【CN110033822A】蛋白质编码方法及蛋白质翻译后修饰位点预测方法及系统【专利】
蛋白质修饰位点预测

蛋白质修饰位点预测
蛋白质修饰位点预测是生物信息学领域的一个重要研究方向。
蛋白质修饰是一种在蛋白质翻译后发生的化学变化,对蛋白质的功能和活性产生重要影响。
目前,许多生物信息学方法已经被开发用于预测蛋白质修饰位点,主要包括以下几种:
1. 基于机器学习的方法:这类方法通过训练一个分类器(如支持向量机(SVM)、神经网络等)来预测蛋白质修饰位点。
这类方法通常需要大量的已知修饰位点和非修饰位点的蛋白质序列作为训练数据。
例如,研究人员针对水稻蛋白质磷酸化位点开发了一种基于SVM的预测工具[1]。
2. 基于氨基酸序列特征的方法:这类方法通过分析蛋白质序列中的氨基酸特征(如氨基酸频率、组成等)来预测修饰位点。
这类方法不需要依赖蛋白质结构信息,仅通过序列信息进行预测。
例如,研究人员利用氨基酸频率计算方法来进行特征提取,并结合SVM算法构建了一种针对水稻蛋白质磷酸化位点的预测工具[2]。
3. 基于结构的方法:这类方法通过分析蛋白质三维结构来预测修饰位点。
由于蛋白质结构与功能密切相关,这类方法具有较高的预测准确性。
然而,结构信息通常不易获取,且计算成本较高。
4. 集成学习方法:这类方法将多个预测模型进行集成,以提高预测准确性。
例如,研究人员将多个基于机器学习的预测模型进行集成,构建了一种针对蛋白质翻译后修饰位点的预测工具[3]。
总之,蛋白质修饰位点预测是一个具有挑战性的课题。
随着生物信息学技术的发展,未来可能会出现更多高效、准确的预测方法。
同时,蛋白质修饰位点预测在生物学研究中的应用也将越来越广泛,有助于揭示蛋白质功能和调控机制。
蛋白质后翻译修饰调控功能的关键

蛋白质后翻译修饰调控功能的关键蛋白质是生物体内最重要的分子之一,它们承担着各种功能,包括结构支持、催化反应和信号传导等。
然而,在蛋白质合成过程中,其后翻译修饰对于蛋白质的功能和调控起着至关重要的作用。
本文将就蛋白质后翻译修饰的关键功能进行讨论。
一、翻译后修饰的概念及分类蛋白质的后翻译修饰是指在蛋白质合成完成后,通过化学修饰或酶催化作用改变蛋白质分子的结构和功能的一系列过程。
根据修饰的方式和效应,可以将蛋白质后翻译修饰分为多个类别,如磷酸化、乙酰化、甲基化等。
二、翻译后修饰的功能与调控1. 磷酸化修饰:磷酸化是最为常见的蛋白质后翻译修饰方式之一。
它通过磷酸基团的添加或去除,改变蛋白质的电荷状态,从而调控蛋白质的稳定性、结构和活性。
例如,磷酸化修饰可以调节细胞周期的进行,控制细胞的增殖和分化。
2. 乙酰化修饰:乙酰化修饰主要发生在蛋白质的赖氨酸残基上,通过在目标蛋白质上加入乙酰基团来改变蛋白质的结构和功能。
乙酰化修饰在调控转录因子活性、细胞凋亡和DNA损伤修复等过程中发挥重要作用。
3. 甲基化修饰:甲基化修饰是通过在蛋白质上加入甲基基团来改变蛋白质的结构和活性。
甲基化修饰在调控基因表达、细胞分化和发育等过程中具有重要功能。
4. 糖基化修饰:糖基化修饰是指将糖类分子连接到蛋白质上,形成复合物的过程。
糖基化修饰对蛋白质的稳定性和功能起着重要的调控作用,同时还参与了细胞识别和免疫反应等过程。
5. 脂基化修饰:脂基化修饰是通过将脂质分子连接到蛋白质上来改变其性质和功能的修饰方式。
脂基化修饰在信号传导、细胞运动和细胞膜组装中起着重要作用。
三、翻译后修饰的调控机制蛋白质后翻译修饰的调控机制非常复杂精细,其主要涉及到多种酶、底物、信号通路和调控因子的相互作用。
例如,磷酸化修饰的酶称为激酶,而去磷酸化的酶则称为磷酸酶。
这些酶的活性和定位受到其他蛋白质的调控。
通过激酶和磷酸酶的平衡作用,可以维持磷酸化修饰的动态平衡,从而对蛋白质的功能进行调控。
蛋白质翻译后修饰的分子机制及其调控

蛋白质翻译后修饰的分子机制及其调控蛋白质是生命体中最为重要的分子之一,其组成了细胞的大部分结构和功能,并参与到了许多生命过程中。
但是蛋白质并不会直接出现在细胞中,而是通过基因的转录和翻译来合成出来。
而蛋白质的翻译过程除了对基因信息的传递外,还需要进行修饰,以使蛋白质能够在正确的位置和时间发挥作用。
蛋白质的修饰主要分为两类:翻译后修饰和翻译前修饰。
其中翻译前修饰主要发生在蛋白质的合成过程中,而翻译后修饰则是在蛋白质合成完成后,由一系列酶的作用来改变蛋白质的性质和功能。
而本文将主要介绍蛋白质翻译后修饰的分子机制及其调控。
一、翻译后修饰的种类蛋白质的翻译后修饰种类繁多,其中较为重要的包括磷酸化、乙酰化、脱乙酰化、甲基化、泛素化、SUMO化、糖基化等。
下面将分别简要介绍这些修饰的特点和作用。
1. 磷酸化磷酸化是一种常见的蛋白质翻译后修饰方式,它是通过激酶将磷酸基团添加到蛋白质分子上,从而改变蛋白质的活性、局部结构以及相互作用。
磷酸化主要发生在蛋白质的氨基酸残基上,如丝氨酸、苏氨酸和酪氨酸等,称为磷酸化位点。
常见的磷酸化酶包括蛋白激酶A、蛋白激酶C、真核细胞激酶等。
2. 乙酰化和脱乙酰化乙酰化是一种通过酰化酶在赖氨酸残基上加入乙酰基的修饰方式,可以影响蛋白质的活性、进一步修饰和降解。
脱乙酰化是相反的过程,即将乙酰基从赖氨酸残基上去除。
乙酰化在许多生命过程中都有重要的作用,如基因转录、染色体修饰、周期性调控等。
3. 甲基化甲基化是一种将甲基基团加入蛋白质分子上的修饰方式,它主要发生在赖氨酸和精氨酸残基上。
甲基化可以影响蛋白质的稳定性、亲水性、生物活性等,还可以作为信号分子影响细胞过程。
4. 泛素化泛素化是一种将泛素蛋白加入到蛋白质分子上的修饰方式,它主要发生在拉链样蛋白和许多调节因子上。
泛素化可以作为信号分子引导受损蛋白质的降解、参与蛋白质的质量控制,同时也可以调节蛋白质的亲水性和亲脂性等生物学特性。
5. SUMO化SUMO化是一种将小泛素样修饰蛋白SUMO加入到蛋白质分子上的修饰方式。
【CN110033822A】蛋白质编码方法及蛋白质翻译后修饰位点预测方法及系统【专利】

(19)中华人民共和国国家知识产权局(12)发明专利申请(10)申请公布号 (43)申请公布日 (21)申请号 201910253412.9(22)申请日 2019.03.29(71)申请人 华中科技大学地址 430074 湖北省武汉市洪山区珞喻路1037号(72)发明人 薛宇 宁万山 许浩东 邓万锟 郭亚萍 (74)专利代理机构 华中科技大学专利中心42201代理人 孙杨柳 曹葆青(51)Int.Cl.G16B 15/20(2019.01)(54)发明名称蛋白质编码方法及蛋白质翻译后修饰位点预测方法及系统(57)摘要本发明公开了蛋白质编码方法及蛋白质翻译后修饰位点预测方法及系统,属于生物信息学领域。
所述蛋白质编码方法包括收集修饰位点信息、位置权重训练和待编码肽段的编码。
蛋白质翻译后修饰位点预测方法包括收集修饰位点信息、特征编码、模型训练和蛋白质翻译后修饰位点预测。
本发明利用深度神经网络和惩罚逻辑回归分别对不同类别的阳性位点和阴性位点的数字向量特征构建预测模型,得到多个预测模型;将每个预测模型的预测结果作为新的特征并利用惩罚逻辑回归构建最终模型。
本发明可以捕获更多蛋白信息从而有助于提高预测的准确度,可以快速的大规模鉴定蛋白质修饰位点。
权利要求书3页 说明书10页 附图3页CN 110033822 A 2019.07.19C N 110033822A1.一种蛋白质编码方法,其特征在于,所述蛋白质编码方法用于表示待编码肽段与阳性数据集肽段的相似度,含有以下步骤:(1)收集修饰位点信息:首先收集蛋白质翻译后目标类型的修饰位点信息;将所述目标类型的修饰位点在蛋白质上的对应位点作为阳性位点,将该蛋白质上与所述阳性位点相同的其它氨基酸位点作为阴性位点;将蛋白质的一级序列切割成以所述阳性位点或阴性位点为中心,该中心上游为n个氨基酸,该中心下游为n个氨基酸,总长度为2n+1个氨基酸序列;所述n大于等于1;所有含有所述阳性位点的所述氨基酸序列构成阳性数据集,所有含有所述阴性位点的所述氨基酸序列构成阴性数据集;(2)位置权重训练:步骤(1)所述阳性数据集和阴性数据集中的每个肽段与阳性数据集基于位置权重和氨基酸替换得分的相似度打分的公式为:其中:L为所述阳性数据集中每个肽段的长度2n+1;N为所述阳性数据集中肽段的数量;T ij是阳性数据集中肽段T i在位置j上的氨基酸,i的取值范围为1≤i≤N;P j为肽段在位置j 上的氨基酸;M[P j,T ij]为氨基酸P j和T ij在BLOSUM62氨基酸替换矩阵中的分值;W j为该肽段中位置j上的权重;所述阳性数据集和阴性数据集中的每条肽段分别与阳性数据集中的每条肽段依次打分,其中肽段不与其自身打分,初始位置权重W j为1,获得肽段中除中心位置以外的其它2n 个位置的得分;然后将该2n个位置的得分使用惩罚逻辑回归执行交叉验证,使AUC值最大的权重向量由肽段中各个位置上的权重W j组成;(3)待编码肽段的编码:待编码肽段与阳性数据集间的氨基酸对的平均相似度S为:其中:L是待编码肽段的长度,j为氨基酸所在位置,C j为待编码肽段与阳性数据集间的任意一个氨基酸对在位置j上出现的次数,M为所述氨基酸对在BLOSUM62氨基酸替换矩阵中的分值,W j为步骤(2)训练得到的待编码肽段位置j上的权重;待编码肽段与阳性数据集间的所有的氨基酸对的相似度得分构成该待编码肽段的数字向量特征。
蛋白质翻译后修饰位点预测及其功能分析

“沾光”,就是地方政府寻虎的真实心态,那么,究竟沾什么光,“光”又从何而来呢?
1.2 财政转移支付体制
1994年中央政府进行财政体制改革7,实行分税制,上收地方财权,钱向中央财政系统集中,地方政府的财政自主权大大削弱。
“取之于民”的财政收入最终要通过财政支出的形式花出去,集中在中央财政系统里的钱,主要通过中央对地方进行转移支付的方式“用之于民”,目前的财政转移支付包括体制性转移支付、财力性转移支付和专项转移支付8三种。
蛋白质翻译后修饰位点预测及其功能分析
作者:索生宝
学位授予单位:南昌大学
引用本文格式:索生宝蛋白质翻译后修饰位点预测及其功能分析[学位论文]硕士 2013
华中科技大学
华南虎照片公布几天后,陕西省林业厅便划出了华南虎特别保护区,10月18日林业厅便开始向陕西省政府和国家林业局申请建立国家级自然保护区,效率之高令人惊叹。依据《中华人民共和国自然保护区条例》,自然保护区分县级、省级、国家级三级,县级和省级自然保护区所需经费由地方政府安排,国家对国家级自然保护区给予适当的资金补助5。一般情况下,从县级开始,起码要花上五六年时间才可能评上国家级,镇坪县林业局局长覃大鹏透露,“省里的意思是,保护华南虎的工作非
蛋白质翻译后修饰
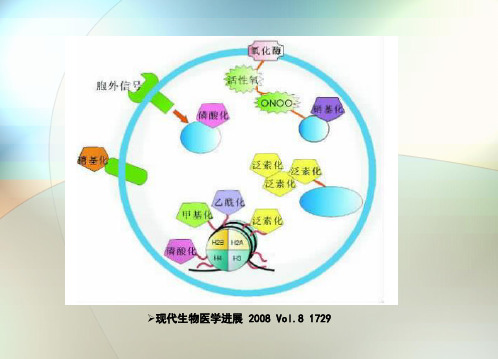
➢ 很长时间里,蛋白质翻译后修饰并未引起足够重视,直到 2004 年泛素介导蛋白质降解的发现获得诺贝尔奖之后,这一 情形才有明显改观。迄今,人们已发现多达200 多种的蛋白 质修饰。蛋白质翻译后修饰是调节蛋白质生物学功能的关键 步骤之一,是蛋白质动态反应和相互作用的一个重要分子基 础,同时,它也是细胞信号网络调控的重要靶点。
2.糖基化
➢ 真核生物中糖基化修饰很普遍。 ➢ 通常情况下,分泌蛋白的寡糖链较复杂,而内质网膜蛋白含有
较高的甘露糖。 下图是细胞中涉及糖基化的蛋白
3.羟基化
在结缔组织的胶原蛋白和弹性蛋白中pro和lys是经过羟基化的。 此外,在乙酰胆碱酯酶(降解神经递质乙酰胆碱)和补体系统(参 与免疫反应的一系列血清蛋白)都发现有4-羟辅氨酸。 位 于 粗 糙 内 质 网 ( RER ) 上 的 三 种 氧 化 酶 ( 脯 氨 酰 -4- 羟 化 酶 , prolyl-4-hydroxylase , 脯 氨 酰 -3- 羟 化 酶 和 赖 氨 酰 羟 化 酶 , lysylhydroxylase)负责特定pro和lys残基的羟化。 脯氨酰-4-羟化酶只羟化-Gly-x-pro-,脯氨酰-3-羟化酶羟化Glypro-4-Hyp(Hyp: hydroxyproline),赖氨酸羟化酶只作用于Gly-X-lys-。 胶原蛋白的脯氨酸残基和赖氨酸残基羟化需要Vc,饮食中Vc不足时 就易患坏血症(血管脆弱,伤口难愈),原因就是胶原纤维的结构 不力(weak collagen fiber structure)。
3.甲基化
➢ 蛋白质的甲基化是指在甲基转移酶催化下,甲基基团由S- 腺 苷基甲硫氨酸转移至相应蛋白质的过程,既可以形成可逆的 甲基化修饰,如羧基端的甲基化修饰;也可以形成不可逆的 甲基化修饰,如氨基端的甲基化修饰。在原核生物中也普遍 存在蛋白质的甲基化。
蛋白质的翻译后修饰和调控

蛋白质的翻译后修饰和调控蛋白质是生命活动中最为重要的分子之一,它们既可以是细胞的结构组成,也可以作为代谢酶、激素、调节因子等生物分子的重要载体。
蛋白质的结构和功能不仅与其天然的氨基酸序列有关,还与其经过多种酶催化的修饰过程密切相关。
这些修饰包括:翻译后修饰、翻译后超表达、裂解和脱附等。
本文将重点探讨蛋白质的翻译后修饰和调控。
一、蛋白质翻译后修饰敲蛋白质的翻译过程通常被认为是从N-到C-端,从氨基基团到羧基,由核酸和翻译机械制成。
生物细胞内的合成蛋白质,则需要进行多种酶的修饰,以使其最终呈现出所要求的生物活性和三维结构。
1. 磷酸化磷酸化是蛋白质修饰的最为普遍的一种方式,通常是由一些酪氨酸或苏氨酸上的酸性侧链上结合的磷酸基所完成。
磷酸化可以使蛋白质结构和荷电特性发生改变,进而影响蛋白质的结合和催化活性。
2. 糖基化蛋白质上的糖基化通常是由一种糖基转移酶催化的,常见的糖基包括N-糖基、O-糖基和C-糖基等。
这些糖基化行为通常可以增强蛋白质的稳定性和生物学活性,还可以改变蛋白质的质量和凝聚性质。
3. 甲基化和乙酰化蛋白质上还经常会发生一些特定结构上的编辑修饰,如甲基化和乙酰化等。
这些修饰可以影响某些细胞稳定性和外界刺激对蛋白质的响应。
二、蛋白质翻译后调控蛋白质合成不仅受制于基因表达水平和翻译效率,还受到各种内部和外部因素的调控。
下面分别分析各种调控因素。
1.蛋白酶降解蛋白质的稳定性一般由蛋白酶进行去催化。
当细胞感觉到一定的环境刺激,如氧化应激或低钙离子等,在一个较短的时间内,通常会发生蛋白酶催化或蛋白利氧化等情况。
2.磷酸酶反应蛋白质的翻译后编辑修饰中,蛋白酶对蛋白质的磷酸化处于一种动态调控周期。
在细胞中,有一类蛋白质酶能够催化磷酸化的去除,并且有很好的选择性。
这意味着当细胞需要调节某些类型蛋白质的磷酸化状态时,通过控制这些蛋白质磷酸酶反应来实现。
3.转录因子转录因子是一些能够识别DNA序列的特异性蛋白质,它们可以促进或阻止基因的转录。
基于生物大数据的蛋白质翻译后修饰预测方法

基于生物大数据的蛋白质翻译后修饰预测方法蛋白质是生物体中起着关键功能的分子,它们的功能和结构都受到一系列修饰的调控。
蛋白质翻译后修饰是指蛋白质在翻译完成后,通过附加特定的化学基团或其他功能元件来改变其结构和功能的过程。
这些修饰可以改变蛋白质的稳定性、活性、亚细胞定位和相互作用能力,从而调控细胞的生理过程。
因此,准确预测蛋白质翻译后修饰对于深入理解蛋白质功能以及相关疾病的发生机制具有重要意义。
随着高通量测序技术的发展,大量的生物数据被积累和共享,为蛋白质翻译后修饰预测提供了丰富的资源。
生物大数据可以包括转录组、蛋白质互作、基因组、表观基因组和代谢组等多个层次的数据。
这些数据为预测蛋白质翻译后修饰提供了丰富的信息,从而帮助科学家们研究蛋白质的结构和功能。
基于生物大数据的蛋白质翻译后修饰预测方法主要依赖于机器学习和人工智能算法。
这些方法通常包括以下几个步骤:数据收集、数据预处理、特征提取、模型构建和模型评估。
首先,需要从公共数据库或实验室测序中获取相关数据,并对数据进行整理和清洗,以保证数据的可靠性和一致性。
然后,根据不同的修饰类型,选择合适的特征提取方法,从数据中提取出与修饰相关的特征信息。
接下来,利用机器学习算法构建预测模型,并使用交叉验证等方法评估模型的性能。
最后,根据评估结果对模型进行改进和优化,以提高预测准确率和稳定性。
目前,有许多基于生物大数据的蛋白质翻译后修饰预测方法被提出,并取得了一定的成果。
例如,利用转录组和蛋白质互作数据可以预测磷酸化修饰,利用基因组和表观基因组数据可以预测乙酰化修饰,利用代谢组数据可以预测甲基化修饰等。
这些方法在不同生物体和生态系统中都取得了一定的成功,为理解蛋白质功能的多样性和复杂性提供了重要的线索。
然而,基于生物大数据的蛋白质翻译后修饰预测方法还存在一些挑战和局限性。
首先,生物大数据的质量和数量仍然是一个问题,需要确保数据的准确性和可靠性。
其次,现有的预测模型往往需要大量的计算资源和时间,限制了其在大规模数据集上的应用。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
(19)中华人民共和国国家知识产权局
(12)发明专利申请
(10)申请公布号 (43)申请公布日 (21)申请号 201910253412.9
(22)申请日 2019.03.29
(71)申请人 华中科技大学
地址 430074 湖北省武汉市洪山区珞喻路
1037号
(72)发明人 薛宇 宁万山 许浩东 邓万锟
郭亚萍
(74)专利代理机构 华中科技大学专利中心
42201
代理人 孙杨柳 曹葆青
(51)Int.Cl.
G16B 15/20(2019.01)
(54)发明名称
蛋白质编码方法及蛋白质翻译后修饰位点
预测方法及系统
(57)摘要
本发明公开了蛋白质编码方法及蛋白质翻
译后修饰位点预测方法及系统,属于生物信息学
领域。
所述蛋白质编码方法包括收集修饰位点信
息、位置权重训练和待编码肽段的编码。
蛋白质
翻译后修饰位点预测方法包括收集修饰位点信
息、特征编码、模型训练和蛋白质翻译后修饰位
点预测。
本发明利用深度神经网络和惩罚逻辑回
归分别对不同类别的阳性位点和阴性位点的数
字向量特征构建预测模型,得到多个预测模型;
将每个预测模型的预测结果作为新的特征并利
用惩罚逻辑回归构建最终模型。
本发明可以捕获
更多蛋白信息从而有助于提高预测的准确度,
可
以快速的大规模鉴定蛋白质修饰位点。
权利要求书3页 说明书10页 附图3页CN 110033822 A 2019.07.19
C N 110033822
A
1.一种蛋白质编码方法,其特征在于,所述蛋白质编码方法用于表示待编码肽段与阳性数据集肽段的相似度,含有以下步骤:
(1)收集修饰位点信息:首先收集蛋白质翻译后目标类型的修饰位点信息;将所述目标类型的修饰位点在蛋白质上的对应位点作为阳性位点,将该蛋白质上与所述阳性位点相同的其它氨基酸位点作为阴性位点;将蛋白质的一级序列切割成以所述阳性位点或阴性位点为中心,该中心上游为n个氨基酸,该中心下游为n个氨基酸,总长度为2n+1个氨基酸序列;所述n大于等于1;所有含有所述阳性位点的所述氨基酸序列构成阳性数据集,所有含有所述阴性位点的所述氨基酸序列构成阴性数据集;
(2)位置权重训练:步骤(1)所述阳性数据集和阴性数据集中的每个肽段与阳性数据集基于位置权重和氨基酸替换得分的相似度打分的公式为:
其中:L为所述阳性数据集中每个肽段的长度2n+1;N为所述阳性数据集中肽段的数量;T ij 是阳性数据集中肽段T i 在位置j上的氨基酸,i的取值范围为1≤i≤N;P j 为肽段在位置j 上的氨基酸;M[P j ,T ij ]为氨基酸P j 和T ij 在BLOSUM62氨基酸替换矩阵中的分值;W j 为该肽段中位置j上的权重;
所述阳性数据集和阴性数据集中的每条肽段分别与阳性数据集中的每条肽段依次打分,其中肽段不与其自身打分,初始位置权重W j 为1,获得肽段中除中心位置以外的其它2n 个位置的得分;然后将该2n个位置的得分使用惩罚逻辑回归执行交叉验证,使AUC值最大的权重向量由肽段中各个位置上的权重W j 组成;
(3)待编码肽段的编码:
待编码肽段与阳性数据集间的氨基酸对的平均相似度S为:其中:L是待编码肽段的长度,j为氨基酸所在位置,C j 为待编码肽段与阳性数据集间的任意一个氨基酸对在位置j上出现的次数,M为所述氨基酸对在BLOSUM62氨基酸替换矩阵中的分值,W j 为步骤(2)训练得到的待编码肽段位置j上的权重;待编码肽段与阳性数据集间的所有的氨基酸对的相似度得分构成该待编码肽段的数字向量特征。
2.多特征算法模型的蛋白质翻译后修饰位点预测方法,其特征在于,含有以下步骤:
(1)收集修饰位点信息:收集蛋白质翻译后目标类型的修饰位点信息;将所述目标类型的修饰位点在蛋白质上的对应位点作为阳性位点,将该蛋白质上与所述阳性位点相同的其它氨基酸位点作为阴性位点;将所述阳性位点和阴性位点按照蛋白质所属物种进行分类;将蛋白质的一级序列切割成以所述阳性位点或阴性位点为中心,该中心上游为n个氨基酸,该中心下游为n个氨基酸,总长度为2n+1个氨基酸的序列;所述n大于等于1;
(2)特征编码:将权利要求1所述的蛋白质编码方法以及其它的编码方案逐个对步骤
(1)所述总长度为2n+1个氨基酸的序列进行特征编码,得到数字向量特征,将所述数字向量特征分别利用惩罚逻辑回归、支持向量机和随机森林验证每种编码方案的AUC性能,将AUC 性能大于0.5的编码方案作为备用编码方案;挑选所述备用编码方案对步骤(1)所述总长度为2n+1个氨基酸的序列进行特征编码得到的数字向量特征;
(3)模型训练:利用深度神经网络和惩罚逻辑回归分别对步骤(2)所述不同类别的阳性位点和阴性位点的数字向量特征构建预测模型,得到多个预测模型;将每个预测模型的预
权 利 要 求 书1/3页2CN 110033822 A。