计量经济学作业第二章练习12
计量经济学第二章练习题及参考解答
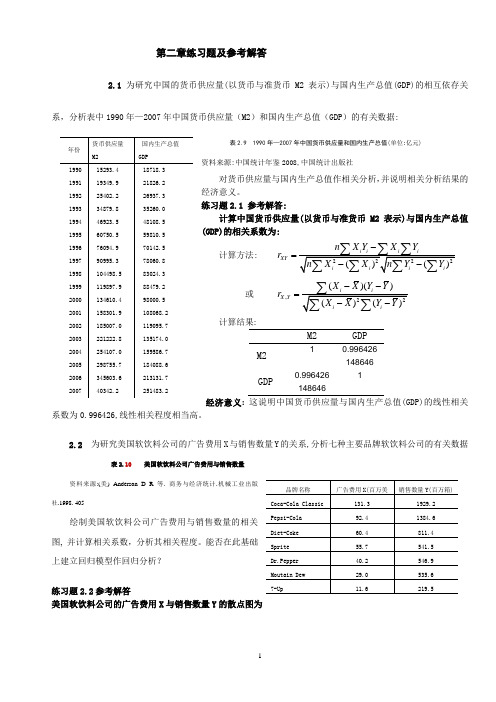
第二章练习题及参考解答2.1 为研究中国的货币供应量(以货币与准货币M2表示)与国内生产总值(GDP)的相互依存关系,分析表中1990年—2007年中国货币供应量(M2)和国内生产总值(GDP )的有关数据:表2.9 1990年—2007年中国货币供应量和国内生产总值(单位:亿元)资料来源:中国统计年鉴2008,中国统计出版社对货币供应量与国内生产总值作相关分析,并说明相关分析结果的经济意义。
练习题2.1 参考解答:计算中国货币供应量(以货币与准货币M2表示)与国内生产总值(GDP)的相关系数为:计算方法: 2222()()i i i iXY i i i i n X Y X Y r n X X n Y Y -=--∑∑∑∑∑∑∑或 ,22()()()()ii X Y iiX X Y Y r X X Y Y --=--∑∑∑计算结果:M2GDPM2 1 0.996426148646 GDP0.9964261486461经济意义: 这说明中国货币供应量与国内生产总值(GDP)的线性相关系数为0.996426,线性相关程度相当高。
2.2 为研究美国软饮料公司的广告费用X 与销售数量Y 的关系,分析七种主要品牌软饮料公司的有关数据表2.10 美国软饮料公司广告费用与销售数量 资料来源:(美) Anderson D R 等. 商务与经济统计.机械工业出版社.1998. 405绘制美国软饮料公司广告费用与销售数量的相关图, 并计算相关系数,分析其相关程度。
能否在此基础上建立回归模型作回归分析?练习题2.2参考解答美国软饮料公司的广告费用X 与销售数量Y 的散点图为年份货币供应量M2国内生产总值GDP1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006 200715293.4 19349.9 25402.2 34879.8 46923.5 60750.5 76094.9 90995.3 104498.5 119897.9 134610.4 158301.9 185007.0 221222.8 254107.0 298755.7 345603.6 40342.218718.3 21826.2 26937.3 35260.0 48108.5 59810.5 70142.5 78060.8 83024.3 88479.2 98000.5 108068.2 119095.7 135174.0 159586.7 184088.6 213131.7 251483.2品牌名称广告费用X(百万美销售数量Y(百万箱)Coca-Cola Classic 131.3 1929.2 Pepsi-Cola 92.4 1384.6 Diet-Coke60.4 811.4 Sprite 55.7 541.5 Dr.Pepper 40.2 546.9 Moutain Dew 29.0 535.6 7-Up11.6219.5说明美国软饮料公司的广告费用X 与销售数量Y 正线性相关。
计量经济学第2章练习题

第2章 多元线性回归模型一、单项选择题1.在由30n =的一组样本估计的、包含3个解释变量的线性回归模型中,计算得多重决定系数为0.8500,则调整后的多重决定系数为( )A. 0.8603B. 0.8389C. 0.8655D.0.83272.下列样本模型中,哪一个模型通常是无效的( )A. i C (消费)=500+0.8i I (收入)B. d i Q (商品需求)=10+0.8i I (收入)+0.9i P (价格)C. s i Q (商品供给)=20+0.75i P (价格)D. i Y (产出量)=0.650.6i L (劳动)0.4i K (资本)3.用一组有30个观测值的样本估计模型01122t t t t y b b x b x u =+++后,在0.05的显著性水平上对1b 的显著性作t 检验,则1b 显著地不等于零的条件是其统计量t 大于等于( ) A. )30(05.0t B. )28(025.0t C. )27(025.0t D. )28,1(025.0F4.模型t t t u x b b y ++=ln ln ln 10中,1b 的实际含义是( ) A.x 关于y 的弹性 B. y 关于x 的弹性 C. x 关于y 的边际倾向 D. y 关于x 的边际倾向 5、在多元线性回归模型中,若某个解释变量对其余解释变量的判定系数接近于1,则表明模型中存在( )A.异方差性B.序列相关C.多重共线性D.高拟合优度6.线性回归模型01122......t t t k kt t y b b x b x b x u =+++++ 中,检验0:0(0,1,2,...)t H b i k ==时,所用的统计量 服从( )A.t(n-k+1)B.t(n-k-2)C.t(n-k-1)D.t(n-k+2)7. 调整的判定系数与多重判定系数 之间有如下关系( ) A.2211n R R n k -=-- B. 22111n R R n k -=--- C. 2211(1)1n R R n k -=-+-- D. 2211(1)1n R R n k -=---- 8.关于经济计量模型进行预测出现误差的原因,正确的说法是( )。
庞皓计量经济学 第二章 练习题及参考解答(第四版)
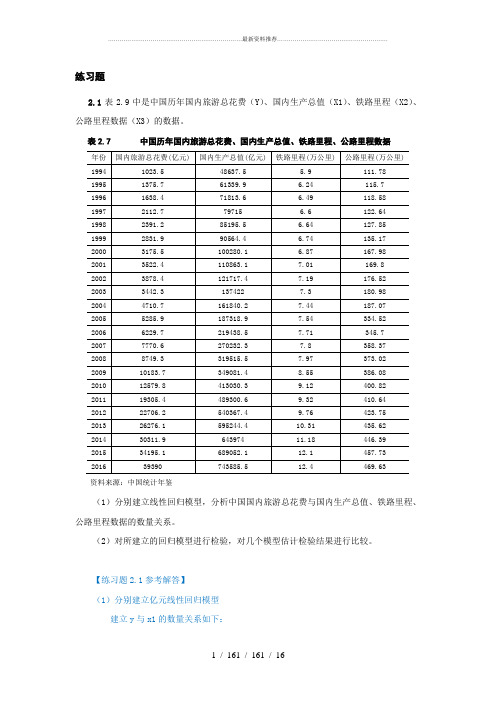
练习题2.1表2.9中是中国历年国内旅游总花费(Y)、国内生产总值(X1)、铁路里程(X2)、公路里程数据(X3)的数据。
表2.7 中国历年国内旅游总花费、国内生产总值、铁路里程、公路里程数据资料来源:中国统计年鉴(1)分别建立线性回归模型,分析中国国内旅游总花费与国内生产总值、铁路里程、公路里程数据的数量关系。
(2)对所建立的回归模型进行检验,对几个模型估计检验结果进行比较。
【练习题2.1参考解答】(1)分别建立亿元线性回归模型建立y与x1的数量关系如下:建立y与x2的数量关系如下:建立y与x3的数量关系如下:(2)对所建立的回归模型进行检验,对几个模型估计检验结果进行比较。
关于中国国内旅游总花费与国内生产总值模型,由上可知,,说明所建模型整体上对样本数据拟合较好。
对于回归系数的t检验:,对斜率系数的显著性检验表明,GDP 对中国国内旅游总花费有显著影响。
同理:关于中国国内旅游总花费与铁路里程模型,由上可知,,说明所建模型整体上对样本数据拟合较好。
对于回归系数的t检验:,对斜率系数的显著性检验表明,铁路里程对中国国内旅游总花费有显著影响。
关于中国国内旅游总花费与公路里程模型,由上可知,,说明所建模型整体上对样本数据拟合较好。
对于回归系数的t检验:,对斜率系数的显著性检验表明,公路里程对中国国内旅游总花费有显著影响。
2.2为了研究浙江省一般预算总收入与地区生产总值的关系,由浙江省统计年鉴得到如表2.8所示的数据。
年份一般预算总收入(亿元)地区生产总值(亿元)年份一般预算总收入(亿元)地区生产总值(亿元)Y X Y X 197827.45123.721998 401.80 5052.62 197925.87157.751999 477.40 5443.92 198031.13179.922000 658.42 6141.03 198134.34204.862001 917.76 6898.34 198236.64234.012002 1166.58 8003.67 198341.79257.092003 1468.89 9705.02 198446.67323.252004 1805.16 11648.70 198558.25429.162005 2115.36 13417.68 198668.61502.472006 2567.66 15718.47 198776.36606.992007 3239.89 18753.73 198885.55770.252008 3730.06 21462.69 198998.21849.442009 4122.04 22998.24 1990101.59904.692010 4895.41 27747.65 1991108.941089.332011 5925.00 32363.381992 118.36 1375.70 2012 6408.49 34739.13 1993 166.64 1925.91 2013 6908.41 37756.58 1994 209.39 2689.28 2014 7421.70 40173.03 1995 248.50 3557.55 2015 8549.47 42886.49 1996 291.75 4188.53 2016 9225.0747251.361997340.524686.11(1)建立浙江省一般预算收入与全省地区生产总值的计量经济模型,估计模型的参数,检验模型的显著性,用规范的形式写出估计检验结果,并解释所估计参数的经济意义(2)如果2017年,浙江省地区生产总值为52000亿元,比上年增长10%,利用计量经济模型对浙江省2017年的一般预算收入做出点预测和区间预测(3)建立浙江省一般预算收入的对数与地区生产总值对数的计量经济模型,估计模型的参数,检验模型的显著性,并解释所估计参数的经济意义。
计量经济学课后题答案
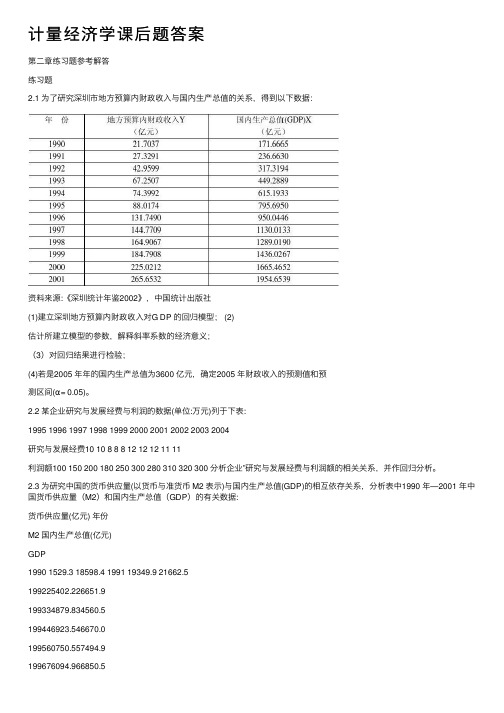
计量经济学课后题答案第⼆章练习题参考解答练习题2.1 为了研究深圳市地⽅预算内财政收⼊与国内⽣产总值的关系,得到以下数据:资料来源:《深圳统计年鉴2002》,中国统计出版社(1)建⽴深圳地⽅预算内财政收⼊对G DP 的回归模型; (2)估计所建⽴模型的参数,解释斜率系数的经济意义;(3)对回归结果进⾏检验;(4)若是2005 年年的国内⽣产总值为3600 亿元,确定2005 年财政收⼊的预测值和预测区间(α= 0.05)。
2.2 某企业研究与发展经费与利润的数据(单位:万元)列于下表:1995 1996 1997 1998 1999 2000 2001 2002 2003 2004研究与发展经费10 10 8 8 8 12 12 12 11 11利润额100 150 200 180 250 300 280 310 320 300 分析企业”研究与发展经费与利润额的相关关系,并作回归分析。
2.3 为研究中国的货币供应量(以货币与准货币 M2 表⽰)与国内⽣产总值(GDP)的相互依存关系,分析表中1990 年—2001 年中国货币供应量(M2)和国内⽣产总值(GDP)的有关数据:货币供应量(亿元) 年份M2 国内⽣产总值(亿元)GDP1990 1529.3 18598.4 1991 19349.9 21662.5199225402.226651.9199334879.834560.5199446923.546670.0199560750.557494.9199676094.966850.5199790995.373142.71998104498.576967.21999119897.980579.42000134610.388228.12001158301.994346.4资料来源:《中国统计年鉴2002》,第51 页、第662 页,中国统计出版社对货币供应量与国内⽣产总值作相关分析,并说明分析结果的经济意义。
计量经济学 张晓峒 第二章习题

计量经济学张晓峒第二章习题1.最小二乘法对随机误差项u作了哪些假定?说明这些假定条件的意义。
答:假定条件:(1)均值假设:E(u i)=0,i=1,2,…;(2)同方差假设:Var(u i)=E[u i-E(u i)]2=E(u i2)=σu2 ,i=1,2,…;(3)序列不相关假设:Cov(u i,u j)=E[u i-E(u i)][u j-E(u j)]=E(u i u j)=0,i≠j,i,j=1,2,…;(4)Cov(u i,X i)=E[u i-E(u i)][X i-E(X i)]=E(u i X i)=0;(5)u i服从正态分布, u i~N(0,σu2)。
意义:有了这些假定条件,就可以用普通最小二乘法估计回归模型的参数。
2.阐述对样本回归模型拟合优度的检验及回归系数估计值显著性检验的步骤。
答:样本回归模型拟合优度的检验:可通过总离差平方和的分解、样本可决系数、样本相关系数来检验。
回归系数估计值显著性检验的步骤:(1)提出原假设H0 :β1=0;(2)备择假设H1 :β1≠0;(3)计算t=β1/Sβ1;(4)给出显著性水平α,查自由度v=n-2的t分布表,得临界值tα/2(n-2);(5)作出判断。
如果|t|<tα/2(n-2),接受H0 :β1=0,表明X对Y无显著影响,一元线性回归模型无意义;如果|t|>tα/2(n-2),拒绝H0 ,接受H1:β1≠0,表明X对Y有显著影响。
4.试说明为什么∑e i2的自由度等于n-2。
答:在模型中,自由度指样本中可以自由变动的独立不相关的变量个数。
当有约束条件时,自由度减少,其计算公式:自由度=样本个数-受约束条件的个数,即df=n-k。
一元线性回归中SSE残差的平方和,其自由度为n-2,因为计算残差时用到回归方程,回归方程中有两个未知参数β0和β1,而这两个参数需要两个约束条件予以确定,由此减去2,也即其自由度为n-2。
计量经济学第2章习题参考答案

量 y 是随机变量, 解释变量 x 是非随机变量, 相关分析对资料的要求是两个变量都是随机变 量。 2. 答: 相关关系是指两个以上的变量的样本观测值序列之间表现出来的随机数学关系, 用相关 系数来衡量。 因果关系是指两个或两个以上变量在行为机制上的依赖性, 作为结果的变量是由作为原因的 变量所决定的, 原因变量的变化引起结果变量的变化。 因果关系有单向因果关系和互为因果 关系之分。 具有因果关系的变量之间一定具有数学上的相关关系。 而具有相关关系的变量之间并不一定 具有因果关系。 3. 答:主要区别:①描述的对象不同。总体回归模型描述总体中变量 y 与 x 的相互关系,而样 本回归模型描述所观测的样本中变量 y 与 x 的相互关系。 ②建立模型的不同。 总体回归模型 是依据总体全部观测资料建立的, 样本回归模型是依据样本观测资料建立的。 ③模型性质不 同。总体回归模型不是随机模型,样本回归模型是随机模型,它随着样本的改变而改变。 主要联系:样本回归模型是总体回归模型的一个估计式,之所以建立样本回归模型,目的是 用来估计总体回归模型。
1 n ∑ ui = 0 ,因为 n i =1
前者是条件期望,即针对给定的 X i 的随机干扰的期望,而后者是无条件的平均值,即针对 所有 X i 的随机干扰取平均值。
二、单项选择题 1. A 2. D 3. A 4. B 5. C 6. B 7. D 8. B 9. D 10. C 11. D 12. D 13. C
14. D 15. D 16. A 17. B
三、多项选择题 1. ACD 2. ABE 3. AC 4. BE 5. BEFH 6. DG, ABCG, G, EF 7. ABDE 8. ADE 9. ACDE
计量经济学习题及参考答案

计量经济学各章习题第一章绪论1.1试列出计量经济分析地主要步骤.1.2计量经济模型中为何要包括扰动项?1.3什么是时间序列和横截面数据? 试举例说明二者地区别1.4估计量和估计值有何区别?第二章计量经济分析地统计学基础2.1名词解释随机变量概率密度函数抽样分布样本均值样本方差协方差相关系数标准差标准误差显著性水平置信区间无偏性有效性一致估计量接受域拒绝域第I 类错误2.2请用例 2.2中地数据求北京男生平均身高地99%置信区间.2.325 个雇员地随机样本地平均周薪为130元,试问此样本是否取自一个均值为120 元、标准差为10 元地正态总体?文档收集自网络,仅用于个人学习2.4某月对零售商店地调查结果表明,市郊食品店地月平均销售额为2500 元,在下一个月份中,取出16 个这种食品店地一个样本,其月平均销售额为2600 元,销售额地标准差为480 元.试问能否得出结论,从上次调查以来,平均月销售额已经发生了变化?文档收集自网络,仅用于个人学习第三章双变量线性回归模型3.1判断题(判断对错;如果错误,说明理由)(1)OLS 法是使残差平方和最小化地估计方法.(2)计算OLS 估计值无需古典线性回归模型地基本假定.(3)若线性回归模型满足假设条件(1)~(4),但扰动项不服从正态分布,则尽管OLS 估计量不再是BLUE ,但仍为无偏估计量.文档收集自网络,仅用于个人学习(4)最小二乘斜率系数地假设检验所依据地是t 分布,要求地抽样分布是正态分布.2(5)R2=TSS/ESS.(6)若回归模型中无截距项,则.(7)若原假设未被拒绝,则它为真.(8)在双变量回归中,地值越大,斜率系数地方差越大.3.2设和分别表示Y 对X 和X 对Y 地OLS 回归中地斜率,证明r 为X 和Y 地相关系数.3.3证明:(1)Y 地真实值与OLS 拟合值有共同地均值,即;(2)OLS 残差与拟合值不相关,即.3.4证明本章中( 3.18)和( 3.19)两式:(1)(2)3.5考虑下列双变量模型:模型1:模型2:(1)1 和1地OLS 估计量相同吗?它们地方差相等吗?(2)2 和2地OLS 估计量相同吗?它们地方差相等吗?3.6有人使用1980-1994 年度数据,研究汇率和相对价格地关系,得到如下结果:其中,Y=马克对美元地汇率X=美、德两国消费者价格指数(CPI)之比,代表两国地相对价格(1)请解释回归系数地含义;(2)X t 地系数为负值有经济意义吗?(3)如果我们重新定义X 为德国CPI与美国CPI之比,X 地符号会变化吗?为什么?3.7随机调查200 位男性地身高和体重,并用体重对身高进行回归,结果如下:其中Weight 地单位是磅(lb ),Height 地单位是厘米(cm).(1)当身高分别为177.67cm、164.98cm、187.82cm 时,对应地体重地拟合值为多少?(2)假设在一年中某人身高增高了 3.81cm,此人体重增加了多少?3.8设有10 名工人地数据如下:X 10 7 10 5 8 8 6 7 9 10Y 11 10 12 6 10 7 9 10 11 10 其中X= 劳动工时,Y= 产量(1)试估计Y=α+βX + u(要求列出计算表格);(2)提供回归结果(按标准格式)并适当说明;(3)检验原假设β=1.0.3.9用12 对观测值估计出地消费函数为Y=10.0+0.90X ,且已知=0.01,=200,=4000,试预测当X=250 时Y 地值,并求Y 地95%置信区间.文档收集自网络,仅用于个人学习3.10设有某变量(Y)和变量(X)1995—1999 年地数据如下:(3)试预测X=10 时Y 地值,并求Y 地95%置信区间.3.11根据上题地数据及回归结果,现有一对新观测值X =20,Y=7.62,试问它们是否可能来自产生样本数据地同一总体?文档收集自网络,仅用于个人学习3.12有人估计消费函数,得到如下结果(括号中数字为t 值):=15 + 0.81 =0.98(2.7)(6.5)n=19(1)检验原假设:=0(取显著性水平为5%)(2)计算参数估计值地标准误差;(3)求地95%置信区间,这个区间包括0 吗?3.13试用中国1985—2003 年实际数据估计消费函数:=α+β + u t其中:C代表消费,Y 代表收入.原始数据如下表所示,表中:Cr=农村居民人均消费支出(元)Cu=城镇居民人均消费支出(元)Y =国内居民家庭人均纯收入(元) Yr =农村居民家庭人均纯收入(元) Yu=城镇居民家庭人均可支配收入(元) Rpop=农村人口比重(%) pop=历年年底我国人口总数(亿人)P=居民消费价格指数(1985=100)Pr=农村居民消费价格指数(1985=100)Pu=城镇居民消费价格指数(1985=100)数据来源:《中国统计年鉴2004》使用计量经济软件,用国内居民人均消费、农村居民人均消费和城镇居民人均消费分别对各自地人均收入进行回归,给出标准格式回归结果;并由回归结果分析我国城乡居民消费行为有何不同.文档收集自网络,仅用于个人学习第四章多元线性回归模型4.1某经济学家试图解释某一变量Y 地变动.他收集了Y 和 5 个可能地解释变量~地观测值(共10 组),然后分别作三个回归,结果如下(括号中数字为t 统计量):文档收集自网络,仅用于个人学习( 1) = 51.5 + 3.21 R=0.63(3.45) (5.21)2) 33.43 + 3.67 + 4.62 + 1.21 R=0.75 文档收集自网络,仅用于个人学(3.61 )(2.56)(0.81) (0.22)3) 23.21 + 3.82 + 2.32 + 0.82 + 4.10 + 1.21(2.21 )(2.83)(0.62) (0.12) (2.10) (1.11)文档收集自网络,仅用于个人学习R=0.80 你认为应采用哪一个结果?为什么?4.2为研究旅馆地投资问题,我们收集了某地地1987-1995 年地数据来估计收益生产函数R=ALKe ,其中R=旅馆年净收益(万年) ,L=土地投入,K=资金投入, e 为自然对数地底.设回归结果如下(括号内数字为标准误差) :文档收集自网络,仅用于个人学习= -0.9175 + 0.273lnL + 0.733lnK R=0.94(0.212) (0.135) (0.125)(1)请对回归结果作必要说明;( 2)分别检验α和β 地显著性;( 3)检验原假设:α =β = 0;4.3我们有某地1970-1987 年间人均储蓄和收入地数据,用以研究1970-1978 和1978 年以后储蓄和收入之间地关系是否发生显著变化. 引入虚拟变量后,估计结果如下(括号内数据为标准差) :文档收集自网络,仅用于个人学习= -1.7502 + 1.4839D + 0.1504 - 0.1034D·R=0.9425 文档收集自网络,仅用于个人学习(0.3319) (0.4704) (0.0163) (0.0332)其中:Y=人均储蓄,X=人均收入,D= 请检验两时期是否有显著地结构性变化.4.4说明下列模型中变量是否呈线性,系数是否呈线性,并将能线性化地模型线性化.(1)(2)(3)4.5有学者根据某国19年地数据得到下面地回归结果:其中:Y=进口量(百万美元),X1 =个人消费支出(百万美元),X2 =进口价格/国内价格.(1)解释截距项以及X1和X2系数地意义;(2)Y 地总变差中被回归方程解释地部分、未被回归方程解释地部分各是多少?(3)进行回归方程地显著性检验,并解释检验结果;(4)对“斜率”系数进行显著性检验,并解释检验结果.4.6由美国46个州1992年地数据,Baltagi 得到如下回归结果:其中,C=香烟消费(包/人年),P=每包香烟地实际价格Y=人均实际可支配收入(1)香烟需求地价格弹性是多少?它是否统计上显著?若是,它是否统计上异于-1?(2)香烟需求地收入弹性是多少?它是否统计上显著?若不显著,原因是什么?(3)求出.4.7有学者从209 个公司地样本,得到如下回归结果(括号中数字为标准误差):其中,Salary=CEO 地薪金Sales=公司年销售额roe=股本收益率(%)ros=公司股票收益请分析回归结果.4.8为了研究某国1970-1992 期间地人口增长率,某研究小组估计了下列模型:其中:Pop=人口(百万人),t=趋势变量,.(1)在模型 1 中,样本期该地地人口增长率是多少?(2)人口增长率在1978 年前后是否显著不同?如果不同,那么1972-1977和1978-1992 两时期中,人口增长率各是多少?文档收集自网络,仅用于个人学习4.9设回归方程为Y= β0+β1X1+β2X2+β3X3+ u, 试说明你将如何检验联合假设:β1= β2 和β3 = 1 .文档收集自网络,仅用于个人学习4.10下列情况应引入几个虚拟变量,如何表示?(1)企业规模:大型企业、中型企业、小型企业;(2)学历:小学、初中、高中、大学、研究生.4.11在经济发展发生转折时期,可以通过引入虚拟变量来表示这种变化.例如,研究进口消费品地数量Y 与国民收入X 地关系时,数据散点图显示1979 年前后明显不同.请写出引入虚拟变量地进口消费品线性回归方程.文档收集自网络,仅用于个人学习4.12柯布-道格拉斯生产函数其中:GDP=地区国内生产总值(亿元)K=资本形成总额(亿元)L= 就业人数(万人)P=商品零售价格指数(上年=100)试根据中国2003 年各省数据估计此函数并分析结果.数据如下表所示第五章模型地建立与估计中地问题及对策5.1判断题(判断对错;如果错误,说明理由)(1)尽管存在严重多重共线性,普通最小二乘估计量仍然是最佳线性无偏估计量(BLUE ).(2)如果分析地目地仅仅是为了预测,则多重共线性并无妨碍. (3)如果解释变量两两之间地相关系数都低,则一定不存在多重共线性. (4)如果存在异方差性,通常用地t 检验和 F 检验是无效地. (5)当存在自相关时,OLS 估计量既不是无偏地,又不是有效地.(6)消除一阶自相关地一阶差分变换法假定自相关系数必须等于 1. (7)模型中包含无关地解释变量,参数估计量会有偏,并且会增大估计量地方差,即增大误差.(8)多元回归中,如果全部“斜率”系数各自经t 检验都不显著,则R2值也高不了.(9)存在异方差地情况下,OLS 法总是高估系数估计量地标准误差.(10)如果一个具有非常数方差地解释变量被(不正确地)忽略了,那么OLS 残差将呈异方差性.5.2考虑带有随机扰动项地复利增长模型:Y 表示GDP,Y0是Y 地基期值,r 是样本期内地年均增长率,t 表示年份,t=1978,⋯,2003.文档收集自网络,仅用于个人学习试问应如何估计GDP 在样本期内地年均增长率?5.3 检验下列情况下是否存在扰动项地自相关 .(1) DW=0.81,n=21,k=3(2)DW=2.25,n=15,k=2(3)DW=1.56,n=30,k=55.4有人建立了一个回归模型来研究我国县一级地教育支出:Y= β0+β1X1+β 2X2+β3X3+u其中:Y,X1,X2 和X3分别为所研究县份地教育支出、居民人均收入、学龄儿童人数和可以利用地各级政府教育拨款.文档收集自网络,仅用于个人学习他打算用遍布我国各省、市、自治区地100 个县地数据来估计上述模型.(1)所用数据是什么类型地数据?(2)能否采用OLS 法进行估计?为什么?(3)如不能采用OLS 法,你认为应采用什么方法?5.5试从下列回归结果分析存在问题及解决方法:(1)= 24.7747 + 0.9415 - 0.0424 R=0.9635SE:(6.7525)(0.8229)(0.0807)其中:Y=消费,X2=收入,X3=财产,且n=5000 (2)= 0.4529 - 0.0041t R=0.5284t:(-3.9606) DW=0.8252其中Y= 劳动在增加值中地份额,t=时间该估计结果是使用1949-1964 年度数据得到地.5.6工资模型:wi=b0+b1Si+b2Ei+b3Ai+b4Ui+ui其中Wi=工资,Si=学校教育年限,Ei=工作年限,Ai=年龄,Ui=是否参加工会.在估计上述模型时,你觉得会出现什么问题?如何解决?5.7你想研究某行业中公司地销售量与其广告宣传费用之间地关系.你很清楚地知道该行业中有一半地公司比另一半公司大,你关心地是这种情况下,什么估计方法比较合理.假定大公司地扰动项方差是小公司扰动项方差地两倍.文档收集自网络,仅用于个人学习(1)若采用普通最小二乘法估计销售量对广告宣传费用地回归方程(假设广告宣传费是与误差项不相关地自变量),系数地估计量会是无偏地吗?是一致地吗?是有效地吗?文档收集自网络,仅用于个人学习(2)你会怎样修改你地估计方法以解决你地问题?(3)能否对原扰动项方差假设地正确性进行检验?5.8考虑下面地模型其中GNP=国民生产总值,M =货币供给. (1)假设你有估计此模型地数据,你能成功地估计出模型地所有系数吗?说明理由.(2)如果不能,哪些系数可以估计?(3)如果从模型中去掉这一项,你对(1)中问题地答案会改变吗?(4)如果从模型中去掉这一项,你对(1)中问题地答案会改变吗?5.9采用美国制造业1899-1922年数据,Dougherty得到如下两个回归结果:(1)(2)其中:Y=实际产出指数,K=实际资本投入指数,L =实际劳动力投入指数,t=时间趋势(1)回归式(1)中是否存在多重共线性?你是如何得知地?(2)回归式(1)中,logK 系数地预期符号是什么?回归结果符合先验预期吗?为什么会这样?(3)回归式(1)中,趋势变量在其中起什么作用?(4)估计回归式(2)背后地逻辑是什么?(5)如果(1)中存在多重共线性,那么(2)式是否减轻这个问题?你如何得知?(6)两个回归地R2可比吗?说明理由.5.10有人估计了下面地模型:其中:C=私人消费支出,GNP=国民生产总值,D=国防支出假定,将(1)式转换成下式:使用1946-1975数据估计(1)、(2)两式,得到如下回归结果(括号中数字为标准误差):1)关于异方差,模型估计者做出了什么样地假定?你认为他地依据是什么?2)比较两个回归结果.模型转换是否改进了结果?也就是说,是否减小了估计标准误差?说明理由.5.11设有下列数据:RSS1=55,K =4,n1=30RSS3=140,K =4,n3=30 请依据上述数据,用戈德佛尔德-匡特检验法进行异方差性检验(5%显著性水平).5.12考虑模型(1)也就是说,扰动项服从AR (2)模式,其中是白噪声.请概述估计此模型所要采取地步骤.5.13对第 3 章练习题 3.13 所建立地三个消费模型地结果进行分析:是否存在序列相关问题?如果有,应如何解决?5.14为了研究中国农业总产值与有效灌溉面积、化肥施用量、农作物总播种面积、受灾面积地相互关系,选31 个省市2003 年地数据资料,如下表所示:文档收集自网络,仅用于个人学习表中:Y=农业总产值(亿元,不包括林牧渔)X1=有效灌溉面积(千公顷)X2=化肥施用量(万吨)X23=化肥施用量(公斤/亩)X3=农作物总播种面积(千公顷)X4=受灾面积(千公顷)(1)回归并根据计算机输出结果写出标准格式地回归结果;(2)模型是否存在问题?如果存在问题,是什么问题?如何解决?第六章动态经济模型:自回归模型和分布滞后模型6.1判断题(判断对错;如果错误,说明理由)(1)所有计量经济模型实质上都是动态模型.(2)如果分布滞后系数中,有地为正有地为负,则科克模型将没有多大用处. (3)若适应预期模型用OLS 估计,则估计量将有偏,但一致. (4)对于小样本,部分调整模型地OLS 估计量是有偏地.(5)若回归方程中既包含随机解释变量,扰动项又自相关,则采用工具变量法,将产生无偏且一致地估计量.(6)解释变量中包括滞后因变量地情况下,用德宾-沃森d 统计量来检测自相关是没有实际用处地.6.2用OLS 对科克模型、部分调整模型和适应预期模型分别进行回归时,得到地OLS 估计量会有什么样地性质?文档收集自网络,仅用于个人学习6.3简述科克分布和阿尔蒙多项式分布地区别.6.4考虑模型假设相关.要解决这个问题,我们采用以下工具变量法:首先用对和回归,得到地估计值,然后回归其中是第一步回归(对和回归)中得到地.(1)这个方法如何消除原模型中地相关?(2)与利维顿采用地方法相比,此方法有何优点?6.5设其中:M=对实际现金余额地需求,Y*=预期实际收入,R*=预期通货膨胀率假设这些预期服从适应预期机制:其中和是调整系数,均位于0和1之间.(1)请将M t 用可观测量表示;(2)你预计会有什么估计问题?6.6考虑分布滞后模型假设可用二阶多项式表示诸如下:若施加约束==0,你将如何估计诸系数(,i=0,1, (4)6.7为了研究设备利用对于通货膨胀地影响,T. A.吉延斯根据1971年到1988年地美国数据获得如下回归结果:文档收集自网络,仅用于个人学习其中:Y=通货膨胀率(根据GNP 平减指数计算)X t=制造业设备利用率X t-1 =滞后一年地设备利用率1)设备利用对于通货膨胀地短期影响是什么?长期影响又是什么?(2)每个斜率系数是统计显著地吗?(3)你是否会拒绝两个斜率系数同时为零地原假设?将利用何种检验?6.8考虑下面地模型:Y t = α+β(W0X t+ W1X t-1 + W2X t-2 + W3X t-3)+u t 请说明如何用阿尔蒙滞后方法来估计上述模型(设用二次多项式来近似) .6.9下面地模型是一个将部分调整和适应预期假说结合在一起地模型:Y t*= βX t+1eY t-Y t-1 = δ(Y t*- Y t-1) + u tX t+1e- X t e= (1-λ)( X t - X t e);t=1,2,⋯, n式中Y t*是理想值,X t+1e和X t e是预期值.试推导出一个只包含可观测变量地方程,并说明该方程参数估计方面地问题.文档收集自网络,仅用于个人学习第七章时间序列分析7.1单项选择题(1)某一时间序列经一次差分变换成平稳时间序列,此时间序列称为()地.A.1 阶单整B.2阶单整C.K 阶单整D.以上答案均不正确文档收集自网络,仅用于个人学习(2)如果两个变量都是一阶单整地,则().A .这两个变量一定存在协整关系B.这两个变量一定不存在协整关系C.相应地误差修正模型一定成立D.还需对误差项进行检验文档收集自网络,仅用于个人学习(3)如果同阶单整地线性组合是平稳时间序列,则这些变量之间关系是() .A. 伪回归关系B.协整关系C.短期均衡关系D. 短期非均衡关系(4).若一个时间序列呈上升趋势,则这个时间序列是().A .平稳时间序列B.非平稳时间序列C.一阶单整序列 D. 一阶协整序列7.2请说出平稳时间序列和非平稳时间序列地区别,并解释为什么在实证分析中确定经济时间序列地性质是十分必要地.文档收集自网络,仅用于个人学习7.3什么是单位根?7.4Dickey-Fuller(DF)检验和Engle-Granger(EG)检验是检验什么地?文档收集自网络,仅用于个人学习7.5什么是伪回归?在回归中使用非均衡时间序列时是否必定会造成伪回归?7.6由1948-1984 英国私人部门住宅开工数(X)数据,某学者得到下列回归结果:注:5%临界值值为-2.95,10%临界值值为-2.60. (1)根据这一结果,检验住宅开工数时间序列是否平稳.(2)如果你打算使用t 检验,则观测地t 值是否统计显著?据此你是否得出该序列平稳地结论?(3)现考虑下面地回归结果:请判断住宅开工数地平稳性.7.7由1971-I 到1988-IV 加拿大地数据,得到如下回归结果;A.B.C.其中,M1=货币供给,GDP=国内生产总值,e t=残差(回归A)(1)你怀疑回归 A 是伪回归吗?为什么?(2)回归 B 是伪回归吗?请说明理由.(3)从回归 C 地结果,你是否改变(1)中地结论,为什么?(4)现考虑以下回归:这个回归结果告诉你什么?这个结果是否对你决定回归 A 是否伪回归有帮助?7.8 检验我国人口时间序列地平稳性,数据区间为1949-2003 年.单位:万人7.9对中国进出口贸易进行协整分析,如果存在协整关系,则建立E CM 模型.1951-2003 年中国进口(im )、出口(ex)和物价指数(pt,商品零售物价指数)时间序列数据见下表.因为该期间物价变化大,特别是改革开放以后变化更为激烈,所以物价指数也作为一个解释变量加入模型中.为消除物价变动对进出口数据地影响以及消除进出口数据中存在地异方差,定义三个变量如下:文档收集自网络,仅用于个人学习第八章联立方程模型8.1判断题(判断对错;如果错误,说明理由)(1)OLS 法适用于估计联立方程模型中地结构方程.(2)2SLS 法不能用于不可识别方程.(3)估计联立方程模型地2SLS 法和其它方法只有在大样本地情况下,才能具有我们期望地统计性质 .(4) 联立方程模型作为一个整体,不存在类似 R 2这样地拟合优度测度 .(5) 如果要估计地方程扰动项自相关或存在跨方程地相关, 则 2SLS 法和其它估 计结构方程地方法都不能用 .(6) 如果一个方程恰好识别,则 ILS 和 2SLS 给出相同结果 .8.2 单项选择题1) 结构式模型中地方程称为结构方程 .在结构方程中, 解释变量可以是前定变3) 如果联立方程模型中某个结构方程包含了模型中所有地变量,则这个方程5)当一个结构式方程为恰好识别时,这个方程中内生解释变量地个数( A .与被排除在外地前定变量个数正好相等 B .小于被排除在外地前定变量个数 C .大于被排除在外地前定变量个数D .以上三种情况都有可能发生 文档收集自网络,仅用于个人学习6) 简化式模型就是把结构式模型中地内生变量表示为 ( ).A. 外生变量和内生变量地函数关系B.前定变量和随机误差项地模型C.滞后变量和随机误差项地模型 D.外生变量和随机误差项地模量,也可以是 ( ).文档收集自网络,仅用于个人学习 A. 外生变量 B.滞后变量2)前定变量是 ( )地合称 .A.外生变量和滞后内生变量C.内生变量D. 外生变量和内生变量 C.外生变量和虚拟变量 D. 解释变量和被解释变量( ).A. 恰好识别B.不可识别 (4) 下面说法正确地是( ).A.内生变量是非随机变量 C.外生变量是随机变量 C.过度识别 D.不确定B. 前定变量是随机变量个人收集整理勿做商业用途型7) 对联立方程模型进行参数估计地方法可以分两类,即:( ).A.间接最小二乘法和系统估计方法B.单方程估计法和系统估计方法个人收集整理勿做商业用途C.单方程估计法和二阶段最小二乘法D.工具变量法和间接最小二乘法(8)在某个结构方程过度识别地条件下,不适用地估计方法是().A. 间接最小二乘法B.工具变量法C.二阶段最小二乘法D.有限信息极大似然估计法8.3行为方程和恒等式有什么区别?8.4如何确定模型中地外生变量和内生变量?8.5考虑下述模型:C t = α + β D t +u t I t = γ + δD t-1 + νt D t = C t +I t + Z t ;t=1 ,2,⋯,n其中 C = 消费支出,D= 收入,I = 投资,Z = 自发支出. C、I 和D是内生变量.试写出消费支出地简化型方程,并研究各方程地识别问题.8.6考虑下述模型:Y t = C t + I t +G t +X tC t = β 0 + β 1D t + β2C t-1 + u tD t = Y t –T tI t = α0 + α1Y t + α2R t-1 +νt 模型中各方程是正规化方程,u t、νt为扰动项.(1)请指出模型中地内生变量、外生变量和前定变量.(2)写出用2SLS法进行估计时,每个阶段中要估计地方程.8.7下面是一个简单地美国宏观经济模型(1960-1999)其中C=实际私人消费,I= 实际私人总投资,G=实际政府支出,Y =实际GDP,M= 当年价M2,R=长期利率;P=消费价格指数.内生变量:C,I,R,Y 前定变量:C t-1,I t-1,M t-1,P t,R t-1 和G t.(1)应用识别地阶条件,决定各方程地识别状态;(2)你打算用什么方法来估计可识别行为方程?8.8假设有如下计量经济模型:其中,Y=国民收入,I=净资本形成,C=个人消费,Q =利润,P=生活费用指数,R= 工业劳动生产率1)写出模型地内生变量、外生变量和前定变量;个人收集整理勿做商业用途(2)用识别地阶条件确定各方程地识别状态;(3)此模型中是否有可以用ILS 法估计地方程?如有,请指出;(4)写出用2SLS 法进行估计时,每个阶段中要估计地方程. 8.9考虑下述模型:消费方程:C t=α0 +α 1Y t +α2C t-1 +u①投资方程:I t=β0 +β1Y t +β2I t –1+u2t②进口方程:M t = 0 + 1Y t + u3t ③Y t = C t+ I t + G t + X t - M t模型中各方程是正规化方程,u 1t, ⋯u3t为扰动项.(1)请指出模型中地内生变量、外生变量和前定变量.(2)利用阶条件识别各行为方程.(3)写出用3SLS 进行估计时地步骤.8.10考察下述国民经济地简单模型式中,C为消费,Y 为国民收入,I 为投资,R为利率.设样本容量n 为20,已算得中间结果为:(1)判别模型中消费方程地识别状态;(2)用间接最小二乘法求消费方程结构式系数;(3)将采用哪种方法估计投资方程?为什么?(不必计算)8.11由联立方程模型;得到其简化式如下:(1)两结构方程可识别吗?(2)如果知道,识别情况有何变化?(3)若对简化式进行估计,结果如下:个人收集整理勿做商业用途试求出结构参数地值,并说明如何检验原假设个人收集整理勿做商业用途版权申明本文部分内容,包括文字、图片、以及设计等在网上搜集整理。
计量经济学作业第二章练习12

计量经济学作业第⼆章练习12第2章练习12下表是中国2007年各地区税收Y和国内⽣产总值GDP的统计资料。
单位:亿元地区Y GDP 地区Y GDP北京1435.7 9353.3 湖北434.0 9230.7 天津438.4 5050.4 湖南410.7 9200.0 河北618.3 13709.5 ⼴东2415.5 31084.4 ⼭西430.5 5733.4 ⼴西282.7 5955.7 内蒙古347.9 6091.1 海南88.0 1223.3 辽宁815.7 11023.5 重庆294.5 4122.5 吉林237.4 5284.7 四川629.0 10505.3 ⿊龙江335.0 7065.0 贵州211.9 2741.9 上海1975.5 12188.9 云南378.6 4741.3 江苏1894.8 25741.2 西藏11.7 342.2 浙江1535.4 18780.4 陕西355.5 5465.8 安徽401.9 7364.2 ⽢肃142.1 2702.4 福建594.0 9249.1 青海43.3 783.6 江西281.9 5500.3 宁夏58.8 889.2 ⼭东1308.4 25965.9 新疆220.6 3523.2 河南625.0 15012.5要求,以⼿⼯和运⽤Eviews软件:(1)作出散点图,建⽴税收随国内⽣产总值GDP变化的⼀元线性回归⽅程,并解释斜率的经济意义;(2)对所建⽴的回归⽅程进⾏检验;(3)若2008年某地区国内⽣产总值为8500亿元,求该地区税收收⼊的预测值及预测区间。
解:(1)作出散点图,如下图所⽰250020001500Y1000500010000200003000040000GDPDependent Variable: YMethod: Least SquaresDate: 10/18/14 Time: 13:18Sample: 1 31Included observations: 31Variable Coefficient Std. Error t-Statistic Prob.GDP 0.071047 0.007407 9.591245 0.0000C -10.62963 86.06992 -0.123500 0.9026R-squared 0.760315 Mean dependent var 621.0548 Adjusted R-squared 0.752050 S.D. dependent var 619.5803 S.E. of regression 308.5176 Akaike info criterion 14.36378 Sum squared resid 2760310. Schwarz criterion 14.45629 Log likelihood -220.6385 F-statistic 91.99198 Durbin-Watson stat 1.570523 Prob(F-statistic) 0.0000001、建⽴模型我们假设拟建⽴如下⼀元回归模型:µββ++=GDP Y 1根据Eviews 软件对表中的数据进⾏回归分析的计算结果,可写出如下的回归分析结果:=^i Y -10.62963+0.071047GDP(-0.123500)(9.591245)=2R 0.760315 F=91.99198 D.W.=1.570523斜率的经济意义:国内⽣产总值GDP 每增加1亿元,国内税收就增加0.071047亿元。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第2章练习12
下表是中国2007年各地区税收Y和国内生产总值GDP的统计资料。
单位:亿元
要求,以手工和运用Eviews软件:
(1)作出散点图,建立税收随国内生产总值GDP变化的一元线性回归方程,并解释斜率的经济意义;
(2)对所建立的回归方程进行检验;
(3)若2008年某地区国内生产总值为8500亿元,求该地区税收收入的预测值及预测区间。
解:
(1)作出散点图,如下图所示
Dependent Variable: Y
Method: Least Squares
Date: 10/18/14 Time: 13:18
Sample: 1 31
Included observations: 31
Variable Coefficient Std. Error t-Statistic Prob.
GDP 0.071047 0.007407 9.591245 0.0000
C -10.62963 86.06992 -0.123500 0.9026
R-squared 0.760315 Mean dependent var 621.0548 Adjusted R-squared 0.752050 S.D. dependent var 619.5803 S.E. of regression 308.5176 Akaike info criterion 14.36378 Sum squared resid 2760310. Schwarz criterion 14.45629 Log likelihood -220.6385 F-statistic 91.99198 Durbin-Watson stat 1.570523 Prob(F-statistic) 0.000000
1、建立模型
我们假设拟建立如下一元回归模型:
μ
ββ++=GDP Y 1
根据Eviews 软件对表中的数据进行回归分析的计算结果,可写出如下的回归分析结果:
=
^
i Y -10.62963+0.071047GDP
(-0.123500) (9.591245)
=2R 0.760315 F=91.99198 D.W.=1.570523
斜率的经济意义:国内生产总值GDP 每增加1亿元,国内税收就增加0.071047亿元。
2、模型检验
从回归估计的结果看,模型拟合较好。
可决系数760315.02=R ,表明
国内税收变化的76.0315%可由国内生产总值GDP 的变化来解释。
从斜率项的t 检验值看,大于5%显著性水平下自由度为292=-n 的临界值045.2)29(025.0=t ,且该斜率值满足1071047.00<<,符合经济理论中税收乘数在0与1之间的说法,表明2007年,国内生产总值GDP 每增加1亿元,国内税收就增加0.071047亿元。
3、预测
由上述回归方程可得中国国内税收的预测值:
26987.5938500071047.062963.10ˆ0=⨯+-=Y (亿元)
下面给出国内税收95%置信度的预测区间。
由于国内生产总值GDP 的样本均值与样本方差为
125806.8891=E GDP
64.57823127)Var(=GDP
在95%的置信度下,某地区)E(0Y 的预测区间为:
()()4764246.11326987.59364.578231271-31125806.8891-85003112-312760310045.226987.5932
±=⎪⎪⎭
⎫
⎝⎛⨯+⨯⨯±
或(479.7934454,706.7462946)
若2008年某地区国内生产总值为8500亿元,该地区税收的个值预测,则仍通过上述样本回归方程得到593.26987的国内税收的预测值。
同样的,在95%的置信度下,某地区国内税收的预测区间为
()()0421337.64126987.59364.578231271-31125806.8891-850031112-312760310045.226987.5932
±=⎪⎪⎭
⎫
⎝⎛⨯++⨯⨯±
或(-47.7722637,1234.312004)。