SPSS因子、聚类案例分析报告
SPSS聚类分析实验报告

SPSS聚类分析实验报告一、实验目的本实验的目的是通过应用SPSS软件进行聚类分析,对样本进行分类和分组,通过群组间的比较来发现变量之间的关系和特征。
通过聚类分析的结果,可以帮助我们更好地理解和解释数据。
二、实验步骤1.数据准备:选择合适的数据集进行分析。
数据集应包含若干个已知变量,以及我们需要进行聚类的目标变量。
2.打开SPSS软件,导入数据集。
3.对数据集进行数据清洗和预处理,包括处理缺失数据、异常值等。
4.进行聚类分析:选择合适的聚类方法和变量,进行聚类分析。
5.对聚类结果进行解释和分析,确定最佳的聚类数目。
6.对不同的聚类进行比较,看是否存在显著差异。
7.结果展示和报告撰写。
三、实验结果及分析在实验过程中,我们选择了学校学生的体测数据作为聚类分析的样本。
数据集共包含身高、体重、肺活量等指标,共有200个样本。
首先,我们进行了数据预处理,包括处理缺失数据和异常值。
对于缺失数据,我们选择用平均值进行填充;对于异常值,我们使用离群值检测方法进行处理。
然后,我们选择了合适的聚类方法和变量,使用K-means聚类算法对样本进行分组。
我们尝试了不同的聚类数目,从2到10进行了分析。
根据轮廓系数和手肘法定量评估了不同聚类数目下聚类效果的好坏。
最终,我们选择了聚类数目为4的结果进行进一步分析。
通过比较不同聚类结果的均值,我们发现不同聚类之间的身高、体重和肺活量等指标存在较大差异。
这说明聚类分析对样本的分类和分组是合理和有效的。
四、实验总结本次实验通过应用SPSS软件进行聚类分析,对样本进行分类和分组,通过群组间的比较来发现变量之间的关系和特征。
通过分析聚类结果,我们发现不同聚类之间存在显著差异,这为进一步研究和探索提供了参考。
聚类分析是一种常用的数据分析方法,可以帮助我们更好地理解和解释数据,对于从大量数据中发现规律和特征具有重要的应用价值。
总之,聚类分析是一种有力的数据分析工具,可以帮助我们更好地理解和解释数据。
spss因子分析、聚类分析

吉林财经大学2011-2012学年第一学期多元统计分析期末论文学院:工商管理学院专业:人力资源管理年级:2009级学号:姓名:西甲球员的综合能力统计分析摘要:足球运动是一项古老的体育活动,是目前全球体育界最具影响力的单项体育运动。
球员是足球运动中不可缺少的部分,球技是影响球员乃至球队发展的重要因素。
本文通过网上搜集西甲联赛部分球员的技术数据统计为依据,运用spss软件对不同球员的球技进行因子分析和聚类分析。
关键词:足球、球员、球技、因子分析、聚类分析引言:足球是世界最受欢迎的一项运动,故有世界第一大运动的美称!当今足球运动已成为人们生活中不可缺少的组成部分,不论在任何地区,足球都成为了一项不可或缺的运动。
当今世界各地都有足球联赛,各地也都有不同形式的球队及比赛,据不完全统计,现在世界上经常参加比赛的球队约80万支,登记注册的运动员约4000万人,其中职业运动员约10万人。
当然,球员的水平也不尽相同,每个人心中都有各自所喜爱的球队及球员。
当今世界两大豪门为巴塞罗那和皇家马德里,他们深受世界大多数人们的喜爱,所以本文选择了最受人们欢迎的西甲球员进行数据统计分析。
一、指标选取进行球员技术的数据统计分析,必须选取合适的指标,做到全面准确地反映每一个球员的技术,对不同的球员加以区分,综合的反映一个球员的技术水平,因此从出场、出场时间、进球、助攻、射门等方面选取了能够反映个人球技水平的10项指标,分别为:X1——出场(次)X2——出场时间(分)X3——进球(个)X4——助攻(个)X5——射门(次)X6——射正(次)X7——犯规(次)X8——越位(次)X9——黄牌(张)X10——角球(个)原始数据的收集与整理:二、因子分析因子分析是一种数据简化的技术,它是将具有相关性的多个原始变量通过空间线性变换为较少的几个抽象的综合指标的一种方法。
得到新的综合指标称为公因子,这些主成分不仅保留了原始指标的绝大多数信息,并且彼此不相关。
SPSS聚类分析实验报告

SPSS聚类分析实验报告一、实验目的本实验旨在通过SPSS软件对样本数据进行聚类分析,找出样本数据中的相似性,并将样本划分为不同的群体。
二、实验步骤1.数据准备:在SPSS软件中导入样本数据,并对数据进行处理,包括数据清洗、异常值处理等。
2.聚类分析设置:在SPSS软件中选择聚类分析方法,并设置分析参数,如距离度量方法、聚类方法、群体数量等。
3.聚类分析结果:根据分析结果,对样本数据进行聚类,并生成聚类结果。
4.结果解释:分析聚类结果,确定每个群体的特征,观察不同群体之间的差异性。
三、实验数据本实验使用了一个包含1000个样本的数据集,每个样本包含了5个变量,分别为年龄、性别、收入、教育水平和消费偏好。
下表展示了部分样本数据:样本编号,年龄,性别,收入,教育水平,消费偏好---------,------,------,------,---------,---------1,30,男,5000,大专,电子产品2,25,女,3000,本科,服装鞋包3,35,男,7000,硕士,食品饮料...,...,...,...,...,...四、实验结果1. 聚类分析设置:在SPSS软件中,我们选择了K-means聚类方法,并设置群体数量为3,距离度量方法为欧氏距离。
2.聚类结果:经过聚类分析后,我们将样本分为了3个群体,分别为群体1、群体2和群体3、每个群体的特征如下:-群体1:年龄偏年轻,女性居多,收入较低,教育水平集中在本科,消费偏好为服装鞋包。
-群体2:年龄跨度较大,男女比例均衡,收入中等,教育水平较高,消费偏好为电子产品。
-群体3:年龄偏高,男性居多,收入较高,教育水平较高,消费偏好为食品饮料。
3.结果解释:根据聚类结果,我们可以看到不同群体之间的差异性较大,每个群体都有明显的特征。
这些结果可以帮助企业更好地了解不同群体的消费习惯,为市场营销活动提供参考。
五、实验结论通过本次实验,我们成功地对样本数据进行了聚类分析,并得出了3个不同的群体。
SPSS因子分析实验报告
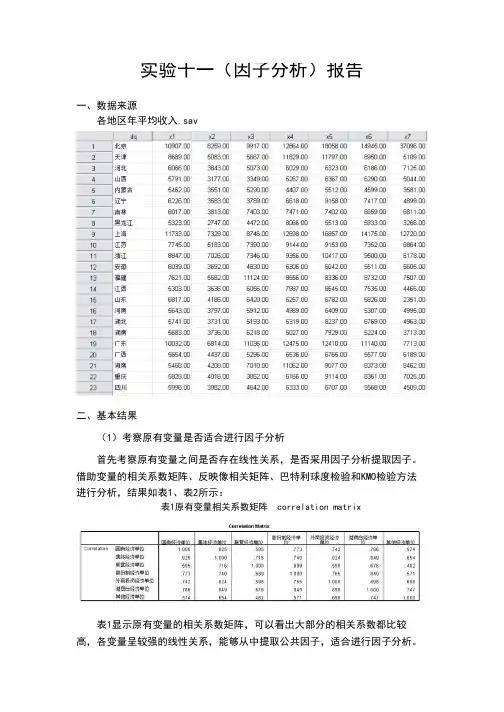
实验十一(因子分析)报告一、数据来源各地区年平均收入.sav二、基本结果(1)考察原有变量是否适合进行因子分析首先考察原有变量之间是否存在线性关系,是否采用因子分析提取因子。
借助变量的相关系数矩阵、反映像相关矩阵、巴特利球度检验和KMO检验方法进行分析,结果如表1、表2所示:表1原有变量相关系数矩阵 correlation matrix表1显示原有变量的相关系数矩阵,可以看出大部分的相关系数都比较高,各变量呈较强的线性关系,能够从中提取公共因子,适合进行因子分析。
表2 KMO and Bartlett's Test由表2可知,巴特利特球度检验统计量观测值为,p值接近0,显著性差异,可以认为相关系数矩阵与单位阵有显著差异,同时KMO值为,根据Kaiser给出的KMO度量标准可知原有变量适合进行因子分析。
(2)提取因子进行尝试性分析:根据原有变量的相关系数矩阵,采用主成分分析法提取因子并选取大于1的特征值。
具体结果见表3:可知,initial一列是因子分析初始解下的共同度,表明如果对原有7个变量采用主成分分析法提取所有特征值,那么原有变量的所有方差都可以被解释,变量的共同度均为1。
事实上,因子个数小于原有变量的个数才是因子分析的目的,所以不可以提取全部特征值。
第二列表明港澳台经济单位、集体经济单位以及外商投资经济单位等变量的绝大部分信息(大于83%)可被因子解释。
但联营经济、其他经济丢失较为表3因子分析中的变量共同度(一)严重。
因此,本次因子提取的总体效果不理想。
重新制定提取特征值的标准,指定提取2个因子,分析表4:可以看出,此时所有变量的共同度均较高,各个变量的信息丢失较少。
因此,本次因子提取的总体效果比较理想。
表4因子分析的变量共同度(二)表5中,第一列是因子编号,以后三列组成一组,每组中数据项为特征值、方差贡献率、累计方差贡献率。
第一组数据项(2-4列)描述因子分析初始解的情况。
在初始解中由于提取了7个因子,因此原有变量的总方差均被解释,累计方差贡献率为100%。
SPSS管理统计 课程设计 因子分析和聚类分析

一:实验名:实验四二:实验要求:练习上课讲过(第10-12章)的例子。
(无需写实验报告)三:实验步骤:1、使用“网购数据”文件进行以下分析。
1.1 产生因子:商品感知风险、网页展示质量、网络安全、卖家信誉、服务质量、便捷性、所属平台质量、以往经验、网络购物意向。
实验步骤:1)读取数据“网购数据”,依次点击analyze--data reduction—factor,弹出小窗口,将“感知风险”以及以下的四列添加到Test Variable(s)中,如图1.11所示2)再点击score按钮,选择“save as variables”选项,如图1.12所示,点击continue 返回。
3)此时data view界面就会出现如图1.13所示列,用相同方法将其余的各组因子归类,如图1.14所示,使其增加了9列fac1_1..9 。
图1.11 因子分析主窗口图1.12 因子分析子窗口图1.13新增因子实验结果:图 1.14 ,如图所示,产生“商品感知风险、网页展示质量、网络安全、卖家信誉、服务质量、便捷性、所属平台质量、以往经验、网络购物意向”9项因子图1.141.2 分别对网络购物意向与商品感知风险、网页展示质量、网络安全、卖家信誉、服务质量、便捷性、所属平台质量、以往经验的相关分析。
实验步骤:1)依次点击analyze--data reduction—factor,弹出小窗口,将“fac_1”以及以下的9列因子添加到Test Variable(s)中,如图1.21所示2)点击descriptives按钮,弹出小窗口,选上“KMO and…sphericity ”选项,(即KMO 测度和巴特利特球体检验)如图1.22,点击continue返回。
3)点击extraction按钮,探出小窗口,在display框中选上scree plot(显示碎石图)如图1.23。
点击continue返回。
4)点击score按钮,选择“save as variables”选项,下面的method小框被激活,系统默认为regression选项(回归方法),如图1.24所示,点击continue返回。
spss聚类分析与因子分析

基于因子分析的31个省行业就业情况分析摘要:就业问题已经越来越受人重视,通过对31个省的17个就业指标进行因子分析,得出3个因子的较为合理的解释,并结合对31个省的就业情况做出相应的聚类分析,给出相应的综合分析结论。
关键词:因子分析聚类分析1、指标的确定根据《中国统计年鉴2009》中的数据表,选取X1: 农、林、牧、渔业就业人数 X2: 采矿业就业人数X3:制造业就业人数 X4:电力、燃气及水的生产及水的生产和供应业就业人数X5:建筑业就业人数 X6:交通运输、仓储和邮政业就业人数X7:信息传输、计算机服务和软件业就业人数X8:批发和零售业就业人数 X9:住宿和餐饮业就业人数X10:金融业就业人数 X11:租赁和商务服务业就业人数X12:科学研究、技术服务和地质勘查业就业人数X13:水利、环境和公共设施管理业就业人数 X14:教育就业人数X15:卫生、社会保障和社会福利业就业人数 X16:文化、体育和娱乐业就业人数X17:公共管理和社会组织就业人数这17个数据对31个省的就业情况进行相关分析。
2、因子分析及结果先标准化数据,且因子分析过程以特征值大于0为标准提取因子,以主成分法做因子分析,由KMO检验值0.766可判别该问题可使用因子分析。
再考察累计贡献率>85﹪的成分,由图1可知应选择3个因子较为适合。
Total Variance Explained14 .016 .091 99.879 .016 .091 99.87915 .011 .064 99.942 .011 .06499.94216 .008 .045 99.987 .008 .045 99.98717 .002 .013 100.000 .002 .013 100.000图1再次以3个主分做标准做提取因子,并以主成分法做因子分析,采用方差极大化方法对因子载荷矩阵进行旋转,可得旋转后的因子特征值和贡献率(图2)以及旋转后的因子载荷矩阵(图3)。
SPSS聚类分析实验报告
SPSS聚类分析实验报告摘要:本实验旨在利用SPSS软件进行聚类分析,并通过实验结果分析数据的分布情况,揭示数据中的隐含规律。
通过聚类分析,我们将数据样本划分为不同的类别,以便更好地理解数据的特征、相似性以及群组之间的差异。
实验结果表明,SPSS软件在聚类分析方面具有较高的可靠性和准确性,能够有效地提取数据的特征和隐含信息,为数据分析提供有力支持。
1.引言2.实验方法2.1数据收集与准备本实验使用到的数据集是从公开渠道获取的一份包含各个地区收入、消费、教育等特征的数据集。
为了保护数据安全和隐私,将被分析的数据进行了匿名化处理。
2.2SPSS操作步骤(1)导入数据集:将数据集导入SPSS软件,并进行数据检查和处理,确保数据的完整性和准确性。
(2)选择合适的聚类算法:根据实验目的和数据特点选择适合的聚类算法,这里选择了k-means算法作为聚类算法。
(3)设置聚类参数:设置聚类的类别数、迭代次数等参数,以得到最优的聚类结果。
(4)进行聚类分析:运行聚类分析模块,观察聚类结果和聚类中心的分布情况。
(5)结果解释与分析:根据聚类结果,对不同类别的数据进行特征分析和差异比较,以更好地理解数据的特点和分布规律。
3.实验结果与分析通过SPSS软件进行聚类分析,得到了数据样本的聚类结果。
根据平均轮廓系数和间隔分析等指标,确定了最优的聚类类别数,并得到了每个类别的聚类中心和分布情况。
3.1聚类类别数的确定为了确定合适的聚类类别数,使用平均轮廓系数方法和间隔分析方法进行评估。
通过计算不同聚类类别数下的平均轮廓系数和间隔分析值,选择具有最大平均轮廓系数和最小间隔分析值的类别数作为最优的聚类类别数。
经过计算分析,确定了聚类类别数为33.2聚类结果与分析根据聚类类别数为3的聚类结果,将数据样本分为了三组。
分别对每组数据进行了特征分析和差异比较。
3.2.1类别1:高收入、高教育水平、低消费该类别的个体具有较高的收入水平和教育水平,但消费水平较低。
使用SPSS软件进行因子分析和聚类分析的方法
使用SPSS软件进行因子分析和聚类分析的方法使用SPSS软件进行因子分析和聚类分析的方法随着统计分析软件的发展,SPSS(Statistical Package for the Social Sciences)软件作为一款功能强大、易于使用的统计分析工具受到广泛欢迎。
它能帮助研究人员进行各种统计分析,其中包括因子分析和聚类分析。
本文将介绍如何使用SPSS软件进行因子分析和聚类分析,并针对每个分析方法提供详细步骤和操作示例。
一、因子分析因子分析是一种常用的统计方法,在数据维度缩减和相关变量结构分析方面具有广泛的应用。
以下是使用SPSS软件进行因子分析的步骤:1. 数据准备首先,需要将原始数据导入SPSS软件中。
可以通过选择“文件”>“打开”>“数据”,然后选择合适的数据文件进行导入。
确保数据是以矩阵的形式存储,每个变量占据一列,每个观察单位占据一行。
2. 因子分析设置在SPSS软件中,选择“分析”>“数据准备”>“特殊分析”>“因子”。
在弹出的对话框中,选择需要进行因子分析的变量,将它们移动到“因子”框中。
然后,选择所需的因子提取方法(如主成分分析或因子分析),并指定所需的因子个数。
可以选择默认值,也可以根据实际需求进行调整。
3. 统计输出完成因子分析设置后,点击“确定”按钮开始分析。
SPSS软件将生成一个因子分析结果报告。
报告中将包含因子载荷矩阵、特征值、解释的方差比例等统计指标。
通过这些指标,可以对变量和因子之间的关系、每个因子的解释能力进行分析。
4. 结果解读对于因子载荷矩阵,可以根据因子载荷的大小来判断变量与因子之间的关系。
一般来说,载荷绝对值大于0.3的变量与因子之间具有显著关联。
解释的方差比例表示每个因子能够解释变量总方差的比例,一般来说,越大越好。
在解读结果时,需要综合考虑因子载荷和解释的方差比例。
二、聚类分析聚类分析是一种用于数据分类的统计方法。
它根据观测值之间的相似性将数据对象分组到不同的类别中。
SPSS因子、聚类案例分析报告.doc
SPSS因子、聚类案例分析报告.doc《多元统计分析SPSS》实验报告实验课程:基于 SPSS的数据分析实验地点:现代商贸实训中心实验室名称:经济统计实验室学院:xxx 学院年级专业班: xxx 班学生姓名:xxx 学号: 015完成时间:2016 年 x 月 x 日开课时间:2016 至 2017 学年第 1 学期成绩教师签名批阅日期实验项目:中国上市银行竞争力分析(一)实验目的本实验目的围绕上市商业银行竞争力这一主线,遵循一般理论、具体分析到对策建议的研究思路,以我国国内上市的十家商业银行为研究对象,采用其2012年度财务报告的数据,从盈利能力、安全能力和发展能力三方面共选取了8 个重要指标,试图通过这些指标量化影响竞争力的因素,构建我国上市商业银行的竞争力评价指标体系,并运用因子分析方法,对我国上市商业银行的竞争力状况进行了分析评价。
最后针对分析的结果,通过对我国上市银行竞争力进行优劣势比较,提出了提升我国上市商业银行竞争力的一些建议。
(二)实验资料通过对资产利润率、不良贷款率、资产负债率、资本充足率、每股收益增长率、贷款增长率、存款增长率、总资产增长率等指标的选择分析不同指标在进行因子分析时所考虑的因素是否存在差异,影响我国上市商业银行的竞争力状况的因素与上述指标是否有关。
具体数据如下所示:十家同类型上市商业银行2012 年指标盈利能力安全能力发展能力资产利润资产负债资本充足每股收益贷款增长存款增长总资产增率不良贷款率率率增长率率率长率平安银行% % % % % % % % 浦发银行% % % % % % % % 建设银行% % % % % % % % 中国银行% % % % % % % % 农业银行% % % % % % % % 工商银行% % % % % % % 10% 交通银行% % % % % % % % 招商银行% % % % % % % % 中信银行% % % % % % % % 民生银行% % % % % % % %(三)实验步骤1、选择菜单2、选择参与因子分析的变量到( 变量 V) 框中3、选择因子分析的样本4、在所示窗口中点击(描述D)按钮,指定输出结果,输出基本统计量、图形等5、在所示窗口中点击(抽取E)按钮指定提取因子的方法为:主成分分析法6、在所示的窗口中点击(旋转T)按钮选择因子旋转方法7、在所示窗口中点击(得分S)按钮选择计算因子得分的方法8、在所示窗口中点击(选项)按钮(四)实验结果及分析分析结果如下表所示。
SPSS聚类分析实验报告
SPSS聚类分析实验报告一.实验目的:1、理解聚类分析的相关理论与应用2、熟悉运用聚类分析对经济、社会问题进行分析、3、熟练SPSS软件相关操作4、熟悉实验报告的书写二•实验要求:1、生成新变量总消费支出=各变量之和2、对变量食品支出和居住支出进行配对样本T检验,并说明检验结果3、对各省的总消费支出做出条形图(用EXCEL故图也行)4、利用K-Mean法把31省分成3类5、对聚类分析结果进行解释说明6完成实验报告三•实验方法与步骤准备工作:把实验所用数据从Word文档复制到Excel,并进一步导入到SPSS数据文件中。
分析:由于本实验中要对31个个案进行分类,数量比较大,用系统聚类法当然也可以得出结果,但是相比之下在数据量较大时,K均值聚类法更快速高效,而且准确性更高。
四、实验结果与数据处理:1•用系统聚类法对所有个案进行聚类:j地区負品支出衣舌支出居性支出家庭设審圧服医疗保储支出交通和通信支文化与娱乐服其它荷品和服务支出出需支出务支岀C39Z902087 911677.351377.771327 2234M.912M1.9384849祈工180229141B.OO916 161033 703437.152596.09砂0 441567.581615.571119.931275 642454 3S1899.50588.73579C 721251 251606 27972 24617362196 S61786 00499 30rjf6746 521230 721925.211208 03339 503419 742375 96653.76河北3335 231225.941344.47693.56923 831398.351001 01395.93山西3052.571206.091245.00612.5&774.8913+0.901229.6A331 14吉林3767 851570.681344.41710.281171 251363.911244.5650609 3784 721606.371128 14618.76948.441191.311001.48402.69河面3675751444.631030 10866 72941.321374.761137 1641B.04 3702 18125S69910.34597 72828 571076.631135.70387.533784 S11165 66923.52544 01716 731116 56903 07332.49宁夏376B 591417471181 7171622390 0515745712跖羽500 12 3694 911513.428M 36669 8770G 161255.87151237444 204211.442203.5913&4一45948.87112&.031TW.651641 17加-述辽宁4658. &Q1586.811314.7S785.671079 811773 261495.90585.787十 1 二1 1、詩ES宽虞■W标荟值缺失底塑标准学符串8卅无无8A^X(N)食品交出M㈣82无无B=t衣蒼支出82无无S至右居住支出a2无无$走右家腥谡备佥…S2无无S走右耒彌医疗保健去出S2无无芋右未知交通和通信32无无三右未知文化与溟乐82无无3三右未知苴它荷品和数值(M)82无无未和1 ______生成新变量总消费支出=各变量之和如图所示:地区食品更出衣着支出居住支出宏庭设备及匪医疗煤健芟出交通和迪信支文化与握乐船苴它商腊手朋H 岀気主出务吏出总稍费支出北亲6392 902007 91157? 351377 771327.223420 912901 93&48 49浙辽6118 461802 291419 00916 161033 703437 152506 W54^361TB58J 去津5940 441567.581615.671119.931275 642454 3S1899.60608J316561.7 m5790721281.251606,27972.24617.362196.8B1786.00499.3014750.0广东67^6.621230.721925.211209.03S29.M3419.742375.966537618439.5河北3335.231225.941344 47693.&G923.83139®. 351001.01395.9310318.3』西3062571205 89124500612.59774 891340M1229 6€331.149792.6吉林376? 651570 681344 41710 281171 251363 91T244 弭506 0911679 0 3?S4 ??1600 371128 1461$ 7694S441191 311001 4S402 &910GQ3 9河旬3575.751444.631080 10B66 72941321374761137.16418.0410838.4甘京3702.181255.69910,34597.72S38.571076.631136.70387.539895.3 3784 8111185.56923,62644.01716761116.569Q8.Q73324996113.8'宁夏3768.091417.471181.7171622BM.O51574.671286. M500 1211334.4 3694.81151142的白3B£69 877W161255.971012.37444.20101&7.04211 482203 5913M 46949 3?1126 0317«r«51641 17710 3713994 6些宁4658 00[阴E n1314 797砧砺1079 811773 261495 90586 7613280 0.----------------- —I.;2.对变量食品支出和居住支出进行配对样本T检验,如图所示:得出结论:■+ T检验[飯据巔°】\Document5 and Settings'.Administrator 面l耒板题3.对各省的总消费支出做出条形图,如图所示:4 •对聚类分析结果进行解释说明:K均值分析将这样的城市分为三类:第一类北京、上海、广东第二类除第一类第三类以外的第三类天津、福建、内蒙古、辽宁、山东第一类经济发展水平高,各项支出占总支出比重高,人民生活水平高。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
喀什大学实验报告《多元统计分析SPSS实验报告实验课程:基于SPSS的数据分析实验地点:现代商贸实训中心实验室名称:经济统计实验室学院: XXX学院年级专业班:XXX班学生姓名:XXX 学号:20131808015完成时间:2016 年X月X日开课时间:2016 至2017 学年第1 学期实验项目:中国上市银行竞争力分析(一)实验目的本实验目的围绕上市商业银行竞争力这一主线,遵循一般理论、具体分析到对策建议的研究思路,以我国国内上市的十家商业银行为研究对象,采用其2012年度财务报告的数据,从盈利能力、安全能力和发展能力三方面共选取了8个重要指标,试图通过这些指标量化影响竞争力的因素,构建我国上市商业银行的竞争力评价指标体系,并运用因子分析方法,对我国上市商业银行的竞争力状况进行了分析评价。
最后针对分析的结果,通过对我国上市银行竞争力进行优劣势比较,提出了提升我国上市商业银行竞争力的一些建议。
(二)实验资料通过对资产利润率、不良贷款率、资产负债率、资本充足率、每股收益增长率、贷款增长率、存款增长率、总资产增长率等指标的选择分析不同指标在进行因子分析时所考虑的因素是否存在差异,影响我国上市商业银行的竞争力状况的因素与上述指标是否有关。
具体数据如下所示:(三)实验步骤1、选择菜单2、选择参与因子分析的变量到(变量V)框中3、选择因子分析的样本4、在所示窗口中点击(描述D)按钮,指定输出结果,输出基本统计量、图5、在所示窗口中点击(抽取E)按钮指定提取因子的方法为:6在所示的窗口中点击(旋转T)按钮选择因子旋转方法形等Vi93 23% U12K15.&*%8 3JK.i4 ir%riOMTSO' 開W05%3 6?%121]tpSJKr?-113TM « 07%WU%124SS 26 £5%谄01%«心羽也帕J叽越雀IB23%42% U W%ig> 13 DQ%31%. T6(H%馬* K.Dfi%fld% 昭卿驚主成分分析法1 42% 0 6S% 44 越鴨1韵飓«的恤站20%髄#A#*/#*7、在所示窗口中点击(得分S)按钮选择计算因子得分的方法8、在所示窗口中点击(选项)按钮(四)实验结果及分析分析结果如下表所示。
通过观察原始变量的相关系数矩阵,可以看到,矩阵中存在许多比较高的相关系数,并且大多数变量通过了原假设为相应变量之间的相关系数为0的t假设。
相关系数实际上反映的是公共因子起作用的空间,相关系数越大,表明数据适合做因子分析。
同时,KM(级Bartlett 检验是否适合做因子分析。
以上是KMC级Bartlett 检验结果,由表可知:KMO值为0.518,说明该数据适合做因子分析。
上表中的巴特利特球体检验的X统计值的显著性概率是O. 000,小于1%,因此拒绝原假设,说明数据具有相关性,适宜做因子分析。
a.取样适切性量数(MSA)反映像矩阵在其对角线上的数字若大于0.05 (出口合同为0.406 )则适合因子分析,小于0.05则不适合因子分析。
从表中得知,适合做因子分析。
提取方法:主成分分析法。
变量共同度,它刻划了全部公共因子对各个变量的总方差所作的贡献,也称为公因子方差,从上表中可以得到变量共同度大部分都接近1,说明该变量的几乎全部原始信息都被所选取的公共因子说明了,也就是说,由原始变量空间转为因子空间转化的性质较好,保留原来信息量多,因此,h「是X i方差的重要组成部分。
检验可以做因子分析后,我们通过因子分析得到相应的特征值和对应因子的贡献率,如下表所示综合因子F,,F2, F3的特征值大于1,且对原始数据的累积贡献率达到了84.485 %,其中F1的贡献率最强,达到了34.998 %, F2的贡献率达到了33.383 %,F3的贡献率也达到了16.104 %。
这三个因子的贡献率都远远大于其它因子的贡献率,因此,F1, F2,F3是决定商业银行竞争力强弱的关键因子。
组杵号从碎石图中得到,第1个因子的特征值高于其他项,对解释原有变量的贡献最大;第5个因子之后的特征值都小,对解释原有变量的贡献较小;因此我们可以取3个或4个因子较为合适。
a提取方法:主成分分析法。
aa.提取了3个成分。
表中给出旋转前的因子载荷阵,从中可以看出,每个因子在不同原始变量上的载荷没有明显的差别,3个因子的实际含义比较模糊。
为了避免初始因子综合性太强,难以找出因子的实际意义的问题,需要通过旋转坐标轴,使负载尽可能向正负0或1的方向靠近,从而降低因子的综合性,使其真实意义凸现出来。
下面使用的因子旋转方法为方差最大正交旋转法,目的是使旋转后的因子载荷矩阵的结构简化,便于对各个公共因子进行合理的解释,同时保证每一个公共因子反映的信息量尽量最大。
a提取方法:主成分分析法。
旋转方法:凯撒正态化最大方差法。
成分得分系数矩阵成分1资产利润率-.165 不良贷款率-.009 资产负债率.359 资本充足率-.368 每股收益增长率.203 贷款增长率-.138存款增长率-.016 总资产增长率.167 2 3-.029 .544-.138 -.516.012-.034 .046 .072-.051 .370.378 .137.371 .003.304 .083a.旋转在4次迭代后已收敛表中给出旋转后的因子载荷阵,从表中可以看出,经过旋转后的载荷系数已经明显的两极分化了。
第一个公共因子在指标X2每股收益增长率、X3资产负债率、X4资本充足率上有较大载荷,说明这3个指标有较强的关联性,可以归为一类,因此可以把第一个因子命名为“流动因子”;第二个公共因子在指标X6贷款增长率、X7存款增长率、X8总资产增长率上有较大载荷,同样可以归为一类,第二个因子可以命名为“发展因子”;同理,X1资产利润率、X5不良贷款率归到第3类,将其命名为“安全和盈利因子”。
腕鶴话的空间叩的组件囹在三维空间组件图中,各因子更接近于组价几,接近组件几对应的是‘旋转后的成分矩阵’的成分几。
旋转方法:凯撒正态化最大方差法。
组件得分。
表中给出了因子得分系数矩阵,根据表中的因子得分系数和原始变量的标准化值就可以计算出每个观测值的各因子的得分。
旋转后的因子得分表达式可以写成F1=-0.165x1+0.203x2+0.359x3-0.368x4-0.009x5-0.138x6-0.016x7+0.167x8F2=-0.029x1-0.051x2+0.012x3+0.046x4-0.138x5+0.378x6+0.371x7+0.304x8F3=0.544x1+0.370x2-0.034x3+0.072x4-0.516x5+0.137x6+0.003x7+0.083x8 五、结论本文通过采用多元统计分析中的因子分析法对国有商业银行的经营绩效加以评价,从盈利能力、安全能力和发展能力三方面来具体分析我国上市商业银行竞争力,对上市银行及非上市银行具有一定的指导作用。
实验项目:商厦评分(一)实验目的:本实验目的利用SPSS层次聚类对商厦评分进行分类分析,以了解了解各商厦之间的相互关系。
(二)实验资料:(三)实验步骤: 表一表一可知,当聚成3类时,A,B俩个商厦为一类,C商厦自成一类,D, E 两个商厦为一类;当聚成两类时,A, B俩个商厦为一类,C, D, E三个商厦为一类,SPSS的层次聚类能够产生任意类数的分类结果。
图一,可知,D 商厦与E 商厦的距离最近,首先合并成一类,其次,合并的 是A ,B 俩个商厦它们的距离比D 商厦与E 商厦大,最后是合并C 商厦。
最后聚 城一体。
图二:图二,可知,当聚成4类时,D, E 两个商厦为一类;其他各商厦自成一类, 聚成3类时,A , B 俩个商厦为一类,C 商厦自成一类,D, E 两个商厦为一类; 当聚成两类时,A, B 俩个商厦为一类,C, D, E 三个商厦为一类。
0同團左I :!・A CRv 1/ARTIBTA ■ 1蚀用冲均勰搂(靖间J 的谱熱開表二,可知,3个初始类中心点的数据,分别为(94,90)(66,64)(84,82)可见第一类最优,第三类次之,第二类最差。
表三aa.由于聚类中心中不存在变动或者仅有小幅变动,因此实现了收敛。
任何中心的最大绝对坐标变动为.000。
当前迭代为2。
初始中心之间的最小距离为12.806。
表三,可知,第一次迭代后,3个类中心点分别偏移了1.803,4.013.0.000 第2类中心点的偏移最大,在第3类和第二次迭代时中心点偏移均小于判定标准(0.02 ),聚类分析结束。
表四表四,可知,最终类中心点的情况,分别为(92.5,89)(69.5,66)(84,82)仍然可见第一类为最优,第三类第二,第二类效果最差。
表五ANOV A| 聚类误差 F 显著性由于已选择聚类以使不同聚类中个案之间的差异最大化,因此F检验只应该用于描述目的。
实测显著性水平并未因此进行修正,所以无法解释为针对“聚类平均值相等”这一假设的检验。
由表五,展现了各指标在不同的均值比较情况,各数据项的含义依次为组间均方、组间自由度、组内均方、组内自由度、F统计量的观察值以及对应的概率P-值。
仍然看出第二类的差异最大。
(三)实验结论:因此,在总数为五,有效数值为五的情况下的聚类分析可得,E商厦属最优类;C,D商厦属良好类;A,B商厦属合格类。