虚拟变量
第七章 虚拟变量

第七章虚拟变量第一节虚拟变量的引入一、什么是虚拟变量前面几章介绍的解释变量都是可以直接度量的,称为定量变量。
如收入、支出、价格、资金等等。
但在现实经济生活中,影响应变量变动的因素,除了这些可以直接获得实际观测数据的定量变量外,还包括一些无法定量的解释变量的影响,如性别、民族、国籍、职业、文化程度、政府经济政策变动等因素,他们只表示某种特征的存在与不存在,所以称为属性变量或定性变量。
属性变量:不能精确计量的说明某种属性或状态的定性变量。
在计量经济模型中,应当包含属性变量对应变量的影响作用。
那怎么才能把定性变量包括在模型中呢?属性变量通常是非数值变量,直接纳入回归方程中进行回归,显然是很困难的。
为此,人们采取了一种构造人工变量的方法,将这些定性变量进行量化,使其能与定量变量一样在回归模型中得以应用。
由于定性变量通常是表明某种特征或属性是否存在,如性别变量中以男性为分析基础的话,那就只有男性、非男性;政策变动变量中以政策不变为基准,则有政策不变,和政策变动;至于有两种以上的状态的话,比如学历分高中,本科,本科以上等等,我们又怎么办呢?把疑问留到后面去解决。
既然定性变量只有存在或不存在两种状态,所以量化的一般方法是取值为0或1。
称为虚拟变量。
虚拟变量:人工构造的取值为0或1的作为属性变量代表的变量。
一般常用D表示。
D=0,表示某种属性或状态不存在D=1,表示某种属性或状态存在比如前面说的性别变量,以男性为基准,则当样本为男性时,虚拟变量取0,当样本为女性时,则虚拟变量取1。
当虚拟变量作为解释变量引入计量经济模型时,对其回归系数的估计和统计检验方法都与定量解释变量相同。
二、虚拟变量的作用1、作为属性因素的代表,如,性别、种族等2、作为某些非精确计量的数量因素的代表,如:受教育程度、年龄段等;3、作为某些偶然因素或政策因素的代表,如战争、911等。
4、时间序列分析中作为季节(月份)的代表(比如对某些明显有淡季、旺季之分的产品)5、分段回归,研究斜率、截距的变动;6、比较两个回归模型;7、虚拟应变量概率模型,应变量本身是定性变量(比如你研究某产品的购买率,应变量本身就是买或不买)三、虚拟变量的设置规则1、虚拟变量D取值为0,还是取值为1,要根据研究的目的决定。
虚拟变量的名词解释

虚拟变量的名词解释在数据分析和统计学中,虚拟变量是一种常用的变量类型。
虚拟变量,也被称为哑变量或指示变量,通常用来表示分类变量的不同水平或类别。
虚拟变量在数据分析中起到了至关重要的作用。
通过将分类变量转化为虚拟变量,我们能够使用数值变量来表示不同的类别,并在统计模型中使用。
这样做的好处是可以将分类变量的影响纳入模型中,而不是简单地将其作为单一的类别。
虚拟变量通常采用二元编码方式来表示分类变量的不同类别。
举个例子,假设我们有一个分类变量是颜色,可能有红、蓝、绿三个类别。
我们可以使用两个虚拟变量来表示这三个类别,比如我们可以设定一个虚拟变量为红色,取值为1表示观测值为红色,取值为0表示观测值不是红色;另外一个虚拟变量设定为蓝色,同样取值为1或0。
这样,对于每个观测值,我们可以用两个二元变量表示其颜色。
虚拟变量在回归分析中特别有用。
通过将分类变量转化为虚拟变量后,我们可以将其纳入回归模型中进行分析。
以线性回归为例,如果我们的自变量包含一个虚拟变量,我们可以在回归模型中将其作为一个系数进行解释。
假设这个虚拟变量是性别,取值为1表示男性,取值为0表示女性。
在回归模型中,该虚拟变量的系数,即回归系数,可以解释男性和女性在因变量上的平均差异。
另一个常见的用途是在分类器和机器学习算法中。
虚拟变量可以作为输入特征,帮助机器学习算法区分不同的类别。
比如,在邮件垃圾分类器中,我们可以使用虚拟变量表示是否包含某个关键词,而分类器可以根据虚拟变量的取值来判断邮件是否是垃圾邮件。
此外,虚拟变量还可以消除分类变量之间的顺序关系。
有时候,分类变量之间存在不同的大小或顺序。
例如,季节变量可以表示春季、夏季、秋季和冬季。
如果我们简单地将这个分类变量用1、2、3、4来编码,模型可能会误认为这是一种连续变量,并对它们的大小加以解释。
为了消除这种顺序关系,我们可以将这个分类变量转化为三个虚拟变量,每个季节一个虚拟变量,使得其取值只能为0或1,而不再具有顺序性。
虚拟变量名词解释

虚拟变量名词解释是数学中的一种变量,它是通过把参数取为整数或零来实现的。
1、变量:现实世界中的变量称为真实变量,而在数学中,将把带有“变量”字样的函数和过程称为虚拟变量。
变量是指处于可测空间的连续函数。
这些函数既可以是实变量,也可以是虚拟变量,两者在数学中统称为变量,如x(t)=t,就是一个虚拟变量。
对于复合函数,即复合变量,我们用“复合变量”表示之。
(2)虚拟变量:处于可测空间中的离散函数。
例如,从f(x)图像上任意一点出发的所有射线的集合称为变量空间中的某一变量(在这里,我们假定不同点对应不同的变量),其中每条射线称为变量x的虚拟变量。
由此可见,变量空间与可测空间是两个不同的概念,但它们之间有一个“中间地带”,即X与Y之间的变量范围。
它们的关系是: X 空间是Y空间的一部分; X空间内的任何一个点都是Y空间内的点;除去虚拟变量之外的变量称为复变量。
3、微分变量:处于可测空间上的离散变量,亦称微商变量。
它是一个复数,其元素是一个实数或复数。
这个复数的所有实部与虚部之和构成一个实部与虚部互异的复数,这就是复数的虚部,记作,称为复数的微分。
对于实数域上的函数g,其自变量称为变量(x, a,b)及,函数(g, x, a, b),称为微分变量,记作,写为,其中g称为g的微分。
4、导数变量:导数是连续可测空间上的可导函数。
导数和微分是不同的,导数的含义是隐函数在自变量的变化下,在函数图象上所描绘出的切线的斜率。
4、导数变量:导数是连续可测空间上的可导函数。
导数和微分是不同的,导数的含义是隐函数在自变量的变化下,在函数图象上所描绘出的切线的斜率。
处理任意阶导数时,只须取自变量的实部与虚部,即实部为一阶导数,虚部为二阶导数。
而三阶导数则须先取自变量的虚部,再取虚部的逆变换。
所以三阶导数为四阶导数的逆变换,四阶导数为五阶导数的逆变换,依次类推。
5、积分变量:积分变量的变量是虚数。
实数积分是在复平面上进行的,但虚数的积分是在可测空间中进行的。
虚拟变量名词解释

虚拟变量名词解释
虚拟变量是计算机程序设计中的一种技术,指的是在程序中定义的暂时存储息的变量,这些变量在程序结束时就会被收回。
虚拟变量是用来模拟物理变量的,它们可以用来模拟无线电频率,电路状态,机械动作等等。
虚拟变量可以用来控制和调节程序的行为,也可以用来存储临时数据。
在程序中,可以将虚拟变量的值设定为某个值,然后将该变量的值传递到程序的其他部分,以控制程序的行为。
虚拟变量可以帮助程序员更好地控制程序,使程序更加灵活,更易于维护和调试。
虚拟变量也可以用来作为缓存,它们可以用来在计算机中存储常用的数据,从而提高程序的运行速度。
它们可以将常用的数据存储在虚拟变量中,以便在程序运行过程中快速访问。
虚拟变量也可以用来模拟物理变量,这样程序员就可以在计算机中模拟一些复杂的物理系统,而不需要实际的物理实验,从而节省时间和精力。
总之,虚拟变量是计算机程序设计中非常重要的一种技术,它可以帮助程序员更好地控制程序,使程序更加灵活,更易于维护和调试,还可以用来作为缓存,以提高程序的运行速度,以及模拟一些复杂的物理系统。
虚拟变量给计算机程序设计带来了许多便利,是一种非常重要的技术。
虚拟变量(dummy variable)
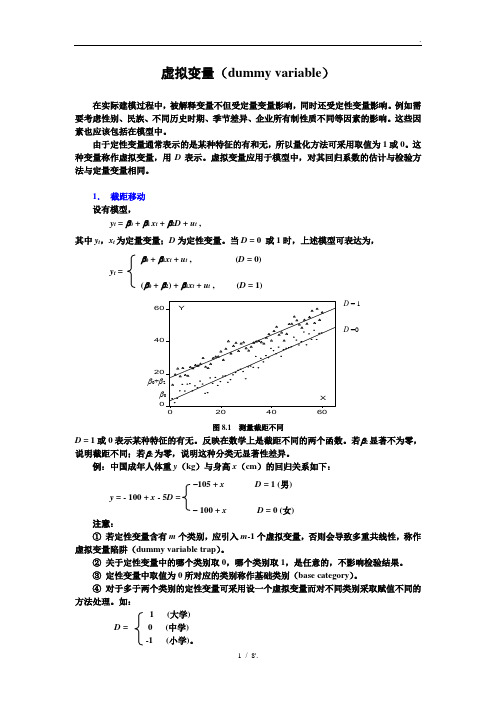
0
0
1
2000:4
2.7280
20
0
0
0
数据来源:《中国统计年鉴》1998-2001
2.斜率变化
以上只考虑定性变量影响截距,未考虑影响斜率,即回归系数的变化。当需要考虑时,可建立如下模型:
yt=0+1xt+2D+3xtD+ut,
其中xt为定量变量;D为定性变量。当D= 0或1时,上述模型可表达为,
若不采用虚拟变量,得回归结果如下,
GDP = 1.5427 + 0.0405 T
(11.0) (3.5) R2= 0.3991, DW = 2.6,s.e.=0.3
定义
1(1季度)1(2季度)1(3季度)
D1=D2=D3=
0(2, 3,4季度)0(1,3, 4季度)0(1,2, 4季度)
第4季度为基础类别。
15
0
0
1982
7.713
384
16
0
0
1983
8.601
34
1
34
1966
1.271
17
0
0
1984
12.010
35
1
35
1967
1.122
18
0
0
以时间T=time为解释变量,进出口贸易总额用trade表示,估计结果如下:
trade= 0.37 + 0.066time- 33.96D+ 1.20timeD
虚拟变量(dummy variable)
在实际建模过程中,被解释变量不但受定量变量影响,同时还受定性变量影响。例如需要考虑性别、民族、不同历史时期、季节差异、企业所有制性质不同等因素的影响。这些因素也应该包括在模型中。
虚拟变量
加法+乘法类型:反映相异回归
• 以乘法形式引入虚拟解释变量,是在设定的计量经济模 型中,将 虚拟解释变量与其他解释变量相乘作为解释变 量,以表示模型中斜率系数的差异。 • 以乘法形式引入虚拟解释变量的主要作用是:
第一:分析因素间的交互影响;
第二:分段线性回归,提高模型对现实经济现象的 描述精度 。
分段回归的实际应用
公司是如何酬劳其销售代表的? 其支付佣金的方式取决于销售量的一个目标或
临界水平X *
销售佣金在临界值X *之前随销售量线性增加, 在这个临界值之后仍线性增加,只是斜率更大。 于是得到由两段构成的分段线性回归
销售佣金是在临界值处改变斜率的。
类似的例子 税金的缴纳,产出与成本之间的关系
* * *
R 2 0.882 R 2 0.866 F 54.78
用虚拟变量表示不同斜率的回归 ---乘法类型:分段线性回归
根据以上分析,可以推导出两个时期的
储蓄-收入回归方程:
平均储蓄函数:1970-1981年 ˆ 1.02 0.0803 X Y
t
平均储蓄函数:1982-1995年 ˆ Y ( 1.02 152.48) (0.0803 0.0655)X
用虚拟变量表示不同斜率的回归 ---乘法类型:分段线性回归
储蓄—收入的回归方程:
Yt 1 2 Dt 1 Xt 2 Dt Xt ut
Y—个人储蓄, X—个人可支配收入
1, 观察值从1982年开始 Dt 0, 其他(观察值到1982年)
Y 1 1 X 2 X X D ut
回归的类型
虚拟变量模型的性质
根据加入的途径,可以将虚拟变量模型分成两种类型:
计量经济学之虚拟变量

一、虚拟变量 为什么要引入“虚拟变量” ??
许多经济变量是可以定量度量的或者说是可以直接观测的 如商品需求量、价格、收入、产量等
但是也有一些影响经济变量的因素无法定量度量或者说无法直接观测 如职业、性别对收入的影响,战争、自然灾害对GDP的影响,季节
对某些产品(如冷饮)销售的影响等。
为了能够在模型中反映这些因素的影响,并提高模型的精度,需要将 它们人为地“量化”,这种“量化”通常是通过引入“虚拟变量”来完成的。
这种用两个相异数字来表示对被解释变量有重要影响而自身又没有观测数值的一 类变量,称为虚拟变量。
虚拟变量的特点是:
1.虚拟变量是对经济变化有重要影响的不可测变量。 2.虚拟变量是赋值变量,一般根据这些因素的属性类型,构造只取 “0”或“1” 的人工变量,通常称为虚拟变量,记为D。这是为了便于计算而把定性因素这样数量 化的,所以虚拟变量的数值只表示变量的性质而不表示变量的数值。
则进口消费品的回归模型可建立如下:
Yt
0
1 X t
2(Xt
X
* t
)
Dt
t
转折期回归示意图
4. 虚拟变量交互效应分析
当分析解释变量对变量的影响时,大多数情形只是分析了解释变量自身变动对被 解释变量的影响作用,而没有深入分析解释变量间的相互作用对被解释变量影响。
前面讨论的分析两个定性变量对被解释变量影响的虚拟变量模型中,暗含着一个假定:
冷饮的销售额与季节因素的关系
如果只取六个观测值,其中春季与夏季取了两次,秋、冬各取到一次观测值,则其中
1 X11 L 1 X12 L
1 ( X D) 1
X 13 X 14
7.虚拟变量

在下降(仅为0.72)。
变参数线性回归模型
如果模型参数取值呈连续变化的,称为连续型确定性变参
数线性回归模型。
(1)截距系统变动模型。即在回归模型中仅截距项发生系统 性变化,而斜率在整个样本期内不发生变化的变参数线性回归
模型。
(2)斜率系统变动模型。即在回归模型中仅有斜率项发生系 统性变化,而截距在整个样本期内不发生变化变参数线性回归
0
0 0 0 0 0 0 0 0
0
0 0 0 0 0 0 0 0
1964
1965 1966 1967 1968
0.975
1.184 1.271 1.122 1.085
15
16 17 18 19
0
0 0 0 0
0
0 0 0 0
年份 1969 1970 1971 1972 1973 1974
进出口总额y 1.069 1.129 1.209 1.469 2.205 2.923
(单位:千美元)
y 0.3 0.0 1.0 2.0 0.4 0.7 1.5 1.6 0.6 0.6 x 9.0 6.0 18.0 20.0 12.0 14.0 15.0 16.0 15.0 14.0 D 0 0 0 1 0 0 1 1 0 0
图4
家庭年储蓄额yt与收入额xt散点图
通过散点图分析,可以给模型加入一个定性变量“住房状况”,用D表 示。虚拟变量D定义如下:
图1表明,在相同的收入水平情况下,有适龄子女家庭的教育费用平均要比无 适龄子女家庭的教育费用多支a出个单位。
图1 虚拟变量对截距的影响
(2)乘法类型 在所设定的计量经济模型中,将虚拟解释变量与其他解释变
量相乘作为新的解释变量出现在模型中,以达到其调整设定模型
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一般地,在虚拟变量的设置中:
• 基础类型、肯定类型取值为1;
• 比较类型,否定类型取值为0。
概念:
同时含有一般解释变量与虚拟变量的模型称为虚拟 变量模型。
例1:为了考察企业职工薪金收入(Yi)的情况, 以工龄(Xi)和性别(Di)为影响因素,建立如 下模型:
Yi 0 1 X i 2 Di i
其中: Di=1,若是男性, Di=0,若是女性。
二、虚拟变量的引入
• 虚拟变量做为解释变量引入模型有两种基本方式:加法 方式和乘法方式。
1、加法方式
上述企业职工薪金模型中性别虚拟变量的引入: Yi 0 1 X i 2 Di i
在该模型中,如果仍假定E(i)=0,则 企业女职工的平均薪金为:
表中给出了中国1979~2001年以城乡储蓄存款余 额代表的居民储蓄以及以GNP代表的居民收入的数 据。
90年前 1979 1980 1981 1982 1983 1984 1985 1986 1987 1988 1989 1990
表 5.1.1
储蓄 281 399.5 523.7 675.4 892.5 1214.7 1622.6 2237.6 3073.3 3801.5 5146.9 7034.2
R 2 =0.9836
由2与3的t检验可知:参数显著地不等于0,强 烈示出两个时期的回归是相异的,
储蓄函数分别为:
1990年前: 1990年后:
Yˆi 1649.7 0.4116Xi Yˆi 15452 0.8881Xi
三、虚拟变量的设置原则
虚拟变量的个数须按以下原则确定:
如果某个定性变量有m种相互排斥的类型,则模型中只能 引入m-1个虚拟变量。否则会陷入所谓的“虚拟变量陷阱”, 产生完全共线性。
t........(3.1)....(12.4)
R2 0.833 DW 0.398
• 模型隐含着一个重要假定: 我国城镇居民家庭的储 蓄行为在1955年至1985年期间是不变的。假定未必 能够成立,因为,与居民储蓄有关的许多重要因素 在1979年以后发生了明显变化,主要表现为:
• 1)在经济体制改革之前,我国居民的收入一直在低水平上徘 徊,大多数居民家庭的收入仅能维持温饱,因而平均储蓄倾 向很低,积蓄很少;1979年之后,我国居民的收入水平迅速 提高,与此同时,居民储蓄也在大幅增长。前后两个时期, 我国居民的储蓄行为有显著差异;
1979年以后:
St 61.7 0.256Xt
• 估计结果表明:1979年之前,我国城镇 居民的边际储蓄倾向仅为0.004,即收入 增加一元储蓄平均增加4厘;而在1979— 1985年期间,城镇居民边际储蓄倾向高 达0.256。
消费模型可建立如下:
Ct 0 1 X t 2 Dt X t t
• 这里,虚拟变量D以与X相乘的方式引入了模型中,从而 可用来考察消费倾向的变化。
• 假定E(i)= 0,上述模型所表示的函数可化为:
正常年份:
反常年份:
当截距与斜率都发生变化时,则需要同时引入 加法与乘法形式的虚拟变量。
• 例5,考察1990年前后中国居民的总储蓄(Y)-收 入(X)关系是否已发生变化。
第八章 虚拟变量
一、虚拟变量的基本含义 二、虚拟变量的引入 三、虚拟变量的设置原则
一、虚拟变量的基本含义
• 许多经济变量是可以定量度量的,如:商品需求 量、价格、收入、产量等
• 但也有一些影响经济变量的因素无法定量度量, 如:职业、性别对收入的影响,战争、自然灾害 对GDP的影响,季节对某些产品(如冷饮)销售 的影响等等。
在统计检验中,如果3=0的假设被拒绝,则说明两个 时期中储蓄函数的斜率不同,即储蓄倾向不一样。如果 2=0的假设被拒绝,则说明两个时期中储蓄的基数存在 显著差异。
• 具体的回归结果为:
Yˆi 15452 0.8881Xi 13802.3Di 0.4765Di Xi
(-6.11) (22.89) (4.33) (-2.55)
• 斜率的变化可通过以乘法的方式引入虚拟变量来 测度。
例4:根据消费理论,消费水平C主要取决于收入 水平X,但在一个较长的时期,人们的消费倾向会发 生变化,尤其是在自然灾害、战争等反常年份,消 费倾向往往出现变化。这种消费倾向的变化可通过 在收入的系数中引入虚拟变量来考察。
如,设
1 Dt 0
正常年份 反常年份
• 还可将多个虚拟变量引入模型中以考察多种 “定性”因素的影响。
例3: 在上述职工薪金的例中,除了工龄和性别两个自变 量外, 再引入代表学历的虚拟变量C:
本科及以上学历 本科以下学历
职工薪金的回归模型可设计为:
2、乘法方式
• 加法方式引入虚拟变量,考察:截距的不同,
• 许多情况下:往往是斜率就有变化,或斜率、截 距同时发生变化。
10201.4
1998
53407.5
11954.5
1999
59621.8
14922.3
2000
64332.4
16917.8
2001
73762.4
18598.4
GNP
21662.5 26651.9 34560.5 46670.0 57494.9 66850.5 73142.7 76967.2 80579.4 88228.1 94346.4
年薪 Y
2 0
男职工 女职工
工龄 X
例2:在横截面数据基础上,考虑个人保健支 出(Y)对个人收入(X)和教育水平(D)的回 归。
教育水平(D)考虑三个层次:
高中以下, 高中, 大学及其以上
这时需要引入两个虚拟变量:
1 D1 0
高中 其他
模型可设定如下:
1 D2 0
大学及其以上 其他
在E(i)=0 的初始假定下,高中以下、高中、大 学及其以上教育水平下个人保健支出的均值:
• 在上述模型中,若再引入第四个虚拟变量
1 冬季 D4t 0 其他
则冷饮销售模型变量为:
Yt 0 1 X1t k X kt 1D1t 2 D2t 3 D3t 4 D4t t
Y (X,D)α β μ
如果只取六个观测值,其中春季与夏季取了 两次,秋、冬各取到一次观测值,则式中的:
• 2)在改革开放前的大多数年份,我国的消费品市场存在严重 短缺的现象。消费者既使有钱也难以买到所需的商品,而不 得不把钱暂时存起来。因此,这一时期储蓄带有“非自愿” 的性质;而在1979年之后,消费品市场日趋丰富,消费者储 蓄的主要目的之一是购买高档耐用消费品,储蓄不再具有 “被迫”性质。
• 为了验证城镇居民储蓄行为的变化,建 立如下截距和斜率同时变动模型:
例。已知冷饮的销售量Y除受k种定量变量Xk的影 响外,还受季节这个定性变量的影响,而季节有四个 相互排斥的类型——春、夏、秋、冬,所以需引入 ? 个虚拟变量:
1 春季 D1t 0 其他
1 夏季 D2t 0 其他
1 D3t 0
秋季 其他
则冷饮销售量的模型为:
Yt 0 1 X1t k X kt 1D1t 2 D2t 3 D3t t
St 0 1Xt 2D 3DX t ut
用最小二乘法得:
1 D 0
t 1979 t 1979
St 61.7 0.256Xt 55.7Dt 0.252Dt Xt
(2.18) (8.1) (3.9) (-9.2)
R 2 0.967
DW 1.6704Xt
• 高中以下: • 高中: • 大学及其以上:
假定3>2>0, 其几何意义:
大学教育
保健
高中教育
支出
低于中学教育
收入
• 还可将多个虚拟变量引入模型中以考察多种 “定性”因素的影响。
例3: 在上述职工薪金的例中,除了工 龄和性别两个自变量外, 再考虑学历的 影响,此时怎么处理?
(学历分为本科及以上、本科以下两种)
1979~2001 年中国居民储蓄与收入数据(亿元)
GNP
90年后
储蓄
4038.2
1991
9107
4517.8
1992
11545.4
4860.3
1993
14762.4
5301.8
1994
21518.8
5957.4
1995
29662.3
7206.7
1996
38520.8
8989.1
1997
46279.8
这就是所谓的“虚拟变量陷井”,应避免。
案例分析:中国城镇居民家庭的储蓄函数
• 根据我国城镇居民家庭1955—1985年人 均收入(X)和人均储蓄(S)的数据资料(以 1955年的物价水平为100),建立储蓄模 型:
St 0 1X t ut
• 用最小二乘法得估计结果为:
•
St 33.4 0.17X t
1 X 11 1 X 12 (X,D) 1 X13 1 X 14 1 X 15 1 X 16
X k1 X k2 X k3 X k4 X k5 X k6
1 0 0 0 0 1 0 0
0
0
1
0
0 0 0 1
0
1
0
0
1 0 0 0
0
β
1 k
1
α
2 3 4
显然,(X,D)中的第1列可表示成后4列的线性组合, 从而(X,D)不满秩,参数无法唯一求出。
• 为了在模型中能够反映这些因素的影响,并提高 模型的精度,需要将它们“量化”,
这种“量化”通常是通过引入“虚拟变量”来 完成的。根据这些因素的属性类型,构造只取“0” 或“1”的人工变量,通常称为虚拟变量(dummy variables),记为D。
• 例如,反映文化程度的虚拟变量可取为: 1, 本科学历