腾讯新闻采集软件
网络舆情报告表

网络舆情报告表1. 引言网络舆情,指的是通过互联网传播和交流的信息与观点。
在现代社会中,网络舆情具有极高的价值和影响力。
通过对网络舆情进行分析和监测,可以了解社会热点、民意倾向以及产品反馈等信息,为决策提供参考依据。
本文将从数据收集、分析和报告三个方面,介绍网络舆情报告表的编写方法。
2. 数据收集2.1 监测渠道网络舆情监测可通过多种途径进行,包括社交媒体、新闻网站、论坛等。
根据监测目标的不同选择相应的渠道进行数据收集。
常见的监测渠道包括但不限于: -微博 - 微信公众号 - Twitter - Facebook - 新浪新闻 - 腾讯新闻 - 百度贴吧2.2 数据抓取针对每个监测渠道,需要使用相应的工具或API实现数据的抓取。
常见的数据抓取工具有: - 爬虫:使用Python语言编写的网络数据采集工具,如Scrapy、Requests等。
- 监测工具:专门用于监测网络舆情的第三方软件,如Hootsuite、Brandwatch等。
2.3 数据存储抓取到的数据需要进行适当的存储和整理。
一般采用数据库存储数据,常见的数据库包括: - MySQL - MongoDB - SQLite除了数据库存储,还可以选择将数据导出为CSV、JSON等格式进行备份和后续分析。
3. 数据分析3.1 文本分析网络舆情的主要内容为文本,因此文本分析是网络舆情分析的重要环节。
文本分析的主要方法包括: - 分词:将长篇文本切分成一个个独立的词语。
- 情感分析:对文本进行情感倾向判断,判断其是正向、负向还是中性。
- 关键词提取:提取文本中的关键词,以了解舆情的核心内容。
3.2 数据可视化为了更直观地展示网络舆情的数据,可以利用数据可视化工具将分析结果以图表的方式展示出来。
常用的数据可视化工具包括:- Matplotlib:Python的绘图库,支持各种类型的图表绘制。
- Tableau:一款专业的数据可视化工具,支持多种图表类型和交互式操作。
ROST CM 使用手册

2) 内容挖掘标签页 ............................................................................................................. 11 打开按钮.................................................................................................................. 11
基于词群的频度统计.............................................................................................. 16
2
提取高频词至辅助文档.......................................................................................... 17 4) 导入菜单 ......................................................................................................................... 17
三、 ROST Content Mining(内容挖掘) ....................................................................... 10 1) 批量处理 ......................................................................................................................... 10
信息获取渠道与技巧

二、数据挖掘方法—学习渠道
寻本溯源,洞悉万象
2020/3/29
二、数据挖掘方法-数据爬虫工具举例
数据爬虫工具
Arachnid
Spiderman ThinkUp
网络矿工
应用
优点
Arachnid是一个基于Java的web spider框架.它包含一个简单 的HTML剖析器能够分析包含HTML内容的输入流.通过实现 Arachnid的子类就能够开发一个简单的Web spiders并能够在 Web站上的每个页面被解析之后增加几行代码调用。 Arachnid的下载包中包含两个spider应用程序例子用于演示如 何使用该框架。
▪其他的网站
寻本溯源,洞悉万象
2020/3/29
一、信息获取渠道:市场信息获取
▪ 1.国内咨询机构网站数据报告 ▪ 2.国内互联网公司数据报告网站 ▪ 3.国外咨询机构网站数据报告 ▪ 4.各大公司不定期发布的报告 ▪ 5.企业信息报告 ▪ 6.政府统计类网站/数据库 ▪ 7.法律规章
寻本溯源,洞悉万象
2020(1)
1、Flurry-国外app行业报告 2、App Annie Blog-app指数报告 3、https:// 4、BI Intelligence-business insider的报告 5、Today's Articles on Digital Marketing and Media-emarker的报告 6、http://侧重于手游行业报告 7、Gartner Press Release Archives-gartner侧重于硬件的出货量,包括智能机和PC等 8、IDC - Search Results-IDC的硬件出货量全球报告 9、Yozzo Telecom News 10、J.P. Morgan Home-摩根投行报告 11、德勤中国 | 审计, 企业管理咨询, 财务咨询, 风险管理, 税务服务及行业洞察 12、Precisely Everywhere-comscore的互联网行业报告 13、Ericsson - A world of communication(Global移动行业报告)
天阗入侵检测与管理系统V6070用户安装手册

信息更新
本手册依据现有信息制作,其内容如有更改,本公司将不另行通知。 出版时间 本文档由北京启明星辰信息安全技术有限公司 2012 年 06 月出版。 北京启明星辰信息安全技术有限公司保留对本手册及本声明的最终解释权和修改权。
图 1-1 安装步骤 后面的章节,我们将按照这 6 个安装步骤对整个安装过程作详细介绍。
2.安装准备 2.1 天阗 V6.0 控制中心安装准备
为了更好的运行天阗入侵检测与管理系统 V6.0,我们建议您采用下面的配置作为起点。系统实际 运行的性能与网络环境和策略配置都有关系,配置越高性能会越好。如果您打算将多个模块安装在一 台计算机上,则需要更快的处理器、更多的内存和更大的硬盘空间。由于系统运行过程中需要不断的 读/写数据库,为了提高系统的处理速度和性能,我们建议您准备专门的数据库服务器安装数据库和专 门的一台服务器安装控制中心。
2.1.1 硬件需求
【控制中心:安装在一台 PC 之上的硬件要求】 硬件形式 PC
1
天阗 V6.0.7.0 用户安装手册
操作系统 处理器
内存 硬盘 网卡 其他设备
Windows 2003(支持 32 位与 64 位)/ Windows Server Standard 2008(支持 32 位与 64 位) 最低配置:Pentium(R)Dual-Core CPUE5200 @ 2.5GHz 2.50GHz 推荐配置:四核 CPU 最低配置:2G 内存,推荐配置:4G 内存 硬盘 80G 以上(存放操作系统) 至少一个,无特殊要求 N/A
目
录
1.简述 ..................................
腾讯新闻标题与内容采集软件使用教程
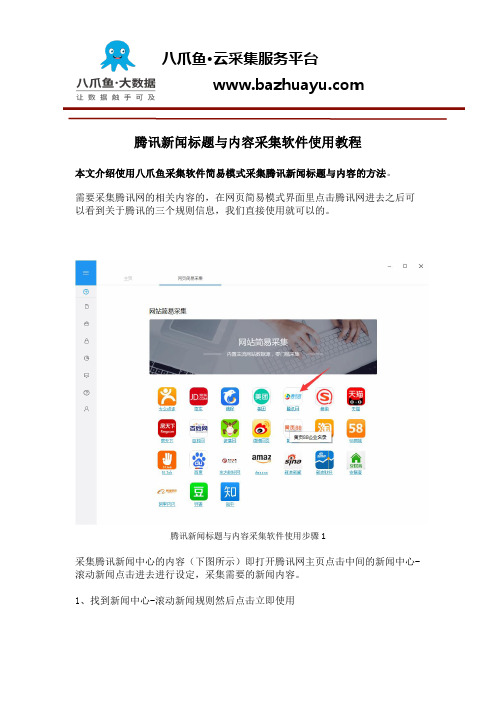
腾讯新闻标题与内容采集软件使用教程本文介绍使用八爪鱼采集软件简易模式采集腾讯新闻标题与内容的方法。
需要采集腾讯网的相关内容的,在网页简易模式界面里点击腾讯网进去之后可以看到关于腾讯的三个规则信息,我们直接使用就可以的。
腾讯新闻标题与内容采集软件使用步骤1采集腾讯新闻中心的内容(下图所示)即打开腾讯网主页点击中间的新闻中心-滚动新闻点击进去进行设定,采集需要的新闻内容。
1、找到新闻中心-滚动新闻规则然后点击立即使用腾讯新闻标题与内容采集软件使用步骤22、下图显示的即为简易模式里面的新闻中心-滚动新闻规则①查看详情:点开可以看到示例网址②任务名:自定义任务名,默认为新闻中心-滚动新闻③任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组④翻页次数:设置要采集的页数⑤采集数目:设置你每页要采集的新闻数⑥示例数据:这个规则采集的所有字段信息腾讯新闻标题与内容采集软件使用步骤33、规则制作示例任务名:自定义任务名,也可以不设置按照默认的就行任务组:自定义任务组,也可以不设置按照默认的就行翻页次数:2采集数目:20设置好之后点击保存,保存之后会出现开始采集的按钮保存之后会出现开始采集的按钮腾讯新闻标题与内容采集软件使用步骤44、选择开始采集之后系统将会弹出运行任务的界面可以选择启动本地采集(本地执行采集流程)或者启动云采集(由云服务器执行采集流程),这里以启动本地采集为例,我们选择启动本地采集按钮腾讯新闻标题与内容采集软件使用步骤55、选择本地采集按钮之后,系统将会在本地执行这个采集流程来采集数据,下图为本地采集的效果:腾讯新闻标题与内容采集软件使用步骤66、采集完毕之后选择导出数据按钮即可,这里以导出excel2007为例,选择这个选项之后点击确定腾讯新闻标题与内容采集软件使用步骤77、然后选择文件存放在电脑上的路径,路径选择好之后选择保存腾讯新闻标题与内容采集软件使用步骤88、这样数据就被完整的导出到自己的电脑上来了哦,点击打开excel表就可以查看了。
各大众包标注采集平台-学习笔记

一、百度数据众包平台人工采集人工采集:适用于各种复杂场景数据采集的需求,海量众包用户定制化线下采集,涵盖图片、文本、语音、视频等全维度多媒体数据全维度多媒体数据无缝采集:万名专职采集员应对各种需求、多种类型和方案完美覆盖采集需求、覆盖全国300+城市针对地理位置定制采集、多重审核机制保障数据质量。
文本数据采集基于众包的方式提供文本数据采集服务,可包括广告、杂志、报纸、教材等多种形式的文本数据。
采集灵活性高、速度快,能够根据需求制定文本采集方案。
(支持实体图片、人物图片、场景图片、基于地理位置的文本采集,并且可按照需求进行特定场景下的采集,采集的图片针对性强、质量高,不与其他用户共享。
采集的应用实例包括:特定人群人脸文本采集、药盒图片采集、医疗单文本采集、街道全景采集、名片采集、商铺多角度照片采集等)图片数据采集根据实际需求提供特定场景的图片数据采集服务,包括实体图片、任务图片、场景图片、基于地理位置的图片采集,采集的图片针对性强、质量高,不与其他用户共享。
语音视屏数据采集提供各种特定条件下的语音视频采集服务,采集目标人群分散广、覆盖全,采集数据高度真实有效。
能够多人并发采集,采集效率高。
O2O|LBS数据采集根据O2O行业的特性,提供基于LBS的O2O数据采集服务,数据采集专员分布覆盖全国300+城市,可快速有效的采集各类O2O数据。
数据标注适用于大规模的图像、视频、语音、文本以及其他特殊数据的数据清洗、评估、提取以及特殊信息标注,专业的标注团队高效、稳定提供数据标注服务数据众标服务专业的标注采集平台(支持定制化开发)数量庞大的高质量标注采集用户专业项目人员策划方案、实时跟进多重审核机制保障数据高质量数据分类/清洗评价内容分类、图片类型分类、图片标签分类、垃圾流量清洗、有效语音筛选数据校验评估文本语法校验、图片相关性评估、搜索相关性评估、情感倾向性评估、质量优劣评估数据内容提取图片特定内容提取、图片文字提取、文本关键词提取、语音转写文本、网页摘要撰写数据抓取适用于对互联网数据有需求的应用场景,通过自动化数据采集终端完成海量互联网数据的自动化采集互联网数据抓取强大的采集能力,超大并发量快速采集、多种应用领域文本,图片及网页数据、300+城市,30+运营商多地域数据抓取、线上监控和报警服务稳定高质量互联网网页抓取通过众包模式,提供互联网网站的定向采集,可更快、更准、更全量的采集需要的互联网网页数据定向站点数据订阅依托与众包模式的采集和抓取服务,积累了一系列常用、知名站点的数据获取和处理方案,可直接提供定向站点的数据订阅服务。
delphi信息采集程序可以推广为网络爬虫程序
下述为新闻采集程序,在理解了新闻采集程序的基础之上就可以做出网络爬虫程序了.今天,我们讨论的是网站新闻采集程序的制作。
所谓新闻采集程序,就是自动抓取网上信息,并保存到自己网站数据库的一种程序。
现在很多大型网站都有自己的新闻采集系统,其中许多采集系统价值不菲。
通过这篇文章,我希望大家都能自己做一个采集程序,来维护自己的网站。
为了便于理解,先阐述一下本文的新闻采集程序的一些基本信息。
这里的新闻系统,是用delphi实现,并将采集到的数据保存到本地access数据库。
所以,这将是一个基与桌面的采集程序,而不是类似“动易采集”的基于浏览器。
个人认为,基于桌面的采集系统,更容易实现强大的功能,有更高的稳定和安全性能。
而经过扩展,大家完全可以把这个例子做成可以访问远程数据库的大型采集系统。
在说如何制作采集程序之前,我们先来定义一个本地access数据库,用来存取采集到的信息。
这个数据库只有一个表,表名”T_Article”,该表有ArticleID、ClassID、Title、Keyword、CopyFrom、Content六个字段,分别代表新闻的编号、类别编号、标题、关键字、出处、内容。
首先,所谓采集,第一步当然是要能抓取信息,并且是能按照用户的要求,从网上抓取相关信息。
这里假设我们要抓取/article/69/69929.shtm 的文章,加到自己网站的“delphi技术”这么一个栏目。
首先要做的,是读取/article/69/69929.shtm 上的文章列表,然后通过列表索引,逐篇将文章正文内容读到我们的网站数据库。
接下来将是关键,如何采集/article/69/69929.shtm 上的文章列表。
这里分为两步,一、利用delphi网络功能,读取69929.shtm的HTML源文件。
二、通过分析69929.shtm的源文件,截取其中列表部分。
第一步的实现,可以用delphi的indy控件族的idHTTP控件,该控件在indy Clients面板,该控件的具体使用,将在后面讲解,现在我们只要知道,给定一个URL地址,就能通过indy控件返回该URL的网页源代码。
数据处理中的数据采集和数据清洗工具推荐(四)
数据处理是现如今信息时代的重要工作之一,数据的采集和清洗是数据处理中不可或缺的环节。
在海量数据的背后,如何高效、准确地采集并清洗数据,成为了数据处理专业人士和数据科学家所面临的重要问题。
本文将为大家推荐几款在数据采集和数据清洗方面出色的工具。
一、数据采集工具推荐1. Selenium:Selenium是一个自动化浏览器测试工具,可以模拟用户在浏览器上的各种操作,如点击、输入、下拉等。
这使得Selenium成为一款强大的数据采集工具。
通过编写脚本,可以自动定位网页元素,提取需要的数据。
Selenium支持多种编程语言,如Python、Java等,适用于各种网页采集需求。
2. Scrapy:Scrapy是一个Python编写的开源网络爬虫框架,它提供了强大的数据采集功能。
Scrapy可以根据用户定义的规则,自动抓取网页并提取数据。
同时,Scrapy还支持分布式爬取、异步IO等高级功能,使得大规模数据采集成为可能。
3. BeautifulSoup:BeautifulSoup是一个Python库,用于解析HTML和XML文档。
它提供了简单灵活的API,可以方便地从网页中提取数据。
BeautifulSoup可以像操作Python对象一样操作网页元素,极大地简化了数据采集的过程。
4. Apache Nutch:Apache Nutch是一款强大的开源网络爬虫工具。
Nutch支持分布式爬取、页面去重、自动分类等功能,能够处理大规模的数据采集任务。
同时,Nutch还提供了丰富的插件机制,可以灵活扩展功能,满足不同的需求。
二、数据清洗工具推荐1. OpenRefine:OpenRefine(旧名Google Refine)是一款专业的数据清洗工具。
它支持导入多种数据格式,如CSV、Excel等,可以自动检测数据中的问题,并提供各种操作,如拆分、合并、过滤等,帮助用户快速清洗数据。
2. Trifacta Wrangler:Trifacta Wrangler是一款集数据清洗、转换和可视化等功能于一体的工具。
人工智能生成内容(AIGC)的应用场景
人工智能生成内容的应用场景各行业对于数字内容的需求呈现井喷态势,数字世界内容消耗与供给的缺口亟待弥合。
AIGC以其真实性、多样性、可控性、组合性的特征,有望帮助企业提高内容生产的效率,以及为其提供更加丰富多元、动态且可交互的内容,或将率先在传媒、电商、影视、娱乐等数字化程度高、内容需求丰富的行业取得重大创新发展。
AIGC+传媒:人机协同生产,推动媒体融合近年来,随着全球信息化水平的加速提升,人工智能与传媒业的融合发展不断升级。
AIGC 作为当前新型的内容生产方式,为媒体的内容生产全面赋能。
写稿机器人、采访助手、视频字幕生成、语音播报、视频锦集、人工智能合成主播等相关应用不断涌现,并渗透到采集、编辑、传播等各个环节,深刻地改变了媒体的内容生产模式,成为推动媒体融合发展的重要力量。
在采编环节,一是实现采访录音语音转写,提升传媒工作者的工作体验。
借助语音识别技术将录音语音转写成文字,有效压缩稿件生产过程中录音整理方面的重复工作,进一步保障了新闻的时效性。
2022年冬奥会期间,科大讯飞的智能录音笔通过跨语种的语音转写助力记者2分钟快速出稿。
二是实现智能新闻写作,提升新闻资讯的时效。
基于算法自动编写新闻,将部分劳动性的采编工作自动化,帮助媒体更快、更准、更智能化地生产内容;美联社使用的智能写稿平台Wordsmith 可以每秒写2000篇报道;第一财经“DT稿王”一分钟可写出1680字。
三是实现智能视频剪辑,提升视频内容的价值。
通过使用视频字幕生成、视频锦集、视频拆条、视频超分等视频智能化剪辑工具,高效节省人力时间成本,最大化版权内容价值。
2020年全国两会期间,人民日报社利用“智能云剪辑师”快速生成视频,并能够实现自动匹配字幕、人物实时追踪、画面抖动修复、横屏速转竖屏等技术操作,以适应多平台分发要求。
2022年冬奥会期间,央视视频通过使用AI智能内容生产剪辑系统,高效生产与发布冬奥冰雪项目的视频集锦内容,为深度开发体育媒体版权内容价值,创造了更多的可能性。
十大新闻app排行榜新闻app哪个好
十大新闻a p p排行榜新闻a p p哪个好集团标准化办公室:[VV986T-J682P28-JP266L8-68PNN]2018十大新闻a p p排行榜:新闻a p p哪个好?目前我们获取资讯新闻的方法绝大多数是在网上,最有名的应该就是今日头条了,除此之外,新闻app哪个好呢?下面排行榜123带来2018十大新闻app排行榜。
1.今日头条下载量:1.3亿软件介绍::今日头条是一款资讯新闻类的应用,头条最知名的就是其算法,能为你推荐你关注和喜欢的内容,里边包含热点新闻,生活资讯等多种内容。
而且头条还开通了头条号,可以让有想去的人,自己写原创文章。
推荐理由:我每天花时间最多的就是看头条,各个看点挺全的,该有的都有,非常好用。
2.腾讯新闻下载量:7190.8万软件介绍:腾讯新闻是一款腾讯旗下的一款资讯类app,能够及时查看到时下的新闻热点,软件新闻分为不同的频道,腾讯的新闻排版和很多细节操作都非常不错。
推荐理由:腾讯新闻界面设置的比较简洁,没有太多广告,用起来非常舒服,还有很多视频新闻,非常搞笑。
3.网易新闻下载量:2596.7万软件介绍:网易新闻是网易名下的一款新闻阅读app,内容包括很多,如新闻资讯和国际新闻资讯等最常见的,不过有一点是网易新闻依然保持的比较高质量的新闻内容,网易新闻的评论区也非常有看点。
推荐理由:网易新闻实用性很强,基金数据比较全面的,更新快速,用过这么多还是这款最好了。
4.凤凰新闻下载量:2485.8万软件介绍:凤凰新闻是一款手机资讯阅读的应用App,虽说最主要的是凤凰台的报道,但是其他的报道也是很多,而且凤凰台自身的新闻质量也不错。
凤凰新闻还有直播功能,最新的赛事直播都可以看。
推荐理由:信息及时,新闻实时性很好,活动类型又多,功能非常强大,是一个非常不错的新闻平台。
5.新浪新闻下载量:1253.4万软件介绍:新浪新闻是一款资讯类app,内柔包含非常多,如国内国外的资讯报道、体育、金融和娱乐新闻等等,你感兴趣的这里几乎都有,还可以直接看NBA球赛,非常方便。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
腾讯新闻采集软件
本文介绍使用八爪鱼采集软件采集腾讯新闻的方法,现在为了提高观众的阅读体验,门户网站一般新闻标题点进去之后都是图文模式的,所以采集起来相对全文字模式难一点点。
但学会之后用户可以熟练使用我们的各种步骤来采集你所需要的各类网站数据,成为采集达人。
采集网站:
/
本文就以腾讯新闻主页下的某一个分类--文化,来具体说明怎么去采集类似的图文新闻或文章。
采集的内容包括:点击标题后新闻的正文(含图文)。
使用功能点:
●列表循环
●Ajax点击
分支判断
步骤1:创建腾讯新闻采集任务
1)进入主界面,选择“自定义采集”
2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
步骤2:创建循环加载更多步骤
1)打开网页之后,进入主页,然后选择类别--文化
2)打开右上角的流程按钮,可以显示你所创建好的步骤,进入到新闻--
文化页
面后,我们往下拖动页面到新闻列表的底部,可以看到一个按钮,点击查看更多
3)这时,我们需要多次点击之后才能把所有新闻标题都显示出来,这样才不会漏采数据,所以我们在页面上点击该位置,然后提示栏那选择循环点击单个链接,循环点击就设置好了
注意,由于点击该按钮,网页
url
地址栏那边没有转动,url 也没有变化,所以
需要设置一下ajax ,这样,循环点击加载更多就创建好了。
步骤3:创建循环列表点击
1)首先我们得了解到,循环列表点击是要等页面上所有的新闻标题都加载出来了才进行操作的,所以循环列表应该是放在循环点击加载更多的下面,而不是包含的关系,所以,我们就按照新手教程3里的操作那样,依次点击第一,第二个标题,这是可以看到所有的新闻标题都包含进来了,我们选择循环点击每个元素
2)就这样,
循环列表点击就创建好了,但是八爪鱼自动生成的位置有点不一致,我们刚才讲了,这个应该放在上一个循环点击加载更多的下面,所以得把循环列表给拖出来,放到下面,规则才是正确的
步骤
4:利用分支判断来采集文章
1)进入新闻详情页后,可以看到文中有一个点击查看全文的按钮,需要点击后才能显示全文,所以我们先设置一个点击元素
2)另外还是要注意一下,这个点击也是
ajax 加载的,所以我们需要在高级选项里勾选一下ajax ,3秒就够了
3)全文显示出来后就需要对文章进行采集了,此时我们可以看到文中是图片跟文本段落并存的,而且图片和文本段落位置都是随机的,这时候如果按照以前的方法,对文中的段落进行循环提取,图片url是没办法采集下来的,而且采集也很容易出错,所以这种办法是行不通的。
所以我们只能通过更复杂一点的步骤来采集所有我们想要的数据,也就是这个教程的重点(难点)--分支判断+xpath!!!
4)首先,我们对图片和文本段落设置好一个循环列表
5)然后,我们从流程的左侧拖一个分支判断进来,放在循环列表的下面
6)注意!因为提取数据的步骤是判断后再执行的,所以我们要把提取数据这个步骤复制一下,放入到两个分支里面(也可以拖入一个提取数据的步骤放进去),分支判断的知识点里有讲到过,左右分支里提取数据的字段名,
字段数量必须是一致的,我们这边两个提取数据的字段名都设置成concent ,设置第二个时它会提示你,选择是即可。
7)这时,我们就要设置好分支判断的条件了,由于是图文都采集,一般默认都是左分支判断图片并采集图片的url ,右分支不做判断,直接采集文本。
判断图片的话就必须得判断元素,需要手写xpath ,由于图片都是img
元素,所以这里的xpath 相对来说比较简单,直接写一个.//img 即可,注意是勾选当前循环项包含元素
8)然后再对左分支里采集图片的提取数据做一个提取字段的设置,首先循环列表里选到一个图片项,然后依次手动执行到分支里的图区数据的步骤,再点击文章中对应图片的位置,设置一个提取图片的字段即可。
9)左分支图片链接和右分支文本信息设置好后,就基本大功告成了。
步骤4:设置追加--字段合并
1)因为我们要把整个正文采集到一个数据里,而且段落格式都应该跟原文是一致的,我们我们得对数据字段进行一个追加。
首先点到提取数据下面的自定义数据字段
2)选择点击第四个--自定义数据合并方式
3)然后再选择第二个--同一字段多次提取合并到一行,点击确定保存
)再对另一个提取数据进行相应的设置,就这样,规则就大功告成了
4
1)我们以本地采集为例,保存任务,然后再点击采集-本地采集
2)这时,可以查看到数据,每一个新闻正文都采集在一个数据里,并且正文格式都保留了下来,就这样,图文模式的文章我们就成功的采集下来,以后如果你有碰到这样的页面,就可以按照这个方法,轻松的采集下来。
相关采集教程:
百度新闻采集:
/tutorialdetail-1/bdnewscj.html
网易新闻数据采集:
/tutorialdetail-1/wycj_7.html
新浪新闻采集:
/tutorialdetail-1/xlnewscj.html
八爪鱼·云采集网络爬虫软件
爆文采集:
/tutorialdetail-1/baowencj.html
微信公众号文章采集:
/blog/224-2.html
自媒体文章采集:
/tutorialdetail-1/wyhcj.html
八爪鱼——90万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网就能采集。
完全可视化流程,点击鼠标完成操作,2分钟即可快速入门。
2、功能强大,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。
3、云采集,关机也可以。
配置好采集任务后可关机,任务可在云端执行。
庞大云采集集群24*7不间断运行,不用担心IP被封,网络中断。
4、功能免费+增值服务,可按需选择。
免费版具备所有功能,能够满足用户的基本采集需求。
同时设置了一些增值服务(如私有云),满足高端付费企业用户的需要。