NCBI在线BLAST使用方法与结果详解
Blast分析报告

Blast分析报告引言Blast(Basic Local Alignment Search Tool)是一种常用的生物信息学工具,用于比对和比较生物序列。
本报告旨在分析和解释Blast结果,帮助读者理解序列的相似性和演化关系。
方法为了进行Blast分析,首先需要准备两个序列:查询序列和参考序列。
查询序列是我们要研究的序列,而参考序列是已知的序列。
Blast会将查询序列与参考序列进行比对,并计算序列之间的相似性。
在本次分析中,我们使用了NCBI(National Center for Biotechnology Information)提供的在线Blast工具。
具体的分析步骤如下:1.登录NCBI网站并进入Blast页面。
2.将查询序列输入到指定的文本框中。
3.选择参考序列数据库。
4.点击“运行Blast”按钮,等待分析结果。
结果经过Blast分析,我们获得了以下结果:1.序列相似性分析:Blast会将查询序列与参考序列进行比对,并计算序列之间的相似性。
结果以百分比的形式表示相似度。
较高的相似度表明序列之间有较高的共同点。
2.演化关系分析:Blast还可以帮助我们了解序列之间的演化关系。
通过比较序列中的保守区域和变异区域,我们可以推断序列的起源和演化路径。
讨论根据Blast分析结果,我们可以得出以下结论:1.查询序列与参考序列的相似性较高。
根据相似性百分比可以判断两个序列之间的关系,例如亲缘关系或功能相似性。
2.查询序列可能与参考序列在演化上存在一定的共同点。
通过比较序列中的保守区域和变异区域,我们可以推断序列的起源和演化路径。
3.查询序列与参考序列之间的差异可能与物种间的差异相关。
通过进一步的分析,可以探究这些差异对生物体功能的影响。
结论本次Blast分析报告旨在帮助读者理解序列的相似性和演化关系。
通过Blast工具,我们可以快速准确地比对和比较生物序列。
通过对结果的分析,我们可以推断序列的起源和演化路径,并进一步探究序列间的差异对生物体功能的影响。
在线blast的用法总结
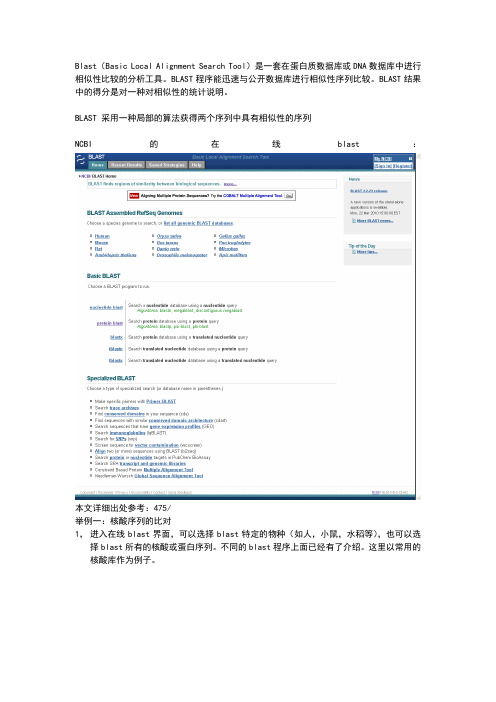
Blast(Basic Local Alignment Search Tool)是一套在蛋白质数据库或DNA数据库中进行相似性比较的分析工具。
BLAST程序能迅速与公开数据库进行相似性序列比较。
BLAST结果中的得分是对一种对相似性的统计说明。
BLAST 采用一种局部的算法获得两个序列中具有相似性的序列NCBI的在线blast:本文详细出处参考:475/举例一:核酸序列的比对1,进入在线blast界面,可以选择blast特定的物种(如人,小鼠,水稻等),也可以选择blast所有的核酸或蛋白序列。
不同的blast程序上面已经有了介绍。
这里以常用的核酸库作为例子。
(补充介绍下:1、BLASTN【 nucleotide blast】是核酸序列到核酸库中的一种查询。
库中存在的每条已知序列都将同所查序列作一对一地核酸序列比对。
2、BLASTP【protein blast】是蛋白序列到蛋白库中的一种查询。
库中存在的每条已知序列将逐一地同每条所查序列作一对一的序列比对。
3、BLASTX是核酸序列到蛋白库中的一种查询。
先将核酸序列翻译成蛋白序列(一条核酸序列会被翻译成可能的六条蛋白),再对每一条作一对一的蛋白序列比对。
4、TBLASTN是蛋白序列到核酸库中的一种查询。
与BLASTX相反,它是将库中的核酸序列翻译成蛋白序列,再同所查序列作蛋白与蛋白的比对。
5、TBLASTX是核酸序列到核酸库中的一种查询。
此种查询将库中的核酸序列和所查的核酸序列都翻译成蛋白(每条核酸序列会产生6条可能的蛋白序列),这样每次比对会产生36种比对阵列。
)2,粘贴fasta格式的序列。
选择一个要比对的数据库。
关于数据库的说明请看NCBI在线blast数据库的简要说明。
一般的话参数默认。
3,blast参数的设置。
注意显示的最大的结果数跟E值,E值是比较重要的。
筛选的标准。
最后会说明一下。
4,注意一下你输入的序列长度。
注意一下比对的数据库的说明。
NCBI在线BLAST使用方法与结果详解

NCBI正在线BLAST使用要领与截止详解之阳早格格创做BLAST(Basic Local Alignment Search Tool)是一套正在蛋黑量数据库或者DNA数据库中举止相似性比较的分解工具.BLAST步调能赶快与公启数据库举止相似性序列比较.BLAST截止中的得分是对于一种对于相似性的统计证明.BLAST 采与一种局部的算法赢得二个序列中具备相似性的序列.Blast中时常使用的步调介绍:1、BLASTP是蛋黑序列到蛋黑库中的一种查询.库中存留的每条已知序列将逐一天共每条所查序列做一对于一的序列比对于.2、BLASTX是核酸序列到蛋黑库中的一种查询.先将核酸序列翻译成蛋黑序列(一条核酸序列会被翻译成大概的六条蛋黑),再对于每一条做一对于一的蛋黑序列比对于.3、BLASTN是核酸序列到核酸库中的一种查询.库中存留的每条已知序列皆将共所查序列做一对于一天核酸序列比对于.4、TBLASTN是蛋黑序列到核酸库中的一种查询.与BLASTX差异,它是将库中的核酸序列翻译成蛋黑序列,再共所查序列做蛋黑与蛋黑的比对于.5、TBLASTX是核酸序列到核酸库中的一种查询.此种查询将库中的核酸序列战所查的核酸序列皆翻译成蛋黑(每条核酸序列会爆收6条大概的蛋黑序列),那样屡屡比对于会爆收36种比对于阵列.底下是简直支配要领1,加进正在线BLAST界里,不妨采用blast特定的物种(如人,小鼠,火稻等),也不妨采用blast所有的核酸或者蛋黑序列.分歧的blast步调上头已经有了介绍.那里以时常使用的核酸库动做例子.2,粘揭fasta要领的序列.采用一个要比对于的数据库.闭于数据库的证明请瞅NCBI正在线blast数据库的简要证明.普遍的话参数默认.3,blast参数的树立.注意隐现的最大的截止数跟E值,E值是比较要害的.筛选的尺度.末尾会证明一下.4,注意一下您输进的序列少度.注意一下比对于的数据库的证明.5,blast截止的图形隐现.出啥佳道的.6,blast截止的形貌天区.注意分值与E值.分值越大越靠前了,E值越小也是那样.7,blast截止的仔细比对于截止.注意比对于到的序列少度.评介一个blast截止的尺度主要有三项,E值(Expect),普遍性(Identities),缺得或者拔出(Gaps).加上少度的话,便有四个尺度了.如图中隐现,比对于到的序列少度为1405,瞅Identities那一值,才匹配到1344bp,而输进的序列少度也是为1344bp(瞅上头的图),便证明比对于到的序列要少一面.由Qurey(起初1)战Sbjct(起初35)的起初位子可知,5'端是是多了一段的.偶尔也要注意3'端的.附:E值(Expect):表示随机匹配的大概性,E值越大,随机匹配的大概性也越大.E值交近整或者为整时,具原上便是实足匹配了.普遍性(Identities):或者相似性.匹配上的碱基数占总序列少的百分数.缺得或者拔出(Gaps):拔出或者缺得.用"—"去表示.。
在线blast的用法总结
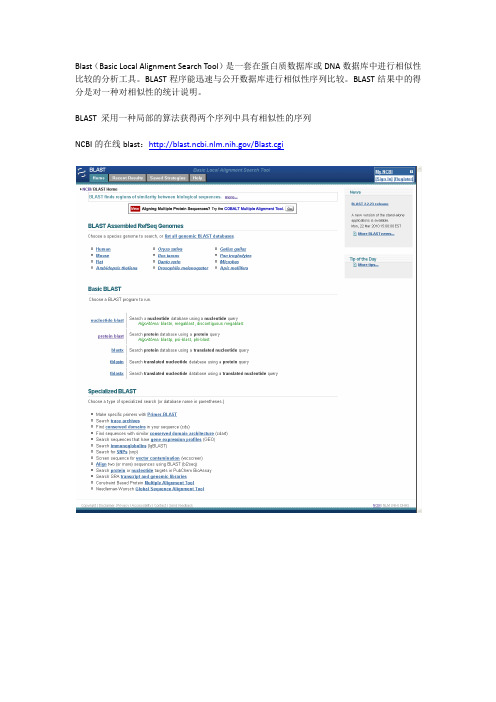
Blast(Basic Local Alignment Search Tool)是一套在蛋白质数据库或DNA数据库中进行相似性比较的分析工具。
BLAST程序能迅速与公开数据库进行相似性序列比较。
BLAST结果中的得分是对一种对相似性的统计说明。
BLAST 采用一种局部的算法获得两个序列中具有相似性的序列NCBI的在线blast:/Blast.cgi本文详细出处参考:/475/举例一:核酸序列的比对1,进入在线blast界面,可以选择blast特定的物种(如人,小鼠,水稻等),也可以选择blast所有的核酸或蛋白序列。
不同的blast程序上面已经有了介绍。
这里以常用的核酸库作为例子。
(补充介绍下:1、BLASTN【nucleotide blast】是核酸序列到核酸库中的一种查询。
库中存在的每条已知序列都将同所查序列作一对一地核酸序列比对。
2、BLASTP【protein blast】是蛋白序列到蛋白库中的一种查询。
库中存在的每条已知序列将逐一地同每条所查序列作一对一的序列比对。
3、BLASTX是核酸序列到蛋白库中的一种查询。
先将核酸序列翻译成蛋白序列(一条核酸序列会被翻译成可能的六条蛋白),再对每一条作一对一的蛋白序列比对。
4、TBLASTN是蛋白序列到核酸库中的一种查询。
与BLASTX相反,它是将库中的核酸序列翻译成蛋白序列,再同所查序列作蛋白与蛋白的比对。
5、TBLASTX是核酸序列到核酸库中的一种查询。
此种查询将库中的核酸序列和所查的核酸序列都翻译成蛋白(每条核酸序列会产生6条可能的蛋白序列),这样每次比对会产生36种比对阵列。
)2,粘贴fasta格式的序列。
选择一个要比对的数据库。
关于数据库的说明请看NCBI在线blast 数据库的简要说明。
一般的话参数默认。
3,blast参数的设置。
注意显示的最大的结果数跟E值,E值是比较重要的。
筛选的标准。
最后会说明一下。
4,注意一下你输入的序列长度。
BLAST使用方法

BLAST使用方法一、BLAST的安装和准备工作2.获取待比对的序列文件,可以是FASTA格式的DNA或蛋白质序列。
二、BLAST的常用参数和选项1. Program:指定使用哪种BLAST程序(如BLASTn、BLASTp等)。
2. Database:指定使用哪个数据库进行比对。
3. Query:指定待比对的序列文件。
4. E-value:期望值。
一种描述比对结果误差率的指标,值越小表示结果越可信。
通常情况下,E-value小于0.01被认为是显著结果。
5. Word size:BLAST在比对时使用的核心词的长度。
长度越大表示查全率(sensitivity)越高,但速度会减慢。
6. Gap open:允许在比对过程中插入空位(如插入一个碱基)。
Gap open参数定义了开放一个空位的惩罚分数。
7. Gap extension:允许空位的延伸。
Gap extension参数定义了延伸一个空位的惩罚分数。
三、使用BLAST进行比对1.命令行方式:-打开命令行界面,并定位到BLAST软件的安装目录。
- 输入命令,指定BLAST程序、数据库、查询文件和其他参数。
例如:blastn -db nt -query query.fasta -out output.txt -evalue 0.01-运行命令,BLAST将开始进行比对并生成结果文件。
2.网页方式(以NCBIBLAST为例):- 打开NCBI网站的BLAST页面()。
-选择需要使用的BLAST程序(如BLASTn、BLASTp等)。
-上传待比对的序列文件,或者粘贴序列文本到输入框中。
-选择适当的数据库和其他参数。
-点击“BLAST”按钮,等待比对完成。
四、解读BLAST结果1. E-value:表示在随机比对中获得与查询序列相似度更高的结果的期望概率。
E-value越小表示比对结果越显著。
2. Bitscore:用于表示比对结果的质量。
Bitscore越高表示比对结果越可信。
如何看懂NCBIBLAST输出结果

如何看懂NCBIBLAST输出结果NCBI BLAST(Basic Local Alignment Search Tool)是一种用于比较生物序列之间的相似性的工具。
BLAST将一个查询序列与一个目标数据库中的序列进行比对,并输出比对结果。
下面将介绍如何看懂NCBI BLAST输出结果。
BLAST报告的不同部分提供了关于比对结果的详细信息。
以下是BLAST输出结果中的重要部分:1.查询信息:在输出结果的第一部分,会显示关于查询序列的信息,如查询序列的名称、长度以及描述。
这些信息可以帮助确认你是否正确提交了查询序列。
2.数据库信息:在查询信息的下方,输出结果会提供关于目标数据库的信息,包括数据库的名称、大小以及参与比对的序列数目。
这些信息可以帮助你了解比对参考的范围和样本数目。
3.参数信息:BLAST在进行比对时使用了一系列的参数,这些参数可以影响比对的灵敏度和特异性。
输出结果会显示用于比对的参数信息,包括比对算法、匹配得分、不匹配得分、开始扣分以及扩展扣分等。
这些参数提供了对比对结果的解释依据。
4.结果摘要:在参数信息的下方,会显示一个结果摘要表,提供了与查询序列最相似的多个数据库序列的信息。
这些信息包括数据库序列的名称、长度、比对得分以及比对的e值。
e值是一个表示比对结果的统计显著性的指标,越小表示比对结果越显著。
这些信息可以帮助你快速了解最相关的序列。
5.序列比对信息:在结果摘要之后,会显示每个比对的详细信息。
比对信息包括目标序列的名称和描述、比对长度、匹配得分、比对得分、e值以及比对图形。
比对图形以垂直线表示查询和目标序列之间的匹配,帮助你在比对中可视化相似区域。
6.比对统计信息:在序列比对信息之后,会显示比对的统计信息。
这些统计信息包括查询序列的覆盖率、比对序列的覆盖率以及总体比对得分。
这些信息对比对结果的解释和评估非常重要。
7.结果解释:在比对统计信息之后,会提供进一步解释和分析比对结果的信息。
NCBI在线BLAST使用方法与结果详解
N C B I在线B L A S T使用方法与结果详解BLAST Basic Local Alignment Search Tool是一套在蛋白质数据库或DNA数据库中进行相似性比较的分析工具;BLAST程序能迅速与公开数据库进行相似性序列比较;BLAST结果中的得分是对一种对相似性的统计说明;BLAST 采用一种局部的算法获得两个序列中具有相似性的序列;Blast中常用的程序介绍:1、BLASTP是蛋白序列到蛋白库中的一种查询;库中存在的每条已知序列将逐一地同每条所查序列作一对一的序列比对;2、BLASTX是核酸序列到蛋白库中的一种查询;先将核酸序列翻译成蛋白序列一条核酸序列会被翻译成可能的六条蛋白,再对每一条作一对一的蛋白序列比对;3、BLASTN是核酸序列到核酸库中的一种查询;库中存在的每条已知序列都将同所查序列作一对一地核酸序列比对;4、TBLASTN是蛋白序列到核酸库中的一种查询;与BLASTX相反,它是将库中的核酸序列翻译成蛋白序列,再同所查序列作蛋白与蛋白的比对;5、TBLASTX是核酸序列到核酸库中的一种查询;此种查询将库中的核酸序列和所查的核酸序列都翻译成蛋白每条核酸序列会产生6条可能的蛋白序列,这样每次比对会产生36种比对阵列;NCBI的在线BLAST:下面是具体操作方法1,进入在线BLAST界面,可以选择blast特定的物种如人,小鼠,水稻等,也可以选择blast 所有的核酸或蛋白序列;不同的blast程序上面已经有了介绍;这里以常用的核酸库作为例子;2,粘贴fasta格式的序列;选择一个要比对的数据库;关于数据库的说明请看NCBI在线blast数据库的简要说明;一般的话参数默认;3,blast参数的设置;注意显示的最大的结果数跟E值,E值是比较重要的;筛选的标准;最后会说明一下;4,注意一下你输入的序列长度;注意一下比对的数据库的说明;5,blast结果的图形显示;没啥好说的;6,blast结果的描述区域;注意分值与E值;分值越大越靠前了,E值越小也是这样;7,blast结果的详细比对结果;注意比对到的序列长度;评价一个blast结果的标准主要有三项,E值Expect,一致性Identities,缺失或插入Gaps;加上长度的话,就有四个标准了;如图中显示,比对到的序列长度为1405,看Identities这一值,才匹配到1344bp,而输入的序列长度也是为1344bp看上面的图,就说明比对到的序列要长一点;由Qurey起始1和Sbjct起始35的起始位置可知,5'端是是多了一段的;有时也要注意3'端的;附:E值Expect:表示随机匹配的可能性,E值越大,随机匹配的可能性也越大;E值接近零或为零时,具本上就是完全匹配了;一致性Identities:或相似性;匹配上的碱基数占总序列长的百分数;缺失或插入Gaps:插入或缺失;用"—"来表示;。
NCBI在线BLAST使用方法与结果详解
NCBI在线BLAST使用方法与结果详解NCBI在线BLAST(Basic Local Alignment Search Tool)是一种广泛使用的生物信息学工具,用于比对和分析DNA、RNA或蛋白质序列。
它可以对已知和未知序列进行,找到与查询序列相似的序列,并提供有关相似性和功能的信息。
使用NCBI在线BLAST可以分为四个主要步骤:选择BLAST程序,输入查询序列,选择目标数据库,解析和分析结果。
第一步:选择BLAST程序NCBI提供了多种BLAST程序可供选择,包括BLASTN(DNA对DNA的比对)、BLASTP(蛋白质对蛋白质的比对)、BLASTX(DNA对蛋白质的比对)等。
根据实际需求选择相应的BLAST程序。
第二步:输入查询序列在查询序列的文本框中输入待比对的序列。
可以输入单个序列,也可以上传包含多个序列的文件。
如果输入的序列是DNA或RNA序列,需要选择相应的序列类型。
此外,还可以选择是否使用掩码序列或低复杂性筛选来优化比对结果。
第三步:选择目标数据库用户可以选择目标数据库来与查询序列相似的序列。
NCBI提供了多个常用的数据库,如nr(非冗余蛋白质数据库)、nt(核酸数据库)等。
此外,还可以选择特定的物种数据库来限制比对范围。
第四步:解析和分析结果在BLAST运行完成后,会生成一个结果页面,其中包含了比对结果的详细信息。
结果页面包括比对统计信息、序列比对图、E值、分数等。
通过分析这些信息,可以了解查询序列与目标数据库中的序列之间的相似性和可能的功能。
此外,NCBI在线BLAST还提供了一些高级选项,例如使用特定的算法或参数来进行比对、设置比对阈值、选择比对输出格式等。
这些选项可以根据实际需求进行调整。
总结起来,使用NCBI在线BLAST可以通过选择BLAST程序、输入查询序列、选择目标数据库以及解析和分析结果来比对和分析序列。
通过权衡算法和参数选择,在特定数据库中找到与查询序列相似的序列,从而获得有关其相似性和功能的信息。
NCBI在线版Blast使用(超详细奥)
NCBI在线版Blast使⽤(超详细奥)⾸先进⾏Blast类型的选择:blastp:将待查询的蛋⽩质序列及其互补序列⼀起对蛋⽩质序列数据库进⾏查询;blastn:将待查询的核酸序列及其互补序列⼀起对核酸序列数据库进⾏查询;blastx:先将待查询的核酸序列按六种可读框架(逐个向前三个碱基和逐个向后三个碱基读码)翻译成蛋⽩质序列,然后将翻译结果对蛋⽩质序列数据库进⾏查询;tblastn:先将核酸序列数据库中的核酸序列按六种可读框架翻译成蛋⽩质序列,然后将待查询的蛋⽩质序列及其互补序列对其翻译结果进⾏查询;tblastx:先将待查询的核酸序列和核酸序列数据库中的核酸序列按六种可读框架翻译成蛋⽩质序列,然后再将两种翻译结果从蛋⽩质⽔平进⾏查询。
基本步骤如下:1,进⼊在线blast界⾯,可以选择blast特定的物种(如下)。
不同的blast程序上⾯已经有了介绍。
这⾥以常⽤的Blast 中nucleotide blast作为例⼦。
Human ⼈类Mouse ⼩⿏Rat ⼤⿏Arabidopsis thaliana 拟南芥Oryza sativa ⽔稻Bos taurus ⽜Danio rerio 斑马鱼Drosophila melanogaster ⿊腹果蝇Gallus gallus 乌⾻鸡Pan troglodytes ⿊猩猩Microbes 微⽣物Apis mellifera 蜜蜂2,粘贴fasta格式的序列(可以是多条奥!!)或使⽤Accession number(s)、gi(s)(注意仅使⽤数字,不加上标志符gi)。
选择⼀个要⽐对的数据库,如果是⼈和⿏则进⾏相应的选择,否则选择Others中的nr/nt 。
关于数据库的说明请看NCBI在线blast数据库的简要说明。
其他选项不是必选的,如Job Title就是这次⽐对的名字,随便起⼀个即可;Organism为物种,可以填⼊你想⽐对的物种(分类单元如green plant等)的名字(拉丁名字,输⼊⼏个字母后会出现索引的)。
如何看懂NCBI-BLAST输出结果
如何看懂NCBI BLAST输出结果2010-11-13 10:38:11| 分类:生物信息分析| 标签:blast |字号大中小订阅本文转自:写在解读报告之前的,首先就使用Blast最终的目的是什么达成一致,Blast 是通过两两比对,找到数据库中与输入序列最相似的序列,或者说是最相似的序列片段。
那么我们看比对结果就是看Blast从数据库中找到哪些相似的序列,然后就是如何相似,这些相似又可以告诉我们哪些信息等。
当然Blast可以衍生出许多的用途,但都是建立在找到相似性序列(片段)的基础上的。
最新的BLAST结果报告解读,本文以BLASTP为例子,说明如何来解读BLAST 结果。
示例BLAST地址:比对用的例子:>gi|16758036|ref|NP_445782.1| ribosomal protein L21 [Rattus norvegicus] MTNTKGKRRGTRYMFSRPFRKHGVVPLATYMRIYKKGDIVDIKGMGTVQKG MPHKCYHGKTGRVYNVTQH AVGIIVNKQVKGKILAKRINVRIEHIKHSKSRDSFLKRVKENDQKKKEAKEKG TWVQLNGQPAPPREAHFVRTNGKEPELLEPIPYEFMA数据选择:nr比对时间:2009年9月9日12:46:23解读报告前需要掌握的概念:alignments 代表比对上的两个序列hits 表示两个序列比对上的片段Score 比对得分,如果序列匹配上得分,不一样,减分,分值越高,两个序列相似性越高E Value 值越小,越可信,相对的一个统计值。
Length 输入序列的长度Identities 一致性,就是两个序列有多少是一样的Query 代表输入序列Sbjct 代表数据库中的序列结果详细说明菜单与基本信息NCBI Blast结果-菜单与基本信息1.下一步操作的菜单,你可以调整参数,重新比对、保存你的搜索条件以便下次比对、调整报告显示的参数,以更符合你的要求、下载你比对的结果;2.此次比对的标题,优先是你填写的,如果没有填写可能是你输入fasta序列头(大于号后面的),如果这个也没有找到,NCBI会自动生成一个;3.你输入序列的信息,包括标识号、描述信息、类型、长度;4.数据库的信息以及你选择的Blast程序;5.查看其他报告,比如摘要、分类、距离树、结构、多重比对等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
NCBI在线BLAST使用方法与结果详解
BLAST(Basic Local Alignment Search Tool)是一套在蛋白质数据库或DNA
数据库中进行相似性比较的分析工具。
BLAST程序能迅速与公开数据库进行相似性序列比较。
BLAST结果中的得分是对一种对相似性的统计说明。
BLAST 采用一种局部的算法获得两个序列中具有相似性的序列。
Blast中常用的程序介绍:
1、BLASTP是蛋白序列到蛋白库中的一种查询。
库中存在的每条已知序列将逐一地同每条所查序列作一对一的序列比对。
2、BLASTX是核酸序列到蛋白库中的一种查询。
先将核酸序列翻译成蛋白序列(一条核酸序列会被翻译成可能的六条蛋白),再对每一条作一对一的蛋白序列比对。
3、BLASTN是核酸序列到核酸库中的一种查询。
库中存在的每条已知序列都将同所查序列作一对一地核酸序列比对。
4、TBLASTN是蛋白序列到核酸库中的一种查询。
与BLASTX相反,它是将库中的核酸序列翻译成蛋白序列,再同所查序列作蛋白与蛋白的比对。
5、TBLASTX是核酸序列到核酸库中的一种查询。
此种查询将库中的核酸序列和所查的核酸序列都翻译成蛋白(每条核酸序列会产生6条可能的蛋白序列),这样每次比对会产生36种比对阵列。
NCBI的在线BLAST:下面是具体操作方法
1,进入在线BLAST界面,可以选择blast特定的物种(如人,小鼠,水稻等),也可以选择blast所有的核酸或蛋白序列。
不同的blast程序上面已经有了介绍。
这里以常用的核酸库作为例子。
2,粘贴fasta格式的序列。
选择一个要比对的数据库。
关于数据库的说明请看NCBI在线blast数据库的简要说明。
一般的话参数默认。
3,blast参数的设置。
注意显示的最大的结果数跟E值,E值是比较重要的。
筛选的标准。
最后会说明一下。
4,注意一下你输入的序列长度。
注意一下比对的数据库的说明。
5,blast结果的图形显示。
没啥好说的。
6,blast结果的描述区域。
注意分值与E值。
分值越大越靠前了,E值越小也是这样。
7,blast结果的详细比对结果。
注意比对到的序列长度。
评价一个blast结果的标准主要有三项,E值(Expect),一致性(Identities),缺失或插入(Gaps)。
加上长度的话,就有四个标准了。
如图中显示,比对到的序列长度为1405,看Identities这一值,才匹配到1344bp,而输入的序列长度也是为1344bp(看上面的图),就说明比对到的序列要长一点。
由Qurey(起始1)和Sbjct(起始35)的起始位置可知,5'端是是多了一段的。
有时也要注意3'端的。
附:
E值(Expect):表示随机匹配的可能性,E值越大,随机匹配的可能性也越大。
E值接近零或为零时,具本上就是完全匹配了。
一致性(Identities):或相似性。
匹配上的碱基数占总序列长的百分数。
缺失或插入(Gaps):插入或缺失。
用"—"来表示。