应用数理统计第二章参数估计(3)区间估计
区间估计 (3)ppt课件

当两样本为成对资料时,在置信度为P=1- α 时,两总体平均数差数µ 1-µ 2的置信区间可估 计为:
0+1.96x
临界值
u x
P ( 1 . 96 x 1 . 96 ) 0 . 95 x x
P ( x 1 . 96 ) P ( x 1 . 96 ) 0 . 05 x x
P ( 2 . 58 x 2 . 58 ) 0 . 99 x x
当为大样本时,不论总体方差σ2为已 知或未知,可以利用样本平均数 x 和总体 方差σ2作出置信度为P=1-α的中体平均数 的区间估计为:
( L x u , L x u ) 1 2 x x
其置信区间的下限L1和上限L2为
L u 1 x x
L u 2 x x
总体平均数的点估计L为:
L x tsx
tа为正态分布下置信度P=1- α时的t临界值
蛋白质含量的点估计为:
L x u 14 . 5 1 . 96 0 . 50 14 . 5 0 . 98 x
说明小麦蛋白质含量有95%的把握落在13.52%~ 15.48%的区间里。
P ( x 2 . 58 ) P ( x 2 . 58 ) 0 . 01 x x
P ( x 1 . 96 x 1 . 96 ) 0 . 95 x x
P ( x 2 . 58 x 2 . 58 ) 0 . 99 x x
总体平均数的点估计未知时,
σ2需由样本方差s2来估计,于是置信度为P
=1-α的总体平均数μ的置信区间可估计为
( x t s , x t s ) x x
统计学02-第三讲 两个总体参数的区间估计_24
2 p
(n1
1)s12
(n2
1)s
2 2
n1 n2 2
3. 估计量x1-x2的抽样标准差
s
2 p
s
2 p
n1 n2
sp
11 n1 n2
两个总体均值之差的估计
(小样本: 1222 )
1. 两个样本均值之差的标准化
t
( x1
x2 ) 1
s p n1
(1
1 n2
2 )
~
t (n1
n2
2)
2. 两个总体均值之差1-2在1- 置信水平下的
x1
32.5
s12
15.996 x2
27.875
s
2 2
23.014
自由度为
15.996
23.014
2
v 12
8
13.188 13
15.996 122 23.014 82
12 1
8 1
(32.5 27.875) 2.1604 15.996 23.014 4.625 4.433
女学生: x2 480
s
2 2
280
试以90%置信水平估计男女学生生活费支出方 差比的置信区间
两个总体方差比的区间估计 (例题分析)
解 : 根 据 自 由 度 n1=25-1=24 , n2=25-1=24 , 查 得 F/2(24)=1.98, F1-/2(24)=1/1.98=0.505
12 /22置信度为90%的置信区间为
两个总体均值之差1-2在1- 置信水平下的置
信区间为
x1 x2 t 2 (v)
s12
s
2 2
n1 n2
自由度 v
第二章参数估计

第二章 参数估计【学习目标】1、掌握矩估计的替代原则;会求已知分布中未知参数的矩估计(值)2、熟练掌握极大似然估计的思想及求法3、估计量的评价标准:无偏性、有效性、相合性的定义4、统计量的无偏性的判断;两个无偏估计的有效性判断;会用Fisher 信息量及c-R 下界进行统计量的UMVUE 充分性判断5、掌握区间估计的定义6、单个正态总体均值的区间估计(包括方差已知、方差未知);单个正态总体方差的区间估计(包括均值已知、均值未知)7、两个正态总体均值差的区间估计(方差未知);两个正态总体方差比的区间估计 8、单侧置信区间的求法 【典型例题讲解】例1、设1,,n X X 是来自均匀分布(,1)U θθ+的总体的容量为n 的样本,其中θ-∞<<+∞为未知参数,试证:θ的极大似然估计量不止一个,例如1(1)ˆXθ=,2()ˆ1n X θ=-,3(1)()11ˆ()22n XXθ=+-都是θ的极大似然估计。
解:(,1)U θθ+分布的密度函数为11()0x f x θθ≤≤+⎧=⎨⎩其他似然函数(1)()11()0n x x L θθθ≤≤≤+⎧=⎨⎩其他由于在(1)()1n x x θθ≤≤≤+上()L θ为常数,所以凡是满足:(1)()ˆˆ1n x x θθ≤≤≤+的ˆθ均为θ的极大似然估计。
从而(1)1(1)ˆX θ=满足此条件,故1(1)ˆX θ=是θ的极大似然估计;(2)由于()(1)1n X X -≤,故2()(1)()2ˆˆ11n n X X X θθ=-≤≤=+,所以2()ˆ1n Xθ=-为θ的极大似然估计;(3)由于()(1)1n X X -≤,故(1)()(1)12n X X X +-≤,(1)()()12n n X X X ++≥,从而有3(1)()(1)()(1)()31111ˆˆ()()12222n n n XXXXXXθθ=+-≤≤≤++=+,故3ˆθ也为θ的极大似然估计。
应用统计方法第二章参数估计

2
1 1
2 x 1 1
2 2
2 dx
1 12
(
2
1 ) 2
令
X
S 2
1 2
(1
2
)
1 12
( 2
1)
解上述关于
1
,
2
的方程得
1 2
X X
3S 3S
8
.
Example 2.4 贝努利试验中,事件 A 发生的频率是该事件 发生概率的矩法估计。 Solution 此处,实际上我们视总体 X 为“唱票随机变量”, 即 X 服从两点分布:
此,必须采用求极值的办法,即对对数似然函数关于 i 求导, 再令之为 0,即得
ln L( ) i
(Xi
X )2
S2
记为ˆ 2 S 2 .第三步等号再一次用到习题 1.4.
7
.
Example 2.3 设 X 为[1, 2 ]上的均匀分布, X1, X 2 ,, X n
为样本,求1, 2 的矩估计。
Solution
a 1
2 xdx
1 2 1
2 2
12
2( 2 1 )
1 2
(
1
2)
2
.
Chapter 2 参数估计
(Parameter Estimation)
1
.
§2.1 点估计(Point Estimation) §2.2 估计量的评价准则 §2.3 区间估计(Interval Estimation)
2
.
§2.1 点估计(Point Estimation)
一、 矩估计法
若总体 X 的期望存在,E(X ) , X1, X 2 ,, X n 是出 自X 的样本,则由柯尔莫哥洛夫强大数定律,以
00907701《应用数理统计》教学大纲

《应用数理统计》教学大纲课程名称:应用数理统计英文名称:Application of Mathematical Statistics课程编号:00907701课程学时:32课程学分:2课程性质:学位课适用专业:全校各专业预修课程:高等数学,线性代数(大学工科), 概率论与数理统计(大学工科)大纲执笔人:周大勇一、课程目的与要求本课程讨论基础数理统计的数学理论和方法,包括数理统计的基本概念,抽样分布,参数估计,假设检验,方差分析,回归分析,正交试验和质量控制初步,为众多学科专业需要较多统计工具的研究生,提供随机数学方面的训练,打下扎实的基础。
数理统计是关于数据资料的收集﹑整理﹑分析和推断的学科,通过对本课程的学习,使学生在本科工程数学的基础上,进一步较收入地掌握数理统计的基本理论和方法,培养运用数理统计的方法分析和解决有关实际问题的能力,并为今后学习后继课程打下必要的基础。
二、教学内容及学时安排第一章抽样和抽样分布 4 学时一、母体和子样二、一些常用的抽样分布第二章参数估计 8学时一、点估计和估计量的求法二、估计量的好坏标准三、区间估计第三章假设检验 8学时一、假设检验初述,二类错误二、检验母体平均数三、检验母体方差四、单侧假设检验五、分布假设检验第四章方差分析、正交试验设计 6学时一、一元方差分析二、二元方差分析三、正交试验设计第五章回归分析 6学时一、一元线性回归中的参数估计二、一元线性回归中的假设检验和预测三、可线性化的意愿非线性回归三、教材及主要参考书1、杨虎,刘琼荪,钟波《数理统计》高等教育出版社,20042、汪荣鑫《数理统计》西安交通大学出版社,19863、吴翊,李永乐,胡庆军《应用数理统计》国防科大出版社,19954、朱勇华,邰淑彩,孙韫玉《应用数理统计》武汉大学出版社,20005、茆诗松、王静龙《数理统计》华东师范大学出版社,1990。
应用数理统计第二章

□
例2.1.11 总体 X ~ U (θ,θ +1) , θ 是未知参数, X1,…,Xn 是一组样本,求θ 的极大似然估计。 解. 总体的密度函数为: f(x,θ ) = 1, θ < x1,…,xn < θ +1 显然不能对参数 θ 求导,无法建立似然方程 注意到这个似然函数不是 0 就是 1 ,利用 顺序统计量,把似然函数改写成如下形式:
f(x,θ ) = 1, θ < x(1) <… < x(n) < θ +1 因此只要 θ < x(1) 并且 x(n) < θ +1 同时满足, 似然函数就可以达到极大值 1 。 所以 U (θ,θ +1) 中参数θ 的极大似然估计 可以是区间 ( x(n) - 1 ,x(1) ) 里的任意一个点 。 说明 MLE 可以不唯一,甚至有无穷多个 同理,总体 U (a,b) 左右端点 a 、b 的MLE 分别就是两个极值统计量 x(1) 、x(n) 。
k =1
n
注意这里总体参数 θ 是一个向量 (µ,σ2 ) , 因此对于似然函数取对数后分别对 µ,σ2 求导, 建立对数似然方程组:
1
σ
−
2
(x − µ) = 0 n + 1 2(σ 2 )2 ( xk − µ )2 = 0 ∑
k =1 n
2σ 2
解方程组得到正态总体两个参数的MLE
ˆ µ=X
1 n n−1 2 ˆ σ 2 = ∑ ( X k − X )2 = S n k =1 n
⎛ N ⎞ ∑ xk nN − ∑ xk L ( x ,θ ) = [ ∏ ⎜ ⎟ ] p (1 − p ) ⎝ xk ⎠
这里每一个 xk = 0、1、…、N 中的某个值
研究生应用数理统计参数估计(讲稿)
, X n )] ,则称$是的渐进
无偏估计量。
注:1 n n i1
Xi X
2不是D(X)的无偏估计量,但是
渐进无偏估计量。
例2.2.1 对任一总体,若E( X )=,D( X )= 2均存在
,且X1, X 2 ,L , X 2为X的样本,试证
(1)1 n
则称$1比$2有效。
注:方差越小越好。那么是否有下界?
例2.2.1 设对总体X : N (, 2 ),X1, X 2,L , X n
是来自总体X的样本,试证
(1)S12
1 n
n i 1
Xi
2 是 2的无偏估计量;
(2)S12是较S 2
1 n 1
n i 1
nI ( )
称为g( )的无偏估计的T的R C方差下界。
注1 对离散总体,将密度函数改为分布律即可;
注2 一般分布都满足正则条件;
注3 利用R-C不等式有时可以判断出一个无偏
估计是否是UMVUE,因为在满足定理条件下,如果
D(T ) g( )2 ,则T是g( )的UMVUE.但UMVUE的
n
试求p的极大似然估计量。
例2.1.5 设总体X的概率分布如下表,
X
012Fra bibliotek3P
2
2(1-) 2
1-2
0
1 2
是未知参数,利用总体X的如下观测值,
3,1,3,0,3,1,2,3
求的极大似然估计值。
例2.1.6 设总体X的分布函数为
F(x;
,
)=
1
第二章 参数估计2-3 区间估计
I=0.814
上页 下页 返回
钢厂铁水含碳量X 例3. 钢厂铁水含碳量 ~ N(µ,0.1082), 现在随机测定 该厂9炉铁水得 炉铁水得X=4.484,求在置信度为 求在置信度为0.95 的条件 该厂 炉铁水得 求在置信度为 下铁水平均含碳量的置信区间。 下铁水平均含碳量的置信区间。 解
置信区间为
上页
下页
返回
联合方差
上页
下页
返回
1、 µ1 - µ2的1-α置信区间 、 α (1)、 σ12 、σ22已知 、
由于 X −Y ~ N(µ1 − µ2 ,
选取
2 2 σ1 σ2
n1
+
n2
)
因此置信度为1-α 因此置信度为 α的µ1 - µ2置信区间可为
上页
下页
返回
(2)、σ12 、σ22未知,且n1,n2较大 如大于 、 未知, 较大(如大于 如大于50)
=27.5, ,
=6.26, ,
上页
下页
返回
测量一批铅锭的比重,设铅锭的比重X 例6. 测量一批铅锭的比重,设铅锭的比重 ~ N(µ, 现进行16次检测得铅锭的比重有 σ2),现进行 次检测得铅锭的比重有 现进行 次检测得铅锭的比重有X=2.705, , S2=0.0292,试求总体 的均值µ和方差 σ2置信度为 求总体X的均值 0.95 的置信区间。 的置信区间。 解 (1)求µ的置信区间 σ2未知 n=16,α=0.05. 求 的置信区间, 未知, α 选取 查表得 置信区间为
(二)、总体X数学期望 (二)、总体X数学期望µ未知 数学期望µ 样本X 的无偏估计. 样本 1,X2, • • • , Xn, 且S2是σ2的无偏估计
选取样本函数
二章节参数估计-精选
n1
E[C (Xi1Xi)2]
i1 n 1
C{D (X i 1X i) [E (X i 1X i)]2}
i 1
n1
C 2D(X) C 2 (n 1 )D (X )
i 1
n1
依题意,要求: E[C (Xi1Xi)2]D(X)
i1
D ( X i 1 即 X i C ) 2 D ( n ( X i 1 ) 1 D ) ( X D ) ( X D i ) ( X 2 ) D ( X )
点估计问题就一 是个 要适 构当 造的统计
ˆ(X1,X2,,Xn),用它的观ˆ(察 x1,x值 2,,xn) 来估计未知 . 参数
ˆ(X 1,X 2,,X n)称的 为估 .通计 称估量 计, ˆ(x1,x2,,xn)称为 的估 . 计 简记值 为ˆ.
例2 在某纺织厂细纱断机头上次的 X数 是一个
无偏估计的实际意义: 无系统误差.
若 l i m E ) , 则 称 ) 是 的 渐 近 无 偏 估 计 . n
例3 设总体X的X1, X2,L , Xn是X的一个样本,试证明不论
总体服从什么分布, k阶样本矩Ak
1 n ni1
Xik
是
k阶总体矩k的无偏估计.
E D ( (X X i )1 0X i ) E C( X 2i (1 n1) 1E ).( (X ii ) 1 ,2 0 , ,n )
注 一般地,一个参数 的无偏估计量不唯一.
如:设样本(X1, X2 , ···, Xn ) 来自总体X,E(X)=,
则X是 的无偏 . 此 估外 计,
随机变,假 量设它服从以 0为参数的泊松 , 分 参数 为未,知 现检查1了 5只 0 纱锭在某一时间 内断头的,次 数数 据如,试 下估计参 .数
应用数理统计(武汉理工大)2-参数估计
1
D(S 2 )nI (
2)
n 1 n
1,
n
故S 2是渐进有效的。
第二章 参数估计
例: 设总体X (), X1, X 2 , , X n是X的一个样本, 讨论的无偏估计X的有效性。
解:lnp( X
,)
ln
X e
X!
X
ln
ln( X
!)
区间估计的关键: 用合适的方法确定两个统计量
1(X1, X2 , , Xn), 2(X1, X2 , , Xn)
第二章 参数估计
1.区间估计的定义及计算步骤
3) 区间估计的例子
例1 设总体X~N(μ , σ2), σ2已知,μ未知,设X1,…,Xn是X的样本, 求μ的置信度为1-α的置信区间。
)
2
n
,
D(ˆ2 )
D(nZ )
n2D(Z )
n2
n
2
2
当n 1时,显然D(ˆ1) D(ˆ2 ),故ˆ1比ˆ2有效。
第二章 参数估计
最小方差无偏估计问题 设 若 及T对 任(g意X(1, , X)的2都,任有一 , XD无n()T是 偏) g估(D计()T的量')一, T '个 ( X无1, X偏2估 , 计, X量n ), 则 无称 偏T估(计X1,, X或2 ,者,称X为n )是最g优(无)的偏一估致计最。小方差
其它类型的估计,如 贝叶斯估计…
第二章 参数估计
2.1参数的点估计
1. 矩估计 2. 极大似然估计 3. 点估计量的评价
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
得所求的标准差的置信区间为 (4.58, 9.60)
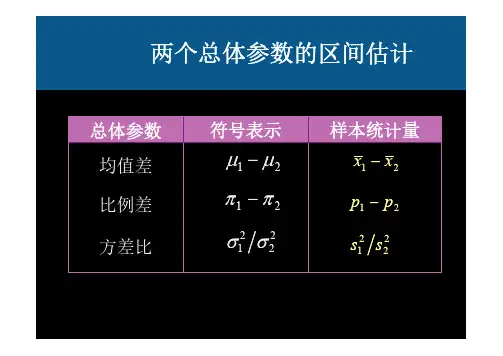
2.4.3 两个正态总体参数的区间估计
在实际中常遇到下面的问题:已知产品的某一质量指标 服从正态分布,但于原料、设备条件、操作人员不同,或 工艺过程的改变等因素,引起总体均值、总体方差有所改变, 我们需要知道这些变化有多大,这就需要考虑两个正态总体 均值差或方差比的估计问题。
1
2.4.1 区间估计的一般步骤
定义1 设总体X的分布函数F(x;)含有一个未知参数,, 对于给定值 (0<<1),若由样本X1, X2, …,Xn确定的两个统 计量 ( X 1 , X 2 ,, X n ) 和 ( X 1 , X 2 ,, X n满足 )
ˆ a ˆ b} {g(a) T ( X , X ,..., X ; ) g(b)} { 1 2 n
其中g ( x )为可逆的已知函数, T ( X 1 , X 2 ,..., X n ; } 的分布已知且与θ无关。
4
2.4.2 单个正态总体的情况
设总体X~N(,2),X1, X2, …,Xn是总体X的样本,求,2 /2 /2 的置信水平为(1)的置信区间.
求得 的置信度水平为(1)的置信区间: (2为已知)
X u u1 / 2 , X u1 / 2 或 1 2 X n n n
5
(b) 2为未知时,因为S 2是 2的点估计量,所以用S替换 ,
X
S n1
~ t ( n 1)
由此可得 1 2 的一个置信水平为 1 的置信区间为:
2 12 2 X Y z1 2 n n 1 2
12
2 2 2 2,但 2为未知. (b) 1
由定理1.15, 12 22 2 时,
M ( 1 2 ) ( X Y ) n1 S1 n2 S2
13
[例2.28] 在例2.27中,随机选取A种灯泡5只,B种灯泡7只, 做灯泡寿命实验,算得两种牌号的平均寿命分别 为1000和980小时,样本方差分别为784和1024小 时2.取置信度0.99,希望进行区间估计.
考察:
(ⅰ)两种灯泡的寿命是否有明显差异;
(ⅱ)两种灯泡的质量稳定性是否有明显差异.
(4.71,5.69)的可信程度为95%. 3)置信水平为(1)的置信区间不唯一.如上例=0.05,可证 X X ÷ P z0.96 z0.99 0.95 z , X z 0 . 0 . 96 99 ÷ / n n n 置信区间长度越短表示估计的精度越高. 7
例1 有一大批月饼,现从中随机地取16袋,称得重量(以克 计)如下:506 508 499 503 504 510 497 512 514 505 493 496 506 502 509 496 ,设袋装月饼的重量近似地服从正态 分布,试求总体均值的置信度为0.95的置信区间。 解: 2未知, 1-=0.95, /2=0.025,n-1=15, t0.975 (15) 2.1315 由已知的数据算得 x 503.75, S* 6.2022
, n 1 15 解:现在 2 0.025,1 2 0.975
2 2 (15) 27.488, 查表得 0.975 0.025 (15) 6.262
又 S* =6.2022 ,
由(4)式
n 1 S * n 1 S * , 2 ( n 1) 2 ( n 1) 1 2 2
§2 ·4
区间估计
为了估计总体X 的未知参数 ,前面已经介绍了矩估计
ˆ 法和极大似然估计法.由于总体X的未知参数 的估计量
是随机变量,无论这个估计量的性质多么好,它只能是未知 参数的近似值,而不是 的真值.并且样本不同,所得到的 估计值也不同.那么 的真值在什么范围内呢?是否能通 过样本,寻求一个区间,并且给出此区间包含参数 真值的 可信程度.这就是总体未知参数的区间估计问题.
n1 (n2 1) S12 12 n1 (n2 1) S12 P F (n 1, n1 1) 2 F (n 1, n1 1) 1 2 /2 2 2 1 / 2 2 2 n2 (n1 1) S2 n2 (n1 1) S2
P{1 2 } 1
则称随机区间 ( 1 , 2 ) 是 的置信度为 (1 ) 的置信区间,
1 和 2 分别称为置信度为 (1 ) 的双侧置信区间的置信下
限与置信上限, (1 ) 称为置信水平(置信度). 这种估计 的方法叫做区间估计. 1)精度: 1 评价一置信区间 好坏的两个标准:
nS 2 nS 2 2 P 2 2 1 2 ( n 1) 1 2 ( n 1)
2 nS 2 2 P 2 (n 1) 2 1 2 (n 1) 1
nS 2 nS 2 , 2 ( n 1) 2 ( n 1) 2 1 2
2 越小越好; P{ 1 2 } 越大越好2 2)置信度: .
[注]
1)当X是连续型随机变量时,对于给定的,我 们总是按要求:
P{ 1 2 } 1
求出置信区间. 2)当X是离散型随机变量时,对于给定的 , 常常找不到区间 ( 1 , 2 ) 使得 P{ 1 2 } 恰好 为 (1 ).此时我们去找 ( 1 , 2 ) 使得 P{ 1 2 } 尽可能地接近 (1 ) .
⑴ 均值 的置信区间
u1 / 2
u1 /2
(a) 2为已知时,因为 X是,的无偏估计,且 X ~ N (0,1) / n 对于给定的(0<<1),令
X P u 1 P X u1 / 2 X u1 / 2 1 1 n n / n 2
n 1 S n 1 S , 2 ( n 1) 2 ( n 1) 1 2 2
标准差 的一个置信度为1- 的置信区间9
例2 有一大批糖果,现从中随机地取16袋,称得重量(以克计) 如下:506 508 499 503 504 510 497 512 514 505 493 496 506 502 509 496 ,设袋装糖果的重量近似地服从正态分布, 试求总体标准差 的置信度为0.95的置信区间。
又若 =1,n=16, 查表得 z 0.975 1.96
X 1 1.96 , X 1 1.96 16 16
于是得到 的置信水平为0.95 的置信区间:
即
X 0.49
2)若样本值为 x 5.20 ,则得到一个置信区间 (5.20 0.49) 即(4.71,5.69)这时已不是随机区间,说明 的真值含在
求得 的置信水平为(1)的置信区间: ( 2未知)
S S* t1 2 (n 1) or X t1 2 (n 1) X n1 n
6
1) 例如当=0.05 时,即1-=0.95, X z0.975 , X z0.975 n n
2 2 Y1,Y2,…,Yn2是Y的样本.这两个样本相互独立, X , Y , S1 , S2
分别为第一、二个总体的样本均值与方差.
1.两个总体均值差 1 2 的置信区间 (a)
12
2 和 2 已知,求 1 2 的置信区间
X Y ( 1 2 ) 2 2 2 2 ~ N ( 0 , 1 ) 相互独立 1 2 X , Y 1 2 X Y ~ N ( , ) 2 2 2 ~n1N ( n2 , X ~ N ( ), Y 1 1 , 21 2 n2 ) n 1 n1 n2
(2)方差 2 的置信区间 (只介绍 未知的情况) /2 2的无偏估计量为S*2 , 当1- 给定后,因为
( n 1) S *
2
/2
2
~ ( n 1)
2
2 / 2 (n 1)
21 / 2 (n 1)
即
得到方差 2 的一个置信度为1- 的置信区间:
由公式(2)得均值的置信度为0.95的置信区间为
6.2022 2.1315 503.75 即(500.4, 507.1) 16 这就是说估计袋装月饼重量的均值在500.4与507.1之间,
这个估计的可信程度为95%。若以此区间内任一值作为 的 6.2022 2.1315 2 6.61 (克),这个 近似值,其误差不大于 16 误差估计的可信程度为95%。 8
2 2 / 于是得 1 2 的一个置信度为 1 的置信区间为 2 2 S*1 S*1 2 F / 2 ( n2 1, n1 1), 2 F1 / 2 ( n2 1, n1 1) S*2 S*2
3
区间估计的一般步骤:
• 1.给出“好”的点估计(按前面的标准),并 知道它的分布(只依赖待估的未知参数);
ˆ a, ˆ b] 2.求一个区间(参数的一个邻域) [ ˆc, ˆd ],使得对于给定的置信水平, 或 [
•
ˆ a ˆ b} 1 P{
且一般要求区间长尽可能小。 将不等式变形得到等价的形式
14
(2) 两个总体方差比 1 / 2 的置信区间 仅讨论总体均值1 ,2 为未知的情况。
2 2
由于
n1 (n2 1) S / ~ F (n1 1, n2 1) n2 (n1 1) S /
2 1 2 2 2 1 2 2
n1 (n2 1) S12 / 12 P F / 2 (n1 1, n2 1) F1 / 2 (n1 1, n2 1) 1 2 2 n2 (n1 1) S2 / 2