计量经济学教程(赵卫亚)课后答案第二章汇编
计量经济学第二章练习题及参考解答
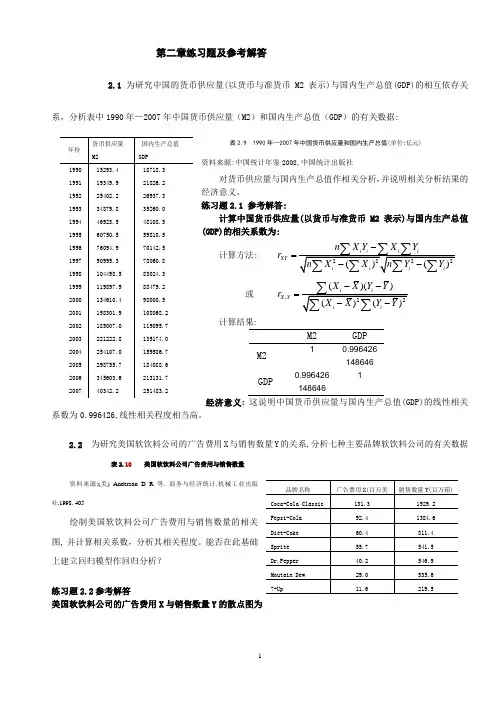
第二章练习题及参考解答2.1 为研究中国的货币供应量(以货币与准货币M2表示)与国内生产总值(GDP)的相互依存关系,分析表中1990年—2007年中国货币供应量(M2)和国内生产总值(GDP )的有关数据:表2.9 1990年—2007年中国货币供应量和国内生产总值(单位:亿元)资料来源:中国统计年鉴2008,中国统计出版社对货币供应量与国内生产总值作相关分析,并说明相关分析结果的经济意义。
练习题2.1 参考解答:计算中国货币供应量(以货币与准货币M2表示)与国内生产总值(GDP)的相关系数为:计算方法: 2222()()i i i iXY i i i i n X Y X Y r n X X n Y Y -=--∑∑∑∑∑∑∑或 ,22()()()()ii X Y iiX X Y Y r X X Y Y --=--∑∑∑计算结果:M2GDPM2 1 0.996426148646 GDP0.9964261486461经济意义: 这说明中国货币供应量与国内生产总值(GDP)的线性相关系数为0.996426,线性相关程度相当高。
2.2 为研究美国软饮料公司的广告费用X 与销售数量Y 的关系,分析七种主要品牌软饮料公司的有关数据表2.10 美国软饮料公司广告费用与销售数量 资料来源:(美) Anderson D R 等. 商务与经济统计.机械工业出版社.1998. 405绘制美国软饮料公司广告费用与销售数量的相关图, 并计算相关系数,分析其相关程度。
能否在此基础上建立回归模型作回归分析?练习题2.2参考解答美国软饮料公司的广告费用X 与销售数量Y 的散点图为年份货币供应量M2国内生产总值GDP1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006 200715293.4 19349.9 25402.2 34879.8 46923.5 60750.5 76094.9 90995.3 104498.5 119897.9 134610.4 158301.9 185007.0 221222.8 254107.0 298755.7 345603.6 40342.218718.3 21826.2 26937.3 35260.0 48108.5 59810.5 70142.5 78060.8 83024.3 88479.2 98000.5 108068.2 119095.7 135174.0 159586.7 184088.6 213131.7 251483.2品牌名称广告费用X(百万美销售数量Y(百万箱)Coca-Cola Classic 131.3 1929.2 Pepsi-Cola 92.4 1384.6 Diet-Coke60.4 811.4 Sprite 55.7 541.5 Dr.Pepper 40.2 546.9 Moutain Dew 29.0 535.6 7-Up11.6219.5说明美国软饮料公司的广告费用X 与销售数量Y 正线性相关。
计量经济学习题参考答案

计量经济学习题参考答案第⼀章导论1.计量经济学是⼀门什么样的学科?答:计量经济学的英⽂单词是Econometrics,本意是“经济计量”,研究经济问题的计量⽅法,因此有时也译为“经济计量学”。
将Econometrics译为“计量经济学”是为了强调它是现代经济学的⼀门分⽀学科,不仅要研究经济问题的计量⽅法,还要研究经济问题发展变化的数量规律。
可以认为,计量经济学是以经济理论为指导,以经济数据为依据,以数学、统计⽅法为⼿段,通过建⽴、估计、检验经济模型,揭⽰客观经济活动中存在的随机因果关系的⼀门应⽤经济学的分⽀学科。
2.计量经济学与经济理论、数学、统计学的联系和区别是什么?答:计量经济学是经济理论、数学、统计学的结合,是经济学、数学、统计学的交叉学科(或边缘学科)。
计量经济学与经济学、数学、统计学的联系主要是计量经济学对这些学科的应⽤。
计量经济学对经济学的应⽤主要体现在以下⼏个⽅⾯:第⼀,计量经济学模型的选择和确定,包括对变量和经济模型的选择,需要经济学理论提供依据和思路;第⼆,计量经济分析中对经济模型的修改和调整,如改变函数形式、增减变量等,需要有经济理论的指导和把握;第三,计量经济分析结果的解读和应⽤也需要经济理论提供基础、背景和思路。
计量经济学对统计学的应⽤,⾄少有两个重要⽅⾯:⼀是计量经济分析所采⽤的数据的收集与处理、参数的估计等,需要使⽤统计学的⽅法和技术来完成;⼀是参数估计值、模型的预测结果的可靠性,需要使⽤统计⽅法加以分析、判断。
计量经济学对数学的应⽤也是多⽅⾯的,⾸先,对⾮线性函数进⾏线性转化的⽅法和技巧,是数学在计量经济学中的应⽤;其次,任何的参数估计归根结底都是数学运算,较复杂的参数估计⽅法,或者较复杂的模型的参数估计,更需要相当的数学知识和数学运算能⼒,另外,在计量经济理论和⽅法的研究⽅⾯,需要⽤到许多的数学知识和原理。
计量经济学与经济学、数学、统计学的区别也很明显,经济学、数学、统计学中的任何⼀门学科,都不能替代计量经济学,这三门学科简单地合起来,也不能替代计量经济学。
赵卫亚教材 第二章 思考题和课后作业(2013春)

第二章 习题课(请先自己做着试试看,能考虑到什么程度就考虑到什么程度,写下来)1.根据某国1980-1993年的数据,得到如下回归结果。
(GNP 为国民生产总值,亿元;M为货币供应量,百万园;s 和t 分别为估计量的标准差和t 检验值。
ˆ787.478.09 ( ) (0.22) (10.0) ( )t tGNP M s t =-+==-要求 (1)完成空缺的数字(2)在5%的显著性水平上是否接受零假设(3)M 的参数的经济学含义是什么?2、下面的方程是Biddle and Hamermesh (1990)研究中所用模型的简化,这项研究要考察工作与休息之间的替代关系。
模型设定如下:Sleep=μββββ++++age edu work 3210其中sleep 和 work 分别表示每周休息和工作的时间(以分钟计),edu 表示接受教育的程度(以接受教育的年数来表示),age 表示年龄。
利用调查的706个样本回归上述模型,估计结果如下(括号内的数字表示参数估计量的标准误差,σˆ表示回归标准差):sleep=3638.25-0.148work-11.13edu+2.20age(112.3) (0.02) (5.88) (1.45)2R =0.11 σˆ= 419.4 请回答如下问题(注:计算过程保留小数点后2位数)(1) 解释系数的意义。
(2) 计算被解释变量的总离差平方和、调整的拟合优度2R 、方程显著性检验的F 统计量。
(3) 对回归方程进行整体显著性检验。
(4) 年龄越大,休息的时间越多吗?给定5%的检验水平,可以得出什么结论?如果检验水平为10%呢?对此应作何解释?(5) 工作时间与休息时间存在替代关系,那么多工作1分钟是否意味着少休息1分钟呢?(检验水平位5%)3、在中国粮食生产函数中,根据理论和经验分析,影响粮食生产(Y)的主要因素有:农业化肥施用量(X1),粮食播种面积(X2),成灾面积(X3),经过逐步回归后选定下列模型。
计量经济学教程赵卫亚课后答案

第二章 回归模型思考与练习参考答案2.1参考答案⑴答:解释变量为确定型变量、互不相关(无多重共线性);随机误差项零的值、同方差、非自相关;解释变量与随机误差项不相关。
现实经济中,这些假定难以成立。
要解决这些问题就得对古典回归理论做进一步发展,这就产生了现代回归理论。
⑵答:总体方差是总体回归模型中随机误差项i ε的方差;参数估计误差则属于样本回归模型中的概念,通常是指参数估计的均方误。
参数估计的均方误为 MSE ()i i b b ˆ=E ()2ˆi i b b -=D ()i b ˆ=()[]iiu 12-'χχσ 即根据参数估计的无偏线,参数估计的均方误与其方差相等。
而参数估计的方差又源于总体方差。
因此,参数估计误差是总体方差的表现,总体方差是参数估计误差的根源。
⑶答:总体回归模型 ()i i i x y E y ε+=样本回归模型i i i e yy +=ˆ i ε是因变量y 的个别值i y 与因变量y 对i x 的总体回归函数值()i x y E 的偏差;i e 为因变量y 的观测值i y 与因变量y 的样本回归函数值i yˆ的偏差。
在概念上类似于i ε,是对i ε的估计。
⑷对于既定理论模型,OLS 法能使模型估计的拟和误差达最小。
但或许我们可选择更理想的理论模型,从而进一步提高模型对数据的拟和程度。
(5)答:2R 检验说明模型对样本数据的拟和程度;F 检验说明模型对总体经济关系的近似程度。
()()()kk n R R k n Model Total k Model k m Error k Model F 111122--∙-=---=--= 由02>∂∂R F 可知,F 是2R 的单调增函数。
对每一个临界值∂F ,都可以找到一个2∂R 与之对应,当22∂>R R 时便有∂>F F 。
(6)答:在古典回归模型假定成立的条件下,OLS 估计是所有的线形无偏估计量中的有效估计量。
计量经济学第二章答案

习题2.8(Ⅰ)证明:由已知的ii y χββ10ˆˆˆ+= )(~~)ˆ(2101i i x c yc ββ+= 公式(2.19 )∑∑==---=ni i ni i ix x y y x x1211)())((ˆ β公式(2.17)x y 10ˆˆββ-= 由公式(2.19)得 2212111221)())((~x c x cy c y c x c x cni i ni i i ---=∑∑==β=2122112)())((x xc y y x x c c ni ini i i ---∑∑===21211)())((x x c y y x x c ni i ni i i ---∑∑===121ˆβc c 由公式(2.17)得x c y c x c c c y c x c y c 111212112110ˆ)()(ˆ)()(~)(~ββββ-=-=-= =0111ˆ)ˆ(ββc x y c =- 所以得证。
(II )证明:由已知的)(~~)ˆ(2101i i x c yc ++=+ββ 根据公式(2.19)得∑∑==+-++-++-+=ni i i i i i ni i x c x cy c y c x c x c1222112121)]()[()]())][(()[(~β=1121ˆ)())((β=---∑∑==ni ini i ix xy y x x根据公式(2.17)得)(ˆ)(~)(~2112110x c y c x c y c +-+=+-+=βββ=12101211ˆˆˆˆββββc c c c x y -+=-+- 所以得证。
(III )证明:由已知得i i x y 10ˆˆ)(g ˆlo ββ+= ii x y c 101~~)(g ˆlo ββ+= 根据公式(2.19)得∑∑==---=ni ini i i ix xy y x x1211)(])log())[log((ˆβ根据公式(2.17)得x y i 10ˆ)log(ˆββ-=∑∑∑∑====---+-=---=ni i ni i i ini i ni i i ix x y c y c x xx x y c y c x x12111121111)(])l o g ()l o g ()l o g ())[l o g (()(])l o g ())[l o g ((~β =∑∑==---ni ini i i ix xy y x x121)(])log())[log((=1ˆβ.111110ˆ)log(ˆ)log()log(~)log(~ββββ+=-+=-=c x y c x y c i i 所以得证(IV )解:由已知得)log(~~210i i x c y ββ+=令i y 对)log(i x 回归的截距和斜率为0β 和1β则∑∑==---=n i i i ni i i i x x y y x x 1211])log()[log()]()lg()[log(ˆβ )l o g (ˆˆ10i i x y ββ-= 112112221221])log()[log()]()lg()[log()]log()log()[log()]()log()log()[log(~ββ=---=-----=∑∑∑∑====n i i i ni i i i n i i i ni i i i x x y y x x x c x cy y x c x c)log(ˆˆ)log(ˆ)log(ˆ])log()[log(ˆ)log(~~21021121210c c x y x c y x c y i i i i i i βββββββ-=--=+-=-=2.9(i )这个方程中的截距代表的意思是当inc=0时,cons 的预测值是-124.84美元。
计量经济学第2章习题参考答案

量 y 是随机变量, 解释变量 x 是非随机变量, 相关分析对资料的要求是两个变量都是随机变 量。 2. 答: 相关关系是指两个以上的变量的样本观测值序列之间表现出来的随机数学关系, 用相关 系数来衡量。 因果关系是指两个或两个以上变量在行为机制上的依赖性, 作为结果的变量是由作为原因的 变量所决定的, 原因变量的变化引起结果变量的变化。 因果关系有单向因果关系和互为因果 关系之分。 具有因果关系的变量之间一定具有数学上的相关关系。 而具有相关关系的变量之间并不一定 具有因果关系。 3. 答:主要区别:①描述的对象不同。总体回归模型描述总体中变量 y 与 x 的相互关系,而样 本回归模型描述所观测的样本中变量 y 与 x 的相互关系。 ②建立模型的不同。 总体回归模型 是依据总体全部观测资料建立的, 样本回归模型是依据样本观测资料建立的。 ③模型性质不 同。总体回归模型不是随机模型,样本回归模型是随机模型,它随着样本的改变而改变。 主要联系:样本回归模型是总体回归模型的一个估计式,之所以建立样本回归模型,目的是 用来估计总体回归模型。
1 n ∑ ui = 0 ,因为 n i =1
前者是条件期望,即针对给定的 X i 的随机干扰的期望,而后者是无条件的平均值,即针对 所有 X i 的随机干扰取平均值。
二、单项选择题 1. A 2. D 3. A 4. B 5. C 6. B 7. D 8. B 9. D 10. C 11. D 12. D 13. C
14. D 15. D 16. A 17. B
三、多项选择题 1. ACD 2. ABE 3. AC 4. BE 5. BEFH 6. DG, ABCG, G, EF 7. ABDE 8. ADE 9. ACDE
计量经济学教程(赵卫亚)课后答案
第二章 回归模型思考与练习参考答案2.1参考答案⑴答:解释变量为确定型变量、互不相关(无多重共线性);随机误差项零的值、同方差、非自相关;解释变量与随机误差项不相关。
现实经济中,这些假定难以成立。
要解决这些问题就得对古典回归理论做进一步发展,这就产生了现代回归理论。
⑵答:总体方差是总体回归模型中随机误差项i ε的方差;参数估计误差则属于样本回归模型中的概念,通常是指参数估计的均方误。
参数估计的均方误为 MSE ()i i b b ˆ=E ()2ˆi i b b -=D ()i b ˆ=()[]iiu 12-'χχσ 即根据参数估计的无偏线,参数估计的均方误与其方差相等。
而参数估计的方差又源于总体方差。
因此,参数估计误差是总体方差的表现,总体方差是参数估计误差的根源。
⑶答:总体回归模型 ()i i i x y E y ε+=样本回归模型i i i e yy +=ˆ i ε是因变量y 的个别值i y 与因变量y 对i x 的总体回归函数值()i x y E 的偏差;i e 为因变量y 的观测值i y 与因变量y 的样本回归函数值i yˆ的偏差。
i e在概念上类似于i ε,是对i ε的估计。
对于既定理论模型,OLS 法能使模型估计的拟和误差达最小。
但或许我们可选择更理想的理论模型,从而进一步提高模型对数据的拟和程度。
⑷答:2R 检验说明模型对样本数据的拟和程度;F 检验说明模型对总体经济关系的近似程度。
()()()kk n R R k n Model Total k Model k m Error k Model F 111122--•-=---=--= 由02>∂∂RF 可知,F 是2R 的单调增函数。
对每一个临界值∂F ,都可以找到一个2∂R 与之对应,当22∂>R R 时便有∂>F F 。
⑸答:在古典回归模型假定成立的条件下,OLS 估计是所有的线形无偏估计量中的有效估计量。
《计量经济学教程(第二版)》习题解答课后习题答案
《计量经济学(第二版)》习题解答第一章1.1 计量经济学的研究任务是什么?计量经济模型研究的经济关系有哪两个基本特征? 答:(1)利用计量经济模型定量分析经济变量之间的随机因果关系。
(2)随机关系、因果关系。
1.2 试述计量经济学与经济学和统计学的关系。
答:(1)计量经济学与经济学:经济学为计量经济研究提供理论依据,计量经济学是对经济理论的具体应用,同时可以实证和发展经济理论。
(2)统计数据是建立和评价计量经济模型的事实依据,计量经济研究是对统计数据资源的深层开发和利用。
1.3 试分别举出三个时间序列数据和横截面数据。
1.4 试解释单方程模型和联立方程模型的概念,并举例说明两者之间的联系与区别。
1.5 试结合一个具体经济问题说明计量经济研究的步骤。
1.6 计量经济模型主要有哪些用途?试举例说明。
1.7 下列设定的计量经济模型是否合理,为什么?(1)ε++=∑=31i iiGDP b a GDPε++=3bGDP a GDP其中,GDP i (i =1,2,3)是第i 产业的国内生产总值。
答:第1个方程是一个统计定义方程,不是随机方程;第2个方程是一个相关关系,而不是因果关系,因为不能用分量来解释总量的变化。
(2)ε++=21bS a S其中,S 1、S 2分别为农村居民和城镇居民年末储蓄存款余额。
答:是一个相关关系,而不是因果关系。
(3)ε+++=t t t L b I b a Y 21其中,Y 、I 、L 分别是建筑业产值、建筑业固定资产投资和职工人数。
答:解释变量I 不合理,根据生产函数要求,资本变量应该是总资本,而固定资产投资只能反映当年的新增资本。
(4)ε++=t t bP a Y其中,Y 、P 分别是居民耐用消费品支出和耐用消费品物价指数。
答:模型设定中缺失了对居民耐用消费品支出有重要影响的其他解释变量。
按照所设定的模型,实际上假定这些其他变量的影响是一个常量,居民耐用消费品支出主要取决于耐用消费品价格的变化;所以,模型的经济意义不合理,估计参数时可能会夸大价格因素的影响。
计量经济学第二章(第三部分)
计量经济学 第二章C
二、实际经济问题中的异方差性
比如:我们建立一个服装需求函数模型,以 服装需求量Q作为被解释变量,以收入Y,服 装价格 P0 和其他商品价格 P1 为解释变量,于 是有模型 : P Q = f ( Y , 0 ,P1 ;u) 在该模型中,气候因素没包含在解释变量里, 而是放在误差项中。但它对服装需求量Q是有 影响的,若该因素构成误差项的主要部分, 则可能产生异方差。
1 2 f(X i ) 而var( ) varui 2 , 即消除了异方差 f(X i ) f(X i ) f(X i )
29
计量经济学 第二章C
同 上
()对新模型进行 OLS 估计, 3 可得到 0, 1具有 BLUE 性质的估计量。
30
计量经济学 第二章C
2、加权最小二乘法
为WLS估计量。
32
计量经济学 第二章C
(2)利用加权最小二乘法处理异方差 假设已知 varui 2 f(X i ) ,
判断模型可能存在 复杂型异方差
14
计量经济学 第二章C
同 上
(2)以残差平方 e 2 为纵轴,某个解释变 量X为横轴,画出残差序列分布图。
15
计量经济学 第二章C
分布图
e
(1)
2
e2
(2) x x
同 上
判断模型基本不 存在异方差
e2
(3) x (4)
e2
x
(2)—(4)可能存在 异方差
16
计量经济学 第二章C
5451.91
6797.71 7869.16 5483.73 5382.91 5853.72
同 上
海南
重庆 四川
349.44
计量经济学各章作业习题(后附答案)
《计量经济学》习题集第一章绪论一、单项选择题1、变量之间的关系可以分为两大类,它们是【】A 函数关系和相关关系B 线性相关关系和非线性相关关系C 正相关关系和负相关关系D 简单相关关系和复杂相关关系2、相关关系是指【】A 变量间的依存关系B 变量间的因果关系C 变量间的函数关系D 变量间表现出来的随机数学关系3、进行相关分析时,假定相关的两个变量【】A 都是随机变量B 都不是随机变量C 一个是随机变量,一个不是随机变量D 随机或非随机都可以4、计量经济研究中的数据主要有两类:一类是时间序列数据,另一类是【】A 总量数据B 横截面数据C平均数据 D 相对数据5、下面属于截面数据的是【】A 1991-2003年各年某地区20个乡镇的平均工业产值B 1991-2003年各年某地区20个乡镇的各镇工业产值C 某年某地区20个乡镇工业产值的合计数D 某年某地区20个乡镇各镇工业产值6、同一统计指标按时间顺序记录的数据列称为【】A 横截面数据B 时间序列数据C 修匀数据D原始数据7、经济计量分析的基本步骤是【】A 设定理论模型→收集样本资料→估计模型参数→检验模型B 设定模型→估计参数→检验模型→应用模型C 个体设计→总体设计→估计模型→应用模型D 确定模型导向→确定变量及方程式→估计模型→应用模型8、计量经济模型的基本应用领域有【】A 结构分析、经济预测、政策评价B 弹性分析、乘数分析、政策模拟C 消费需求分析、生产技术分析、市场均衡分析D 季度分析、年度分析、中长期分析9、计量经济模型是指【】A 投入产出模型B 数学规划模型C 包含随机方程的经济数学模型D 模糊数学模型10、回归分析中定义【】A 解释变量和被解释变量都是随机变量B 解释变量为非随机变量,被解释变量为随机变量C 解释变量和被解释变量都是非随机变量D 解释变量为随机变量,被解释变量为非随机变量11、下列选项中,哪一项是统计检验基础上的再检验(亦称二级检验)准则【】A. 计量经济学准则 B 经济理论准则C 统计准则D 统计准则和经济理论准则12、理论设计的工作,不包括下面哪个方面【】A 选择变量B 确定变量之间的数学关系C 收集数据D 拟定模型中待估参数的期望值13、计量经济学模型成功的三要素不包括【】A 理论B 应用C 数据D 方法14、在经济学的结构分析中,不包括下面那一项【】A 弹性分析B 乘数分析C 比较静力分析D 方差分析二、多项选择题1、一个模型用于预测前必须经过的检验有【】A 经济准则检验B 统计准则检验C 计量经济学准则检验D 模型预测检验E 实践检验2、经济计量分析工作的四个步骤是【】A 理论研究B 设计模型C 估计参数D 检验模型E 应用模型3、对计量经济模型的计量经济学准则检验包括【】A 误差程度检验B 异方差检验C 序列相关检验D 超一致性检验E 多重共线性检验4、对经济计量模型的参数估计结果进行评价时,采用的准则有【】A 经济理论准则B 统计准则C 经济计量准则D 模型识别准则E 模型简单准则三、名词解释1、计量经济学2、计量经济学模型3、时间序列数据4、截面数据5、弹性6、乘数四、简述1、简述经济计量分析工作的程序。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第二章 回归模型思考与练习参考答案2.1参考答案⑴答:解释变量为确定型变量、互不相关(无多重共线性);随机误差项零的值、同方差、非自相关;解释变量与随机误差项不相关。
现实经济中,这些假定难以成立。
要解决这些问题就得对古典回归理论做进一步发展,这就产生了现代回归理论。
⑵答:总体方差是总体回归模型中随机误差项i ε的方差;参数估计误差则属于样本回归模型中的概念,通常是指参数估计的均方误。
参数估计的均方误为 MSE ()i i b b ˆ=E ()2ˆi i b b -=D ()i b ˆ=()[]iiu 12-'χχσ 即根据参数估计的无偏线,参数估计的均方误与其方差相等。
而参数估计的方差又源于总体方差。
因此,参数估计误差是总体方差的表现,总体方差是参数估计误差的根源。
⑶答:总体回归模型 ()i i i x y E y ε+=样本回归模型i i i e yy +=ˆ i ε是因变量y 的个别值i y 与因变量y 对i x 的总体回归函数值()i x y E 的偏差;i e 为因变量y 的观测值i y 与因变量y 的样本回归函数值i yˆ的偏差。
i e 在概念上类似于i ε,是对i ε的估计。
对于既定理论模型,OLS 法能使模型估计的拟和误差达最小。
但或许我们可选择更理想的理论模型,从而进一步提高模型对数据的拟和程度。
⑷答:2R 检验说明模型对样本数据的拟和程度;F 检验说明模型对总体经济关系的近似程度。
()()()kk n R R k n Model Total k Model k m Error k Model F 111122--•-=---=--= 由02>∂∂RF 可知,F 是2R 的单调增函数。
对每一个临界值∂F ,都可以找到一个2∂R 与之对应,当22∂>R R 时便有∂>F F 。
⑸答:在古典回归模型假定成立的条件下,OLS 估计是所有的线形无偏估计量中的有效估计量。
⑹答:如果模型通过了F 检验,则表明模型中所有解释变量对被解释变量的影响显著。
但这并不说明多个解释变量的影响都是显著的。
建模开始时,常根据先验知识尽可能找出影响被解释变量的所有因素,这样就可能会选择不重要的因素作为解释变量。
对单个解释变量的显著性检验可以剔除这些不重要的影响因素。
⑺答:考虑两个经济变量y 与x ,及一组观测值(){},,2,1,,n i y x i i =。
若假定这两个变量都是随机的,要确定相关关系的存在性及相关程度,则相应的统计分析就是相关分析。
若假定两变量一为随机变量一为确定变量,则相应的统计分析就是回归分析。
回归分析以随机变量为因变量而确定型变量为自变量,研究自变量对因变量的影响,对因变量值进行预测。
相关分析是回归分析的基础,进行回归分析之前,通常要检验自变量与因变量间、自变量与自变量间是否存在相关关系。
2.2参考答案答:考虑一元线形回归模型,i i i bx a y ε++= I=1,2,……,n根据古典回归模型的假定,我们有:0)(=i E ε;0)(,=J I E εε, j i ≠; 2)(σε=i D 。
从而①i i i i bx a E bx a y E +=++=)()(ε②2)()()(σεε==++=i i i i D bx a D y D③0),()])([(),(==--=j i j j i i j i E Ey y Ey y E y y Cov εε2.3参考答案答:对于样本回归模型e B x y +=ˆ,使用OLS 法求解Bˆ的微分极值条件为0='e x 。
展开X 矩阵,有,,1[1x e x ='…,0]='e x k①0111121='=⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡'⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡=∑e e e e e n i ②0)(ˆˆ)ˆ(ˆˆˆˆˆ2121=''=''='='=⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡'⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡=∑e x B e x B e B x e y e e e y y y e y n n i i 2.4 参考答案答:注意区分模型与函数、总体与样本。
模型是满足某些假设条件的方程;样本是来自总体的随机抽样。
总体回归模型:i i i i i bx a x y E y εε++=+=)( 总体回归函数:i i bx a x y E +=)(样本回归模型:ii i i i e x b a e y y ++=+=ˆˆˆ 样本回归函数:ii x b a y ˆˆˆ+= 因此,⑵⑷⑺正确。
2.5 参考答案证:设有一元样本回归模型形式如下:e x b b e y y ++=+=110ˆ1ˆˆ 令1110'-=nI M n ,则0M 为离差幂等阵,并且有010=M 和e e M =0。
由)ˆ()ˆ1ˆ(ˆ11011000x b M x b b M y M =+=,从而 回归模型的判定系数为y M y x M x b y M y b x M b x y M y y M y R 01012101011002)ˆ()ˆ()ˆ(ˆˆ''=''=''= y 与x 的相关系数为2101011101210101012101010121010101][ˆ][ˆ][)ˆ(][1y M y x M x b x M x y M y x M x y M x y M y x M x e y M x y M y x M x y M x r yx '''='''=''+'='''=进而 yM y x M x b r yx 0101212)ˆ()(1''= 因此 22)(1R r yx = 证毕。
注意:证明过程中隐含了OLS 法求解的微分极值条件[]011='='e x e x 。
于是,有 e e e n e e n I e M n =-='-=⎥⎦⎤⎢⎣⎡'-=0)1(111110 0101='='e x e M x2.6 参考答案解:αα-=⎭⎬⎫≤⎪⎩⎪⎨⎧-1)ˆ(ˆ2t b S b b prob i i i )ˆ(ˆ)ˆ(ˆ22i i i i i b S t b b b S t b •+≤≤•-αα,置信度%100)1(α-。
2.7参考答案证:显著性水平为α时,2αt t i 。
此处隐含了一个零假设0:0=b H 。
从而 2)ˆ(ˆ)ˆ(ˆαt b S b b S b b t i i i i i i =-= 即)ˆ(ˆ2i i b S t b α 于是,置信度为%100)1(α-的置信区间]ˆ,ˆ[tS b tS b ii +-必不包含0。
2.8参考答案解:i b 的95%置信域为)]ˆ(ˆ),ˆ(ˆ[025.0025.0ii i i b S t b b S t b +-。
当所取样本容量30≥n 时,2025.0≈t 。
此时,i b 的95%置信域为[)]ˆ(2ˆ),ˆ(2ˆ[ii i i b S b b S b +-。
对于例4,L b 的置信域近似地为]27.0220.1,27.0220.1[⨯+⨯-k b 的置信域(95%)近似地为]05.0283.0,05.0283.0[⨯+⨯-① 边际产出L MP 和K MP 的95%置信域② 42.4=L t 和53.14=K t ,均大于1.2)1217(025.0=--t这表明L b 和K b 的95%置信域均不包含零。
换句话说,显著性水平为0.05时,L b 和K b 均显著非零。
2.9参考答案答:判定系数2R 是解释变量个数K 的单调增函数,即0)(2>∆∆K R 。
为克服这种缺陷,可采用调整后的判定系数2R 。
2R 可以消除K 的影响,即0)(2=∆∆K R 。
由1112----=n Total k n Error R 。
可知样本容量n 充分大时,221R TotalError R =-≈。
2.10参考答案解:①5.0ln ln =∆∆xy 为收入需求弹性; 2.0ln ln -=∆∆py 为价格需求弹性。
②%10ln =∆=∆p p p ,则%102.0ln ⨯-=∆=∆y y y③ 价格上涨10%,即%10ln =∆p ;需求水平保持不变,即0ln =∆y 。
由p x y ln 2.0ln 5.0ln ∆-∆=∆, 得%4ln =∆=∆xx x2.11参考答案解:回归方程下,第一行圆括号内的数值为)ˆ(i b S ,第二行为i t 。
在零假设0H :0=i b 的条件下,)ˆ()0ˆ(ii i b S b t -=。
由51.1731.1052.180=及16.55.0)58.2(-=-,可以判定各统计量的属性。
2.12参考答案解:选择模型的步骤及准则:① 先验检验:不合经济原理的模型要排除;② 2R 检验;③ t 检验:2<t 的参数被认为不显著。
2.13参考答案解:① t t x y100.098.862ˆ+= )ˆ(ib S 63.58 0.002 i t 13.57 48.54i t prob > 0.000 0.000Adjusted R-squared 0.992S.E. of regression 197.89F prob > 0.0000100.0=∆∆x y 表明GNP 每增一亿,则财政收入增加0.1亿。
②00.86318.78017100.098.862100.098.862ˆ19981998≈⨯+=+=x y点预测值。
1.2)120(11ˆ025.019981998=--≤+-K t n S yy n=20,k=1 S=197.8983.425ˆ19981998≤-yy 因此,1998年财政收入的95%置信域为[8205.17,9056.83],这也就是显著性水平为0.05的预测区间。
2.14 参考答案解:①②2191.005.053.158ˆt t t x x y-+= )ˆ(ib S 121.81 0.005 0.99 i t 1.30 10.55 –0.92i t prob 0.23 0.000 0.38Adjusted R-squared 0.93S.E. of regression 20.22F prob 0.00拟合优度高,F 检验显著,但t 检验表明常数虚拟变量和变量2x 均不显著。
③ 2120184.000038.06837.2)(t t t t x x x y -+=)ˆ(ib S 0.9970 3.83E-05 0.0081 i t 2.69 9.99 -2.27i t prob 0.027 0.00 0.052Adjusted R-squared 0.92S.E. of regression 0.16F-statistic 57.40F prob 0.00被解释变量经修改后消除了价格因素的影响,从而反映了“实际”的消费支出。