统计学整理讲解
统计学基础第三章统计整理

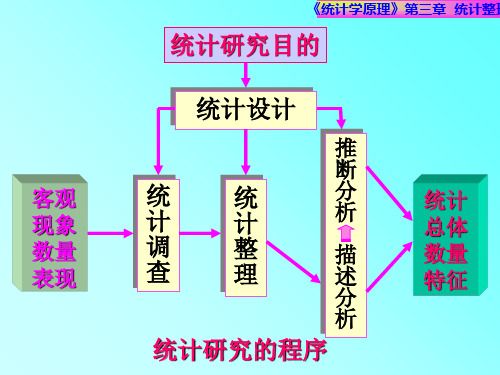
第三章统计整理【教学目的】1. 深刻理解统计分组的作用,并且能够对不同的社会经济现象进行统计分组2. 运用分配数列对原始数据进行系统整理3. 制作统计表,运用计算机绘制统计图【教学重点】1. 能够对不同的社会经济现象进行统计分组2. 运用分配数列对原始数据进行系统整理3. 制作统计表,运用计算机绘制统计图【教学难点】1. 运用分配数列对原始数据进行系统整理2. 制作统计表,运用计算机绘制统计图【教学时数】教学学时为8 课时【教学内容参考】第一节统计整理的意义一、统计整理的意义统计整理,就是根据统计研究的目的和任务的要求,对统计调查所搜集到的原始资料进行分组、汇总,使其条理化、系统化,从而得到表现总体特征的综合统计资料的工作过程。
对于已整理过的初级资料进行再整理,也属于统计整理。
统计调查取得的各种原始资料是分散的、不系统的,只能表明各个被调查单位的具体情况,反映事物的表面现象或一个侧面,不能说明事物的总体情况与全貌。
因此,只有对这些资料进行加工、整理,才能认识事物的总体及其内部联系。
例如,工业企业普查中,所调查的每个工业企业资料,只能说明每个工业企业的经济类型、注册资本、职工人数、工业总产值、工业增加值、实现利税等具体情况。
必须通过对所有资料进行分组、汇总等加工处理后,才能得到全国工业企业的综合情况,从而分析工业企业的构成、经营状况等,达到对全国工业企业的全面的、系统的认识。
统计整理是统计调查的继续,也是统计分析的前提,它在统计研究中起着承前启后的作用。
因此,资料整理得是否正确,直接决定着整个统计研究任务的完成,不恰当的加工整理,不完善的整理方法,往往使调查得来的丰富、完备的资料失去价值。
因此,必须十分重视统计整理工作。
二、统计整理的步骤统计整理的基本步骤是:(一)对原始资料进行审查。
1. 审查被调查单位的资料是否齐全;2. 应审查数据是否准确。
审查的办法主要有:①逻辑审查:主要是从定性角度审查数据是否符合逻辑,内容是否合理,各项目或数量之间有无相互矛盾的现象。
统计学 第3章 统计数据的整理

统计分组的标志
第三章 统计数据的整理
统计分组的标志:分组标志就是将总体分为各个性质不同的标准或根据。
根
据分组标志的特征不同,总体可按属性标志分组,也可按数量标志分组。
1.按属性标志分组
以属性标志作为分组标志,并在属性标志的变异范围内划分各组界限,将总体 分为若干组。属性标志划分,概念明确,容易确定分组组数,如性别。
2.按数量标志分组
以数量标志作为分组标志,并在数量标志的变异范围内划分各组界限,将总体 分为若干组。如工资。
第三章 统计数据的整理
(五)简单分组和复合分组
在统计分组时,根据统计研究目的不同,分组标志的选择可以是一个标志,也可以是 两个或两个以上的标志,这样就有简单分组和复合分组之分:
1.简单分组 对总体只按一个标志分组称为简单分组。
第三章 统计数据的整理
数量次数分布的编制方法
在组距次数分布中,各组组距相同的次数分布称为等距次数分 布(表3-8)。各组组距不同的次数分布称为异距次数分布。
等距次数分布一般在现象性质差异变动比较均衡的条件下使用。
优点:
• 易于掌握次数分布的特性。
• 各组次数可以直接比较。
组数= 全距/组距
组距=全距/组数
100.00
提问:这是单 项次数分布还 是组距次数分 布?
第三章 统计数据的整理
数量次数分布的编制方法
例:对某工厂某月50名工人装配零件(件)情况进行调查, 得到下列初级资料:
106 81 98 111 91 107 86 105 93 106 82 108 114 122 109 104 125 103 113 102 106 84 128 104 91 112 85 96 115 89 97 105 92 111 107 97 105 124 106 86 96 110 112 103 108 110 109 125 101 119
统计整理知识点总结

统计整理知识点总结一、数据的收集和整理1. 数据的来源:数据可以来自多种渠道,比如实验、调查、统计报表、数据库等。
2. 数据的收集方法:调查、实验、观测等。
3. 数据的整理与清洗:数据整理包括对数据进行排序、分类、整理和清理,以确保数据的可靠性和完整性。
4. 数据的表示与汇总:可以用频数分布、直方图、饼状图、线图、散点图等方法来表示和汇总数据。
二、统计描述与推断1. 描述统计学:描述统计学是研究数据分布、中心趋势、离散程度等统计量的方法,包括均值、中位数、众数、标准差、方差等。
2. 推断统计学:推断统计学是通过对样本数据的分析和推断,从而对总体的性质进行估计和推断。
包括参数估计、假设检验、置信区间等方法。
三、随机变量与概率分布1. 随机变量:随机变量是随机试验结果的数值表示,包括离散型随机变量和连续型随机变量。
2. 概率分布:概率分布描述了随机变量的可能取值及其对应的概率,包括离散分布和连续分布。
3. 常见的概率分布包括二项分布、泊松分布、正态分布、指数分布等。
四、参数估计和假设检验1. 参数估计:参数估计是通过样本数据对总体参数进行估计,包括点估计和区间估计。
2. 假设检验:假设检验是通过样本数据来对总体假设进行检验,包括原假设、备择假设、显著性水平、检验统计量等。
3. 假设检验的步骤包括提出假设、选择适当的检验方法、计算检验统计量、进行决策和得出结论。
五、回归分析和方差分析1. 简单线性回归分析:简单线性回归分析是研究两个变量之间线性关系的方法,包括回归方程、回归系数、相关系数等。
2. 多元回归分析:多元回归分析是研究多个自变量对因变量的影响的方法,包括多元回归方程、多元回归系数、多重相关系数等。
3. 方差分析:方差分析是研究不同因素对总体均值是否有显著影响的方法,包括单因素方差分析和双因素方差分析。
六、贝叶斯统计1. 贝叶斯定理:贝叶斯定理是用来更新先验概率为后验概率的方法,包括先验分布、似然函数、后验分布等。
第三章--统计整理-幻灯片(1)
如某班学生按年龄分组:17岁,18岁,19岁, 20岁, 21岁,22岁。
组距式分组
将作为分组依据的数量标志的整个取 值范围依次划分为若干个满足互斥性
和包容性的区间,用这些数值区间作
为组的名称。
某班学生统计 学原理成绩分 组
60分以下 60—70分 70—80分 80—90分 90分以上
组距式分组中的一些概念 《统计学原理》第三章 统计整理
对教师 的分类
按性别分类
男性 女性
高级 按职称分类 中级 共计7组
初级 2+3+2
青年 按年龄分类
中年
复合分组体系
对教师 的分类
按性别 分类
按职称 分类
按年龄 分类
《统计学原理》第三章 统计整理
共计12组 男 2×3×2
女 高级
中级
初级 青年 中年
《统计学原理》第三章 统计整理
统计资料的再分组
• 统计资料的再分组就是把统计分 组资料按某种要求,重新划定各 组界限,再将资料中的单位数或 比重分布重新做出调整。
对总体单位而言,是“合”,即将性质相同的 个体组合起来,在同一组内则保持着相同的性 质。
分组
《统计学原理》第三章 统计整理
25%
33%
分组前
分组后
42%
作用:1·区分事物的性质
例:按所有制性质划分,我国现有8种经济类型:
国有经济;集体经济;私营经济;个体经济 联营经济;股份制经济;外商投资经济;港 澳台投资经济
将统计调查得到的原始资料进行科
统计整理 学的分类和汇总,使之成为系统化、
条理化的综合资料,以反映研究总 体的特征。
地位 是统计调查的继续,统计分析的前提 和基础,起着承前启后的作用。
统计学第3章统计整理

14
7.0 21 10.5 193 96.5
4 90 —100 31 15.5 52 26.0 179 89.5 5 100—110 65 32.5 117 58.5 148 74.0
6 110—120 52 26.0 169 84.5 83 41.5
7 120—130 8 130—140
23 11.5 192 96.0 31 15.5
一、分配数列的概念和种类
1.概念
统计总体按照某一标志分组以后, 用以反映总体各单位分配情况的统计 数列,称分配数列,又可称次数分配, 或次数分布。
它由两部分组成: 总体所分的各个组和各组所拥有的 单位数(次数或频数)。
例
月工资分组(元) 工人数(人) 占总数比重(%)
1000 以下
210
39.6
1000-1500
组距式 分组
以变量值变动的一个区间作为一组,区间的 距离称为组距。适用于连续型变量和离散型 变量的变量值较多的情况。
第三章 统计整理
在进行组距分组时,会涉及到一 些问题,包括:等距分组和不等距分 组、组限、组中值。
第三章 统计整理
等距 分组
不等距 分组
各组组距均相等。如: 10—20 20—30 30—40
组中值 = (上限值+下限值)÷2
开口组组中值的计算: 缺下限:组中值=本组上限— 相邻组组距/2
缺上限:组中值=本组下限+ 相邻组组距/2
例
产值(万元)
第一组组中值:
50以下 50 — 60 60 — 70 70以上
50-(10÷2)= 45 最后一组组中值: 70+(10÷2)= 75
第二节 分配数列
较合适是? (c)
统计学理论基础知识(史上最全最完整)

统计学理论基础知识(史上最全最完整)统计学是一门关于收集、分析、解释和展示数据的学科。
它在许多领域中都发挥着重要作用,包括自然科学、社会科学、商业和医学等。
基本概念- 数据:统计学的研究对象,可以是数值、文字或图像等。
- 总体与样本:总体是我们想要研究的所有个体或事物,而样本是从总体中选择的一部分。
- 参数与统计量:参数是总体的数值特征,统计量是样本的数值特征。
- 频数与频率:频数是某个数值出现的次数,频率是频数与样本大小之比。
描述统计学- 中心趋势:用于衡量数据集中的位置,常用的统计量有平均数、中位数和众数。
- 变异程度:用于衡量数据集中的离散程度,常用的统计量有标准差、方差和四分位数。
- 数据分布:用于描述数据集中每个值的频率分布情况,常用的图表有直方图和箱线图。
推断统计学- 参数估计:通过样本统计量对总体参数进行估计,包括点估计和区间估计。
- 假设检验:根据样本数据对总体参数的假设进行推断性统计分析,包括设置原假设和备择假设,并进行显著性检验。
相关分析- 相关系数:用于衡量两个变量之间的关联程度,常用的相关系数有Pearson相关系数和Spearman等级相关系数。
- 回归分析:用于建立变量之间的数学关系,常用的回归分析有线性回归和多元回归。
统计学软件- 常用统计软件:如SPSS、R、Excel等。
- 数据可视化工具:如Tableau、Power BI等。
这份文档提供了统计学的基础知识概述,包括基本概念、描述统计学、推断统计学、相关分析和统计学软件。
它将帮助读者理解统计学的核心概念和方法,为进一步探索统计学打下坚实的基础。
统计课知识点总结
一、描述统计描述统计是统计学的基础,它通过对数据的整理、呈现和概括,帮助我们更好地理解数据的特征。
描述统计方法包括:频数分布、图表分析、中心位置和离散程度的测度等。
1. 频数分布:频数分布是指按照数据的取值范围划分成若干个等距子区间,并统计每个子区间中数据出现的次数。
通过频数分布,我们可以直观地了解数据的分布情况,发现数据的规律。
2. 图表分析:图表是描述统计的重要工具,包括直方图、饼图、折线图等。
它们能够直观地表现数据的分布规律,帮助我们更好地理解数据。
3. 中心位置和离散程度的测度:中心位置测度包括均值、中位数和众数,它们是数据的集中趋势指标;离散程度测度包括极差、方差和标准差,它们是数据的离散程度指标。
通过这些指标,我们可以更全面地了解数据的特征。
二、推断统计推断统计是指根据样本数据对总体数据进行推断的方法,它包括参数估计和假设检验两个方面。
1. 参数估计:参数估计是对总体参数进行估计的方法,其中包括点估计和区间估计。
点估计是指根据样本数据估计总体参数的数值,例如样本均值用来估计总体均值;区间估计是对总体参数建立一个置信区间,这个区间可以包含总体参数的真值。
2. 假设检验:假设检验是根据样本数据对总体参数假设进行检验的方法,它包括单样本假设检验、两个样本假设检验和多个样本假设检验等。
假设检验能够帮助我们判断总体参数的假设是否成立,从而对决策提供依据。
三、概率统计概率统计是统计学的重要分支,它通过概率模型描述随机现象的规律,提供了一种理论框架来分析和解释数据。
1. 概率基本概念:概率是指随机事件发生的可能性大小,它包括古典概率、几何概率和统计概率等。
通过概率的计算,我们可以对随机事件的发生进行预测和分析。
2. 随机变量与概率分布:随机变量是指在一定范围内取值的变量,概率分布是指随机变量的取值和对应的概率之间的关系。
常见的概率分布包括正态分布、泊松分布、二项分布、均匀分布等,它们能够描述不同类型的随机现象。
统计的知识点总结
统计的知识点总结1. 描述统计描述统计是通过数据的收集、整理和呈现,来对数据的特征进行描述和解释的方法。
描述统计包括了测度中心趋势的方法(如均值、中位数、众数)、测度离散程度的方法(如标准差、方差、极差)以及数据的呈现方法(如表格、图表、频率分布)。
2. 推论统计推论统计是通过对样本数据的分析和推断,来对总体特征进行推测和预测的方法。
推论统计包括了参数估计和假设检验两个主要方法。
在参数估计中,我们通过样本数据来估计总体的参数值;在假设检验中,我们通过样本数据来对总体的某个假设进行检验。
推论统计方法在科学研究和决策制定中具有重要的应用价值。
3. 概率统计概率统计是研究随机现象规律性的科学,它包括了概率的概念、概率分布、随机变量的概念和性质、大数定律和中心极限定理等。
概率统计的基本概念对于理解统计学的理论和方法具有重要的意义。
4. 回归分析回归分析是一种对两个或多个变量之间关系进行建模和分析的方法。
它包括了简单线性回归、多元线性回归、非线性回归等。
回归分析的方法对于预测和决策具有重要的应用价值。
5. 方差分析方差分析是一种用于比较两个或两个以上样本均值之间差异的方法。
它包括了单因素方差分析、双因素方差分析、多因素方差分析等。
方差分析的方法在生物、医学、社会科学等领域都具有重要的应用价值。
6. 生存分析生存分析是一种对时间至事件发生之间关系进行建模和分析的方法。
它包括了生存函数、风险集与危险比、生存曲线、生存比较等。
生存分析的方法在医学、流行病学、生物统计学等领域都具有重要的应用价值。
以上是统计学的一些基本知识点总结。
统计学作为一门科学,它的研究对象是数据,通过数据的收集、整理、分析和解释,来探索数据之间的关系和规律,从而推断和验证问题的解答。
统计学的方法和技术在各个领域都有着广泛的应用价值,它不仅可以帮助我们理解世界,还可以指导我们进行决策和预测。
统计学的知识点非常丰富,每一个知识点都有着自己的理论和方法,对于我们学习和应用统计学都具有着重要的意义。
统计学第三章 统计数据的整理
汇总技术:
有传统手工汇总和现代电子计算机汇总两种技术。
(1)手工汇总。常用的汇总方式有四种: • 划记法。划“正”字符号计数,多用于对总体单位数或次数的简单汇总。
• 过录法。将原始资料分类过录到事先设计的汇总简表中,可用于对内容项 目较多的资料的汇总。
• 折叠法。将每张调查表中需要汇总的同类项目及数据折压一个印记,一张 一张的重叠在一起,再进行汇总。这种方法一次只能选择一个项目及其数 据进行汇总,故适用于数据较少的资料。
• 卡片法。将需要汇总的项目数据分类登记在卡片上,再汇总计算。这种方 法适用于总体单位数多、且多采用复合分组形式的事物,特别是设备、器 材类的实物资产的汇总。
(2)电子计算机汇总。其数据处理程序如下: • 第一步,编程。使用计算机语言编写出一套完整的数据处理程序。
• 第二步,数据录入。计算机自动按程序进行数据处理,并将数据处理结果 存储在磁盘、磁带等磁介质中。
树茎
数叶
数据 个数
10 7 8 8
3
11 0 2 2 3 4 5 7 7 7 8 8 8 9
13
向上累 计个数
3
16
12 0 0 1 2 2 2 2 3 3 3 3 4 4 4 5 5 6 6 7 7 7 8 8 9
24
40
13 0 1 3 3 4 4 5 7 9 9
10
50
14 0 0 1 3
16284
22.3
第三产业
20228
27.7
合计
73025
100.0
3、变量数列的编制
成绩 (分)
某班学生《统计学》考试成绩分布表
学生人数 频率 (人) (%)
向上累计
人
统计学总结知识点
统计学总结知识点1. 总体和样本在统计学中,总体是指研究对象的全部个体,而样本是从总体中选取的一部分个体。
总体和样本是统计学研究的基本单位,研究者通常会通过对样本进行研究来推断总体的特征。
2. 描述统计描述统计是对数据进行整理、汇总和展示的过程,常用的描述统计方法包括平均数、中位数、众数、标准差等。
通过描述统计,研究者可以更好地理解数据的特征和分布情况。
3. 推断统计推断统计是根据样本数据对总体参数进行推断的过程,常用的推断统计方法包括假设检验、置信区间估计和方差分析等。
推断统计能够帮助研究者对总体特征进行推断,并做出相应的决策。
4. 概率分布概率分布是描述随机变量取值规律的数学函数,常见的概率分布包括正态分布、泊松分布、指数分布等。
概率分布在统计学中有着重要的应用,能够帮助研究者对随机现象进行建模和分析。
5. 方差分析方差分析是一种用于比较多个总体均值是否相等的统计方法,通过方差分析可以判断不同处理组之间的平均差异是否显著。
方差分析在实验设计和市场调研中有着重要的应用,能够帮助研究者理解不同因素对结果的影响。
6. 回归分析回归分析是一种用于研究变量之间关系的统计方法,常见的回归分析包括简单线性回归和多元线性回归。
通过回归分析可以揭示变量之间的相关性和因果关系,对预测和决策提供重要参考。
7. 抽样方法抽样是从总体中选取样本的过程,常见的抽样方法包括随机抽样、系统抽样、分层抽样和群集抽样等。
合适的抽样方法能够保证样本的代表性和可靠性,对统计推断和结论的准确性具有重要影响。
8. 数据可视化数据可视化是利用图表、图像和地图等形式将数据进行直观展示的过程,常见的数据可视化方法包括柱状图、折线图、散点图和地理信息系统等。
数据可视化能够帮助研究者更直观地理解数据特征和规律。
9. 统计软件统计软件是进行数据分析和统计推断的重要工具,常见的统计软件包括SPSS、SAS、R和Python等。
统计软件能够帮助研究者进行复杂的数据处理和分析,提高工作效率和结果质量。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
也可能出现。 调查中的有些误差纯粹是统计上的,主要的统计误差即所谓的 抽样误差 。 抽样误差:并非错误的 " 误差 " 未响应误差 未响应误差是指由于包含在样本中的一部分人未回答调查而造成的误差。
? 一些经验表明, 在大部分情况下, 未响应者和响应者并无多大差别。 如果我们开始时有 一个高的响应率,那么可假定未响应者也依同样的比例作出回答。 但是如果响应率很低, 例如不超过 50%,那么不响应的影响可能会很大。
分析数据时,几乎总会丢失某些信息。 数据分析的三个原则 1、绘制一个图。图像可以帮助你看到从数据表里看不到的信息,有助于你选择分析的方法, 帮你明确思考隐藏在数据背后的模式和关系。 2、绘制一个图。精心设计的图像在分析工作中很重要。它能够展现重要的特征和模式,有时 候可以揭示出你意想不到的事情:值得注意的(可能是错误的)数据或意想不到的模式。 3、绘制一个图。使用一个精心挑选的图像是向其他人汇报你的数据分析结果的最佳方式。 频数表
近,所以两组之间只有一项系统性的差别,就是一组参加了工作培训,另外一组没有。
第 2 章 分类数据的描述方法
数据分析的三个原则 2.2 频数表 2.3 统计图 2.4 列联表 数据分析包括三种形式:为数据画一个图,制作一个表或者计算一些我们感兴趣的东西。
? 这可以帮助我们对数据进行简化。简化使得理解数据和从数据中提取信息变得容易了。 ? 但是数据简化有一个不足之处, 就是难以从简化的形式中恢复原始数据, 因此,当我们
time
and cost
总体和样本
? 收集数据是为了从收集的个体中得出结论。 ? 所有我们感兴趣的个体就组成了 总体 。比如,你读本教材这一时刻, 我国所有居民就构
成了一个总体。
? 有时我们能够收集到总体中所有个体的数据。 在这种情况下, 我们就是对总体做了 普查
(census) 。 我国进行的第六次全国人口普查就是希望确定我国所有居民数。
系统抽样 1. 将总体中的所有单位 ( 抽样单位 ) 按一定顺序排列, 在规定的范围内随机地抽取一个单位 作为初始单位,然后按事先规定好的规则确定其他样本单位
- 先从数字 1 到 k 之间随机抽取一个数字 r 作为初始单位,以后依次取 r +k, r +2k…等单位 2. 优点:操作简便,可提高估计的精度 3. 缺点:对估计量方差的估计比较困难
1. 定量变量或数值变量
– 可以用阿拉伯数据来记录其观察结果
– 如“企业销售额”、 “上涨股票的家数”、 “生活费支出”、 “投掷一枚骰子出
现的点数”
– 定量变量的观察结果称为定量数据或数值型数据
2. 分类变量
– 表现为不同的类别
– 如“性别”、“企业所属的行业”、“学生所在的学院”
等
– 分类变量的观察结果就是分类数据
的流动人口数量。 观测数据是指仅通过对世界的观察 ( 而没有操纵或控制它 ) 所得到的数据。
收集观测数据的研究者们尽量不干涉研究对象的行为模式。
数据的来源——观测研究 1. 抽样调查( sample survey ) 2. 普查( census) 3. 抽样的精髓:从检查一部分来得知全体。
4. 抽样调查是一种很重要的观测研究,选中这些人是因为他们具有代表性局限性:
方便样本:如何产生一个 " 坏的 " 样本 能够很容易、很经济地得到的样本称为 方便样本
? 从方便样本中得出的结果有时候很难推广到整个总体。 收集观测数据时的错误和误差
? 随机抽样误差 是样本统计量和总体参数之间的差距,是在选取样本时因机遇造成的。 ? 非抽样误差 是和“从总体取样本”这个动作无关的误差。 非抽样误差即使在人口普杳中
硕士,博士
人
失业 孩子数
有工作,无工作 0, 1 , 2 , 3 ,…
人 家庭
贫困程度
严重,一般,边缘, 没有
地区
? 上面介绍的是 经验变量 ,级处理的对像是我们周围可观测到的物质世界中的事物。 ? 用数学方法推导的变量称为 理论变量—— z,t , 和 F 变量。 ? 与变量相对的概念是 常数 。在统计中经常使用的一种被称做 参数 的常数。
随机样本
指一个合适的、能够被推广应用于更大的总体的统计样本。
当一个总体中的名字或代码被放进一个纸箱子里, 搅拌均匀, 并随机抽取, 其结果就是一个简
单随机样本
简单随机抽样 1. 从总体 N 个单位 ( 元素 ) 中随机地抽取 n 个单位作为样本, 使得 总体中每一个元素 都有相 同的机会 ( 概率 ) 被抽中 ——帽子抽签法 2. 抽取元素的具体方法有重复抽样和不重复抽样 可以使用随机数表或电脑产生的随机数字来实现 1. 特点 – 简单、直观。 – 用样本统计量对目标量进行估计比较方便 2. 局限性 – 抽出的单位很分散,给实施调查增加了困难 – 没有利用其他辅助信息以提高估计的效率
响应误差 响应误差是在调查过程中, 由于问题的提问方式、 问题所处的位置或访员的影响而使得响应者 在回答问题时产生的偏差。 实验数据:寻找造成结果的原因
? 实验数据 是指在实验中控制实验对象而收集到的变量的数据。 实验是检验变量间因果关 系的一种方法。 在实验中, 研究者试图控制某一情形的所有相关方面, 操纵少数感兴趣
1. 频数: 落在各类别中的数据个数 2. 比例: 某一类别数据个数占全部数据个数的比值 3. 百分比: 将对比的基数作为 100 而计算的比值 4. 比率: 不同类别数值个数的比值 频数表或频数分布表可以帮助了解变量取值的分布状况。 频数表是遵循既不重叠又不遗漏的原则,按变量(数据特征)的取值归类分组,把总体的所有 单位按组归并排列,其各个组别所包含的数据数目(频数)的汇总表格。简而言之,频数表包 括两个要素:总体按其标志所分的组和各组所分布的单位数量。 统计图 ? 如果想获得更生动的展示,我们可以使用统计图。 ? 统计图是用几何图形或具体事物的形象来表现统计数据的一种形式。 ? 统计图既可以节省大量文字叙述, 又可便于数据的对比分析与积累。 利用统计图表现统
第 1章
什么是统计学? 统计学是研究收集数据,整理数据,分析数据以及由数据分析得出结论的方法,简称为“数据 的科学”。 统计滥用 ——不好的样本 ——过小的样本 ——误导性图表 ——局部描述 ——故意曲解 统计应用上的两个极端 ——不用或几乎不用统计 ——简单问题复杂化 随机性和规律性
当我们不能预测一件事情的结果时,这件事就和随机性联系起来了。 通过对看起来随机的现象进行统计分析, 统计知识能够帮助我们把随机性归纳于可能的规律性 中。统计从我们如何观察事物和事物本身如何真正发生这两个方面帮助我们理解随机性和规律 性的重要性。因此,统计可以看做是一项对随机性中的规律性的研究。 规律也表现出某种随机性。 在这种意义下来说,统计就成了对数据中的 偏差 问题的研究。根据作为统计基础的数学理论, 我们可以确定一项调查中的某一比例有多大的随机性, 以及在下一次的重复调查中, 这个比例 可能有多大的偏差。 我们还可以指出, 两个比例之间的差异是否大到了随机性本身所不能解释 的地步。 概率 概率是一个 0 到 1 之间的数,它告诉我们某一事件发生的机会有多大。
整群抽样 1. 将总体中若干个单位合并为组 ( 群) ,抽样时直接抽取群, 然后对中选群中的所有单位全 部实施调查 2. 特点 – 抽样时只需群的抽样框,可简化工作量 – 调查的地点相对集中,节省调查费用,方便调查的实施 – 缺点是估计的精度较差
普查 ? 又称“清点”。企图把整个总体纳入样本的抽样调查。 ? 即使有政府的强大后盾,普查也不是一定做得到的。 ? 但一个糟糕的普查往往比不上一个设计和实施都比较好的抽样调查。
? 然而,在苛刻的现实生活中,由于资金、时间有限以及不断变化的环境条件,普查通常
是很困的。 此时,我们需要把收集数据限制在总体的一个 样本 上,样本是总体的中的一
个被选中的部分。
样本的选择
? 我们希望基于样本得出的结论能够适用于该样本所属的总体,这依赖于获得一个
" 好"
的样本,否则这是不可能实现的。
简单随机样本 1. 由简单随机抽样形成的样本 2. 从总体 N 个单位中随机地抽取 n 个单位作为样本, 使得 每一个容量为 n 样本 都有相同的 机会 ( 概率 ) 被抽中 3. 参数估计和假设检验所依据的主要是简单随机样本
分层抽样 1. 将总体单位按某种特征或某种规则划分为不同的层, 然后从不同的层中独立、 随机地抽 取样本 2. 优点 – 保证样本的结构与总体的结构比较相近,从而提高估计的精度 – 组织实施调查方便 – 既可以对总体参数进行估计,也可以对各层的目标量进行估计
? 概率为统计学的第三个方面——如何从数据中得出结论——奠定了基石。 ? 我们可能永远不能确定两个数字的差异是否超出了随机性本身所预期的范围, 但是我们
可以确定,这种差异发生的概率是大还是小。根据这个基本思想,在很多情况下,我们 可以得出关于我们所处的这个世界的重要结论。 变量 (variable) 是指一个可以取两个或更多个可能值的特征、特质或属性。比如,性别是取两个值的变量,因 为一个人只可能是男性或女性。还有其它变量的例子,如人的寿命,体重,以及汽车每升汽油 所能行驶的距离,等等。