第六章 异方差与序列相关2
异方差检验与序列相关

ˆ t 2 = α0 +α1 xt1 +α2 xt2 + α3 xt12 +α4 xt22 + α5 xt1 xt2 + vt u ˆ t 2 对原回归式中的各解释变量、解释变量的平方项、交叉积项进行 OLS 回归。注意,上 即用 u
人均消费 支出 Y 3552.1 2050.9 1429.8 1221.6 1554.6 1786.3 1661.7 1604.5 4753.2 2374.7 3479.2 1412.4 2503.1 1720 1905 1375.6 1649.2 1990.3 2703.36 1550.62 1357.43 1475.16 1497.52 1098.39 1336.25 1123.71 1331.03 1127.37 1330.45 1388.79 1350.23 从事农业经营 的收入 X1 579.1 1314.6 928.8 609.8 1492.8 1254.3 1634.6 1684.1 652.5 1177.6 985.8 1013.1 1053 1027.8 1293 1083.8 1352 908.2 1242.9 1068.8 1386.7 883.2 919.3 764 889.4 589.6 614.8 621.6 803.8 859.6 1300.1 其他收入 X2 4446.4 2633.1 1674.8 1346.2 480.5 1303.6 547.6 596.2 5218.4 2607.2 3596.6 1006.9 2327.7 1203.8 1511.6 1014.1 1000.1 1391.3 2526.9 875.6 839.8 1088 1067.7 647.8 644.3 814.4 876 887 753.5 963.4 410.3
第六章 自相关性

接前页
3、降低预测精度
由于参数估计值方差虚假增大,致使预测区间的 可信程度降低,预测结果将失去实际意义。
6.3自相关性检验方法
从上述内容的介绍我们可以发现,自相关对模型产生的 不良后果是比较严重的,因此,必须采取相应措施加以 修正或克服。但在修正或克服之前,应该对模型误差项 序列是否存在自相关进行判断,即自相关检验。其方 法主要有:
6.2自相关产生的后果
1、参数估计值非有效(即不再具有最小方差性) 根据前面学过的内容,我们知道,只有在符合同 方差和非自相关性假定条件下,OLS估计结果才 具有最小方差性。当模型存在自相关,参数估计 值方差不是最小(即估计结果不是最优)。
2、模型的显著检验(T检验)失效
标准差增大,导致t统计量变小,进而低估了参数
第二步,对原数据进行广义差分变换,得:
yt*= yt- ρ Yt-1 , xt*= xt- ρ xt-1,再对模型 yt*=A+b1 xt*+ vt*进行回归,并根据回归结果得到原模型 参数估计值b0= A/ (1- ρ ^)和b1
总结说明
迭代法: 是采用一系列迭代,而每一次迭代都 能得到比前一次更好的一阶自回归 系数ρ ^ 杜宾两步法: 也是获得比较准确的一阶自回归系数ρ ^的方法
t
关来判断随机项的自相关。
1、按时间顺序绘制残差分布图:
1.1 正自相关:残差e随时间t的变化并不频繁改变符号,而是几个正的 后面有几个负的。
e
O t
正自相关
接前页
1.2 负自相关:e随t变化依次改变正负符号
计量经济学第六章自相关

计量经济学第六章自相关自相关是计量经济学中一种重要的现象,它指的是一个变量与其自己在过去时间点上的相关性。
自相关在实证研究中十分常见,对经济学家来说,了解和掌握自相关性质是至关重要的。
1. 引言自相关作为计量经济学的一项基础概念,是经济学研究中不可或缺的一个重要方法。
自相关性的存在通常会引起回归结果的偏误,而忽略自相关性可能导致估计不准确的结果。
因此,探讨自相关性的性质和应对方法是计量经济学的重点之一。
2. 自相关的定义和表示自相关是指一个变量与其自身在过去时间点上的相关性。
假设我们有一个时间序列数据集,其中变量yt表示一个时间点上的观测值,t表示时间索引。
自相关系数可以通过计算观测值yt与其在过去某一时间点上的观测值yt-k(k为时间滞后期数)的相关性来得到。
数学上,自相关系数可以用公式表示为:ρ(k) = Cov(yt, yt-k) / (σ(yt) * σ(yt-k))其中,ρ(k)表示第k期的自相关系数,Cov表示协方差,σ表示标准差。
3. 自相关性的性质自相关性具有以下几个性质:3.1 一阶自相关性一阶自相关性是指变量值yt与前一期的观测值yt-1之间的相关性。
一阶自相关系数ρ(1)通常用来检验时间序列数据是否存在自相关性。
若ρ(1)大于零且显著,则表明存在正的一阶自相关性;若ρ(1)小于零且显著,则表明存在负的一阶自相关性。
3.2 高阶自相关性除了一阶自相关性,时间序列数据还可能存在高阶自相关性。
高阶自相关性是指变量值yt与过去第k期的观测值yt-k之间的相关性。
通过计算不同滞后期的自相关系数ρ(k),可以了解数据在不同时间跨度上的自相关性情况。
3.3 异方差自相关性异方差自相关性是指时间序列数据中的方差不仅与自身相关,还与过去观测值的相关性有关。
异方差自相关性可能导致在回归分析中的标准误差失效,从而产生无效的回归结果。
因此,在处理存在异方差自相关性的数据时要采取合适的修正方法。
4. 自相关性的检验方法在实证研究中,经济学家通常使用多种方法来检验数据中的自相关性,常用的方法包括:4.1 Durbin-Watson检验Durbin-Watson检验是一种常用的检验自相关性的方法,其基本思想是通过检验误差项的相关性来判断自相关是否存在。
第6章 序列相关和异方差性

6.1.2异方差的检验
• 3.White Test
6.2序列相关性
• 当不同时刻的误差相关时,则误差项是 序列相关.不仅在时间序列,而且在截 面数据研究中也会发生. • 主要讨论一阶序列相关问题:一个时刻 的误差直接与下个时刻的误差相关. • 正相关与相关 • 影响:
6.1.2异方差的检验
• 异方差的非正式检验方式是对残差进行观察,看 看残差是否随观测值而变. • 1.Goldfeld-Guandt Test:假设考虑一元回归模 型. • 思想:对两个回归直线方程进行估计,看这两 个回归直线残差的方差是否相等. • 步骤: • 例6.2
6.1.2异方差的检验
*
Y X X 1 变换为: i 1 2 3 3i k ki i* X 2i X 2i X 2i X 2i 1 Var( ) Var( ) 2 Var( i ) C X 2i X 2i
* i
i
6.1.1异方差的修正
3.使用方差的一致估计 第10章进行详细讨论
第6章 序列相关和异方差性
• 6.1异方差性 • 6.2序列相关性
6.1异方差性
• 误差项同方差假设同现实不符. • 例如:企业的销售额,家庭的收入和支出. • 如果误差项服从异方差的分布,那么OLS估计将会给误差方差大的观测 值以较大的权重.所以,OLS估计量虽然是无偏和一致的,但是它们不再 是有效的. • OLS估计的无偏性可以通过一元回归模型证明. • 当存在异方差时,正确的方差公式
*
Yi
* ji
X ji
* i
* 变换后为:Yi * 1 2 X 1*i k X ki i*
异方差、序列相关性、多重共线性的比较

(2)对多个解释变量模型,采用综合统计检验法
2判明存在多重共线性的范围
(1)判定系数检验法:构造辅助回归模型(Auxiliary Regression)并计算相应的拟合优度
(2)排除变量法(Stepwise Backward Regression )
(3)逐步回归法(Stepwise forward Regression)
后果
(Consequences)
1.参数估计量非有效(但,是线性的、无偏的)
2.变量的显著性检验失去意义(t检验、F检验)
3.模型的预测失效(对Y的预测误差变大,降低预测精度)
与异方差性引起的后果相同:
1.参数估计量非有效
2.变量的显著性检验失去意义
3.模型的预测失效
1.完全共线性下参数估计量不存在
异方差、序列相关性、多重共线性的比较( )
异方差(Heteroskedasticity)
(截面数据:Cross Sectional Data)
序列相关性(SerialCorrelation)
(时间序列数据:Time Series Data)
多重共线性(Multicollinearity)
(时间序列数据:Time Series Data)
,(X’X)-1不存在
2.近似共线性下OLS估计量非有效(估计方差变大)
(1)参数估计量经济含义不合理(变现似乎反常的现象)
(2)变量的显著性检验失去意义(t变小,R2变大,F变大)
(3)模型的预测功能失效(方差变大使预测“区间”变大)
检验
(Test)
1.图示法(散点图)
2.帕克检验(ParkTest)
3.第三类方法:减小参数估计量的方差
第六章 自相关性
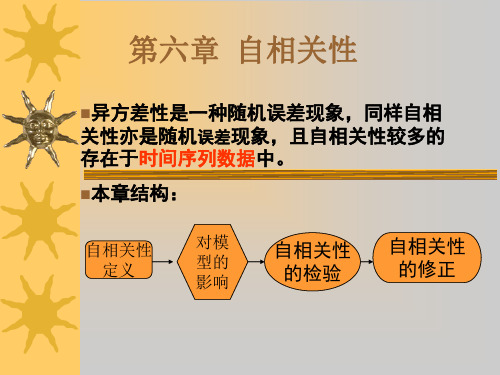
进一步,如果
ut ut 1 t
其中
1,t满足E(t ) 0,Var(t )
2
,
cov(t , s ) 0, (t s)
则称ut是一阶线性自相关。
二、自相关性产生的原因
1、经济变量惯性的作用 2、经济行为的滞后性 3、一些随机偶然因素的干扰或影响 4、模型设定的偏误 5、蛛网现象模型
例如:“真实”的边际成本与产量之间的函数关
系式应为:
Yt
1
2 X t
3 X
2 t
ut
其中Yt表示边际成本,X t表示产量,由于认识上的偏
误可能建立如下模型: Yt 1 2 X t vt
其中vt
3
X
2 t
ut,这时由于vt中包含了带有X
2对边
t
际成本的系统影响,使得vt很有可能出现自相关性。
3、一些随机偶然因素的干扰或影响 通常偶然因素是指战争、自然灾害、政策制定
的错误后果、面对一些现象人们的心理因素等等, 这些因素可能影响若干时期,反映在模型中很容 易形成随机误差序列的自相关。
4、设定偏误:
所谓设定偏误是指所建模型“不真实”或“不正 确”。引起设定偏误的主要原因有:模型函数的形式 不正确或遗漏了主要变量。
1、经济变量惯性的作用 大多数经济时间数据都有一个明显的特点,就是
它的惯性,表现在时间序列数据不同时间的前后关联 上。
例如,绝对收入假设下居民总消费函数模型:
Ct=0+1Yt+t
t=1,2,…,n
由于消费习惯的影响被包含在随机误差项中, 则可能出现序列相关性(往往是正相关 )。
第五讲-多重共线性、异方差、自相关

表 4.3.3 中国粮食生产与相关投入资料
农业化肥施 粮食播种面 受灾面积 农业机械总
用量 X 1
(万公斤)
积X 2
(千公顷)
X3
(公顷)
动力X 4
(万千瓦)
1659.8
114047 16209.3
18022
1739.8
11288பைடு நூலகம் 15264.0
19497
1775.8
108845 22705.3
20913
0.9752 1.53
t值
0.85
19.6 3.35 -3.57
Y=f(X1,X2,X3,X4) -13056 6.17 0.42 -0.17 -0.09
0.9775 1.80
t值
-0.97 9.61 3.57 -3.09 -1.55
Y=f(X1,X3,X4,X5) -12690 5.22 0.40 -0.20
含义:解释变量的样本向量近似线性相关。
多重共线性来源:
(1)解释变量x受到同一个因素的影响; 例如:政治事件对很多变量都产生影响,这些变量同时上升 或同时下降。
(2)解释变量x自己的当期和滞后期;
(3)错误设定。
二、多重共线性的后果
1、完全共线性下参数估计量不存在
Y X
的OLS估计量为: βˆ (XX) 1 XY
1、检验多重共线性是否存在
(1)对两个解释变量的模型,采用简单相关系数法 求出X1与X2的简单相关系数r,若|r|接近1,则说
明两变量存在较强的多重共线性。
(2)对多个解释变量的模型,采用综合统计检验法
若 在OLS法下:R2与F值较大,但t检验值较小, 说明各解释变量对Y的联合线性作用显著,但各解 释变量间存在共线性而使得它们对Y的独立作用不 能分辨,故t检验不显著。
计量第六章习题

自相关性一、单项选择题1、如果模型t t t u X b b Y ++=10存在序列相关,则【 】A cov (t x ,t u )=0B cov (t u ,s u )=0(ts )C cov (t x ,t u )0D cov (t u ,s u )0(ts ) 2、DW 检验的零假设是(为随机项的一阶自相关系数)【 】A DW=0B =0C DW=1D =13、下列哪种形式的序列相关可用DW 统计量来检验(i v 为具有零均值,常数方差,且不存在序列相关的随机变量)【 】A t t t v u u +=-1ρB t t t t v u u u +++=--Λ221ρρC t t v u ρ=D Λ++=-12t t t v v u ρρ4、DW 值的取值范围是【 】A -1DW0B -1DW1C -2DW2D 0 DW4 5、当DW =4是时,说明【 】A 不存在序列相关B 不能判断是否存在一阶自相关C 存在完全的正的一阶自相关D 存在完全的负的一阶自相关6、根据20个观测值估计的结果,一元线性回归模型的DW =。
在样本容量n=20,解释变量k=1,显着性水平=时,查得L d =1,U d =,则可以判断【 】A 不存在一阶自相关B 存在正的一阶自相关C 存在负的一阶自相关D 无法确定 7、当模型存在序列相关现象时,适宜的参数估计方法是【 】A 加权最小二乘法B 间接最小二乘法C 广义差分法D 工具变量法 8、对于原模型t t t u X b b Y ++=10,一阶广义差分模型是指【 】A)()()(1)(1t t t t t t t X f u X f X b X f b X f Y ++=B tt t u X b Y ∆+∆=∆1C t t t u X b b Y ∆+∆+=∆10D )()()1(11101----+-+-=-t t t t t t u u X X b b Y Y ρρρρ9、采用一阶差分模型克服一阶线性自相关问题适用于下列哪种情况【 】 A 0 B 1 C -1<<0 D 0<<110、假定某企业的生产决策由模型t t t u P b b S ++=10描述(其中t S 为产量,t P 为价格),如果该企业在t-1期生产过剩,经济人员会削减t 期的产量。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
d ( d ≈ 2(1 − ρ ) ) ,在小样本的情况下,我们有 Theil 修正: 2 d n 2 (1 − ) + k 2 2 ˆ= ρ ,其中 n 为样本容量, k 为回归元的个数。 2 n − k2 ˆ = 1− ρ
4、Hildreth-Lu 方法
确定 ρ 的一组网格值,这些值通常是作为 ρ 的猜测的一些间隔开的值。 第一步,若已知 ρ > 0 ,则可选 ρ 的网格点值为 0, 0.1," , 0.9,1 用每一个网格点值对方程进行广义差分,并进行 OLS 回归。选择具有最
4
3)若 ρ = 1 ,则广义差分变成一阶差分,而一阶差分后的回归方程将没
有截距项,因此在估计除截距项外的参数后,截距项的参数
ˆ =Y −β ˆ X −" − β ˆ X 。 β 1 2 t2 k tk
广义差分法在 ρ 已知时会非常有用,但 ρ 往往是未知的。因此,需 要估计 ρ 。
2、Cochrane-Orcutt 方法
ˆ。 小误差平方和的方程作为最优的方程, 并选定此时的 ρ 值为第一步的 ρ ˆ 的一个邻域内划分新的网格值,并重复第一步的过程,直 第二步,在 ρ
至达到需要的精度为止。 该方法的特点是:
1)可以收敛到 ρ 的 MLE 估计。 2)网格点的选择可以任意间隔,任意细密。
6
若采用模型: Yt = β1 + β 2 X t + μt 。 则 μt 为:X t2 + ε t ,从而扰动项随解释变量的变化而变化,会导致自相关。
1
③忽略了滞后效应 如:在消费支出对收入的时间序列的回归中,人们常常发现当期的消费 支出除了依赖于其他变量外,还依赖于前期的消费支出: 消费t = β1 + β 2收入t + β k 消费t −1 + ε t 如果忽略了模型中的滞后项,所造成的误差项将由于滞后消费对当前消 费的影响而反映出一种系统性模式。从而造成自相关。 4、蜘网现象 许多农产品的供应反映一种蜘网现象。供给对价格的反映要滞后一个时 期,是因为供给需要经过一定的时间才能实现。因此,供给函数是: 供给t = β1 + β 2价格t −1 + ε t 假使时期 t 的期末价格 Pt 低于 Pt −1 ,农民就很可能决定在时期 t + 1 生产比 时期 t 更少的东西。诸如此类的现象,就不能期望扰动项是不相关的,因 此,在存在蜘网现象时,很可能会出现自相关。 5、数据处理不当造成的自相关 例如对数据进行平滑。为了估计季度数据模型,我们可能会将月度数据 进行平均从而得到季度数据。而这种“平滑”可能会使扰动项出现系统 性样式,从而导致自相关。当然数据的内插和外推往往也会造成扰动项 的自相关。 需要注意的是:虽然自相关问题也可能出现在截面数据中,但大多数情 况下,自相关出现在时间序列数据中。 二、自相关的后果
这个方法是一个迭代过程,每一次迭代所产生的 ρ 的估计都比前一 次迭代的 ρ 的估计更好一些。迭代的过程如下: 第一步,用 OLS 对模型 Y = XB + ε 进行估计,对其残差进行如下的回归
ˆt = ρ1ε ˆt −1 + μt 。 分析: ε
第二步, 用估计出来的 ρ1 对 Y , X 进行广义差分得到 Y* 和 X * 。 用 Y* 和 X * 进 行 OLS 估计,将估计量代入原模型,计算新的残差,然后对新的残差进
就可能
低估了真实的最小二乘估计量的方差。
(1)最小二乘估计量仍然是线性的和无偏的。 (2)OLS估计量不再有效。 (3)OLS估计量的方差是有偏的。 (4)通常所用的 t 检验和 F 检验一般来说是不可靠的。 (5)计算得到的误差方差=残差平方和/自由度,是真实 σ 2 的有偏估计量,
它低估了真实的 σ 2 。
ˆ )= Var ( β 2
∑
σ ε2
2 t =1 t n
x
∑ (1 + 2 ρ ∑
n
t = 2 t t −1 n 2 t =1 t
xx x
+ " + 2 ρ n −1
∑
x1 xn x2 t =1 t
n
如果回归元和干 ),
ˆ ∑μ
2 i
ˆ2 = 扰都有正的自相关,不考虑自相关的扰动项方差估计 σ
n−2
ρσ ε2
#
ρ
T −2
σ ε2
" ρ T −1σ ε2 ⎞ ⎟ % # ⎟ σ ε2 ⎟ " ⎠
ρ
#
ρ
T −2
" ρ T −1 ⎞ ⎟ % # ⎟ " 1 ⎟ ⎠
2、序列相关后果
假设误差项呈现如AR(1)的模式,使用O L S法会导致什么后果呢? 以一元回归方程 Yt = β1 + β 2 X t + ε t,ε t = ρε t −1 + μt 为例:
ˆ =ρε ˆ ˆ ˆ 行如下分析: ε t 2 t −1 + μt
第三步,用新估计出来的 ρ 2 对 Y , X 进行广义差分得到新的 Y* 和 X * 。然 后重复前两步的做法。 当进行到第 n 次迭代时, ρ n 和 ρ n −1 的差达到一定的精度要求时,停止迭 代。
3、Durbin 两步法
类似地我们可以得到:
Cov[ε t , ε t − s ] = ρ sσ ε2 , Corr[ε t , ε t − s ] = ρ s = ρ s 。
2
⎛ ε12 ε1ε 2 " ε1ε T ⎞ ⎛ σ ε2 ⎜ ⎟ ⎜ E (εε ') = E ⎜ # # % # ⎟=⎜ # 2 ⎟ ⎜ ε T ε1 ε T ε 2 " ε T ⎜ T −1 2 ⎝ ⎠ ⎝ ρ σε ⎛ 1 2⎜ = σε ⎜ # ⎜ ρ T −1 ⎝
对模型的如下变换:
Yt = β1 + β 2 X 2t + " + β k X kt + ε t
ρYt −1 = ρβ1 + ρβ 2 X 2t −1 + " + ρβ k X kt −1 + ρε t −1
两式相减得:
Yt = β1 (1 − ρ ) + ρYt −1 + β 2 X 2t − ρβ 2 X 2t −1 + " + β k X kt − ρβ k X kt −1 + ε t − ρε t −1
t =2 t =2 t =2
T
T
T
2 t
∑e
t =1
T
2 t
3
当 T 充分大时, ∑ e ≈ ∑ e
t =1 2 t t =2
T
T
2 t −1
≈ ∑ e ,所以 d ≈ 2 − 2 t = 2T
t =2 2 t
T
∑e e ∑e
t =1
T
t t −1 2 t
ˆ ≈ 2 − 2ρ
ˆ 是自相关系数 ρ 的估计。由于 ρ ≤ 1 ,所以 DW ∈ [0, 4] 其中 ρ ˆ 检验判断: d ≈ 2 − 2 ρ
ρ → 0 , d → 2 ,无自相关; ρ → 1 , d → 1 ,正自相关; ρ → −1 , d → 4 ,负自相关;
D-W检验适用条件: 1)检验扰动项一阶自相关 2)解释变量与扰动项不相关 3)无滞后因变量作为解释变量 4)样本容量比较大
4、D-h检验: (模型中有滞后因变量)
Yt = β1 + β 2 X t 2 + " + β K X tK + α1Yt −1 + " + α sYt − s + ε t H0 : ρ = 0 , T ⎛ d⎞ D − h = ⎜1 − ⎟ ˆ1 ) ⎝ 2 ⎠ 1 − T var (α
四、自相关修正
1、 ρ 已知时的广义差分
若 ρ 已知可以通过对因变量和自变量进行广义差分来消除自相关的 影响。具体做法是:
1)对数据进行变换: Yt * = Yt − ρYt −1 , X t* = X t − ρ X t −1 ,t=2,…T。 2)用 Y* 对 X * 进行 OLS 估计,从而得到参数的有效估计。
ˆ 作为 ρ 的一个一致 对新模型进行 OLS 回归,并将 Yt −1 的系数的估计值 ρ ˆ 对原模型进行广义差分,再用 OLS 估计得到原模型参数 估计。然后用 ρ
的有效估计。
Durbin 两步法的优点:可以推广到高阶自回归过程。
5
ˆ 的估计精度较低。 Durbin 两步法的缺点: ρ ˆ 注意:当对 ρ 的估计精度不太高时,可由 Durbin-Waston 统计量来求 ρ
三、自相关的检验
1、图示法
2、Durbin-Waston检验:用于检验扰动项一阶自相关。
检验的假设是:
H 0 : ρ = 0 ,即不存在一阶自相关; H1 : ρ ≠ 0 ,存在一阶自相关。
检验统计量为: d =
∑ (et − et −1 )
t =2
T
∑e
t =1
T
=
Байду номын сангаас
∑ et2 + ∑ et2−1 − 2∑ et et −1
1、AR(1)过程的形式和特点 Yt = X t β + ε t,ε t = ρε t −1 + μt ,
其中 E ( μt ) = 0, E ( μ t2 ) = σ 2 , Cov( μt , μ s ) = 0, t ≠ s, ρ < 1
ε t , μ s 相互独立,当 s > t 时。
2 (1) Var (ε t ) = ρ 2Var (ε t −1 ) + σ μ 。 2 ρσ μ (2) Cov[ε t , ε t −1 ] = E (ε t ε t −1 ) = E[ε t −1 ( ρε t −1 + μt )] = ρVar[ε t −1 ] = , 1− ρ 2