实验报告3—— SAS描述统计分析
SAS软件实验二单描述统计分析
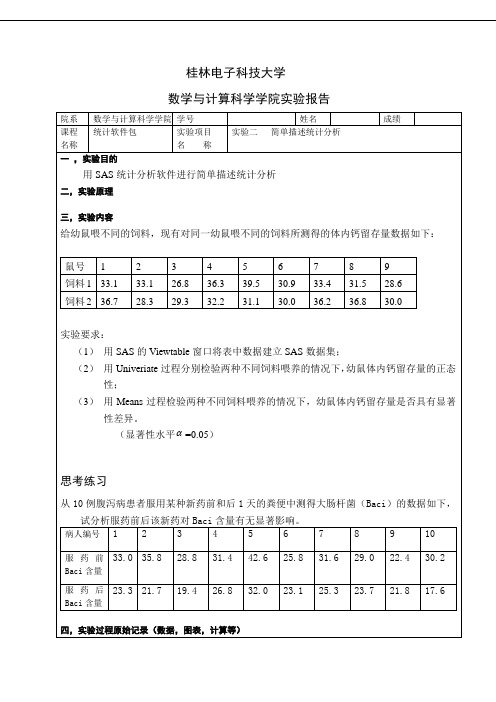
思考练习
data shiyan2; input x1 x2; diff=x1-x2; cards; 33 23.3 35.8 28.8 31.4 42.6 25.8 31.6 29 22.4 30.2 ; proc univariate data=shiyan2 normal ; var diff; run; 21.7 19.4 26.8 32 23.1 25.3 23.7 21.8 17.6
饲料 1 33.1 饲料 2 36.7 实验要求:
(1) 用 SAS 的 Viewtable 窗口将表中数据建立 SAS 数据集; (2) 用 Univeriate 过程分别检验两种不同饲料喂养的情况下, 幼鼠体内钙留存量的正态 性; (3) 用 Means 过程检验两种不同饲料喂养的情况下,幼鼠体内钙留存量是否具有显著 性差异。 (显著性水平 =0.05)
结果分析:
由 Shapiro-Wilk 检验中 p= 0.8944>0.05 知不拒绝原假设,认为差量 diff 服从正态分布; 进而由 t 检验中 p= 0.0004<0.05 知拒绝原假设,认为差量均值显著不为 0, 这说明: 服药前后该新药对 Baci 含量有显著影响。
五,实验结果分析或总结
通过这次实验,我学会了用 SAS 统计分析软件进行简单描述统计分析;学会了做正态性检 验。
思考练习
从 10 例腹泻病患者服用某种新药前和后 1 天的粪便中测得大肠杆菌(Baci)的数据如下, 试分析服药前后该新药对 Baci 含量有无显著影响。 病人编号 1 2 3 4 5 6
SAS数据的描述性统计分析答案

实验一数据的描述性统计分析一、选择题1、以下( B )语句对变量进行分组,在使用前需按分组变量进行排序?以下( C )语句可对变量进行分类,在使用前不必按分类变量进行排序?用( A )语句可以选择输入数据集的一个行子集来进行分析?(A)WHERE语句(B)BY语句(C)CLASS语句(D)FREQ语句2、排序过程步中必须用什么语句对变量进行排序?( A )(A)BY语句(B)CLASS语句(C)WHERE语句3、如果要对数据集中的数据进行正态性检验,需要使用哪个过程?( B )(A)MEANS (B)UNIV ARIATE (C)FREQ4、用UNIV ARIATE过程进行数据分析,要求此过程输出茎叶图、正态概率图等,应在语句中加上什么选项?(plot )5、用UNIV ARIATE过程进行数据分析,在输出结果中哪个统计量是对样本均值为零的T检验的概率值?( A )(A)T: Mean (B)Prob>|S| (C)Sgn Rank (D)Prob>|T|二、假设某校100名女生的血清总蛋白含量(g/L)服从均值为75,标准差为3的正态分布,试产生样本数据,并利用SAS软件解决下面问题:1、计算样本均值、方差、标准差、极差、四分位极差、变异系数、偏度、峰度;2、画出直方图(垂直条形图);3、画出茎叶图、盒形图和正态概率图;4、试进行正态性检验。
Data N;DO i=1to100;x=75+3*normal(12345);output;end;proc print;run;proc univariate data=N;var x;run;proc gchart data=N;block x;run;proc univariate data=N plot;var x;run;proc univariate data=N normal;var x;run;三、某校测得20名学生的四项指标:性别、年龄、身高(CM)和体重(KG),具体数据如表1所示。
多元统计分析实验报告,计算协方差矩阵,相关矩阵,SAS

院系:数学与统计学学院专业:__统计学年级:2009 级课程名称:统计分析 ____学号:____________姓名:_________________指导教师:____________2012年4月28日(一)实验名称1. 编程计算样本协方差矩阵和相关系数矩阵;2. 多元方差分析MANOVA。
(二)实验目的1. 学习编制sas程序计算样本协方差矩阵和相关系数矩阵;2. 对数据进行多元方差分析。
(三)实验数据第一题:第二题:(四)实验内容1. 打开SAS软件并导入数据;2. 编制程序计算样本协方差矩阵和相关系数矩阵;3. 编制sas程序对数据进行多元方差分析;4. 根据实验结果解决问题,并撰写实验报告;(五)实验体会(结论、评价与建议等)第一题:程序如下:proc corr data=sasuser.sha n cov;proc corr data=sasuser.sha n no simple cov;with x3 x4;partial x1 x2;run;结果如下:(1)协方差矩阵$AS亲坯曲;15 Friday, Apr: I SB,沙DOCOUR过程x4目由度=30Xi x2x3x4x5X?-10.I9B4944-0.45E2GJ5I.3347097-G.1193E48-£0.e75»GS-ID. 188494669,36&Q3?9-7.22IO&OS1J5692043I5.49ee^91S.Oa97SM-8.45S2645■7,221050829.S78&S46-6.372E47I-15.3084183-21.7352376-11.56747851.3841097 1.G5S2M7t.3726171IJ24«17B 4.e093011 4.4C124732.B747CM-G. I1S3S49 1.GS92043-is.soul aa 4.B09B01I68.7978495劣』S670971S.57ai1B3-IH.05l6l?a15.43S6569-J1.73S2376孔耶124TB27.0387097105.103225&S7.3505S7E:-2D K5752??319-11337204-1L55M7S52r9747?3i19,573118337.3S0&87E33.3SQ6452 (2) 相关系数矩阵Pearson相关系数” N =引当HO: Rho=0 时.Prob > |r|Xi Xixl1.QQ000x2-C.239540.2061x3-0,304590.0957x40.18975Q.3092x5'0.141570.4475x6-0.837870.0630-0.492920.0150x2-0.23354 1.00000-0.162750.143510.022700.181520.24438 x20.20C10.31:1?0.441?0.90350.32640.1761x3-0.30459-0.16275 1.00000-0.06219-0.34641-0.^797-0.23674 x30.095?0.381?<.00010.0563o.oses0 JS97x40.1S8760.14351-0.86219L000000.400540,313650.22610 x40.30920.4412<.0001 D.02EG Q.085S0.2213x5-0J 41570.02270-0.946410.40054 1.000000.317370.26750 x50.4J750.90350.0G68Q.025&0.08130+1620x6-0.33?e?0.1S162-0.397970.813650.31787LOOOOO0.82976 x60.0S300.32840.02660.08580.0813C0001辺-0.432920.24938-0.288740.22810 D.267600.92976 1.00000 x70,01500J7610.19970.22130JG20<.0001第二题:程序如下:proc anova data=sasuser.hua ng;class kind;model x1-x4=k ind;manova h=k ind;run;结果如下:(1)分组水平信息The ANNA ProcedureCla^s Level Informat ionClass Level®Valueskind 3 123Number of observatIons CO(2) x1、x2、x3、x4的方差分析Dependent Variable : xl xlSource DFSum of SquaresMea n Square F Value Pr > F Model 25221.30000 2610.650003.380.0411Error57 44069.55000773.15000Corrected Total 5949290.85000R-Square Coeff Var Rcot MSE xl Mean 0.10592832.3508727.8055785.95000Source DF Anova SS Mean Square F ValuePr > F kind25221.300000 2610.6500003.380.0411The ANOVA ProcsdureDependent Variable : x2 x2S UB ofSource DFSquares Mean Square F ValuePr > F Model 2 518.533333 259.26666?1.620.2078Error57 9148.050000160.492105Corrected Total 599666.583333R-Square Coeff Var Root MSE 0.05364222.9988812.6685555.08333Source DF Anova SS Mean Square F ValuePr > Fkind2518.5333333259.26666671.620.2078The ANOVA Procedure)epende 「t Variable : x:3 x3S UM ofSource DF Squares Mean SquareF Value Pr > FModel2 2480.8333 1240.41670.170.8478Error57 427028.50007491.7281Corrected Total 59429509.3333R-Square Coeff Var Root MSE x3 Mean0.00577621.1798088.55477408.66672480.8333331240.4166670.17 0.8478The ANOVA Procedurex2 Mean SourceAnova SS Mean Square F Value Pr > Fkind(3) 多元方差分析The ProcedureMulti var I ate Ana lysis of Vari sinceCharacteri st ic Roots and Vectors of :: E Inverse 水 H, whereH =舫ow SSCP Matrix for kindE = Error SSCP MatrixChareucteri st icRoot Percent Characteristic Vector V F EV=1x1 x2 x30.33804686 73J7 -0.00045795 -0.00379096 0.00090988 0.00279339 0.12323983 26,C3 0.00424111 0.00236878 0.00D01B42 0.00002832 0.00000000 0.00 0.00121062 -0.00032401 0.00157046 -0.00006539 0.000000000,00-0.003177880.010435260.000070140.00078872MANOVA Test Criteria and F ApproxI nat Ions for the Hypothesis of No Overall kind EffectH 二 Anova SSCP Matr ix for kindE = Error SSCP MatrixS=2M=0*5 N=26 Stat ist icVa 1 ueF Value Num DFDsn DF Pr > F Wilks' Lambda0*660359533.04 8 IDS 0.0040 Pi 1lai f s Trace0.36123585 3,03 e 110 0.0041 Hote11 ing-Law 1ey Trace Q.45927921 3.07 e 74.85G0.0048 Roy s Greatest Root 0.336045804.624550.0027NOTE : F Statistic for Roy's Greatest Root iis an upper boundsNOTE: F Statist ic f or Wilks' Lambdei is exact.根据多元分析结果,p 指小于0.05,表明在0.05的显著水平下,四个变量有 显著差异SourceDF Sum of Squares Mean iSouare F ValuePr > F Model239529,3000 192B4.8E0D 8.010.0009Error57 197115.10002405.5281Corrected Totiii59175644.4000R-SqusreGreff Vir Root M SE x4 Mean0.21936018.96604 49.04610 250.6000SourceDFA JWVI SSMean ^4j&re F V&luePr > F kind2 38529.3000019264.650008.010.0009The ANOVA ProcedureDependent Var iabls : x4 x4。
sas测量实验报告

sas测量实验报告SAS测量实验报告引言:SAS(Statistical Analysis System)是一种广泛应用于统计分析和数据管理的软件系统。
它提供了一系列强大的工具和功能,可以帮助研究人员进行数据处理、数据分析和数据可视化。
本文将介绍一项关于SAS测量的实验,旨在探索其在数据处理和分析方面的应用。
实验目的:本次实验的目的是通过使用SAS软件,对一组数据进行处理和分析,以验证其在实际应用中的效果和可行性。
同时,通过实验的过程,我们也可以进一步了解SAS在数据处理和分析中的优势和局限性。
实验步骤:1. 数据收集:首先,我们需要收集一组与实验目的相关的数据。
这些数据可以来自于实验观察、问卷调查或其他方式。
在本次实验中,我们选择了一个关于消费者购买行为的数据集。
2. 数据清洗:在数据收集后,我们需要对数据进行清洗,以去除无效或错误的数据。
SAS提供了一系列强大的数据处理功能,可以帮助我们进行数据清洗和转换。
例如,我们可以使用SAS的数据步骤(DATA Step)来删除重复的数据、填补缺失值或调整数据格式。
3. 数据分析:一旦数据清洗完成,我们可以开始进行数据分析。
SAS提供了多种统计分析方法,包括描述性统计、假设检验、回归分析等。
根据实验的具体目的,我们可以选择合适的分析方法,并使用SAS进行计算和结果展示。
4. 结果解释:在完成数据分析后,我们需要对分析结果进行解释和讨论。
通过SAS生成的统计报告和图表,我们可以直观地了解数据的分布、相关性和趋势等。
同时,我们还可以使用SAS的图形功能,绘制各种图表和图形,以更好地展示和解释数据分析结果。
实验结果:在本次实验中,我们使用SAS对一组消费者购买行为数据进行了处理和分析。
通过对数据的清洗和转换,我们得到了一个干净、完整的数据集。
然后,我们使用SAS的统计分析功能,对数据进行了描述性统计和相关性分析。
最后,我们使用SAS的回归分析功能,建立了一个购买行为预测模型,并对模型进行了评估。
多元统计分析实验报告计算协方差矩阵相关矩阵SAS

多元统计分析实验报告计算协方差矩阵相关矩阵SAS实验目的:通过对多元统计分析中的协方差矩阵和相关矩阵的计算,探究变量之间的相关性,并使用SAS进行实际操作。
实验步骤:1.数据准备:选择一个数据集,例如学生的成绩数据,包括数学成绩、语文成绩和英语成绩。
2.数据整理:将数据转化为矩阵形式,每一行代表一个学生,每一列代表一个变量(即成绩),记为X。
3. 计算协方差矩阵:根据公式计算协方差矩阵C,其中元素Cij表示变量Xi和Xj之间的协方差。
计算公式为Cij = cov(Xi, Xj) = E((Xi - u_i)(Xj - u_j)),其中E为期望值,u_i和u_j分别是变量Xi和Xj的均值。
4. 计算相关矩阵:根据协方差矩阵计算相关矩阵R,其中元素Rij表示变量Xi和Xj之间的相关性。
计算公式为Rij = cov(Xi, Xj) / (sigma_i * sigma_j),其中sigma_i和sigma_j分别是变量Xi和Xj的标准差。
5.使用SAS进行实际操作:使用SAS软件导入数据集,并使用PROCCORR和PROCPRINT命令进行协方差矩阵和相关矩阵的计算和输出。
实验结果:通过计算协方差矩阵和相关矩阵,可以得到变量之间的相关性信息。
协方差矩阵的对角线上的元素表示每个变量的方差,非对角线上的元素表示不同变量之间的协方差。
相关矩阵的对角线上的元素都是1,表示每个变量与自身的相关性为1,非对角线上的元素表示不同变量之间的相关性。
使用SAS进行实际操作后,我们可以得到一个包含协方差矩阵和相关矩阵的输出表格。
该表格可以帮助我们更直观地理解变量之间的相关性情况,从而为后续的统计分析提供参考。
实验总结:通过本次多元统计分析实验,我们了解了协方差矩阵和相关矩阵的计算方法,并使用SAS软件进行实际操作。
这些矩阵可以帮助我们评估变量之间的相关性,为后续的统计分析提供重要的基础信息。
在实际应用中,我们可以根据协方差矩阵和相关矩阵的结果,选择合适的统计方法和模型,并做出恰当的推断和决策。
SAS数据分析实验报告

SAS数据分析实验报告摘要:本文使用SAS软件对一组数据集进行了分析。
通过数据清洗、数据变换、数据建模和数据评估等步骤,得出了相关的结论。
实验结果表明,使用SAS软件进行数据分析可以有效地处理和分析大型数据集,得出可靠的结论。
1.引言数据分析在各个领域中都扮演着重要的角色,可以帮助人们从大量的数据中提取有用信息。
SAS是一种常用的数据分析软件,被广泛应用于统计分析、商业决策、运营管理等领域。
本实验旨在探究如何使用SAS软件进行数据分析。
2.数据集描述本实验使用了一个包含1000个样本的数据集。
数据集包括了各个样本的性别、年龄、身高、体重等多种变量。
3.数据清洗在进行数据分析之前,首先需要对数据进行清洗。
数据清洗包括缺失值处理、异常值处理和重复值处理等步骤。
通过使用SAS软件中的相应函数和命令,我们对数据集进行了清洗,确保数据的质量和准确性。
4.数据变换在进行数据分析之前,还需要对数据进行变换。
数据变换包括数据标准化、数据离散化和数据归一化等操作。
通过使用SAS软件中的变换函数和操作符,我们对数据集进行了变换,使其符合分析的需要。
5.数据建模数据建模是数据分析的核心过程,包括回归分析、聚类分析和分类分析等。
在本实验中,我们使用SAS软件的回归、聚类和分类函数,对数据集进行了建模分析。
首先,我们进行了回归分析,通过拟合回归模型,找到了自变量对因变量的影响。
通过回归模型,我们可以预测因变量的值,并分析自变量的影响因素。
其次,我们进行了聚类分析,根据样本的特征将其分类到不同的群组中。
通过聚类分析,我们可以发现样本之间的相似性和差异性,从而做出针对性的决策。
最后,我们进行了分类分析,根据样本的特征判断其所属的类别。
通过分类分析,我们可以根据样本的特征预测其所属的类别,并进行相关的决策。
6.数据评估在进行数据分析之后,还需要对结果进行评估。
评估包括模型的拟合程度、变量的显著性和模型的稳定性等。
通过使用SAS软件的评估函数和指标,我们对数据分析的结果进行了评估。
SAS数据分析实验报告
数理与土木工程学院实验报告课程名称:《统计软件SPSS、SAS及实践》实验结果(包括程序代码、程序结果分析)第一题:②基于数据集transaction,将变量“Revenue”中的缺失数据用其均值代替;data a;set a;array s(*) aa1-aa2;n=n(of s(*));mean=mean(of s(*));sum=sum( of s(*));do i=1to dim(s);if s(i)=.then s(i)=mean;end;run;proc print;run;③基于②,将取值全部缺失的变量删除。
data a;set a;array aa aa1-aa2;do over aa;if col=.then delete;end;run;proc transpose data=a out=transaction(drop=_name_);var aa1-aa2;run;proc print;run;第二题:a) 建立一个数据集合读入数据,变量为length,width和 height;data b;input length width height;cards;32 18 1216 15 2448 12 3215 30 4520 30 36;run;proc print data=b;run;b) 使用 set 语句,利用a)的数据集建立一个新数据集,它包括a)的所有数据,并建立三个新变量:每个c) 使用b)建立的数据集建立一个新数据集,只包括其中的volume 和 cost 变量。
data d;set c(keep=volume cost);run;proc print data=d;run;第三题:a)对车的标志(brand)的频数画竖直条形图。
libname mydata 'D:\data';proc print data=edcar;run;data e;set edcar; run;proc gchart;vbar brand;run;b)c)data g;set f;proc means data=g ;run;第四题:试分析:该地区单身人士的收入与住房面积之间是否相关?如果线性相关,确定一元线性回归方程,并做显著性检验。
sas描述性统计分析
28
27
26
散点图
25
24
23
22
21 女 20 1900 1920 1940 1960 1980 2000 男
定性变量的图表示:饼图 定性变量(或属性变量,分类变量 )不能点出直方图、散点图或茎 叶图,但可以描绘出它们各类的 比例。
饼图
定性变量的图表示:条形图
从每一条可以看出讲各种语言的 实际人数,而且分别给出了每 个语种中母语和日常使用的人 数(在图中并排放置)。条形 图显示比例不如饼图直观。
数据的“尺度”
另一个常用的尺度统计量为(样本)标 准差 (standard deviation) 。度量样 本中各数值到均值距离的一种平均。 标准差实际上是方差 (variance) 的平方 根。如果记样本中的观测值为 x1,…,xn,则样本方差为
数据的“尺度”
两个均值一样,但右边的要 “胖”些,方差为左边的一 倍
描述性统计分析
East China JiaoTong University
如 同 给 人 画 像 一 样
数 据 的 描 述
在对数据进行深入加工之前,总 应该对数据有所印象。 可以借助于图形和简单的运算, 来了解数据的一些特征。 由于数据是从总体中产生的,其 特征也反映了总体的特征。对 数据的描述也是对其总体的一 个近似的描述。
其中茎叶图中茎的单位为10cm,而叶子单位为1cm。比如,由于 第一行茎为150cm,因此叶子中的九个数字001223344代表九个数 目150、150、151、152、152、153、153、154、154cm等。每 行左边有一个频数(比如第一行有9个数目,第二行有17个等等); 可以看出最长的一行为从165cm到169cm的一段(有35个数)。
数据分析(SAS描述性统计分析过程)
var
变量列表 ;
by
变量列表 ;
freq
变量 ;
weight 变量 ;
id
变量列表 ;
output <out=输出数据集名> <统计量关键字=变量名列表> <pctlpts= 百分位数 pctlpre=变量前缀名 pctlname=变量后缀名>;
run;
proc uiate过程旳主要控制语句如下:
proc means(5)
SAS程序 data examp1; input x @@; cards; 70.4 72.0 76.5 74.3 76.5 77.6 67.3 72.0 75.0 74.3 73.5 79.5 73.5 74.7 65.0 76.5 81.6 75.4 72.7 72.7 67.2 76.5 72.7 70.4 77.2 68.8 67.3 67.3 67.3 72.7 75.8 73.5 75.0 72.7 73.5 73.5 72.7 81.6 70.3 74.3 73.5 79.5 70.4 76.5 72.7 77.2 84.3 75.0 76.5 70.4 ; proc means data=examp1 n mean cv skewness kurtosis range median ; var x; run;
mode sumwgt max min range median t prt clm lclm uclm
众数,出现频数最高旳数 权数和 最大值 最小值 极差,max—min 中间值 总体均值等于0旳t统计量 t分布旳双尾p值 置信度上限和下限
置信度下限
置信度上限
kurtosis
对尾部陡平旳度量——峰度
------Quantile-----Percent Observed Estimated
sas数据分析报告
SAS数据分析报告1. 引言SAS(统计分析系统)是一款广泛应用于数据分析和统计建模的软件工具。
本报告将介绍如何使用SAS进行数据分析,并提供一系列步骤,以帮助读者快速上手。
2. 数据准备在开始数据分析之前,我们首先需要准备好待分析的数据集。
数据集应包含所需的变量和观测值,并且应该经过清洗和预处理,以确保数据的准确性和一致性。
3. SAS环境设置在使用SAS进行数据分析之前,我们需要设置SAS环境。
这包括设置工作目录、导入数据和加载所需的SAS库。
markdown sas ** 设置工作目录** libname mydata ‘/path/to/data/’;** 导入数据** data mydata.mydataset; infile ‘/path/to/dataset.csv’ delimiter = ‘,’ firstobs = 2; input var1 var2 var3; run;** 加载SAS库 ** proc sql; create table mydata.mytable as select * from mydata.mydataset; quit; ```4. 数据探索一旦准备好数据并设置好SAS环境,我们可以开始进行数据探索。
这包括计算描述性统计量、绘制图表和查找数据间的相关性等操作。
markdown sas ** 计算描述性统计量 ** proc means data = mydata.mytable; var var1 var2 var3; output out = mydata.summary_stats mean = mean std = std min = min max = max; run;** 绘制直方图 ** proc univariate data = mydata.mytable; histogram var1; run;** 计算相关性 ** proc corr data = mydata.mytable; var var1 var2 var3; run; ```5. 数据分析有了对数据的初步了解后,我们可以开始进行更深入的数据分析。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验报告
实验项目名称SAS描述统计分析所属课程名称现代统计软件实验类型验证性实验实验日期2014-10-28
班级
学号
姓名
成绩
实验报告说明
1.实验项目名称:要用最简练的语言反映实验的内容。
要求与实验指导书中相一致。
2.实验类型:一般需说明是验证型实验还是设计型实验,是创新型实验还是综合型实验。
3.实验目的与要求:目的要明确,要抓住重点,符合实验指导书中的要求。
4.实验原理:简要说明本实验项目所涉及的理论知识。
5.实验环境:实验用的软硬件环境(配置)。
6.实验方案设计(思路、步骤和方法等):这是实验报告极其重要的内容。
概括整个实验过程。
对于操作型实验,要写明依据何种原理、操作方法进行实验,要写明需要经过哪几个步骤来实现其操作。
对于设计型和综合型实验,在上述内容基础上还应该画出流程图、设计思路和设计方法,再配以相应的文字说明。
对于创新型实验,还应注明其创新点、特色。
7.实验过程(实验中涉及的记录、数据、分析):写明上述实验方案的具体实施,包括实验过程中的记录、数据和相应的分析(原程序、程序运行结果、结果分析解释)。
8.结论(结果):即根据实验过程中所见到的现象和测得的数据,做出结论。
9.小结:对本次实验的心得体会、思考和建议。
10.指导教师评语及成绩:指导教师依据学生的实际报告内容,用简练语言给出本次实验报告的评价和价值。
注意:
∙每次实验开始时,交上一次的实验报告。
∙实验报告文档命名规则:“实验序号”+“_”+ “班级”+“_”+“学号”+“姓名”+“_”+ “.doc”例如:管信11班的张军同学学号为:2011312299 本次实验为第2次实验即:实验二、SAS编程基础;则实验报告文件名应为:实验二_管信11 _2011312299_张军.doc 。