SPSS与研究方法 CH13
结核感染T淋巴细胞斑点试验技术在学校结核密切接触者中筛查潜伏结核感染的应用

=0.07,P<O.01),但T.sPOT.11B结果不受BcG接种的影响,特异性优于髑T。 【关键词】结核;接触者追踪;结核菌素试验
2.咖:由经过专门培训的护士用皮内注射法
(Montous法,1908年)做佟T实验的接种和判定。 试剂为结核菌素纯蛋白衍生物(PPD5TU),成都生 物制品研究所生产,批号00720070101。注射部位
在左前臂背侧上1/3处,皮内注射0.1
表l御反应硬结平均直径[人数(%)]
IIll,聊试验
结果在72 h后测定,硬结平均直径=(横径+纵
同学院(金融管理学院)437名(54.4%);男生392
进行统计学分析。组间比较采用,检验,2种试验
方法的比较采用McNemaur检验,惭>O.75为一
差异有统计学意义。
结 果
致性较好,K卿口<O.4为一致性较差,P<0.05为
1.聊试验结果:803名学生中,聊反应硬结
平均直径<5、5一<lO、10一<15和≥20 mm,分别 为34.1%(274/803),16.8%(135/803),26.8%
P=O.28).Condusi蚰s
mte
of L1’BI in the coUege w鹊9.1%.During tlle latent TB scree血ng,雒∽ement between
T.SPOT.TB is
not
Wjth T.SPOT.TB positive results鹊山e standard for dia印08is of latent TB,the tests w酗low
spss中怎样进行fisher精确概率法统计
spss中怎样进行fisher精确概率法统计最短距离法是把两个类之间的距离定义为一个类中的所有案例与另一类中的所有案例之间的距离最小者.缺点是它有链接聚合的趋势,因为类与类之间的距离为所有距离中最短者,两类合并以后,它与其他类之间的距离缩小了,这样容易形成一个较大的类.所以此方法效果并不好,实际中不太用. 2.最长距离法是把类与类之间的距离定义为两类中离得最远的两个案例之间的距离.最长距离法克服了最短距离法链接聚合的缺点,两类合并后与其他类的距离是原来两个类中的距离最大者,加大了合并后的类与其他类的距离. 3.平均联结法,最短最长距离法都只用两个案例之间的距离来确定两类之间的距离,没有充分利用所有案例的信息,平均联结法把两类之间的距离定义为两类中所有案例之间距离的平均值,不再依赖于特殊点之间的距离,有把方差小的类聚到一起的趋势,效果较好,应用较广泛. 4.重心法,把两类之间的距离定义为两类重心之间的距离,每一类的重心是该类中所有案例在各个变量的均值所代表的点.与上面三种不同的是,每合并一次都要重新计算重心.重心法也较少受到特殊点的影响.重心法要求用欧氏距离,其主要缺点是在聚类过程中,不能保证合并的类之间的距离呈单调增加的趋势,也即本次合并的两类之间的距离可能小于上一次合并的两类之间的距离. 5.离差平方和法,也称沃尔德法.思想是同一类内案例的离差平方和应该较小,不同类之间案例的离差平方和应该较大.求解过程是首先使每个案例自成一类,每一步使离差平方和增加最小的两类合并为一类,直到所有的案例都归为一类为止.采用欧氏距离,它倾向于把案例数少的类聚到一起,发现规模和形状大致相同的类.此方法效果较好,使用较广.个独立样本率比较的χ2检验属四格表资料χ2检验。
这类资料在医学研究中较为多见。
例如比较两种方法治疗某种疾病的有效率是否相同?治疗结果如下:有效无效有效率(%)试验组12 1 92.31对照组 3 8 27.27可以在SPSS中进行统计分析,具体操作详见附件中的.EXE文件。
植物组织中有机酸的提取方法比较

收稿日期 : 2005 01 11 基金项目 : 国家自然科学基金资助项目 (30270790) ; 中国博士后科学基金资助项目 (2003033494) 作者简介 : 董园园 ( 1981 ) , 硕士研究生 , E2mail: qianlicao99 @ sina1com。3 通讯作者 Corresponding author: 沈其荣 ( 1957 ) , 教
有机酸广泛存在于水果 、蔬菜中 , 其种类和含量是决定果蔬风味的重要指标 , 也是果蔬成熟度 、耐 储藏性 、加工性的重要依据 , 因此测定果蔬中有机酸的种类及含量具有重要的意义 。有机酸的测定方法 主要有 3种 , 蒸馏水直接提取法 [ 1, 2 ] , 乙醇 旋转蒸发提取法 [ 3~5 ] , 乙氰 、甲醇提取法 [ 6, 7 ] 。由于乙氰 、 甲醇成本高且有毒性 , 因此较少使用 。根系分泌物中有机酸含量的分析步骤通常采用蒸馏水提取 —冷冻 干燥 (或旋转蒸发 ) 浓缩 —溶解 —HPLC分析 [8 ] 。为了确保植物组织中有机酸的高效提取和分离 , 我们 也将此法运用于植物组织中有机酸的分析 。
11412 80%乙醇 旋转蒸发浓缩提取 (简写为醇提 , E) 参照李连朝等方法 [3 ] 。将 11411中提取液改
为 80%乙醇溶液 , 称样 、研磨 、水浴 、离心步骤同上 。番茄沉淀用 10 mL 80%乙醇溶液洗涤 2次 , 上
清液定容至 50 mL; 不结球白菜叶片沉淀用 2 mL 80%乙醇溶液洗涤 2次 , 上清液定容至 10 mL , 于旋转 蒸发仪 75 ℃蒸干 , 番茄残渣加 20 mL (不结球白菜叶片用 5 mL ) 流动相溶解 , 过 0122μm 滤膜 , 然后
弹力带抗阻运动对高龄老年人工作记忆的影响—来自fNIRS_的证据

专题探索弹力带抗阻运动对高龄老年人工作记忆的影响—来自fNIRS的证据蔡治东1,2,江婉婷2,王 兴2(1. 苏州科技大学体育部,江苏苏州 215009;2. 上海体育大学体育教育学院,上海 200438)摘 要: 目的观察长期弹力带运动改善高龄老年人工作记忆的效果,采用近红外光谱技术探究可能的脑机制。
方法将60名高龄老年人随机分为弹力带组与对照组,弹力带组接受16周、每周3次、每次40 min的弹力带干预,对照组保持原有生活状态;采集实验前后受试者完成工作记忆任务期间的前额叶血流动力学指标。
结果反应时的时间×组别交互效应具有统计学意义(P<0.001);正确率的时间×记忆负荷交互效应具有统计学意义(P=0.003);正确反应率的时间×组别交互效应具有统计学意义(P<0.001);氧合血红蛋白结果显示,9条通道组别×时间×记忆负荷交互效应均具有统计学意义(P<0.002)。
结论规律性中低强度弹力带抗阻运动能改善高龄老年人的工作记忆表现;在低记忆负荷时前额叶激活不明显,中、高记忆负荷时双侧腹外侧前额叶、左背外侧前额叶、左额极区显著激活,这种前额叶激活优化模式可能是弹力带抗阻运动改善工作记忆的脑机制。
关键词: 高龄老年人;执行功能;功能性近红外光谱;抗阻运动;弹力带;脑激活中图分类号: G804.7文献标志码:A文章编号:1000-5498(2024)03-0065-10DOI:10.16099/j.sus.2023.01.09.0002随着我国老龄化的不断深入,高龄化趋势日益凸显,高龄老年人认知功能损害已成为影响其生活质量的重要因素。
我国60~69岁、70~79岁、80~89岁、90岁及以上4个年龄段轻度认知障碍(Mild CognitiveImpairment,MCI)的患病率分别为11.83%、19.23%、24.15%、32.46%,痴呆患病率分别为2.89%、8.38%、14.35%、31.23%[1],随着年龄的增大,MCI、痴呆的患病率急剧增加。
SPSS—非线性回归(模型表达式)案例解析

SPSS—非线性回归(模型表达式)案例解析2011-11-16 10:56由简单到复杂,人生有下坡就必有上坡,有低潮就必有高潮的迭起,随着SPSS 的深入学习,已经逐渐开始走向复杂,今天跟大家交流一下,SPSS非线性回归,希望大家能够指点一二!非线性回归过程是用来建立因变量与一组自变量之间的非线性关系,它不像线性模型那样有众多的假设条件,可以在自变量和因变量之间建立任何形式的模型非线性,能够通过变量转换成为线性模型——称之为本质线性模型,转换后的模型,用线性回归的方式处理转换后的模型,有的非线性模型并不能够通过变量转换为线性模型,我们称之为:本质非线性模型还是以“销售量”和“广告费用”这个样本为例,进行研究,前面已经研究得出:“二次曲线模型”比“线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的趋势变化”,那么“二次曲线”会不会是最佳模型呢?答案是否定的,因为“非线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的变化趋势” 下面我们开始研究:第一步:非线性模型那么多,我们应该选择“哪一个模型呢?”1:绘制图形,根据图形的变化趋势结合自己的经验判断,选择合适的模型点击“图形”—图表构建程序—进入如下所示界面:点击确定按钮,得到如下结果:放眼望去, 图形的变化趋势,其实是一条曲线,这条曲线更倾向于"S" 型曲线,我们来验证一下,看“二次曲线”和“S曲线”相比,两者哪一个的拟合度更高!点击“分析—回归—曲线估计——进入如下界面在“模型”选项中,勾选”二次项“和”S"两个模型,点击确定,得到如下结果:通过“二次”和“S“ 两个模型的对比,可以看出S 模型的拟合度明显高于“二次”模型的拟合度(0.912 >0.900)不过,几乎接近接着,我们采用S 模型,得到如下所示的结果:结果分析:1:从ANOVA表中可以看出:总体误差= 回归平方和 + 残差平方和(共计:0.782)F统计量为(240.216)显著性SIG为(0.000)由于0.000<0.01 (所以具备显著性,方差齐性相等)2:从“系数”表中可以看出:在未标准化的情况下,系数为(-0.986)常数项为2.672所以 S 型曲线的表达式为:Y(销售量)=e^(b0+b1/t) = e^(2.672-0.986/广告费用)当数据通过标准化处理后,常数项被剔除了,所以标准化的S型表达式为:Y(销售量) = e^(-0.957/广告费用)下面,我们直接采用“非线性”模型来进行操作第一步:确定“非线性模型”从绘图中可以看出:广告费用在1千万——4千多万的时候,销售量增加的跨度较大,当广告费用超过“4千多万"的时候,增加幅度较小,在达到6千多万”达到顶峰,之后呈现下降趋势。
SPSS单因素方差分析步骤-单因素显著性分析步骤.docx

SPSS教程:单因素方差分析用来测试某一个控制变量的不同水平是否给观察变量造成显著差异和变动。
方差分析前提:不同水平下,各总体均值服从方差相同的正态分布。
所以方差分析就是研究不同水平下各个总体的均值是否有显著的差异。
统计推断方法是计算F统计量,进行F检验,总的变异平方和SST, 控制变量引起的离差SSA(BetWeen Group离差平方和),另一部分随机变量引起的SS(组内Within Group离差平方和),SST=SSA+SSE方法/步骤1.计算检验统计量的观察值和概率P_直:SPSS自动计算F统计值,如果相伴概率P小于显著性水平a,拒绝零假设,认为控制变量不同水平下各总体均值有显著差异,反之,贝S相反,即没有差异。
ANOVA2.方差齐性检验:控制变量不同水平下各观察变量总体方差是否相等进行分析。
采用方差同质性检验方法(Homogeneity OfVariance ),原假设“各水平下观察变量总体的方差无显著差异,思路同SPSS两独立样本t检验中的方差分析”。
图中相伴概率0.515大于显著性水平0.05 ,故认为总体方差相等。
趋势检验:趋势检验可以分析随着控制变量水平的变化,观测变量值变化的总体趋势是怎样的,线性变化,二次、三次等多项式。
趋势检验可以帮助人们从另一个角度把握控制变量不同水平对观察0.05 ,故不符合线性关系SH≠⅛≡⅛1frS⅛k¾iT= ×∣M*P55CΓ1≡,華脛陰方基丘X∣+G l9 ⅛ ® http⅛r^aπ.balduxoιr√alb⅛m∕375c8el⅛935a2a25f2a229cb i h ≠ 轉肩駅站.≡ghaolΞ3 冏百∙1S∣⅛]ERSfSS⅛fτ⅛≤t¾r= X ∣i⅛] ⅞p⅝!∏≡ : ⅛S(W5⅛ X ∣4∣0 1Q ⅛ φ http^⅛r t gyaπ.⅛ldu.corr√al⅛jm∕37Bc⅛l⅛9J5a2i25f2a229cb.lι fi⅞⅞∣Ξ) π常网⅛S .⅛JhHO123 ⅛]≡.*变量总体作用的程度。
分裂型人格创造性思维大脑皮层的激活特征研究

分裂型人格创造性思维大脑皮层的激活特征研究田玉梅;薛小保;刘敏【摘要】目的研究分裂型人格创造性思维大脑皮层的激活特征.方法在高校中招募大学生志愿者共100名,采用分裂型人格量表(SPQ)进行问卷调查,总分前10%者为高分裂型人格个体(HS)共22名(HS组),总分后10%者为低分裂型人格个体(LS)共24名(LS组).比较两组的创造力任务行为结果、任务思考期功能近红外脑成像(fNIRS)大脑皮层激活通道氧合血红蛋白(Hbo)相对浓度变化.结果 HS组的非常规用途任务新颖性和流畅性、外星生物绘画任务差异性和新颖性均显著高于LS组(P<0.05);在任务思考期,HS组在Ch31、Ch35、Ch3、Ch7、Ch11、Ch14、Ch15、Ch18、Ch22通道的Hbo相对浓度显著低于LS组(P<0.05).结论高分裂型人格者的创造力显著高于低分裂型人格者,其创造性思维大脑皮层以角回、前额、前额叶背外侧皮质激活水平较低为特征.【期刊名称】《西南国防医药》【年(卷),期】2018(028)011【总页数】3页(P1061-1063)【关键词】分裂型人格;创造性思维;大脑皮层;激活特征;氧合血红蛋白【作者】田玉梅;薛小保;刘敏【作者单位】710061西安,西安市精神卫生中心康复部;710061西安,西安市精神卫生中心康复部;710061西安,西安市精神卫生中心康复部【正文语种】中文【中图分类】R749.91分裂型人格是指在基因层面具有精神分裂症倾向的个体,具有精神分裂症的易感人格特质,是一种处于正常人格与精神分裂症人格之间的人格状态,表现为类似精神分裂症的症状,包括奇异思维和言语、不寻常知觉体验、魔术性思维等[1]。
但分裂型人格是一种相对稳定的人格状态,只是发展为精神分裂症的概率高于正常人。
创造力是指产生新颖性和适应性观点或产品的能力,是人们解决实际问题、认知社会、取得成功不可或缺的能力[2]。
创造性思维过程是创造力的一部分,包括发散性思维(DT)和聚合性思维(CT),创造力需要 DT与 CT相结合,CT包含了评判性思维,需要对DT的结果进行判断[3]。
spss卡方检验

spss卡方检验SPSS卡方检验SPSS(统计软件包 for the Social Sciences)是一种功能强大的统计软件,在社会科学、商业智能和市场调研等领域得到广泛应用。
其中,卡方检验是SPSS中常用的统计方法之一。
本文将介绍SPSS 中使用卡方检验进行数据分析的基本步骤、原理和注意事项。
一、卡方检验的基本概念卡方检验,又称为卡方拟合优度检验,用于比较观察样本与理论预期分布之间的差异。
它基于卡方统计量,可以用于分析分类数据的关联性和独立性。
卡方检验的结果可以帮助研究人员判断观察数据与理论模型之间的差异程度以及独立性。
二、SPSS中进行卡方检验的步骤1. 收集数据并导入到SPSS中。
2. 在SPSS中选择“分析”菜单,点击“描述统计”下的“交叉表”。
3. 在交叉表对话框中,选择需要比较的两个变量。
4. 点击“统计”按钮,选择“卡方”选项。
5. 点击“继续”按钮,然后点击“OK”按钮生成交叉表结果。
三、SPSS卡方检验的原理SPSS中的卡方检验基于卡方统计量,该统计量用于衡量观察值与理论期望值之间的差异。
卡方统计量的计算公式如下:\\[ X^2 = \\sum \\frac{(O-E)^2}{E} \\]其中,O表示观察值,E表示理论期望值。
卡方统计量服从自由度为(k-1) × (m-1)的卡方分布,其中k表示列数,m表示行数。
通过计算卡方统计量,可以得到卡方值和P值。
如果P值小于设定的显著性水平(通常为0.05),则认为观察值与理论期望值存在显著差异,拒绝原假设。
四、卡方检验的应用场景卡方检验通常用于以下几种情况:1. 检验分类变量之间的关联性。
例如,研究某一地区的居民性别与吸烟习惯之间的关系。
2. 检验分类变量与某一特定属性的关联性。
例如,研究某个产品的用户满意度与不同年龄段之间的关系。
3. 检验分类变量的分布是否服从某一特定的理论分布。
例如,研究某一地区的选民支持率是否符合某个政党的预期。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
圖13-5 「Discriminant Analysis: Classification」視窗設定
• 在「Discriminant Analysis」視窗中,按〔Sa ve〕,就會產生「Discriminant Analysis: Sa ve」視窗,我們選定的情形如圖13-6所示。
圖13-6 「Discriminant Analysis: Save」視窗設定
圖13-2 「Discriminant analysis: Define」視窗設定
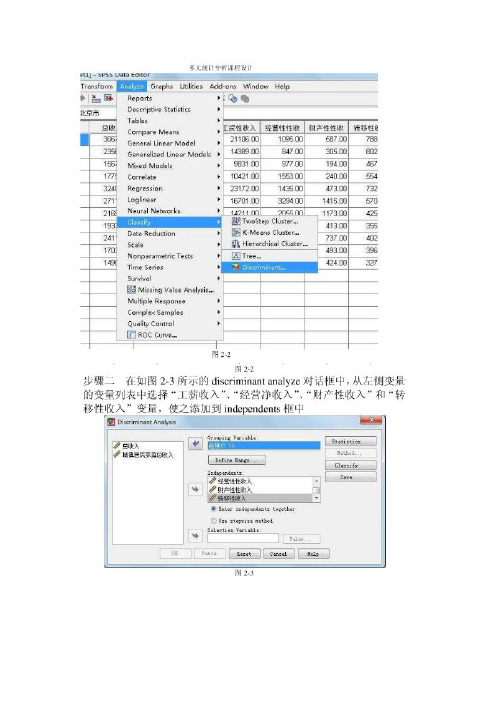
• 將「經驗」、「在校成績」、「測驗成績」這 些自變數選入「Independents」(自變數)下 的方盒內,如圖13-3所示。可以用SPSS內定的 「Enter independents together」(使用所有 變數)或者「Use stepwise method」(使用逐 步方法)。
13.2 區別分析-區別二群
• 大海軟體公司裡面具有企管碩士學位的幹部30 名,分別有15名「前途光明」的幹部,15名 「前途黯淡」的幹部。該公司的總經理想要了 解,在人力資源管理中的員工錄用上,應特別 重視「經驗」、「在校成績」、「測驗成績」 中的什麼因素
• 開啟檔案(檔案名稱:...\Chap13\Discriminant Two Groups.sav)。此檔案包括了組別(分為二組, 以1表示「前途光明」組,以2表示「前途黯淡」 組)、經驗(工作經驗)、在校成績(在校成績總 平均)、測驗成績(應徵測驗成績)。組別為名義 變數,其他的變數為區間變數。 • 進入SPSS,按〔Analyze〕、〔Classify〕、〔Dis criminant〕(〔分析〕〔分類〕〔判別〕),在 所產生的「Discriminant Analysis」視窗中,將 「組別」變數選入右邊的「Grouping Variable」 (分組變數)下的空格中,選取〔分組(??)〕, 按其下的〔Define Range〕(定義範圍),在「Di scriminant analysis: Define」視窗中的「Minim um:」(最小值)填入「1」,「Maximum:」(最大 值)填入「2」,如圖13-2所示。表示我們是將資 料分成二組。
• 區別分析是一種相依方法,其準則變數(依變
數)為事先訂定的類別或組別。其預測變數(自變 數)是區間資料或比率資料。 • 區別分析的目的是: 1. 找出預測變數(自變數)的線性組合,使組間變異 相對於組內變異的比值為最大。 2. 找出哪些預測變數具有最大的區別能力。 3. 根據新受試者的預測變數的數值,將該受試者指派 到某一群體。換句話說,在區別方程式建立之後, 研究者可將某人的有關資料(這些資料是在模式中 的變數)代入這個方程式中,以了解這個人被歸類 到哪一群。 4. 檢定各係數與0之間是否有顯著性的差異,以及檢 定各組的重心(centroid)是否有顯著性的差異。
• 區別函數的數目等於從分組數目減一與 自變數數目(有幾個自變數)中取最小 的數目。例如,分組數目有三個(分成 三組),自變數數目有三個,則區別函 數的數目等於Min(分組數目減一,自變 數數目)Min2。因此會有兩個區別函數。
• 在單因子多變量變異數分析的檢定達到顯著水 準之後,進一步可採用區別分析。區別分析適 用的情況是依變數有一個且為名義變數,自變 數可為區間變數或名義變數。如自變數為區間 變數,則可進行區別分析或者Logistic迴歸分 析,如果自變數為名義變數則要進行虛擬變數 區別分析,如圖13-1所示。
• 從「各組平均數的相等性檢定」表中可知,經驗 在二組(前途光明組及前途黯淡組)的平均數有 顯著差異,顯著性=0.003,達到顯著水準。在校 成績及測驗成績均未達顯著水準,表示在校成績 及測驗成績在二組(前途光明組及前途黯淡組) 的平均數均沒有顯著差異。
• Wilks‘ Lambda可用來檢定虛無假說。在下表中, 「經驗」、「在校成績」、「測驗成績」的顯著性分別為 0.003、0.870、0.594,在α=0.05之下, 我們要棄卻d1=0的虛無假設(經驗在二組上無顯著差異), 而認為經驗在二組上有顯著差異。
• 圖13-7顯示了儲存的資料,SPSS的內定名稱是D is_1、Dis1_1、Dis1_2、Dis2_2。以第一名觀 察值來看,在SPSS處理後,他被分到第一組 (前途光明組),他的判別分數(discriminan t score)是3.58。他被分到第一組的機率是0. 98,被分到第二組的機率是0.02。 • 圖13-8顯示了SPSS的內定名稱Dis_1、Dis1_1、 Dis1_2、Dis2_2的註解(所代表的意義)。
• 描述性統計量(descriptives):
• 矩陣(Matrices):
• 區別函數係數(Function Coefficients):
• 在「Discriminant Analysis」視窗中,按〔Class ify〕,就會產生「Discriminant Analysis: Clas sification」視窗,我們選定的情形如圖13-5所 示。 • 在「Prior Probabilities」(事前機率)的方盒下, 使用內定的「All groups equal」(所有組別大小均 等),也就是將所有組別的事前機率假設為相等。 • 在「Use Covariance Matrix」(使用共變異數矩陣), 使用內定的「Within-groups」(組內變數),表示以組內 的共變異數矩陣來將觀察值加以分類。在「Display」 (顯示)下的方盒內,點選「Summary table」 (分類統計表)。
• 複區別分析的處理與13.2節所說明的大同小異。開 啟檔案(檔案名稱:...\Chap13\Discriminant Th ree Groups.sav)。此檔案包括了組別(分為三組, 以1表示「前途光明」組,以2表示「前途普通」組, 以3表示「前途黯淡」組)、經驗(工作經驗)、 在校成績(在校成績總平均)、測驗成績(應徵測 驗成績)。組別為名義變數,其他的變數為區間變 數。 • 首先進入SPSS,按〔Analyze〕、〔Classify〕、 〔Discriminant〕(〔分析〕〔分類〕〔判別〕), 在所產生的「Discriminant Analysis」視窗中, 將「組別」變數選入右邊的「Grouping Variable」 (分組變數)下的空格中,選取〔分組(??)〕, 按其下的〔Define Range〕(定義範圍),在「Di scriminant analysis: Define」視窗中的「Minim um:」(最小值)填入「1」,「Maximum:」(最大 值)填入「3」,表示我們是將資料分成三組。
從典型區別函數係數來看,「經驗」的相對重要性較高。
• 結構矩陣(Structure Matrix)顯示,區別變 數和標準化典型區別函數之間的合併後組內相 關。變數係依函數內相關的絕對值大小加以排 序。相關係數的絕對值愈大者,表示此變數與 區別函數的相關愈高。從結構矩陣來看,「經 驗」與區別函數的相關最高。
• 「對數行列式」表中,如果變數之間具有高度多元共線 性問題,則對數行列式值(log determinant)會趨近 於0,而且等級(rank)會不等於自變數的數目。 • 此表顯示,「前途光明」組、「前途黯淡」組的對數行 列式值分別為12.783、12.657,與0距離相當大,而且等級 (=3),與自變數的數目(=3)相同,所以有理由相 信, 變數之間沒有高度多元共線性問題。
為了達成上述的目的,必須建立一個區別的直 線函數(linear function)如下:
• 在區別分析中,研究者常常將不同的人或個體分成 不同的群組,但是除此之外,我們還可以從區別函 數中來檢視各變數的相對重要性。假設我們用區別 分析對成功、不成功的管理者建立如下的區別函數:
• 其中,X1表示「與人相處的能力」、X2表示「對部 屬的激勵」、X3表示「專業技能」。由於區別函數 中的各係數值都經過標準化,我們可以說:在分辨 管理者的成功與否時,「與人相處的能力」的重要 性低於另外兩個變數
圖13-7 儲存的資料
圖13-8 SPSS的內定名稱Dis_1、Dis1_1、Dis1_2、Dis2_2 的註解(所代表的意義)
13.3 複區別分析
• 如前所述,如果所分類的二個群組,則會有一 個標準化的典型區別函數,如果所分類的是三 個群組,則會有二個標準化的典型區別函數。 • 由於每一個群組都會有一組Fisher's線性區別 函數,因此在三個群組下,會有三個Fisher's 線性區別函數。 • 如果必須分為三組(及以上),我們所涉及的 就是多元區別分析(multiple discriminant a nalysis)或稱複區別分析的問題。
• 在樣本數的要求上,全部觀察值數目最好是自變數(預 測變數)的10~20倍。每個自變數應有20個觀察值。
• 進行區別分析有以下的假定: 1. 自變數(預測變數)所屬母群體是常 態分配。 2.每組樣本均來自多變量常態分配的母群 體,亦即每一組內共變異數矩陣應大致 相等。 3.任何自變數(預測變數)都不是其他自 變數的線性組合,也就(Classification Results)表又稱為混淆矩 陣(Confusion Matrix)表。在我們的觀察值中,有15 名屬於前途光明組,有15名屬於前途黯淡組。經過分類 之後,前途光明組有11名,前途黯淡組有11名。每一組 都有4名被分到另外一組去了。正確分類的比率是73.3% (22/30)。
圖13-3 「Discriminant Analysis」視窗設定
• 在「Discriminant Analysis」視窗中,按〔Stati stics〕,就會產生「Discriminant Analysis: St atistics」視窗,我們選定的情形如圖13-4所示
圖13-4
「Discriminant Analysis: Statistics」視窗設定
• Wilks' Lambda值=0.710,顯著性=0.028>0.05, 表示區別函數對於依變數有顯著的解釋能力。