第七章 多元回归分析-虚拟变量
虚拟变量回归模型

PART 07
虚拟变量回归模型的发展 趋势和未来展望
发展趋势
模型应用范围不断扩大
随着数据科学和统计学的发展,虚拟变量回归模型的应用范围不断扩大,不仅局限于传统的回归分析,还广泛应用于 分类、聚类、预测等领域。
模型复杂度不断提高
为了更好地处理复杂的数据结构和特征,虚拟变量回归模型的复杂度不断提高,出现了多种新型的模型,如集成学习 模型、深度学习模型等。
医学领域的应用
流行病学研究
在流行病学研究中,利用虚拟变量回归模型分析疾病发病率和死亡 率的影响因素,如年龄、性别、生活习惯等。
临床医学研究
在临床医学研究中,利用虚拟变量回归模型分析治疗效果的影响因 素,如治疗方案、患者特征、疾病严重程度等。
药物研究
在药物研究中,利用虚拟变量回归模型分析药物疗效的影响因素, 如药物剂量、给药方式、患者生理特征等。
模型解释性要求更高
随着人们对数据分析和模型结果的关注度提高,虚拟变量回归模型的解释性要求也更高,需要更加清晰、 直观地解释模型结果和变量之间的关系。
未来展望
模型可解释性研究
未来将更加注重虚拟变量回归模型的可解释性研究,以提高模型结果的透明度和可信度。
新型特征选择和降维技术
随着数据规模的扩大和特征维度的增加,未来将更加关注新型的特征选择和降维技术,以提取关 键特征并降低模型复杂度。
PART 01
引言
目的和背景
探索自变量与因变量之间的关系
虚拟变量回归模型主要用于探索自变量与因变量之间的数量关系,帮助我们理 解不同类别数据对结果的影响。
处理分类变量
当自变量是分类变量时,虚拟变量回归模型能够将这些分类变量转换为一系列 二进制(0和1)的虚拟变量,从而进行回归分析。
虚拟变量回归课件

虚拟变量回归面临的问题
在进行虚拟变量回归时,我们可能会面临多重共线性问题。为了解决这个问 题,我们将介绍哑变量陷阱和特征选 收集数据 2. 对数据进行预处理 3. 分析数据 4. 建立模型 5. 模型的评估与优化
虚拟变量回归
通过介绍虚拟变量回归,我们将探讨其概念、作用以及应用。还将讨论面临 的问题和解决方法,以及如何进行虚拟变量回归并提高模型精度。
什么是虚拟变量回归
虚拟变量回归是一种统计方法,用于处理具有分类特征或非数字特征的数据。 它将非数字变量转换为二元变量,以便在回归模型中使用。
虚拟变量回归的应用
总结
虚拟变量回归具有自身的优点和局限性。我们将总结这些,并探讨未来的发 展方向。最后,我们将分享一些提高模型精度的技巧和建议。
关于虚拟变量的回归

关于虚拟变量(Dummy Variable )的回归1.虚拟变量的性质● 在回归分析中,应变量不仅受量化好了的变量的影响,还受定性性质的变量的影响(如性别,种族,肤色,宗教,国籍,地震等等)● 这类定性变量指某一“性质”或属性出现或不出现。
量化这些变量的方法,是构造一个取值1或0 的人为变量,0代表某一属性不出现,而1代表该属性出现。
● 取这样的0和1 值的变量叫做虚拟变量 (dummy variable)● 在回归分析中,可以清一色的使用虚拟变量,这样的模型叫做方差分析模型(analysis of variance, ANOV A ), 例:i i i u D Y ++=βα其中Y=学院教授的年薪 D i = 1 若是男教授= 0 若是女教授● 学院女教授的平均薪金:α==)0/(i i D Y E 学院男教授的平均薪金:βα+==)1/(i i D Y E● 截距项α给出学院女教授的平均薪金,而斜率系数β告诉我们学院男教授和女教授的平均薪金的差额,α+β反映学院男教授的平均薪金。
● 在大多数经济研究中,一个回归模型既含有一些定量的又含有一些定性的解释变量。
协方差分析(analysis of covariance ANCOV A )2.对一个定量变量和一个两分定性变量的回归● ANCOV 的一个例子:i i i i u X D Y +++=βαα21其中Y i = 学院教授的年薪 X i = 教龄 D i = 1 若是男教授 = 0 若是女教授● 假定和平常一样E (u i )=0,学院女教授的平均薪金:i i i X D Y E βα+==1)0/( 学院男教授的平均薪金:i i i X D Y E βαα++==)()1/(21 ● 图● 以上模型设想学院男教授和女教授的薪金作为教龄的函数,有相同的斜率,但不同的截距● 如果2α统计上显著,则表明有性别歧视● 上述虚拟变量回归模型有以下特点:(1) 为了区分两个类别,男性和女性,我们只引进了一个虚拟变量D i 。
第七章 虚拟变量 虚拟变量回归模型ppt汇总 计量经济学

• 在回归分析中,被解释变量的影响因素 除了量(或定量)的因素还有质(或定 性)的因素,这些质的因素可能 会使回 归模型中的参数发生变化,为了估计质 的因素产生的影响,在模型中就需要引 入一种特殊的变量—虚拟变量。
2020/6/16
(二)作用
• 1、可以描述和测量定性(或属性)因素 的影响;
2、多个因素各两种属性
• 如果有m个定性因素,且每个因素各有两个不同的 属性类型,则引入m个虚拟变量。
• 例2
• 研究居民住房消费函数时,考虑到城乡差异和不同 收入层次的影响将消费函数设定为:
Yt=b0+b1Xt+a1D1t+ a2D2t+ μt
Yt=居民住房消费支出
Xt=居民可支配收入
1城镇居民
2020/6/16
虚拟变量对截距的影响
y
有适龄子女
b0&#
o
图1 虚拟变量对截距的影响
x
2020/6/16
2、乘法方式引入虚拟变量
• 基本思想:以乘法方式引入虚拟解释变量
,是在所设定的计量经济模型中,将虚拟 解释变量与其他解释变量相乘作为新 的解释变量,以达到其调整模型斜率的
目的。 • 该方式引入虚拟变量主要作用:
D=
0 无适龄子女
将家庭教育费用支出函数写成:Yt=b0+b1Xt+aDt+μt 即以加法形式引入虚拟变量。
2020/6/16
子女年龄结构不同的家庭教育 费用支出函数为:
• 无适龄子女家庭的教育费用支出函数(D=0 ):Yt=b0+b1Xt+μt
• 有适龄子女家庭的教育费用支出函数(D=1 ):Yt=(b0+a)+b1Xt+μt
计量经济学导论:ch07 多元回归分析:虚拟变量

wage b1male b2 female b2educ u
将总截距去掉,将每一组的虚拟变量包括进来,
男人的截距是b1,女人的截距是b
,因为没有总
2
截距,所以不存在虚拟变量陷阱。但检验截距的
差值更困难,而且对于不含截距项的回归R2计算
方法没有一致同意的方法。
5
例7.1 是否存在性别歧视
waˆge 1.571.81 female 0.572educ 0.025exp er 0.141tenure
将式7.13中的调整R 平方与把排名作为一个单独变量得到
的调整R 平方比较,前者是0.905,后者是0.836。所以,式
7.13 增加了回归的灵活性。 另外,式 7.13中所有其他变量都变得不显著了,联合显著性
检验给出P值为0.055;当 rank以其原有形式被包括在模型中时, 联合显著性检验的P值在小数点后四位数都是零。
3
Example of d0 > 0
y y = (b0 + d0) + b1x
d= 1
slope = b1
{d0
d= 0
b0
y = b0 + b1x
x
4
wage b0 b1male b2 female b2educ u
由于female male 1, 模型同时引入male和female 将产生完全共线性,产生所谓的虚拟变量陷阱。
1 模型的基组是? 2已婚男性组的截距是? 3已婚女性组的截距是? 4 未婚女性组的截距是?
单身男性,截距为0.321. 0.321+0.213=0.534 0.321-0.110+0.213-0.301=0.123 0.321-0.110=0.211
伍德里奇《计量经济学导论》复习笔记和课后习题详解-含有定性信息的多元回归分析:二值变量

第7章含有定性信息的多元回归分析:二值(或虚拟)变量7.1复习笔记考点一:带有虚拟自变量的回归★★★★★1.对定性信息的描述定性信息是指通常以二值信息(0-1)的形式出现的信息,如性别、是否结婚等。
在计量经济学中,二值变量又称为虚拟变量。
2.只有一个虚拟自变量(1)只有一个虚拟自变量的简单模型考虑决定小时工资的简单模型:wage=β0+δ0female+β1educ+u。
根据多元回归的解释方式,δ0表示控制educ不变时,female变化1单位给wage带来的变化。
假定零条件均值假定E(u|female,educ)=0成立,那么:δ0=E(wage|female=1,educ)-E(wage|female=0,educ),其中female=1表示女性,female=0表示男性。
可以发现,在任意教育水平下,男性与女性的工资差异是固定的,女性工资比男性工资多δ0。
除了β0之外,模型中只需要引入一个虚拟变量。
因为female+male=1,所以引入两个虚拟变量会导致完全多重共线性,即虚拟变量陷阱。
(2)当因变量为log(y)时,对虚拟解释变量系数的解释当变量中有一个或多个虚拟变量,且因变量以对数的形式存在时,虚拟变量的系数可以理解为百分比的变化。
将虚拟变量的系数乘以100,表示的是在保持所有其他因素不变时y 的百分数差异,精确的百分数差异为:100·[exp(∧β1)-1]。
其中∧β1是一个虚拟变量的系数。
3.使用多类别虚拟变量(1)在方程中包括虚拟变量的一般原则如果回归模型具有g 组或g 类不同截距,一种方法是在模型中包含g-1个虚拟变量和一个截距。
基组的截距是模型的总截距,某一组的虚拟变量系数表示该组与基组在截距上的估计差异。
如果在模型中引入g 个虚拟变量和一个截距,将会导致虚拟变量陷阱。
另一种方法是只包括g 个虚拟变量,而没有总截距。
这种方法存在两个实际的缺陷:①对于相对基组差别的检验变得更繁琐;②在模型不包含总截距时,回归软件通常都会改变R 2的计算方法。
虚拟变量回归模型_OK

是一样的,但两者的平均薪金水平相差 a。
可以通过传统的回归检验,对 a的统计显著性进行检验,以
判断男女职工的平均薪金水平是否显著差异。
16
例7.1.4 居民家庭的教育费用支出除了受收入水平的影响之外,还与子女 的年龄结构密切相关。如果家庭中有适龄子女(6-21岁),教育费用支出就 多。因此,为了反映“子女年龄结构”这一定性因素,设置虚拟变量:
当tt*=1978年, Dt = 1
ˆyt = bˆ0 aˆxt + bˆ1 + aˆ xt
32
28
例如,进口消费品数量Y主要取决于国民收入 X的多少,中国在改革开放前后,Y对X的回归关 系明显不同。
这时,可以t*=1978年为转折期,以1978年的 国民收入Xt*为临界值,设如下虚拟变量:
1 Dt = 0
t t* t t*
则进口消费品的回归模型可建立如下:
yt = b0 + b1 xt + a xt xt Dt + ut
9
概念:
同时含有一般解释变量与虚拟变量的模型称为 虚 拟 变 量 模 型或 者 方差 分 析 ( analysis-of variance: ANOVA)模型。
一个以性别为虚拟变量考察企业职工薪金的模型:
Yt = b 0 + b1 Xt + b 2Dt + mt
其中:Yt为企业职工的薪金,Xt为工龄, Dt=1,若是男性,Dt=0,若是女性。
D4=
1 喜欢某种商品 0 不喜欢某种商品
5)表示天气变化的虚拟变量可取为
D5=
1 晴天 0 雨天
6
2.引入虚拟变量的作用 引入虚拟变量的作用,在于将定性因素或属性因素对因变量
第七章多元回归分析虚拟变量
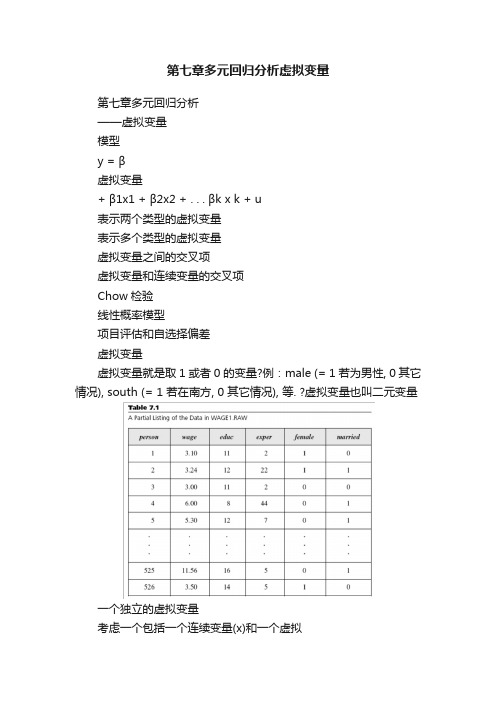
第七章多元回归分析虚拟变量第七章多元回归分析——虚拟变量模型y = β虚拟变量+ β1x1 + β2x2 + . . . βk x k + u表示两个类型的虚拟变量表示多个类型的虚拟变量虚拟变量之间的交叉项虚拟变量和连续变量的交叉项Chow检验线性概率模型项目评估和自选择偏差虚拟变量虚拟变量就是取1 或者0 的变量?例:male (= 1 若为男性, 0 其它情况), south (= 1 若在南方, 0 其它情况), 等. ?虚拟变量也叫二元变量一个独立的虚拟变量考虑一个包括一个连续变量(x)和一个虚拟变量(d)的模型y = β+ δ0d + β1x + u这可以解释成截距项的变化若d = 0, 那么y = β+ β1x + u若d = 1, 那么y = (β+ δ0) + β1x + ud = 0 的样本是参照组δ0 > 0 的例子y y = (β0 + δ0) + β1xd = 1{ δslope = β1d =0 }βy = β0 + β1xx从多个数值的类型变量到虚拟变量?我们可以用虚拟变量来控制有多种类型因素?假设样本中的个人是中学辍学或者仅仅中学毕业或者大学毕业现在要拿仅仅中学毕业和大学毕业的人和中学辍学的人比较定义hsgrad = 1 如果仅仅是中学毕业, 0 其它情况; colgrad = 1 如果大学毕业, 0 其它情况多个数值的类型变量(续)?任何类型变量都可以变成一组虚拟变量?因为参照组由常数项表示了, 那么如果一共有n 个类型,就应该由n –1 虚拟变量如果有太多的类型,通常应该对其进行分组例:前10 , 11 –25, 等虚拟变量之间的交叉项求虚拟变量的交叉项就相当于对样本进行进一步分组例:有男性(male)的虚拟变量和hsgrad(仅仅中学毕业)和colgrad (大学毕业)的虚拟变量加入male*hsgrad 和male*colgrad, 共有五个虚拟变量–> 共有六种类型参照组是女性中学辍学的人此时hsgrad 代表女性仅仅中学毕业者, colgrad 表示女性大学毕业者交叉项表示男性仅仅中学毕业者和男性大学毕业者虚拟变量之间的交叉项(续)?模型可以写成y = β0 + δ1male + δ2hsgrad +δ3colgrad + δ4male*hsgrad + δ5male*colgrad+ β1x + u, 那么:若male = 0 且hsgrad = 0 且colgrad = 0则y = β0 + β1x + u若male = 0 且hsgrad = 1 且colgrad = 0则y = β0 + δ2hsgrad + β1x + u若male = 1且hsgrad = 0且colgrad = 1则y = β0 + δ1male + δ3colgrad + δ5male*colgrad+ βx + u1其它变量与虚拟变量的交叉项?也可以考虑虚拟变量d 和连续变量x 之间的交叉项y = β+ δ1d + β1x + δ2d*x + u若d = 0, 那么y = β+ β1x + u若d = 1, 那么y = (β+ δ1) + (β1+ δ2) x + u这里的两种情况可以看成是斜率的变化δ0 > 0 且δ 1 < 0的例子yy = β+ β1xd = 0d = 1y = (β0 + δ0) + (β 1 + δ1) x。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
δ0 > 0 的例子
y
y = (β0 + δ0) + β1x
d=1 slope = β1 d=0
δ0
{
} β0
y = β0 + β1x
x
从多个数值的类型变量到虚拟变量
• 我们可以用虚拟变量来控制有多种类型因素 • 假设样本中的个人是中学辍学或者仅仅中学毕业 或者大学毕业 • 现在要拿仅仅中学毕业和大学毕业的人和中学辍 学的人比较 • 定义hsgrad = 1 如果仅仅是中学毕业, 0 其它情 况; colgrad = 1 如果大学毕业, 0 其它情况
线性概率模型(续)
• 即使概率的预测值在 [0,1] 范围内, 我们也可能估 计出x 的变化对成功概率的影响大于+1 或者小于 –1, 因此最好用x 均值附近的变化 • 此外,该模型的扰动项不满足同方差的假设,因 此会对检验产生影响 • 虽然有以上不足,线性概率模型还是可以在y 为 二元变量的情况下作为初步的模型来使用
事实上是经济过程检验
• 做模型回归时我们假设所有的样本观测值 都来自同一个总体,如果总体发生改变, 那么模型参数也将发生改变,因此检验总 体也就是经济过程是否发生改变是用计量 进行经济研究的主要步骤。或者是在进行 经济计量研究时必须考虑的一个重要步 骤。其具体方法是:
• 假设我们在1到n个时期研究经济的结构关系,得到如 下的回归模型: Y=b0+b1X1+b2X2+…+bkXk+e 在第q期(1<q < n)曾出台一个经济政策,为检验该 经济政策是否影响我们所研究的经济结构可作如下检 验: 1、用1到q个观测值对模型进行回归,得到回归残差的平 方和,记为ESS1;用q+1到n个观测值对模型进行回 归,得到回归残差平方和,记为ESS2,并令 ESSUR= ESS1+ ESS2。 2、用1到n个观测值对模型进行回归,得到回归残差平方 和,记为ESSR,这可用下面的F统计量检验在k时期出 台的经济政策是否导致经济结构变化: ( ESS R − ESSUR ) / k F ( k , n − 2k ) = ESSUR /(n − 2k )
其它变量与虚拟变量的交叉项
• 也可以考虑虚拟变量 d 和连续变量 x 之间 的交叉项 • y = β0 + δ1d + β1x + δ2d*x + u • 若 d = 0, 那么 y = β0 + β1x + u • 若 d = 1, 那么 y = (β0 + δ1) + (β1+ δ2) x + u • 这里的两种情况可以看成是斜率的变化
SSR1 + SSR2 k +1
Chow 检验(续)
• Chow 检验其实就是一个对排除性限制条 件的F 检验, 我们注意到 SSRur = SSR1 + SSR2 • 注,我们一共有k + 1 限制条件 (针对每 一个斜率和一个截距) • 注, 无限制条件的模型估计了两个截距项 和两组不同的系数,因此自由度(df)为 n – 2k – 2
例、ห้องสมุดไป่ตู้油消费市场的结构检验
变量:1960-1995 数据Taba58 G=总汽油消费、Pg=汽油的价格指数、Y=人均可支配收 入、Pnc=新车的价格指数、Puc=旧车的价格指数、Ppt= 公共交通的价格指数、Pd=耐用消费品的总价格指数、 Pn=非耐用消费品的总价格指数、Ps=服务的总价格指 数、Pop=美国的总人口数(百万) 回归方程: Log(G/Pop)=b1+b2logY+b3log(Pg)+b4log(Pnc)+b5log(Puc)+e 利用1960到1995的样本数据检验1960到1973和1974到1995 的市场结构是否发生变化的问题。
第七章 多元回归分析 ——虚拟变量
• • • • • • • • • • 模型 y = β0 + β1x1 + β2x2 + . . . βkxk + u 虚拟变量 表示两个类型的虚拟变量 表示多个类型的虚拟变量 虚拟变量之间的交叉项 虚拟变量和连续变量的交叉项 Chow检验 线性概率模型 项目评估和自选择偏差
作业:pp241-244 7.3 7.5 7.6
虚拟变量
• 虚拟变量就是取 1 或者 0 的变量 • 例:male (= 1 若为男性, 0 其它情况), south (= 1 若在南方, 0 其它情况), 等. • 虚拟变量也叫二元变量
一个独立的虚拟变量
• 考虑一个包括一个连续变量(x)和一个虚拟 变量(d)的模型 • y = β0 + δ0d + β1x + u • 这可以解释成截距项的变化 • 若 d = 0, 那么 y = β0 + β1x + u • 若 d = 1, 那么 y = (β0 + δ0) + β1x + u • d = 0 的样本是参照组
在项目评估中的注意之处
• 当我们考查一个项目的影响时,我们常会 用到虚拟变量 • 例如,我们会遇到一些接受过工作培训或 福利项目的人的数据,等等 • 需要记住的是:通常个人会对是否参与某 个项目做出选择的,这样就可能存在自选 择的问题
自选择的问题
• 如果我们能够控制住所有与是否参加项目 以及相应结果相关的因素,那么自选择也 就不是一个问题 • 但是,通常存在一些不可观察的因素与参 与行为相关 • 在这种情况下,项目效果的估计就是有偏 的,我们也不应该在此基础上进行政策的 制定!
线性概率模型
• 当y 为二元变量时:P(y = 1|x) = E(y|x), 我 们可以将模型设为 • P(y = 1|x) = β0 + β1x1 + … + βkxk • 因此, βj 应该解释成xj 的变化对成功(y = 1)概率的 影响 • y 的预测值就是成功概率的预测值 • 潜在问题是概率的预测值可能会在 [0,1]之 外
多个数值的类型变量(续)
• 任何类型变量都可以变成一组虚拟变量 • 因为参照组由常数项表示了, 那么如果一共 有n 个类型,就应该由n – 1 虚拟变量 • 如果有太多的类型,通常应该对其进行分 组 • 例:前10 , 11 – 25, 等
虚拟变量之间的交叉项
• 求虚拟变量的交叉项就相当于对样本进行进一 步分组 • 例:有男性(male)的虚拟变量和hsgrad (仅仅中学毕业) 和 colgrad (大学毕业)的 虚拟变量 • 加入 male*hsgrad 和 male*colgrad, 共有五个 虚拟变量 –> 共有六种类型 • 参照组是女性中学辍学的人 • 此时hsgrad 代表女性仅仅中学毕业者, colgrad 表示女性大学毕业者 • 交叉项表示男性仅仅中学毕业者和男性大学毕 业者
δ0 > 0 且 δ1 < 0的例子
y y = β0 + β1x d=0 d=1 y = (β0 + δ0) + (β1 + δ1) x x
检验不同组之间的差异
• 为了检验一个回归方程对不同的组是否应 该取不同的参数,我们可以检验表示组的 虚拟变量及其和所有其他x变量的交叉项的 显著性 • 因此可以估计有所有交叉项和没有交叉项 两种情况下的模型,然后构造F 统计量, 但 这种方法不容易把握
Chow 检验
• 也可以仅仅做没有交叉项的回归来构造适当的F统计 量 • 如果我们对第一组样本做没有交叉项的回归,得到 SSR1, 然后再对第二组样本做同样的回归,得到 SSR2 • 再同样对所有样本做没有交叉项的回归,得到 SSR, 那么
[ SSR − (SSR1 + SSR2 )] [n − 2(k + 1)] F= •
虚拟变量之间的交叉项(续)
• 模型可以写成 y = β0 + δ1male + δ2hsgrad + δ3colgrad + δ4male*hsgrad + δ5male*colgrad + β1x + u, 那么: • 若 male = 0 且 hsgrad = 0 且 colgrad = 0 则 y = β0 + β1x + u • 若 male = 0 且 hsgrad = 1 且 colgrad = 0 则 y = β0 + δ2hsgrad + β1x + u • 若male = 1且hsgrad = 0且 colgrad = 1 则 y = β0 + δ1male + δ3colgrad + δ5male*colgrad + β1x + u