如何基于Docker快速搭建多节点Hadoop集群
Hadoop环境搭建及wordcount实例运行
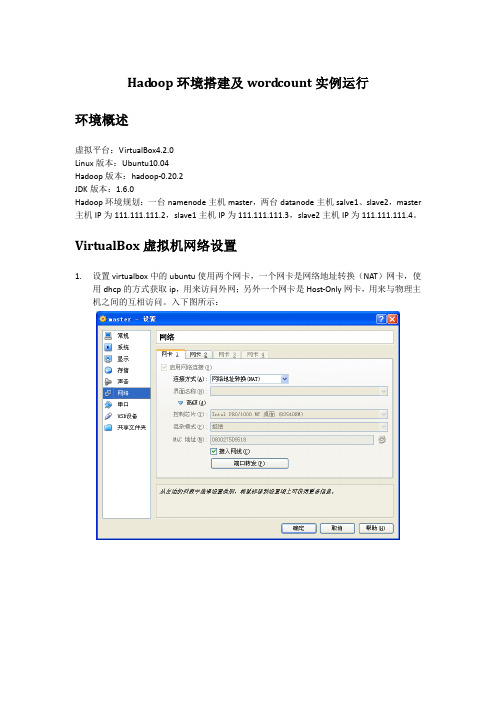
环境概述
虚拟平台:VirtualBox4.2.0
Linux版本:Ubuntu10.04
Hadoop版本:hadoop-0.20.2
JDK版本:1.6.0
Hadoop环境规划:一台namenode主机master,两台datanode主机salve1、slave2,master主机IP为111.111.111.2,slave1主机IP为111.111.111.3,slave2主机IP为111.111.111.4。
ssh_5.3p1-3ubuntu3_all.deb
依次安装即可
dpkg -i openssh-client_5.3p1-3ubuntu3_i386.deb
dpkg -i openssh-server_5.3p1-3ubuntu3_i386.deb
dpkg -i ssh_5.3p1-3ubuntu3_all.deb
14/02/20 15:59:58 INFO mapred.JobClient: Running job: job_201402201551_0003
14/02/20 15:59:59 INFO mapred.JobClient: map 0% reduce 0%
14/02/20 16:00:07 INFO mapred.JobClient: map 100% reduce 0%
111.111.111.2 master
111.111.111.3 slave1
111.111.111.4 slave2
然后按以下步骤配置master到slave1之间的ssh信任关系
用户@主机:/执行目录
操作命令
说明
hadoop@master:/home/hadoop
如何使用Docker构建一个高性能的大数据平台

如何使用Docker构建一个高性能的大数据平台在当今数字化时代,大数据应用正日益普及,各行业也在积极探索如何构建高性能的大数据平台。
Docker作为一种流行的容器化技术,为大数据平台的构建提供了一种全新的方式。
本文将探讨如何使用Docker构建一个高性能的大数据平台,以满足对数据分析和应用的需求。
一、Docker与大数据平台Docker是一种轻量级的虚拟化技术,可以将应用程序及其依赖项打包成独立的容器,并在任何环境中进行部署和运行。
与传统的虚拟机相比,Docker具有更低的资源占用和更快的启动时间,同时提供了更好的扩展性和便携性。
这些特点使得Docker成为构建高性能大数据平台的理想选择。
二、构建Docker镜像在构建一个高性能的大数据平台之前,首先需要构建好适用于大数据处理的Docker镜像。
Docker镜像是一个轻量级的、可执行的软件包,其中包含了应用程序及其所需的所有依赖项。
对于大数据平台,我们可以使用Apache Hadoop、Apache Spark等开源框架,将其与操作系统和其他相关组件打包成一个Docker镜像。
为了构建一个高性能的大数据平台,我们可以选择使用包含了最新版本的Apache Hadoop和Apache Spark的Docker镜像。
此外,还可以针对特定的应用场景和需求进行个性化定制,例如添加适用于分布式计算和存储的文件系统,或者集成一些常用的数据处理框架和工具等。
三、分布式环境部署构建好Docker镜像后,接下来需要将其部署到分布式环境中。
在大数据平台中,通常会涉及到多台计算机节点的协同工作,因此需要使用Docker Swarm或者Kubernetes等容器编排工具来管理和协调多个Docker容器的运行。
这些工具可以实现容器的自动伸缩、负载均衡和故障恢复等功能,从而提高大数据平台的性能和可用性。
在进行分布式环境部署时,需要注意设置合适的容器配置和网络设置。
例如,可以为每个容器分配足够的内存和CPU资源,以充分发挥其计算能力。
在Docker中部署ZooKeeper集群的详细教程

在Docker中部署ZooKeeper集群的详细教程一、介绍Docker是一种流行的容器化技术,允许开发人员将应用程序和其依赖项打包到一个可移植的容器中,实现软件环境的一致性和可移植性。
而ZooKeeper是一个开源的协调服务,用于分布式系统中的配置管理,命名服务和分布式锁等功能。
本文将详细介绍如何在Docker中部署ZooKeeper集群。
二、准备工作首先,需要在系统上安装Docker和Docker Compose。
具体的安装过程可以参考Docker和Docker Compose的官方文档。
安装完成后,确保Docker和Docker Compose正确运行。
三、创建Docker Compose文件在部署ZooKeeper集群之前,需要创建一个Docker Compose文件来定义集群中的容器。
创建一个新文件,命名为docker-compose.yml,并在其中输入以下内容:version: "3"services:zoo1:image: zookeeper:3.4.14restart: alwaysports:- "2181:2181"environment:ZOO_MY_ID: 1ZOO_SERVERS: server.1=zoo1:2888:3888 server.2=zoo2:2888:3888 server.3=zoo3:2888:3888volumes:- ./data/zoo1:/datazoo2:image: zookeeper:3.4.14restart: alwaysenvironment:ZOO_MY_ID: 2ZOO_SERVERS: server.1=zoo1:2888:3888 server.2=zoo2:2888:3888 server.3=zoo3:2888:3888volumes:- ./data/zoo2:/datazoo3:image: zookeeper:3.4.14restart: alwaysenvironment:ZOO_MY_ID: 3ZOO_SERVERS: server.1=zoo1:2888:3888 server.2=zoo2:2888:3888 server.3=zoo3:2888:3888volumes:- ./data/zoo3:/data在这个文件中,我们定义了三个ZooKeeper节点:zoo1、zoo2和zoo3。
在Docker Swarm中进行多集群和跨地域部署

在Docker Swarm中进行多集群和跨地域部署一级标题:Docker Swarm 多集群和跨地域部署简介在当今云计算环境中,容器化已经成为了部署和管理应用程序的主流方式之一。
Docker Swarm 是一个用于管理 Docker 容器的工具,它允许用户将多个 Docker 主机组织成一个集群,从而方便进行应用程序的部署和扩展。
而多集群和跨地域部署则提供了更高级的功能,允许用户在不同的地理位置、不同的云服务商之间进行容器化应用的分布式部署。
二级标题:Docker Swarm 多集群部署Docker Swarm 的多集群部署机制允许用户将多个 Swarm 集群连接起来,以便共同管理容器。
这使得用户可以更加灵活地部署应用程序,实现高可用和负载均衡。
要在 Docker Swarm 中进行多集群部署,需要遵循以下步骤:1. 创建并初始化第一个 Swarm 集群,可以选择任意一个 Docker 主机作为Swarm manager,并在其他 Docker 主机上作为 Swarm worker 加入该集群。
2. 创建其他 Swarm 集群,方法与第一个 Swarm 集群类似,只需将第一个Swarm manager 的 IP 地址用于初始化其他 Swarm 集群。
3. 运行 Docker 命令连接不同 Swarm 集群,这样就可以在这些集群之间进行容器的部署和管理。
通过 Docker 命令可以查看不同 Swarm 集群的状态、信息等。
4. 使用 Docker Stack 部署应用程序。
Docker Stack 是 Swarm mode 提供的一个部署工具,它允许用户通过 YAML 文件描述应用程序的服务、网络和其他相关配置,然后将其部署到 Swarm 集群中的多个节点上。
通过以上步骤,用户可以在 Docker Swarm 中实现多集群的部署,以满足不同应用场景下的需求。
二级标题:Docker Swarm 跨地域部署Docker Swarm 的跨地域部署功能使得用户可以在不同的地理位置进行容器化应用的分布式部署。
搭建hadoop集群的步骤

搭建hadoop集群的步骤Hadoop是一个开源的分布式计算平台,用于存储和处理大规模的数据集。
在大数据时代,Hadoop已经成为了处理海量数据的标准工具之一。
在本文中,我们将介绍如何搭建一个Hadoop集群。
步骤一:准备工作在开始搭建Hadoop集群之前,需要进行一些准备工作。
首先,需要选择适合的机器作为集群节点。
通常情况下,需要至少三台机器来搭建一个Hadoop集群。
其次,需要安装Java环境和SSH服务。
最后,需要下载Hadoop的二进制安装包。
步骤二:配置Hadoop环境在准备工作完成之后,需要对Hadoop环境进行配置。
首先,需要编辑Hadoop的配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml。
其中,core-site.xml用于配置Hadoop的核心参数,hdfs-site.xml用于配置Hadoop分布式文件系统的参数,mapred-site.xml用于配置Hadoop的MapReduce参数,yarn-site.xml用于配置Hadoop的资源管理器参数。
其次,需要在每个节点上创建一个hadoop用户,并设置其密码。
最后,需要在每个节点上配置SSH免密码登录,以便于节点之间的通信。
步骤三:启动Hadoop集群在完成Hadoop环境的配置之后,可以启动Hadoop集群。
首先,需要启动Hadoop的NameNode和DataNode服务。
NameNode是Hadoop分布式文件系统的管理节点,负责管理文件系统的元数据。
DataNode是Hadoop分布式文件系统的存储节点,负责实际存储数据。
其次,需要启动Hadoop的ResourceManager和NodeManager服务。
ResourceManager 是Hadoop的资源管理器,负责管理集群中的资源。
NodeManager是Hadoop的节点管理器,负责管理每个节点的资源。
组建hadoop集群实验报告

组建hadoop集群实验报告一、实验目的本次实验的目的是通过组建Hadoop 集群,熟悉和掌握Hadoop 的部署过程和相关技术,加深对分布式计算的理解并掌握其应用。
二、实验环境- 操作系统:Ubuntu 20.04- Hadoop 版本:3.3.0- Java 版本:OpenJDK 11.0.11三、实验步骤1. 下载和安装Hadoop在官方网站下载Hadoop 的二进制文件,并解压到本地的文件夹中。
然后进行一些配置,如设置环境变量等,以确保Hadoop 可以正常运行。
2. 配置Hadoop 集群a) 修改核心配置文件在Hadoop 的配置目录中找到`core-site.xml` 文件,在其中添加以下配置:xml<configuration><property><name>fs.defaultFS</name><value>hdfs:localhost:9000</value></property></configuration>b) 修改HDFS 配置文件在配置目录中找到`hdfs-site.xml` 文件,在其中添加以下配置:xml<configuration><property><name>dfs.replication</name><value>1</value></property></configuration>c) 修改YARN 配置文件在配置目录中找到`yarn-site.xml` 文件,在其中添加以下配置:xml<configuration><property><name>yarn.resourcemanager.hostname</name><value>localhost</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</nam e><value>org.apache.hadoop.mapred.ShuffleHandler</value></property></configuration>3. 启动Hadoop 集群在终端中执行以下命令来启动Hadoop 集群:bashstart-all.sh这将启动Hadoop 中的所有守护进程,包括NameNode、DataNode、ResourceManager 和NodeManager。
使用Docker部署多节点集群的步骤详解

使用Docker部署多节点集群的步骤详解在当今的科技领域,云计算和容器化技术已成为发展的热点。
而Docker作为一种轻量级的容器化技术,被广泛应用于构建、部署和管理应用程序的场景中。
本文将为大家介绍使用Docker部署多节点集群的步骤详解,帮助读者了解此过程并实践。
一、Docker简介Docker是一种开源的容器化技术,可以将应用程序及其所有依赖项打包到一个独立的容器中。
通过使用容器,开发人员可以更方便地构建、部署和管理应用程序,提高开发和运维效率。
二、多节点集群的概念多节点集群是指将多个服务器或主机连接在一起,通过集群的方式共同完成任务。
通过使用多节点集群,可以实现更高的可靠性、可扩展性和容错性。
三、Docker集群的工作原理Docker集群是一组共享资源的Docker主机,它们通过网络进行通信并协同工作。
Docker集群通常包含一个主节点和多个从节点,主节点负责管理和控制整个集群的操作,从节点则提供计算和存储资源。
四、准备工作1. 安装Docker:在每个节点上安装Docker引擎,可以通过Docker官方网站或各个操作系统的软件包管理器来安装。
2. 创建Docker网络:在主节点上创建一个Docker网络,以便在集群中的各个节点之间建立通信。
可以使用以下命令创建一个自定义的Docker网络:```docker network create mynetwork```五、配置主节点1. 初始化主节点:在主节点上运行以下命令,初始化主节点并启动集群管理器:```docker swarm init --advertise-addr <主节点IP地址>```此命令将生成一个令牌,后续用于将从节点加入集群。
2. 获取从节点加入命令:运行以下命令,获取将从节点加入集群的命令:```docker swarm join-token worker```将显示加入命令,类似于:```docker swarm join --token <令牌> <主节点IP地址>:2377```六、配置从节点在从节点上运行上一步中的加入命令,将从节点加入到主节点所在的集群中。
《hadoop基础》课件——第三章 Hadoop集群的搭建及配置

19
Hadoop集群—文件监控
http://master:50070
20
Hadoop集群—文件监控
http://master:50070
21
Hadoop集群—文件监控
http://master:50070
22
Hadoop集群—任务监控
http://master:8088
23
Hadoop集群—日志监控
http://master:19888
24
Hadoop集群—问题 1.集群节点相关服务没有启动?
1. 检查对应机器防火墙状态; 2. 检查对应机器的时间是否与主节点同步;
25
Hadoop集群—问题
2.集群状态不一致,clusterID不一致? 1. 删除/data.dir配置的目录; 2. 重新执行hadoop格式化;
准备工作:
1.Linux操作系统搭建完好。 2.PC机、服务器、环境正常。 3.搭建Hadoop需要的软件包(hadoop-2.7.6、jdk1.8.0_171)。 4.搭建三台虚拟机。(master、node1、node2)
存储采用分布式文件系统 HDFS,而且,HDFS的名称 节点和数据节点位于不同机 器上。
2、vim编辑core-site.xml,修改以下配置: <property>
<name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/soft/hadoop-2.7.6/tmp</value> </property> <property> <name>fs.trash.interval</name> <value>1440</value> </property>
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
如何基于Docker快速搭建多节点Hadoop集群Docker最核心的特性之一,就是能够将任何应用包括Hadoop打包到Docker镜像中。
这篇教程介绍了利用Docker在单机上快速搭建多节点 Hadoop集群的详细步骤。
作者在发现目前的Hadoop on Docker项目所存在的问题之后,开发了接近最小化的Hadoop镜像,并且支持快速搭建任意节点数的Hadoop集群。
Docker最核心的特性之一,就是能够将任何应用包括Hadoop打包到Docker镜像中。
这篇教程介绍了利用Docker在单机上快速搭建多节点 Hadoop集群的详细步骤。
作者在发现目前的Hadoop on Docker项目所存在的问题之后,开发了接近最小化的Hadoop镜像,并且支持快速搭建任意节点数的Hadoop集群。
一. 项目简介GitHub: kiwanlau/hadoop-cluster-docker直接用机器搭建Hadoop集群是一个相当痛苦的过程,尤其对初学者来说。
他们还没开始跑wordcount,可能就被这个问题折腾的体无完肤了。
而且也不是每个人都有好几台机器对吧。
你可以尝试用多个虚拟机搭建,前提是你有个性能杠杠的机器。
我的目标是将Hadoop集群运行在Docker容器中,使Hadoop开发者能够快速便捷地在本机搭建多节点的Hadoop集群。
其实这个想法已经有了不少实现,但是都不是很理想,他们或者镜像太大,或者使用太慢,或者使用了第三方工具使得使用起来过于复杂。
下表为一些已知的Hadoop on Docker项目以及其存在的问题。
我的项目参考了alvinhenrick/hadoop-mutinode项目,不过我做了大量的优化和重构。
alvinhenrick/hadoop-mutinode项目的GitHub主页以及作者所写的博客地址如下:GitHub:Hadoop (YARN) Multinode Cluster with Docker∙博客:Hadoop (YARN) Multinode Cluster with Docker下面两个表是alvinhenrick/hadoop-mutinode项目与我的kiwenlau/hadoop-cluster-docker项目的参数对比:可知,我主要优化了这样几点:∙更小的镜像大小∙更快的构造时间∙更少的镜像层数更快更方便地改变Hadoop集群节点数目另外,alvinhenrick/hadoop-mutinode项目增加节点时需要手动修改Hadoop配置文件然后重新构建hadoop-nn-dn 镜像,然后修改容器启动脚本,才能实现增加节点的功能。
而我通过shell脚本实现自动话,不到1分钟可以重新构建hadoop-master镜像,然后立即运行!本项目默认启动3个节点的Hadoop集群,支持任意节点数的Hadoop集群。
另外,启动Hadoop,运行wordcount以及重新构建镜像都采用了shell脚本实现自动化。
这样使得整个项目的使用以及开发都变得非常方便快捷。
开发测试环境∙操作系统:ubuntu 14.04 和 ubuntu 12.04∙内核版本: 3.13.0-32-generic∙Docker版本:1.5.0 和1.6.2小伙伴们,硬盘不够,内存不够,尤其是内核版本过低会导致运行失败。
二. 镜像简介本项目一共开发了4个镜像:∙serf-dnsmasq∙hadoop-base∙hadoop-master∙hadoop-slaveserf-dnsmasq镜像∙基于ubuntu:15.04 (选它是因为它最小,不是因为它最新)∙安装serf: serf是一个分布式的机器节点管理工具。
它可以动态地发现所有Hadoop 集群节点。
∙安装dnsmasq: dnsmasq作为轻量级的DNS服务器。
它可以为Hadoop集群提供域名解析服务。
容器启动时,master节点的IP会传给所有slave节点。
serf会在container启动后立即启动。
slave节点上的serf agent会马上发现master节点(master IP它们都知道嘛),master节点就马上发现了所有slave节点。
然后它们之间通过互相交换信息,所有节点就能知道其他所有节点的存在了。
(Everyone will know Everyone)。
serf发现新的节点时,就会重新配置dnsmasq,然后重启dnsmasq。
所以dnsmasq就能够解析集群的所有节点的域名啦。
这个过程随着节点的增加会耗时更久,因此,若配置的Hadoop节点比较多,则在启动容器后需要测试serf是否发现了所有节点,DNS是否能够解析所有节点域名。
稍等片刻才能启动Hadoop。
这个解决方案是由SequenceIQ公司提出的,该公司专注于将Hadoop运行在Docker中。
参考这个演讲稿。
hadoop-base镜像∙基于serf-dnsmasq镜像∙安装JDK(OpenJDK)∙安装openssh-server,配置无密码SSH∙安装vim:介样就可以愉快地在容器中敲代码了∙安装Hadoop 2.3.0: 安装编译过的Hadoop(2.5.2, 2.6.0, 2.7.0 都比2.3.0大,所以我懒得升级了)另外,编译Hadoop的步骤请参考我的博客。
如果需要重新开发我的hadoop-base, 需要下载编译过的hadoop-2.3.0安装包,放到hadoop-cluster-docker/hadoop-base/files目录内。
我编译的64位hadoop-2.3.0下载地址:/s/1sjFRaFz另外,我还编译了64位的Hadoop 2.5.2、2.6.0,、2.7.0, 其下载地址如下:∙hadoop-2.3.0: /s/1sjFRaFz∙hadoop-2.5.2: /s/1jGw24aa∙hadoop-2.6.0:/s/1eQgvF2M∙hadoop-2.7.0: /s/1c0HD0Nuhadoop-master镜像∙基于hadoop-base镜像∙配置hadoop的master节点∙格式化namenode这一步需要配置slaves文件,而slaves文件需要列出所有节点的域名或者IP。
因此,Hadoop节点数目不同时,slaves文件自然也不一样。
因此,更改Hadoop集群节点数目时,需要修改slaves文件然后重新构建hadoop-master镜像。
我编写了一个resize- cluster.sh 脚本自动化这一过程。
仅需给定节点数目作为脚本参数就可以轻松实现Hadoop集群节点数目的更改。
由于hadoop-master 镜像仅仅做一些配置工作,也无需下载任何文件,整个过程非常快,1分钟就足够了。
hadoop-slave镜像∙基于hadoop-base镜像∙配置hadoop的slave节点镜像大小分析下表为sudo docker images的运行结果:易知以下几个结论:∙serf-dnsmasq镜像在ubuntu:15.04镜像的基础上增加了75.4MB∙hadoop-base镜像在serf-dnsmasq镜像的基础上增加了570.7MB∙hadoop-master和hadoop-slave镜像在hadoop-base镜像的基础上大小几乎没有增加下表为sudo docker history /kiwenlau/hadoop-base:0.1.0的部分运行结果可知:∙基础镜像ubuntu:15.04为131.3MB∙安装OpenJDK需要324.6MB∙安装Hadoop需要158.5MB∙Ubuntu、OpenJDK与Hadoop均为镜像所必须,三者一共占了614.4MB 因此,我所开发的hadoop镜像以及接近最小,优化空间已经很小了。
三. 3节点Hadoop集群搭建步骤1. 拉取镜像1.sudo docker pull /kiwenlau/hadoop-master:0.1.02.3.sudo docker pull /kiwenlau/hadoop-slave:0.1.04.5.sudo docker pull /kiwenlau/hadoop-base:0.1.06.7.sudo docker pull /kiwenlau/serf-dnsmasq:0.1.03~5分钟OK~也可以直接从我的DokcerHub仓库中拉取镜像,这样就可以跳过第2步:1.sudo docker pull kiwenlau/hadoop-master:0.1.02.3.sudo docker pull kiwenlau/hadoop-slave:0.1.04.5.sudo docker pull kiwenlau/hadoop-base:0.1.06.7.sudo docker pull kiwenlau/serf-dnsmasq:0.1.0查看下载的镜像:1.sudo docker images运行结果:其中hadoop-base镜像是基于serf-dnsmasq镜像的,hadoop-slave镜像和hadoop-master镜像都是基于hadoop-base镜像。
所以其实4个镜像一共也就777.4MB。
2. 修改镜像tag1.sudo docker tag d6*******c03 kiwenlau/hadoop-slave:0.1.02.3.sudo docker tag 7c9d32ede450 kiwenlau/hadoop-master:0.1.04.5.sudo docker tag 5571bd5de58e kiwenlau/hadoop-base:0.1.06.7.sudo docker tag 09ed89c24ee8 kiwenlau/serf-dnsmasq:0.1.0查看修改tag后镜像:1.sudo docker images运行结果:之所以要修改镜像,是因为我默认是将镜像上传到Dockerhub, 因此Dokerfile以及shell脚本中得镜像名称都是没有alauada前缀的,sorry for this....不过改tag还是很快滴。
若直接下载我在DockerHub中的镜像,自然就不需要修改tag...不过Alauda镜像下载速度很快的哈~3.下载源代码git clone https:///kiwenlau/hadoop-cluster-docker为了防止GitHub被XX,我把代码导入到了开源中国的Git仓库:git clone /kiwenlau/hadoop-cluster-docker4. 运行容器1.cd hadoop-cluster-docker2.3../start-container.sh运行结果:1.start master container...2.3.start slave1 container...4.5.start slave2 container...6.7.root@master:~#一共开启了3个容器,1个master, 2个slave。