kernel(核函数学习)
kernel密度法

kernel密度法(原创版)目录1.介绍 Kernel 密度估计法2.Kernel 密度法的原理3.Kernel 密度法的应用4.Kernel 密度法的优缺点正文一、介绍 Kernel 密度估计法Kernel 密度估计法是一种常用的非参数统计方法,用于估计连续型随机变量的概率密度函数。
该方法通过核函数将数据映射到高维空间,在高维空间中计算密度,再将密度映射回原空间。
Kernel 密度估计法具有较强的理论性质和实用性。
二、Kernel 密度法的原理Kernel 密度法的基本思想是利用核函数将原始数据映射到高维空间,然后使用高维空间中的数据计算密度。
核函数的选择和带宽的确定是Kernel 密度估计法的关键。
1.核函数:核函数是一种对称的函数,将原始数据映射到高维空间。
常用的核函数有高斯核、线性核、多项式核等。
2.带宽:带宽是核函数中的重要参数,决定了核函数的形状。
带宽越小,核函数越尖锐,估计的密度函数越接近真实密度函数;带宽越大,核函数越平缓,估计的密度函数越平滑。
三、Kernel 密度法的应用Kernel 密度法广泛应用于数据分析、信号处理、模式识别等领域,具有重要的实际意义。
1.数据分析:Kernel 密度法可以用于分析数据的分布特征,如均值、方差等。
2.信号处理:Kernel 密度法可以用于信号的滤波、去噪等。
3.模式识别:Kernel 密度法可以用于图像识别、语音识别等领域。
四、Kernel 密度法的优缺点1.优点:Kernel 密度法具有较强的理论性质,可以估计任意形状的密度函数;同时,Kernel 密度法具有较好的鲁棒性,能够处理含有异常值的数据。
机器学习算法调参技巧解读

机器学习算法调参技巧解读机器学习算法调参是提高模型性能的关键一步。
通过合理地调整算法的参数,可以使得模型更准确地对数据进行拟合,从而提高预测精度和泛化能力。
在本文中,我们将以逻辑回归和支持向量机为例,探讨机器学习算法调参的技巧和方法。
一、逻辑回归算法调参技巧解读逻辑回归是一种广泛应用于分类问题的机器学习算法。
在调参过程中,我们通常会关注以下几个参数:正则化参数lambda、学习率alpha 以及迭代次数iterations。
1. 正则化参数lambda正则化参数lambda的作用是缓解模型的过拟合问题。
过低的lambda值会导致模型在训练集上过拟合,而过高的lambda值则会导致欠拟合。
因此,我们可以通过交叉验证的方法来选择最合适的lambda 值。
2. 学习率alpha学习率alpha决定了每次参数更新的步长。
过大的学习率可能导致无法收敛,而过小的学习率则会导致收敛速度过慢。
在调参过程中,我们可以通过尝试不同的学习率来找到最合适的取值。
3. 迭代次数iterations迭代次数iterations指的是训练数据的遍历次数。
当迭代次数太少时,模型可能没有充分学习到数据的规律;而当迭代次数太多时,可能会导致过拟合。
因此,在调参过程中,我们可以通过观察模型在训练集和验证集上的表现来选择合适的迭代次数。
二、支持向量机算法调参技巧解读支持向量机是一种常用于分类和回归问题的机器学习算法。
在调参过程中,重要的参数包括:核函数类型kernel、正则化参数C以及gamma。
1. 核函数类型kernel核函数用于将低维数据映射到高维空间中,从而使数据更容易分类。
常见的核函数包括线性核函数、多项式核函数和高斯核函数等。
在实际调参中,我们可以通过对比不同核函数的表现来选择最适合的类型。
2. 正则化参数C正则化参数C控制着模型对误分类样本的惩罚程度。
较小的C值会使模型更加关注少数类别的分类准确性,而较大的C值则会平衡所有类别。
Kernel Method 核回归 核方法

15
i =1
局部线性回归
ˆ E ( r ( x0 ) ) = ∑wi ( x0 ) r ( xi )
n
r ( xi ) ≈ r ( x0 ) + r′ ( x0 )( xi − x0 ) +
r′′( x0 ) 2 xi − x0 ) ( 2
局部线性回归通过自动修改核,将偏差降至一阶
≈ r ( x0 ) ∑wi ( x0 ) + r′ ( x0 ) ∑( xi − x0 ) wi ( x0 )
r′′ ( x0 ) 2 + ∑( xi − x0 ) wi ( x0 ) 2 i=1
局部线性回归:在每一个将要被预测的点x 处解一个单独的加权最小二乘问题,找到使 下述表达式最小的 β ( x)
∑K ( x, x ) y − x β ( x)
i =1 h i i i
n
2
13
局部线性回归
Y = sin ( X ) + ε , X ~ Uniform[0,1] , ε ~ N ( 0,1 3)
G =φ ( X) (φ ( X) ) , Gij = φ ( xi ) ,φ ( x j ) = K( xi , x j )
T
利用核函数计算内积
27
另一种对偶表示推导方式
线性岭回归最小化:
p p n 2 yi − r ( xi ) ) + λ∑β j2 , r ( xi ) = ∑xij β j ∑( j =1 j=1 i=1
= ∫∫ Kh ( x, u) yf ( y | u) f ( u) dydu
cuda 核函数使用

cuda 核函数使用在 CUDA 编程中,核函数(kernel function)是在 GPU 上执行的函数,用于并行计算。
以下是 CUDA 核函数的基本使用方式:定义核函数:核函数是一个在 GPU 上并行执行的函数,通常使用 __global__ 修饰符声明。
函数的参数表示线程的索引和数据。
以下是一个简单的核函数示例:__global__ void myKernel(int* input, int* output, int size) {int tid = blockIdx.x * blockDim.x + threadIdx.x;if (tid < size) {output[tid] = input[tid] * 2;}}启动核函数:在主机代码中,使用 CUDA 的启动语法来启动核函数。
以下是一个使用核函数的示例:cppCopy codeint main() {// 分配和初始化数据int size = 1000;int* hostInput = new int[size];int* hostOutput = new int[size];// 在 GPU 上分配内存int* deviceInput;int* deviceOutput;cudaMalloc((void**)&deviceInput, size * sizeof(int));cudaMalloc((void**)&deviceOutput, size * sizeof(int));// 将数据从主机复制到设备cudaMemcpy(deviceInput, hostInput, size * sizeof(int), cudaMemcpyHostToDevice);// 定义启动核函数的网格和线程块大小int blockSize = 256;int gridSize = (size + blockSize - 1) / blockSize;// 启动核函数myKernel<<<gridSize, blockSize>>>(deviceInput, deviceOutput, size);// 将结果从设备复制回主机cudaMemcpy(hostOutput, deviceOutput, size * sizeof(int), cudaMemcpyDeviceToHost);// 清理内存delete[] hostInput;delete[] hostOutput;cudaFree(deviceInput);cudaFree(deviceOutput);return 0;}核函数调用的语法:使用 <<<...>>> 语法来指定执行核函数的网格和线程块大小。
核函数

核函数摘要根据模式识别理论,低维空间线性不可分的模式通过非线性映射到高维特征空间则可能实现线性可分,但是如果直接采用这种技术在高维空间进行分类或回归,则存在确定非线性映射函数的形式和参数、特征空间维数等问题,而最大的障碍则是在高维特征空间运算时存在的“维数灾难”。
采用核函数技术可以有效地解决这样问题。
本文详细的介绍了几种核函数:多项式空间和多项式核函数,Mercer 核,正定核以及核函数的构造关键词:模式识别理论,核函数0引言核方法是解决非线性模式分析问题的一种有效途径,其核心思想是:首先,通过某种非线性映射将原始数据嵌入到合适的高维特征空间;然后,利用通用的线性学习器在这个新的空间中分析和处理模式。
相对于使用通用非线性学习器直接在原始数据上进行分析的范式,核方法有明显的优势:首先,通用非线性学习器不便反应具体应用问题的特性,而核方法的非线性映射由于面向具体应用问题设计而便于集成问题相关的先验知识。
再者,线性学习器相对于非线性学习器有更好的过拟合控制从而可以更好地保证泛化性能。
还有,很重要的一点是核方法还是实现高效计算的途径,它能利用核函数将非线性映射隐含在线性学习器中进行同步计算,使得计算复杂度与高维特征空间的维数无关。
核函数理论不是源于支持向量机的。
它只是在线性不可分数据条件下实现支持向量方法的一种手段.这在数学中是个古老的命题。
Mercer定理可以追溯到1909年,再生核希尔伯特空间(ReproducingKernel Hilbert Space, RKHS)研究是在20世纪40年代开始的。
早在1964年Aizermann等在势函数方法的研究中就将该技术引入到机器学习领域,但是直到1992年Vapnik等利用该技术成功地将线性SVMs推广到非线性SVMs时其潜力才得以充分挖掘。
核函数方法是通过一个特征映射可以将输入空间(低维的)中的线性不可分数据映射成高维特征空间中(再生核Hilbert空间)中的线性可分数据.这样就可以在特征空间使用SVM方法了.因为使用svm方法得到的学习机器只涉及特征空间中的内积,而内积又可以通过某个核函数(所谓Mercer 核)来表示,因此我们可以利用核函数来表示最终的学习机器.这就是所谓的核方法。
本书介绍了核方法Kernel记得上高等数理统计
本书第六章介绍了核方法(Kernel)。
记得上高等数理统计的时候,老师布置过关于核方法的一片小论文作业,只不过当时并没有重视,作业也是应付了事。
这两天读了这一章,觉得核方法是一种非常重要的工具。
当然,这一章中也有众多地方读不懂,慢慢继续读吧。
下面写点读书笔记和心得。
6.1节,先从最基本的一维核平滑说起。
所谓的平滑,我觉得可以这样理解。
对于一维变量及其相应,可以在二维空间中画一个散点图。
如果利用插值,将点连接起来,那么连线可能是曲折不平的。
所谓的平滑,就是用某种手段使得连线变得平滑光滑一点。
那么手段可以有多种,比如第五章介绍的样条平滑,是利用了正则化的方法,使得连线达到高阶可微,从而看起来比较光滑。
而本章要介绍的核方法,则是利用核,给近邻中的不同点,按照其离目标点的距离远近赋以不同的权重,从而达到平滑的效果。
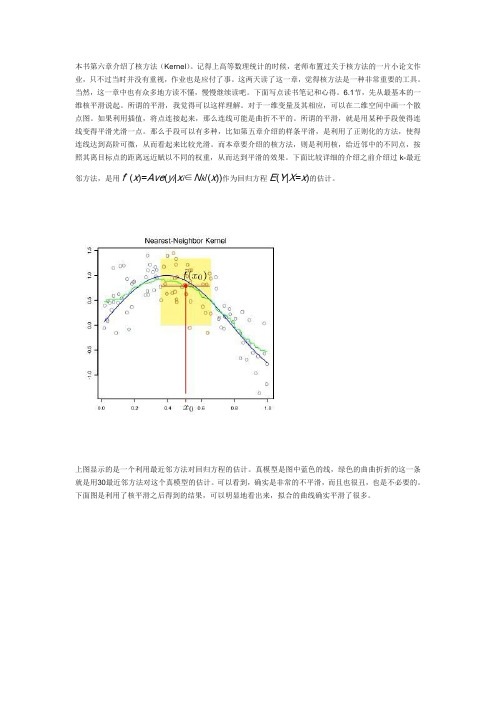
下面比较详细的介绍之前介绍过k-最近邻方法,是用fˆ(x)=Ave(y i|x i∈N k/(x))作为回归方程E(Y|X=x)的估计。
上图显示的是一个利用最近邻方法对回归方程的估计。
真模型是图中蓝色的线,绿色的曲曲折折的这一条就是用30最近邻方法对这个真模型的估计。
可以看到,确实是非常的不平滑,而且也很丑,也是不必要的。
下面图是利用了核平滑之后得到的结果,可以明显地看出来,拟合的曲线确实平滑了很多。
上面仅仅是一个核平滑的例子。
下面给出一维核平滑的一些具体的公式fˆ(x0)=∑Ni=1Kλ(x0,xi)yi∑Ni=1Kλ(x0,xi)这个就是利用核平滑对x0点的真实值的估计,可以看出,这其实是一个加权平均,相比起最近邻方法,这里的特殊的地方就是权重Kλ(x0,x)。
这个权重就称为核。
核函数有很多种,常用的包括Epanechnikov quadratic 核:Kλ(x0,x)=D(x−x0λ) with D(t)=34(1−t2),|t|<1这个图就是D(t)的图像,可以看出,随着离目标点的距离越来越远,所附加的权重也是平滑的越来越小。
核函数(kernelfunction)

核函数(kernelfunction)在接触反演、算法等⽅⾯的知识后,经常听到“核”这个字,它不像对原始变量的线性变换,也不像类似于机器学习中激活函数那样的⾮线性变换,对原始数据进⾏变换,就可以将复杂的问题简单化。
接下来,就让我们了解了解“核”这个东西。
参考链接:注,kernel function 与kernel function指的是同⼀个东西,可以这样理解:核⽅法只是⼀种处理问题的技巧,低维空间线性不可分可以在⾼维空间线性可分,但是⾼维空间的计算复杂度⼜很⼤,那么我们就把⾼维空间的计算通过低维空间的计算外加⼀些线性变换来完成。
还有,都说核⽅法与映射⽆关,怎么理解呢?核⽅法是⼀种技巧,不管怎么映射,我们都是⽤低维空间的计算来解决⾼维空间计算复杂的问题。
1. 问题描述给定两个向量(x_i)和(x_j),我们的⽬标是要计算他们的内积\(I\) = <\(x_i\), \(x_j\)>。
现在假设我们通过某种⾮线性变换:\(\Phi : x \rightarrow \phi(x)\)把他们映射到某⼀个⾼维空间中去,那么映射后的向量就变成:\(\phi(x_i)\)和\(\phi(x_j)\),映射后的内积就变成:\(I’\) = <\(\phi(x_j)\),\ (\phi(x_j)\)>。
现在该如何计算映射后的内积呢?传统⽅法是先计算映射后的向量\(\phi(x_i)\)和\(\phi(x_j)\),然后再计算它俩的内积。
但是这样做计算很复杂,因为映射到⾼维空间后的数据维度很⾼。
⽐如,假设\(x_i\)和\(x_j\)在映射之后都是⼀个( \(1 \times 10000\))维的向量,那么他们的内积计算就需要做10000次加法操作和10000次乘法操作,显然复杂度很⾼。
于是,数学家们就想出⼀个办法:能不能在原始空间找到⼀个函数\(K(x_i,x_j)\)使得\(K(x_i,x_j) = <\phi(x_j),\phi(x_j)>\)呢?如果这个函数存在,那么我们只需要在低维空间⾥计算函数\(K(x_i,x_j)\)的值即可,⽽不需要先把数据映射到⾼维空间,再通过复杂的计算求解映射后的内积了。
支持向量机(四)--核函数

⽀持向量机(四)--核函数⼀、核函数的引⼊问题1:SVM 显然是线性分类器。
但数据假设根本就线性不可分怎么办?解决⽅式1:数据在原始空间(称为输⼊空间)线性不可分。
可是映射到⾼维空间(称为特征空间)后⾮常可能就线性可分了。
问题2:映射到⾼维空间同⼀时候带来⼀个问题:在⾼维空间上求解⼀个带约束的优化问题显然⽐在低维空间上计算量要⼤得多,这就是所谓的“维数灾难”。
解决⽅式2:于是就引⼊了“核函数”。
核函数的价值在于它尽管也是讲特征进⾏从低维到⾼维的转换。
⼆、实例说明⽐如图中的两类数据,分别分布为两个圆圈的形状,不论是不论什么⾼级的分类器,仅仅要它是线性的。
就没法处理。
SVM 也不⾏。
由于这种数据本⾝就是线性不可分的。
从上图我们能够看出⼀个理想的分界应该是⼀个“圆圈”⽽不是⼀条线(超平⾯)。
假设⽤ 和 来表⽰这个⼆维平⾯的两个坐标的话,我们知道⼀条⼆次曲线(圆圈是⼆次曲线的⼀种特殊情况)的⽅程能够写作这种形式:注意上⾯的形式,假设我们构造另外⼀个五维的空间,当中五个坐标的值分别为 , , , , ,那么显然。
上⾯的⽅程在新的坐标系下能够写作:关于新的坐标 。
这正是⼀个超平⾯ 的⽅程!也就是说,假设我们做⼀个映射 。
将 依照上⾯的规则映射为 ,那么在新的空间中原来的数据将变成线性可分的,从⽽使⽤之前我们推导的线性分类算法就能够进⾏处理了。
这正是 Kernel ⽅法处理⾮线性问题的基本思想。
三、具体分析还记得之前我们⽤内积这⾥是⼆维模型,可是如今我们须要三维或者更⾼的维度来表⽰样本。
这⾥我们如果是维度是三。
那么⾸先须要将特征x 扩展到三维,然后寻找特征和结果之间的模型。
我们将这样的特征变换称作特征映射(feature mapping )。
映射函数称作,在这个样例中我们希望将得到的特征映射后的特征应⽤于SVM 分类,⽽不是最初的特征。
这样,我们须要将前⾯公式中的内积从,映射到。
为什么须要映射后的特征⽽不是最初的特征来參与计算,⼀个重要原因是例⼦可能存在线性不可分的情况,⽽将特征映射到⾼维空间后,往往就可分了。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2015/12/12
上海交通大学计算机系
Kernelized-KMeans
K-Means聚类
Kernelized-KMeans
Kernelized-KMeans聚类方法
解决方法二: Kernelized K-medoids clustering
上海交通大学计算机系
核方法思想
核方法的主要思想是基于这样一个假设:在低维空间中不能线性分
割的点集,通过转化为高维空间中的点集时,很有可能变为线性可 分的。 核方法是解决非线性模式分析的一种有效途径。
2015/12/12
上海交通大学计算机系
核方法思想
Linear kernels
2015/12/12
2015/12/12
上海交通大学计算机系
SVMs
(3)
2015/12/12
上海交通大学计算机系
上海交通大学计算机系
Kernelized-KMeans
Code:
for row in rows: #input: point, rows, offset if bel==0: sum0 += Kernel(point, row.data) count0 += 1 else: sum1 += Kernel(point, row.data) count1 += 1 output = (1.0/count0)*sum0 - (1.0/count1)*sum1 + offset if output < 0: return 0 else: return 1
基于核方法的算法设计。它为处理许多问题提供 了统一框架。 核方法的核心在于概念转换(映射),即如何利 用距离关系将笛卡儿积空间映射到实数域线性空 间,而且还能很好的体现原空间上存在的关系。
2015/12/12
上海交通大学计算机系
提纲
1、核方法思想 2、核技巧(Kernel Trick) 3、核函数的分类 4、核函数的存在性和构造 5、Kernelized-KMeans, SVMs
核技巧(Kernel Trick )
2015/12/12
上海交通大学计算机系
核技巧(Kernel Trick )
核函数-内积
2015/12/12
上海交通大学计算机系
常见核函数
2015/12/12
上海交通大学计算机系
常见核函数
2015/12/12
上海交通大学计算机系
核函数的存在性
Mercer 定理:
上海交通大学计算机系
核方法思想
Kernels for comparing documents
2015/12/12
上海交通大学计算机系
核方法思想
String kernels
2015/12/12
上海交通大学计算机系
核技巧(Kernel Trick )
2015/12/12
上海交通大学计算机系
核方法
2015/12/12
上海交通大学计算机系
核函数的定义
2015/12/12
上海交通大学计算机系
核函数的定义
2015/12/12
上海交通大学计算机系
核函数的定义
2015/12/12
上海交通大学计算机系
核函数的定义
2015/12/12
上海交通大学计算机系
Kernel Smoothing
2015/12/12
上海交通大学计算机系
Kernel Smoothing
2015/12/12
上海交通大学计算机系
Kernel Smoothing
2015/12/12
上海交通大学计算机系
Kernel Smoothing
2015/12/12
上海交通大学计算机系
总结
核方法是一种模块化的方法,分为核函数设计和