数学建模中SPSS运用
以数学建模竞赛为例基于spss建立arima模型

20201/295徐燕1981要/数理统计学专业副教授/博士/广州民航职业技术学院人文社科学院/南方医科大学访问学者/从事统计学方法和应用研究工作(广州510403)以数学建模竞赛为例基于SPSS 建立ARIMA 模型Combined with learning pass and BOPPPS model to improve the teaching effect of electrical science徐燕基金项目:2019年高等学校中青年教师国内访问学者项目资助。
摘要SPSS 软件是当前应用最广泛的统计软件之一,其菜单化操作模式能够让使用者快速入门,SPSS 软件中时间序列模块能够实现模型的自动化筛选,参数估计和模型检验,是非统计学专业人员进行数据分析的有力工具。
是本文以2019年全国大学生数学建模竞赛D 题为例,以SPSS23软件为工具,对数据进行时间序列分析,建立ARIMA 模型。
关键词数学建模;SPSS;时间序列;ARIMA 模型中图分类号:R058文献标识码:ADOI :10.19694/ki.issn2095-2457.2020.01.160引言SPSS 软件是当前世界上应用最广泛的统计软件之一,菜单化操作、图表化输出的特点特别受到非统计学专业人员的欢迎。
使用SPSS 软件,我们几乎可以完全自动的自变量的预变换、筛选、模型优化、检验等工作。
SPSS 软件中的预测模块,纳入了常用的时间序列分析模型,如ARIMA 模型,包括自动的模型选择、参数估计和模型检验等功能,实现了简单操作即可得到可靠的时间序列模型,其功能得到了使用者的肯定。
近年来,全国大学生数学建模竞赛频频出现大数据统计建模试题,作为非统计学专业的大学生,对于复杂的数据统计分析方法和工具接触并不很多,如何让这些学生快速入门和掌握一门有利的数据分析软件工具、完成数据分析和建模等任务就是我们近几年来数学建模培训教学研究的重点。
SPSS在数学建模中的应用

04 SPSS在数学建模中的实 践案例
案例一:利用SPSS进行市场细分
总结词
利用SPSS的统计分析功能,对市场进 行细分,为企业的市场策略提供依据。
详细描述
通过收集市场数据,利用SPSS的聚类 分析、因子分析等统计方法,将市场 划分为不同的细分市场,了解各细分 市场的特点,为企业制定针对性的市 场策略提供依据。
02 SPSS在数学建模中的优 势
强大的统计分析能力
描述性统计
SPSS提供了丰富的描述性统计功 能,如均值、中位数、方差等, 帮助用户快速了解数据的基本特 征。
推论性统计
SPSS支持多种推论性统计方法, 如回归分析、方差分析、卡方检 验等,能够揭示数据之间的内在 关系。
高级统计
SPSS还提供了许多高级统计方法, 如主成分分析、因子分析、聚类 分析等,能够满足复杂的数据分 析需求。
方便的数据处理功能
01
数据导入导出
数据清洗
02
03
数据转换
SPSS支持多种数据格式的导入和 导出,方便用户进行数据交换和 整合。
SPSS提供了数据筛选、缺失值处 理、异常值检测等功能,帮助用 户清洗和整理数据。
SPSS支持对数据进行分组、排序、 变量转换等操作,能够满足用户 对数据处理的各种需求。
03 SPSS在数学建模中的具 体应用
线性回归分析
总结词
线性回归分析是利用SPSS软件对因变量和自变量之间的关系进行建模的一种方法,通过最小二乘法拟合出最佳直 线,并计算出各因素对因变量的影响程度。
详细描述
在SPSS中,可以使用“回归”菜单下的“线性”命令来进行线性回归分析。用户需要指定因变量和自变量,并选 择适当的选项,如置信区间、模型拟合度等。SPSS将输出回归系数、标准误差、置信区间等统计量,帮助用户了 解自变量对因变量的影响程度。
SPSS在数学建模中的应用实例_周静
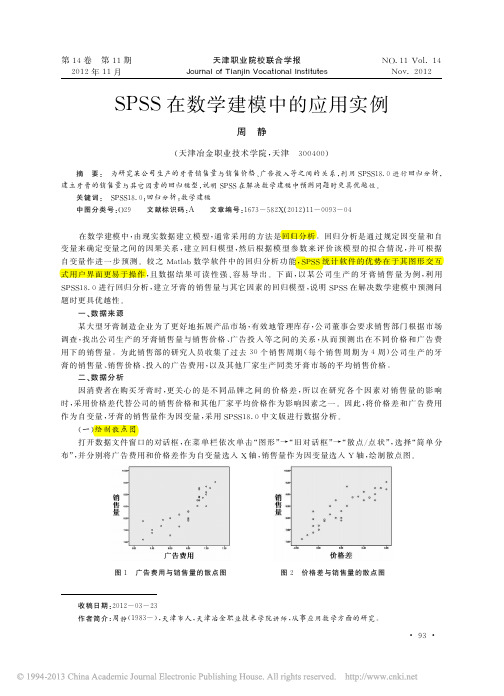
b2
b3
-1.728 -3.674 2.802
由表2可以看出,三个模型的拟合度基本相同 ,其 中 拟 合 度 最 好 的 是 立 方 曲 线 模 型 ,其 次 是 二 次 项 曲 线模型,但立方曲线模型的参数比另外两种模型的 参 数 多 ,更 为 复 杂。若 从 F 值 来 看,线 性 模 型 拟 合 的 最 为显著。但以上的结果还不足以作出判断 ,还需要对各模型系数作显著性检验 。重复上述 操 作,并 且 在 曲 线估计对话框勾选“显示 ANOVE 表格”。
多元回归分析之前 ,需引入新的变量 。从“转换”菜单中,打开计算变量对话框 ,输入 新 的 目 标 变 量 名, 即广告费用的平方 ,然后在数字表达式中编辑函 数 ,生 成 新 的 变 量。 接 下 来 在“分 析”菜 单 中,打 开 线 性 回
· 94 ·
归对话框,将广告费用、价格差和广告费用的平方同时选为自变量 ,将销售量选为因变量 ;单击“统 计 量”按
互作用;若变量包含分类变量和连续变量 ,可将分类变 量 转 换 为 虚 拟 变 量 后 ,当 成 连 续 变 量 再 进 行 回 归 分
以数学建模竞赛为例基于SPSS建立ARIMA模型

以数学建模竞赛为例基于SPSS建立ARIMA模型一、引言数学建模竞赛是在各种学科领域中,通过数学方法解决实际问题的一种竞赛形式。
参加数学建模竞赛需要队员具备一定的数学建模能力,包括数学建模的理论知识、数学工具的使用和数学模型的构建能力。
在数学建模竞赛中,队员需要根据给定的问题和数据,使用数学方法建立合适的数学模型,并进行模型的求解和分析。
数学建模竞赛中的数学建模和数据分析方法对于队员来说是至关重要的。
在本文中,我们将以数学建模竞赛的一个实际问题为例,演示如何利用SPSS软件建立ARIMA模型对相关数据进行预测和分析。
我们将首先介绍ARIMA模型的基本原理和建模流程,然后利用SPSS软件对给定的数据进行ARIMA模型的建立和检验,最后对模型的效果进行评价并给出相关建议。
二、ARIMA模型的基本原理ARIMA模型是时间序列分析中常用的一种模型,用于对时间序列数据进行预测和分析。
ARIMA模型包括自回归(AR)、差分(I)和移动平均(MA)三部分,分别表示时间序列数据中的自相关、季节性趋势和误差项。
ARIMA模型的建立包括模型的识别、参数的估计和模型的检验三个步骤。
1. 模型的识别:首先需要对时间序列数据进行平稳性和自相关性检验,确定ARIMA模型的参数p、d、q。
p表示自回归的阶数,d表示差分的阶数,q表示移动平均的阶数。
2. 参数的估计:利用最大似然估计等方法,对ARIMA模型中的参数进行估计,得到模型的估计系数。
3. 模型的检验:对估计的ARIMA模型进行残差分析和预测检验,对模型的拟合效果进行评价,并进行模型的调整和优化。
三、SPSS建立ARIMA模型的步骤在SPSS软件中,利用时间序列建模功能可以方便地进行ARIMA模型的建立和分析。
下面我们以一个实际的数据为例,演示在SPSS中建立ARIMA模型的具体步骤。
1. 数据导入:首先在SPSS中导入要分析的时间序列数据,可以是Excel表格或者文本文件格式。
数学建模SPSS案例分析

02
CATALOGUE
数据准备与预处理
数据来源与获取
确定数据来源
01
根据研究目的和问题,确定合适的数据来,如问卷调查、实验数据、公开数据库等。
数据获取
02
通过相应的方法和工具,如网络爬虫、数据接口、数据库查询
等,获取所需数据。
数据初步检查
03
对获取的数据进行初步检查,包括数据完整性、一致性、异常
SPSS建模过程演示
数据准备
根据研究目的和问题,收集和整理相关数据,并进行预处理和清洗, 确保数据质量和一致性。
变量定义与测量
明确研究中的自变量、因变量和控制变量,并进行相应的测量和编码 。
模型构建
根据研究假设和理论框架,选择合适的统计方法和模型进行构建,例 如回归分析、方差分析等。
模型检验与修正
通过案例分析,展示 数学建模在解决实际 问题中的优势和作用 。
案例分析概述
案例选择
选取具有代表性的案例,涉及不同领域和数 据类型,以便全面展示数学建模在SPSS中 的应用。
分析方法
采用数学建模方法,如回归分析、聚类分析、因子 分析等,对案例数据进行深入挖掘和分析。
结果展示
通过图表、表格等形式展示分析结果,直观 呈现数学建模在SPSS中的应用效果。
输标02入题
同时,可以深入研究数学建模和SPSS统计分析在大数 据处理和分析中的应用,以应对日益增长的数据量和 复杂性。
01
03
最终,我们希望通过不断的研究和实践,推动数学建 模和SPSS统计分析的进一步发展,为社会进步和科技
发展做出更大的贡献。
04
此外,还可以关注数学建模和SPSS统计分析在人工智 能、机器学习等新兴技术中的应用,探索其在智能化 决策和自动化处理中的潜力。
SPSS软件与应用-数学建模用

绘制直方图
• 统计指标只能给出数据的大致情况,没有 直方图那样直观,我们就来画个直方图瞧 瞧!选择Graphs==>Histogram
进行统计分析
• 用SPSS来做成组设计两样本均数比较的t检 验,选择Analyze==>Compare Means==>Independent-Samples T test
Means过程
• • • • • • • 界面说明 【Dependent List框】 用于选入需要分析的变量。 【Independent List框】 用于选入分组变量。 【Options钮】 弹出Options对话框,选择需要计算的描述 统计量和统计分析:
• Statistics框 可选的描述统计量。它们是: • 1.sum,number of cases 总和,记录数 • 2.mean, geometric mean, harmonic mean 均数,几何均 数,修正均数 • 3.standard deviation,variance,standard error of the mean 标准差,均数的标准误, 方差 • 4.median, grouped median 中位数,频数表资料中位数 (比如30岁组有5人,40岁组有6人,则在计算grouped median时均按组中值35和45进行计算)。 • 5.minimum,maximum,range 最小值,最大值,全距 • 6.kurtosis, standard error of kurtosis 峰度系数,峰度系数 的标准误 • 7.skewness, standard error of skewness 偏度系数,偏度 系数的标准误 • 8.percentage of total sum, percentage of total N 总和的 百分比,样本例数的百分比
2-统计分析与SPSS应用-数学建模

(1)定性变量。 (2)定序变量。 (3)定距变量。
列格式、对齐、测度方式
返回
2.1.2 变量定义信息的复制
如果有多个变量的类型相同,可以先定义 一个变量,然后把该变量的定义信息复制给新 变量。
2.2 数据的输入与保存 2.2.1 录入数据的一般方法
定义了所有变量后,单击“Data View” 标签,即可在出现的数据视图(编辑)窗中输 入数据。 数据录入时可以逐行录入,也可以逐列。
8.变量的显示宽度(Columns)
输入变量的显示宽度,默认为8。
9.变量显示的对齐方式(Align)
选择变量值显示时的对齐方式:Left(左 对齐)、Right(右对齐)、Center(居中对 齐)。默认是右对齐。
10.变量的测量尺度(Measure)
变量按测量精度可以分为定性变量、定序 变量、定距变量几种。
3.变量长度(Width)
设置变量的长度,当变量为日期型时无效。
4.变量小数点位数(Decimal)
设置变量的小数点位数,当变量为日期型 时无效。
5.变量标签(Label)
变量标签是对变量名的进一步描述,变量 只能由不超过8个字符组成,而8个字符经常不 足以表示变量的含义。而变量标签可长达120 个字符,变量标签可显示大小写,需要时可用 变量标签对变量名的含义加以解释。
实现数据文件的横向连接,必须有一个相 同的公共变量,这个变量是两个数据文件横向 对应连接的依据。 在合并的两个数据文件中,数据含义不同 的变量,变量名不应取相同的名称。
图2-42 数据文件横向合并窗口
2.6 读入其他格式文件数据
在前面的数据保存中,已经讲到SPSS数据 文件可以保存成其他格式的文件,如文本文件、 dbf文件等。反过来,SPSS是否可以直接读取 其他格式数据文件呢?答案是肯定的。SPSS可 以读取文本文件、数据库文件等内容。
运用spss软件解决数学建模 楼盘的分类问题 论文 附有答案
楼盘的分类问题摘要本文结合统计学和因子分析学,对给出的楼盘指标信息进行系统聚类分析,利用spss 、excel软件求解,得出楼盘分类类别、物业分类因素排名。
问题一:对表1的数据进行统计分析,建立了系统聚类分析模型,对楼盘进行了分类。
由于各因素的量纲不同,对其量纲化统一处理。
最终得到楼盘的物业标值进行了比较,根据其特征贡献率的不同,判断其影响程度的大小。
贡献率越高,影响越大。
在11个指标中,某些指标对物业类别的分类影响甚微,以至产生干扰,因此我们可以筛选某些变量,先筛选的变量影响最小,然后从小到大依次排序,得出各种楼盘影响因素的顺序。
以普通住宅为例,得到结果如下:均价、原装修、车位、配套、总套数、绿化率、物业费、户型、位置、总占地、物状。
本模型具有较强的适用性和普遍性,可以为决策者提供多种决策方案,具有较强的实用价值。
关键字:系统聚类分析 SPSS软件主成分分析法欧式距离特征值累积贡献率一、问题的背景21 世纪是世界城市化高度发展的世纪。
据联合国人居中心预测,2010年将达到55% ,2025 年达到65% ,其中发达国家将达到83% 。
发展中国家将达到61%。
我国目前的城市化水平约在30% 左右,不仅远落后于发达国家,也落后于发展中国家的平均水平,滞后于相对社会经济发展,需要迅速加以提高。
随着我国城市化进程的加快,人们在城市购房自然成为人人所关心的头等大事,那么我们就必要了解房产情况;面对眼花缭乱的楼盘信息,如何根据自己的实际情况,选择属于自己的物业呢?针对人们的需求,开发商该如何投资建设,又该考虑建哪些物业及关于楼盘该如何定价呢?解决这类问题是有很大的现实意义的。
二、问题的提出与重述根据商品房个性化,一般可以将商品房自高至低划分为6种物业类别,分别为:别墅、甲级公寓、公寓、甲级住宅、普通住宅、经济适用房。
现得到某城市一届房交会数据(见附表1),我们就此信息将解决以下问题: (1)给出表1各楼盘的物业类别;(2)关于该城市楼盘各物业类别,找出影响各物业类别的主要因素(或因素顺序);三、基本假设(1) 在人为的推测和软件的基础之上考虑,会出现许多的误差,假设误差极小。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1.偏度(skewness)
g1 0,则可以认为分布是对称的;若g1>0,则认为分布有右偏态;若g1<0,认为分布有左偏态
2.峰度(kurtosis)
它以正态分布为标准,比较两侧极端数据分布的情况。
对于正态分布有g2=0;若g2>0,表示数据中有较多远离均值的极端数据;若g2<0,则均值两侧极端数据较少。
1命令位置:分析\描述统计\频率(Frequencis)\统计量(Statistics)
适合求分位点,一般情况下是首选命令
2.分析\描述统计\描述统计(Descriptive)
此命令可以完成数据的标准化,并把结果以变量的形式存放在数据文件上
Z分数一般小数可以先行转化为T分数
操作:转换(transform)→计算变量
是否服从正态分布
方法:
⏹定性方法
⏹观察偏度和峰度
⏹画直方图
⏹QQ图:散点基本在直线上,可以认为服从正态分布
⏹可靠方法:单样本KS检验
操作:图形->旧对话框
3.假设检验的步骤
提出原假设(零假设)H0;
确定适当的检验统计量;
计算检验统计量的值发生的概率(P值);
给定显著性水平a;
作出统计决策。
注:
必须搞清楚原假设(零假设)是什么
应该知道检验所用统计量服从什么分布
会根据软件求得的p值(sig.),作出判断
即:p<0.05,拒绝原假设;
P>0.05, 接受原假设.
4.单样本KS检验法:单样本KS检验-非参方法
操作:分析――>非参数检验――>旧对话框
5.列联表分析:判明所考察的各属性之间有无关联,即是否独立。
(利用交叉表分析)
转化为一个假设检验问题,构造检验统计量卡方
1)设置权重变量!
数据\加权个案
操作:分析->描述统计->交叉表->统计量->卡方
6.1均值比较
单样本t检验:目的:检验单个变量的均值是否与给定的常数(总体均值)之间是否存在显著差异。
要求样本来自的总体服从或近似服从正态分布。
H0:总体均值和指定检验值之间不存在显著差异。
⏹两独立样本t检验:目的:利用来自两个总体的独立样本,推断两个总体的均值是否存在显著
性差异;样本来自的总体服从或近似服从正态分布,H0:两总体均值之间不存在显著差异
Analyze――>compare――>independent-sample t test――>
两配对样本t检验:根据样本数据对样本来自的两配对总体的均值是否有显著性差异进行推断。
要求:1.两个样本应是配对的,首先两个样本的观察数目相同,其次两样本的观察值顺序不能随意改变。
2.样本来自的两个总体应服从正态分布。
操作:操作到pared-samples t test 对话框paiedvariables
7。
方差分析(NAOV A):用于两个及两个以上样本均数差别的显著性检验。
方差分析中的有关术语
1. 因素或因子(factor)
所要检验的对象
要分析颜色对销量是否有影响,颜色是要检验的因素或因子
2. 水平或处理(treatment)
因子的不同表现
如,四种颜色就是因子的水平
3. 观察值
在每个因素水平下得到的样本值
每种颜色的销量就是观察值
7.1单因素方差分析
•前提的检验:各水平下方差齐性检验
•实现方法:option中的statistics:Homogeneity-of-variance——检验各水平下各总体方差是否齐性.
1单因素方差分析中的多重比较:目的:多重比较将对每个水平的均值逐对进行比较检验.
2几种常用的多重比较方法
1.LSD(Least significant Difference)最小显著性差异法
2.特点:
利用了全部样本数据,而不仅是所比较的两组的数据,且认为各水平均是等方差的
与其他方法相比,其检验敏感度最高
在一定程度上克服了放大犯一类错误的问题
2. S-N-K法:运用最广泛的一种两两比较方法,采用student range分布进行所各组的组间均值的配对比较控制了一类错误post hoc选项
如果事先无法判断方差是否具有齐性,可以考虑都选上,从结果中选择应用。
Lsd法,tukey法,scheffe法,tamhane‘s t2法
1单因素方差分析步骤:分析――>比较均值――>单因素ANOV A (选项一定选方差同质性检验)
多重比较方差分析的步骤:(选两两比较中lsd选项和S-N-K)
8.相关分析与回归
8.1相关分析:0<r≤1,正。
−1≤r<0,负|r|=1,两者函数关系。
|r|>=0.8时,视为高度相关,0.5<=|r|<=0.8,中度相关。
0.3<=|r|<=0.5时,视为低度相关。
|r|<0.3时,视为不相关。
在二元变量的相关分析过程中比较常用的几个相关系数是
Pearson简单相关系数、用来衡量定距变量间的线性关系
Spearman
Kendall's tua-b等级相关系数。
Spss中的实现过程:先画散点图再做相关分析
8.2 回归分析
• 1 回归分析概述
• 2 线性回归分析
1确定回归方程中的解释变量(自变量)和被解释变量(因变量)2确定回归方程3对回归方程
进行各种检验4利用回归方程进行预测。
2.3 线性回归方程的统计检验,
一、回归方程的拟合优度
2、可决系数(判定系数、决定系数)
R 称为复相关系数(恰好是Pearson 相关系数的绝对值), R 或R 2是一个从直观
上判断回归方程拟合好坏的尺度,有0≤R ≤1,显然R 值越大,回归方程拟合越好。
一元—R 2 多元—调整的R 2
多元回归
● 二、回归方程的显著性检验(F 检验)多元回归f 检验~p 1F n p --(,)
利用方差分析F 检验,H0: β1=β2=…=βk =0H0: β1=β2=…=βk =0,(意:回归方程不显著)
● 三、回归系数的显著性检验(t 检验)
t 检验,(微观分析)
H0:βj =0(即变量X j 不显著) H1:βj ≠ 0
以上属于回归分析基本检验;
另有进一步检验:
如多元回归中的残差分析、多重共线性
检验等,待续…
● 四、残差分析
1残差分析包括以下内容:
2残差服从均值为零的正态分布(正态检验诊断)
3残差方差相等(方差齐性诊断)
4残差不存在自相关(残差独立性诊断)
5探测样本中的异常值(自学)
注:对于残差均值和方差齐性检验可以利用残差图进行分析。
1.残差均值为零的正态性诊断
残差的正态性诊断可以通过直方图和P -P 正态概率图来实现,当P -P 图基本成一直线时,
正态性诊断通过。
2.残差的方差齐性诊断
通过分析标准化预测值(X 轴)——学生化残差(Y 轴)散点图来实现。
当图中各点分布没有明显的规律性,即残差的分布不随预测值的变化而增大或减小时,(或图中各点在纵轴零点对应的直线下基本均匀分布),因此可以认为方差齐性的假设成立。
3、残差独立性诊断-常用DW 检验
DW=2表示无自相关,在0-2之间说明存在正自相关,在2-4之间说明存在负的自相关。
一般情况下,DW 值在1.5-2.5之间即可说明无自相关现象。
五、多元回归分析的解释变量筛选问题
变量的筛选一般有向前筛选、向后筛选、逐步筛选三种基本策略。
在对话框Linear Regession 分别是 Forward ,Backword 和Stepwise 三种方法
六、多元回归分析的多重共线性分析
1容忍度:容忍度的取值范围在0-1之间,越接近0表示多重共线性越强,越接近1表示多重共线性越弱。
2方差膨胀因子VIF ;方差膨胀因子是容忍度的倒数。
VIF 越大多重共线性越强,当VIF 大于等于10时,说明存在严重的多重共线性。
● 五、多重共线性
• 3 曲线估计
回归分析小结。