PL0编译程序
编译原理(PL0编译程序源代码)

编译原理(PL0编译程序源代码)/*PL/0编译程序(C语言版)*编译和运行环境:*Visual C++6.0*WinXP/7*使用方法:*运行后输入PL/0源程序文件名*回答是否将虚拟机代码写入文件*回答是否将符号表写入文件*执行成功会产生四个文件(词法分析结果.txt符号表.txt虚拟代码.txt源程序和地址.txt)*/#include#include"pl0.h"#include"string"#define stacksize 500//解释执行时使用的栈int main(){bool nxtlev[symnum];printf("请输入源程序文件名:");scanf("%s",fname);fin=fopen(fname,"r");//以只读方式打开pl0源程序文件cifa=fopen("词法分析结果.txt","w");fa1=fopen("源程序和地址.txt","w");//输出源文件及各行对应的首地址fprintf(fa1,"输入pl0源程序文件名:");fprintf(fa1,"%s\n",fname);if(fin){printf("是否将虚拟机代码写入文件?(Y/N)");//是否输出虚拟机代码scanf("%s",fname);listswitch=(fname[0]=='y'||fname[0]=='Y');printf("是否将符号表写入文件?(Y/N)");//是否输出符号表scanf("%s",fname);tableswitch=(fname[0]=='y'||fname[0]=='Y');init();//初始化err=0;cc=cx=ll=0;ch=' ';if(-1!=getsym()){fa=fopen("虚拟代码.txt","w");fas=fopen("符号表.txt","w");addset(nxtlev,declbegsys,statbegsys,symnum);nxtlev[period]=true;if(-1==block(0,0,nxtlev)){//调用编译程序fclose(fa);fclose(fa1);fclose(fas);fclose(fin);return 0;}if(sym!=period){error(9);//结尾丢失了句号}if(err!=0){printf("pl0源程序出现错误,退出编译请从第一个错误处开始修改.\n\n");fprintf(cifa,"源程序出现错误,请检查");fprintf(fa1,"源程序出现错误,请检查");fprintf(fa,"源程序出现错误,请检查");fprintf(fas,"源程序出现错误,请检查");}fclose(fa);fclose(fa1);fclose(fas);}fclose(fin);}else{printf("Can't open file!\n");}fclose(cifa);//printf("\n");return 0;}void init(){//初始化int i;for(i=0;i<=255;i++)ssym[i]=nul;//设置单字符符号ssym['+']=plus;ssym['-']=minus;ssym['*']=times;ssym['/']=slash;ssym['(']=lparen;ssym[')']=rparen;ssym['=']=eql;ssym[',']=comma;ssym['.']=period;ssym['#']=neq;ssym[';']=semicolon;strcpy(&(word[0][0]),"begin");//保留字设置,以字母顺序排列便于折半查找strcpy(&(word[1][0]),"call");strcpy(&(word[2][0]),"const");strcpy(&(word[3][0]),"do");strcpy(&(word[4][0]),"end");strcpy(&(word[5][0]),"if");strcpy(&(word[6][0]),"odd");strcpy(&(word[7][0]),"procedure");strcpy(&(word[8][0]),"read");strcpy(&(word[9][0]),"then");strcpy(&(word[10][0]),"var");strcpy(&(word[11][0]),"while");strcpy(&(word[12][0]),"write");wsym[0]=beginsym;//设置保留字类别一字即一类wsym[1]=callsym;wsym[2]=constsym;wsym[3]=dosym;wsym[4]=endsym;wsym[5]=ifsym;wsym[6]=oddsym;wsym[7]=procsym;wsym[8]=readsym;wsym[9]=thensym;wsym[10]=varsym;wsym[11]=whilesym;wsym[12]=writesym;strcpy(&(mnemonic[lit][0]),"lit");//设置指令名称strcpy(&(mnemonic[opr][0]),"opr");strcpy(&(mnemonic[lod][0]),"lod");strcpy(&(mnemonic[sto][0]),"sto");strcpy(&(mnemonic[cal][0]),"cal");strcpy(&(mnemonic[inte][0]),"int");strcpy(&(mnemonic[jmp][0]),"jmp");strcpy(&(mnemonic[jpc][0]),"jpc");for(i=0;i<="">declbegsys[i]=false;statbegsys[i]=false;facbegsys[i]=false;}declbegsys[constsym]=true;//设置声明开始符号集declbegsys[varsym]=true;declbegsys[procsym]=true;statbegsys[beginsym]=true;//设置语句开始符号集statbegsys[callsym]=true;statbegsys[ifsym]=true;statbegsys[whilesym]=true;facbegsys[ident]=true;//设置因子开始符号集facbegsys[number]=true;facbegsys[lparen]=true;}//用数组实现集合的集合运算int inset(int e,bool* s){return s[e];}int addset(bool*sr,bool* s1,bool* s2,int n){int i;for(i=0;i<n;i++)< p="">sr[i]=s1[i]||s2[i];return 0;}void error(int n){//出错处理,打印出错位置和错误编码char space[81];memset(space, 32,81);space[cc-1]=0;printf("error(%d)",n);fprintf(fa1,"error(%d)",n);switch(n){case 1:printf("\t\t常量说明中的“=”写成“:=”\n"); fprintf(fa1,"\t\t常量说明中的“=”写成“:=”\n"); break;case 2:printf("\t\t常量说明中的=后应该是数字\n"); fprintf(fa1,"\t\t常量说明中的=后应该是数字\n"); break;case 3:printf("\t\t常量说明符中的表示符应该是=\n" ); fprintf(fa1,"\t\t常量说明符中的表示符应该是=\n"); break;case 4:printf("\t\tconst,var,procedure后应为标识符\n" ); fprintf(fa1,"\t\tconst,var,procedure后应为标识符\n");break;case 5:printf("\t\t漏掉了“,”或“;”\n" );fprintf(fa1,"\t\t漏掉了“,”或“;”\n" );break;case 6:printf("\t\t过程说明后的符号不正确\n" );fprintf(fa1,"\t\t过程说明后的符号不正确\n"); break;case 7:printf("\t\t应是语句开始符\n" );fprintf(fa1,"\t\t应是语句开始符\n" );case 8:printf("\t\t程序体语句部分的后跟符不正确\n" );fprintf(fa1,"\t\t程序体语句部分的后跟符不正确\n" );break;case 9:printf("\t\t程序结尾丢了句号“.”\n\n" );fprintf(fa1,"\t\t程序结尾丢了句号“.”\n");break;case 10:printf("\t\t语句之间漏了“;”\n" );fprintf(fa1,"\t\t语句之间漏了“;”\n");break;case 11:printf("\t\t标识符拼写错误或未说明\n" );fprintf(fa1,"\t\t标识符拼写错误或未说明\n");break;case 12:printf("\t\t赋值语句中,赋值号左部标识符属性应是变量\n" );fprintf(fa1,"\t\t赋值语句中,赋值号左部标识符属性应是变量\n");break;case 13:printf("\t\t赋值语句左部标识符后应是复制号“:=”\n" );fprintf(fa1,"\t\t赋值语句左部标识符后应是复制号“:=”\n");break;case 14:printf("\t\tcall后应为标识符\n" );fprintf(fa1,"\t\tcall后应为标识符\n");break;printf("\t\tcall后标识符属性应为过程\n" );fprintf(fa1,"\t\tcall后标识符属性应为过程\n"); break;case 16:printf("\t\t条件语句中丢了then\n" );fprintf(fa1,"\t\t条件语句中丢了then\n"); break;case 17:printf("\t\t丢了“end”或“;”\n" );fprintf(fa1,"\t\t丢了“end”或“;”\n"); break;case 18:printf("\t\twhile型循环语句中丢了“do”\n" ); fprintf(fa1,"\t\twhile型循环语句中丢了“do”\n"); break;case 19:printf("\t\t语句后的符号不正确\n" );fprintf(fa1,"\t\t语句后的符号不正确\n" ); break;case 20:printf("\t\t应为关系运算符\n" );fprintf(fa1,"\t\t应为关系运算符\n");break;case 21:printf("\t\t表达式标示符属性不能是过程\n" ); fprintf(fa1,"\t\t表达式标示符属性不能是过程\n"); break;case 22:printf("\t\t表达式漏掉了右括号\n" );fprintf(fa1,"\t\t表达式漏掉了右括号\n");break;case 23:printf("\t\t因子后的非法符号\n" );fprintf(fa1,"\t\t因子后的非法符号\n");break;case 24:printf("\t\t表达式的开始符不能是此符号\n" );fprintf(fa1,"\t\t表达式的开始符不能是此符号\n"); break;case 25:printf("\t\t标识符越界\n" );fprintf(fa1,"\t\t标识符越界\n");break;case 26:printf("\t\t非法字符\n" );fprintf(fa1,"\t\t非法字符\n");break;case 31:printf("\t\t数越界\n");fprintf(fa1,"\t\t数越界\n");break;case 32:printf("\t\tread语句括号中的标识符不是变量\n" ); fprintf(fa1,"\t\tread语句括号中的标识符不是变量\n"); break;case 33:printf("\t\twrite()或read()中应为完整表达式\n" ); fprintf(fa1,"\t\twrite()或read()中应为完整表达式\n"); break;default:printf("\t\t出现未知错误\n" );fprintf(fa1,"\t\t出现未知错误\n");}err++;}//漏掉空格,读取一个字符,每次读一行,存入line缓冲区,line 被getsym取空后再读一//行,被函数getsym调用int getch(){if(cc==ll){if(feof(fin)){printf("program incomplete");return-1;}ll=0;cc=0;printf("\n%d ",cx);fprintf(fa1,"\n%d ",cx);ch=' ';while(ch!=10){if(EOF==fscanf(fin,"%c",&ch)){line[ll]=0;break;}printf("%c",ch);fprintf(fa1,"%c",ch);line[ll]=ch;ll++;}fprintf(cifa,"\n");}ch=line[cc];cc++;return 0;}int getsym(){//词法分析int i,j,k,l;</n;i++)<>。
编译原理(PL0编译程序源代码)

/*PL/0编译程序(C语言版)*编译和运行环境:*Visual C++6.0*WinXP/7*使用方法:*运行后输入PL/0源程序文件名*回答是否将虚拟机代码写入文件*回答是否将符号表写入文件*执行成功会产生四个文件(词法分析结果.txt符号表.txt虚拟代码.txt源程序和地址.txt)*/#include <stdio.h>#include"pl0.h"#include"string"#define stacksize 500//解释执行时使用的栈int main(){bool nxtlev[symnum];printf("请输入源程序文件名:");scanf("%s",fname);fin=fopen(fname,"r");//以只读方式打开pl0源程序文件cifa=fopen("词法分析结果.txt","w");fa1=fopen("源程序和地址.txt","w");//输出源文件及各行对应的首地址fprintf(fa1,"输入pl0源程序文件名:");fprintf(fa1,"%s\n",fname);if(fin){printf("是否将虚拟机代码写入文件?(Y/N)");//是否输出虚拟机代码scanf("%s",fname);listswitch=(fname[0]=='y'||fname[0]=='Y');printf("是否将符号表写入文件?(Y/N)");//是否输出符号表scanf("%s",fname);tableswitch=(fname[0]=='y'||fname[0]=='Y');init();//初始化err=0;cc=cx=ll=0;ch=' ';if(-1!=getsym()){fa=fopen("虚拟代码.txt","w");fas=fopen("符号表.txt","w");addset(nxtlev,declbegsys,statbegsys,symnum);nxtlev[period]=true;if(-1==block(0,0,nxtlev)){//调用编译程序fclose(fa);fclose(fa1);fclose(fas);fclose(fin);return 0;}if(sym!=period){error(9);//结尾丢失了句号}if(err!=0){printf("pl0源程序出现错误,退出编译!!!请从第一个错误处开始修改.\n\n");fprintf(cifa,"源程序出现错误,请检查!!!");fprintf(fa1,"源程序出现错误,请检查!!!");fprintf(fa,"源程序出现错误,请检查!!!");fprintf(fas,"源程序出现错误,请检查!!!");}fclose(fa);fclose(fa1);fclose(fas);}fclose(fin);}else{printf("Can't open file!\n");}fclose(cifa);//printf("\n");return 0;}void init(){//初始化int i;for(i=0;i<=255;i++)ssym[i]=nul;//设置单字符符号ssym['+']=plus;ssym['-']=minus;ssym['*']=times;ssym['/']=slash;ssym['(']=lparen;ssym[')']=rparen;ssym['=']=eql;ssym[',']=comma;ssym['.']=period;ssym['#']=neq;ssym[';']=semicolon;strcpy(&(word[0][0]),"begin");//保留字设置,以字母顺序排列便于折半查找strcpy(&(word[1][0]),"call");strcpy(&(word[2][0]),"const");strcpy(&(word[3][0]),"do");strcpy(&(word[4][0]),"end");strcpy(&(word[5][0]),"if");strcpy(&(word[6][0]),"odd");strcpy(&(word[7][0]),"procedure");strcpy(&(word[8][0]),"read");strcpy(&(word[9][0]),"then");strcpy(&(word[10][0]),"var");strcpy(&(word[11][0]),"while");strcpy(&(word[12][0]),"write");wsym[0]=beginsym;//设置保留字类别一字即一类wsym[1]=callsym;wsym[2]=constsym;wsym[3]=dosym;wsym[4]=endsym;wsym[5]=ifsym;wsym[6]=oddsym;wsym[7]=procsym;wsym[8]=readsym;wsym[9]=thensym;wsym[10]=varsym;wsym[11]=whilesym;wsym[12]=writesym;strcpy(&(mnemonic[lit][0]),"lit");//设置指令名称strcpy(&(mnemonic[opr][0]),"opr");strcpy(&(mnemonic[lod][0]),"lod");strcpy(&(mnemonic[sto][0]),"sto");strcpy(&(mnemonic[cal][0]),"cal");strcpy(&(mnemonic[inte][0]),"int");strcpy(&(mnemonic[jmp][0]),"jmp");strcpy(&(mnemonic[jpc][0]),"jpc");for(i=0;i<symnum;i++){//设置符号集declbegsys[i]=false;statbegsys[i]=false;facbegsys[i]=false;}declbegsys[constsym]=true;//设置声明开始符号集declbegsys[varsym]=true;declbegsys[procsym]=true;statbegsys[beginsym]=true;//设置语句开始符号集statbegsys[callsym]=true;statbegsys[ifsym]=true;statbegsys[whilesym]=true;facbegsys[ident]=true;//设置因子开始符号集facbegsys[number]=true;facbegsys[lparen]=true;}//用数组实现集合的集合运算int inset(int e,bool* s){return s[e];}int addset(bool*sr,bool* s1,bool* s2,int n){int i;for(i=0;i<n;i++)sr[i]=s1[i]||s2[i];return 0;}void error(int n){//出错处理,打印出错位置和错误编码char space[81];memset(space, 32,81);space[cc-1]=0;printf("error(%d)",n);fprintf(fa1,"error(%d)",n);switch(n){case 1:printf("\t\t常量说明中的“=”写成“:=”\n");fprintf(fa1,"\t\t常量说明中的“=”写成“:=”\n");break;case 2:printf("\t\t常量说明中的=后应该是数字\n");fprintf(fa1,"\t\t常量说明中的=后应该是数字\n");break;case 3:printf("\t\t常量说明符中的表示符应该是=\n" );fprintf(fa1,"\t\t常量说明符中的表示符应该是=\n");break;case 4:printf("\t\tconst,var,procedure后应为标识符\n" );fprintf(fa1,"\t\tconst,var,procedure后应为标识符\n");break;case 5:printf("\t\t漏掉了“,”或“;”\n" );fprintf(fa1,"\t\t漏掉了“,”或“;”\n" );break;case 6:printf("\t\t过程说明后的符号不正确\n" );fprintf(fa1,"\t\t过程说明后的符号不正确\n");break;case 7:printf("\t\t应是语句开始符\n" );fprintf(fa1,"\t\t应是语句开始符\n" );break;case 8:printf("\t\t程序体语句部分的后跟符不正确\n" );fprintf(fa1,"\t\t程序体语句部分的后跟符不正确\n" );break;case 9:printf("\t\t程序结尾丢了句号“.”\n\n" );fprintf(fa1,"\t\t程序结尾丢了句号“.”\n");break;case 10:printf("\t\t语句之间漏了“;”\n" );fprintf(fa1,"\t\t语句之间漏了“;”\n");break;case 11:printf("\t\t标识符拼写错误或未说明\n" );fprintf(fa1,"\t\t标识符拼写错误或未说明\n");break;case 12:printf("\t\t赋值语句中,赋值号左部标识符属性应是变量\n" );fprintf(fa1,"\t\t赋值语句中,赋值号左部标识符属性应是变量\n");break;case 13:printf("\t\t赋值语句左部标识符后应是复制号“:=”\n" );fprintf(fa1,"\t\t赋值语句左部标识符后应是复制号“:=”\n");break;case 14:printf("\t\tcall后应为标识符\n" );fprintf(fa1,"\t\tcall后应为标识符\n");break;case 15:printf("\t\tcall后标识符属性应为过程\n" );fprintf(fa1,"\t\tcall后标识符属性应为过程\n");break;case 16:printf("\t\t条件语句中丢了then\n" );fprintf(fa1,"\t\t条件语句中丢了then\n");break;case 17:printf("\t\t丢了“end”或“;”\n" );fprintf(fa1,"\t\t丢了“end”或“;”\n");break;case 18:printf("\t\twhile型循环语句中丢了“do”\n" );fprintf(fa1,"\t\twhile型循环语句中丢了“do”\n");break;case 19:printf("\t\t语句后的符号不正确\n" );fprintf(fa1,"\t\t语句后的符号不正确\n" );break;case 20:printf("\t\t应为关系运算符\n" );fprintf(fa1,"\t\t应为关系运算符\n");break;case 21:printf("\t\t表达式标示符属性不能是过程\n" );fprintf(fa1,"\t\t表达式标示符属性不能是过程\n");break;case 22:printf("\t\t表达式漏掉了右括号\n" );fprintf(fa1,"\t\t表达式漏掉了右括号\n");break;case 23:printf("\t\t因子后的非法符号\n" );fprintf(fa1,"\t\t因子后的非法符号\n");break;case 24:printf("\t\t表达式的开始符不能是此符号\n" );fprintf(fa1,"\t\t表达式的开始符不能是此符号\n");break;case 25:printf("\t\t标识符越界\n" );fprintf(fa1,"\t\t标识符越界\n");break;case 26:printf("\t\t非法字符\n" );fprintf(fa1,"\t\t非法字符\n");break;case 31:printf("\t\t数越界\n");fprintf(fa1,"\t\t数越界\n");break;case 32:printf("\t\tread语句括号中的标识符不是变量\n" );fprintf(fa1,"\t\tread语句括号中的标识符不是变量\n");break;case 33:printf("\t\twrite()或read()中应为完整表达式\n" );fprintf(fa1,"\t\twrite()或read()中应为完整表达式\n");break;default:printf("\t\t出现未知错误\n" );fprintf(fa1,"\t\t出现未知错误\n");}err++;}//漏掉空格,读取一个字符,每次读一行,存入line缓冲区,line被getsym取空后再读一//行,被函数getsym调用int getch(){if(cc==ll){if(feof(fin)){printf("program incomplete");return-1;}ll=0;cc=0;printf("\n%d ",cx);fprintf(fa1,"\n%d ",cx);ch=' ';while(ch!=10){if(EOF==fscanf(fin,"%c",&ch)){line[ll]=0;break;}printf("%c",ch);fprintf(fa1,"%c",ch);line[ll]=ch;ll++;}fprintf(cifa,"\n");}ch=line[cc];cc++;return 0;}int getsym(){//词法分析int i,j,k,l;while(ch==' '||ch==10||ch==9)//忽略空格换行 TABgetchdo;if(ch>='a'&&ch<='z'){//以字母开头的为保留字或者标识符k=0,l=1;do{if(k<al){//al为标识符或保留字最大长度a[k]=ch;k++;}if(k==al&&l==1){error(25);l=0;}getchdo;}while(ch>='a'&&ch<='z'||ch>='0'&&ch<='9');a[k]=0;//末尾存零strcpy(id,a);i=0;j=norw-1;do{//开始折半查找k=(i+j)/2;if(strcmp(id,word[k])<=0){j=k-1;}if(strcmp(id,word[k])>=0){i=k+1;}}while(i<=j);if(i-1>j){//找到即为保留字sym=wsym[k];fprintf(cifa,"%s\t\t%ssym\n",id,id);//printf("%s\t\t%ssym\n",id,id);}else{//否则为标识符或数字sym=ident;fprintf(cifa,"%s\t\tident\n",id);//printf("%s\t\tident\n",id);}}else {if(ch>='0'&&ch<='9'){k=0;num=0;sym=number;do{num=10*num+ch-'0';//数字的数位处理k++;getchdo;}while(ch>='0'&&ch<='9');k--;if(k>nmax){//数字的长度限制fprintf(cifa,"0\t\tnumber\n");num=0;error(31);}elsefprintf(cifa,"%d\t\tnumber\n",num);//printf("%d\t\tnumber\n",num);}else{if(ch==':'){//检测赋值符号,:只能和=匹配,否则不能识别getchdo;if(ch=='='){sym=becomes;fprintf(cifa,":=\t\tbecomes\n");getchdo;}else{sym=nul;}}else{if(ch=='<'){getchdo;if(ch=='='){sym=leq;//小于等于fprintf(cifa,"<=\t\tleq\n");getchdo;}else{sym=lss;//小于fprintf(cifa,"<\t\tlss\n");}}else{if(ch=='>'){getchdo;if(ch=='='){sym=geq;//大于等于fprintf(cifa,">=\t\tgeq\n");getchdo;}else{sym=gtr;//大于fprintf(cifa,">\t\tgtr\n");}}else{sym=ssym[ch];//不满足上述条件时按单字//符处理switch(ch){case'+':fprintf(cifa,"%c\t\tplus\n",ch);break;case '-':fprintf(cifa,"%c\t\tminus\n",ch );break;case '*':fprintf(cifa,"%c\t\ttimes\n",ch);break;case '/':fprintf(cifa,"%c\t\tslash\n",ch);break;case '(':fprintf(cifa,"%c\t\tlparen\n",ch);break;case ')':fprintf(cifa,"%c\t\trparen\n",ch);break;case '=':fprintf(cifa,"%c\t\teql\n",ch);break;case ',':fprintf(cifa,"%c\t\tcomma\n",ch);break;case '#':fprintf(cifa,"%c\t\tneq\n",ch);break;case ';':fprintf(cifa,"%c\t\tsemicolon\n",ch);break;case '.':break;default :error(26);}if(sym!=period){//判断是否结束getchdo;}else{printf("\n");fprintf(cifa,".\t\tperiod\n");}}}}}}return 0;}//生成目标代码//目标代码的功能码,层差和位移量int gen(enum fct x,int y,int z){if(cx>=cxmax){//如果目标代码索引过大,报错printf("Program too long");return -1;}code[cx].f=x;code[cx].l=y;code[cx].a=z;cx++;return 0;}//测试字符串int test(bool* s1,bool* s2,int n){if(!inset(sym,s1)){//测试sym是否属于s1,不属于则报错nerror(n);while((!inset(sym,s1))&&(!inset(sym,s2))){//检测不通过时,不停获得符号,直到它属于需要或补救的集合getsymdo;}}return 0;}//编译程序主体//lev:当前分程序所在层,tx:名字表当前尾指针fsys:当前模块后跟符号集合int block(int lev,int tx,bool* fsys){int i;int dx;//名字分配到的相对地址int tx0;//保留初始txint cx0;//保留初始cxbool nxtlev[symnum];dx=3;//相对地址从3开始,前3个单元即0、1、2单元分别为 SL:静态链;//DL:动态链;RA:返回地址tx0=tx;//记录本层的初始位置table[tx].adr=cx;gendo(jmp,0,0);if(lev>levmax){//层数超过3error(32);}do{if(sym==constsym){//收到常量声明printf("该语句为常量定义语句\n");getsymdo;do{constdeclarationdo(&tx,lev,&dx);//常量声明处理,dx 会改//变所以使用指针while(sym==comma){//处理一次多常量定义getsymdo;constdeclarationdo(&tx,lev,&dx);}if(sym==semicolon){//常量声明处理结束getsymdo;}else{error(5);//漏掉了逗号或者分号(一般是分号)}}while(sym==ident);}if(sym==varsym){//收到变量声明printf("该语句为变量声明语句\n");getsymdo;do{vardeclarationdo(&tx,lev,&dx);//变量声明处理while(sym==comma){//处理一次多变量定义getsymdo;vardeclarationdo(&tx,lev,&dx);}if(sym==semicolon){//变量声明处理结束getsymdo;}else{error(5);//漏掉逗号或者分号}}while(sym==ident);}while(sym==procsym){//收到过程声明printf("该语句为过程声明语句\n");getsymdo;if(sym==ident){enter(procedur,&tx,lev,&dx);//记录过程名getsymdo;}else{error(4);//过程声明后应为标识符}if(sym==semicolon){getsymdo;}else{error(5);//漏掉了分号}memcpy(nxtlev,fsys,sizeof(bool)*symnum);nxtlev[semicolon]=true;if(-1==block(lev+1,tx,nxtlev)){return -1;}if(sym==semicolon){getsymdo;memcpy(nxtlev,statbegsys,sizeof(bool)*symnum);nxtlev[ident]=true;nxtlev[procsym]=true;testdo(nxtlev,fsys,6);}else{error(5);}}memcpy(nxtlev,statbegsys,sizeof(bool)*symnum);nxtlev[ident]=true;nxtlev[period]=true;testdo(nxtlev,declbegsys,7);}while(inset(sym,declbegsys));//直到没有声明符号code[table[tx0].adr].a=cx;//开始生成当前过程代码table[tx0].adr=cx;//当前过程代码地址table[tx0].size=dx;cx0=cx;gendo(inte,0,dx);//生成分配存代码if(tableswitch){//输出符号表if(tx0+1<tx){fprintf(fas,"TABLE:\n");//printf("NULL\n");}for(i=tx0+1;i<=tx;i++){switch(table[i].kind){case constant:fprintf(fas,"%d const %s ",i,table[i].name);fprintf(fas,"val=%d\n",table[i].val);break;case variable:fprintf(fas,"%d var %s ",i,table[i].name);fprintf(fas,"lev=%daddr=%d\n",table[i].level,table[i].adr);break;case procedur:fprintf(fas,"%d proc %s ",i,table[i].name);fprintf(fas,"lev=%daddr=%dsize=%d\n", table[i].level,table[i].adr,table[i].size);break;}}}memcpy(nxtlev,fsys,sizeof(bool)*symnum);//每个后跟符号集和都包含上层后跟符//号集和,以便补救nxtlev[semicolon]=true;nxtlev[endsym]=true;statementdo(nxtlev,&tx,lev);gendo(opr,0,0);//每个过程出口都要使用的释放数据指令memset(nxtlev,0,sizeof(bool)*symnum);//分程序没有补救集合testdo(fsys,nxtlev,8);//检测后跟符号集的正确性listcode(cx0);//输出代码return 0;}//k:const var procedure//ptx:符号表尾的指针//pdx:dx为当前应分配变量的相对地址//lev:符号名字所在的层次//往符号表中添加void enter(enum object k,int* ptx,int lev,int* pdx){(* ptx)++;strcpy(table[(*ptx)].name,id);table[(* ptx)].kind=k;switch(k){case constant:if(num>amax){error(31);num=0;}table[(*ptx)].val=num;break;case variable:table[(*ptx)].level=lev;table[(*ptx)].adr=(*pdx);(*pdx)++;break;case procedur:table[(*ptx)].level=lev;break;}}//寻找符号在符号表中的地址int position(char*idt,int tx){int i;strcpy(table[0].name,idt);i=tx;//符号表尾while(strcmp(table[i].name,idt)!=0){i--;}return i;}//常量声明处理int constdeclaration(int* ptx,int lev,int* pdx){if(sym==ident){getsymdo;if(sym==eql||sym==becomes){if(sym==becomes){error(1);}getsymdo;if(sym==number){enter(constant,ptx,lev,pdx);getsymdo;}else{error(2);}}else{error(3);}}else{error(4);}return 0;}//变量声明处理int vardeclaration (int* ptx,int lev,int* pdx){if(sym==ident){enter(variable,ptx,lev,pdx);getsymdo;}else{error(4);}return 0;}//输出目标代码清单void listcode(int cx0){int i;if(listswitch){for(i=cx0;i<cx;i++){fprintf(fa,"%d %s %d %d\n",i,mnemonic[code[i].f],code[i].l,code[i],a);}}}//语句处理int statement(bool* fsys,int* ptx,int lev){int i,cx1,cx2;bool nxtlev[symnum];if(sym==ident){i=position(id,*ptx);if(i==0){error(11);}else{if(table[i].kind!=variable){error(12);i=0;}else{getsymdo;if(sym==becomes){getsymdo;printf("该语句为赋值语句。
PL0源程序-编译原理实验代码

附件1 小组成员:程序清单Main.c#include<stdio.h>#include<stdlib.h>#include<string.h>void error(int n);void getsym();//void enter(enum object k,int *ptx,int lev,int *pdx);int position(char*idt,int tx);int constdeclaration(int *ptx,int lev,int *pdx);int vardeclaration(int *ptx,int lev,int *pdx);int factor(int*ptx,int lev);int term(int *ptx,int lev);int expression(int *ptx,int lev);int statement(int *ptx,int lev);int block();enum object{constant,variable,procedure};struct tab{char name[14];enum object kind;int val;int level;int adr;int size;}table[100];enum symbol{nul,ident,number,plus,minus,times,slash,oddsym,eql,neq,lss,leq,gtr,geq,lparen,r paren,comma,semicolon,period,becomes,beginsym,endsym,ifsym,thensym,whilesym,writesym,readsym,dosym,ca llsym,constsym,varsym,procsym,progsym,};enum symbol sym=nul;enum symbol mulop;enum symbol wsym[14];enum symbol ssym[256];char ch=' ';char *str;charword[14][10]={"begin","call","const","do","end","if","odd","procedure","program ","read","then","var","while","write"};//设置保留字名字int num;int lev=0;int tx=0;int k;int *mm;//=(int *)malloc(sizeof(int));char *id,sign[14];char a[14];FILE *fp1,*fp2,*fp3;void error(int n){switch(n){case 1:printf("常数说明中的\"=\"写成了\":=\"。
PL0编译程序

PL/0语言编译系统春秋五霸目录1 PL/0语言及编译系统2 驱动代码3 编译程序4 解释程序①词法分析②语法分析③语义分析及目标代码生成1 PL/0语言编译系统PL/语言编译系统PL/0语言编译系统是世界著名计算机科学家N.Wirth编写的。
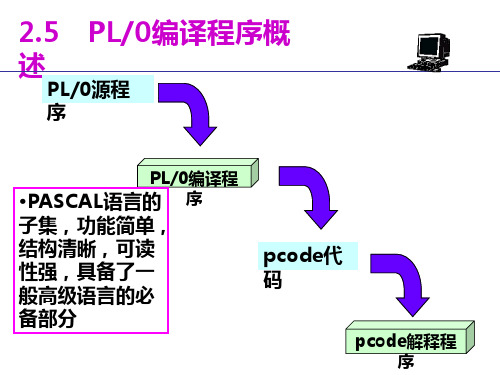
对PL/0编译程序进行实例分析,有助于对一般编译过程和编译程序结构的理解。
PL/0语言功能简单、结构清晰、可读性强,又具备了一般高级语言的必须部分,因而PL/0语言的编译程序能充分体现一个高级语言编译程序实现的基本技术和步骤,是一个非常合适的编译程序教学模型。
PL/0源程序PL/0编译系统语法语义分析程序词法分析程序目标代码代码生成程序表格管理程序出错处理程序PL/0源程序PL/0编译系统构成类P-code程序PL/0编译程序输出数据输入数据类P-code虚拟机类P-code解释程序PL/0语言文法的EBNF表示●〈程序〉∷=〈分程序〉.●〈分程序〉∷=[〈常量说明部分〉][〈变量说明部分〉][〈过程说明部分〉]〈语句〉●〈常量说明部分〉∷=CONST〈常量定义部分〉{,〈常量定义〉};●〈常量定义〉 ::= 〈标识符〉=〈无符号整数〉;●〈无符号整数〉∷=〈数字〉{〈数字〉}●〈变量说明部分〉∷=V AR〈标识符〉{,〈标识符〉};●〈标识符〉∷=〈字母〉{〈字母〉|〈数字〉}PL/0语言文法的EBNF表示●<过程说明部分>::=<过程首部><分程序>{;<过程说明部分>}●<过程首部>::=PROCEDURE<标识符>;●<语句>::=<赋值语句>|<条件语句>|<当型循环语句>|<过程调用语句>|<读语句>|<写语句>|<复合语句>|<空>●<赋值语句>::= <标识符>:=<表达式>●<复合语句>::= BEGIN<语句>{;<语句>}END●<条件>::= <表达式><关系运算符><表达式>PL/0语言文法的EBNF表示●<表达式>::=[+|-]<项>{<加法运算符><项>}●<项>::= <因子>{<乘法运算符><因子>}●<因子>::= <标识符>|<无符号整数>|‘(’<表达式>‘)’PL/0语言文法的EBNF表示●<加法运算符>::= +|-●<乘法运算符>::= *|/●<关系运算符>::= =|#|<|<=|>|>=●<条件语句>::= IF<条件>THEN<语句>●<过程调用语句>::= CALL<标识符>●<当型循环语句>::= WHILE<条件>DO<语句>●<读语句>::= READ’(’<标识符>{,<标识符>}‘)’PL/0语言文法的EBNF表示●<写语句>::= WRITE’(’<表达式>{,<表达式>}‘)’●<字母>::= a|b|…|X|Y|Z●<数字>::= 0|1|…|8|9指令过程调用相关指令类P-code 虚 拟机指令系 统…存取指令int 0 a cal l ajmp 0 alit 0 alod l a sto l a指令一元运算和比较指令类P-code 虚 拟机指令系 统…二元运算指令opr 0 5opr 0 1opr 0 6opr 0 2opr 0 3 opr 0 4指令转移指令类P-code 虚 拟机指令系 统输入输出指令二元运算指令opr 0 13 jmp 0 ajpc 0 aopr 0 8 opr 0 10opr 0 12opr 0 14opr 0 16opr 0 15opr 0 9opr 0 112 驱动代码词法分析主要函数:main()函数功能:驱动整个编译系统的运行变量说明:fa.tmp 输出虚拟机代码fa1.tmp 输出源文件及其各行对应的首地址fa2.tmp 输出结果fas.tmp 输出名字表main函数int main(){……/*打开源程序文件*/If 打开源程序文件成功{…… /*初始化输出文件信息*/init(); /*初始化各类名字和符号信息*/err=0; /*初始化错误数*/…… /*初始化其他信息*/if(-1!=getsym()) /*成功读取第一个单词*/{……main函数if(-1==block(0,0,nxtlev)) /*调用编译程序*/{…… /*编译过程未成功结束关闭所有已打开的文件,返回*/}…… /*编译过程结束关闭所有已打开的输出文件*/if(sym!=period) /*当前符号不是程序结束符’.’*/{error(9); /*提示9号出错信息:缺少程序结束符’.’*/}if(err==0) /*未发现程序中的错误*/{……interpret(); /*调用解释程序,执行所产生的类P-code代码*/……main函数else{printf("Errors in pl/0 program");}}…… /*关闭已打开的文件*/}else{printf(“Can‘t open file! \n”);/*打开源程序文件不成功*/}printf("\n");return 0; /*返回*/}集合运算函数int inset(int e,bool* s){/*返回e在数组s中的值*/return s[e];}int addset(bool* sr,bool* s1,bool* s2,int n){/*逻辑或运算*/int i;for(i=0;i<n;i++){sr[i]=s1[i]||s2[i];}return 0;}集合运算函数int subset(bool* sr,bool* s1,bool* s2,int n){/*s1[i]为true,s2[i]为false时,sr[i]才为true*/int i;for(i=0;i<n;i++){sr[i]=s1[i]&&(!s2[i]);}return 0; }int mulset(bool* sr,bool* s1,bool* s2,int n){/*逻辑与运算*/int i;for(i=0;i<n;i++){sr[i]=s1[i]&&s2[i]; }return 0;}错误处理函数void error(int n){char space[81];memset(space,32,81);printf("-------%c\n",ch);fprintf(fa1,"-------%c\n",ch);space[cc-1]=0;//出错时当前符号已经读完,所以cc-1printf("****%s!%d\n",space,n);fprintf(fa1,"****%s!%d\n",space,n);err++;}PL/O语言的出错信息表:出错编号出错原因1:常数说明中的“=”写成“∶=”。
PL0编译程序

PL/0编译程序的运行机制:语法分析开始后,首先调用分程序处理过程(block)处理分程序。
过程入口参数置为:0层、符号表位置0、出错恢复单词集合为句号、声明符或语句开始符。
进入block过程后,首先把局部数据段分配指针设为3,准备分配3个单元供运行期存放静态链SL、动态链DL和返回地址RA。
然后用tx0记录下当前符号表位置并产生一条jmp指令,准备跳转到主程序的开始位置,由于当前还没有知到主程序究竟在何处开始,所以jmp的目标暂时填为0,稍后再改。
同时在符号表的当前位置记录下这个jmp指令在代码段中的位置。
在判断了嵌套层数没有超过规定的层数后,开始分析源程序。
首先判断是否遇到了常量声明,如果遇到则开始常量定义,把常量存入符号表。
接下去用同样的方法分析变量声明,变量定义过程中会用dx变量记录下局部数据段分配的空间个数。
然后如果遇到procedure保留字则进行过程声明和定义,声明的方法是把过程的名字和所在的层次记入符号表,过程定义的方法就是通过递归调用block过程,因为每个过程都是一个分程序。
由于这是分程序中的分程序,因此调用block时需把当前的层次号lev加一传递给block过程。
分程序声明部分完成后,即将进入语句的处理,这时的代码分配指针cx的值正好指向语句的开始位置,这个位置正是前面的jmp指令需要跳转到的位置。
于是通过前面记录下来的地址值,把这个jmp指令的跳转位置改成当前cx的位置。
并在符号表中记录下当前的代码段分配地址和局部数据段要分配的大小(dx 的值)。
生成一条int指令,分配dx个空间,作为这个分程序段的第一条指令。
下面就调用语句处理过程statement分析语句。
分析完成后,生成操作数为0的opr指令,用于从分程序返回(对于0层的主程序来说,就是程序运行完成,退出)。
逻辑表达式的处理:首先判断是否为一元逻辑表达式:判奇偶。
如果是,则通过调用表达式处理过程分析计算表达式的值,然后生成判奇指令。
第2章 简介PL0
数据类型
整型
说明类型
(1)常量说明(全局) (2)变量说明; (3)过程说明。
• 标识符(字母开始的字母数字串)的有效长度 是10 • 数字最多为14位 • 过程无参,可嵌套(最多三层)定义,可递归 调用 • 变量的作用域同PASCAL • 13个保留字:if, then, while, do, read, write, call, begin, end, const, var, procedure, odd
±°¥ Ê µ Ç µ ´ Ç ²Î Ô Ì ò á ÷ ø Ê ñ ª ´ ³ Ð ½ Ê ² '.'£ ¿ Y ´ Ì ò Ð Ô ³ Ð Ö Ç ñ Ð í ó ¿ Ê ²Ó ´ Î £ N ôà â Í ù Ì µ Ó ½ Ê ¸ ³ INTERPRET â Ê ´ ½ Í Ö Ð Ä ±³ Ð ¿ ê Ì ò Y
"semicolon","period","becomes","beginsym","endsym","ifsym",
"thensym","whilesym","writesym","readsym","dosym","callsym", "constsym","varsym","procsym"};
因子 factor
语法图
程序
分程序
分程序
const
.
ident ,
=
number
; var ident
,
; ;
编译原理课程设计报告PL0编译程序改良及完善

燕山大学《编译原理课程设计》题目:《PL/0编译程序改良及完善》姓名:简越班级:06级运算机应用3班学号:060104010084日期:2020年7月15日设计题目:PL/0编译程序改良及完善。
设计目的:阅读研究,改良设计和调试一个简单的编译程序。
加深对编译理论和进程的了解。
设计要求:1.有选择的对PL/0编译源程序补充,完善.2.设计编译典型的运行实例,以便反映出自己作出改良后的编具有的功能。
设计思想:PL/0语言能够看成PASCAL语言的子集,它的编译程序是一个编译说明执行系统。
PL/0的目标程序为假想栈式运算机的汇编语言,与具体运算机无关。
PL/0的编译程序和目标程序的说明执行程序都是用PASCAL语言书写的,因此PL/0语言可在配备PASCAL语言的任何机械上实现。
其编译进程采纳一趟扫描方式,以语法分析程序为核心,词法分析和代码生成程序都作为一个独立的进程,当语法分析需要读单词时就挪用词法分析程序,而当语法分析正确需要生成相应的目标代码时,那么挪用代码生成程序。
用表格治理程序成立变量、常量和进程表示符的说明与引用之间的信息联系。
当源程序编译正确时,PL/0编译程序自动挪用说明执行程序,对目标代码进行说明执行,并按用户程序的要求输入数据和输出运行结果。
要紧变量说明:/*变量说明*/FILE* fas; /*输出名字表*/FILE* fa; /*输出虚拟机代码*/FILE* fa1; /*输出源文件及其各行对应的首地址*/FILE* fa2; /*输出结果*/bool listswitch; /*显示虚拟机代码与否*/bool tableswitch; /*显示名字表与否*/char ch; /*获取字符的缓冲区,getch利用*/enum symbol sym; /*当前的符号*/char id[al+1]; /*当前ident,多出的一个字节用于寄存0*/ int num; /*当前number*/int cc,ll; /*getch利用的计数器,cc表示当前字符(ch)的位置*/int cx; /*虚拟机代码指针,取值范围[0,cxmax-1]*/char line[81]; /*读取行缓冲区*/char a[al+1]; /*临时符号,多出的一个字节用于寄存0*/ struct instruction code[cxmax]; /*寄存虚拟机代码的数组*/char word[norw][al]; /*保留字*/enum symbol wsym[norw]; /*保留字对应的符号值*/enum symbol ssym[256]; /*单字符的符号值*/char mnemonic[fctnum][5]; /*虚拟机代码指令名称*/bool declbegsys[symnum]; /*表示声明开始的符号集合*/bool statbegsys[symnum]; /*表示语句开始的符号集合*/bool facbegsys[symnum]; /*表示因子开始的符号集合*//* 目标指令*/一、LIT:将常量值取到运行栈顶.二、LOD:将变量放到运行栈顶.3、STO:将栈顶的内容送入某变量单元中.4、CAL:挪用进程的指令.五、INT:为被挪用的进程(或主程序)在运行栈中开辟数据区.六、JMP:无条件转移指令.7、JPC:条件转移指令,当栈顶的布尔值为真时, 顺序执行,不然转向域的地址.八、OPR:系运算符和算术运算指令.将栈顶和次栈顶的内容进行运算,结果寄存栈顶./*函数说明*/void error(int n,int line)说明:犯错处置函数,打印犯错信息,错误总数加1。
pl0编译原理

pl0编译原理编译原理是计算机科学中的一门重要课程,它研究的是如何将高级语言转化为机器语言的过程。
在编译原理中,pl0是一种简单的编程语言,它的设计目标是为了教学和研究目的而产生的。
本文将介绍pl0编译原理的基本概念和主要过程。
一、pl0编译原理的基本概念1.1 什么是pl0编程语言pl0是一种结构化的过程性编程语言,它的语法规则简单明了,易于学习和理解。
pl0支持基本的数据类型和控制结构,包括整型、实型、布尔型等。
1.2 pl0编译器的作用pl0编译器的主要作用是将pl0源代码转化为目标代码,使计算机能够理解和执行这些代码。
编译器的工作包括词法分析、语法分析、语义分析、中间代码生成和目标代码生成等。
1.3 pl0编译过程的主要阶段pl0编译过程主要包括词法分析、语法分析、语义分析和代码生成等阶段。
在词法分析阶段,编译器将源代码分解成一个个的词法单元;在语法分析阶段,编译器将词法单元按照语法规则组织成一个抽象语法树;在语义分析阶段,编译器对抽象语法树进行语义检查和类型推导;最后,在代码生成阶段,编译器将抽象语法树转化为目标代码。
二、pl0编译原理的主要过程2.1 词法分析词法分析是编译过程的第一步,它将源代码分解成一个个的词法单元。
在pl0编译器中,常见的词法单元包括关键字、标识符、常量、运算符和界符等。
编译器通过正则表达式和有限自动机等技术来实现词法分析。
2.2 语法分析语法分析是编译过程的第二步,它将词法单元按照语法规则组织成一个抽象语法树。
在pl0编译器中,常见的语法规则包括表达式、语句、函数和过程等。
编译器通过上下文无关文法和递归下降等技术来实现语法分析。
2.3 语义分析语义分析是编译过程的第三步,它对抽象语法树进行语义检查和类型推导。
在pl0编译器中,常见的语义检查包括变量声明检查、类型匹配检查和作用域检查等。
编译器通过符号表和类型推导等技术来实现语义分析。
2.4 代码生成代码生成是编译过程的最后一步,它将抽象语法树转化为目标代码。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
PL/0编译程序的运行机制:语法分析开始后,首先调用分程序处理过程(block)处理分程序。
过程入口参数置为:0层、符号表位置0、出错恢复单词集合为句号、声明符或语句开始符。
进入block过程后,首先把局部数据段分配指针设为3,准备分配3个单元供运行期存放静态链SL、动态链DL和返回地址RA。
然后用tx0记录下当前符号表位置并产生一条jmp指令,准备跳转到主程序的开始位置,由于当前还没有知到主程序究竟在何处开始,所以jmp的目标暂时填为0,稍后再改。
同时在符号表的当前位置记录下这个jmp指令在代码段中的位置。
在判断了嵌套层数没有超过规定的层数后,开始分析源程序。
首先判断是否遇到了常量声明,如果遇到则开始常量定义,把常量存入符号表。
接下去用同样的方法分析变量声明,变量定义过程中会用dx变量记录下局部数据段分配的空间个数。
然后如果遇到procedure保留字则进行过程声明和定义,声明的方法是把过程的名字和所在的层次记入符号表,过程定义的方法就是通过递归调用block过程,因为每个过程都是一个分程序。
由于这是分程序中的分程序,因此调用block时需把当前的层次号lev加一传递给block过程。
分程序声明部分完成后,即将进入语句的处理,这时的代码分配指针cx的值正好指向语句的开始位置,这个位置正是前面的jmp指令需要跳转到的位置。
于是通过前面记录下来的地址值,把这个jmp指令的跳转位置改成当前cx的位置。
并在符号表中记录下当前的代码段分配地址和局部数据段要分配的大小(dx 的值)。
生成一条int指令,分配dx个空间,作为这个分程序段的第一条指令。
下面就调用语句处理过程statement分析语句。
分析完成后,生成操作数为0的opr指令,用于从分程序返回(对于0层的主程序来说,就是程序运行完成,退出)。
逻辑表达式的处理:首先判断是否为一元逻辑表达式:判奇偶。
如果是,则通过调用表达式处理过程分析计算表达式的值,然后生成判奇指令。
如果不是,则肯定是二元逻辑运算符,通过调用表达式处理过程依次分析运算符左右两部分的值,放在栈顶的两个空间中,然后依不同的逻辑运算符,生成相应的逻辑判断指令,放入代码段。
判断单词合法性与出错恢复过程分析:本过程有三个参数,s1、s2为两个符号集合,n为出错代码。
本过程的功能是:测试当前符号(即sym变量中的值)是否在s1集合中,如果不在,就通过调用出错报告过程输出出错代码n,并放弃当前符号,通过词法分析过程获取一下单词,直到这个单词出现在s1或s2集合中为止。
这个过程在实际使用中很灵活,主要有两个用法:在进入某个语法单位时,调用本过程,检查当前符号是否属于该语法单位的开始符号集合。
若不属于,则滤去开始符号和后继符号集合外的所有符号。
在语法单位分析结束时,调用本过程,检查当前符号是否属于调用该语法单位时应有的后继符号集合。
若不属于,则滤去后继符号和开始符号集合外的所有符号。
通过这样的机制,可以在源程序出现错误时,及时跳过出错的部分,保证语法分析可以继续下去。
PL/0编译程序流程图oprlod stocaljmpjpcprogram pl0(fa,fa1,fa2);(* PL/0 compiler with code generation *)label 99; (* 声明出错跳转标记*)const (* 常量定义*)norw = 13; (* 保留字的个数*)txmax = 100; (* 标识符表的长度(容量)*)nmax = 14; (* 数字允许的最长位数*)al = 10; (* 标识符最长长度*)amax = 2047; (* 寻址空间*)levmax = 3; (* 最大允许的块嵌套层数*)cxmax = 200; (* 类PCODE目标代码数组长度(可容纳代码行数)*)type (* 类型定义*)symbol = (nul, ident, number, plus, minus, times, slash, oddsym,eql, neq, lss, leq, gtr, geq, lparen, rparen, comma,semicolon, period, becomes, beginsym, endsym, ifsym,thensym, whilesym, writesym, readsym, dosym, callsym,constsym, varsym, procsym); (* symobl类型标识了不同类型的词汇*)alfa = packed array[1..al] of char; (* alfa类型用于标识符*)object1 = (constant, variable, procedur); (* object1为三种标识符的类型*)(* wirth used the word "procedure" there, whick won't work! *)symset = set of symbol; (* symset是symbol类型的一个集合类型,可用于存放一组symbol *)fct = (lit, opr, lod, sto, cal, int, jmp, jpc); (* fct类型分别标识类PCODE的各条指令*) instruction = packed recordf: fct; (*指令f*)l: 0..levmax; (*层差l*)a: 0..amax;end;(* lit 0, a load constant aopr 0, a execute opr alod l, a load variable l, asto l, a store variable l, acal l, a call procedure a at level lint 0, a increment t-register by ajmp 0, a jump to ajpc 0, a jump conditional to a *)varfa: text; (* 文本文件fa用于列出源程序*)fa1, fa2: text; (* 文本文件fa1用于PCODE代码、fa2用于记录解释执行类PCODE代码的过程*)listswitch: boolean;ch: char; (* last char read *)bol read *)id: alfa; (* 词法分析器输出结果之用,存放最近一次识别出来的标识符的名字*)num: integer; (* 词法分析器输出结果之用,存放最近一次识别出来的数字的值*)cc: integer; (* 行缓冲区指针*)ll: integer; (* 行缓冲区长度*)kk: integer;cx: integer; (* 代码分配指针,代码生成模块总在cx所指位置生成新的代码*)line: array[1..81] of char; (* 行缓冲区,用于从文件读出一行,供词法分析获取单词时之用*)a: alfa; (* 词法分析器中用于临时存放正在分析的词*)code: array[0..cxmax] of instruction; (* 生成的类PCODE代码表,存放编译得到的类PCODE代码*)word: array[1..norw] of alfa;wsym: array[1..norw] of symbol; (* 保留字表中每一个保留字对应的symbol类型*) ssym: array[' '..'^'] of symbol; (* 一些符号对应的symbol类型表*)mnemonic: array[fct] of packed array[1..5] of char;(* 类PCODE指令助记符表*) declbegsys, statbegsys, facbegsys: symset;table: array[0..txmax] of recordname: alfa;case kind: object1 ofconstant:(val: integer);variable, procedur:(level, adr, size: integer) (* 存放层差、偏移地址和大小*)end;fin, fout: text; (* fin文本文件用于指向输入的源程序文件,fout程序中没有用到*) fname: string; (* 存放PL/0源程序文件的文件名*)err: integer;procedure error(n: integer);beginwriteln('****', ' ': cc-1, '!', n:2); (* 在屏幕cc-1位置显示!与出错代码提示,由于cc 是行缓冲区指针,所以!所指位置即为出错位置*)writeln(fa1, '****', ' ': cc-1, '!', n:2); (* 在文件cc-1位置输出!与出错代码提示*)err := err + 1 (* 出错总次数加一*)end (* error *);(* 词法分析过程getsym *)procedure getsym;vari, j, k: integer;(* 读取原程序中下一个字符过程getch *)procedure getch;beginif cc = ll then (* 如果行缓冲区指针指向行缓冲区最后一个字符就从文件读一行到行缓冲区*)beginif eof(fin) then (* 如果到达文件末尾*)beginwrite('Program incomplete'); (* 出错,退出程序*)close(fa);close(fa1);close(fin);halt(0);{goto 99}end;ll := 0; (* 行缓冲区长度置0 *)cc := 0; (* 行缓冲区指针置行首*)write(cx: 4, ' '); (* 输出cx值,宽度为4 *)write(fa1, cx: 4, ' '); (* 输出cx值,宽度为4到文件*)while not eoln(fin) do (* 当未到行末时*)beginll := ll + 1; (* 行缓冲区长度加一*)read(fin, ch); (* 从文件读入一个字符到ch *)write(ch); (* 在屏幕输出ch *)write(fa1, ch); (* 把ch输出到文件*)line[ll] := ch; (* 把读到的字符存入行缓冲区相应的位置*)end;(* 可见,PL/0源程序要求每行的长度都小于81个字符*)writeln;ll := ll + 1; (* 行缓冲区长度加一,用于容纳即将读入的回车符CR *)read(fin, line[ll]);(* 把#13(CR)读入行缓冲区尾部*)read(fin, ch);writeln(fa1);end;cc := cc + 1; (* 行缓冲区指针加一,指向即将读到的字符*)ch := line[cc] (* 读出字符,放入全局变量ch *)end (* getch *);begin (* getsym *)while (ch = ' ') or (ch = #13) dogetch;if ch in ['a'..'z'] then (* 如果读出的字符是一个字母,说明是保留字或标识符*)begink := 0; (* 标识符缓冲区指针置0 *)repeat (* 这个循环用于依次读出源文件中的字符构成标识符*)if k < al then (* 如果标识符长度没有超过最大标识符长度(如果超过,就取前面一部分,把多余的抛弃) *)begink := k + 1;a[k] := ch;end;getch (* 读下一个字符*)until not (ch in ['a'..'z','0'..'9']);if k >= kk then (* 如果当前获得的标识符长度大于等于kk *)kk := k (* 令kk为当前标识符长度*)elserepeat (* 这个循环用于把标识符缓冲后部没有填入相应字母或空格的空间用空格补足*)a[kk] := ' ';kk := kk - 1until kk = k;id := a; (* 最后读出标识符等于a *)i := 1;j := norw; (* j指向最后一个保留字*)repeatk := (i + j) div 2; (* k指向中间一个保留字*)if id <= word[k] then (* 如果当前的标识符小于k所指的保留字*)j := k - 1;if id >= word[k] then (* 如果当前的标识符大于k所指的保留字*)i := k + 1until i > j; (* 循环直到找完保留字表*)if i - 1 > j then (* 如果i - 1 > j表明在保留字表中找到相应的项,id中存的是保留字*) sym := wsym[k] (* 找到保留字,把sym置为相应的保留字值*)elsesym := ident (* 未找到保留字,把sym置为ident类型,表示是标识符*)end(* 至此读出字符为字母即对保留字或标识符的处理结束*)else (* 如果读出字符不是字母*)if ch in ['0'..'9'] then (* 如果读出字符是数字*)begin (* number *) (* 开始对数字进行处理*)k := 0;num := 0;sym := number;repeat (* 这个循环依次从源文件中读出字符,组成数字*)num := 10 * num + (ord(ch) - ord('0'));k := k + 1; (* 数字位数加一*)getchuntil not (ch in ['0'..'9']); (* 直到读出的字符不是数字为止*)if k > nmax then (* 如果组成的数字位数大于最大允许的数字位数*)error(30) (* 发出30号错*)end(* 至此对数字的识别处理结束*)elseif ch = ':'then (* 如果读出的不字母也不是数字而是冒号*)begingetch;if ch = '=' then (* 如果读到的是等号,正好可以与冒号构成赋值号*)beginsym := becomes; (* sym的类型设为赋值号becomes *)getchendelsesym := nul; (* 如果不是读到等号,那单独的一个冒号就什么也不是*) end(* 以上完成对赋值号的处理*)else (* 如果读到不是字母也不是数字也不是冒号*)if ch = '<' then (* 如果读到小于号*)begingetch;if ch = '=' then (* 如果读到等号*)beginsym := leq; (* 购成一个小于等于号*)getch (* 读一个字符*)endelse (* 如果小于号后不是跟的等号*)sym := lss (* 那就是一个单独的小于号*)endelse (* 如果读到不是字母也不是数字也不是冒号也不是小于号*)if ch = '>' then (* 如果读到大于号,处理过程类似于处理小于号*)begingetch;if ch = '=' then (* 如果读到等号*)beginsym := geq; (* 购成一个大于等于号*)getch (* 读一个字符*)endelse (* 如果大于号后不是跟的等号*)sym := gtr (* 那就是一个单独的大于号*)endelse(* 如果读到不是字母也不是数字也不是冒号也不是小于号也不是大于号*)begin (* 那就说明它不是标识符/保留字,也不是复杂的双字节操作符,应该是一个普通的符号*)sym := ssym[ch]; (* 直接成符号表中查到它的类型,赋给sym *)getchendend (* getsym *);procedure gen(x: fct; y, z: integer);beginif cx > cxmax then (* 如果cx>cxmax表示当前生成的代码行号大于允许的最大代码行数*)beginwrite('program too long'); (* 输出"程序太长",退出*)close(fa);close(fa1);close(fin);halt(0){goto 99}end;with code[cx] do (* 把代码写入目标代码数组的当前cx所指位置*)beginf := x;l := y;a := z;end;cx := cx + 1 (* 移动cx指针指向下一个空位*)end (* gen *);procedure test(s1, s2: symset; n: integer);beginif not (sym in s1) then (* 如果当前符号不在s1中*)beginerror(n);s1 := s1 + s2; (* 把s2集合补充进s1集合*)while not (sym in s1) do (* 通过循环找到下一个合法的符号,以恢复语法分析工作*) getsymendend (* test *);procedure block(lev, tx: integer; fsys: symset);vardx: integer; (* 数据段内存分配指针,指向下一个被分配空间在数据段中的偏移位置*) tx0: integer; (* 记录本层开始时符号表位置*)cx0: integer; (* 记录本层开始时代码段分配位置*)procedure enter(k: object1);begin (* enter object into table *)tx := tx + 1; (* 符号表指针指向一个新的空位*)with table[tx] do (* 开始登录*)beginname := id; (* name是符号的名字,对于标识符,这里就是标识符的名字*)kind := k; (* 符号类型,可能是常量、变量或过程名*)case k of (* 根据不同的类型进行不同的操作*)constant: (* 如果是常量名*)beginif num > amax then (* 在常量的数值大于允许的最大值的情况下*)beginerror(31); (* 抛出31号错误*)num := 0; (* 实际登陆的数字以0代替*)end;val := num (* 如是合法的数值,就登陆到符号表*)end;variable: (* 如果是变量名*)beginlevel := lev; (* 记下它所属的层次号*)adr := dx; (* 记下它在当前层中的偏移量*)dx := dx+1; (* 偏移量自增一,为下一次做好准备*)end;procedur: (* 如果要登陆的是过程名*)level := lev (* 记录下这个过程所在层次*)endendend (* enter *);function position (id: alfa): integer;vari: integer;begintable[0].name := id; (* 先把id放入符号表0号位置*)i := tx; (* 从符号表中当前位置也即最后一个符号开始找*)while table[i].name <> id do (* 如果当前的符号与要找的不一致*)i := i - 1; (* 找前面一个*)position := i (* 返回找到的位置号,如果没找到则一定正好为0 *)end(* position *);(* 常量声明处理过程constdeclaration *)procedure constdeclaration;beginif sym = ident then (* 常量声明过程开始遇到的第一个符号必然应为标识符*) begingetsym; (* 获取下一个token *)if sym in [eql, becomes] then (* 如果是等号或赋值号*)beginif sym = becomes then (* 如果是赋值号(常量生明中应该是等号) *)error(1); (* 抛出1号错误*)(* 这里其实自动进行了错误纠正使编译继续进行,把赋值号当作等号处理*)getsym; (* 获取下一个token,等号或赋值号后应接上数字*)if sym = number then (* 如果的确是数字*)beginenter(constant); (* 把这个常量登陆到符号表*)getsym (* 获取下一个token,为后面作准备*)endelseerror(2) (* 如果等号后接的不是数字,抛出2号错误*)endelseerror(3) (* 如果常量标识符后接的不是等号或赋值号,抛出3号错误*)endelseerror(4) (* 如果常量声明过程遇到的第一个符号不为标识符,抛出4号错误*) end(* constdeclaration *);(* 变量声明过程vardeclaration *)procedure vardeclaration;beginif sym = ident then (* 变量声明过程开始遇到的第一个符号必然应为标识符*) beginenter(variable); (* 将标识符登陆到符号表中*)getsym (* 获取下一个token,为后面作准备*)endelseerror(4) (* 如果变量声明过程遇到的第一个符号不是标识符,抛出4号错误*) end(* vardeclaration *);(* 列出当前一层类PCODE目标代码过程listcode *)procedure listcode;vari: integer;beginif listswitch then (* 如果用户选择是要列出代码的情况下才列出代码*)beginfor i := cx0 to cx - 1 do (* 从当前层代码开始位置到当前代码位置-1处,即为本分程序块*)with code[i] dobeginwriteln(i: 4, mnemonic[f]: 5, l: 3, a: 5); (* 显示出第i行代码的助记符和L与A操作数*)(* 我修改的代码:原程序此处在输出i时,没有指定占4个字符宽度,不美观也与下面一句不配套。