算法分析与设计-第07章
人工智能课件 -07.机器学习

第五节 类比学习
类比推理形式的说明 设有两个具有相同或相似的论域:源域S和目标域T,
且已知S中的元素a和T中的元素b具有相似的属性P,即 P(a) ≌ P(b),a还具有属性Q,即Q(a)。根据类比推理, b也具有属性Q。即
P(a)∧Q(a), P(a) ≌ P(b) |- Q(b)Q(a)
第五节 类比学习
第四节 归纳学习
2、联想归纳 若已知两个事物a与b有n个属性相似或相同,即 a具有属性P1,b具有属性P1 a具有属性P2,b具有属性P2 …… a具有属性Pn,b具有属性Pn
发现a具有属性Pn+1,则当n足够大时,可归纳出: b也具有属性Pn+1
的结论。
第四节 归纳学习
3、类比归纳 设A、B分别是两类事物的集合:
类比推理是在两个相似域之间进行的:一个是已认识的域, 称为源域,记为 S;另一个是当前尚未完全认识的域,称为 目标域,记为T。类比推理的目的就是从S中选出与当前问题 最近似的问题及其求解方法来求解当前的问题,或者建立起 目标域中已有命题间的联系,形成新知识。
设S1、T1分别表示 S 与 T 中的某一情况,且S1与T1相似, 再假设S2与S1相关,则由类比推理可推出T中的T2,且T2与S2 相似。
第四节 归纳学习
5、消除归纳
当我们对某个事物发生的原因不清楚时,通常会作一
些假设,这些假设之间是析取关系。以后,随着对事物
Байду номын сангаас
认识的不断深化,原先作出的某些假设有可能被否定,
经过若干次否定后,剩下的就可作为事物发生的原因。
这样的思维过程称为消除归纳。
已知:
A1 V A2 V … V An ~A1 ~Ai
SMIS第07章_安全管理信息系统的设计实施和运行管理1

山东工商学院
陈章良
第07章 系统设计
结构化系统设计的基本思想
办公自动化
自顶向下地将系 统划分成若干子系 统,子系统再分为 模块,层层划分;
然后自下而上地 逐步设计。
日 常 办 公
个 人 信 息
公 文 管 理
信 访 管 理
档 案 管 理
公 司 简 介
系 统 设 置
日常办公
电 子 公 告
公 共 信 息
山东工商学院
陈章良
7.3.7 案例:身份证号码设计
新身份证号码 奇数男、偶数021 1
出生地 出生时间
验证码
山东工商学院
陈章良
7.4 输出设计
为什么在设计阶段是先输出设计,再
输入设计?
输出设计的目的是正确及时地反映和组成用于生产和服务 部门的有用信息。 输出设计对输入设计提出了内容、格式等方面的要求。
强 山东工商学院 独立性 弱
陈章良
7.2.2 模块间的联系
模块内聚 反映模块内部联系的紧密程度。一个内聚程度高的 模块应当只完成软件过程中的一个单一的任务,只做 一件事。 一般模块的内聚性分为7种类型,它们的关系如 下图所示:
低 内聚性 高
偶然内聚
弱
逻辑内聚
时间内聚
步骤内聚
独立性
通信内聚
顺序内聚
功能内聚
忻展红,舒华英 北京邮电大学出版社 李代平 清华大学出版社 忻展红,舒华英 北京邮电大学出版社 西安交通大学出版社 机械工业出版社 薛华成译
200612239 刘易斯 9787560517797 管理研究方法论 李怀祖
…… …… ……
…… …… ……
…… …… ……
…… …… ……
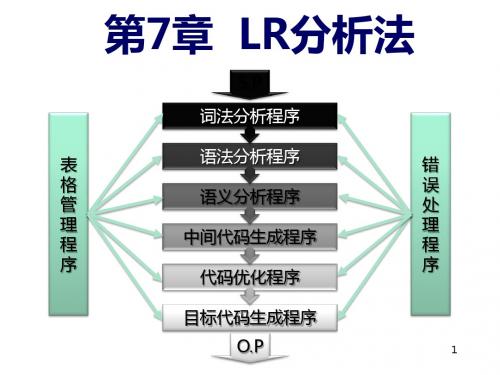
第07章、LR分析法
10
三、 LR分析器
1. LR分析器的组成 由3部分组成:总控程序、分析表、分析栈。 2. LR分析器的构造 (1) 构造识别文法活前缀的确定有限自动机 (2) 根据该自动机构造相应的分析表(ACTION表、GOTO表)
圆点不在产生式右部最左边的项目称为核,唯一的 例外是S’ → • S。因此用GO(I,X)转换函数得到的J为 转向后状态所含项目集的核。 使用闭包函数(CLOSURE)和转换函数(GO (I,X)) 构造文法G’的LR(0)的项目集规范族,步骤如下: (1) 置项目S’→ • S为初态集的核,然后对核求闭包 CLOSURE({S’→ • S})得到初态的项目集; (2) 对初态集或其它所构造的项目集应用转换函数GO (I,X)= CLOSURE(J)求出新状态J的项目集; (3) 重复(2)直到不出现新的项目集为止。
28
例:文法G[S]: (1) S → aAcBe (2) A → b (3) A → Ab (4) B → d
a S2 ACTION c e b d # acc S5 r2 r3 r4 r1 S4 S6 r2 r3 r4 r1 3 r2 S8 r3 r4 r1 r2 r3 r4 r1 GOTO S A B 1
是否推导出abbcde?
每次归约句型的 前部分依次为: ab[2] aAb[3] aAcd[4] aAcBe[1]
9
二、LR分析要解决的问题
• LR分析需要构造识别活前缀的有穷自动机
可以把文法的终结符和非终结符都看成有 穷自动机的输入符号,每次把一个符号进 栈看成已识别过了该符号,同时状态进行 转换,当识别到可归前缀时,相当于在栈 中形成句柄,认为达到了识别句柄的终态。
道路工程 第07章 路基边坡稳定性设计

(3)滑动面假定
松散的砂性土和砾石内摩擦角较大,粘聚力较小,滑动
面近似平面,平面力学模型采用直线。 粘性土粘聚力较大,内摩擦角较小,破裂时滑动面近似 于圆曲面,平面力学模型采用圆弧。
———路基路面工程———
直线平面 :由松散的砂性土和砾石填筑。
曲面 :以粘性土填筑 。
1.25 (0.4663 a0 )0.5 2 a0 (0.4663 a0 )( 0.5 2 1)
———路基路面工程———
经整理得: 解得:
4a0 4.3655 a0 1.034 0
a0 0.2002
a0 2c H
2
由:
得:
H
2c 2 14.70 8.7m a0 16.90 0.2002
路基边坡稳定性设计
———路基路面工程———
图1 路堤边坡滑坡实况
———路基路面工程———
图2 路堑边坡滑坡实况
———路基路面工程———
———路基路面工程———
———路基路面工程———
———路基路面工程———
———路基路面工程———
———路基路面工程———
———路基路面工程———
———路基路面工程———
———路基路面工程———
第一节 边坡稳定性分析原理 与计算参数
———路基路面工程———
一、边坡稳定性分析原理
(1)岩石边坡 岩石路堑边坡稳定性取决于岩石的产状和地质构造特 征,岩体中存在的构造弱面,如层面,层理,断层, 节理等,是岩体中潜在的滑动面,一旦工程地质条件 向不利方向变化,岩体就会失稳形成滑坡。 (2)土质路基 令:T-土体的下滑力,F-抗滑力, K=F/T。 当K>1,稳定;K<1,滑动面形成,滑体下滑。考虑到 一些不确定性因素,为安全起见工程上常采用K= 1.2~1.5作为稳定的界限值。 滑动面有直线,曲线,折线三大类。
DSP器件原理与应用-07 XDAIS算法标准

第7章 XDAIS算法标准7.1 概述XDAIS(eXpressDSP algorithm standard)算法标准是TI公司提出的一套DSP算法编程时所应遵循的规范。
DSP算法标准在三个层次上定义了一系列编程规范,其内容包括图7-1中的第1层到第3层。
图7-1 DSP算法标准●第1层,定义所有算法必须遵循的通用编程规范,适用于任何DSP。
●第2层,定义在一个系统中同时存在多种算法时各算法应遵循的编程规范,包括内存使用、外部标识符的命名以及算法封装等。
●第3层,定义针对特定DSP的编程规范。
●第4层,包含各种应用,不属于DSP算法标准所涉及的范围。
如果DSP算法遵循了第1层到第3层的编程规范,则该算法满足XDAIS。
XDAIS算法标准的内容分为规则和建议两类:规则是满足XDAIS的算法必须遵循的;建议不作强制规定,但极力推荐程序员遵循。
7.2 通用编程规范通用编程规范面向所有应用和所有DSP。
7.2.1 C语言的使用所有的算法都必须遵循C语言编程规范,从而保证系统集成时可以使用C语言将各种算法“捆绑”在一起。
【规则1】所有算法必须遵循TI的C语言规范。
算法可以用纯汇编语言编写,但是它必须能被C语言调用并且遵循C语言规范。
软件内部可能有许多内部函数,这些内部函数并不需要遵循C语言规范,只要求软件的最高层接口满足C语言规范即可。
但是内部函数的操作不能让最高层接口违反C语言规范。
7.2.2 线程和可重入DSP系统中可能出现各种类型的线程,要求算法能够可重入,即一段程序能够同时被多个线程使用。
可重入代码中不能包含自身的“状态”信息,否则不同的线程都会使用相同的状态数据进行计算,从而得到相同的结果。
如果在程序代码中无法避免状态信息的出现,那么保护状态信息的最号方法是在某些特定的程序段运行时禁止线程调度。
【规则2】所有算法必须能够在抢先式多任务环境下可重入。
7.2.3 数据存储器DSP的片内存储器和片外存储器(即使在片外使用SRAM)在性能上存在很大的差异。
第07章 检索结果相关反馈与优化

Information Retrieval and Processing
第7章 检索结果相关反馈与优化
Information Retrieval and Processing
信息检索的一个问题
信息 集合
特征化 表示
信息检索系统
特征化 表示
需求 集合
选择与匹配
问题:当首次信息检索结果不能满足用户需求时, 应该如何处理以满足用户的需要?
Information Retrieval and Processing
一个解决策略—查询优化
查询优化(Query Refinement),也称查询修正、查询 改进、查询精化或查询细化,国外亦称之为查询点移动 (Query Point Movement),是根据检索结果的满足程 度来进一步调整检索策略的方法与技术。
6.制定具体的检索程序
确定回溯时间,分配检索任务
7.判断检索结果的相关性,必要时进行反 馈检索,获取原始信息单元
Information Retrieval and Processing
7.1 检索策略的构造与优化
7.1.1 检索策略的含义 7.1.2 检索策略的构造 7.1.3 检索词的选择 7.1.4 检索式的拟定 7.1.5 检索策略的优化
颖率等
费用
用户为检索所投入的费用
时间
用户检索所花费的时间
Information Retrieval and Processing
检索策略
用于 提高 查全 率的 措施
用于 提高 查准 率的 措施
调整检索策略的方式
1、去掉用AND连接的非主题限定词
2、增加用OR连接的相关检索词
3、减少用NOT限定的检索式
n07第七章 消化率的测定
饲料指示剂添加量:3%
粪中CF含量: 40%
粪中指示剂含量:6%
CF消化率= 100 - 3 × 40 ×100 6 40 = 50
消化能值的计算
直接测定
根据消化试验结果和结合能值测定进行 DE = (GE - FE)/采食量(kg) 例如
体重50Kg的猪,每日食入日粮2Kg,含总能33.47MJ,每日排粪中的总能为 8.34MJ,计算其采食饲料的的消化能。 饲料消化能 = (33.47-8.34)/2 =12.57(MJ/Kg)
第二组
基础日粮 + 被测饲料
试验期
基础日粮
消化率的计算
D(%) = (B-A) X100 + A F
式中:D为被测饲料养分消化率 A为基础饲粮养分消化率 B为混合饲粮养分消化率
F为被测饲料养分占混合饲粮该养分的比例。
假定
基础饲粮养分消化率不变 养分间无互作效应
四、消化试验的基本步骤与要求
1、动物选择 2、日粮配制 3、试验步骤 4、食糜的收集和处理
全收粪法养分消化率计算
例 1:测定仔猪饲粮CP消化率
日采食量:1000g, 饲粮CP含量:16% 日排粪量:250g, 粪中CP含量:12% CP消化率=
( 1000×16%-250×12%)
(1000×16%)
×100
= 81.2%
指示剂法养分消化率计算
例 2: 某饲粮消化实验结果如下,计算CF消化率
消化率计算公式
(食入养分 - 粪中养分) X 100% 表观消化率= 食入养分 食糜养分组成
饲料中未消化的养分; 消化道分泌物; 消化道脱落细胞; 消化道微生物及其代谢产物。
算法设计与分析-课后习题集答案
(2)当 时, ,所以,可选 , 。对于 , ,所以, 。
(3)由(1)、(2)可知,取 , , ,当 时,有 ,所以 。
11. (1)当 时, ,所以 , 。可选 , 。对于 , ,即 。
(2)当 时, ,所以 , 。可选 , 。对于 , ,即 。
(3)因为 , 。当 时, , 。所以,可选 , ,对于 , ,即 。
第二章
2-17.证明:设 ,则 。
当 时, 。所以, 。
第五章
5-4.SolutionType DandC1(int left,int right)
{while(!Small(left,right)&&left<right)
{int m=Divide(left,right);
所以n-1<=m<=n (n-1)/2;
O(n)<=m<=O(n2);
克鲁斯卡尔对边数较少的带权图有较高的效率,而 ,此图边数较多,接近完全图,故选用普里姆算法。
10.
T仍是新图的最小代价生成树。
证明:假设T不是新图的最小代价生成树,T’是新图的最小代价生成树,那么cost(T’)<cost(T)。有cost(T’)-c(n-1)<cost(t)-c(n-1),即在原图中存在一颗生成树,其代价小于T的代价,这与题设中T是原图的最小代价生成树矛盾。所以假设不成立。证毕。
13.template <class T>
select (T&x,int k)
{
if(m>n) swap(m,n);
if(m+n<k||k<=0) {cout<<"Out Of Bounds"; return false;}
第7章抽样
随机抽样技术的优缺点
(1) 优点 ①随机抽样是从总体中按照随机原则抽取一部分单位进行的 调查。 ②随机抽样技术能够计算调查结果的可靠程度。 (2) 不足 ① 对所有调查样本都给予平等看待,难以体现重点。 ② 抽样范围比较广,所需时间长,参加调查的人员和费用多。 ③ 需要具有一定专业技术的专业人员进行抽样和资料分析。 一般调查人员难以胜任。 ④抽样框难以构建。 ⑤比其他概率抽样精确度低,标准差较大。 30
24
1.简单随机抽样 • 又称纯随机抽样,即对总体单位不进行任何分组 排列,仅按随机原则直接从总体中抽取样本,以 使总体中的每一个单位均有同等的被抽取的机会。
• 这是最基本,最简单的的机率抽样方法。它易于 理解,样本结果可以推断总体,大多数统计推论 方法都假定数据是由简单随机抽样法法获得的。
25
1.简单随机抽样 • 每个单位被选取的机会是相同的。就好像把各个 单位的名字写在大小相同的纸上,放到一个箱子 中,由我们抽取,每个个案都有被抽到的可能, 而且机会相同。如平日常见的摸彩或摇奖,在数 学上则会利用随机数表来抽取样本。
第七章
抽样
1
本章的学习目标 一、抽样的概念
二、抽样的基本过程
三、概率抽样
四、非概率抽样
五、样本量的确定
六、 PPS抽样简介
七、 KISH表的运用
2
一、抽样的概念
3
(一)什么是抽样?
• 抽样就在我们的日常生活中。抽血化验,尝试水 温,窥一斑而知全豹。
• 抽样,就是从研究总体中抽取一部分的过程。 • 抽样调查,就是从研究总体中抽取一部分代表加 以调查研究,然后用所得结果推论和说明总体的 特性。这也称为推论统计。
2.等距抽样
• 又称系统抽样或机械抽样。 • 具体做法: • 1)将总体的所有单位按一定顺序排列起来; • 2)计算抽样间隔R=N/n;
计算机网络课后题答案第七章
第七章网络安全7-01 计算机网络都面临哪几种威胁?主动攻击和被动攻击的区别是什么?对于计算机网络的安全措施都有哪些?答:计算机网络面临以下的四种威胁:截获(interception),中断(interruption),篡改(modification),伪造(fabrication)。
网络安全的威胁可以分为两大类:即被动攻击和主动攻击。
主动攻击是指攻击者对某个连接中通过的PDU 进行各种处理。
如有选择地更改、删除、延迟这些PDU。
甚至还可将合成的或伪造的PDU 送入到一个连接中去。
主动攻击又可进一步划分为三种,即更改报文流;拒绝报文服务;伪造连接初始化。
被动攻击是指观察和分析某一个协议数据单元PDU 而不干扰信息流。
即使这些数据对攻击者来说是不易理解的,它也可通过观察PDU 的协议控制信息部分,了解正在通信的协议实体的地址和身份,研究PDU 的长度和传输的频度,以便了解所交换的数据的性质。
这种被动攻击又称为通信量分析。
还有一种特殊的主动攻击就是恶意程序的攻击。
恶意程序种类繁多,对网络安全威胁较大的主要有以下几种:计算机病毒;计算机蠕虫;特洛伊木马;逻辑炸弹。
对付被动攻击可采用各种数据加密动技术,而对付主动攻击,则需加密技术与适当的鉴别技术结合。
7-02 试解释以下名词:(1)重放攻击;(2)拒绝服务;(3)访问控制;(4)流量分析;(5)恶意程序。
答:(1)重放攻击:所谓重放攻击(replay attack)就是攻击者发送一个目的主机已接收过的包,来达到欺骗系统的目的,主要用于身份认证过程。
(2)拒绝服务:DoS(Denial of Service)指攻击者向因特网上的服务器不停地发送大量分组,使因特网或服务器无法提供正常服务。
(3)访问控制:(access control)也叫做存取控制或接入控制。
必须对接入网络的权限加以控制,并规定每个用户的接入权限。
(4)流量分析:通过观察PDU 的协议控制信息部分,了解正在通信的协议实体的地址和身份,研究PDU 的长度和传输的频度,以便了解所交换的数据的某种性质。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
多段图的向前递推关系式
1
9 s 0 7 3 2 1 2
4
2 5 6
8 5 是 有 向边 c(j,p) cost(i,j)是从第i阶 4 2 4 3 7段的状态j到t的最 2 11 t <j,p>的权值 6 9 5 5 短路径的长度 3 11 6 10 7 11 8 4
cost(5,11)=0; cost(4,10)=5; cost(4,9)=2; cost(4,8)=4;
cost(3,7)=min{6+cost(4,10), 5+cost(4,9)}=7; cost(3,6)=min{3+cost(4,9), 4+cost(4,8)}=5; cost(3,5)=min{5+cost(4,9), 6+cost(4,8)}=7;
南京邮电大学计算机学院 10/22/2013
7.1 7.2 7.3 7.4 7.5 7.6 7.7
一般方法和基本要素 每对结点间的最短路径 矩阵连乘 最长公共子序列 最优二叉搜索树 0/1背包 流水作业调度
南京邮电大学计算机学院 10/22/2013
7.1 一般方法和基本要素
南京邮电大学计算机学院 10/22/2013
分治法的子问题相互独立,相同的子问题 被重复计算,动态规划法解决这种子问题重 叠现象。
南京邮电大学计算机学院 10/22/2013
Hale Waihona Puke n 例如用分治法递归求解组合数 Cm :
当n 0或m n时 1 Cm n n 1 Cm-1 Cm1 当m n 0时 C53
n
C43
C42
此可以避免分治法重复计算这种重叠子问题
南京邮电大学计算机学院 10/22/2013
设计动态规划算法的几个步骤: (1)刻画最优解的结构特性; (2)递归定义最优解值; (3)以自底向上方式计算最优解值;
(4)根据计算得到的信息构造一个最优解。
第(1)至(3)步是动态规划算法的基本步骤。
最优解值是最优解的目标函数的值。
南京邮电大学计算机学院 10/22/2013
7.1.2 基本要素
一个最优化多步决策问题是否适合用 动态规划法求解有两个要素:最优子结构 特性和重叠子问题。
南京邮电大学计算机学院 10/22/2013
动态规划算法的基本要素
最优子结构特性: 即问题的最优解包含了其子问 题的最优解。
分析(证明)问题的最优子结构特性时:首先假设 由问题的最优解导出的子问题的解不是最优的, 然后再设法说明在这个假设下可构造出比原问题 最优解更好的解,从而导致矛盾。 利用问题的最优子结构特性,以自底向上的方式 递推地从子问题的最优解逐步构造出整个问题的 最优解。最优子结构是问题能用动态规划算法求 解的前提。 南京邮电大学计算机学院
这是一条最 V4 V5 短路径。
南京邮电大学计算机学院 10/22/2013
多段图具有最优子结构 可以证明多段图的最优解满足最优子结构。
1
9
1 2 7 3
4
2
5
4
6 5
8
2
7
4
s 0
6
7
3
5 6
9
10
2
5
t 11
3
2
11 11 8
4
南京邮电大学计算机学院 10/22/2013
证明:假定(s,v2,v3,…,vk-1,t)是一条最短路径, 并假定在初始状态已经做出到达v2 的决策。 如果将v2看成是原问题的一个子问题的初始状态, 求解该子问题就是寻找一条从v2到t的最短路径。 一个最优策略具有这样的性质:不论过去状态和决策如 何,对前面的决策所形成的状态而言,其余决策必定构, 如果(s,v2,v3,…,vk-1,t)是最短路径,那么(v2,v3,…,vk-1 成最优策略。 t)必定是一条最短路径。 ——这便是最优决策序列的最优子结构性质。,…,vk-1,t) 若不是,则一定还有(v2,q3,…qk-1,t)比(v2,v3 更短,这 样 可 以 推 出 (s,v2,q3,…qk-1,t) 比 (s,v2,v3,…, 在分析(证明)问题的最优子结构性质时,所用的方法 具有普遍性: 与假设矛盾。 vk-1,t)更短,
算法设计与分析
Design and Analysis of Algorithms In C++
主讲 王海艳 计算机学院 wanghy@
南京邮电大学计算机学院 10/22/2013
第7章 动态规划法
基本要求: 理解动态规划算法的算法思想、两大 基本要素以及最优子结构特性,掌握用动 态规划法求解最优化问题的算法设计策略。 重点掌握每对结点间的最短路径、最长公 共子序列和0/1背包问题三个范例 。
南京邮电大学计算机学院 10/22/2013
动态规划法与分治法
共同点: 将待求解的问题分解成若干子问题,先求解子问题,然 后再从这些子问题的解得到原问题的解 不同点: 1、适合于用动态规划法求解的问题,分解得到的各子问题 往往不是相互独立的; 而分治法中子问题相互独立。 2、动态规划法用表保存已求解过的子问题的解,再次碰到 同样的子问题时不必重新求解,而只需查询答案,故可 获得多项式级时间复杂度,效率较高; 而分治法中对于每次出现的子问题均求解,导致同样的 子问题被反复求解,故产生指数增长的时间复杂度,效 率较低。 南京邮电大学计算机学院
2
(0, q=t(11);
d(2,1)=q(6); cost(4,10)=5; cost(3,7)=7; cost(2,4)=16; q=1; cost(4,9)=2; cost(3,6)=5; cost(2,3)=18; d(1,0)=q(1); cost(4,8)=4; cost(3,5)=7; cost(2,2)=9; cost(2,1)=7; d(4,9)=q(11); d(3,6)=q(9); q=9; q=6;
cost(1,0)=min{9+cost(2,1), 7+cost(2,2), 3+cost(2,3), 2+cost(2,4)} =16;
南京邮电大学计算机学院 10/22/2013
4
多段图的最短路径
1 9 s 0 7 3 3 2 4 1 2 4 2 5 4 7 11 11 8 7 6 6 5 3 5 6 8 9 10 4 2 5 11 t
南京邮电大学计算机学院 10/22/2013
多段图问题是一种特殊的有向无环图的最短路径 问题。 1 4
9 1 2 2
5
4
6 5 3 5 6
8 9 10
s 0
7 3
2
7
4 2 5
6
t 11
3
2
11 11
8
7
V3
4
V1
5个阶段
V5 每个结点代 V4 一个汇点 一个5段图 V3={5,6,7} 表一个状态
10/22/2013
动态规划法与贪心法
共同点:
都是求解最优化问题;都要求问题具有最优子结构性质。
不同点:
1、求解方式不同: 动态规划法:自底向上; 贪心法:自顶向下。以迭代的方式作出相继的贪心选择, 每作一次贪心选择就将所求问题简化为一个规模更小的子 问题。 2、对子问题的依赖不同: 动态规划法:依赖于各子问题的解,所以只有在解出相关 子问题后,才能作出选择;应使各子问题最优,才能保证整 体最优; 贪心法:不依赖于子问题的解。仅在当前状态下作出最好 选择,即局部最优选择,然后再去解作出这个选择后产生 的相应的子问题。
2
d(i,j)纪录从第i阶段的状态j到t的最短路径 上该结点的下一个结点编号。
例如:d(4,9)=11;d(3,6)=9; d(2,1)=6; d(1,0)=1;
南京邮电大学计算机学院 10/22/2013
多段图最短路径的确定
1 9 s 0 7 3 1 2 4 2 5 4 7 6 6 5 3 8 9 4 2 11 t
南京邮电大学计算机学院 10/22/2013
学习要点
理解动态规划算法的概念。 掌握动态规划算法的基本要素 (1)最优子结构性质 (2)重叠子问题性质 掌握设计动态规划算法的步骤。 理解动态规划算法与分治法、贪心法的异同 通过应用范例学习动态规划算法设计策略。 (1)多段图问题 (2)每对结点间的最短路径 (3)最长公共子序列 (4)0/1背包
南京邮电大学计算机学院 10/22/2013
最优性原理指出,一个最优策略具有这 样的性质,不论过去状态和决策如何,对 前面的决策所形成的状态而言,其余决策 必定构成最优策略。这便是最优决策序列 的最优子结构特性。 分治法将问题分解成子问题时,它们并 不总是完全相互独立的,常常共享更小的 子问题,这就是重叠子问题。如果用递归 的分治法求解,则存在重复计算。 动态规划法实施自底向上计算,并保存子问题的解,因
南京邮电大学计算机学院 10/22/2013
一个源点
V2
多段图问题是一种特殊的有向无环图的最短路径 问题。 1 4
9 1 2 2
5
4
6 5 3 5 6
8 9 10
s 0
7 3
2
7
4 2 5
6
t 11
3
2
11 11
8
7
4 最优解值 V1 是16。V2
最优解是 V3 (0,1,6,9,11) 一个5段图
南京邮电大学计算机学院 10/22/2013
7.1.1 一般方法
贪心法求解问题的每一步上根据最优量度标准做出 某种决策,产生n-元组解的一个分量。用于决策的 贪心准则仅依赖于局部的和以前的选择,但不依赖 于尚未做出的选择和子问题的解。 而动态规划法每一步的决策依赖于子问题的解。 为了在某一步上做出选择,需要先求解若干子问题, 再根据子问题的解做出决策,这就是动态规划法求 解问题的自底向上的方法。