灰度预测模型数学建模论文
灰色预测模型论文

GM(1,1)灰色预测模型摘要灰色理论认为系统的行为现象尽管是朦胧的,数据是复杂的,但它毕竟是有序的,是有整体功能的。
灰数的生成,就是从杂乱中寻找出规律。
同时,灰色理论建立的是生成数据模型,不是原始数据模型,因此,灰色预测的数据是通过生成数据的gm(1,1)模型所得到的预测值的逆处理结果。
本文利用灰色预测对重庆市的人均收入进行模拟,容易理解,操作简单灵活,直接面向用户,精度较高。
一、GM(1,1)预测模型的基本原理:灰色预测的基本原理时间序列预测是采用趋势预测原理进行的.然而时间序列预测存在以下问题:(1)时间序列变化趋势不明显时,很难建立起较精确的预测模型.(2)它是在系统按原趋势发展变化的假设下进行预测的,因而未考虑对未来变化产生影响的各种不确定因素.为克服上述缺点,邓聚龙教授引入了灰色因子的概念,采用“累加”和“累减”的方法创立了灰色预测理论.1.1 GM(1,1)模型的基本原理当一时间序列无明显趋势时,采用累加的方法可生成一趋势明显的时间序列.如时间序列X(0)={32,38,36,35,40,42}的趋势并不明显,但将其元素进行“累加”所生成的时间序列X(1)={32,70,106,141,181,223}则是一趋势明显的数列,按该数列的增长趋势可建立预测模型并考虑灰色因子的影响进行预测,然后采用“累减”的方法进行逆运算,恢复原时间序列,得到预测结果,这就是灰色预测的基本原理.数据来源:重庆市统计年鉴重庆城市居民家庭人均可支配收入:收入4375.435022.965302.05表1二、利用软件对数据进行模拟:模拟值残差相对误差4375.432 3910.0859 -1112.8741 -22.1557433 4368.869126 -933.180874 -17.6003794 4881.482893 -561.357107 -10.313685 5454.243318 -374.186682 -6.4200256 6094.207607 -82.092393 -1.3291527 6809.261006 236.961006 3.605458 7608.213972 370.143972 5.1138499 8500.910713 407.240713 5.03159510 9498.350496 277.390496 3.0082611 10612.823165 368.833165 3.60048312 11858.060575 288.320575 2.49202313 13249.40578 -465.84422 -3.39654214 14804.00209 -904.73791 -5.75945615 16541.004292 -650.095708 -3.78158316 18481.814669 -617.915331 -3.235205三、实验结果表21995200020052010x 104时间(年)人均收入(元)图1所得预测值与实测值折线比较 如图 1。
数学建模灰色模型论文
灰色模型
摘要:
通常可以运用此方法来分析各个因素对于结果的影响程度,也可以运用此方法解决随时间变化的综合评价类问题,其核心是按照一定规则确立随时间变化的母序列,把各个评估对象随时间的变化作为子序列,求各个子序列与母序列的相关程度,依照相关性大小得出结论。
关键词:
灰色理论,灰关联模型
一、问题描述
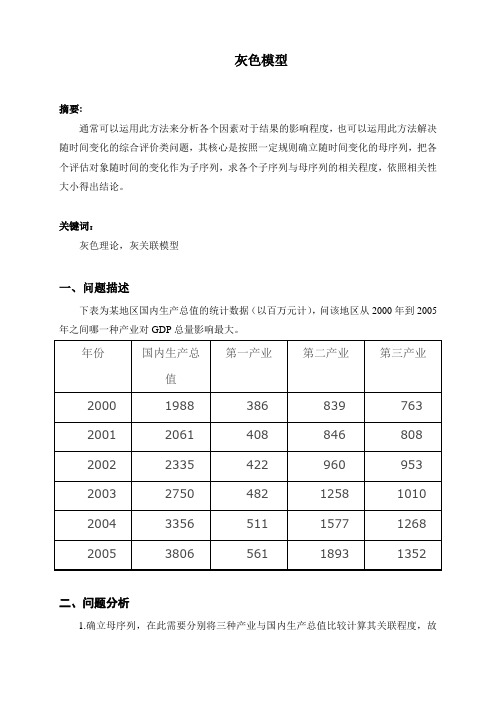
下表为某地区国内生产总值的统计数据(以百万元计),问该地区从2000年到2005年之间哪一种产业对GDP总量影响最大。
二、问题分析
1.确立母序列,在此需要分别将三种产业与国内生产总值比较计算其关联程度,故
母序列为国内生产总值。
若是解决综合评价问题时则母序列可能需要自己生成,通常选定每个指标或时间段中所有子序列中的最佳值组成的新序列为母序列。
2.无量纲化处理,在此采用均值化法,即将各个序列每年的统计值与整条序列的均值作比值,可以得到如下结果:
3.计算每个子序列中各项参数与母序列对应参数的关联系数,运用公式
其中表示第i个子序列的第j个参数与母序列(即0序列)的第j个参数的关联系数,为分辨系数取值范围在[0,1],其取值越小求得的关联系数之间的差异性越显著,在此取为0.5进行计算可得到如下结果:
4.计算关联度,用公式,可以得到=0.5088、=0.6248、
=0.7577,通过比较三个子序列与母序列的关联度可以得出结论:该地区在2000年到2005年期间的国内生产总值受到第三产业的影响最大。
三、符号说明
参考文献
[1]数学建模——灰色关联分析法
[2]数学建模案例分析--灰色系统方法建模1灰色关联度与优势分析。
灰色预测建模论文

公共危机事件网络舆情影响趋势预测及其应对策略研究摘要:当前我国正处于突发事件的高发期和社会的转型期,随着网络的日益普及,网络逐渐成为广大民众展现情绪、表达民意的公共话语空间,进而引出的是公共危机事件网络舆情,这是社会政治生活领域里出现的新问题。
若网络舆情未合理引导,则在较大程度上会引发公共危机,危害社会稳定和经济发展。
所谓预警就是指对某一警情的现状和未来进行测度,预报不正常状态的时空范围和危害程度,以及提出防范措施。
本文采用SPSS数据分析软件对原始数据进行分析与聚类,归纳出网络舆情发展的不同种类。
通过对每类事件网络舆情发展趋势的分析,找出规律。
在此基础上应用matlab软件建立预测模型,依据灰色理论,建立预测模型,该模型是微分回归分析的一个特例,以指数形式为基础,以一次累加数据作为原始数据,以初始观测值为准确定积分常数。
本文采用此法将杂乱无章数据列进行整理、生成,将空缺的数据通过计算加以补充,用其所整理过的数据列建立模型并通过它进行决策和预测,将结构、关系、机制不清楚的网络舆情过程作灰色预测以进行提前控制。
关键词:网络舆情;灰色理论;预测模型;预警。
1问题重述公共危机或突发性群体事件是由临时的、自发的同类个体组成的整体,由于某种共同要求,造成对社会具有不平常影响的事情,其从发酵到爆发都伴随相关信息传播活动。
而网络信息传播是指民众以网络为平台,借助网络论坛(BBS)、网络聊天(Chatting)、博客(Blog)、维客(Wiki)、电子邮件(E-mail)及网络新闻组(Usernet News)等网络渠道,围绕即将发生或已发生的群体性事件发布信息。
当传播途径从传统渠道向互联网等途径转移后,出现了流言广泛传播,难以实施有效控制或澄清;舆情信息传播速度快、范围广、影响大;信息交流呈现非理性化、情绪化倾向的新特征。
网络舆情是群体性事件发展演变的一个重要因素,它常直接引发或间接推动群体性事件的恶性发展。
基于灰色模型与指数平滑法对未来汽车销售数额的预测

基于灰色模型与指数平滑法对未来汽车销售数额的预测摘要:总所周知的,预测汽车的销售量,无论是对于整体的掌控汽车市场的发育与成长态势的政策制定者,还是对于研究市场行情以制定营销策略的汽车厂商而言,都具有极其重要的作用。
我们根据题中所给的历史以来的销量数据,利用灰色模型GM(1,1)根据长期趋势性和周期性,通过灰色预测算法dx/dt+ax=u,x(k+1)=(x⑴-u/a)e+u/a。
对问题进行编程并带入16年和17年的数据进行迭代运算对汽车销量即时间序列的未来值进行数学建模分析预测,然后利用指数平滑法对各个数据进行加权处理,并可利用此对原方法进行优化改进。
根据“最近数据对未来数据影响大,远古数据反之”的特点,且前灰色预测出来的函数图像为曲线增长的模式,则利用三次指数平滑预测公式,yt+1’=yt’+a(yt- yt’),yt+m=(2+am/(1-a))yt’-(1+am/(1-a))yt=(2yt’-yt)+m(yt’-yt)a/(1-a)求解关键词:汽车销量;灰色预测;指数平滑法一、模型的建立首先,我们根据以往几年的数据想要求得2018年的预测数据并希望其理论真实值比较可靠,在某种程度上会持续到未来,所以将较大的权数放在最近的资料。
从而得到2018年的预测数据以及图像。
其次,光是得到2018年的预测数据是不够的,我们希望能够得到以后几年的预测数据,而灰色理论认为系统的行为现象尽管是朦胧的,数据是复杂的,但它毕竟是有序的,是有整体功能的。
同时,灰色理论建立的是生成数据模型,不是原始数据模型,因此,灰色预测的数据是通过生成数据gm(1,1)模型所得到的预测值的逆处理结果。
故利用灰色预测模型对往几年的数据进行拟合,并可根据往几年的数据对以后几年进行预测计算,从而得到比较可靠的问题解决。
在第一种方法中,对于指数平滑法,时间从2000年到2017年。
并分别用一次二次三次指数平滑进行远古数据拟合,观测得到最合理的一个,并对此基础上求得2018年的营销数据。
【数学建模】灰色预测模型(预测)

【数学建模】灰色预测模型(预测)文章目录•一、算法介绍•o 1.灰色预测模型o 2.灰色系统理论o 3. 针对类型o 4. 灰色系统o 5. 灰色生成o 6. 累加生成o7. GM(1,1)模型o▪推导▪精度检验▪精度检验等级参照表•二、适用问题•三、算法总结•o 1. 步骤•四、应用场景举例•o 1. 累加生成o 2. 建立GM(1,1)模型o 3. 检验预测值•五、MATLAB代码•六、实际案例•七、论文案例片段(待完善)灰色预测模型主要针对数学建模问题中的一些小的子问题进行求解,如果想直接使用请跳转至——四、五另外之前看过一篇比较完整的【数学建模常用算法】之灰色预测模型GM,作者:張張張張视频回顾一、算法介绍1.灰色预测模型灰色预测模型(Gray Forecast Model)是通过少量的、不完全的的信息,建立数学模型并做出预测的一种预测方法.当我们应用运筹学的思想方法解决实际问题,制定发展战略和政策、进行重大问题的决策时,都必须对未来进行科学的预测.预测是根据客观事物的过去和现在的发展规律,借助于科学的方法对其未来的发展趋势和状况进行描述和分析,并形成科学的假设和判断。
2.灰色系统理论灰色系统理论是研究解决灰色系统分析、建模、预测、决策和控制的理论.灰色预测是对灰色系统所做的预测。
目前常用的一些预测方法(如回归分析等),需要较大的样本,若样本较小,常造成较大误差,使预测目标失效。
灰色预测模型所需建模信息少,运算方便,建模精度高,在各种预测领域都有着广泛的应用,是处理小样本预测问题的有效工具。
3. 针对类型灰色系统理论是由华中理工大学邓聚龙教授于1982年提出并加以发展的。
二十几年来,引起了不少国内外学者的关注,得到了长足的发展。
目前,在我国已经成为社会、经济、科学技术在等诸多领域进行预测、决策、评估、规划控制、系统分析与建模的重要方法之一。
特别是它对时间序列短、统计数据少、信息不完全系统的分析与建模,具有独特的功效,因此得到了广泛的应用.4. 灰色系统灰色系统是黑箱概念的一种推广。
灰色预测模型※※分析

灰色预测模型灰色预测是就灰色系统所做的预测. 所谓灰色系统是介于白色系统和黑箱系统之间的过渡系统,其具体的含义是:如果某一系统的全部信息已知为白色系统,全部信息未知为黑箱系统,部分信息已知,部分信息未知,那么这一系统就是灰箱系统. 一般地说,社会系统、经济系统、生态系统都是灰色系统.灰色系统理论认为对既含有已知信息又含有未知或非确定信息的系统进行预测,就是对在一定方位内变化的、与时间有关的灰色过程的预测. 尽管过程中所显示的现象是随机的、杂乱无章的,但毕竟是有序的、有界的,因此这一数据集合具备潜在的规律,灰色预测就是利用这种规律建立灰色模型对灰色系统进行预测.灰色预测模型只需要较少的观测数据即可,这和时间序列分析,多元回归分析等需要较多数据的统计模型不一样. 因此,对于只有少量观测数据的项目来说,灰色预测是一种有用的工具.一、GM(1,1)模型灰色系统理论是邓聚龙教授在1981年提出来的,是一种对含有不确定因素系统进行预测的方法. 通过鉴别系统因素之间发展趋势的相异程度,进行关联分析,并通过对原始数据进行生成处理来寻找系统的变化规律,生成较强规律性数据序列,然后建立相应微分方程模型,从而预测事物未来的发展趋势和未来状态. 目前使用最广泛的灰色预测模型是关于数列预测的一个变量、一阶微分的GM(1,1)模型.GM(1,1)模型是基于灰色系统的理论思想,将离散变量连续化,用微分方程代替差分方程,按时间累加后所形成的新的时间序列呈现的规律可用一阶线性微分方程的解来逼近,用生成数序列代替原始时间序列,弱化原始时间序列的随机性,这样可以对变化过程作较长时间的描述,进而建立微分方程形式的模型. 其建模的实质是建立微分方程的系数,将时间序列转化为微分方程,通过灰色微分方程可以建立抽象系统的发展模型. 经证明,经一阶线性微分方程的解逼近所揭示的原始时间数列呈指数变化规律时,灰色预测GM(1,1)模型的预测将是非常成功的.1.1 GM(1,1)模型的建立灰色理论认为一切随机量都是在一定范围内、一定时间段上变化的灰色量及灰色过程. 数据处理不去寻找其统计规律和概率分布, 而是对原始数据作一定处理后, 使其成为有规律的时间序列数据, 在此基础上建立数学模型.GM(1,1)模型是指一阶,一个变量的微分方案预测模型,是一阶单序列的线性动态模型,用于时间序列预测的离散形式的微分方程模型.设时间序列()0X有n 个观察值,()()()()()()(){}00001,2,,Xx x x n =,为了使其成为有规律的时间序列数据,对其作一次累加生成运算,即令()()()()101tn xt x n ==∑从而得到新的生成数列()1X,()()()()()()(){}11111,2,,Xx x x n =,新的生成数列()1X 一般近似地服从指数规律. 则生成的离散形式的微分方程具体的形式为dxax u dt+= 即表示变量对于时间的一阶微分方程是连续的. 求解上述微分方程,解为当t =1时,()(1)x t x =,即(1)c x a=-,则可根据上述公式得到离散形式微分方程的具体形式为 ()()()11a t u u x t x e a a --⎛⎫=-+ ⎪⎝⎭其中,ax 项中的x 为dxdt的背景值,也称初始值;a ,u 是待识别的灰色参数,a 为发展系数,反映x 的发展趋势;u 为灰色作用量,反映数据间的变化关系.按白化导数定义有0()()lim t dx x t t x t dt t→+-= 显然,当时间密化值定义为1时,当1t →时,则上式可记为1lim(()())t dxx t t x t dt→=+- 这表明dxdt是一次累减生成的,因此该式可以改写为 (1)(1)(1)()dxx t x t dt=+- 当t 足够小时,变量x 从()x t 到()x t t +是不会出现突变的,所以取()x t 与()x t t +的平均值作为当t 足够小时的背景值,即(1)(1)(1)1()(1)2xx t x t ⎡⎤=++⎣⎦将其值带入式子,整理得 (0)(1)(1)1(1)()(1)2x t a x t x t u ⎡⎤+=-+++⎣⎦ 由其离散形式可得到如下矩阵:(1)(1)(0)(1)(1)(0)(0)(1)(1)1(1)(2)2(2)1(2)(3)(3)2()1(1)()2x x x x x x a u x n x n x n ⎛⎫⎡⎤-+ ⎪⎣⎦⎛⎫ ⎪ ⎪ ⎪⎡⎤-+ ⎪⎣⎦ ⎪=+ ⎪ ⎪ ⎪⎪ ⎪⎝⎭ ⎪⎡⎤--+ ⎪⎣⎦⎝⎭令 (0)(0)(0)(2),(3),,()TY x x x n ⎡⎤=⎣⎦(1)(1)(1)(1)(1)(1)11(1)(2)211(2)(3)21(1)()12x x x x B x n x n ⎛⎫⎡⎤-+ ⎪⎣⎦ ⎪⎪⎡⎤-+⎣⎦ ⎪= ⎪ ⎪ ⎪⎡⎤--+ ⎪⎣⎦⎝⎭()Ta u α=称Y 为数据向量,B 为数据矩阵,α为参数向量. 则上式可简化为线性模型:Y B α=由最小二乘估计方法得()1T T a B B B Y uα-⎛⎫== ⎪⎝⎭上式即为GM(1,1)参数,a u 的矩阵辨识算式,式中()1TT B B B Y -事实上是数据矩阵B 的广义逆矩阵.将求得的a ,u 值代入微分方程的解式,则()1(1)()((1))a t u ux t x e a a--=-+其中,上式是GM(1,1)模型的时间响应函数形式,将它离散化得(1)(0)(1)ˆ()(1)a t u u xt x e a a --⎛⎫=-+ ⎪⎝⎭ 对序列()()1ˆxt 再作累减生成可进行预测. 即()(0)(1)(1)(0)(1)ˆˆˆ()()(1)(1)1a a t xt x t x t u x e ea --=--⎛⎫=-- ⎪⎝⎭ 上式便是GM(1,1)模型的预测的具体计算式. 或对()atux t cea-=+求导还原得 (0)(0)(1)ˆ()((1))a t uxt a x e a--=-- 1.2 GM(1,1)模型的检验GM(1,1)模型的检验包括残差检验、关联度检验、后验差检验三种形式.每种检验对应不同功能:残差检验属于算术检验,对模型值和实际值的误差进行逐点检验;关联度检验属于几何检验范围,通过考察模型曲线与建模序列曲线的几何相似程度进行检验,关联度越大模型越好;后验差检验属于统计检验,对残差分布的统计特性进行检验,衡量灰色模型的精度. ➢ 残差检验残差大小检验,即对模型值和实际值的残差进行逐点检验. 设模拟值的残差序列为(0)()e t ,则(0)(0)(0)ˆ()()()e t x t xt =- 令()t ε为残差相对值,即残差百分比为(0)(0)(0)ˆ()()()%()x t xt t x t ε⎡⎤-=⎢⎥⎣⎦令∆为平均残差,11()nt t n ε=∆=∑.设残差的方差为22S ,则[]22211()n t S e t e n ==-∑. 故后验差比例C 为21/C S S =,误差频率P 为{}1()0.6745P P e t e S =-<.对于,C P 检验指标如下表:检验指标好合格勉强不合格P >0.95 >0.80 >0.70 <0.70 C <0.35 <0.50 <0.65 >0.65表 1 灰色预测精确度检验等级标准一般要求()20%t ε<,最好是()10%t ε<,符合要求.➢ 关联度检验关联度是用来定量描述各变化过程之间的差别. 关联系数越大,说明预测值和实际值越接近.设 {}(0)(0)(0)(0)ˆˆˆˆ()(1),(2),,()Xt xx x n =⋯ {}(0)(0)(0)(0)()(1),(2),,()X t x x x n =⋯序列关联系数定义为(){}{}{}(0)(0)(0)(0)(0)(0)(0)(0)ˆˆmin ()()max ()(),0ˆˆ()()max ()()1,0x t x t x t x t t t x t x t x t x t t σξσ⎧-+-⎪≠⎪=⎨-+-⎪=⎪⎩ 式中,(0)(0)ˆ()()xt x t -为第t 个点(0)x 和(0)ˆx 的绝对误差,()t ξ为第t 个数据的关联系数,ρ称为分辨率,即取定的最大差百分比,0ρ<<1,一般取0.5ρ=.(0)()x t 和(0)ˆ()xt 的关联度为()11nt r t n ξ==∑精度等级 关联度均方差比值小误差概率好(1级) 0.90≥ 0.35≤ 0.95≥ 合格(2级) 0.80≥ 0.50≤ 0.80≥ 勉强(3级) 0.70≥ 0.65≤ 0.70≥ 不合格(4级)0.70< 0.65>0.70<表 2 精度检验等级关联度大于60%便满意了,原始数据与预测数据关联度越大,模型越好.➢ 后验差检验后验差检验,即对残差分布的统计特性进行检验. 检验步骤如下:1、计算原始时间数列(){}0(0)(0)(0)(1),(2),,()Xx x x n =的均值和方差()2(0)(0)2(0)11111(),()n n t t xx t S x t x n n ====-∑∑ 2、计算残差数列{}(0)(0)(0)(0)(1),(2),,()ee e e n =的均值e 和方差22s()2(0)2(0)21111(),()n n t t e e t S e t e n n ====-∑∑其中(0)(0)(0)ˆ()()(),1,2,,e t x t xt t n =-=为残差数列.3、计算后验差比值21C S S =4、计算小误差频率{}(0)1()0.6745P P e t e S =-<令0S =0.67451S ,(0)()|()|t e t e ∆=-,即{}0()P P t S =∆<.若对给定的00C >,当0C C <时,称模型为方差比合格模型;若对给定的00P >,当0P P >时,称模型为小残差概率合格模型.>0.95 <0.35 优 >0.80 <0.5 合格 >0.70 <0.65 勉强合格 <0.70>0.65不合格表 3 后验差检验判别参照表1.3 残差GM(1,1)模型当原始数据序列(0)X建立的GM(1,1)模型检验不合格时,可以用GM(1,1)残差模型来修正. 如果原始序列建立的GM(1,1)模型不够精确,也可以用GM(1,1)残差模型来提高精度.若用原始序列(0)X建立的GM(1,1)模型(1)(0)ˆ(1)[(1)]at u uxt x e a a-+=-+ 可获得生成序列(1)X 的预测值,定义残差序列(0)(1)(1)ˆ()()()e k x k x k =-. 若取k=t , t+1, …, n ,则对应的残差序列为{}(0)(0)(0)(0)()(1),(2),,()e k e e e n =计算其生成序列(1)()e k ,并据此建立相应的GM(1,1)模型(1)(0)ˆ(1)[(1)]e a k e ee eu u et e e a a -+=-+ 得修正模型(1)(0)(0)(1)(1)()()(1)e a k ak e e e u u u x t x e k t a e e a a a δ--⎡⎤⎡⎤+=-++---⎢⎥⎢⎥⎣⎦⎣⎦其中1()0k tk t k t δ≥⎧-=⎨≤⎩为修正参数.应用此模型时要考虑:1、一般不是使用全部残差数据来建立模型,而只是利用了部分残差.2、修正模型所代表的是差分微分方程,其修正作用与()k t δ-中的t 的取值有关.1.4 GM(1,1)模型的适用范围定理:当GM(1,1)发展系数||2a ≥时,GM(1,1)模型没有意义.我们通过原始序列()0i X 与模拟序列()0ˆiX 进行误差分析,随着发展系数的增大,模拟误差迅速增加. 当发展系数0.3a -≤时,模拟精度可以达到98%以上;发展系数0.5a -≤时,模拟精度可以达到95%以上;发展系数1a ->时,模拟精度低于70%;发展系数 1.5a ->时,模拟精度低于50%. 进一步对预测误差进行考虑,当发展系数0.3a -<时,1步预测精度在98%以上,2步和5步预测精度都在90%以上,10步预测精度亦高于80%;当发展系数0.8a ->时,1步预测精度已低于70%.通过以上分析,可得下述结论:1、当0.3a -<时,GM(1,1)可用于中长期预测;2、当0.30.5a <-≤时,GM(1,1)可用于短期预测,中长期预测慎用;3、当0.50.8a <-≤时,GM(1,1)作短期预测应十分谨慎;4、当0.81a <-≤时,应采用残差修正GM(1,1)模型;5、当1a ->时,不宜采用GM(1,1)模型.1.5 GM(1,1)模型实例分析例:则该学生成绩时间序列如下:()()(0)(0)(0)(0)(0)(1),(2),(3),(4)79,74.825,74.29,76.98X x x x x ==对(0)X作一次累加后的数列为()()(1)(1)(1)(1)(1)(1),(2),(3),(4)79,153.825,228.115,305.095X x x x x ==对(1)X做紧邻均值生成. 令(1)(1)(1)()0.5()0.5(1)Z k x k x k =+-,得()()(1)(1)(1)(1)(2),(3),(4)116.4125,151.47,150.1925Z z z z ==则数据矩阵B 及数据向量Y 为(1)(1)(1)(2)1116.41251(3)1151.471(4)1150.19251z B z z ⎡⎤--⎡⎤⎢⎥⎢⎥=-=-⎢⎥⎢⎥⎢⎥⎢⎥--⎣⎦⎣⎦,(0)(0)(0)(2)74.825(3)74.29(4)76.98x Y x x ⎡⎤⎡⎤⎢⎥⎢⎥==⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦⎣⎦ 对参数列ˆ[,]Taa b =进行最小二乘估计,得 176.61ˆ()[,]0.0144T T T T a B B B Y B Y a u -⎡⎤====⎢⎥-⎣⎦即 0.0144a =-,76.61u = 则GM(1,1)模型为()()110.014476.61dx x dt-= 时间响应式为(1)0.0144ˆ(1)5399.13895320.1389xk e -+=- 当1k =时,我们取(1)(0)(0)ˆˆ(1)(1)(0)79xx x === 还原求出(0)X的模拟值. 由(0)(1)(1)ˆˆˆ()()(1)Xk x k x k =--,取2,3,4k =,得 ()()(0)(0)(0)(0)(0)ˆˆˆˆˆ(1),(2),(3),(4)79,74.281,74.3584,76.4513xx x x x == 通过预测,得到实际值与预测值如下表:实际值 预测值 相对误差()k ε 第一学期79 79 0 第二学期 74.825 74.2810 0.73% 第三学期 74.29 74.3584 0.0921% 第四学期76.9876.45130.7051%表 4 四学期的实际值与预测值的误差表因为()10%k ε<,那就可得学生的预测值,与现实值进行比较得出该模型精度较高,可进行预测和预报.我们对学生未来两个学期(也就是第五、六个学期)的成绩进行预测,分别为77.5602分和78.6851分.例:某大型企业1999年至2004年的产品销售额如下表,试建立GM(1,1)预测模型,并预测2005年的产品销售额。
数学建模案例分析--灰色系统方法建模2灰色预测模型GM(1,1)及其应用
§2 灰色预测模型GM(1,1)及其应用蠕变是材料在高温下的一个重要性能。
处于高温状态下的材料长期受到载荷作用时,即使其载荷较低,并且在短时间的高温拉伸试验中材料不发生变形,但在此情况下仍会有微小的蠕变,极端的情况下,甚至会使材料发生破坏。
高温材料多应用于各种车辆的发动机及冶金厂中各种设备上,如果因蠕变引起破坏,可能造成很大的事故。
为了保证设备的安全可靠,在某一使用温度下,预先知道该材料对不同载荷应力下断裂的时间是很重要的。
过去,人们都是通过蠕变试验测量断裂时间。
而做蠕变试验时,需要很长时间才能得到结果,即使通过试验得出的数据,也只是对某几个具体试样而言,存在很大的偶然性,不能代表普遍的规律。
如果将实测的数据用灰色系统理论来处理,可以预测在某一温度下的任何载荷应力的断裂时间。
一、灰色预测模型GM (1,1) 建模步骤如下:(1)GM (1,1)代表一个白化形式的微分方程:u aX dtdX =+)1()1( (1) 式中,u a ,是需要通过建模来求得的参数;)1(X是原始数据)0(X的累加生成(AGO )值。
(2)将同一数据列的前k 项元素累加后生成新数据列的第k 项元素,这就是数据处理。
表示为:∑==kn n X k X1)0()1()()( (2)不直接采用原始数据)0(X建模,而是将原始的、无规律的数据进行加工处理,使之变得较有规律,然后利用生成后的数据列来分析建模,这正是灰色系统理论的特点之一。
(3)对GM (1,1),其数据矩阵为⎪⎪⎪⎪⎪⎭⎫⎝⎛+--+-+-=1)]()1([5.01)]3()2([5.01)]2()1([5.0)1()1()1()1()1()1(N X N X X X X X B (3) 向量T N N X X X Y )](,),3(),2([)0()0()0( = (4)作最小二乘估计,求参数u a ,N TT Y B B B u a 1)(ˆ-=⎪⎪⎭⎫⎝⎛=α (4) (5)建立时间响应函数,求微分方程(1)的解为au e a u X t Xat +-=+-))1(()1(ˆ)0()1( (5) 这就是要建立的灰色预测模型。
大学生数学建模竞赛模板--sars模型灰色预测
SARS对经济指标的影响王海燕徐昊天吴德春摘要本文针对SARS 疫情传播对经济指标影响的问题,建立灰色预测模型,得到03年预测数据,并与实际数据作比较,进而研究SARS疫情对该市各经济指标的影响及其程度。
为研究SARS疫情对该市各经济指标的影响,我们作出了不同经济指标的散点图和数据列表,使得对问题的研究更直观。
(1)SARS对零售业的影响为简化计算,我们以1997--2002年年总值构造参考数列,得到一个预测各年总值的方程。
利用方程先预测出2003年零售额的年总值,根据各月综合服务业数额在年总值中所占比例求得各月预测值。
利用MATLAB软件求解,得到得预测值与实际值有一定的相差但相差并不大。
从表三我们得出结论:SARS疫情的传播对零售业从4月份开始产生影响,5、6月份影响最大,10月份以后影响就很小了。
(2)SARS对海外旅游业的影响以1997--2002年每年同期的数据构造参考数列,可以得到1-12月的共12个预测方程,即可预测2003年各月的海外旅游人数。
利用MATLAB软件求解,得到的预测值和实际值相差很大,说明从4月份开始SARS疫情就对旅游业产生影响,尤其5、6月份影响最大,但10月份以后影响就变小甚至没有影响了。
(3)SARS对综合服务业总额的影响以1997--2002年年总值构造参考数列,得到一个预测各年总值的方程。
利用方程先预测出2003年的年总值,再根据各月综合服务业数额在年总值中所占比例求得各月的预测值。
利用MATLAB软件求解,得到得预测值与实际值是很一致的。
因此,我们得出结论:SARS疫情的传播对综合服务业没有影响。
另外,本文对模型的误差进行了准确的分析,使得结论更加科学更加有说服力。
虽然模型的建立都是采用了灰色预测法,但在具体的数据处理时,采用了不同的方法,使模型更加丰满,更有特色。
关健词:经济指标;灰色预测;MATLAB;相对误差§1问题的提出背景知识与要解决的问题2003年SARS疫情席卷全球,对世界各国各地区各行业都造成一定的影响。
灰色预测模型在公路货运量预测中应用论文
灰色预测模型在公路货运量预测中的应用摘要:为了提高公路运输行业的管理水平,为设计、修建货运场站或现代物流中心提供数据依据和决策支持,就必须要准确的预测公路货运量。
在运输业今年运量统计的基础上,利用灰色预测理论的gm(1,1)模型,给出了gm(1,1)模型的详细步骤,并以公路货运量历年数据预测为例进行了实际应用。
可有效处理小样本、贫信息的不确定性,并在一定预测时段内有良好的预测精度和实用性。
关键词:公路货运量 gm(1,1)模型预测1.现有的预测方法当前普遍存在的对于社会经济的预测方法主要有时间序列法、回归分析法、灰色预测法、指数平滑法、神经网络预测法以及将不同的预测方法结合起来,按照提供信息量的多少和精度的不同,分别取不同的权重形成的组合预测模型。
货运量作为交通运输的一个重要评价指标,对于货运量的预测可以采取不同的方法进行预测,不同的方法提供的有价值信息各不相同,预测精度也各异。
本文主要采用灰色预测模型对公路货运量进行预测。
2.灰色理论与灰色预测模型由于环境对系统的干扰,系统信息中原始数据序列往往呈现离乱情况,离乱数列即为灰色数列或称灰色过程,灰色理论利用那些较少的或不确切的表示系统行为特征的原始数据序列作生成变换后建立微分方程,建立的模型称为灰色模型(greymodel),简称gm模型。
gm(1,1)表示一阶单个变量微分方程,是最常用的灰色预测模型,其形式为:式中,x=x(t),u和b为待估参数。
这个微分方程的解是:3.灰色预测模型的应用3.1灰色模型建模机理灰色系统建模是利用离散的时间序列数据建立近似连续的微分方程模型。
在这一过程中,累加生成运算(ago)是基本手段,其生成函数是灰色建模、预测的基础。
来自所收集的描述过去、现在状况的数据,是构造系统数学模型的依据。
在贫信息情况下,用概率统计方法寻求其统计规律,或用模糊统计方法寻求其隶属规律是困难的,但对于离散过程,在一定程度上相对强化确定性(规律性)和弱化不确定性是可能的,其途径就是通过累加生成运算得到生成时间序列x。
灰色预测建模技术研究
灰色预测建模技术研究一、本文概述随着大数据时代的到来,预测建模技术在众多领域如经济、社会、环境、医疗等中发挥着越来越重要的作用。
灰色预测建模技术,作为一种重要的预测方法,具有对数据量少、信息不完全、规律性不强等问题的处理能力,因此在处理复杂系统预测问题时具有显著优势。
本文旨在对灰色预测建模技术进行深入研究,探讨其理论基础、方法原理、应用现状以及未来发展趋势,以期为该领域的研究者和实践者提供有益的参考和指导。
本文首先对灰色预测建模技术的起源、发展及现状进行概述,明确其在预测领域的重要地位。
接着,详细阐述灰色预测建模技术的基本原理和核心算法,包括灰色模型的基本类型、建模步骤、参数估计方法等,以便读者全面理解并掌握该技术的核心要点。
在此基础上,本文还将对灰色预测建模技术在各个领域的应用案例进行梳理和分析,展示其在解决实际问题中的实际效果和潜在价值。
本文还将对灰色预测建模技术的未来发展趋势进行展望,探讨其在、大数据、云计算等新技术背景下的发展方向和应用前景。
本文将对灰色预测建模技术的局限性进行讨论,并提出相应的改进建议,以期为该领域的技术创新和应用拓展提供新的思路和方向。
本文将全面系统地研究灰色预测建模技术的理论基础、方法原理、应用现状以及未来发展趋势,以期为该领域的研究者和实践者提供有益的参考和指导。
二、灰色预测建模理论基础灰色预测建模技术,作为一种针对“小样本、贫信息”问题的预测方法,其核心在于利用已有的不完全信息进行建模和预测。
该理论由我国著名学者邓聚龙教授提出,并逐步发展成为一门独立的学科——灰色系统理论。
灰色预测建模的基础理论主要包括灰色生成、灰色关联分析、灰色预测等几个方面。
其中,灰色生成是通过累加生成、累减生成等操作,将原始数据转化为规律性更强的新数据序列,从而弱化原始数据的随机性,提高数据的规律性。
灰色关联分析则是通过计算各因素之间的关联度,找出系统中的主要因素,为后续的预测和决策提供依据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
承诺书我们仔细阅读了全国大学生数学建模的竞赛规则()。
我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与本队以外的任何人(包括指导教师)研究、讨论与赛题有关的问题。
我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。
我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。
如有违反竞赛规则的行为,我们愿意承担由此引起的一切后果。
我们的参赛(报名)队号为:参赛组别:本科组参赛队员(先打印,后签名,并留联系电话) :题目节能减排摘要本文通过建立模型对全国各省会城市的大气环境质量做出定量的综合评价,并对未来各地区大气的污染状况进行分析比较。
经过查阅资料得到大量数据,利用MATLAB软件编写程序计算得到了各城市的空气质量综合评价模型;通过曲线拟合和灰度预测模型,分别预测出了未来空气质量的趋势,并比较实际数据得到较好的模型;利用EXCEL软件将各城市每年的空气质量绘制成各种图表,给人更加直观的感受。
在大气环境质量的量化问题上,通过计算空气质量指数AQI来综合评价各城市的空气质量。
利用MATLAB软件编写程序计算得到结果,如2010年空气质量最好的三个城市为海口、拉萨、呼和浩特,其AQI分别为40、48、59;空气质量最差的三个城市为兰州、乌鲁木齐、西安,其AQI分别为10.5、91.5、88。
在空气质量预测问题上,我们分别尝试了曲线拟合与灰度预测两种方法,将2011年的预测值和实际值比较,发现灰度预测在数据量较少情况下更具有优势。
基于此在后续问题处理上都沿用了灰度预测模型,并预测了2012年的空气质量指数和不节能减排情况下2007至2011年的空气质量指数。
解决问题3、4时,用之前建模得到的数据,用EXCEL软件绘制图表,清晰直白的分析节能减排对大气环境质量改善所起作用,文章的最后给出了下一步实施节能减排提出建议。
关键字:AQI MATLAB 灰度预测一、问题的提出环境保护是重大民生问题,随着社会对环境保护的日益重视,人们越来越重视环境的改善,工业革命以来,世界各国尤其是西方国家经济的飞速发展是以大量消耗能源资源为代价的,并且造成了生态环境的日益恶化。
节约能源资源,保护生态环境,已成为世界人民的广泛共识。
我国从2007年8月起,中央财政开始实施节能减排工作,既是对人类社会发展规律认识的不断深化,也是积极应对全球气候变化的迫切需要。
《国民经济和社会发展第十一个五年规划纲要》提出了“十一五”期间单位国内生产总值能耗降低20%左右,主要污染物排放总量减少10%的约束性指标。
根据这两个指标,如中国GDP年均增长一成,五年内就需要节能六亿吨标准煤,减排二氧化硫六百二十多万吨、化学需氧量五百七十多万吨。
试根据我国近年污染物总量减排和大气环境相关数据,并结合经济发展情况,根据附录中的数据,结合你们收集到的相关资料,建立数学模型,完成以下问题:1、建立模型对全国各省会城市的大气环境质量做出定量的综合评价,并对2012年各地区大气的污染状况进行分析比较。
2、假如不采取节能减排,依照过去几年的主要统计数据,对我国大气环境的发展趋势做出预测分析,3、建立模型分析讨论节能减排对大气环境质量改善所起作用。
4、建立模型对节能减排实施前后各省会城市大气环境质量改善情况进行科学分析。
5、对下一步实施节能减排提出建议。
二、问题分析如题所述,环境问题是重大的民生问题,就我国而言,我们在发展经济的同时往往忽略了对环境的保护。
而今人们对环境的重视程度逐步提升,节约能源资源,保护生态环境,已成为世界人民的广泛共识。
本题就是对我国环境质量以及我国主动采取环保措施的效果进行统计与分析:对于问题一中的综合评价各省会城市的大气环境质量,通过查阅《中国统计年鉴》【1】和《环境空气质量指数(AQI)技术规定》【2】,获取相关数据及的计算公式,得出各省会城市在各年的大气环境质量。
对于问题一中的预测2012年大气的污染状况,可以通过数值方法估测2012年的空气质量指数,从而反映2012年的环境质量。
问题二要求依照过去几年的主要统计数据预测出假如2007年不采取节能减排措施时我国大气环境的发展趋势。
利用2003到2006年的数据即可做出预测。
问题三和问题四可以合并为一个问题:讨论节能减排对大气环境质量改善所起作用并对改善情况进行科学分析。
为解决此问题,可以将利用2003至2006年的数据所得的2007至2011年的不节能减排的预测值与这些年的实际空气质量指数值相对比并分析。
问题五是对下一步实施节能减排提出建议。
此问题是根据问题三和四对节能减排政策实施的效果的分析而得的。
三、基本假设1.由于仅已知2003到2011年的数据,且题目要求利用这些数据来进行相关预测,故假设已知数据已足够多,可以进行准确预测;2.各个省份的指标的统计数据信息均由《中国统计年鉴》【1】所得,故假设所有数据真实有效;3.假设二氧化硫、二氧化氮及可吸入颗粒物的浓度即可正确反映出空气质量的状况;4.假设忽略由于自然灾害等原因造成的空气质量突变情况;5.假设节能减排措施是全国统一地在2007年8月开始实施的,各地区同步。
四、符号说明五、模型设计与模型求解5.1问题一:对全国各省会城市的大气环境质量定量综合评价,分析比较2012年各地区大气的污染状况5.1.1、问题分析大气质量优劣与人们的生活息息相关,所以能知道当天或者某一阶段的大气质量十分必要。
题目中问题1要求我们能给出全国个省会城市大气质量综合评价的模型。
我们通过查阅《中国统计年鉴》【1】和《环境空气质量指数(AQI )技术规定》【2】,得知空气质量主要与空气中的二氧化硫、二氧化氮、一氧化碳、臭氧、可吸入颗粒物等的浓度有关,通过计算各成分的IAQI ,取最大值,即为当地空气质量指数AQI ,其值越大,污染越严重。
同时《环境空气质量指数(AQI )技术规定》【2】给出了计算AQI 的公式()Lo Lo P LoHi Lo Hi P IAQI BP C BP BP IAQI IAQI IAQI +---=以及},,,m ax {21n IAQI IAQI IAQI AQI =,《中国统计年鉴》【1】上查阅得到了个年份的二氧化硫、二氧化氮、可吸入颗粒物三种成分的浓度。
我们基于这三种污染物,建立计算AQI 的数学模型。
将得到的数据通过EXCEL 处理,绘出更加直观的各个城市在个个年份间AQI 的变化曲线。
对于2012年各地区大气的污染状况的预测,我们建立了两个模型:模型一通过MATLAB 软件利用已计算出的各城市2003到2010年的空气质量指数来进行三次拟合,得出2011年和2012年的预测值;模型二选择灰色系统预测方法,对2011和2012年的指数进行灰色预测。
比较两种模型得出的2011年预测值与我们查到的2011年的实际值,检验结果是否准确。
5.1.2、模型建立与求解5.1.2.1环境质量综合评价在《环境空气质量指数(AQI )技术规定(试行)》【2】中的污染物项目的空气质量分指数的计算公式()Lo Lo P LoHi Lo Hi P IAQI BP C BP BP IAQI IAQI IAQI +---= (5.1.1) 以及空气质量指数的计算公式},,,m ax {21n IAQI IAQI IAQI AQI = (5.1.2)的基础上计算各地的环境空气质量指数,其中123,,IAQI IAQI IAQI 分别为二氧化硫、二氧化氮和可吸入颗粒物的空气质量分指数,Hi BP 、Lo BP 、P Hi IAQI 、PLo IAQI可通过查表而得,P C 通过查阅各年的《中国统计年鉴》【1】得到。
以由此计算出的各年各省份的AQI 为主要依据,对各城市的环境质量给出评价,AQI 数值越低则环境质量越好。
5.1.2.2.预测2012年空气质量指数(1)曲线拟合模型建立将计算得到的各城市2003到2010年AQI 值进行3次曲线拟合,公式为321234()***f x q x q x q x q =+++ (5.1.3)该计算利用MATLAB 软件进行,得到1q 、2q 、3q 、4q 四个参数后,代入年份编号x ,得出2011和2012 的预测值。
(2)灰度预测模型建立将2003至2010个年份各城市的AQI 值写入数据列(0)(0)(0)(0){(1),(2),,(8)}x x x x = (5.1.4)经过一次累加,得到(1)(1)(1)(1){(1),(2),,(7)}x x x x = (5.1.5)假设(1)x 满足一阶常微分方程(1)(1)dx ax u dt (5.1.6)(1)(1)00()t t x x t ==当时的解为0()(1)(1)0()().a t t u u x t x t e a a --⎡⎤=-+⎢⎥⎣⎦ (5.1.7) 由于年分是离散值,所以公示变为(1)(1)(1)[(1)].ak u u x k x e a a-+=-+ (5.1.8) 灰色建模的途径是一次累加序列(1.2.3)通过最小二乘法来估计常数a 与u 。
利用查分代替微分,保留(1)(1)x 做初值,又因等间隔(1)1,t t t ∆=+-=故公式(5.1.9)变为(0)(1)(0)(1)(0)(1)(2)(2),(3)(3),..............................(7)(7).x ax u x ax u x ax u (5.1.10) 写成向量形式(0)(1)(0)(1)(0)(1)(2)[(2),1](3)[(3),1](7)[(7),1]a x x u a x x u a x x u ⎧⎡⎤=-⎪⎢⎥⎣⎦⎪⎪⎡⎤⎪=-⎪⎢⎥⎨⎣⎦⎪⎪⎪⎡⎤=-⎪⎢⎥⎪⎣⎦⎩(5.1.11)如果用矩阵表示(1)(1)(0)12(1)(1)(0)12(1)(1)(0)12[(2)(1)]1(2)[(3)(2)]1(3).1[(7)(6)]1(7)x x x a x x x u x x x ⎡⎤⎡⎤-+⎢⎥⎢⎥-+⎡⎤⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦⎢⎥⎢⎥-+⎢⎥⎣⎦⎣⎦(5.1.12) 令(0)(0)(0)T ((2),(3),,()).y x x x N =(1)(1)12(1)(1)12(1)(1)12[(2)(1)]1[(3)(2)]1,,[()(1)]1x x a x x B U u x N x N ⎡⎤-+⎢⎥-+⎡⎤⎢⎥==⎢⎥⎢⎥⎣⎦⎢⎥-+-⎢⎥⎣⎦ 则(5.1.12)式就变为y BU =,其最小二乘估计为1ˆˆ()ˆT T a U B B B y u-⎡⎤==⎢⎥⎣⎦ (5.1.13) 把估计值ˆˆau 与代入(1.2.10),得到时间相应方程 ˆ(1)(1)ˆˆˆ(1)(1)ˆˆak u u x k x e a a -⎡⎤+=-+⎢⎥⎣⎦ (5.1.14) 因为得到的是一次累加序列的拟合值,所以要用减法还原,即得到原始序列的拟合值。