SPSS实验8-二项Logistic回归分析
SPSS—二元Logistic回归结果分析报告
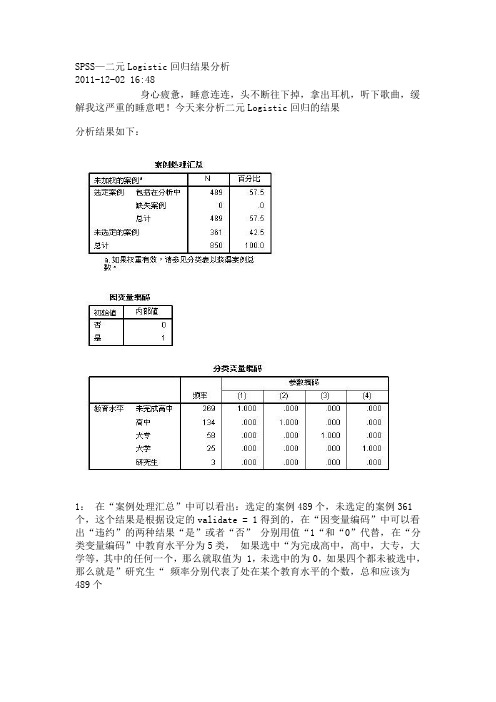
SPSS—二元Logistic回归结果分析2011-12-02 16:48身心疲惫,睡意连连,头不断往下掉,拿出耳机,听下歌曲,缓解我这严重的睡意吧!今天来分析二元Logistic回归的结果分析结果如下:1:在“案例处理汇总”中可以看出:选定的案例489个,未选定的案例361个,这个结果是根据设定的validate = 1得到的,在“因变量编码”中可以看出“违约”的两种结果“是”或者“否” 分别用值“1“和“0”代替,在“分类变量编码”中教育水平分为5类,如果选中“为完成高中,高中,大专,大学等,其中的任何一个,那么就取值为 1,未选中的为0,如果四个都未被选中,那么就是”研究生“ 频率分别代表了处在某个教育水平的个数,总和应该为489个1:在“分类表”中可以看出:预测有360个是“否”(未违约)有129个是“是”(违约)2:在“方程中的变量”表中可以看出:最初是对“常数项”记性赋值,B为-1.026,标准误差为:0.103那么wald =( B/S.E)²=(-1.026/0.103)² = 99.2248, 跟表中的“100.029几乎接近,是因为我对数据进行的向下舍入的关系,所以数据会稍微偏小,B和Exp(B) 是对数关系,将B进行对数抓换后,可以得到:Exp(B) = e^-1.026 = 0.358, 其中自由度为1, sig为0.000,非常显著1:从“不在方程中的变量”可以看出,最初模型,只有“常数项”被纳入了模型,其它变量都不在最初模型表中分别给出了,得分,df , Sig三个值, 而其中得分(Score)计算公式如下:(公式中(Xi- X¯) 少了一个平方)下面来举例说明这个计算过程:(“年龄”自变量的得分为例)从“分类表”中可以看出:有129人违约,违约记为“1”则违约总和为 129,选定案例总和为489那么: y¯ = 129/489 = 0.16x¯ = 16951 / 489 = 34.2所以:∑(Xi-x¯)² = 30074.9979y¯(1-y¯)=0.16 *(1-0.16 )=0.216则:y¯(1-y¯)* ∑(Xi-x¯)² =0.216 * 30074.9979 = 5 840.9044060372 则:[∑Xi(yi - y¯)]^2 = 43570.8所以:=43570.8 / 5 840.9044060372 = 7.76 = 7.46 (四舍五入)计算过程采用的是在 EXCEL 里面计算出来的,截图如下所示:从“不在方程的变量中”可以看出,年龄的“得分”为7.46,刚好跟计算结果吻合!!答案得到验证~!!!!1:从“块1” 中可以看出:采用的是:向前步进的方法,在“模型系数的综合检验”表中可以看出:所有的SIG 几乎都为“0”而且随着模型的逐渐步进,卡方值越来越大,说明模型越来越显著,在第4步后,终止,根据设定的显著性值和自由度,可以算出卡方临界值,公式为:=CHIINV(显著性值,自由度) ,放入excel就可以得到结果2:在“模型汇总“中可以看出:Cox&SnellR方和 Nagelkerke R方拟合效果都不太理想,最终理想模型也才:0.305 和 0.446,最大似然平方的对数值都比较大,明显是显著的似然数对数计算公式为:计算过程太费时间了,我就不举例说明计算过程了Cox&SnellR方的计算值是根据:1:先拟合不包含待检验因素的Logistic模型,求对数似然函数值INL0 (指只包含“常数项”的检验)2:再拟合包含待检验因素的Logistic模型,求新的对数似然函数值InLB (包含自变量的检验)再根据公式:即可算出:Cox&SnellR 方的值!提示:将Hosmer 和 Lemeshow 检验和“随机性表” 结合一起来分析1:从Hosmer 和 Lemeshow 检验表中,可以看出:经过4次迭代后,最终的卡方统计量为:11.919,而临界值为:CHINV(0.05,8) = 15.507卡方统计量< 临界值,从SIG 角度来看: 0.155 > 0.05 , 说明模型能够很好的拟合整体,不存在显著的差异。
SPSS—二元Logistic回归结果分析

SPSS—二元Logistic回归结果分析2011-12-02 16:48身心疲惫,睡意连连,头不断往下掉,拿出耳机,听下歌曲,缓解我这严重的睡意吧!今天来分析二元Logistic回归的结果分析结果如下:1:在“案例处理汇总”中可以看出:选定的案例489个,未选定的案例361个,这个结果是根据设定的validate = 1得到的,在“因变量编码”中可以看出“违约”的两种结果“是”或者“否” 分别用值“1“和“0”代替,在“分类变量编码”中教育水平分为5类,如果选中“为完成高中,高中,大专,大学等,其中的任何一个,那么就取值为 1,未选中的为0,如果四个都未被选中,那么就是”研究生“ 频率分别代表了处在某个教育水平的个数,总和应该为489个1:在“分类表”中可以看出:预测有360个是“否”(未违约)有129个是“是”(违约)2:在“方程中的变量”表中可以看出:最初是对“常数项”记性赋值,B为,标准误差为:那么wald =( B/²=² = , 跟表中的“几乎接近,是因为我对数据进行的向下舍入的关系,所以数据会稍微偏小,B和Exp(B) 是对数关系,将B进行对数抓换后,可以得到:Exp(B) = e^ = , 其中自由度为1, sig为,非常显著1:从“不在方程中的变量”可以看出,最初模型,只有“常数项”被纳入了模型,其它变量都不在最初模型内表中分别给出了,得分,df , Sig三个值, 而其中得分(Score)计算公式如下:(公式中(Xi- X¯) 少了一个平方)下面来举例说明这个计算过程:(“年龄”自变量的得分为例)从“分类表”中可以看出:有129人违约,违约记为“1”则违约总和为 129,选定案例总和为489那么: y¯ = 129/489 =x¯ = 16951 / 489 =所以:∑(Xi-x¯)² =y¯(1-y¯)= *()=则:y¯(1-y¯)* ∑(Xi-x¯)² = * = 5则:[∑Xi(yi - y¯)]^2 =所以:= / 5 = = (四舍五入)计算过程采用的是在 EXCEL 里面计算出来的,截图如下所示:从“不在方程的变量中”可以看出,年龄的“得分”为,刚好跟计算结果吻合!!答案得到验证~!!!!1:从“块1” 中可以看出:采用的是:向前步进的方法,在“模型系数的综合检验”表中可以看出:所有的SIG 几乎都为“0”而且随着模型的逐渐步进,卡方值越来越大,说明模型越来越显著,在第4步后,终止,根据设定的显著性值和自由度,可以算出卡方临界值,公式为:=CHIINV(显著性值,自由度) ,放入excel就可以得到结果2:在“模型汇总“中可以看出:Cox&SnellR方和 Nagelkerke R方拟合效果都不太理想,最终理想模型也才:和,最大似然平方的对数值都比较大,明显是显著的似然数对数计算公式为:计算过程太费时间了,我就不举例说明计算过程了Cox&SnellR方的计算值是根据:1:先拟合不包含待检验因素的Logistic模型,求对数似然函数值INL0 (指只包含“常数项”的检验)2:再拟合包含待检验因素的Logistic模型,求新的对数似然函数值InLB (包含自变量的检验)再根据公式:即可算出:Cox&SnellR 方的值!提示:将Hosmer 和 Lemeshow 检验和“随机性表” 结合一起来分析1:从Hosmer 和 Lemeshow 检验表中,可以看出:经过4次迭代后,最终的卡方统计量为:,而临界值为:CHINV,8) =卡方统计量< 临界值,从SIG 角度来看: > , 说明模型能够很好的拟合整体,不存在显著的差异。
SPSS的Logistics回归

SPSS的Logistics回归实验⽬的学会使⽤SPSS的简单操作,Logistic回归。
实验要求使⽤SPSS。
实验内容实验步骤 (1)⼆项分类Logistic回归SPSS分析,使⽤Hosmer和Lemeshow于1989年研究低出⽣体重婴⼉的影响因素作为演⽰例⼦。
结果变量为“是否娩出低出⽣体重⼉”,考虑影响因素有8个,详见Logistics_step.sav⽂件。
本例题主要演⽰“⾃变量的筛选与逐步回归”。
操作如下:点击【分析】→【回归】→【⼆元Logistics回归】,在打开的对话框中,把待结果变量LOW选⼊【因变量】中,将变量LWT,AGE,SMOKE,PTL,HT,UI,FTV,RACE选⼊【协变量】中。
点击【分类】,把RACE选⼊【分类协变量】→【第⼀个】→【变化量】→【继续】,【块】⾥的【⽅法(M)】选【向前:LP】,【选项】→【Exp(B)的置信区间】→【继续】,单击【运⾏】。
主要分析结果如下:分类变量编码频率参数编码(1)(2)种族⽩⼈96.000.000⿊⼈26 1.000.000其他种族67.000 1.000 上表输出race在产⽣哑变量时的编码情况,以⽩⼈为参照⽔平。
未包括在⽅程中的变量得分⾃由度显著性步骤 0变量产妇体重 4.6161.032产妇年龄 2.4071.121产妇在妊娠期间是否吸烟 4.9241.026本次妊娠前早产次数7.2671.007是否患有⾼⾎压 4.3881.036应激性 4.2051.040随访次数.9341.334种族 5.0052.082种族(1) 1.7271.189种族(2) 1.7971.180总体统计29.1409.001 输出的是拟合包含常数项和任⼀⾃变量的Logistics回归模型检验统计量、⾃由度及P值。
其中race产⽣两个哑变量,因此其总⾃由度为2。
由上表可以发现,本次妊娠前早产次数(ptl)的score统计量最⼤,P=0.007,⼩于SPSS默认选⼊变量的标准(0.05)因此下⼀步将它⾸先选⼊模型。
SPSS—二元Logistic回归结果分析

SPSS—二元Logistic回归结果分析2011-12-02 16:48身心疲惫,睡意连连,头不断往下掉,拿出耳机,听下歌曲,缓解我这严重的睡意吧!今天来分析二元Logistic回归的结果分析结果如下:1:在“案例处理汇总”中可以看出:选定的案例489个,未选定的案例361个,这个结果是根据设定的validate = 1得到的,在“因变量编码”中可以看出“违约”的两种结果“是”或者“否” 分别用值“1“和“0”代替,在“分类变量编码”中教育水平分为5类,如果选中“为完成高中,高中,大专,大学等,其中的任何一个,那么就取值为 1,未选中的为0,如果四个都未被选中,那么就是”研究生“ 频率分别代表了处在某个教育水平的个数,总和应该为489个1:在“分类表”中可以看出:预测有360个是“否”(未违约)有129个是“是”(违约)2:在“方程中的变量”表中可以看出:最初是对“常数项”记性赋值,B为-1.026,标准误差为:0.103那么wald =( B/S.E)²=(-1.026/0.103)² = 99.2248, 跟表中的“100.029几乎接近,是因为我对数据进行的向下舍入的关系,所以数据会稍微偏小,B和Exp(B) 是对数关系,将B进行对数抓换后,可以得到:Exp(B) = e^-1.026 = 0.358, 其中自由度为1, sig为0.000,非常显著1:从“不在方程中的变量”可以看出,最初模型,只有“常数项”被纳入了模型,其它变量都不在最初模型内表中分别给出了,得分,df , Sig三个值, 而其中得分(Score)计算公式如下:(公式中(Xi- X¯) 少了一个平方)下面来举例说明这个计算过程:(“年龄”自变量的得分为例)从“分类表”中可以看出:有129人违约,违约记为“1”则违约总和为 129,选定案例总和为489那么: y¯ = 129/489 = 0.2638036809816x¯ = 16951 / 489 = 34.664621676892所以:∑(Xi-x¯)² = 30074.9979y¯(1-y¯)=0.2638036809816 *(1-0.2638036809816 )=0.19421129888216则:y¯(1-y¯)* ∑(Xi-x¯)² =0.19421129888216 * 30074.9979 = 5 840.9044060372则:[∑Xi(yi - y¯)]^2 = 43570.8所以:=43570.8 / 5 840.9044060372 = 7.4595982010876 = 7.46 (四舍五入)计算过程采用的是在 EXCEL 里面计算出来的,截图如下所示:从“不在方程的变量中”可以看出,年龄的“得分”为7.46,刚好跟计算结果吻合!!答案得到验证~1:从“块1” 中可以看出:采用的是:向前步进的方法,在“模型系数的综合检验”表中可以看出:所有的SIG 几乎都为“0”而且随着模型的逐渐步进,卡方值越来越大,说明模型越来越显著,在第4步后,终止,根据设定的显著性值和自由度,可以算出卡方临界值,公式为:=CHIINV(显著性值,自由度) ,放入excel就可以得到结果2:在“模型汇总“中可以看出:Cox&SnellR方和 Nagelkerke R方拟合效果都不太理想,最终理想模型也才:0.305 和 0.446,最大似然平方的对数值都比较大,明显是显著的似然数对数计算公式为:计算过程太费时间了,我就不举例说明计算过程了Cox&SnellR方的计算值是根据:1:先拟合不包含待检验因素的Logistic模型,求对数似然函数值INL0 (指只包含“常数项”的检验)2:再拟合包含待检验因素的Logistic模型,求新的对数似然函数值InLB (包含自变量的检验)再根据公式:即可算出:Cox&SnellR 方的值!提示:将Hosmer 和 Lemeshow 检验和“随机性表” 结合一起来分析1:从Hosmer 和 Lemeshow 检验表中,可以看出:经过4次迭代后,最终的卡方统计量为:11.919,而临界值为:CHINV(0.05,8) = 15.507卡方统计量< 临界值,从SIG 角度来看: 0.155 > 0.05 , 说明模型能够很好的拟合整体,不存在显著的差异。
利用SPSS进行Logistic回归分析
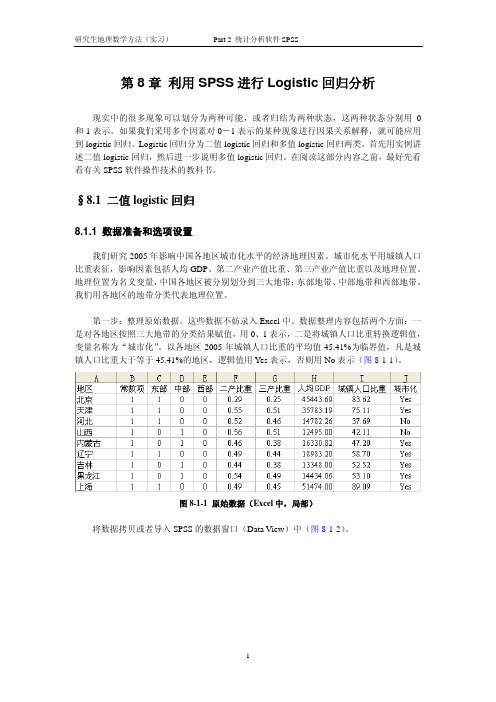
图 8-1-10 因变量编码
3. Categorical Variables Codings(分类变量编码)。我们的自变量中涉及到代表不同地 域类型的名义变量(图 8-1-11)。在我们开始的分类中,属于中部用 1 表示,否则用 0 表示。 但是,SPSS 改变了这种编码,原来的 0 改用 1 表示,原来的 1 改用 0 表示。也就是说,在 这次 SPSS 分析过程中,0 代表属于中部的地区,1 代表不属于中部的地区。记住这个分类 对后面开展预测分析非常重要。
图 8-1-6 定义分类变量选项
⒉ 设置 Save(保存)选项:决定保存到 Data View 的计算结果(图 8-1-7) 。 选中 Leverage values、DfBeta(s)、Standardized 和 Deviance 四项。 完成后,点击 Continue 继续。
4
研究生地理数学方法(实习)
Categorical Variables Codings Paramete
中部
0 1
Frequency 22 9
(1) 1.000 .000
图 8-1-11 分类变量编码
4. Classification Table(初始分类表) 。Logistic 建模如同其他很多种建模方式一样,首先 对模型参数赋予初始值,然后借助迭代计算寻找最佳值。以误差最小为原则,或者以最大似 然为原则,促使迭代过程收敛。当参数收敛到稳定值之后,就给出了我们需要的比较理想的 参数值。下面是用初始值给出的预测和分类结果(图 8-1-12) 。这个结果主要用于对比,比 较模型参数收敛前后的效果。
SPSS—二元Logistic回归结果分析.docx

SPSS—二元Logistic回归结果分析2011-12-02 16:48身心疲惫,睡意连连,头不断往下掉,拿出耳机,听下歌曲,缓解我这严重的睡意吧!今天来分析二元Logistic回归的结果分析结果如下:1:在“案例处理汇总”中可以看出:选定的案例489个,未选定的案例361个,这个结果是根据设定的validate = 1得到的,在“因变量编码”中可以看出“违约”的两种结果“是”或者“否” 分别用值“1“和“0”代替,在“分类变量编码”中教育水平分为5类,如果选中“为完成高中,高中,大专,大学等,其中的任何一个,那么就取值为 1,未选中的为0,如果四个都未被选中,那么就是”研究生“ 频率分别代表了处在某个教育水平的个数,总和应该为489个1:在“分类表”中可以看出:预测有360个是“否”(未违约)有129个是“是”(违约)2:在“方程中的变量”表中可以看出:最初是对“常数项”记性赋值,B为-1.026,标准误差为:0.103那么wald =( B/S.E)²=(-1.026/0.103)² = 99.2248, 跟表中的“100.029几乎接近,是因为我对数据进行的向下舍入的关系,所以数据会稍微偏小,B和Exp(B) 是对数关系,将B进行对数抓换后,可以得到:Exp(B) = e^-1.026 = 0.358, 其中自由度为1, sig为0.000,非常显著1:从“不在方程中的变量”可以看出,最初模型,只有“常数项”被纳入了模型,其它变量都不在最初模型内表中分别给出了,得分,df , Sig三个值, 而其中得分(Score)计算公式如下:(公式中(Xi- X¯) 少了一个平方)下面来举例说明这个计算过程:(“年龄”自变量的得分为例)从“分类表”中可以看出:有129人违约,违约记为“1”则违约总和为 129,选定案例总和为489那么: y¯ = 129/489 = 0.2638036809816x¯ = 16951 / 489 = 34.664621676892所以:∑(Xi-x¯)² = 30074.9979y¯(1-y¯)=0.2638036809816 *(1-0.2638036809816 )=0.19421129888216则:y¯(1-y¯)* ∑(Xi-x¯)² =0.19421129888216 * 30074.9979 = 5 840.9044060372则:[∑Xi(yi - y¯)]^2 = 43570.8所以:=43570.8 / 5 840.9044060372 = 7.4595982010876 = 7.46 (四舍五入)计算过程采用的是在 EXCEL 里面计算出来的,截图如下所示:从“不在方程的变量中”可以看出,年龄的“得分”为7.46,刚好跟计算结果吻合!!答案得到验证~!!!!1:从“块1” 中可以看出:采用的是:向前步进的方法,在“模型系数的综合检验”表中可以看出:所有的SIG 几乎都为“0”而且随着模型的逐渐步进,卡方值越来越大,说明模型越来越显著,在第4步后,终止,根据设定的显著性值和自由度,可以算出卡方临界值,公式为:=CHIINV(显著性值,自由度) ,放入excel就可以得到结果2:在“模型汇总“中可以看出:Cox&SnellR方和 Nagelkerke R方拟合效果都不太理想,最终理想模型也才:0.305 和 0.446,最大似然平方的对数值都比较大,明显是显著的似然数对数计算公式为:计算过程太费时间了,我就不举例说明计算过程了Cox&SnellR方的计算值是根据:1:先拟合不包含待检验因素的Logistic模型,求对数似然函数值INL0 (指只包含“常数项”的检验)2:再拟合包含待检验因素的Logistic模型,求新的对数似然函数值InLB (包含自变量的检验)再根据公式:即可算出:Cox&SnellR 方的值!提示:将Hosmer 和 Lemeshow 检验和“随机性表” 结合一起来分析1:从Hosmer 和 Lemeshow 检验表中,可以看出:经过4次迭代后,最终的卡方统计量为:11.919,而临界值为:CHINV(0.05,8) = 15.507卡方统计量< 临界值,从SIG 角度来看: 0.155 > 0.05 , 说明模型能够很好的拟合整体,不存在显著的差异。
SPSS实验8-二项Logistic回归分析
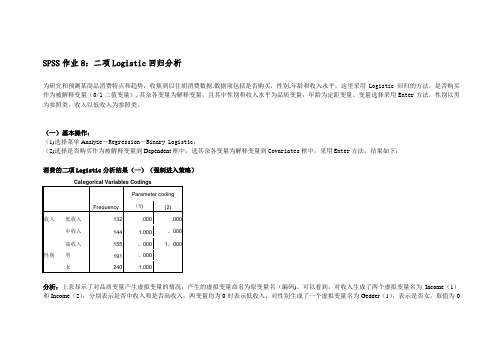
SPSS作业8:二项Logistic回归分析为研究和预测某商品消费特点和趋势,收集到以往胡消费数据.数据项包括是否购买,性别,年龄和收入水平。
这里采用Logistic回归的方法,是否购买作为被解释变量(0/1二值变量),其余各变量为解释变量,且其中性别和收入水平为品质变量,年龄为定距变量。
变量选择采用Enter方法,性别以男为参照类,收入以低收入为参照类。
(一)基本操作:(1)选择菜单Analyz e-Regression-Binary Logistic;(2)选择是否购买作为被解释变量到Dependent框中,选其余各变量为解释变量到Covariates框中,采用Enter方法,结果如下:消费的二项Logistic分析结果(一)(强制进入策略)Categorical Variables CodingsFrequency Parameter coding (1) (2)收入低收入132 .000 .000中收入144 1.000 。
000高收入155 。
000 1。
000性别男191 。
000女240 1.000分析:上表显示了对品质变量产生虚拟变量的情况,产生的虚拟变量命名为原变量名(编码)。
可以看到,对收入生成了两个虚拟变量名为Income(1)和Income(2),分别表示是否中收入和是否高收入,两变量均为0时表示低收入;对性别生成了一个虚拟变量名为Gedder(1),表示是否女,取值为0时表示为男。
消费的二项Logistic 分析结果(二)(强制进入策略)Block 0: Beginning BlockClassification Table a,bObserved Predicted是否购买 Percentage Correct不购买购买Step 0是否购买不购买 269 0 100。
购买162。
0 Overall Percentage62。
4a 。
Constant is included in the model 。
spss的logistic分析教程

Logistic回归主要分为三类,一种是因变量为二分类得logistic回归,这种回归叫做二项logistic回归,一种是因变量为无序多分类得logistic回归,比如倾向于选择哪种产品,这种回归叫做多项logistic回归。
还有一种是因变量为有序多分类的logistic回归,比如病重的程度是高,中,低呀等等,这种回归也叫累积logistic回归,或者序次logistic回归。
二值logistic回归:选择分析——回归——二元logistic,打开主面板,因变量勾选你的二分类变量,这个没有什么疑问,然后看下边写着一个协变量。
有没有很奇怪什么叫做协变量?在二元logistic回归里边可以认为协变量类似于自变量,或者就是自变量。
把你的自变量选到协变量的框框里边。
细心的朋友会发现,在指向协变量的那个箭头下边,还有一个小小的按钮,标着a*b,这个按钮的作用是用来选择交互项的。
我们知道,有时候两个变量合在一起会产生新的效应,比如年龄和结婚次数综合在一起,会对健康程度有一个新的影响,这时候,我们就认为两者有交互效应。
那么我们为了模型的准确,就把这个交互效应也选到模型里去。
我们在右边的那个框框里选择变量a,按住ctrl,在选择变量b,那么我们就同时选住这两个变量了,然后点那个a*b的按钮,这样,一个新的名字很长的变量就出现在协变量的框框里了,就是我们的交互作用的变量。
然后在下边有一个方法的下拉菜单。
默认的是进入,就是强迫所有选择的变量都进入到模型里边。
除去进入法以外,还有三种向前法,三种向后法。
一般默认进入就可以了,如果做出来的模型有变量的p值不合格,就用其他方法在做。
再下边的选择变量则是用来选择你的个案的。
一般也不用管它。
选好主面板以后,单击分类(右上角),打开分类对话框。
在这个对话框里边,左边的协变量的框框里边有你选好的自变量,右边写着分类协变量的框框则是空白的。
你要把协变量里边的字符型变量和分类变量选到分类协变量里边去(系统会自动生成哑变量来方便分析,什么事哑变量具体参照前文)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SPSS作业8:二项Logistic回归分析为研究和预测某商品消费特点和趋势,收集到以往胡消费数据。
数据项包括是否购买,性别,年龄和收入水平。
这里采用Logistic回归的方法,是否购买作为被解释变量(0/1二值变量),其余各变量为解释变量,且其中性别和收入水平为品质变量,年龄为定距变量。
变量选择采用Enter方法,性别以男为参照类,收入以低收入为参照类。
(一)基本操作:(1)选择菜单Analyz e-Regression-Binary Logistic;(2)选择是否购买作为被解释变量到Dependent框中,选其余各变量为解释变量到Covariates框中,采用Enter方法,结果如下:消费的二项Logistic分析结果(一)(强制进入策略)Categorical Variables CodingsFrequency Parameter coding (1) (2)收入低收入132 .000 .000中收入144 1.000 .000高收入155 .000 1.000性别男191 .000女240 1.000分析:上表显示了对品质变量产生虚拟变量的情况,产生的虚拟变量命名为原变量名(编码)。
可以看到,对收入生成了两个虚拟变量名为Income(1)和Income(2),分别表示是否中收入和是否高收入,两变量均为0时表示低收入;对性别生成了一个虚拟变量名为Gedder(1),表示是否女,取值为0时表示为男。
消费的二项Logistic 分析结果(二)(强制进入策略)Block 0: Beginning BlockClassification Table a,bObserved Predicted是否购买 Percentage Correct不购买购买Step 0是否购买不购买 269 0100.0购买162.0 Overall Percentage62.4a. Constant is included in the model.b. The cut value is .500分析:上表显示了Logistic 分析初始阶段(第零步)方程中只有常数项时的错判矩阵。
可以看到:269人中实际没购买且模型预测正确,正确率为100%;162人中实际购买了但模型均预测错误,正确率为0%。
模型总的预测正确率为62.4%。
消费的二项Logistic 分析结果(三)(强制进入策略)Variables in the EquationB S.E. Wald df Sig. Exp(B)Step 0 Constant -.507 .099 26.002 1 .000 .602分析:上表显示了方程中只有常数项时的回归系数方面的指标,各数据项的含义依次为回归系数,回归系数标准误差,Wald检验统计量的观测值,自由度,Wald检验统计量的概率p值,发生比。
由于此时模型中未包含任何解释变量,因此该表没有实际意义。
消费的二项Logistic分析结果(四)(强制进入策略)Variables not in the EquationScore df Sig.Step 0 Variables age 1.268 1 .260gender(1) 4.667 1 .031income 10.640 2 .005income(1) 2.935 1 .087income(2) 10.640 1 .001Overall Statistics 18.273 4 .001分析:上表显示了待进入方程的各个变量的情况,各数据项的含义依次为Score检验统计量的观测值,自由度和概率p值。
可以看到,如果下一步Age 进入方程,则Score检验统计量的观测值为1.268,概率p值为0.26。
如果显著性水平a为0.05,由于Age的概率p值大于显著性水平a,所以是不能进入方程的。
但在这里,由于解释变量的筛选策略为Enter,所以这些变量也被强行进入方程。
消费的二项Logistic分析结果(五)(强制进入策略)Block 1: Method = EnterOmnibus Tests of Model CoefficientsChi-square df Sig.Step 1 Step 18.441 4 .001Block 18.441 4 .001Model 18.441 4 .001分析:上表显示了Logistic分析第一步时回归方程显著性检验的总体情况,各数据项的含义依次为似然比卡方的观测值,自由度和概率p值。
可以看到,在本步所选变量均进入方程(Method=Enter)。
与前一步相比,似然比卡方检验的观测值18.441,概率p值为0.001。
如果显著性水平a为0.05,由于概率p值小于显著性水平a,应拒绝零假设,认为所有回归系数不同时为0,解释变量的全体与Logit P之间的线性关系显著,采用该模型是合理的。
在这里分别输出了三行似然比卡方值。
其中,Step行是本步与前一步相比的似然卡方比;Block行是本块(Block)与前一块相比的似然卡方比;Model 行是本模型与前一模型相比的似然卡方比。
在本例中,由于没有设置解释变量块,且解释变量是一次性强制进入模型,所以三行结果都相同。
消费的二项Logistic分析结果(六)(强制进入策略)Model SummaryStep -2 Log likelihood Cox & Snell RSquareNagelkerke RSquare1 552.208a.042 .057a. Estimation terminated at iteration number 4 because parameter estimates changed by less than .001.分析:上表显示了当前模型拟合优度方面的指标,各数据项的含义依次为-2倍的对数似然函数值,Cox&SnellR^2。
-2倍的对数似然函数值越小则模型的拟合优度越高。
这里该值较大,所以模型的拟合优度并不理想。
从NagelkerkeR^2也可以看到其值接近零,因此拟合优度比较低。
消费的二项Logistic 分析结果(七)(强制进入策略)Classification Table aObserved Predicted是否购买 Percentage Correct不购买购买Step 1是否购买不购买 236 33 87.7 购买1313119.1 Overall Percentage61.9a. The cut value is .500分析:上表显示了当前所得模型的错判矩阵。
可以看到,脚注中的The Cut value is .500意味着:如果预测概率值大于0.5,则认为被解释变量的分类预测值为1,如果小于0.5,则认为被解释变量的分类预测值为0.;在实际没购买的269人中,模型正确识别了236人,识别错误了131人,正确率为19.1%。
模型总的预测正确率为61.9%。
与前一步相比,对未购买的预测准确度下降了,对购买的预测准确度上升了,但总体预测精度仍下降了。
因此模型预测效果并不十分理想。
消费的二项Logistic 分析结果(八)(强制进入策略)分析:上表显示了当前所得模型中各个回归系数方面的指标。
可以看出,如果显著性水平a为0.05,由于Age的Wald检验概率p值大于显著性水平a,不应拒绝零假设,认为该回归系数与0无显著差异,它与Logit P的线性关系是不显著的,不应保留在方程中。
由于方程中包含了不显著的解释变量,因此该模型是不可用的,应重新建模。
下面是对模型做进一步分析,解释变量的筛选采用基于极大似然估计的逐步筛选策略(Forward:LR),分析的具体操作以及结果如下:(二)基本操作:(1)选择菜单Analyz e-Regression-Binary Logistic;(2)选择是否购买作为被解释变量到Dependent框中,选其余各变量为解释变量到Covariates框中,采用Forward:LR方法,在Option框中对模型做近一步分析,结果如下:消费的二项Logistic分析结果(一)(逐步筛选策略)Block 1: Method = Forward Stepwise (Likelihood Ratio)Omnibus Tests of Model CoefficientsChi-square df Sig.Step 1 Step 10.543 2 .005 Block 10.543 2 .005Model 10.543 2 .005 Step 2 Step 5.917 1 .015 Block 16.459 3 .001Model 16.459 3 .001消费的二项Logistic分析结果(二)(逐步筛选策略)Model if Term RemovedVariable Model LogLikelihoodChange in -2 LogLikelihood dfSig. of theChangeStep 1 income -285.325 10.543 2 .005Step 2 gender -280.053 5.917 1 .015income -282.976 11.761 2 .003分析:上面第一个表显示了变量逐步筛选过程中对数似然比卡方检验的结果,用于回归方程的显著性检验。
这里略去了第零步分析的结果。
结果上面的两个表共同分析。
在Step1中,模型中包含常数项和INCOME。
如果此时剔除INCOME将使-2LL减少10.543,即10.543是INCOME进入模型引起的,-285.325即为零模型的对数似然比;在Step2中,模型中包含常数项,INCOME,GENDER。
此时剔除GENDER,即-2LL将减少5.917,即5.917是在Step1基础上GENDER所引起的,-280.053即为Step1模型的对数似然比,此时-2*285.325+2*280.053=10.543,即INCOME引起的。
其他同理。
可以看到,如果显著性水平a为0.05,由于各步的概率p值均小于显著性水平a,因此此时模型中的解释变量全体与Logit P的线性关系是显著,模型合理。
消费的二项Logistic分析结果(三)(逐步筛选策略)分析:上表显示了解释变量筛选的过程和各解释变量的回归系数检验结果。
可以看到,最终的模型(第二步)中包含了性别和收入变量,各自回归系数显著性检验的Wald观测值对应的概率p值都小于显著性水平a,因此均拒绝零假设,意味它们与Logit P的线性关系是显著,应保留在方程中。
表中的第七,第八列分别是发生比的95%的置信区间。
最终年龄变量没有引入方程,因为如果引入则相应的Score检验的概率p值大于显著性水平a,不应拒绝零假设,它与Logit P的线性关系不显著,不应进入方程。