计量经济学第三章课后习题详解
计量经济学(第四版)第三章练习题及答案
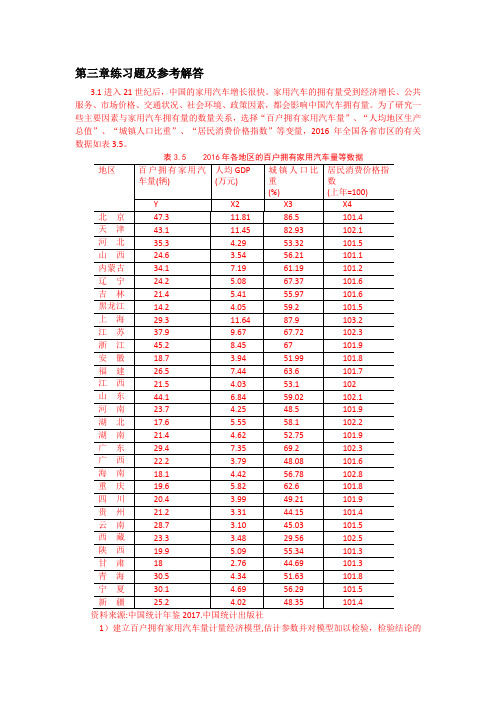
第三章练习题及参考解答3.1进入21世纪后,中国的家用汽车增长很快。
家用汽车的拥有量受到经济增长、公共服务、市场价格、交通状况、社会环境、政策因素,都会影响中国汽车拥有量。
为了研究一些主要因素与家用汽车拥有量的数量关系,选择“百户拥有家用汽车量”、“人均地区生产总值”、“城镇人口比重”、“居民消费价格指数”等变量,2016年全国各省市区的有关数据如表3.5。
表3.5 2016年各地区的百户拥有家用汽车量等数据资料来源:中国统计年鉴2017.中国统计出版社1)建立百户拥有家用汽车量计量经济模型,估计参数并对模型加以检验,检验结论的依据是什么?。
2)分析模型参数估计结果的经济意义,你如何解读模型估计检验的结果? 3) 你认为模型还可以如何改进?【练习题3.1 参考解答】:1)建立线性回归模型: 1223344t t t t t Y X X X u ββββ=++++ 回归结果如下:由F 统计量为14.69998, P 值为0.000007,可判断模型整体上显著, “人均地区生产总值”、“城镇人口比重”、“居民消费价格指数”等变量联合起来对百户拥有家用汽车量有显著影响。
解释变量参数的t 统计量的绝对值均大于临界值0.025(27) 2.052t =,或P 值均明显小于0.05α=,表明在其他变量不变的情况下,“人均地区生产总值”、“城镇人口比重”、“居民消费价格指数”分别对百户拥有家用汽车量都有显著影响。
2)X2的参数估计值为4.8117,表明随着经济的增长,人均地区生产总值每增加1万元,平均说来百户拥有家用汽车量将增加近5辆。
由于城镇公共交通的大力发展,有减少家用汽车的必要性,X3的参数估计值为-0.4449,表明随着城镇化的推进,“城镇人口比重”每增加1%,平均说来百户拥有家用汽车量将减少0.4449辆。
汽车价格和使用费用的提高将抑制家用汽车的使用, X4的参数估计值为-5.7685,表明随着家用汽车使用成本的提高, “居民消费价格指数”每增加1个百分点,平均说来百户拥有家用汽车量将减少5.7685辆。
(NEW)李子奈《计量经济学》(第3版)课后习题详解

目 录第1章 绪 论第2章 经典单方程计量经济学模型:一元线性回归模型第3章 经典单方程计量经济学模型:多元线性回归模型第4章 经典单方程计量经济学模型:放宽基本假定的模型第5章 经典单方程计量经济学模型:专门问题第6章 联立方程计量经济学模型:理论与方法第7章 扩展的单方程计量经济学模型第8章 时间序列计量经济学模型第9章 计量经济学应用模型第1章 绪 论1什么是计量经济学?计量经济学方法与一般经济数学方法有什么区别?答:(1)计量经济学是经济学的一个分支学科,以揭示经济活动中客观存在的数量关系为主要内容,是由经济理论、统计学和数学三者结合而成的交叉学科。
(2)计量经济学方法通过建立随机的数学方程来描述经济活动,并通过对模型中参数的估计来揭示经济活动中各个因素之间的定量关系,是对经济理论赋予经验内容;而一般经济数学方法是以确定性的数学方程来描述经济活动,揭示的是经济活动中各个因素之间的理论关系。
2计量经济学的研究对象和内容是什么?计量经济学模型研究的经济关系有哪两个基本特征?答:(1)计量经济学的研究对象是经济现象,主要研究的是经济现象中的具体数量规律,即是利用数学方法,依据统计方法所收集和整理到的经济数据,对反映经济现象本质的经济数量关系进行研究。
(2)计量经济学的内容大致包括两个方面:一是方法论,即计量经济学方法或理论计量经济学;二是应用计量经济学。
任何一项计量经济学研究和任何一个计量经济学模型赖以成功的三要素是理论、方法和数据。
(3)计量经济学模型研究的经济关系的两个基本特征是随机关系和因果关系。
3为什么说计量经济学在当代经济学科中占据重要地位?当代计量经济学发展的基本特征与动向是什么?答:(1)计量经济学自20世纪20年代末30年代初形成以来,无论在技术方法还是在应用方面发展都十分迅速,尤其是经过20世纪50年代的发展阶段和60年代的扩张阶段,使其在经济学科占据重要的地位,主要表现在:①在西方大多数大学和学院中,计量经济学的讲授已成为经济学课程表中最具有权威的一部分;②从1969~2003年诺贝尔经济学奖的53位获奖者中有10位是与研究和应用计量经济学有关;③计量经济学方法与其他经济数学方法结合应用得到了长足的发展。
计量经济学第三章练习题及参考全部解答

计量经济学第三章练习题及参考全部解答第三章练习题及参考解答3.1为研究中国各地区入境旅游状况,建立了各省市旅游外汇收入(Y ,百万美元)、旅行社职工人数(X1,人)、国际旅游人数(X2,万人次)的模型,用某年31个省市的截面数据估计结果如下:ii i X X Y 215452.11179.00263.151?++-= t=(-3.066806)(6.652983) (3.378064)R 2=0.934331 92964.02=R F=191.1894 n=31 1)从经济意义上考察估计模型的合理性。
2)在5%显著性水平上,分别检验参数21,ββ的显著性。
3)在5%显著性水平上,检验模型的整体显著性。
练习题3.1参考解答:(1)由模型估计结果可看出:从经济意义上说明,旅行社职工人数和国际旅游人数均与旅游外汇收入正相关。
平均说来,旅行社职工人数增加1人,旅游外汇收入将增加0.1179百万美元;国际旅游人数增加1万人次,旅游外汇收入增加1.5452百万美元。
这与经济理论及经验符合,是合理的。
(2)取05.0=α,查表得048.2)331(025.0=-t 因为3个参数t 统计量的绝对值均大于048.2)331(025.0=-t ,说明经t 检验3个参数均显著不为0,即旅行社职工人数和国际旅游人数分别对旅游外汇收入都有显著影响。
(3)取05.0=α,查表得34.3)28,2(05.0=F ,由于34.3)28,2(1894.19905.0=>=F F ,说明旅行社职工人数和国际旅游人数联合起来对旅游外汇收入有显著影响,线性回归方程显著成立。
3.2 表3.6给出了有两个解释变量2X 和.3X 的回归模型方差分析的部分结果:表3.6 方差分析表1)回归模型估计结果的样本容量n 、残差平方和RSS 、回归平方和ESS 与残差平方和RSS 的自由度各为多少?2)此模型的可决系数和调整的可决系数为多少? 3)利用此结果能对模型的检验得出什么结论?能否确定两个解释变量2X 和.3X 各自对Y 都有显著影响?练习题3.2参考解答:(1) 因为总变差的自由度为14=n-1,所以样本容量:n=14+1=15 因为TSS=RSS+ESS 残差平方和RSS=TSS-ESS=66042-65965=77 回归平方和的自由度为:k-1=3-1=2 残差平方和RSS 的自由度为:n-k=15-3=12(2)可决系数为:2659650.99883466042ES R TSS S === 修正的可决系数:222115177110.998615366042i i e n R n k y --=-=-?=--∑∑(3)这说明两个解释变量2X 和.3X 联合起来对被解释变量有很显著的影响,但是还不能确定两个解释变量2X 和.3X 各自对Y 都有显著影响。
计量经济学第3章参考答案

(3) = TSS
RSS 480 = = 750 2 1− R 1 − 0.36
7. 答: (1) cov( = x, y )
1 2 2 ( xt − x )( y = r σx σ y = 0.9 × 16 ×10 =11.38 ∑ t − y) n −1
∑ ( x − x )( y − y )=
即表明截距项也显著不为 0,通过了显著性检验。 (3)Yf=2.17+0.2023×45=11.2735
2 1 (x f − x ) 1 (45 − 29.3) 2 ˆ 1+ + = × × + = 4.823 t0.025 (8) × σ 1.8595 2.2336 1+ n ∑ ( x −x ) 2 10 992.1
3
2
五、综合题 1. 答: (1)建立深圳地方预算内财政收入对 GDP 的回归模型,建立 EViews 文件,利用地方预 算内财政收入(Y)和 GDP 的数据表,作散点图
可看出地方预算内财政收入(Y)和 GDP 的关系近似直线关系,可建立线性回归模型:
Yt = β1 + β 2 GDPt + u t
第 3 章参考答案
一、名词解释 1. 高斯-马尔可夫定理:在古典假定条件下,OLS 估计量是模型参数的最佳线性无偏估计 量,这一结论即是高斯-马尔可夫定理。 2. 总变差(总离差平方和) :在回归模型中,被解释变量的观测值与其均值的离差平方和。 3. 回归变差(回归平方和) :在回归模型中,因变量的估计值与其均值的离差平方和,也就 是由解释变量解释的变差。 4. 剩余变差(残差平方和) :在回归模型中,因变量的观测值与估计值之差的平方和,是不 能由解释变量所解释的部分变差。 5. 估计标准误差:在回归模型中,随机误差项方差的估计量的平方根。 6. 样本决定系数:回归平方和在总变差中所占的比重。 7. 拟合优度:样本回归直线与样本观测数据之间的拟合程度。 8. 估计量的标准差:度量一个变量变化大小的测量值。 9. 协方差:用 Cov(X,Y)表示,度量 X,Y 两个变量关联程度的统计量。 10. 显著性检验:利用样本结果,来证实一个虚拟假设的真伪的一种检验程序。 11. 拟合优度检验:检验模型对样本观测值的拟合程度,用 R 2 表示,该值越接近 1,模型 对样本观测值拟合得越好。 12. t 检验:是针对每个解释变量进行的显著性检验,即构造一个 t 统计量,如果该统计量 的值落在置信区间外,就拒绝原假设。 13. 点预测:给定自变量的某一个值时,利用样本回归方程求出相应的样本拟合值,以此作 为因变量实际值均值的估计值。
计量经济学(第四版)第三章练习题及答案
第三章练习题及参考解答3.1进入21世纪后,中国的家用汽车增长很快。
家用汽车的拥有量受到经济增长、公共服务、市场价格、交通状况、社会环境、政策因素,都会影响中国汽车拥有量。
为了研究一些主要因素与家用汽车拥有量的数量关系,选择“百户拥有家用汽车量”、“人均地区生产总值”、“城镇人口比重”、“居民消费价格指数”等变量,2016年全国各省市区的有关数据如表3.5。
表3.5 2016年各地区的百户拥有家用汽车量等数据资料来源:中国统计年鉴2017.中国统计出版社1)建立百户拥有家用汽车量计量经济模型,估计参数并对模型加以检验,检验结论的依据是什么?。
2)分析模型参数估计结果的经济意义,你如何解读模型估计检验的结果? 3) 你认为模型还可以如何改进?【练习题3.1 参考解答】:1)建立线性回归模型: 1223344t t t t t Y X X X u ββββ=++++ 回归结果如下:由F 统计量为14.69998, P 值为0.000007,可判断模型整体上显著, “人均地区生产总值”、“城镇人口比重”、“居民消费价格指数”等变量联合起来对百户拥有家用汽车量有显著影响。
解释变量参数的t 统计量的绝对值均大于临界值0.025(27) 2.052t =,或P 值均明显小于0.05α=,表明在其他变量不变的情况下,“人均地区生产总值”、“城镇人口比重”、“居民消费价格指数”分别对百户拥有家用汽车量都有显著影响。
2)X2的参数估计值为4.8117,表明随着经济的增长,人均地区生产总值每增加1万元,平均说来百户拥有家用汽车量将增加近5辆。
由于城镇公共交通的大力发展,有减少家用汽车的必要性,X3的参数估计值为-0.4449,表明随着城镇化的推进,“城镇人口比重”每增加1%,平均说来百户拥有家用汽车量将减少0.4449辆。
汽车价格和使用费用的提高将抑制家用汽车的使用, X4的参数估计值为-5.7685,表明随着家用汽车使用成本的提高, “居民消费价格指数”每增加1个百分点,平均说来百户拥有家用汽车量将减少5.7685辆。
计量经济学(第二版)第三章习题答案

1)建立家庭书刊消费的计量经济模型: i i i i u T X Y +++=321βββ其中:Y 为家庭书刊年消费支出、X 为家庭月平均收入、T 为户主受教育年数 (2)估计模型参数,结果为即 i ii T X Y 3703.5208645.00162.50ˆ++-= (49.46026)(0.02936) (5.20217) t= (-1.011244) (2.944186) (10.06702) R 2=0.951235 944732.02=R F=146.2974(3) 检验户主受教育年数对家庭书刊消费是否有显著影响:由估计检验结果, 户主受教育年数参数对应的t 统计量为10.06702, 明显大于t 的临界值131.2)318(025.0=-t ,同时户主受教育年数参数所对应的P 值为0.0000,明显小于05.0=α,均可判断户主受教育年数对家庭书刊消费支出确实有显著影响。
(4)本模型说明家庭月平均收入和户主受教育年数对家庭书刊消费支出有显著影响,家庭月平均收入增加1元,家庭书刊年消费支出将增加0.086元,户主受教育年数增加1年,家庭书刊年消费支出将增加52.37元。
Dependent Variable: LNYMethod: Least SquaresDate: 03/21/12 Time: 23:11Sample: 1970 1982Variable Coefficient Std. Error t-Statistic Prob.C 2.899899 0.500289 5.796453 0.0002LNX2 -1.205700 0.320662 -3.760041 0.0037R-squared 0.849114 Mean dependent var 1.974525 Adjusted R-squared 0.818937 S.D. dependent var 0.408050 S.E. of regression 0.173631 Akaike info criterion -0.464591 Sum squared resid 0.301478 Schwarz criterion -0.334218 Log likelihood 6.019839 F-statistic 28.13760 Durbin-Watson stat 1.822175 Prob(F-statistic) 0.000078。
计量经济学第三章多元线性回归模型习题

第三章练习题及参考解答3.1为研究中国各地区入境旅游状况,建立了各省市旅游外汇收入(Y ,百万美元)、旅行社职工人数(X1,人)、国际旅游人数(X2,万人次)的模型,用某年31个省市的截面数据估计结果如下:ii i X X Y 215452.11179.00263.151ˆ++-= t=(-3.066806) (6.652983) (3.378064)R 2=0.934331 92964.02=R F=191.1894 n=311)从经济意义上考察估计模型的合理性。
2)在5%显著性水平上,分别检验参数21,ββ的显著性。
3)在5%显著性水平上,检验模型的整体显著性。
练习题3.1参考解答:(1)由模型估计结果可看出:从经济意义上说明,旅行社职工人数和国际旅游人数均与旅游外汇收入正相关。
平均说来,旅行社职工人数增加1人,旅游外汇收入将增加0.1179百万美元;国际旅游人数增加1万人次,旅游外汇收入增加1.5452百万美元。
这与经济理论及经验符合,是合理的。
(2)取05.0=α,查表得048.2)331(025.0=-t 因为3个参数t 统计量的绝对值均大于048.2)331(025.0=-t ,说明经t 检验3个参数均显著不为0,即旅行社职工人数和国际旅游人数分别对旅游外汇收入都有显著影响。
(3)取05.0=α,查表得34.3)28,2(05.0=F ,由于34.3)28,2(1894.19905.0=>=F F ,说明旅行社职工人数和国际旅游人数联合起来对旅游外汇收入有显著影响,线性回归方程显著成立。
3.2 表3.6给出了有两个解释变量2X 和.3X 的回归模型方差分析的部分结果:表3.6 方差分析表RSS 的自由度各为多少?2)此模型的可决系数和调整的可决系数为多少?3)利用此结果能对模型的检验得出什么结论?能否确定两个解释变量2X 和.3X 各自对Y 都有显著影响?练习题3.2参考解答:(1) 因为总变差的自由度为14=n-1,所以样本容量:n=14+1=15因为 TSS=RSS+ESS 残差平方和RSS=TSS-ESS=66042-65965=77回归平方和的自由度为:k-1=3-1=2残差平方和RSS 的自由度为:n-k=15-3=12(2)可决系数为:2659650.99883466042ES R TSS S === 修正的可决系数:222115177110.998615366042i ie n R n ky--=-=-=ᄡ--¥¥(3)这说明两个解释变量2X 和.3X 联合起来对被解释变量有很显著的影响,但是还不能确定两个解释变量2X 和.3X 各自对Y 都有显著影响。
计量经济学(第四版)第三章练习题及答案
第三章练习题及参考解答3.1进入21世纪后,中国的家用汽车增长很快。
家用汽车的拥有量受到经济增长、公共服务、市场价格、交通状况、社会环境、政策因素,都会影响中国汽车拥有量。
为了研究一些主要因素与家用汽车拥有量的数量关系,选择“百户拥有家用汽车量”、“人均地区生产总值”、“城镇人口比重”、“居民消费价格指数”等变量,2016年全国各省市区的有关数据如表3.5。
表3.5 2016年各地区的百户拥有家用汽车量等数据资料来源:中国统计年鉴2017.中国统计出版社1)建立百户拥有家用汽车量计量经济模型,估计参数并对模型加以检验,检验结论的依据是什么?。
2)分析模型参数估计结果的经济意义,你如何解读模型估计检验的结果? 3) 你认为模型还可以如何改进?【练习题3.1 参考解答】:1)建立线性回归模型: 1223344t t t t t Y X X X u ββββ=++++ 回归结果如下:由F 统计量为14.69998, P 值为0.000007,可判断模型整体上显著, “人均地区生产总值”、“城镇人口比重”、“居民消费价格指数”等变量联合起来对百户拥有家用汽车量有显著影响。
解释变量参数的t 统计量的绝对值均大于临界值0.025(27) 2.052t =,或P 值均明显小于0.05α=,表明在其他变量不变的情况下,“人均地区生产总值”、“城镇人口比重”、“居民消费价格指数”分别对百户拥有家用汽车量都有显著影响。
2)X2的参数估计值为4.8117,表明随着经济的增长,人均地区生产总值每增加1万元,平均说来百户拥有家用汽车量将增加近5辆。
由于城镇公共交通的大力发展,有减少家用汽车的必要性,X3的参数估计值为-0.4449,表明随着城镇化的推进,“城镇人口比重”每增加1%,平均说来百户拥有家用汽车量将减少0.4449辆。
汽车价格和使用费用的提高将抑制家用汽车的使用, X4的参数估计值为-5.7685,表明随着家用汽车使用成本的提高, “居民消费价格指数”每增加1个百分点,平均说来百户拥有家用汽车量将减少5.7685辆。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2011年各地区的百户拥有家用汽车量等数据河南湖北湖南广东广西海南重庆四川贵州云南西藏陕西甘肃青海宁夏新疆一、研究的目的和要求经济增长,公共服务、市场价格、交通状况,社会环境、政策因素都会影响中国汽车拥有量。
为了研究一些主要因素与家用汽车拥有量的数量关系,选择“人均地区生产总值”、“城镇人口比重”、“交通工具消费价格指数”等变量来进行研究和分析。
为了研究影响2011年各地区的百户拥有家用汽车量差异的主要原因,分析2011年各地区的百户拥有家用汽车量增长的数量规律,预测各地区的百户拥有家用汽车量的增长趋势,需要建立计量经济模型。
二、模型设定为了探究影响2011年各地区的百户拥有家用汽车量差异的主要原因,选择百户拥有家用汽车量为被解释变量,人均GDR城镇人口比重、交通工具消费价格指数为解释变量。
首先,建立工作文件、选择数据类型“integer data ”、“Start date ”中输入“ 1 ”,“End date ”中3>输入“ 31” ,在EViews 命令框直接键入“ data Y X2 X3 X4 ”,在对应的“ Y X2 X3 X4 ”下输入或粘贴相应 的数据。
探索将模型设定为线性回归模型形式: |Yt"=El 彳 映t 十" P4X4L + U L 三、 估计参数 在命令框中输入“ LS Y C X2 X3 X4 ” ,回车即出现下面的回归结果: 根据数据,模型估计的结果写为: Y t - 246.8540 1 5.99686SX, 0. 524027X 5 2.265680:<4 F= n=31 四、1.(1) 模型检验统计检验 拟合优度:由上表中的 数据可以得到:I 询=,修正的可决系数为 同=,这说明模型对样本的拟合一般。
说明解释变量“人 均地区生产总值”、“城镇人口比重”、“交通工具消费价格指数”联合起来对被解释变量“百户拥 有家用汽车量”做了绝大部分的解释。
(2) F 检验:针对1切B 2 - B B “=0,给定显著水平a =,在F 分布表中查出自由度为 k-1=3和n-k=27的临界值卜n(3,27)=,由上表可知 F=>(3,27)=,应拒绝原假设卩!=0,说明回归方程显著,即“人均地区生产总值”、“城镇人口比重”、“交通工具消费价格指数” “百户拥有家用汽车量”确实有显著影响。
变量联合起来确实对 (3) t 检验:分别针对4=0,给定显著水平a =查t 分布表得自由度为n-k=31-4=27 临界值(4)T- *to.03 ~(n-k)= T"t--to. 03 ~(n-k)=(27)=,与趴、B A B 弘& 4对应的t 统计量分别为、、、,其绝对值均大于(27)=,这说明在显著性水平 乜=下,分别都应当拒绝I : : - ..=0,也就是说,当在其他解释变量不变的情况下,解释变量“人均地区生产总值” (X2)、“城镇人口比重”(X3)、“交通工具消费价格指数” (X4)分别对被解释变量“百户拥有家用汽车量”( Y )都有显著的影响。
p 值判断:与Bi 、仏 B A 对应的P 值分别为:、、、,均,表明在小于,表明在显著水平应解释变量对被解释变量影响显著。
检验的依据:1> 合程度越好。
2> =的水平下,对可决系数越大,说明拟F 的值与临界值比较, 若大于临界值,则否定原假设,回归方程是显著的;若小于临界值,则接受原假设,回归方程不显著。
t 的值与临界值比较, 若大于临界值,则否定原假设,系数都是显著地;若小于临界值,则接受原假设,系数不显著。
4>较,若大于p 值,则可在显著性水平 a 下拒绝原假设,系数显著;若小于 不显著。
2.经济意义检验模型估计结果说明,在假定其他变量不变的情况下,人均GDP 每增加1万元,平均说来百户拥有家用汽车量将增加 ■ 辆城镇人口比重每增加1%平均说来百户拥有家用汽车量将减少 :瑟农为辆交通工具消费价格指数 龙n m 常小竝扩忙二 生皿廿辆这与理论分析和经验判断相一致。
五、模型改进1.1= - ■ ' ! 12. ' = ■ …-.=>拟合程度得到提高,所以也可以这样= 一改进模型。
W11拟合程度得到提高,所以也可以这0051论]-230 可样改进模型>拟合程度得到提高,所以也可以这样改进模型。
------------------------------1994〜2011年中国出口货物总额等数据年份 出口货物总额 Y/亿元工业增加值X2/亿元人民币汇率X3( 100美元)1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009 2010显著水平与p 值比 p 值,则接受原假设,系数3.= - - ■■ 丄・ ----- ■'1063.034 斗 5/8门 73X M 「6 5245O0U - 226LnXst - 2=>2011一、研究的目的和要求工业增加值、人民币汇率等都会影响出口货物总额。
为了研究一些主要因素与出口货物总额的数量关系,选择“工业增加值”、“人民币汇率”等变量来进行研究和分析。
为了研究影响1994~2011年每年年出口货物总额差异的主要原因,分析1994~2011年每年年出口货物总额增长的数量规律,预测每年年出口货物总额的增长趋势,需要建立计量经济模型。
二、模型设定为了探究影响1994~2011年每年年出口货物总额差异的主要原因,选择年出口货物总额为被解释变量,工业增加值、人民币汇率为解释变量。
首先,建立工作文件、选择数据类型“annual ”、“Start date ”中输入“1994”,“End date ”中输入“2011” 在EViews命令框直接键入“ data Y X2 X3 ”,在对应的“ Y X2 X3 ”下输入或粘贴相应的数据。
探索将模型设定为线性回归模型形式:^t-=Pi 1卩应盐+ + Pt建立出口货物总额计量经济模型:乩=:弓1卜卜Bjfct + Ut三、估计参数①对于计量经济模型:在命令框中输入“ LS Y C X2 X3 ” ,回车即出现下面的回归结果:根据数据,模型估计的结果写为:Y t -■ 1823L 58 ' 0.135474X; + 18.8531813t == 忙=F= n=18②对于计量经济模型:geniMny=log(y) ”“genr Inx2=log(x2) ” “LS InY C lnX2 X3 ” ,回车即出现下在命令框中依次输入“面的回归结果:根据数据,模型估计的结果写为:lnYt -■ L0.81090 + 1. 5737041^ + 0. 002438X3=F= n=18四、模型检验1. 统计检验对于计量经济模型:1)拟合优度:由上表中的数据可以得到:^=,修正的可决系数为臣=,这说明模型对样本的拟合很好。
说明解释变量“工业增加值”、“人民币汇率”联合起来对被解释变量“出口货物总额”做了绝大部分的解释。
2)F检验:针对血Bg - P 1=0,给定显著水平口=,在F分布表中查出自由度为k-仁2和n-k=15的临界值F口(2,15)=,由上表可知F= > (2,15)=,应拒绝原假设|二』:4「0,说明回归方程显著,即“工业增加值”、“人民币汇率”变量联合起来确实对“出口货物总额”确实有显著影响。
3)t检验:分别针对血|旳- 吐-X - 0,给定显著水平山=查t分布表得自由度为n-k=18-3=15临界值t oa tn. co _ ______ 亠l(n-k)= (15)=,与B, 对应的t统计量分别为t =、、,其绝对值除了吕:大于(n-k)= (15)=夕卜,其他均小于.这说明在显著性水平习=下,分别都应当接受}] C -歩7=0,也就是说,当在其他解释变量不变的情况下,“人民币汇率” (X3)对被解释变量“出口货物总额”(Y)亠 1 ico to.tfl 没有有显著的影响。
当在给定显著水平口=时,由于与B Q对应的t统计量为,大于丁(n-k)= 〒(15)=,所以应拒绝原假设Ho:卩2 - 0,表明在给定显著水平口=的显著性水平下,“工业增加值” (X2)对被解释变量“出口货物总额” (Y有显著的影响。
但是当给定显著性水平|口=时,查t分布表得自由度ft. id (ji- io 亠ic tmw 为n-k=18-3=15临界值T(n-k)= 寸1(15)=,与R:.对应的t统计量为,大于~(n-k)= 丁(15)=,表明在|口=的显著性水平下,“人民币汇率” (X3)对被解释变量“出口货物总额”(Y)有显著的影响。
这样的结论从上面的表中的P值也可以判断,与亍』估计值对应的P值为小于|口|=,表明在显著性水平|口=下,“工业增加值” (X2)对被解释变量“出口货物总额” (Y)有显著的影响。
与B E对应的P值为小于=,表明在=的显著性水平下,“人民币汇率” (X3)对被解释变量“出口货物总额” (Y)有显著的影响。
②对于计量经济模型:I = | ■1)拟合优度:由上表中的数据可以得到:R二=,修正的可决系数为臣=,这说明模型对样本的拟合很好。
说明解释变量“工业增加值的对数”、“人民币汇率”联合起来对被解释变量“出口货物总额的对数”做了绝大部分的解释。
2)F检验:针对山:Bg -卩<=0,给定显著水平。
=,在F分布表中查出自由度为k-仁2和n-k=15的临界值陪(2,15)=,由上表可知F= > (2,15)=,应拒绝原假设匸』:4「巴:」-0,说明回归方程显著,即“工业增加值的对数”、“人民币汇率”变量联合起来确实对“出口货物总额的对数”确实有显著影响。
3)t检验:分别针对山:0]-冃]-目3 - 0,给定显著水平|口=查t分布表得自由度为n-k=18-3=15临界值t aw f电佟亠亠亠二(n-k)= P(15)=,与R], 阳对应的t统计量分别为t =、、,其绝对值均大于(n-k)=;警(15)=,这说明在显著性水平=下,分别都应当拒绝射:.- - - 0,也就是说,当在其他解释变量不变的情况下,解释变量“工业增加值的对数”(lnX2 )、“人民币汇率” (X3)分别对被解释变量“出口货物总额的对数”(InY)都有显著的影响。
2.经济意义检验:①对于计量经济模型:(=趴+卩血* B為+X(讥-•丄823L 5&卜0.1354T4X」853⑹[』)模型估计结果说明,在假定其他变量不变的情况下,工业增加值每增加1亿元,平均说来出口货物总额将增加二:亿元人民币汇率每增加100美元,平均说来出口货物总额将增加範亿元这与理论分析和经验判断相一致。