统计学教程(含spss)二 统计量描述
SPSS软件学习_spss统计描述过程

11
分布曲线形状:偏度的含义
偏度:
大于0表示=正偏=右偏=均值在中位数的右边
左偏
右偏
均值 中位数 众数
众数 中位数 均值
63
12
分布曲线形状:峰度的布
峰度大于0
13
二、描述统计量过程
Frequency
Horsepower
70
60
50
40
30
20
10
Std. Dev = 38.52
Mean = 104.8
0
N = 400.00
50.0 70.0 90.0 110.0 130.0 150.0 170.0 190.0 210.0 230.0
60.0 80.0 100.0 120.0 140.0 160.0 180.0 200.0 220.0
中位数适用于任意分布类型的资料。用中 位数来描述连续变量会损失很多信息,对于 对称分布资料,优先考虑使用均数,仅仅均 数不能使用时才用中位数加以描述;
中位数对于定序变量、连续变量均可以使 用。对定序变量通常采用中位数(不是众数) 来反映更多、更精确的信息。
36
4.2.3 其它集中趋势描述指标
1. 截尾均数 数据排序 去掉最两端的数据(常用的截尾均数有5% 截尾均数,即两端去掉5%的数据,在SPSS 中Explore中可以实现)
如果截尾均数与原均数相差不大,说明 数据不存在极端值,反之相反。
37
2.几何平均数
常用于计算百分比、比率、指数、增长率等 指标的平均数
几何平均数 算术平均数 公式(要求 xi > 0 )
第3章SPSS描述性统计分析

3.1.1 频数分析的基本原理
图3-14 【描述性】对话框
Step 02 在左侧的候选变量列表框中选择“male”和 “female”变量,将其添加至【变量】列表框中,表示它是 进行描述性统计分析的变量,如图3-15所示。
图3-15 选择分析变量
Step 03 单击【选项】按钮,其主要目的是选择需要输出 的描述性统计量,这里除了选择系统默认的统计量外,还勾 选了范围、偏度系数和峰度系数复选框;再单击【继续】按 钮,返回【描述性】对话框,如图3-16所示。 Step 04 单击【确定】按钮完成操作。
图3-13 【描述:选项】对话框
Step 04 在【描述性】对话框中,勾选【将标准化得分另 存为变量】复选框,表示对所选择的每一个变量进行标准化 处理,同时产生相应的Z得分,并作为新变量保存到数据窗 口中。
Step 05 单击【Bootstrap】按钮,弹出如图3-5所示的 【Bootstrap】对话框,在此对话框中可以进行均值、标准 差、方差、偏度和峰度的Bootstrap估计。
图3-17 【探索】对话框
Step 02 在对话框左侧的候选变量列表框中选取一个或多 个待分析变量,将它们移入右侧的【因变量列表】列表框中 ,表示要进行探索性分析的变量。 Step 03 在候选变量列表框中可以选取一个或多个分组变 量,将它们移入右侧的【因子列表】列表框中。分组变量的 选择可以将数据按该变量中的观测值进行分组分析。如果选 择的分组变量不止一个,那么会以分组变量的不同取值进行 组合分组。
统计学原理SPSS实验报告
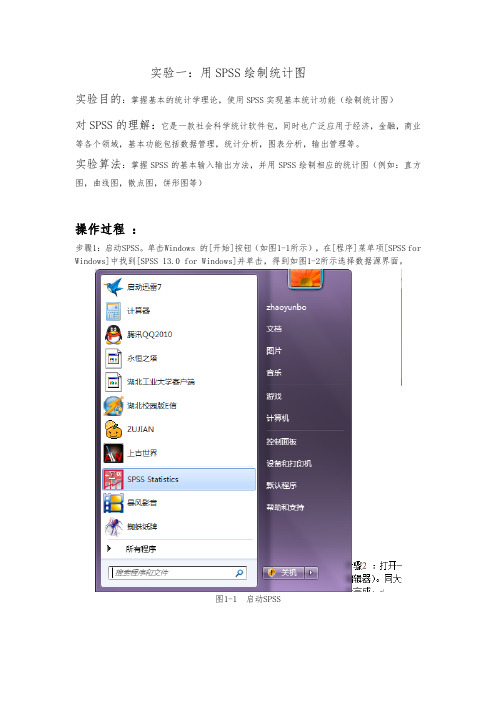
实验一:用SPSS绘制统计图实验目的:掌握基本的统计学理论,使用SPSS实现基本统计功能(绘制统计图)对SPSS的理解:它是一款社会科学统计软件包,同时也广泛应用于经济,金融,商业等各个领域,基本功能包括数据管理,统计分析,图表分析,输出管理等。
实验算法:掌握SPSS的基本输入输出方法,并用SPSS绘制相应的统计图(例如:直方图,曲线图,散点图,饼形图等)操作过程:步骤1:启动SPSS。
单击Windows 的[开始]按钮(如图1-1所示),在[程序]菜单项[SPSS for Windows]中找到[SPSS 13.0 for Windows]并单击,得到如图1-2所示选择数据源界面。
图1-1 启动SPSS图1-2 选择数据源界面步骤2 :打开一个空白的SPSS数据文件,如图1-3。
启动SPSS 后,出现SPSS 主界面(数据编辑器)。
同大多数Windows 程序一样,SPSS 是以菜单驱动的。
多数功能通过从菜单中选择完成。
图1-3 空白的SPSS数据文件步骤3:数据的输入。
打开SPSS以后,直接进入变量视图窗口。
SPSS的变量视图窗口分为data view和variable view两个。
先在variable view中定义变量,然后在data view里面直接输入自定义数据。
命名为mydata并保存在桌面。
如图1-4所示。
图1-4 数据的输入步骤4:调用Graphs菜单的Bar过程,绘制直条图。
直条图用直条的长短来表示非连续性资料(该资料可以是绝对数,也可以是相对数)的数量大小。
选择的数据源见表1。
步骤5:数据准备。
激活数据管理窗口,定义变量名:年龄标化发生率为RATE,冠心病临床型为DISEASE,血压状态为BP。
RATE按原数据输入,DISEASE按冠状动脉机能不全=1、猝死=2、心绞痛=3、心肌梗塞=4输入,BP按正常=1、临界=2、异常=3输入。
步骤6:选Graphs菜单的Bar...过程,弹出Bar Chart定义选项框(图1-5)。
SPSS知识2:统计描述

统计描述符合正态分布或近似正态分布资料的统计描述统计量:(一)描述平均水平的常用统计量——算术均数(二)描述变异水平(离散程度)的常用统计量——离均差平方和(SS)、平均方差(方差:MS)、标准差(SD)(三)描述抽样误差大小的统计量——标准误(SE)。
SPSS操作:对某1变量(如time)进行统计描述:正态性检验:Analyze→nonparametric tests→1-sample K-S→调入某变量和激活Nomal→OK。
正态的统计描述:analyze→descriptive statistics→descriptives→调入某变量,点击option…→点击mean、SE、SD→OK。
分析结果:表descriptive statistics(可看N、min、max、mean、SD);Z=0.649;P=0.794>0.05.说明time服从近似正态分布。
对某一变量分组进行统计描述(如按男、女分别做time的统计描述):文件分割:data→split file;注意:计算机有记忆功能,文件分割后需要把它还原,才不会影响后续操作。
统计描述(操作同上):analyze→descriptive statistics→descriptives→调入某变量,点击option…→点击mean、SE、SD→OK。
非正态资料的统计描述统计量:(一)描述集中位置——中位数(二)描述变异水平(离散程度)——四分位数间距=P75-P25。
SPSS操作:对某1变量(红血球体积hct)进行统计描述:正态性检验(同上):Analyze→nonparametric tests→1-sample K-S→调入某变量和激活Nomal→OK。
非正态的统计描述:analyze→descriptive statistics→frequencies→调入某变量,点击statistics…→点击median和quartiles。
编制频数分布表和绘制频数分布直方图一、对数据进行重新编码(recod e)SPSS操作:统计描述:Recode:Transform→recode into different variables…(表示recode后存入新的变量名中,原始数据还在)→调入变量进入“input→output”中,在右侧output框中输入新的变量名,可label→点击change→点击框下的old and new values…→根据手工分组,确定组距后:lowest:1→range→higest:最后一组→OK。
最新第2讲.SPSS描述性统计分析PPT课件

待分析变量,移入右侧。 3)“显示频率表格”,勾选该复选
框,可输出频数分析表。
SPSS频数分析
二、几个重要的设置对话框 “统计量”按钮对应的对话框:
1)四分位数:显示25%、50%、 75%的分位数。 2)割点:勾选后可输入数值A, 将数据平分为A等分。例如,输 入5,表示输出20%、40%、 60%、80%的百分位数。 3)百分位数:选中后,可激活 右侧的文本框和列表。可输入、 更改和删除自定义的百分位数。
幂估计:对每一组数据产生一个中位数的自然对数与四 分位数的自然对数的散列点图,达到方差齐次性要求的 幂次估计;并据此散布图,来估计将各组方差转换成同 方差所需的幂次。
转换:对原始数据进行变换。可在下拉列表中选 择转换的幂值。 未转换:不对数据进行转换,产生原始数据的散 布图。注:“无”是不产生该选项的图形。
二、按钮对应的界面介绍
统计量对话框
输出前面所讲述的各个描述统计量,并可设置均值的 置信5个最大值与最小值。在输出窗 口被表明为极端值。
“选项”对话 框
输出结果显示5%,10%,25%,50%,75%,90%和95% 的百分位数。
从所有分析中,将因变量或分组变量中带有缺失值的观测 量予以剔除。 从当前分析中,将有缺失值的观测量均予以剔除。
SPSS探索性统计分析整体分析与设计的内容
二、操作
探索性数据分析过程用于计算指定变量的探索性统计量和有关的图 形。从这个过程中可以获得箱图、茎叶图、直方图、各种正态检验 图、频数表、方差齐性检验等结果,以及对非正态或正态非齐性数据 进行变换,以表明和检验连续变量的数值分布情况。
SPSS应用二 描述统计

列合计 n j f ij , j 1 , 2 , , c . 而样本容量 n f ij
r i 1
i 1 j 1
r
c
r × c 列联表
列 行 1 2 … 1 2 … … … … c 合计
f11 f 21
…
f 12
f 22
…
f1c
f r2
…
n1
n2
…
r
合计
P25
P0
偏度和峰度系数
偏态是指大部份的数值落在平均数的哪一边, 若分配較多集中在低数值方面,是为正偏态分配 (或称右偏态分配);若分配较多集中在高数值方面, 是为负偏态分配(或称左偏态分配),正态分布的偏 态为0,SPSS计算公式为:
n SKewness (n 2)
s ( xi x )2
计算
公式: n为奇数时
MX
(
n 1 ) 2
n为偶数时
1 M X n X n ( 1) 2 (2) 2
中位数的特征
1. 计算时只利用了位置居中的测量值 优点:对极值不敏感 缺点:并非考虑到每个观测值 2. 适用于各种分布类型的资料, 特别适合于:大样本偏态分布资料 或者一端或两端无确切数值的资料
580 560 540 520 500 480 460 440 420
560 540 500 460 440
2500
520 510 500 490 480
2500
510 505 500 495 490
2500
均数
500
500
500
甲
乙 丙
离散与变异性指标
全距 四分位间距 方差 标准差 变异系数
第5章-SPSS基本统计分析说课讲解

6.单击Format指定列联表各单元的输出排 列顺序;
7.单击Statistics指定用哪种方法分析行变 量和列变量的关系。
5.5 多选项分析
一、什么是多选项问题 二、分析多选项问题的一般方案 三、多选项分析处理多选项问题
一、什么是多选项问题
③Charts 统计图形
④Format 设置频数表输出格式。
● Multiple variables 多变量栏 •Compare variables,将所有变量结果在一个图形z 中输出 •Organize output by variables ,为每一个变量单独 输出一个图形。
Statistics
variables/File is already sorted。
四、分组计算描述统计量
5.2 变量的频数分析
一、变量频数的描述方法 利用变量的频数分布分析可以方便
的对数据按组进行归类整理,形成各观 测量的不同水平(分组)的频数分布情 况表和图形,以便对数值的数量特征和 内部结构状况有一个概括的认识。
7
11.00
12.00
13.00
16.00
5.4 交叉分组下的频数分析
一、交叉分组下的频数分析
1.主要任务: (1)编制交叉列联表
(2)变量间进行相关性分析
一、交叉分组下的频数分析
1. 交叉列联表 两个或两个以上的变量交叉分组后形成的
列联表。 行变量(Row):表1、2中 职称 列变量(Column):表1、2中文化程度 层变量(Layer):表2中性别
5.3 变量的频数分析
1.频数、百分比 有效百分比:各频数占总有效样本数之比 累计百分比:各百分比逐级累加结果。 2.分位数 4分位数(Quartiles) 3.统计图形 条形图、饼图、直方图
SPSS统计分析实用教程(第2版)

探索性分析
03
均值比较与t检验
总结词
单样本t检验用于检验单个样本的均值是否与已知的某个值或参考值存在显著差异。
详细描述
在单样本t检验中,我们将已知的某个值或参考值作为检验标准,然后比较单个样本的均值与此标准之间的差异。通过计算t统计量和对应的p值,我们可以判断样本均值与标准值是否存在显著差异。
单样本t检验
通过图形方式展示两个变量之间的关系,可以直观地观察到它们之间的模式和趋势。
相关分析
散点图
相关系数
预测模型
通过一个或多个自变量预测因变量的值,建立预测模型,并评估模型的拟合优度和预测能力。
回归系数
描述自变量对因变量的影响程度,通过回归系数可以了解各个自变量对因变量的贡献。
线性回归分析
非线性关系
协方差分析是在考虑一个或多个协变量的影响后,比较两个或多个分类变量对数值型变量的影响。通过控制协变量的影响,可以更准确地评估各组之间的差异,并确定分类变量对数值型变量的真实效应。
总结词
详细描述
协方差分析
05
非参数检验
适用范围
01
卡方检验主要用于比较实际观测频数与期望频数之间的差异。
计算方法
02
通过卡方统计量,即实际观测频数与期望频数的差的平方与期望频数的比值,来评估两者之间的差异程度。
聚类分析
聚类分析基于观测数据之间的相似性或距离将它们分组,使得同一聚类中的数据尽可能相似,不同聚类中的数据尽可能不同。
聚类分析在市场细分、生物信息学和社交网络等领域有广泛应用。
THANKS FOR
WATCHING
感谢您的观看
详细描述
探索性分析
总结词
探索性分析还可以用于预测和分类,例如决策树、逻辑回归等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
用SPSS作统计量描述
用SPSS作统计量描述
由 descriptive statistics 计算
由 Frequencies 计算 由 Explore 计算
由 descriptive statistics 计算
三十名学生的身高与体重数据 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 性别 男 男 男 男 男 女 女 女 女 女 男 男 男 男 男 年龄 13 13 13 13 13 13 13 13 13 13 13 14 14 14 14 身高 156.0 155.0 144.6 161.5 161.3 158.0 161.0 162.0 164.3 144.0 157.9 176.1 168.0 164.5 153.0 体重 47.5 37.8 38.6 41.6 43.3 47.3 47.1 47.0 33.8 33.8 49.2 54.5 50.0 44.0 58.0 序号 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 性别 女 女 女 女 女 男 男 男 男 男 女 女 女 女 女 年龄 14 14 14 14 14 15 15 15 15 15 15 15 15 15 15 身高 164.7 160.5 147.0 153.2 157.9 166.0 169.0 170.0 165.1 172.0 159.4 161.3 158.0 158.6 169.0
选入分 析变量
由 Frequencies 计算
百分位数 四分位数 均值 中位数 众数 合计
标准差 方差 全距
最小值 最大值 均值标准误
偏度 峰度
由 Frequencies 计算
由 Frequencies 计算
由 Frequencies 计算
由 Frequencies 计算
由 Explore 计算
关键术语 五数概括法(five-number summary)是一种探索性数据分析的技术。用五个数据值:最小值、第1四分位数、平均数、第3四分位数 和最大值来概括数据集 盒形图(box plot)一种用图形概括数据的方法。用一个以第1和第3四分位数为边界的盒来表明在中心位置50%的数据。以一条横线 线 (须线)从方盒两侧延伸以表明大于第3四分位数和小于第1四分位数的数据值的位置。所有异常值民予以标明 协方差(covariance)用以衡量两变量间线性相关关系的数值量度。正值表示正相关,负值表示负相关 相关系数(correlation coefficient)用以衡量两变量间线性相关关系的数值量度。 加权平均数(weighted mean)将每个数据值予以一个权重以反映其在数据集中重要程度。以此获得的平均数即为加权平均数 分组数据(grouped data)将数据分为若干个组并配以频数分布,而不记录原始数据的个体值 偏度(skewness)对分布偏斜方向和程度的测度 峰度(kurtosis)对分布曲线尖削程度的测度
结束
案例
案例3-1 某联合食口公司抽取100个客户做为样本,记录其支付方式和支付金额。 公司经理要求从这个样本中得到客户实际支付情况的信息。样本数据见“案 例3-1”: 要求:以分析报告的形式,运用图表描述和统计量描述中介绍的描述统计学 方法,对样本数据加以概括。 概括中应包含下列的概括和讨论: 1、对于各个平均数和中位数的比较和理解; 2、对于各个显示变异程度的统计量,如极ቤተ መጻሕፍቲ ባይዱ和标准差进行比较和理解; 3、分别对于3种支付方式用五数概括法进行比较和理解。 4、分别对3种支付方式画盒形图 *报告的总结部分,讨论一下从中可以得出关于联合食品公司的客户支付方 式和支付金额的什么结论。
结束
[据集2] 体重 44.1 53.0 36.4 30.1 40.4 57.0 58.5 51.0 58.0 55.0 44.7 45.4 44.3 42.8 51.1
由 descriptive statistics 计算
由 descriptive statistics 计算
选入分 析变量
由 descriptive statistics 计算
由 Explore 计算
选入分 析变量
由 Explore 计算
由 Explore 计算
结束
关键术语 平均数(mean)衡量数据集中心位置的量度。用所有数据值相加的和除以项数计算 中位数(median)衡量数据集中心位置的量度。中位数将所有的数据分为两个相等的部分,一部分的值都大于或等于它,而另一部分 都小于或等于它 众数(mode)衡量数据中心位置的量度。它是发生频数最高的数据值 百分位数(percentile)至少有p%的数据项小于等于这个值,且至少有(100-p)%的数据项大于等于这个值。第50百分位数即为中位 数 四分位数( quartile )第25、第50、第75百分位数即为第1、第2、第3四分位数。四分位数将数据集分为4个部分。每一部分含有25% 的数据 临界点(hinges)下端临界点为第1四分位数,上端临界点为第3四分位数。 全距(range)用以衡量变异程度的量度,它是最大值减最小值的差 四分位内距(interquartile range,IQR)用以衡量变异程度的量度,它是第3四分位数与第1四分位数之差 方差(variance)用以衡量数据集变异程度的量度,是建立在距平均数离差的平方值的基础上的 标准差(standard deviation)用以衡量数据集变异程度的量度,取方差的正的平方根 Z分数(z-score)以距平均数的离差除以标准差所得的值。是标准化的数值,指数据值距离平均数的标准差的个数 切贝谢夫定理(chebysher’s theorem)这一定理可以用于任何数据集,用来描述与平均数的距离在特定数目个标准差范围之内的数据 项的百分比 经验法则(empirical rule)这一法则适用于钟形分布的数据,用以描述与平均数的距离在1、2、3个标准差之内的数据项的百分比 异常值(outlier)异常大或异常小的数据值
均值 离散趋势 标准差 方差 全距
合计
最小观测值
最大观测值 均值标准误
分布形态 峰度 偏度
输出顺序 按数据集中变量的排列顺序显示统计量 按变量名字母顺序显示统计量 按均值升序显示统计量 按均值降序显示统计量
由 descriptive statistics 计算
由 Frequencies 计算
由 Frequencies 计算