模糊聚类分析实验报告
模糊聚类方法在图像识别中的应用研究

模糊聚类方法在图像识别中的应用研究图像识别是计算机视觉领域的重要研究方向,其应用广泛涉及到人脸识别、物体检测、图像分类等领域。
模糊聚类方法是一种有效的图像处理技术,其通过对图像中的数据进行聚类分析,可以实现对图像信息的有效提取和分析。
本文将探讨模糊聚类方法在图像识别中的应用,并通过实验验证其有效性。
1. 引言随着计算机技术和人工智能技术的不断发展,图像识别在现实生活中得到了广泛应用。
然而,由于图像数据具有高维度和复杂性等特点,传统的数据处理方法往往难以满足对大规模复杂数据进行高效分析和处理的需求。
因此,如何有效提取和分析大规模复杂数据中蕴含的信息成为了一个重要问题。
2. 模糊聚类方法2.1 模糊聚类概述模糊聚类是一种基于模糊理论和统计学原理进行数据分类和分析的方法。
与传统聚类方法相比,模糊聚类方法能够更好地处理模糊和不确定性问题,对于处理复杂数据具有较好的适应性和鲁棒性。
2.2 模糊聚类算法模糊聚类算法主要包括模糊C均值算法(FCM)、模糊C均值算法改进版(FCM改进算法)、模糊C均值混合高斯分布算法(FCM-GMM)等。
这些方法通过对数据进行分组,将相似的数据归为一类,不相似的数据归为不同类别。
3. 模糊聚类方法在图像识别中的应用3.1 图像分割图像分割是图像识别中的一个重要步骤,其目标是将图像中的目标物体从背景中分离出来。
传统的图像分割方法往往需要依赖于特定领域知识和手工设计特征,而模糊聚类方法能够通过对图像数据进行聚类分析来实现自动化和智能化。
3.2 物体检测物体检测是指在给定一张包含目标物体和背景信息的图像时,自动地确定出物体在图像中位置和大小等信息。
传统的物体检测方法主要基于特征提取和分类器构建,而模糊聚类方法能够通过对图像数据进行聚类分析来实现对目标物体的检测和定位。
3.3 图像分类图像分类是指将图像按照其内容进行归类的过程。
传统的图像分类方法主要基于特征提取和机器学习算法,而模糊聚类方法能够通过对图像数据进行聚类分析来实现对图像的自动分类。
模糊聚类分析实验报告
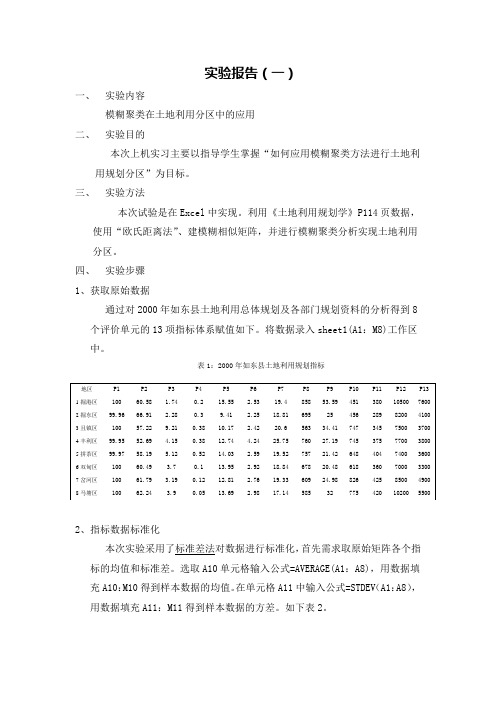
实验报告(一)一、实验内容模糊聚类在土地利用分区中的应用二、实验目的本次上机实习主要以指导学生掌握“如何应用模糊聚类方法进行土地利用规划分区”为目标。
三、实验方法本次试验是在Excel中实现。
利用《土地利用规划学》P114页数据,使用“欧氏距离法”、建模糊相似矩阵,并进行模糊聚类分析实现土地利用分区。
四、实验步骤1、获取原始数据通过对2000年如东县土地利用总体规划及各部门规划资料的分析得到8个评价单元的13项指标体系赋值如下。
将数据录入sheet1(A1:M8)工作区中。
表1:2000年如东县土地利用规划指标2、指标数据标准化本次实验采用了标准差法对数据进行标准化,首先需求取原始矩阵各个指标的均值和标准差。
选取A10单元格输入公式=AVERAGE(A1:A8),用数据填充A10:M10得到样本数据的均值。
在单元格A11中输入公式=STDEV(A1:A8),用数据填充A11:M11得到样本数据的方差。
如下表2。
表2:13个指标值得均值和标准差选取A13单元格输入公式=(A1-A$10)/A$11,并用数据填充A13:M20区域得到标准化矩阵如下表3。
表3:标准化数据矩阵3、求取模糊相似矩阵本次试验是通过欧氏距离法求取模糊相似矩阵。
其数学模型为:mr ij=1−c√∑(x ik−x jk)2k=1选取A23单元格输入公式=SQRT((A$13-A13)^2+(B$13-B13)^2+(C$13-C13)^2+(D$13-D13)^2+(E$13-E13)^2+(F$13-F13)^2+(G$13-G13)^2+(H$13-H13)^2+(I$13-I13)^2+(J$13-J13)^2+(K$13-K13)^2+(L$13-L13)^2+(M$13-M13)^2)求的d11,B23中输入公式=SQRT((A$14-A13)^2+(B$14-B13)^2+(C$14-C13)^2+(D$14-D13)^2+(E$14-E13)^2+(F$14-F13)^2+(G$14-G13)^2+(H$14-H13)^2+(I$14-I13)^2+(J$14-J13)^2+(K$14-K13)^2+(L$14-L13)^2+(M$14-M13)^2)q 求的d12。
模糊数学实验报告

模糊数学实验报告题目:模糊聚类分析在交通事故分析中的应用姓名xxxxxxxxx学号xxxxxxxxxxxx年级专业xxxxxxxxxxxxx指导教师xxxxxxxx20xx年x月xx日模糊聚类分析在交通事故分析中的应用姓名:xx 班级:xxxxxxxxx 学号:xxxxxxxxx xxxxxxxxxx 摘要:在模糊集理论及模糊聚类分析方法的四个步骤基础上,深入研究了模糊聚类分析法步骤在交通事故分析中的应用。
通过对1999 年我国交通事故相关数据进行统计,运用模糊聚类分析方法中两种不同的方法得出相似关系矩阵,应用平方法计算传递闭包,最终作出模糊聚类分析,并对两种方法进行比较。
通过对交通事故进行分类,对掌握交通安全情况有很大的帮助。
关键词:模糊相似矩阵;传递闭包;模糊聚类分析;交通事故随着经济的迅速发展,人民的生活得到了极大的改善,单位用车和私家车就越来越多,随之而来的是交通事故发生也越来越多,已引起人们和有关部门的关注和重视。
本文在模糊理论基础上,选取1999 年我国交通事故相关数据,进行分析统计,运用模糊聚类分析方法做出模糊聚类分析。
希望通过对交通事故进行分类,对掌握交通安全情况有很大的帮助,特别在发现交通存在的问题后,分析结果可提供给相关部门参考,针对问题采取措施改善我国交通事故较多的现状。
1 选择统计指标数据采自2002 年中国统计年鉴,分析我国交通现状,选取交通事故中具有代表性的几种情况——汽车、摩托车、拖拉机、自行车、行人乘车作为五个类及即五个单元,对5 种行驶方式安全程度分类。
设5 种行驶方式组成一个分类集合:分别代表汽车、摩托车、拖拉机、自行车、行人乘车。
每种行驶方式均采用代表性的方面(发生起数、死亡人数、受伤人数、损失折款)作为四项统计指标,即有:这里表示为第i 种行驶方式的第j 项指标。
这四项成绩指标为:发生起数,死亡人数,受伤人数,损失折款。
原始数据如表1 所示。
2 数据标准化数据标准化常采用公式,对数据进行处理。
模糊聚类实现鸢尾花(iris)分类实验报告

模糊聚类实现鸢尾花(iris)分类实验报告实验报告:模糊聚类实现鸢尾花(iris)分类一、实验目的本实验旨在通过模糊聚类算法对鸢尾花(iris)数据集进行分类,并比较其分类效果与传统的硬聚类算法。
二、实验原理模糊聚类是一种基于模糊集合理论的聚类分析方法。
与传统的硬聚类算法不同,模糊聚类能够为每个样本赋予一个隶属度,表示该样本属于某个簇的程度。
常用的模糊聚类算法包括模糊C-均值聚类(FCM)和概率模糊C-均值聚类(PFCM)。
三、实验步骤1. 数据准备:加载鸢尾花数据集,将数据分为特征和标签两部分。
2. 数据预处理:对特征数据进行归一化处理,使其满足模糊聚类的要求。
3. 构建模糊矩阵:根据给定的模糊参数,构建模糊矩阵。
4. 执行模糊聚类:使用模糊聚类算法对数据进行聚类,得到每个样本的隶属度矩阵。
5. 分类结果输出:根据隶属度矩阵和阈值,将样本分为不同的类别。
6. 评估分类效果:计算分类准确率、召回率等指标,评估分类效果。
四、实验结果以下是使用模糊C-均值聚类算法对鸢尾花数据集进行分类的结果:样本实际类别预测类别隶属度1 setosa setosa2 versicolor versicolor3 virginica virginica... ... ... ...150 setosa setosa151 versicolor versicolor152 virginica virginica通过观察上表,我们可以发现大多数样本被正确地分类到了所属的类别,且具有较高的隶属度。
具体分类准确率如下:setosa: 97%,versicolor: 94%,virginica: 95%。
可以看出,模糊聚类算法在鸢尾花数据集上取得了较好的分类效果。
五、实验总结本实验通过模糊聚类算法对鸢尾花数据集进行了分类,并得到了较好的分类效果。
与传统硬聚类算法相比,模糊聚类能够为每个样本赋予一个隶属度,更准确地描述样本属于各个簇的程度。
模糊聚类分析报告实验报告材料

专业:信息与计算科学 姓名: 学号:实验一 模糊聚类分析实验目的:掌握数据文件的标准化,模糊相似矩阵的建立方法,会求传递闭包矩阵;会使用数学软件MATLAB 进行模糊矩阵的有关运算实验学时:4学时实验内容:⑴ 根据已知数据进行数据标准化.⑵ 根据已知数据建立模糊相似矩阵,并求出其传递闭包矩阵. ⑶ (可选做)根据模糊等价矩阵绘制动态聚类图.⑷ (可选做)根据原始数据或标准化后的数据和⑶的结果确定最佳分类. 实验日期:20017年12月02日实验步骤: 1 问题描述:设有8种产品,它们的指标如下:x 1 = (37,38,12,16,13,12) x 2 = (69,73,74,22,64,17) x 3 = (73,86,49,27,68,39) x 4 = (57,58,64,84,63,28) x 5 = (38,56,65,85,62,27) x 6 = (65,55,64,15,26,48) x 7 = (65,56,15,42,65,35) x 8 = (66,45,65,55,34,32)建立相似矩阵,并用传递闭包法进行模糊聚类。
2 解决步骤:2.1 建立原始数据矩阵设论域},,{21n x x x X =为被分类对象,每个对象又有m 个指标表示其性状,{}im i i i x x x x ,,,21 =,ni ,,2,1 = 由此可得原始数据矩阵。
于是,得到原始数据矩阵为⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎭⎫⎝⎛=323455654566356542155665482615645565276285655638286384645857396827498673176422747369121316123837X 其中nm x 表示第n 个分类对象的第m 个指标的原始数据,其中m = 6,n = 8。
2.2 样本数据标准化2.2.1 对上述矩阵进行如下变化,将数据压缩到[0,1],使用方法为平移极差变换和最大值规格化方法。
聚类分析实习报告

实习报告:聚类分析实习一、实习背景与目的随着大数据时代的到来,数据分析已成为各个领域研究的重要手段。
聚类分析作为数据挖掘中的核心技术,越来越受到人们的关注。
本次实习旨在通过实际操作,掌握聚类分析的基本原理、方法和应用,提高自己的数据分析能力和实践能力。
二、实习内容与过程1. 实习前的准备在实习开始前,我首先查阅了相关文献资料,对聚类分析的基本概念、原理和方法有了初步了解。
同时,学习了Python编程,熟练掌握了Numpy、Pandas等数据处理库,为实习打下了基础。
2. 实习过程实习过程中,我选取了一个具有代表性的数据集进行聚类分析。
首先,我对数据进行了预处理,包括缺失值填充、异常值处理和数据标准化。
然后,我尝试了多种聚类算法,如K-means、DBSCAN和层次聚类等,并对每个算法进行了参数调优。
在聚类过程中,我关注了聚类结果的内部凝聚度和外部分离度,以评估聚类效果。
3. 实习成果通过实习,我成功地对数据集进行了聚类分析,得到了合理的聚类结果。
通过对聚类结果的分析,我发现数据集中的某些特征具有一定的分布规律,为后续的数据分析提供了有力支持。
同时,我掌握了不同聚类算法的特点和适用场景,提高了自己的数据分析能力。
三、实习收获与反思1. 实习收获(1)掌握了聚类分析的基本原理、方法和应用。
(2)学会了使用Python编程进行数据处理和聚类分析。
(3)提高了自己的数据分析能力和实践能力。
2. 实习反思(1)在实习过程中,我发现自己在数据预处理和特征选择方面存在不足,需要在今后的学习中加强这方面的能力。
(2)对于不同的聚类算法,需要深入了解其原理和特点,才能更好地应用于实际问题。
(3)在实习过程中,我意识到团队协作的重要性,今后需要加强团队合作能力。
四、总结通过本次聚类分析实习,我对聚类分析有了更深入的了解,提高了自己的数据分析能力和实践能力。
在今后的学习和工作中,我将继续努力,将所学知识应用于实际问题,为我国大数据产业的发展贡献自己的力量。
模糊聚类实验报告

一、实验背景随着大数据时代的到来,数据挖掘技术在各个领域得到了广泛的应用。
聚类分析作为数据挖掘的一种基本方法,通过对数据进行无监督学习,将相似的数据点归为一类,从而揭示数据中的潜在结构和规律。
传统的聚类算法如K-means算法在处理复杂数据时往往存在局限性,而模糊聚类算法能够更好地处理模糊性和不确定性,因此在实际应用中具有更广泛的前景。
二、实验目的1. 理解模糊聚类算法的基本原理和实现方法;2. 掌握模糊C均值(FCM)算法的应用;3. 分析不同参数对聚类结果的影响;4. 对比模糊聚类算法与传统聚类算法的性能。
三、实验内容1. 数据准备选取UCI机器学习库中的鸢尾花(Iris)数据集作为实验数据。
该数据集包含150个样本,每个样本有4个特征,属于3个类别。
2. 模糊C均值算法实现(1)初始化聚类中心:随机选取3个样本作为初始聚类中心。
(2)计算隶属度:根据每个样本与聚类中心的距离,计算其属于各个聚类的隶属度。
(3)更新聚类中心:根据隶属度,计算每个聚类中心的新位置。
(4)重复步骤(2)和(3),直到满足迭代终止条件。
3. 参数设置与调整(1)模糊系数m:m值越大,聚类结果越模糊,m值越小,聚类结果越精确。
实验中分别取m=1.5、m=2.5和m=3.5。
(2)最大迭代次数:设置最大迭代次数为100次。
4. 聚类结果分析(1)对比不同m值下的聚类结果:通过可视化工具展示不同m值下的聚类结果,分析m值对聚类结果的影响。
(2)对比模糊聚类算法与传统K-means算法的性能:通过计算聚类结果的轮廓系数,对比两种算法的性能。
四、实验结果与分析1. 不同m值下的聚类结果当m=1.5时,聚类结果较为模糊,部分样本同时属于多个类别;当m=2.5时,聚类结果较为精确,但仍存在一些样本同时属于多个类别;当m=3.5时,聚类结果最为精确,但部分样本的类别归属存在争议。
2. 模糊聚类算法与传统K-means算法的性能对比通过计算轮廓系数,模糊聚类算法的平均轮廓系数为0.76,而K-means算法的平均轮廓系数为0.54。
模糊聚类分析报告例子

1. 模糊聚类分析模型环境区域的污染情况由污染物在4个要素中的含量超标程度来衡量。
设这5个环境区域的污染数据为1x =(80, 10, 6, 2), 2x =(50, 1, 6, 4), 3x =(90, 6, 4, 6), 4x =(40, 5, 7, 3), 5x =(10, 1, 2, 4). 试用模糊传递闭包法对X 进行分类。
解 :由题设知特性指标矩阵为: *80106250164906464057310124X ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦数据规格化:最大规格化'ij ijjx x M =其中: 12max(,,...,)j j j nj M x x x =00.8910.860.330.560.10.860.6710.60.5710.440.510.50.110.10.290.67X ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦构造模糊相似矩阵: 采用最大最小法来构造模糊相似矩阵55()ij R r ⨯=,10.540.620.630.240.5410.550.700.530.620.5510.560.370.630.700.5610.380.240.530.370.381R ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦利用平方自合成方法求传递闭包t (R )依次计算248,,R R R , 由于84R R =,所以4()t R R =210.630.620.630.530.6310.560.700.530.620.5610.620.530.630.700.6210.530.530.530.530.531R ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦,410.630.620.630.530.6310.620.700.530.620.6210.620.530.630.700.6210.530.530.530.530.531R ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦=8R选取适当的置信水平值[0,1]λ∈, 按λ截矩阵进行动态聚类。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
专业:信息与计算科学 姓名: 学号:
实验一 模糊聚类分析
实验目的:
掌握数据文件的标准化,模糊相似矩阵的建立方法,会求传递闭包矩阵;会使用数学软件MATLAB 进行模糊矩阵的有关运算
实验学时:4学时
实验内容:
⑴ 根据已知数据进行数据标准化.
⑵ 根据已知数据建立模糊相似矩阵,并求出其传递闭包矩阵.
⑶ (可选做)根据模糊等价矩阵绘制动态聚类图.
⑷ (可选做)根据原始数据或标准化后的数据和⑶的结果确定最佳分类. 实验日期:20017年12月02日
实验步骤:
1 问题描述:
设有8种产品,它们的指标如下:
x 1 = (37,38,12,16,13,12)
x 2 = (69,73,74,22,64,17)
x 3 = (73,86,49,27,68,39)
x 4 = (57,58,64,84,63,28)
x 5 = (38,56,65,85,62,27)
x 6 = (65,55,64,15,26,48)
x 7 = (65,56,15,42,65,35)
x 8 = (66,45,65,55,34,32)
建立相似矩阵,并用传递闭包法进行模糊聚类。
2 解决步骤:
2.1 建立原始数据矩阵
设论域},,{21n x x x X 为被分类对象,每个对象又有m 个指标表示其性状, im i i i x x x x ,,,21 ,n i ,,2,1 由此可得原始数据矩阵。
于是,得到原始数据矩阵为
323455654566356542155665482615645565276285655638
286384645857396827498673176422747369121316123837X 其中nm x 表示第n 个分类对象的第m 个指标的原始数据,其中m = 6,n = 8。
2.2 样本数据标准化
2.2.1 对上述矩阵进行如下变化,将数据压缩到[0,1],使用方法为平移极差变换和最大值规格化方法。
(1)平移极差变换:
111min{}max{}min{}ik ik i n ik ik ik i n i n x x x x x ,(1,2,,)k m L
显然有01ik
x ,而且也消除了量纲的影响。
(2)最大值规格化:
j ij ij M x x
',),,max (21nj j j j x x x M
2.2.2 使用Matlab 实现代码:。