机除了计算还需要进行其它的工作的话,建议CPU数量不要设满。
2、Parallel Settings标签页此标签页下设定的是并行计算的一些连接方式。
一般情况下使用默认方式即可。
3、Run typeFLUENT提供了两种并行工作方式:shared memory on local machine与distributed memory on a cluster。
Shared memory on local machine:通常用于单机计算。
单计算机共享内存计算。
Distributed memory on a cluster:分布式内存计算。
激活此选项后如下图所示。
可以有两种方式指定计算机:利用计算机名与导入包含计算机名的文本文件。
4、Remote标签页勾选use remote Linux node选项后,将多出一个Remote标签页。
如下图所示。
Remote FLUENT Root Path:设置远程FLUENT根路径。
Remote Working Directory:设置远程工作目录。
Remote Spawn Command:设置连接方式。
FLUENT提供了三种连接方式:RSH、SSH以及其它方式。
默认连接方式为RSH。
关于并行计算的详细设置,以后作专题讨论。
的启动界面如图1所示。
1、Dimension(模型维度)FLUENT中可以求解2D模型(在一些求解器中只能求解3D模型,如CFX),因此模型是2D还是3D需要在此处设定,一经设定,进入FLUENT之后,就没办法更改(即此处若设定2D,则导入的网格文件必须为2D模型,否则出错。
fluent计算技巧
fluent计算技巧Fluent计算技巧是指在使用Fluent软件进行流体力学仿真时,能够提高计算效率和准确性的一系列技巧和方法。
以下是一些常用的Fluent计算技巧:1. 网格优化:良好的网格质量是获得准确结果的关键。
在进行计算前,应对网格进行优化,包括网格划分、剖分、网格尺寸调整等操作,以确保网格质量良好。
2. 边界条件设置:正确设置边界条件对计算结果的准确性至关重要。
应根据具体情况选择合适的边界条件,如速度入口、压力出口、壁面摩擦等,并确保边界条件设置正确无误。
3. 松弛因子调整:在迭代计算过程中,调整松弛因子可以加快收敛速度。
通常情况下,可以逐步减小松弛因子,直到收敛为止。
4. 迭代收敛准则:设置合适的收敛准则可以控制计算的精度和收敛速度。
通常情况下,可以将残差的变化率设置为一个较小的值,以确保计算结果的准确性。
5. 并行计算:Fluent支持并行计算,可以利用多个处理器同时进行计算,提高计算效率。
在进行大规模计算时,可以选择使用并行计算来加快计算速度。
6. 结果后处理:合理的结果后处理可以更好地理解和分析计算结果。
Fluent提供了丰富的后处理功能,可以绘制流线、剖面、矢量图等,以及计算各种流体力学参数。
7. 参数优化:在进行计算前,可以通过参数优化来寻找最佳的计算条件。
可以通过改变模型参数、边界条件、松弛因子等来优化计算结果。
8. 多尺度模拟:对于复杂的流动问题,可以采用多尺度模拟的方法,将整个流场划分为多个区域进行计算。
这样可以提高计算效率,并且可以更好地捕捉流动的细节。
9. 网格独立性分析:在进行计算前,可以进行网格独立性分析,通过逐步细化网格来确定所需的最小网格尺寸。
这样可以确保计算结果对网格的依赖性较小。
总之,Fluent计算技巧是一系列在使用Fluent软件进行流体力学仿真时的实用技巧和方法,通过合理应用这些技巧,可以提高计算效率和准确性,得到更可靠的计算结果。
fluent并行
fluent version –t0 –pnet [-cnf= hostsfile](用 socket 传输装置)
fluent version –t1 –pnmpi[-cnf= hostsfile] (用网络 MPI 传输装置)
这样就可以开启远程机器上的计算节点的控制程序。如果设置了-cnf= hostsfile,则在
并行计算简介
Fluent 并行计算就是利用多个计算节点(处理器)同时进行计算。并行计算可将网格分割
成多个子域, 子域的数量是计算节点的整数倍(如 8 个子域可对应于 1、 4、 个计算节点)。 2、 8
每个子域(或子域的集合)就会 “居住” 在不同的计算节点上。 它有可能是并行机的计算节点,
!!当起用并行网络版是, 必须选择 Communicator 下拉菜单的 Socket, 除非 Vendor
MPI 支持集成。如果选用 Default 时,就会起用一个 MPI 并行版本,那就不能生成
附加计算节点。
3. 在 Processes 上设置初始并行计算节点数。 可先从 1 或 0 个节点开始, 后面再生成其
设备了。
如果你想利用命令开始并行计算,可键入如下命令:
fluent version -t n [-p comm ] [-load host ] [-path path ]
其中 version 可选择 2d、3d、2ddp 和 3ddp,n 指的是 CPU 数。其他的根据需要使用,
使用时根据方括号提示的信息写(写时不包括方括号)。 comm 指的是并行传输库的名称, host
中 File Run...,用 Select Solver(图 28.2.1)控制面板设定并行架构和求解器信息。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
28. 并行处理Fluent支持并行计算,且提供检查和修改并行配置工具。
你可用一个专用并行机(如多处理器工作站)或通过工作平台的网络运行Fluent。
下面介绍Fluent并行计算的特点。
28.1 并行计算简介Fluent并行计算就是利用多个计算节点(处理器)同时进行计算。
并行计算可将网格分割成多个子域,子域的数量是计算节点的整数倍(如8个子域可对应于1、2、4、8个计算节点)。
每个子域(或子域的集合)就会“居住”在不同的计算节点上。
它有可能是并行机的计算节点,或是运行在多个CPU工作平台上的程序,或是运行在用网络连接的不同工作平台(UNIX平台或是Windows平台)上的程序。
计算信息传输率的增加将导致并行计算效率的降低,因此在作并行计算时选择求解问题很重要。
推荐运行并行Fluent的操作步骤如下:1.开启平行求解器,选择计算节点数,详见28.2和28.3节。
2.读入case文件,让Fluent自动将网格分割为几个子域。
最好是在建立问题之后分割,因为这种分割和计算的模型有关(象非等形接触面、滑移网格、shell-conduction encapsulation的自适应)。
如果你的case文件中包含滑移网格,或是在计算过程中要对非等形接触面进行修改,那就得用串行求解器进行分割。
还有其他的方法进行分割,如在串行或并行求解器上进行手工分割。
3.仔细检查分割区域,如必要再重新分割,详见28.4.5节如何检查分割区域。
4.进行计算,详见28.5节如何检查和提高并行计算。
28.2 开启并行求解器开启Fluent并行求解器的方法依赖于操作平台是专用并行机还是工作站。
28.2.1 在UNIX系统下开启并行求解器可以在装有UNIX系统的专用并行机或工作平台网络上运行Fluent,如何运行如下:在多处理器UNIX机上运行Figure 28.2.1: Select Solver控制面板在专用并行机(多处理器工作平台或大型并行机)运行Fluent,键入运行命令,点击Fluent 中File Run...,用Select Solver(图28.2.1)控制面板设定并行架构和求解器信息。
1.在Version框里,点击3D和Double Precision来选择所求解问题是3D还是2D问题,所采用精度是单精度还是双精度,然后点击Parallel选项。
2.在Options框里,在Communicator下拉菜单中选择所要用的信息传输库。
推荐选用Default库,因为它可以为并行机提供最全面的并行操作。
这里还包含Vendor MPI和Shared Memory MPI (MPICH)。
Vendor MPI选用被机器硬件优化的信息传输库。
如果机器上的硬件支持并行工具包,当选用Default时,Fluent会自动检测它。
Shared Memory MPI (MPICH)选用MPICH信息传输库(MPI 公共域)。
3.在Processes上选择并行计算的CPU数。
4.点击Run按钮就可以进行并行计算了,一旦求解器开始运行,就不需要任何其他的设备了。
如果你想利用命令开始并行计算,可键入如下命令:fluent version -t n [-p comm ] [-load host ] [-path path ]其中version可选择2d、3d、2ddp和3ddp,n指的是CPU数。
其他的根据需要使用,使用时根据方括号提示的信息写(写时不包括方括号)。
comm指的是并行传输库的名称,host 指的是连接计算节点的主机(默认的是你使用的主机)名,path指的是Fluent.Inc安装的路径。
!!一般,只有你想不用默认的传输库时才需要设置-p comm。
专用并行机上的传输装置和与它相关的传输库列表如下:vmpi vendor MPIsmpi shared memory MPI (MPICH)net socket在UNIX工作平台上运行在UNIX工作平台网络上运行Fluent,键入运行命令,点击Fluent中File Run...,用Select Solver(图28.2.1)控制面板设定并行架构和求解器信息。
1.在Version框里,点击3D和Double Precision来选择所求解问题是3D还是2D问题,所采用精度是单精度还是双精度,然后点击Parallel选项。
2.在Options框里,在Communicator下拉菜单中选择Socket信息传输库。
!!当起用并行网络版是,必须选择Communicator下拉菜单的Socket,除非Vendor MPI支持集成。
如果选用Default时,就会起用一个MPI 并行版本,那就不能生成附加计算节点。
3.在Processes上设置初始并行计算节点数。
可先从1或0个节点开始,后面再生成其他节点,详见28.3.1节。
4.(可选择)在Hosts File键入包含机器列表的文件的名字。
如果Processes被设为0,Fluent会为文件中列出的每一台机器产生一个节点。
5.点击Run按钮就可以进行并行计算了。
如果你想利用命令开始网络并行计算,可键入如下命令:fluent version–t1 –pnet(用socket传输装置)fluent version–t1 –pnmpi(用网络MPI传输装置)这样就可以在工作平台上的某个计算节点上开启求解器了,然后用Network Configuration控制面板添加远程工作平台上的计算节点,详见28.3.1节。
如果键入如下命令:fluent version–t0 –pnet [-cnf= hostsfile](用socket传输装置)fluent version–t1 –pnmpi[-cnf= hostsfile] (用网络MPI传输装置)这样就可以开启远程机器上的计算节点的控制程序。
如果设置了-cnf= hostsfile,则在hostsfile文件中列出的每个机器都被设为一个计算节点,详见28.3.1节。
28.2.2在Windows系统下开启并行求解器可以在装有Windows系统的专用并行机或网络Windows平台上运行Fluent。
在多处理器Windows机上运行在Windows系统下,可通过MS-DOS窗口开启Fluent专用并行版本。
如在x处理器上开启并行版本,可键入fluent version–t x在提示命令下,将version替换为求解器版本(2d、3d、2dpp、3ddp),将x替换为处理器的数量(如fluent 3d –t3是在3台处理器上运行3D版本)。
如果Fluent命令不被识别,1.5.3节介绍了如何修改用户的环境变量。
在Windows工作平台上运行有两种方法在Windows工作平台网络上运行Fluent:一种是用RSHD传输装置软件,另外一种是采用硬件支持的信息传输接口(VMPI)。
参考Windows并行安装说明书来安装。
启动说明书是在假定机器已经装了必要的软件(遵照安装说明书安装)前提下的。
启动基于RSHD的Fluent并行版本如果你的机器是采用RSHD软件进行网络传输的,在命令提示符中键入:fluent version -pnet [-path sharename ] [-cnf= hostfile ] -t nprocs●version必须用你所运行的Fluent版本(2d、3d、2ddp、3ddp)代替。
●-path sharename是用通用命名标准设定Fluent.Inc路径的网络共享名。
只有你不是在安装Fluent的那台机器上计算才进行这项操作,如果是在同一台机器上进行计算就不必键入这项信息。
例如,Fluent是安装在computer1上,就将sharename用共享路径\\computer1\Fluent.Inc代替。
●-cnf= hostfile指定所有你要运行并行工作的计算机列表的文件。
如果这个文件不在系统默认的路径下,就要给出它的全路径。
用Notepad类文本编辑器生成hostfile,仅有的要求就是文件名中不能含有空格,如hosts.txt是对的,而my hosts.txt不行。
这个hostfile要包含如下内容:computer1computer2!!列表中的第一个计算机必须是你所使用的计算机。
如果网络上的计算机是多处理器,可将它在列表中多写几次。
例如,computer1有两个CPU,在hosts.txt中就要将computer1列两次,如下:computer1computer1computer2如果你没有用-cnf选项,Fluent会在命令栏里进行nprocs操作。
然后就可以用Fluent 里Network Configuration控制面板在工作站上引入交互式计算节点。
●-t nprocs设置所用节点数。
如果-cnf被选用,hostfile就会自行选择那几台计算机用于并行工作。
例如,hostfile里列有10台计算机,而你只想用其中的5个节点进行计算,就可以将nprocs设为5(即-t5),Fluent就会用hostfile中列出的前5台计算机工作。
可用Network Configuration控制面板杀掉进程或是引入其他节点,详见28.3节。
例子:对一个基于RSHD的3D问题,启用名字为hosts.txt的hostfile中前3台计算机进行并行计算的完整命令是:fluent 3d -pnet -cnf=hosts.txt -path\\computer1\fluent.inc -t3启动基于Vendor-MPI的Fluent并行版本如果你的机器是采用硬件支持的MPI软件进行网络传输的,在命令提示符中键入:fluent version–pvmpi [-path sharename ] [-cnf= hostfile ] -t nprocs各选项的含义与上节中相同,但要注意以下两点:●hostfile是必须的。
当使用MPI软件时不能用Network Configuration控制面板为工作站引入计算节点(注意:列表中的第一个计算机必须是你所使用的计算机)。
●当使用MPI软件时不能用Network Configuration控制面板杀掉进程或是引入新的计算节点。
例子:对一个基于Vendor-MPI的3D问题,启用名字为hosts.txt的hostfile中前3台计算机进行并行计算的完整命令是:fluent 3d –pvmpi -cnf=hosts.txt -path\\computer1\fluent.inc -t328.3使用并行网络工作平台可利用在网络上连接的工作平台引入(杀掉)计算节点来形成一个虚拟并行机。
即使一个工作平台仅有一个CPU,也允许有多个计算节点共同存在。