eviews实验5
Eviews 实验操作手册(部分)

Eviews实验操作记录(慢慢整理)相关系数检验:W AGE ED SEXW 1.000000 0.210152 0.495856 -0.260906AGE 0.210152 1.000000 -0.038637 0.144689ED 0.495856 -0.038637 1.000000 -0.084487SEX -0.260906 0.144689 -0.084487 1.000000①可以在命令窗口键入命令:cor x y z……,就会输出相关系数矩阵。
②假设你的样本数据序列:x1 x2从主菜单选择Quick/Group Statistics/Correlations之后会弹出个对话框,在对话框选择你的目标序列x1 x2说明:序列相关好像只有正相关、负相关、完全相关、完全不相关、强相关、弱相关等概念。
相关系数为1是完全正相关,-1是完全负相关,0是完全不相关。
个人感觉0.5左右的相关关系(趋势)就比较弱了。
eviews提供的相关计算是指序列之间的线性相关关系。
如果序列之间不存在线性相关,也有可能存在其他类型的相关关系,如对数相关、指数相关等等。
通常显著性是和建设检验关联的。
统计假设检验也称为显著性检验,即指样本统计量和假设的总体参数之间的显著性差异。
显著性是对差异的程度而言的,程度不同说明引起变动的原因也有不同:一类是条件差异,一类是随机差异。
显著性差异就是实际样本统计量的取值和假设的总体参数的差异超过了通常的偶然因素的作用范围,说明还有系统性的因素发生作用,因而就可以否定某种条件不起作用的假设。
假设检验时提出的假设称为原假设或无效假设,就是假定样本统计量与总体参数的差异都是由随机因素引起,不存在条件变动因素。
假设检验运用了小概率原理,事先确定的作为判断的界限,即允许的小概率的标准,称为显著性水平。
如果根据命题的原假设所计算出来的概率小于这个标准,就拒绝原假设;大于这个标准则接受原假设。
这样显著性水平把概率分布分为两个区间:拒绝区间,接受区间。
eviews实验报告
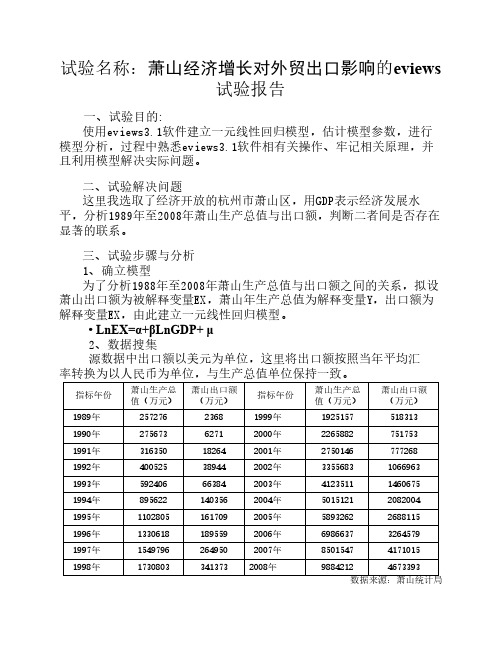
图二 点击“view/ Multiple Graphs/XY line”得到下图。
图三 Xy line图中,横坐标表示表示EX出口额,纵坐标表示GDP生产总 值,从图中曲线的形状分析,EX与GDP的线性关系较强,有继续分析 的意义。 5、描述性统计 (1)、打开对象“EX”,点击“view/Descriptive statistics/Histogram and stats”,可得到EX的描述性统计量。 EX的描述性统计。 均值(mean)为1134213。 中位数(median)为429843。 最大值(maximum)为4673393、最小值(minimum)为2368,可 知EX序列数据跨度大。 标准差(std.dev)为1463811,说明Y序列数据离散程度大。
9、最终确定模型 综上所述,最终确定的模型为 LnEX = -7.756501 + 1.438620 LnGDP +0.574091AR(1) 该模型不仅与样本的拟合程度高,而且不存在自相关问题,具有对 显示经济现象进行解释与预测的意义。 经济分析:InGDP的系数为正,说明经济发展水平的提高的确可以 增加出口额,而这与现实经济现象也是一致的。 统计分析:R2 =0.995071,说明模型很好地拟合了样本,所有参数 的Prob(t-statistic) <0.05,说明显著性检验通过,D.W.= 1.898759, du <1.898759<4-du,说明模型不存在自相关问题。
图四 (2)、打开对象“GDP”,点击“view/Descriptive statistics/Histogram and stats”,可得到GDP的描述性统计量。
eviews操作及案例-简版
■ 成本分析和预测
■ 蒙特卡罗模拟
■ 经济模型的估计和仿真 ■ 利率与外汇预测
EViews 引入了流行的对象概念,操作灵活简便,可采用多种操作方式进行各种计量分
析和统计分析,数据管理简单方便。其主要功能有:
(1)采用统一的方式管理数据,通过对象、视图和过程实现对数据的各种操作;
(2)输入、扩展和修改时间序列数据或截面数据,依据已有序列按任意复杂的公式生
实验七 ___________________________________________________________67
1
FuRretAlphlreorridrguehctpesrdordewsuitectrhivopenedrpbrmyioshEsiicbooitnneoodfmtewhtitreihccosoutIpynprsiteirgthumttiesosiowfonnSe.r.WUFE.
第一部分 EViews 基本操作
第一章 预 备 知识
一、什么是 EViews
EViews (Econometric Views)软件是 QMS(Quantitative Micro Software)公司开发的、基
于 Windows 平台下的应用软件,其前身是 DOS 操作系统下的 TSP 软件。EViews 具有现代
自 结合课程论文,自拟上机内容(不低于 定 10 学时上机)。
FuRretAlphlreorridrguehctpesrdordewsuitectrhivopenedrpbrmyioshEsiicbooitnneoodfmtewhtitreihccosoutIpynprsiteirgthumttiesosiowfonnSe.r.WUFE.
eviews实验报告总结(范本)

eviews实验报告总结eviews实验报告总结篇一:Evies实验报告实验报告一、实验数据:1994至201X年天津市城镇居民人均全年可支配收入数据 1994至201X年天津市城镇居民人均全年消费性支出数据 1994至201X年天津市居民消费价格总指数二、实验内容:对搜集的数据进行回归,研究天津市城镇居民人均消费和人均可支配收入的关系。
三、实验步骤:1、百度进入“中华人民共和国国家统计局”中的“统计数据”,找到相关数据并输入Exc el,统计结果如下表1:表11994年--201X年天津市城镇居民消费支出与人均可支配收入数据2、先定义不变价格(1994=1)的人均消费性支出(Yt)和人均可支配收入(Xt)令:Yt=cn sum/priceXt=ine/pri ce 得出Yt与Xt的散点图,如图1.很明显,Yt和X t服从线性相关。
图1 Yt和Xt散点图3、应用统计软件EVies完成线性回归解:根据经济理论和对实际情况的分析也都可以知道,城镇居民人均全年耐用消费品支出Yt依赖于人均全年可支配收入Xt的变化,因此设定回归模型为 Yt=β0+β?Xt﹢μt(1)打开E Vies软件,首先建立工作文件, Fil e rkfile ,然后通过bject建立 Y、X系列,并得到相应数据。
(2)在工作文件窗口输入命令:l s y c x,按E nter键,回归结果如表2 :表2 回归结果根据输出结果,得到如下回归方程:Y t=977.908+0.670Xt s=(172.3797) (0.0122) t=(5.673) (54.950) R2=0.995385 Adjust ed R2=0.995055 F-sta tistic=3019.551 残差平方和Sum sq uared resi d =1254108回归标准差S.E.f regressi n=299.2978(3)根据回归方程进行统计检验:拟合优度检验由上表2中的数分别为0.995385和0.995055,计算结果表明,估计的样本回归方程较好地拟合了样本观测值。
Eviews虚拟变量实验报告
实验四虚拟变量【实验目的】掌握虚拟变量的基本原理,对虚拟变量的设定和模型的估计与检验,以及相关的Eviews操作方法。
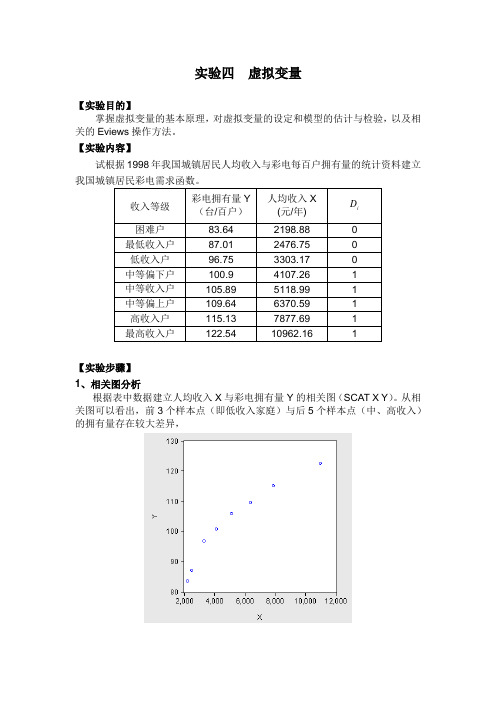
【实验内容】试根据1998年我国城镇居民人均收入与彩电每百户拥有量的统计资料建立我国城镇居民彩电需求函数。
收入等级彩电拥有量Y(台/百户)人均收入X(元/年) iD困难户83.64 2198.88 0最低收入户87.01 2476.75 0低收入户96.75 3303.17 0中等偏下户100.9 4107.26 1中等收入户105.89 5118.99 1中等偏上户109.64 6370.59 1高收入户115.13 7877.69 1最高收入户122.54 10962.16 1【实验步骤】1、相关图分析根据表中数据建立人均收入X与彩电拥有量Y的相关图(SCAT X Y)。
从相关图可以看出,前3个样本点(即低收入家庭)与后5个样本点(中、高收入)的拥有量存在较大差异,因此,为了反映“收入层次”这一定性因素的影响,设置虚拟变量如下:⎩⎨⎧=低收入家庭中、高收入家庭1D2、构造虚拟变量构造虚拟变量 1D (DATA D1),并生成新变量序列:GENR XD=X*D13、估计虚拟变量模型LS Y C X D1 XD得到估计结果:我国城镇居民彩电需求函数的估计结果为:XD D X Y 009.0873.31012.0611.571-++=∧(16.25) (9.03) (8.32) (-6.59)366,066.1..,9937.02===F e s R再由t 检验值判断虚拟变量的引入方式,并写出各类家庭的需求函数。
虚拟变量的回归系数的t 检验都是显著的,且模型的拟合优度很高,说明我国城镇居民低收入家庭与中高收入家庭对彩电的消费需求,在截距和斜率上都存在着明显差异,所以以加法和乘法方式引入虚拟变量是合理的。
低收入家庭与中高收入家庭各自的需求函数为:低收入家庭:∧.57+=611XY012.0中高收入家庭:∧611.87331.57(+++-==012.0484)XX.Y003.0(.0009)89由此可见我国城镇居民家庭现阶段彩电消费需求的特点:对于人均年收入在3300元以下的低收入家庭,需求量随着收入水平的提高而快速上升,人均年收入每增加1000元,百户拥有量将平均增加12台;对于人均年收入在4100元以上的中高收入家庭,虽然需求量随着收入水平的提高也在增加,但增速趋缓,人均年收入每增加1000元,百户拥有量只增加3台。
eviews计量经济学实验报告

eviews计量经济学实验报告EViews计量经济学实验报告引言计量经济学是经济学领域中的一个重要分支,它运用数学、统计学和计量学的方法来分析经济现象。
EViews是一个常用的计量经济学软件,它提供了丰富的数据分析和模型建立工具,被广泛应用于学术研究和实际经济分析中。
本实验报告将利用EViews软件进行计量经济学实验,以探讨经济现象并得出相关结论。
实验目的本实验旨在利用EViews软件对某一经济现象进行实证分析,通过建立相应的计量经济模型,对经济现象进行量化分析,并得出相关结论。
实验步骤1. 数据收集:首先,我们需要收集与所研究经济现象相关的数据,包括时间序列数据和横截面数据等。
这些数据可以来自于官方统计机构、学术研究机构或者自行收集整理。
2. 数据预处理:接下来,我们需要对收集到的数据进行预处理,包括数据清洗、缺失值处理、异常值处理等,以确保数据的质量和完整性。
3. 模型建立:在数据预处理完成后,我们可以利用EViews软件建立计量经济模型,包括回归分析、时间序列分析、面板数据分析等,以探讨经济现象的内在规律和影响因素。
4. 模型估计:建立模型后,我们需要对模型进行参数估计,得到模型的具体参数估计值,并进行显著性检验和模型拟合度检验,以验证模型的可靠性和有效性。
5. 结果分析:最后,我们将对模型估计结果进行分析,得出与经济现象相关的结论,并对实证分析结果进行解释和讨论。
实验结论通过以上实验步骤,我们得出了关于某一经济现象的实证分析结果,并得出了相关的结论。
这些结论对于理解经济现象的内在规律和制定经济政策具有重要的参考价值。
总结EViews计量经济学实验报告通过利用EViews软件进行实证分析,对经济现象进行了深入探讨,并得出了相关结论。
这些结论对于经济学研究和实际经济分析具有重要的理论和实践意义,为我们深入理解经济现象和推动经济发展提供了重要的参考依据。
EViews软件的应用为我们提供了一个强大的工具,帮助我们更好地理解和分析经济现象,为经济学领域的研究和实践提供了重要的支持和帮助。
计量经济学试验-Eviews

12
0.759316100176
27
13
24.0588008707
0.027744 -0.008265 38.94474 40950.71 -146.3152 1.698005
Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic)
下:
序号
Y
X
序号
Y
X
1
2940
3547
16
1609
1963
2
2322
2769
17
2048
2450
3
1898
2334
18
2087
2688
4
1560
1957
19
3777
4632
5
1585189320源自230328956
1977
2314
21
2404
3072
7
1596
1953
22
2034
2421
8
1660
1960
0.133926 271.8586
7.278296 -1.056384
Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic)
EVIEWS软件实验

表 3-1 (元)
2002 年 中 国 各 地 区 城 市 居 民 人 均 年 消 费 支 出 和 可 支 配 收 入
地
城市居民家庭平均每人每年消费支 城市居民人均年可支配收入
区
出
X
Y
北京 天津 河北 山西 内蒙古 辽宁 吉林 黑龙江 上海 江苏 浙江 安徽 福建 江西 山东 河南 湖北 湖南 广东 广西 海南
571.70
4517.8
1228.83
106.0
1981
629.89
4862.4
1138.41
102.4
1982 1983 1984 1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002
Weekly ( 周数据 )
Quartrly (季度) 数据 )
Daily (5 day week ) ( 每周 5 天日
Semi Annual (半年) 数据 )
Daily (7 day week ) ( 每周 7 天日
Monthly (月度) 不规则的)
Undated or irreqular (未注明日期或
或点已存的文件名,再点“ok”。若要读取已存盘数据,点击“fire/Open”,在 对话框的“Drives”点所存的磁盘名,在“Directories”点文件路径,在“Fire Name”点文件名,点击“ok”即可。
STEP4:在 EViews 主页界面点击“Quick”菜单,点击“Estimate Equation”, 出现“Equation specification”对话框,选 OLS 估计,即选击“Least Squares”, 键入“Y C X”,点“ok”或按回车,即出现如图 3-14 那样的回归结果。也可以 在 EViews 命令框中直接键入“LS Y C X”,按回车,即出现回归结果。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
EViews 最小二乘法估计结果:
Dependent Variable: LNY Method: LeasБайду номын сангаас Squares Date: 12/01/11 Time: 11:09
Sample: 1980 2000 Included observations: 21 Coefficient C LNX R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood F-statistic Prob(F-statistic) 1.452109 0.870419 0.988300 0.987684 0.117889 0.264059 16.15139 1604.952 0.000000 Std. Error 0.190925 0.021727 t-Statistic 7.605641 40.06186 Prob. 0.0000 0.0000 9.031179 1.062296 -1.347752 -1.248273 -1.326162 0.451709
-0.027388 0.003293 1.034982 -0.521883 0.057467 0.582003 0.477503 0.083057 0.110376 25.31033 5.569435 0.005271
0.0006 0.0022
Time: 11:17
Sample: 1980 2000 Included observations: 21 Presample missing value lagged residuals set to zero. Coefficient C LNX RESID(-1) RESID(-2) R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood F-statistic Prob(F-statistic) -0.025902 0.003098 1.008103 -0.465000 0.580668 0.506668 0.080706 0.110728 25.27686 7.846883 0.001679 Std. Error 0.131079 0.014926 0.216751 0.217953 t-Statistic -0.197609 0.207594 4.650981 -2.133486 Prob. 0.8457 0.8380 0.0002 0.0478 1.09E-15 0.114904 -2.026367 -1.827411 -1.983189 1.516376
Breusch-Godfrey Serial Correlation LM Test: F-statistic Obs*R-squared Test Equation: Dependent Variable: RESID Method: Least Squares Date: 12/01/11 Time: 11:18 7.425914 12.22205 Prob. F(3,16) Prob. Chi-Square(3) 0.0025 0.0067
Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion Hannan-Quinn criter. Durbin-Watson stat
由于resid(-1)、resid(-2)分别为0.0002、0.0478.均小于显著性水平0.05,且其T统计量的 绝对值均大于1.729,所以此方程存在二阶序列相关。 接着进行三阶序列相关的检验:
Sample: 1980 2000 Included observations: 21 Presample missing value lagged residuals set to zero. Coefficient Std. Error t-Statistic Prob.
C LNX RESID(-1) RESID(-2) RESID(-3) R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood F-statistic Prob(F-statistic)
F-statistic Obs*R-squared Test Equation: Dependent Variable: RESID Method: Least Squares Date: 12/01/11
11.77032 12.19402
Prob. F(2,17) Prob. Chi-Square(2)
Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion Hannan-Quinn criter. Durbin-Watson stat
3.做 LM 检验
Breusch-Godfrey Serial Correlation LM Test:
.3
.2
.1
R(-1)
.0 -.1 -.2 -.2 -.1 .0 R .1 .2 .3
根据 OLS 计算结果,看出残差 r 呈线性自回归,表明随机误差μ 存在自相关。且 由 DW 检验得: Durbin-Watson stat=0.451709,给定显著性水平 a=0.05,查 D-W 表, n=21, k (解释变量个数) =1, 得下限临界值 dL=1.22, 上限临界值 dU=1.42, 因为 DW 统计量为 0.451709<dL=1.22。根据判定区域知,此时随机误差项存在一 阶自相关。
Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion Hannan-Quinn criter. Durbin-Watson stat
11
.3
10
.2
9
.1
.15 8 .10 7
.0
.05 .00
-.1
暨南大学本科实验报告专用纸
课程名称 计量经济学成绩评定 实验项目名称序列相关指导教师黄建军 实验项目编号 02010037905 实验项目类型 综合性 学生姓名 李碧妍学号 2009050226 学院经济学院系财税系专业财政学专业 实验时间 2011 年 12 月 1 日 上午实验地点 经济学院机房
为此,进行如下的校正:
Dependent Variable: LNY
Method: Least Squares Date: 12/13/11 Time: 19:51
Sample (adjusted): 1982 2000 Included observations: 19 after adjustments Convergence achieved after 7 iterations Variable C LNX AR(1) AR(2) R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood F-statistic Prob(F-statistic) Inverted AR Roots Dependent Variable: R Method: Least Squares Date: 12/13/11 Time: 19:55 Coefficient 1.067728 0.911255 0.913717 -0.427302 0.996982 0.996379 0.060374 0.054675 28.62274 1651.791 0.000000 .46+.47i .46-.47i Std. Error 0.253666 0.027926 0.203740 0.180875 t-Statistic 4.209196 32.63122 4.484725 -2.362418 Prob. 0.0008 0.0000 0.0004 0.0321 9.180568 1.003240 -2.591867 -2.393038 -2.558217 1.983830
Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion Hannan-Quinn criter. Durbin-Watson stat
Sample (adjusted): 1982 2000 Included observations: 19 after adjustments Variable C LNY R(-1) R(-2) R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood F-statistic Prob(F-statistic) Coefficient -0.285362 0.029973 0.894153 -0.381699 0.718521 0.662225 0.056613 0.048076 29.84463 12.76331 0.000209 Std. Error 0.131589 0.014182 0.201074 0.178163 t-Statistic -2.168586 2.113405 4.446888 -2.142411 Prob. 0.0466 0.0517 0.0005 0.0490 -0.021596 0.097410 -2.720487 -2.521658 -2.686837 1.989727
-.05
-.2 80 82 84 86 88 90 92 94 96 98 00
-.10 82 84 86 88 Residual 90 92 Actual 94 96 Fitted 98 00