现代汉语词语切分研究
现代汉语语法的五种研究分析方法

1- 2主谓关系
照片放大了 一点儿。
1-2主谓关系
3-4述补关系
65-6述补关系
3.发现新的语法现象,揭示新的语法规律;
如: 父亲的 父亲的 父亲 父亲的 父亲的 父亲
2—(b)—1
按(a)切分,意思是 祖父的父亲”,即曾祖父;按(b)切分,意思是 父亲的祖父”,也
到底哪种是正确的划分方法呢?
语法学中所讲的某一小类实词的语义特征是指该小类实词所特有的、
能对它所在的句法格式
起制约作用的、并足以区别于其他小类实词的语义内涵或语义要素。
这里有两层含义:
1.如果离开具体句式,单纯从词汇角度概括一些词的语义特点,
1分析的对象是单句;
2.认为句子又六大成分组成一一主语、谓语(或述语)、宾语、补足语、形容词附加语(即 定语)和副词性附加语(即状语和补语)。
这六种成分分为三个级别:主语、谓语(或述语)是主要成分,宾语、补足语是连 带成分,形容词附加语和副词性附加语是附加成分;
3.作为句子成分的只能是词;
4.分析时,先找出全句的中心词作为主语和谓语,让其他成分分别依附于它们;
同,每一层面的直接组成成分之间的语法结构关系相同, 征分析法来解决问题。
如上述: 楼上演着戏。(a)楼上坐着人。(b)
经过分析,我们可以发现,虽然两句都属于名词[处所]+动词+着+名词”的句式,可是 动词表示的语法意义却不相同:
⑻式:名词[处所]+
动词+着+名词
动词表示活动,表动态
(b)式:名词[处所]+
①:双宾结构的远宾语不能有表示占有领属关系的偏正结构充任;
②:现代汉语里不用 被”给”一类字的受事主语句有一个特点,即受事主语不能是人称代词;
汉语分词技术研究现状与应用展望

续的字符串( , C )输 出是汉语的词 串( . CC C… ,
2 1 通用 词表和 切分 规范 .
… ) 这里 , 可 以是单字词也可 以是多字 ,
词. 那么 , 在这个过程中, 我们所要解决 的关键问题是什么 , 我们又有什么样 的解决方案呢? 至今为止 , 分词系统仍然没有一个统一的具有权威性的分词词表作为分词依据. 这不能不说是分词系
要 解决 的重要 问题 ,
除了同音词的自动辨识 , 汉语的多音字 自动辨识仍然需要分词 的帮助. 例如 : 校 、 、 、 、 等都 “ 行 重 乐 率” 是多音字. 无论是拼音 自动标注还是语音合成都需要识别出正确的拼音. 而多音字的辨识可以利用词以及
句子中前后词语境 , 即上下文来实现. 如下面几个多音字都可以通过所在的几组词得 以定音 : ) 、 z n ) 重(hn ) 快乐(e/ jo 对 行( ag 列/ x g 进 重(h g 量/ cog 新、 i n o 1)音乐 (u ) 率 (h a) 效 ye 、 sui领/
率( ) 1. v
2 汉语分词所面临 的关键 问题
汉语分词是由计算机 自动识别文本中的词边界的过程. 从计算机处理过程上看 , 分词系统的输入是连
定义两个字的互信息计算两个汉字结合程互信息体现了汉字之间结合关系的紧密程度需要大量的训练文本用以建立模型的参数到底哪种分词算法的准确度更高目前尚无定论对于任何一个成熟的分单独依靠某一种算法来实现都需要综合不同的算法汉语分词技术的应用国内自80年代初就在中文信息处理领域提出了自动分词从而产生了一些实用京航空航天大学计算机系1983年设计实现的cdws分词系统是我国第一个实用的自度约为625开发者自己测试结果下同早期分词系统机系研制的abws自动分词系统和北京师范大学现代教育研究所研制的书面汉语这些都是将新方法运用于分词系统的成功尝试具有很大的理论意义随后比较有代表性的有清华大学seg和segtag分词系统复旦分词系统州大学改进的mm分词系统北大计算语言所分词系统分词和词类标注相结合在自然语言处理技术中中文处理技术比西文处理技术要落后很大一段距离文不能直接采用就是因为中文必需有分词这道工序汉语分词是其他中文信息处理是汉语分词的一个应用语音合成自动分类自动摘要要用到分词因为中文需要分词可能会影响一些研究但同时也为一些企业带来机会参考文献汉语信息处理词汇01部分朱德熙
《现代汉语语法教程》-陆俭明(自用读书笔记)

第一章词类研究词类是指词的语法分类。
所谓“词的语法分类”,是说语法研究中的词类是词按照其各自语法功能的不同而分出来的类别。
对于划分词类,前人曾提出过三种依据:词的形态,词的语法意义,词的语法功能。
但就划分汉语词类来说,最佳的依据是词的语法功能。
如果按照词的形态来进行词的语法分类,适用于印欧语系那样有形态标志和形态变化的语言,但不适合于汉语,因为汉语没有严格意义的形态标志和形态变化。
如果根据词的语法意义来划分,词的意义优两种,一种是概念义(认知义),一种是语法意义(语法范畴义),理论上来说是可行的,但是语法意义层面太多,极为复杂,具体划分起来难易操作(如“事物”与“什么”指的事物,外延很大。
)所以,从现实来说,还是需要根据词的语法功能来划分词类:(1)吕叔湘先生说过“区分词类,是为的讲语法的方便、为了讲语句组织。
”陈望道先生也曾指出“划分词类就是‘为了研究语文的组织,为了把文法体系化,为了找出语文组织跟词类的经常而确切的联系来。
’”是的,划分词类确实就是为了研究语法、讲解语法,如“小王吃苹果”体现了“名词+动词+名词”这种词类序列。
(2)从词的二维关系来看,组合关系/配置关系(横向)和聚合关系/会同关系(纵向),词类确实是按照词在句法结构中起的作用(即词的语法功能)所分出来的类。
(3)依据词的形态分类,实质上就是依据词的语法功能分类。
英语中加后缀s表复数,虽然形态变化,但是在句子里的语法功能是一致的,同时也有单复同形的词语,虽然没有形态变化但功能依旧一样。
我们能根据形态划分词类,是因为形态反映了功能。
形态不过是功能的标志(朱德熙)。
词的语法功能是词的语法意义的一种外在表现,而词的形态又是词的语法功能的外在表现形式。
划分依据:①词充当句法成分的功能,如作主语、谓语等;②词跟词结合的功能,如前加“不、很”或后带“了、着”等;③词所具有的表示类别作用的功能,实际就是词的语法意义,如计数功能、指代功能、连接功能等。
中文分词与词性标注技术研究与应用

中文分词与词性标注技术研究与应用中文分词和词性标注是自然语言处理中常用的技术方法,它们对于理解和处理中文文本具有重要的作用。
本文将对中文分词和词性标注的技术原理、研究进展以及在实际应用中的应用场景进行综述。
一、中文分词技术研究与应用中文分词是将连续的中文文本切割成具有一定语义的词语序列的过程。
中文具有词汇没有明确的边界,因此分词是中文自然语言处理的基础工作。
中文分词技术主要有基于规则的方法、基于词典的方法和基于机器学习的方法。
1.基于规则的方法基于规则的中文分词方法是根据语法规则和语言学知识设计规则,进行分词操作。
例如,按照《现代汉语词典》等标准词典进行分词,但这种方法无法处理新词、歧义和未登录词的问题,因此应用受到一定的限制。
2.基于词典的方法基于词典的中文分词方法是利用已有的大规模词典进行切分,通过查找词典中的词语来确定分词的边界。
这种方法可以处理新词的问题,但对未登录词的处理能力有所限制。
3.基于机器学习的方法基于机器学习的中文分词方法是利用机器学习算法来自动学习分词模型,将分词任务转化为一个分类问题。
常用的机器学习算法有最大熵模型、条件随机场和神经网络等。
这种方法具有较好的泛化能力,能够处理未登录词和歧义问题。
中文分词技术在很多自然语言处理任务中都起到了重要的作用。
例如,在机器翻译中,分词可以提高对齐和翻译的质量;在文本挖掘中,分词可以提取关键词和构建文本特征;在信息检索中,分词可以改善检索效果。
二、词性标注技术研究与应用词性标注是给分好词的文本中的每个词语确定一个词性的过程。
中文的词性标注涉及到名词、动词、形容词、副词等多个词性类别。
词性标注的目标是为后续的自然语言处理任务提供更精确的上下文信息。
1.基于规则的方法基于规则的词性标注方法是根据语法规则和语境信息,确定每个词语的词性。
例如,根据词语周围的上下文信息和词语的词义来判断词性。
这种方法需要大量的人工制定规则,并且对于新词的处理能力较差。
现代汉语语料库加工规范词语切分和词性标注词...
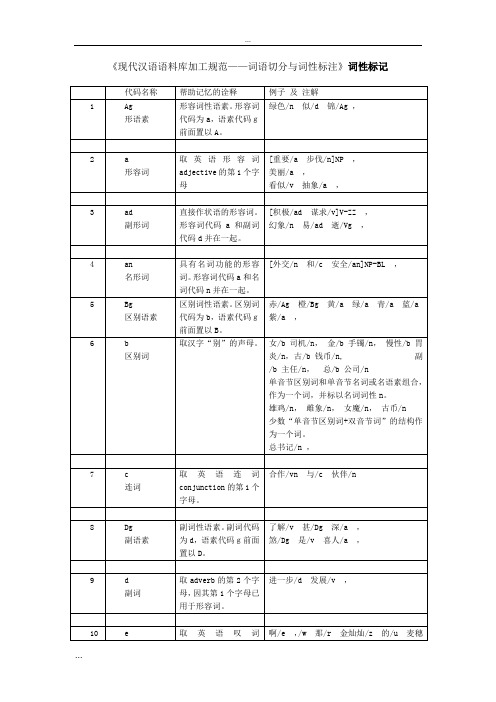
[芜湖/ns专区/n] NS,
[宣城/ns地区/n]ns,
[内蒙古/ns自治区/n]NS,
[深圳/ns特区/n]NS,
[厦门/ns经济/n特区/n]NS,
[香港/ns特别/a行政区/n]NS,
甲/Mg减下/v的/u人/n让/v乙/Mg背上/v ,
凡/d“/w寅/Mg年/n”/w中/f出生/v的/u人/n生肖/n都/d属/v虎/n ,
18
m数词
取英语numeral的第3个字母,n,u已有他用。
1.数量词组应切分为数词和量词。三/m个/q, 10/m公斤/q,一/m盒/q点心/n ,
但少数数量词已是词典的登录单位,则不再切分。
合作/vn与/c伙伴/n
8
Dg
副语素
副词性语素。副词代码为d,语素代码g前面置以D。
了解/v甚/Dg深/a,
煞/Dg是/v喜人/a,
9
d
副词
取adverb的第2个字母,因其第1个字母已用于形容词。
进一步/d发展/v,
10
e
叹词
取英语叹词exclamation的第1个字母。
啊/e,/w那/r金灿灿/z的/u麦穗/n,
约/d一百/m多/m万/m,仅/d一百/m个/q,四十/m来/m个/q,二十/m余/m只/q,十几/m个/q,三十/m左右/m,
两个数词相连的及“成百”、“上千”等则不予切分。
五六/m年/q,七八/m天/q,十七八/m岁/q,成百/m学生/n,上千/m人/n,
4.表序关系的“数+名”结构,应予切分。
[宝山/ns钢铁/n总/b公司/n]NT,(/w宝钢/j)/w
现代汉语词汇研究总结

第一章词和词汇第一节什么是词第一节主要是讲什么是词。
对词的定义:词是最小的有相对固定的语音形式和适度词长的能独立运用的语音单位。
第二节是讲词的离散性问题,最早提出这个问题的是前苏联学者彼施考夫斯基,之后就是斯米尔尼兹基。
第二部分是关于如何区分词和语素。
语素,一般定义为语言中最小的音义结合体,是构词的材料。
关于词和语素的区别,国内学者普遍接受的观点是词是可以在语言片段中单独出现或独立运用的一种语言单位词在句子层面具有离散性;而语素则不能独立运用于语言片段中,语素的离散性是属于词汇层面——发生在词的内部,而不是句子层面的。
第三部分是如何区分词和短语。
词一般具有结构的完整定型性、意义的整体性、不可扩展性以及适度的词长等特征,而短语则一般不具街这些特征。
关于不可扩展性,陆志韦先生提出了“扩展法”但并非万能的。
第三节词位和词位变体一,词位的含义:一个词项可以是一个间,也可以是两个或两个以上的词,而其中“等于一个词的词项叫词位。
如“成语就是一种特殊的词位”,“等于两个或两个以上词的词项”则叫“超词位,如“打长工”。
词位”实际上是同一个词的具体表现形式,“它表明了是一个可能包含有不同变异状态的、统合的单位。
”二、讲词位变体。
关于词位变体有四种情形:1.词的语音形式的变异会形成词位变体。
其中一种变异是由异读引起的,如:露[lòu] ——露[lù] 结[jiē]——结[jié];另一种变异是由变调引起的:不(bú)——不bù。
有些词的语音形式发生变异后,词义也随之发生了变化,这就形成了不同词位的词位,而非间位变体。
如:倒[dǎo]——倒[dào]。
还有儿化现象,如:唱片一唱片儿,中间一中间儿2.。
词的书写形式的变异也会形成变体。
如:绝招一绝着,龟裂一皲裂。
3. 词的语法形式的变异也会形成词位变体。
有些同伴随语法意义的变化的还有词的语音形式、词汇意义的变化,如:1.好[hǎo]2.好[hào]。
国家语委现代汉语语料库介绍
应用文 难于归类的语料
人文与社会科学类
人文与社会科学类划分为8个大类和30个小类:
政法:哲学、政治、宗教、法律; 历史:历史、考古、民族; 社会:社会学、心理、语言文字、教育、文艺理论、新闻、
民俗; 经济:工业经济、农业经济、政治经济、财贸经济; 艺术:音乐、美术、舞蹈、戏剧; 文学:小说、散文、传记、报告文学、科幻、口语; 军体:军事、体育; 生活。
章程法规:章程、条例、细则、制度、公约、办法、法律条 文等;
司法文书:诉讼、辩护词、控告信、委托书等; 商业文告:说明、广告、调查报告、经济合同等; 礼仪辞令:欢迎词、贺电、讣告、唁电、慰问信、祝酒词等; 实用文书:请假条、检讨、申请书、请愿书等。
综合类约占语料总量的20%
样例 语料分类
信息处理用现代汉语词类标记集规范
基本词类体系 基本词类体系的标记代码 《规范》的制定
在国家社科基金“九五”重大项目《信息处理用现代汉语词汇研 究》的子项目“信息处理用现代汉语词类标记集规范的基础上完 成
得到国家语委“九五”重大项目《现代汉语语料库建设》子课题 “国家语委核心语料分词及词性标注加工”的支持。
样例 语料库查询统计工具
样例 句法树库的信息检索
样例 基于互联网的语料库例句检索
样例 语料库全文检索
语料库的管理
国家语委语料库由国家语委委托语言文字应用 研究所负责建设和管理
国家语委语料库可以提供的服务
语料库使用权许可 检索、查询、统计等数据服务 软件开发等其他服务
语料库提供服务的方式
语料库选材
人文与社会科学类
以1919年为上限,选取五四以来的语言材料。 对五四以来各个历史时期的语料采取不等密度选用的方式。
现代汉语二分法
现代汉语二分法
现代汉语二分法(也称二元切分法),是一种常见的自然语言处
理技术。
其基本思想是将一个汉字组成的串按照两个汉字一组进行划分,从而得到一系列的“词语”。
这些“词语”是由连续的汉字组成的,可以代表一些常见的实际对象、抽象概念、动作行为等,具有一
定的语义意义。
具体而言,二分法会依次对输入文本的每一对相邻汉字进行匹配,判断它们是否可以构成一个常见的“词语”。
如果可以,则将这个
“词语”加入到分词结果中,并从新的位置重新开始寻找下一个“词语”。
如果不能,则将第一个汉字作为单独的词语加入到分词结果中,并从下一个位置重新开始匹配。
这样一直重复,直到所有的汉字都被
扫描过,得到完整的分词结果。
二分法算法简单、效率高,因此在汉语分词中广泛应用。
但是,
由于有些词语并不符合常见的组合方式,二分法分词结果可能存在一
定的局限性和错误率,需要结合其他技术进行优化和修正。
现代汉语语法研究 第二节 层次分析法
1 辅层音次的分发析音法
3.切分所得的各个直接组成成分,它们在意义上的组合必须
跟原结构的意义相等。
1
a.我 最好的朋友
b.我 最好的 朋友
原:最好的是说明“朋友” 今:最好的是说明“我”
1 辅层音次的分发析音法
2. 6 层次分析法的作用
1.可分析复句
1
①掌柜是一副凶脸孔,②主顾也没有好声气,③教人活泼不得;
1 34
2 1-2定中 3-4定中
1
2 34
1-2定中
3-4定中
五、每一个层面切分所得到的直接组成成分,彼此按句法规则组
合起来,在意义上必须跟原先的整个结构所表示的意思相一致。
1
1.切分所得的各个直接组成成分,都必须有意义
a.年轻的 一代 b.年轻 的一代
2.切分所得的各个直接组成成分,彼此在意义上有搭配的可能
a.一片 好风光 b.一片好 风光
一片好(主谓关系)在意义上不能和“风光”搭配
画线法:由小到大
画线法:由大到小
他刚 来
他刚来
1 2
或1
2
3
4
树结构 他刚 来
1他
2 刚来
1“状-中”偏正关系 1-2主谓关系
2主谓关系
3-4“状-中”偏正关系
3 刚 4来 1-2主谓关系 3-4“状-中”偏正关系
1 辅层音次的分发析音法
层次分析的基本精神 1.承认句子或句法结构在构造上有层次性,在句子中严格按照其内
1 部的构造层次进行层层分析 2.每一次分析,都要明确说出每一个构造层面的直接组成部分
他刚来 第一层次(刚来):状中-偏正关系 第二层次(他与“刚来”):主谓关系
1 辅层音次的分发析音法
(整理)现代汉语语料库加工规范词语切分与词性标注词
出/v过/u两/m天/q差/Ng,
疾病成本法和人力资本法将环境污染引起人体健康的经济损失分为直接经济损失和间接经济损失两部分。直接经济损失有:预防和医疗费用、死亡丧葬费;间接经济损失有:影响劳动工时造成的损失(包括病人和非医务人员护理、陪住费)。这种方法一般通常用在对环境有明显毒害作用的特大型项目。理/v了/u一/m次/q发/Ng,
一个/m ,一些/m ,
2.基数、序数、小数、分数、百分数一律不予切分,为一个切分单位,标注为m。
一百二十三/m,20万/m,123.54/m,一个/m,第一/m,第三十五/m,20%/m,三分之二/m,千分之三十/m,几十/m人/n,十几万/m元/q,第一百零一/m个/q ,
3.约数,前加副词、形容词或后加“来、多、左右”等助数词的应予分开。
岗位/n ,城市/n ,机会/n ,
[例题-2006年真题]下列关于建设项目环境影响评价实行分类管理的表述,正确的是( )她/r是/v责任/n编辑/n ,
(编辑/v科技/n文献/n )
21
nr人名
名词代码n和“人(ren)”的声母并在一起。
1.汉族人及与汉族起名方式相同的非汉族人的姓和名单独切分,并分别标注为nr。
张/nr仁伟/nr,欧阳/nr修/nr,阮/nr志雄/nr,朴/nr贞爱/nr
汉族人除有单姓和复姓外,还有双姓,即有的女子出嫁后,在原来的姓上加上丈夫的姓。如:陈方安生。这种情况切分、标注为:陈/nr方/nr安生/nr;唐姜氏,切分、标注为:唐/nr姜氏/nr。
2.姓名后的职务、职称或称呼要分开。
江/nr主席/n,小平/nr同志/n,江/nr总书记/n,张/nr教授/n,王/nr部长/n,陈/nr老总/n,李/nr大娘/n,刘/nr阿姨/n,龙/nr姑姑/n
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
中文人名识别
在汉语的未登录词中,中国人名是规律 性最强,也是最容易识别的一类;
中国人名一般由以下部分组合而成:
–姓:张、王、李、刘、诸葛、西门 –名:李素丽,王杰、诸葛亮 –前缀:老王,小李 –后缀:王老,赵总
中国人名各组成部分用字比较有规律
中文人名识别
根据统计, 汉语姓氏大约有1000多个, 姓氏中使 用频度最高的是“王”姓, “王, 陈, 李, 张, 刘”等5 个大姓覆盖率达32%, 姓氏频度表中的前14个高 频度的姓氏覆盖率为50%, 前400个姓氏覆盖率 达99%。人名的用字也比较集中。频度最高的 前6个字覆盖率达10.35%, 前10个字的覆盖率达 14.936%, 前15个字的覆盖率达19.695%, 前400 个字的覆盖率达90%
中文人名识别
中国人名的组合规律 –姓(1)+名(2) –姓(1)+名(1) –姓(2)+名(2) –姓(2)+名(1)
中文人名识别
一个识别模型
word name name 1-hanzifamily 2-hanzigiven name 1-hanzifamily 1-hanzigiven name 2-hanzifamily 2-hanzigiven name 2-hanzifamily 1-hanzigiven 1-hanzifamily hanzii 2-hanzifamily hanzii hanzij 1-hanzigiven hanzii 2-hanzigiven hanzii hanzij
英语中的切分问题
英语中不是完全没有切分问题,不能仅仅凭 借空格和标点符号解决切分问题。
1.
缩写词 如:
N.A.T.O. i.e. m.p.h Mr. AT&T
2.
连写形式以及所有格词尾
I’m He’d don’t Tom’s
3.
数字、日期、编号
128,236 +32.56 –40.23 02/02/94 02-02-94 D-4 T-1-A B.1.2
歧义消解
基于统计的歧义消解
在词图上寻找统计意义上的最佳路径 统计词表中每个词的词频,并将其转换为路 径代价
C = - log(f/N)
切分路径的代价为路径上所有词的代价之和 寻求代价最小的路径
未登录词识别
中国人名:李素丽 老张 李四 王二麻子 中国地名:定福庄 白沟 三义庙 韩村河 马甸 翻译人名:乔治·布什 叶利钦 包法利夫人 酒井法子 翻译地名:阿尔卑斯山 新奥尔良 约克郡 机构名:方正公司 联想集团 国际卫生组织 外贸部 商标字号:非常可乐 乐凯 波导 杉杉 同仁堂 专业术语:万维网 主机板 模态逻辑 贝叶斯算法 缩略语:三个代表 五讲四美 打假 扫黄打非 计生办 新词语:卡拉OK 波波族 美刀 港刀
未登录词识别
未登录词识别困难
未登录词没有明确边界 许多未登录词的构成单元本身都可以独立成词
每一类未登录词都要构造专门的识别算法 识别依据
–内部构成规律(用字规律) –外部环境(上下文)
未登录词识别
未登录词识别进展
较成熟
–中国人名、译名 –中国地名
较困难
–商标字号 –机构名
很困难
–专业术语 –缩略语 –新词语
1. 2.
正向最大匹配法(MM) 逆向最大匹配法配法
正向最大匹配法 从左向右匹配词典 逆向最大匹配法 从右向左匹配词典 例子
输入:企业要真正具有用工的自主权 MM:企业/要/真正/具有/用工/的/自主/权 RMM:企业/要/真正/具有/用工/的/自/主权
最大匹配法
[1]刘挺、王开铸,1998,关于歧义字段切分的思考与实验。《中文信息学报》 [1]刘挺、王开铸,1998,关于歧义字段切分的思考与实验。《中文信息学报》 第2期,63-64页。 第2期,63-64页。
切分歧义
交集型歧义的链长
交集型歧义字段中含有交集字段的个数,称为链长。 从小学 链长是1 结合成分 链长是2 为人民工作 链长是3 中国产品质量 链长是4 部分居民生活水平 链长是6 治理解放大道路面积水 链长是7
多种切分形式均匀分布 12% 应用于 将信息技术/应用/于/教学实践 信息技术/应/用于/教学中的哪个方面
一种切分形式占优 88%
解除了 上级/解除/了/他的职务 (大多数) 方程的/解/除了/零以外还有…
[1] 中文文本自动分词和标注,刘开瑛著,商务印书馆,2000,66~67 [1] 中文文本自动分词和标注,刘开瑛著,商务印书馆,2000,66~67
歧义的发现
MM+逆向最小匹配法 全切分算法
依据词表,给出输入文本的所有可能的切分结果 效率低于MM法 可以检测到所有的歧义现象 输入: 提高人民生活水平 输出: 提/高/人/民/生/活/水/平 提高/人/民/生/活/水/平 提高/人民/生/活/水/平 提高/人民/生活/水/平 提高/人民/生活/水平 ……
[1]孙茂松、左正平等,1999, 高频最大交集型歧义切分字段在汉语自动分词 [1]孙茂松、左正平等,1999, 高频最大交集型歧义切分字段在汉语自动分词 中的作用。《中文信息学报》第1期,27-34页。 中的作用。《中文信息学报》第1期,27-34页。
歧义消解
基于规则的歧义消解
P[+R+M+Q+A|Z]+”马上” 马+上 他从大红/马/上/下来 这件事需要/马上/办 “一起”+~V 一+起 我们/一起/去故宫 一/起/恶性交通事故
歧义的分类
2. 伪歧义
歧义字段单独拿出来看有歧义,但在(所有)真实 语境中仅有一种切分形式可接受。 挨批评 挨/批评(√) 挨批/评(×) 学生/挨/批评/挥拳打老师 平淡 平淡(√) 平/淡(×) 平淡/生活感动人
歧义的分类
根据文献[1],对于交集型歧义字段,真实文本中伪歧 义现象远远多于真歧义现象。 伪歧义 94% 真歧义 6%
歧义的发现
歧义消解的前提是发现歧义。切分算法应该有 能力检测到输入文本中何时出现了歧义切分现 象。 MM和RMM法均没有检测歧义的能力。
只能给出一种切分结果。
最短路径法
选择词数最少的切分结果 没有歧义检测能力,尤其组合歧义
歧义的发现
双向最大匹配(MM+RMM) 同时采用MM法和RMM法 若果MM法和RMM法给出同样的结果,则认 为没有歧义,若不同,则认为发生了歧义。 输入:企业要真正具有用工的自主权 MM:企业/要/真正/具有/用工/的/自主/权 RMM:企业/要/真正/具有/用工/的/自/主权
F-评价(F-measure 综合准确率和召回率的评价指标)
F-指标=2PR/(P+R)
关键问题
切分歧义(消解)
一个字串有不止一种切分结果
未登录词识别
专有名词 新词
切分歧义
1. 交集型歧义
字串AJB中,若AJ∈D、JB∈D、A∈D、B∈D , 则AJB为交集型歧义字段。此时,AJB有AJ/B、 A/JB两种切分形式。其中J为交集字段。 从小学 从小/学/电脑 从/小学/毕业 组合型歧义 字串AB中,若AB ∈D、 A ∈D、 B ∈D,则AB为 组合型歧义字段。此时,AB有AB、A/B两种切分 形式。 中将
为什么要进行汉语的切分研究
2.
信息检索
切分有助于提高信息检索的准确率,如: a.和服务于三日后裁制完毕,并呈送将军府中。 b.王府饭店的设施和服务是一流的。
3.
词语的计量分析
词频统计 (汉语中最常用的词是哪个词?)
4.
… 句法分析、语义分析等
汉语切词也是深层汉语分析的基础
基本方法
最大匹配法(MM)
统计数据[1]
文本中90%左右的句子,MM和RMM结果相同且 正确。 文本中1%左右的句子,MM和RMM结果相同且 不正确。 文本中9%左右的句子, MM和RMM结果不相同 (其中一个正确或两者均不正确)(检测到歧义)
双向最大匹配法使用较为广泛的原因。
[1] Sun,M.S.and Benjamin K. T. 1995. Ambiguity resolution in Chinese word [1] Sun,M.S.and Benjamin K. T. 1995. Ambiguity resolution in Chinese word segmentation. Proceedings of the 10th Asia Conference on Language,Information segmentation. Proceedings of the 10th Asia Conference on Language,Information and Computation, 121 -126.Hong Kong. and Computation, 121 -126.Hong Kong.
现代汉语词语切分研究
常宝宝 北京大学计算语言学研究所 chbb@
什么是汉语自动切分?
通过计算机把组成汉语文本的字串自动转换为 词串的过程被称为自动切分(segmentation)。
例子:
鱼在长江中游 鱼/在/长江/中/游
汉语和英语等印欧语不同,词和词之间没有空 格。
例子:
I’m going to show up at the ACL
评测
国内863、973 国际SIGHAN
什么是词?
词是由语素构成的、能够独立运用的最 小的语言单位。 词就是说话的时侯表示思想中一个观念 的词。 缺乏操作标准。 汉语中语素、词和词组的界线模糊。
什么是词?
长词优先
输入:他将来中国 MM:他/将来/中国 RMM:他/将来/中国 正确:他/将/来/中国
算法非常简单
自动切分的评价
准确率(precision)
准确率(P)=切分结果中正确分词数/切分结果中 所有分词数*100%