中国知网学术不端文献检测系统
中国知网学术不端文献检测系统(含检测原理)

预防论文中的学术不端,除了提高认识、熟悉禁止事项外,还可以借助技术手段进行检测,提前发现论文中可能出现的问题,并及时纠正,确保正式提交的论文符合学术道德和学术规范的要求,以免影响论文答辩和期刊投稿。
目前,很多大学的学位论文管理机构和期刊编辑部都已经配置了中国知网CNKI和中国学术期刊(光盘版)编辑部联合开发的学术不端检测系统(简称TMLC) ,用以对本校学生的学位论文和本刊投稿论文进行学术不端检测。
本文对该系统作简单介绍。
一、系统简介学术论文学术不端行为检测系统由中国知网和中国学术期刊(光盘版)编辑部2008年12月底推出,2009年3月开始应用。
目前,已涵盖上千家期刊编辑部,360多家高校,基本覆盖了全国重点院校。
到目前为止,光是研究生学位论文检测,TMLC的检测量就已达到了20万篇次。
TMLC采用CNKI自主研发的自适应多阶指纹(AMLFP)特征检测技术,具有检测速度快、准确率和召回率高、抗干扰性强等特征。
不仅支持篇章、段落、句子的各层级检测,也支持文献改写、多篇文献组合等各种文献的变形检测。
TMLC以《中国学术文献网络出版总库》为全文比对数据库,实现了对抄袭与剽窃、伪造、篡改等学术不端行为的快速检测,可供用户检测学位论文、学术论文及着作等长文献,并支持用户自建比对库。
对任意一篇需要检测的文献,系统首先对其进行分层处理,按照篇章、段落、句子等层级分别创建指纹,而比对资源库中的比对文献,也采取同样技术创建指纹索引。
这样的分层多阶指纹结构,不仅可以满足对超长文献的快速检测,而且因为最小指纹粒度为句子,因此也满足了系统对检准率和检全率的高要求。
理论上,只要检测文献与比对文献存在一个相同的句子,就能被系统发现。
系统主要功能包括已发表文献检测、论文检测、问题库查询、自建比对库管理等。
其中,已发表文献检测,指检测系统能够自动将属于用户的已正式发表的论文检索出来,并对每一篇已发表文献进行实时检测,快速给出检测结果;论文检测,主要实现论文的实时在线检测;问题库查询,指用户可以将检测结果中确认有问题的文献放入问题库,便于用户集中管理;自建比对库,指管理人员可以选择将检测文献放入个人比对库或者批量上传文献作为个人比对库,该个人比对库即可作为以后学术不端文献检测的比对数据库。
“中国知网”大学生论文检测系统使用手册(学生)

“中国知网”大学生论文检测系统使用手册(学生)同方知网数字出版技术股份有限公司科研诚信技术分公司1.登录系统 (3)2.提交论文 (3)3.已提交论文 (5)3.1查看已提交论文 (6)3.2提交权限 (6)3.3检测结果查看 (7)3.3.1不允许查看检测结果 (7)3.3.2仅可查看文字复制比 (7)3.3.3可查看简洁报告单 (7)3.3.4可查看全文报告单 (8)3.4报告单 (8)3.4.1简洁报告单 (8)3.4.2全文报告单 (12)3.5写作助手 (13)3.6修改和审阅意见 (14)3.7附件下载 (14)4.论文列表 (14)5.用户资料 (16)6.修改密码 (16)1.登录系统使用学生账号和密码登录系统。
首先需要选择自己所在的学校名称。
点击学校输入框,在弹出的对话框中,选定学校。
系统提供了两种方法:一是根据地区和省市名称选择自己的学校;二是直接输入学校名称进行检索并选择。
学生在选择好学校的名称后,输入用户名、密码、选择身份(学生)、输入验证码,点击“登录”按钮登录系统。
2.提交论文如果学生账号没有上传过论文,登录系统后会进入到“提交新论文页面”。
也可以点击“提交新论文”按钮进入该页面;系统会提示论文状态为“待提交”,并显示提交次数。
进入“提交新论文”页面,页面上方显示学生账号的一些基本信息。
(1)选择指导教师:学生首次登录系统提交论文时,需要先选择指导教师。
点击“选择指导教师”,会弹出选择教师的弹框,可选择某个教师,或者输入搜索教师,选定即可(学生选择的教师将会在教师页面查看该学生上传的论文并进行评阅,请选择正确的指导教师)。
(2)填写论文基本信息:学生选好指导教师后,填写篇名、关键词、创新点、中文摘要和英文摘要。
(3)上传待检测论文:点击“浏览”按钮选择论文,点击“提交”按钮上传论文。
说明:如果管理员设置上传论文的截止时间,该截止时间到期之前学生可多次上传论文,系统在该截止时间到期时对学生上传的最新的论文进行检测。
学术不端文献检测系统50简明使用手册【模板】

学术不端文献检测系统5.0简明使用手册中国知网学术出版分社学位论文采编部二零一六年十二月目录目录 (1)第一章上传论文 (3)1.1文件夹管理 (3)1.1.1创建和修改文件夹 (4)1.1.2删除文件夹 (4)1.2上传检测文献 (4)1.2.1上传单篇/多篇文献 (5)1.2.2上传压缩文献 (5)1.2.3手工录入 (6)第二章检测结果 (6)2.1文献操作 (6)2.1.1选中文献报告单与下载报告单 (6)2.1.2文件夹报告单 (6)2.1.3导出Excel (6)2.1.4选择报告单 (7)2.2检测结果 (7)2.2.1 加入问题库及个人对比库 (8)2.2.2 文献分段浏览及修改 (8)第三章结果查询 (8)3.1文献查询及操作 (8)3.2查看检测结果 (9)第四章辅助功能 (9)4.1引文核对 (9)4.2两两比对 (9)4.3问题库 (10)第五章信息统计 (10)5.1文件夹信息统计 (10)5.2专业信息统计 (10)5.3年度报表 (11)第六章管理员中心 (11)6.1会员管理 (11)6.1.1 新增子账号 (11)6.1.2管理员账号信息 (11)6.2文献管理 (12)6.3会员查询 (12)6.4文献转移 (12)第七章设置 (13)7.1修改密码 (13)7.2 文件夹管理 (13)7.3个人比对库 (13)7.4一键清空 (14)7.5提建议 (14)第一章上传论文进入TMLC系统(【网址】)后,点击导航条“上传论文”进入上传论文页面。
注:也可以从检测结果页面点击“上传论文”进入上传论文页面。
1.1文件夹管理文件夹是用户管理论文的重要工具,用户可以根据实际需求创建文件夹、设置文件夹的属性。
合理的文件夹设置能有效的减轻用户的工作量。
1.1.1创建和修改文件夹用户可以在上传论文页面、检测结果页面左侧或设置——文件夹管理页面创建文件夹和修改文件夹信息。
用户可在文件夹信息页面根据实际需要选择对比库类型与范围,之后所有上传至该文件夹的文献都默认按照该对比库范围进行检测。
学术不端文献检测系统

学术不端文献检测系统学术不端文献检测系统是一种重要的工具,用于帮助学术界对论文的撰写进行评估和筛选。
该系统的主要功能是识别和检测学术文献中的各种不端行为,包括抄袭、篡改、伪造等,以保证学术研究的真实性和可靠性。
本文将介绍学术不端文献检测系统的工作原理和优势,并探讨其在学术界应用中的潜在挑战。
学术不端文献检测系统是基于人工智能技术开发的一种软件工具。
它通过大数据分析和算法模型构建,能够对文献中的内容进行全面扫描和比对。
首先,该系统会将待检测的文献与已有的学术数据库进行比对,以寻找潜在的相似性或重复内容。
其次,系统还能够检测出文献中的段落结构和句式模式,以判断是否存在抄袭或篡改行为。
最后,该系统还能够分析文献中的数据和实验结果,以排查是否存在虚假或伪造的研究成果。
学术不端文献检测系统的应用具有许多优势。
首先,它可以大大提高学术评审的效率和准确性。
传统的学术审稿过程依赖于专家的主观判断和经验,容易受到主观因素的影响,而该系统则可以客观、快速地发现潜在的不端行为,帮助评审专家做出更准确的判断。
其次,该系统可以促进学术诚信意识的培养。
存在不端行为的学者在被系统发现后,将面临严重的声誉损失和学术惩罚,从而提高了学者们对学术诚信的重视度。
此外,当学术不端行为得到有效遏制后,学术界的竞争环境将更加公平和健康。
然而,学术不端文献检测系统的应用也存在一些潜在的挑战。
首先,该系统的准确性和可靠性仍然需要进一步提高。
尽管系统能够自动扫描大量文献,并进行相似性比对和模式识别,但仍然有可能遗漏一些潜在的不端行为。
此外,该系统也可能将一些正当引用和学术合作误判为不端行为,给学术界的合作与创新带来一定的困扰。
因此,需要不断优化该系统的算法模型和机制,提高其准确性和适用性。
其次,隐私保护也是学术不端文献检测系统中需要考虑的重要问题。
系统在检测和比对过程中需要获取大量文献和研究数据,因此需要确保这些数据的安全性和保密性,以免给学术界的知识产权和个人隐私造成损害。
“TMLC检测系统”简介及主要检测

“TMLC检测系统”简介及主要检测“TMLC检测系统”即“学位论文学术不端行为检测系统”,是以《中国学术文献网络出版总库》为全文比对数据库,可以对学位论文中的抄袭、伪造及篡改数据等学术不端行为进行快速检测,是检测研究生培养过程中学术及学位论文出现不端行为的辅助工具。
该系统设有总检测指标和子检测指标二部分指标体系,涉及重合字数、文字复制比、首(尾)部复制比等多项内容,从多个角度对学位论文中的文字复制情况进行详细描述,根据指标参数以及其他数据相关信息,自动给出预判的诊断类型并生成检测报告。
学位论文一般篇幅较大,为了便于快速准确的分析论文与比对文献的复制关系,系统设计了多个检测指标,这些指标从多个角度反映文字复制的特征。
一、总检测指标:从整体情况描述了论文的检测情况,便于快速了解该论文总的检测情况。
1、总重合字数(CCA):检测结果的核心指标,反映一篇论文复制比对文献的绝对字数总和。
2、总文字复制比(TTR):指学位论文中总的重合字数在论文总的字数中所占的比例。
该指标可以直观了解重合字数在该学位论文中所占的比例情况。
3、首(尾)部重合文字数(HCCA、ECCA):首部重合文字数是指学位论文前1万字中重合的文字数量。
尾部重合文字数是指除去前1万字,剩下的部分中重合的文字数量。
对于学位论文,一般开头部分均是综述性的报告介绍,其重要性远低于论文尾部。
二、子检测指标:学位论文核心内容一般主要存在于某几章中,子检测指标可以让用户迅速了解每一章节的检测情况。
1、文字复制比(TR):反映第一章节段落的文字情况,比例越高,反映该章节越多的文字来自于其他已发表文献。
该指标反映了文章“抄袭”的文字数量比例。
2、重合字数(CNW):指学位论文该章节与比对文献比较后,重合部分的字数。
一般来说,不管文字复制比如何,重合字数越多,存在学术不端行为的可能性越大。
3、段文字比(PR):该章节文字重合段的字数之和占该章节文字数的比例为段文字比。
科技期刊学术不端文献检测系统(AMLC)
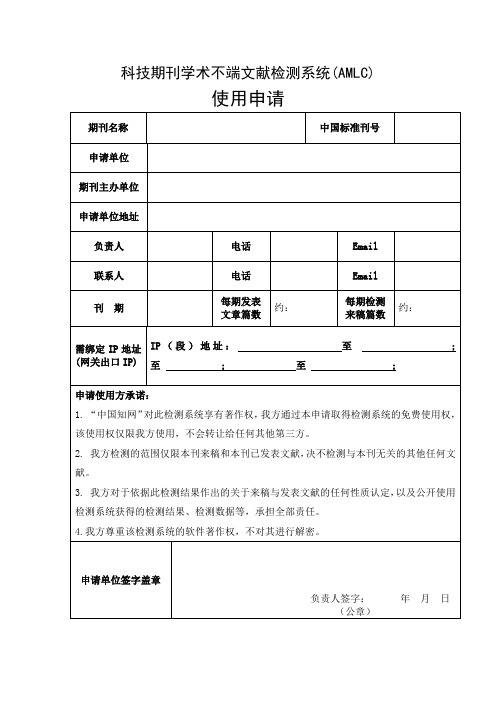
科技期刊学术不端文献检测系统(AMLC)
使用申请
期刊名称
中国标准刊号
申请单位
期刊主办单位
申请单位地址
负责人
电话
联系人
电话
刊 期
每期发表文章篇数
约:
每期检测来稿篇数
约:
需绑定IP地址(网关出口IP)
IP(段)地址:至;至;至;
申请使用方承诺:
1. “中国知网”对此检测系统享有著作权,我方通过本申请取得检测系统的免费使用权,该使用权仅限我方使用,不会转让给任何其他第三方。
2. 我方检测的范ห้องสมุดไป่ตู้仅限本刊来稿和本刊已发表文献,决不检测与本刊无关的其他任何文献。
3. 我方对于依据此检测结果作出的关于来稿与发表文献的任何性质认定,以及公开使用检测系统获得的检测结果、检测数据等,承担全部责任。
4.我方尊重该检测系统的软件著作权,不对其进行解密。
申请单位签字盖章
负责人签字: 年 月 日
(公章)
【最新】中国知网大学生论文检测系统操作指南

05.学生
(3)已提交论文
展示学生提交检测的最新1篇论文的检测结果 a.提示论文提交的状态(已检 测的无权限、有权限可再次提 交检测) b.论文信息 c.查看检测结果的权限(无、 复制比、简洁、全文标明引文) d.指导教师(选错可修改) e.指导教师的意见(附件可下 载)
05.学生
(4)论文列表
(2)网址输入:输入 进入中心网站
第2步
第3步
选择大学生系统进入首页
选择角色登录
特别说明:学生登录需选择学校(学生用户名和初始密码均为学 号,请及时修改密码!)
学生操作基本流程
获得账号 和登录权限
登录 系统
上传 论文2直接 检测源自1设置了上 传截止时间多次上传or 等待截止时间
查看检测结果 (根据权限)
05.学生
(1)提交新论文
第1步:学生首次登录系统 提交论文时,需要先选择指 导教师 第2步:输入篇名、关键词、 创新点、中英文摘要信息 (可从待上传的文献中复制 粘贴) 第3步:选择论文提交至系统
05.学生
(2)提交的论文存放和展示
与管理员是否设置了检测截止时间有关 设置:截止时间前“预提交论文”;未设置:正常检测并给予结果(权限) 学生可点击“篇名”查看教师的审核意见,进行修改后再提交
论文列表展示学生多次上传的论文
05.学生
(4)论文列表
根据学生查看检测结果权限不同,列表会展示不同 第1种:无权限查看:不能查看检测结果复制比、不能点击篇名查看报告单
第2种:仅文字复制比:可查看复制比、不能点击篇名查看报告单
第3种:可查看复制比,可点击篇名打开报告单(简单、全文)
04.报告单
生成和下载PDF版本报告单 点击打开网页版本报告单
学术不端检测系统简介及修改方法

专业的修改老师QQ:1423057668加他即可学术不端检测系统简介及修改方法简介(看完以下内容对于您写论文也有益)在每个学生毕业时都要写一篇学位论文,现在学位论文的过关不仅是要求过答辩就OK,还要通过学术不端检测!自从2008年各高校使用中国知网论文学术不端检测系统后,每年各高校都会使用该系统对每届毕业生的论文进行一下测试,此系统不是软件,不是下载一下就可以用的。
软件在北京的中国知网,各高校也只是拥有账号和密码,可以进去提交论文,且上传文章的篇数是根据本校毕业生的人数来定的。
一般每年若有1000人毕业,该校会有1000个检测指标使用。
学校将论文上传到该系统后,文章就会与中国知网所收录的期刊文章、报纸文章、本、硕、博论文库等库存内容进行比对。
全文比对结束后,会出现一个百分比,就是你的文章抄袭别人内容占你整篇文章的百分比。
这个百分比如果超过本校的规定指标(一般学校规定是不准超过30%,有的学校规定是不准超过10%,这些是各个学校自己定的,没有定论),如超标,就会被推迟答辩和取消授予学位资格。
这已经成为事实,各高校都有案例可查。
有的同学说,我不担心,我引用了。
我们的回答是:机器检测,说不准,机器毕竟是机器。
如果超标,哭都来不及。
现在您不用担心了!!!可以到我店进行提前检测,检测后进行相关的修改,躲过学校的最终检测,避免自己因此耽误毕业。
检测后的修改方法,我们针对在本店购买的客户是直接送的强烈呼吁广大同学,不要把希望寄托在学校的免费检测上,那次检测如果结果不妙,将会成为您终生的遗憾!现在江湖中流传多份修改密集。
店主根据多年的工作经验总结,实际上很简单:就是改变句子的结构。
比如,将:“弯变的月亮”改变成:“天上有个弯弯的像镰刀一样的月亮”。
这样改后,就是创新了,至少可以躲过检测系统了。
还有一个比较急办方法,抄书。
因为不管是中国知网还是万方,哪家公司也没有收录书籍。
但你要看清楚,书的封面要写了“中国优秀博士论文……”,这样的书肯定已经被收录了,可以抄教材等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
“中国知网”学术不端文献检测系统
报告单使用说明书
CNKI科研诚信管理研究中心
2014年
第一章报告单类别 (3)
1.1简洁报告单 (3)
1.2全文(标明引文)报告单 (3)
1.2去除本人文献报告单 (3)
1.3 全文对照报告单 (3)
第二章报告单信息 (3)
2.1被检测文献基本信息 (3)
2.2文字复制比 (4)
2.2.1总文字复制比 (4)
2.2.2去除引用文献文字复制比 (4)
2.2.3去除本人文献文字复制比 (4)
2.2.4 单篇最大文字复制比 (4)
2.3检测指标 (4)
2.3.1重合字数 (4)
2.3.2总字数 (5)
2.3.3总段落数 (5)
2.3.4疑似段落数 (5)
2.3.5 疑似段落最大重合字数、疑似段落最小重合字数 (5)
2.3.6前部重合字数、后部重合字数 (5)
2.2.7 《标准》鉴定指标 (5)
2.2.8 表格、脚注和尾注 (6)
2.4章节信息 (6)
2.4.1段落检测信息 (6)
2.4.2相似文献列表 (6)
第一章报告单类别
学术不端文献检测系统分为三种报告单:简洁报告单、全文(标明引文)报告单、去除本人文献报告单和全文对照报告单。
1.1简洁报告单
简洁报告单突出的是简洁而不“简单”,上半部分主要显示了被检测文献的基本信息,下半部分按照章节显示了各章节的相似文献信息。
1.2全文(标明引文)报告单
全文(标明引文)报告单在简洁报告单的基础上,增加了被检测文献的全文,红色文字表示文字复制部分,黄色文字表示引用部分。
1.2去除本人文献报告单
去除文人文献报告单,是指去除了本人发表的文献后的报告单。
1.3 全文对照报告单
全文对照报告单,突出显示了被检测文献和相似文献的重合部分,并且显示了相似文献的来源信息。
第二章报告单信息
2.1被检测文献基本信息
基本信息主要显示了被检测文献的篇名、作者、检测范围和检测时间。
2.2文字复制比
在检测结果中,复制比是最主要的指标,即总文字复制比、去除引用文献复制比和去除本人文献复制比。
无论是总检测指标还是子检测指标,这三个复制比都是衡量检测文章结果的最重要指标。
复制比反映了文章“抄袭”的文字数量比例,一般来说,文字复制比越高,存在抄袭行为的可能性越大。
2.2.1总文字复制比
总文字复制比是指所检测文献总的重合字数在总的文献字数中所占的比例。
通过该指标,可以直观了解到重合字数在该检测文献中所占的比例情况。
2.2.2去除引用文献文字复制比
去除引用文献文字复制比,是指去除了作者在文中标明了引用文献的重合文字的复制比。
2.2.3去除本人文献文字复制比
去除本人文献文字复制比,是指去除了本人发表的文献之后,重合的文字的复制比。
2.2.4 单篇最大文字复制比
单篇最大文字复制比,是指被检测文献与所有相似文献比对后,重合字数比例最大的那一篇文献的文字复制比。
2.3检测指标
检测指标主要包括重合字数、文献总字数、总段落数和疑似段落数等信息。
2.3.1重合字数
检测系统使用绝对字数,即总重合字数作为检测结果的核心指标。
2.3.2总字数
总字数是该检测文献所有包含的字数,文字复制比与总字数的乘积即为重合字数。
2.3.3总段落数
总段落数是指文献总的章节数,由于有的文献没有章节信息,系统会按照每一万字的标准来分割文献,即每一万字为一段落。
2.3.4疑似段落数
疑似段落数是指检测文献疑似存在抄袭行为的章节的数量。
2.3.5 疑似段落最大重合字数、疑似段落最小重合字数
疑似段落最大重合字数是指在该检测文献所有疑似段落中,重合文字最多的段落中的重合字数。
疑似段落最小重合字数是指在该检测文献所有疑似段落中,重合字数最少的段落中的重合字数。
2.3.6前部重合字数、后部重合字数
前部重合字数指检测文献整体前20%文字中的重合数量。
后部重合字数是指去除前20%剩下的部分中重合的文字数量。
对于学位论文,一般开头部分均是综述性的报告介绍,其重要性远低于论文尾部。
2.2.7 《标准》鉴定指标
《标准》鉴定指标是指系统根据《学术期刊论文不端行为的界定标准》自动生成的系列指标,旨在展示被检测文献疑似出现的学术不端行为。
目前的指标包括剽窃观点、自我剽窃、一稿多投、过度引用、整体剽窃、重复发表和剽窃文字表述七类。
该七类指标的含义,参见《学术期刊论文不端行为的界定标准》的具体描述。
在报告单中,七类指标前的图标,如果显示为红色,表示被检测文献存在该类型的不端行为,如果为黑色,则不存在该类型的不端行为。
并且显示了被检测文献存在不端行为的文字。
2.2.8 表格、脚注和尾注
系统自动抽取了被检测文献的表格、尾注和尾注,并且显示了相似表格数量及脚注和尾注的数量。
2.4章节信息
2.4.1段落检测信息
报告单显示了检测文献每一段落检测信息,包括段落的文字复制比、重合字数和总字数。
2.4.2相似文献列表
相似文献列表显示了检测文献相似的文献信息,显示了相似文献的篇名、作者、出处和发表时间,并且显示了检测文献与相似文献的文字复制比,而且验证了检测文献是否引用了该相似文献。