关键词采集方法
java 内容提取关键字的方法

一、概述在信息检索、文本挖掘、自然语言处理等领域,提取文本内容的关键字是一项重要的任务。
Java作为一种常用的编程语言,在文本内容提取关键字方面也有多种方法和工具可供选择。
本文将介绍在Java中提取文本内容关键字的几种常用方法,包括基于统计的方法、基于机器学习的方法和基于自然语言处理技术的方法。
二、基于统计的方法1. TF-IDF算法TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用的基于统计的关键字提取方法。
它通过计算词项在文档中的频率以及在语料库中的逆文档频率来确定词项的重要性。
在Java中,可以使用开源的工具包,如Apache Lucene或Elasticsearch,来实现TF-IDF算法的文本内容提取关键字。
2. TextRank算法TextRank是一种基于图的排序算法,它通过分析文本中词项之间的关联关系来确定关键字。
在Java中,可以使用开源的NLP工具包,如Stanford NLP或HanLP,来实现TextRank算法的文本内容提取关键字。
三、基于机器学习的方法1. 词袋模型词袋模型是一种常用的机器学习方法,它将文本转换为向量表示,并使用分类器来确定文本中的关键字。
在Java中,可以使用开源的机器学习库,如Weka或Mallet,来实现词袋模型的文本内容提取关键字。
2. 深度学习模型深度学习模型,如卷积神经网络(CNN)和长短期记忆网络(LSTM),在文本内容提取关键字中也取得了不错的效果。
在Java 中,可以使用深度学习框架,如Deeplearning4j或DL4J,来实现深度学习模型的文本内容提取关键字。
四、基于自然语言处理技术的方法1. 分词技术分词是自然语言处理中的重要步骤,它将文本分割成词项。
在Java中,可以使用开源的分词工具包,如HanLP或Jieba,来实现文本内容的分词和关键字提取。
2. 命名实体识别技术命名实体识别是自然语言处理中的另一项重要技术,它可以识别文本中的人名、地名、组织机构名等实体。
关键词提取算法综述及评测比较

关键词提取算法综述及评测比较在信息检索、文本分类、文本摘要以及知识管理等领域中,关键词提取一直是一个重要的问题。
关键词是文本的核心,能够直接反映文本的主题、内容及关键性信息。
在自然语言处理中,关键词提取就是从文本中自动抽取出一些最重要的、最代表性的关键词。
近年来,随着互联网的快速发展以及文本数据的大量积累,关键词提取算法也逐渐得到了广泛的关注和研究。
本文将对目前常见的关键词提取算法进行综述,并针对它们的优缺点进行评测比较。
一、传统的关键词提取算法1. TF-IDF算法TF-IDF算法是一种传统的关键词提取算法,它通过计算词频和逆文档频率来确定一个词汇在文档中的重要性。
具体来说,TF-IDF算法首先将文本分词,并统计每个词汇在文档中的出现频率。
然后,根据出现频率计算每个词汇的TF值。
最后,根据逆文档频率(一个词汇在整个文集中出现次数的倒数)和词汇的TF值,计算每个词汇的TF-IDF值,以此来确定每个词汇在文档中的重要性。
2. TextRank算法TextRank算法是一种图排序算法,适用于自然语言处理中的文本关键词提取、文本摘要、文本分类等应用。
TextRank算法同样将文本分词,并将每个词汇看作图中的一个节点。
然后,将同一句子中的所有词汇间连一条边,根据它们之间的共现关系构建一个无向加权图。
之后,根据图中节点之间的关系,计算每个词汇的PageRank值,以此确定每个词汇的重要性。
3. LDA主题模型LDA主题模型是一种基于概率分布的文本关键词提取算法。
该算法首先将文本分词,并将每个词汇向量化。
然后,根据词汇之间的相关性,计算每个词汇相应的主题分布表示。
最后,根据主题分布,确定每个词汇的重要性。
二、新兴的关键词提取算法1. 基于深度学习的模型随着深度学习技术的不断发展,深度学习模型在文本关键词提取中也被广泛应用。
目前,已经有很多基于深度学习的模型,如TextCNN、Attention-Based TextCNN等,这些模型通过卷积神经网络和注意力机制等方式,对文本进行建模和提取,能够较好地处理不同类型的文本数据。
如何利用自然语言处理技术进行关键词提取(十)

自然语言处理(Natural Language Processing,NLP)是一项高度复杂且具有挑战性的技术,它涉及到计算机科学、人工智能和语言学等多个领域的知识。
NLP 技术的发展已经在许多领域产生了深远的影响,包括语音识别、机器翻译、文本分类、情感分析等。
其中,关键词提取是 NLP 技术的一个重要应用,它可以帮助人们更好地理解和组织文本信息。
一、关键词提取的意义关键词提取是指从一段文本中自动抽取出具有代表性和重要性的词语或短语,以便更好地理解文本的主题和内容。
在信息检索、文本摘要、信息过滤等领域,关键词提取都扮演着重要的角色。
通过关键词提取,可以帮助用户快速了解文本的核心内容,节省阅读时间,提高工作效率。
此外,对于搜索引擎来说,关键词提取也可以帮助其更准确地理解用户的检索意图,提高搜索结果的相关性。
二、基于统计的关键词提取方法在自然语言处理领域,有许多基于统计的关键词提取方法。
其中,TF-IDF (Term Frequency-Inverse Document Frequency)是一种常用的基于统计的关键词提取算法。
它通过计算词语在文本中的出现频率和在语料库中的重要性来确定关键词。
具体来说,TF-IDF算法会给那些在当前文档中频繁出现,但在整个语料库中罕见的词语赋予较高的权重,认为这些词语具有较高的区分度和重要性。
通过TF-IDF算法,我们可以很快地找到文本中的关键词,从而更好地理解文本的主题和内容。
三、基于机器学习的关键词提取方法除了基于统计的方法外,还有许多基于机器学习的关键词提取方法。
例如,TextRank 算法是一种基于图的关键词提取算法,它借鉴了 PageRank 算法的思想,并通过构建词语之间的相似度图来抽取关键词。
TextRank 算法认为,那些与其他词语有较多连接的词语往往具有较高的重要性,因此会将这些词语作为关键词。
通过机器学习方法,我们可以更加准确地抽取出文本中的关键词,提高关键词提取的效果。
如何提取关键词

如何提取关键词如何提取关键词一.提取关键词的本质1. 提取关键词本质上是对语段关键、主要、核心信息的集中。
2. 提取关键词本质上是压缩的压缩,精练的精练,关键的关键。
3. 提取关键词本质上是要淘汰掉次要的、支撑的、解说的信息。
4. 提取关键词本质上考查的语段信息筛选能力和梳理思路能力。
二.提取关键词的三大原则1. 首先通览语段寻找锁定有效信息:冷静取舍。
2. 其次筛选有效信息中的核心信息:再次取舍。
3. 提取而不是组合语段中的关键词:文中原有。
4. 主要用双音词或短语的形式表述:二字多字。
三.提取关键词的三个技法1. 核心话题法:抓取语段核心话题词语l 任何文体性质的语段都得围绕某个核心话题展开l 这个话题词语在语段中出现的频率一般较多l 承载语段核心话题的词语肯定是关键词之一2. 关键语句法:筛选语段中的关键句l 有的语段中会有针对核心话题的核心陈述句l 有的语段中有或总领或总结的概括性中心句l 抓住这类关键语句就易于筛选出关键词3. 结构层次法:任何语段都表现为一定的思路层次l 并列式语段关键词常散布在各层次中l 递进式语段关键词常出现在最后层次中l 总分式语段关键词常出现在总说句中四.提取关键词的高考真题例析1. 提取下面一段话的主要信息,写出四个关键词。
(2005年高考全国卷)据报道,我国国家图书馆浩瀚的馆藏古籍中,仅1.6万卷“敦煌遗书”就有5000余米长卷需要修复,而国图从事古籍修复的专业人员不过10人;各地图书馆、博物馆收藏的古籍文献共计3000万册,残损情况也相当严重,亟待抢救性修复,但全国的古籍修复人才总共还不足百人。
以这样少的人数去完成如此浩大的修复工程,即使夜以继日地工作也需要近千年。
[答案]古籍修复人才不足[解析]这个语段谈论的核心话题是古籍修复的处境问题,“古籍”“修复”这两个词是我们在答题时首先要考虑的。
文段通过一系列的数据告诉我们古籍修复这个核心话题的处境不好,最重要的具体表现是事多人少,这样,我们就又可找出另外两个关键词——“人才”“不足”。
长尾关键词挖掘的27个方法
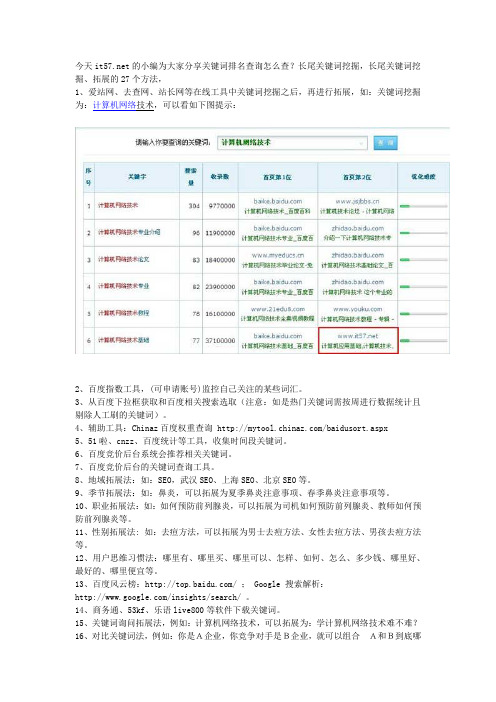
今天的小编为大家分享关键词排名查询怎么查?长尾关键词挖掘,长尾关键词挖掘、拓展的27个方法,1、爱站网、去查网、站长网等在线工具中关键词挖掘之后,再进行拓展,如:关键词挖掘为:计算机网络技术,可以看如下图提示:2、百度指数工具,(可申请账号)监控自己关注的某些词汇。
3、从百度下拉框获取和百度相关搜索选取(注意:如是热门关键词需按周进行数据统计且剔除人工刷的关键词)。
4、辅助工具:Chinaz百度权重查询 /baidusort.aspx5、51啦、cnzz、百度统计等工具,收集时间段关键词。
6、百度竞价后台系统会推荐相关关键词。
7、百度竞价后台的关键词查询工具。
8、地域拓展法:如:SEO,武汉SEO、上海SEO、北京SEO等。
9、季节拓展法:如:鼻炎,可以拓展为夏季鼻炎注意事项、春季鼻炎注意事项等。
10、职业拓展法:如:如何预防前列腺炎,可以拓展为司机如何预防前列腺炎、教师如何预防前列腺炎等。
11、性别拓展法: 如:去痘方法,可以拓展为男士去痘方法、女性去痘方法、男孩去痘方法等。
12、用户思维习惯法:哪里有、哪里买、哪里可以、怎样、如何、怎么、多少钱、哪里好、最好的、哪里便宜等。
13、百度风云榜:/ ; Google 搜索解析:/insights/search/ 。
14、商务通、53kf、乐语live800等软件下载关键词。
15、关键词询问拓展法,例如:计算机网络技术,可以拓展为:学计算机网络技术难不难?16、对比关键词法,例如:你是A企业,你竞争对手是B企业,就可以组合A和B到底哪个好?17、百度知道,搜搜问问等问答平台。
18、分析同行网站关键词。
19、网民搜索意图,举例:以“减肥”为目标关键词,“我要减肥,减肥用什么药”都是通过网民搜索意图拓展。
20、质地特点功能,举例:以“汽车”为目标关键词,“敞篷汽车”是根据该产品特点拓展的长尾关键词。
21、应用领域和地域,举例:以“除湿机”为目标关键词,“工业用途除湿机”是根据应用领域拓展的。
毕业论文的文献综述中的关键词提取与分析

毕业论文的文献综述中的关键词提取与分析在进行毕业论文的文献综述时,关键词的提取与分析是非常重要的一部分。
合理的关键词选择可以使读者快速了解论文的核心内容,也能帮助研究者准确定位相关研究。
本文将探讨如何提取与分析关键词,并介绍几种常用的关键词提取方法。
一、关键词提取的重要性在进行文献综述时,关键词是标识论文主题和内容的关键词汇。
通过合理的关键词选择,读者可以迅速了解论文的研究重点,提高阅读效率。
而对于研究者来说,关键词的选择也是十分重要的。
通过合理提取的关键词,研究者可以更加精确地定位和识别相关文献,了解研究热点和前沿动态。
二、关键词提取方法1. 手工提取法手工提取法是最常用的关键词提取方法之一。
通过仔细阅读文献,研究者可以根据论文的主题和内容提取出关键词。
在提取关键词时,可以注意以下几点:a) 关注论文的中心思想和研究目的;b) 重点关注论文中频繁出现的词汇;c) 注意论文标题和摘要中的关键词。
2. 自动提取法除了手工提取法外,还可以利用计算机技术进行关键词提取。
自动关键词提取法可以通过算法分析文本中的词频、词性等信息,辅助研究者提取关键词。
常用的自动提取方法包括:a) 基于词频的提取方法:根据词频统计每个词在文献中出现的频率,选取频率较高的词作为关键词;b) 基于词性的提取方法:根据词性标注对文献中的词进行分类,选取具有代表性的词作为关键词;c) 基于机器学习的提取方法:利用机器学习算法训练模型提取关键词。
三、关键词分析的意义与方法提取出关键词后,还需进行关键词分析,以了解文献的研究热点和趋势。
关键词分析可以通过以下几种方式进行:1. 热词分析通过统计关键词出现的频率,研究者可以获得一些热门的研究领域和研究热点。
通过对这些热词的分析,研究者可以了解当前的研究趋势,并选择合适的研究方向。
2. 同现分析同现分析是指通过分析关键词之间的关联关系,揭示不同领域之间的交叉点和联系。
同现分析可以帮助研究者发现新的研究领域和研究思路,促进学科交叉和创新。
挖掘商品的关键词方法

挖掘商品的关键词方法
1、搜索词法。
采用网站搜索日志中带有商品关键字的搜索词,筛选出与商品相关的搜索词。
2、热门关键词法。
在商品的流量较大的页面,如热度较高的首页、分类页、销量高的商品页等,分析页面内容并统计页面内容中出现次数最高的关键词,从而作为商品的关键词。
3、价格分析法。
分析商品在同类商品中的价格优势或者价格折扣,以最优惠价格作为商品的关键字可以吸引更多用户关注,最终购买。
4、基于SEO的关键词分析。
从搜索引擎角度出发,根据关键词分析有助于拓展商品的覆盖度,确定商品的SEO关键词,使搜索引擎有效地进行抓取,起到对商品进行网店推广的作用。
英语听力中的关键词抓取方法

英语听力中的关键词抓取方法随着全球化的加速发展,英语已经成为了全球通用的语言之一。
无论是在学术研究、商务交流还是日常生活中,英语的重要性不言而喻。
而对于学习者来说,掌握英语听力技巧是提高英语水平的重要一环。
本文将探讨英语听力中的关键词抓取方法,帮助读者更好地理解和应用英语听力技巧。
一、理解上下文在进行英语听力时,理解上下文是非常重要的一步。
通过抓住关键词并结合上下文,我们可以更好地理解对话或文章的含义。
例如,当我们听到一个生词时,可以通过上下文中的其他词语或句子来推测其意思。
这样,我们就能够更准确地理解整个对话或文章的内容。
二、注意重读和停顿在英语中,重读和停顿往往会给我们提供一些重要的信息。
重读通常意味着这个词或短语的重要性,而停顿则可能表明说话者正在进行思考或强调某个观点。
因此,当我们听到重读或停顿时,应该特别注意,并将其作为关键词来抓取。
三、注意连词和过渡词连词和过渡词在英语听力中扮演着非常重要的角色。
它们可以帮助我们理解句子之间的关系,从而更好地理解整个对话或文章的逻辑结构。
例如,当我们听到"however"、"therefore"、"in addition"等词语时,就应该意识到前后句子之间存在着转折、因果或并列的关系。
四、注意修饰词和副词修饰词和副词在英语听力中也是非常重要的关键词。
它们可以帮助我们更好地理解名词或动词的具体含义。
例如,当我们听到"beautiful"、"quickly"、"carefully"等词语时,就应该意识到它们对名词或动词的修饰作用,从而更准确地理解句子的含义。
五、注意上下文的转变在英语听力中,上下文的转变往往会给我们带来一些挑战。
当对话或文章的主题发生变化时,我们需要及时调整自己的思维方式,并抓住新的关键词。
这样,我们才能够更好地理解对话或文章的整体内容。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
八爪鱼·云采集网络爬虫软件
www.bazhuayu.com
关键词采集方法
本文将介绍如何利用【词库】批量挖掘并采集长尾词的方法,对SEOSEM站长
来说非常实用。本来还将介绍一款免费好用的数据采集工具【八爪鱼数据采集】,
让站长采集关键词的工作事半功倍。
长尾词对于站长来说是提高网站流量的核心之技能之一,是不容忽视的一项技巧,
在搜索引擎营销中对关键词策略的制定是非常重要的,这些长尾关键词能为网站
贡献很大的一部分流量,并且带来的顾客转化率也很不错。
下面就以【词库】为例,教各位站长如何是用【八爪鱼数据采集器】批量采集关
键词。
采集网站:
http://www.ciku5.com/
本文就以一组(100个B2B行业有指数的关键词)为例,来采集关于这一组关
键词的所有相关长尾关键词。
八爪鱼·云采集网络爬虫软件
www.bazhuayu.com
采集的内容包括:搜索后的长尾关键词,360指数,该长尾关键词搜索量以及搜
索量的第一位网站(页面)这四个有效字段。
使用功能点:
循环文本输入
http://www.bazhuayu.com/tutorialdetail-1/wbxh_7.html
Xpath
xpath入门教程1
xpath入门2
相对XPATH教程-7.0版
数字翻页
http://www.bazhuayu.com/tutorialdetail-1/szfy_7.html
步骤1:创建词库网采集任务
1)进入主界面,选择“自定义采集”
八爪鱼·云采集网络爬虫软件
www.bazhuayu.com
2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
八爪鱼·云采集网络爬虫软件
www.bazhuayu.com
步骤2:创建循环输入文本
八爪鱼·云采集网络爬虫软件
www.bazhuayu.com
1)打开网页之后,点开右上角的流程,然后从左侧拖一个循环进来
2)点击循环步骤,在它的高级选项那里选择文本列表,再点开下面的A,把复
制好的关键词全部粘贴进去,注意换行,再点击确定保存。
八爪鱼·云采集网络爬虫软件
www.bazhuayu.com
3)创建好循环文本输入后,点击页面上的搜索框,创建输入文本的步骤,注意,
不需要输入任何文本即可,若是自动生成的是在循环外面,拖入进去,再勾选循
环即可。
八爪鱼·云采集网络爬虫软件
www.bazhuayu.com
4)右键选择页面上的搜索按钮,设置好点击元素,这样,循环文本输入就设置
好了,流程下方就是搜索出来的长尾关键词。
步骤3:创建数字翻页
1)由于该搜索结果页面没有下一页按钮,只有数字页数,所以我们需要用到
xpath的一些相关知识,来设置特殊的数字翻页。首先去火狐浏览器里把该网页
打开并搜索相应关键词后,打开浏览器右上角的firebug工具--小瓢虫(不懂的
同学可以去官网教程看一下相应的xpath教程)
八爪鱼·云采集网络爬虫软件
www.bazhuayu.com
2)翻到页面下方,找到数字位置的源码,可以看到当前页面的数字跟其他数字,
在源码里节点的属性class是有所不同的
八爪鱼·云采集网络爬虫软件
www.bazhuayu.com
3)收益我们首先定位到该页面的数字位置,手写xpath:
//div[@id="page"]/a[contains(@class,'current')]
八爪鱼·云采集网络爬虫软件
www.bazhuayu.com
4)再利用固定函数following-sibling来定位到该节点后的第一个同类节点,
注意,该函数后面接::是固定格式,a[1]是指该节点后的第一个同类节点
八爪鱼·云采集网络爬虫软件
www.bazhuayu.com
5)可以查看翻页后还是正常定位到下一页的数字上,说明该xpath没有问题
6)再回到八爪鱼,在左侧流程页面拖一个循环进来,高级选项里选择单个元素,
并把xpath放入进去,点确定保存好
八爪鱼·云采集网络爬虫软件
www.bazhuayu.com
7)再从左侧拖一个点击元素进来,并在高级选项里勾选好循环,特殊数字翻页
循环就创建好了
八爪鱼·云采集网络爬虫软件
www.bazhuayu.com
步骤4:创建循环列表
1)我们安装常规方法创建循环列表,发现,由于搜索结果后的表格中出现了这
个无用的一整行信息。
八爪鱼·云采集网络爬虫软件
www.bazhuayu.com
2)于是在八爪鱼里面是无法正常的创建好循环列表的,因为这个无用的信息导
致八爪鱼自动生成的列表会定位不准
八爪鱼·云采集网络爬虫软件
www.bazhuayu.com
3)所以我们还是得用到xpath的知识,去火狐浏览器里面手动创建一个循环列
表的xpath。首先定位到第一行第一列的源码位置
4)再找到每一行的源码位置,发现他们都是tbody父节点下相同的tr标签
八爪鱼·云采集网络爬虫软件
www.bazhuayu.com
5)再观察每一行真正的tr节点里都有一个共同的属性“id”,并且id属性都
有一个共同的tr值,所以我们以此为共同点,手写该
xpath:.//tbody/tr[contains(@id,'tr')],来定位到所有的tr节点,并把所有无
用的tr给过滤掉,这样,循环列表的xpath就创建好了
八爪鱼·云采集网络爬虫软件
www.bazhuayu.com
6)再从左侧拖一个循环进去,循环方式选择不固定元素,把该xpath放入八爪
鱼里,并以第一个循环为例,设置相应的采集字段(由于部分字段源码里是没有
的,所以采集不到),
八爪鱼·云采集网络爬虫软件
www.bazhuayu.com
步骤5:启动采集
八爪鱼·云采集网络爬虫软件
www.bazhuayu.com
1)点击保存任务后,运行采集,以本地采集为例
2)采集完成后,会跳出提示,选择“导出数据”。选择“合适的导出方式”,
将采集好的数据导出。
八爪鱼·云采集网络爬虫软件
www.bazhuayu.com
本文来自于:http://www.bazhuayu.com/tutorialdetail-1/cikucrawl.html
相关采集教程:
京东商品信息采集(通过搜索关键词)
http://www.bazhuayu.com/tutorial/jdspsscj
阿里巴巴关键词采集:
http://www.bazhuayu.com/tutorialdetail-1/aliwordcj.html
八爪鱼·云采集网络爬虫软件
www.bazhuayu.com
爱站关键词采集:
http://www.bazhuayu.com/tutorialdetail-1/azkeywordcj.html
百度相关搜索关键词采集:
http://www.bazhuayu.com/tutorialdetail-1/bdxgsscj.html
亚马逊关键词采集:
http://www.bazhuayu.com/tutorialdetail-1/amzwordcj.html
京东关键词采集:
http://www.bazhuayu.com/tutorialdetail-1/jdkeywordcj.html
新浪微博关键词采集:
http://www.bazhuayu.com/tutorialdetail-1/xlwbgjccj.html
关键词提取
http://www.bazhuayu.com/tutorial/hottutorial/qita/guanjianci
八爪鱼——90万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网就能采集。完全可视化
流程,点击鼠标完成操作,2分钟即可快速入门。
八爪鱼·云采集网络爬虫软件
www.bazhuayu.com
2、功能强大,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布
流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。
3、云采集,关机也可以。配置好采集任务后可关机,任务可在云端执行。庞大
云采集集群24*7不间断运行,不用担心IP被封,网络中断。
4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的
基本采集需求。同时设置了一些增值服务(如私有云),满足高端付费企业用户
的需要。