完整word版t值、f值与r方区别.docx
(完整word版)两因素方差分析.
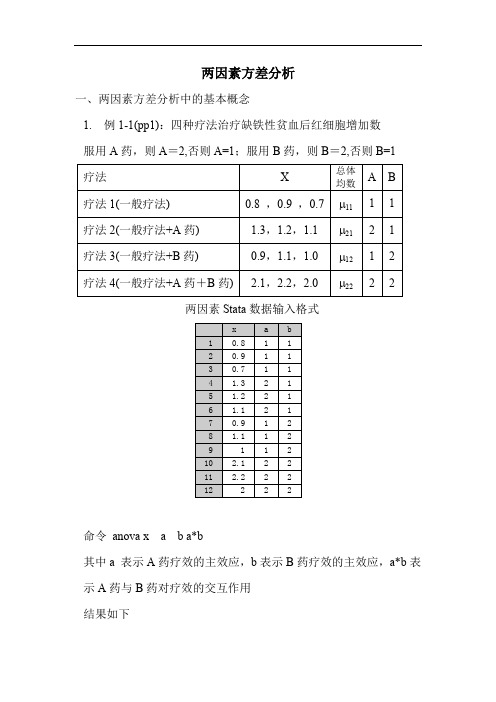
两因素方差分析一、两因素方差分析中的基本概念1. 例1-1(pp1):四种疗法治疗缺铁性贫血后红细胞增加数服用A药,则A=2,否则A=1;服用B药,则B=2,否则B=1两因素Stata数据输入格式命令anova x a b a*b其中a 表示A药疗效的主效应,b表示B药疗效的主效应,a*b表示A药与B药对疗效的交互作用结果如下结果表明:对于 =0.05而言H10:没有交互作用并且A药和B药疗效的主效应都没有差异H11:有交互作用或A药主效应有差异或B药主效应有差异F Model=98.75,P值<0.05,因此认为模型是有效的(或有交互作用或有主效应)。
H20:没有交互作用H21:有交互作用F A×B=36.75,P值=0.0003<0.05,因此A药与B药的疗效有交互作用,并且有统计意义。
H30:A药没有差异H31:A药主效应有差异F A=168.75,P值<0.05,A药的主效应有统计意义H40:B药没有差异H41:B药主效应有差异F B =90.75,P 值<0.05,B 药的主效应也有统计意义。
问题:模型是什么? 模型:..()ab a b ab μμαβαβ=+++其中μab 是x 的总体均数,αa 称为A 因素的主效应,βb 称为B 因素的主效应,(αβ)ab 称为A 因素和B 因素对因变量x(观察指标变量)的交互作用。
2. 主效应的意义A 药B 药平均A 主效应表示未服用服用 未服用 μ11μ1211121.2μμμ+=1...1μμα=+服用 μ21 μ22 21222.2μμμ+= 2...2μμα=+ 平均1121.12μμμ+= 1222.22μμμ+= 11122122..4μμμμμ+++= B 主效应 .1..1μμβ=+ .2..2μμβ=+称α1和α2为A 因素的主效应,β1和β2为B 因素的主效应。
并且可以验证:α1+α2=0(即:α1=-α2)以及β1+β2=0(β1=-β2) 若α1=α2(即α1=α2=0),则对应A 因素的主效应没有作用。
t、F、U检验doc

标准误即样本均数的标准差,是样本均数的抽样误差。
在实际工作中,我们无法直接了解研究对象的总体情况,经常采用随机抽样的方法,取得所需要的指标,即样本指标。
样本指标与总体指标之间存在的差别,称为抽样误差,其大小通常用均数的标准误来表示。
标准误差不是测量值的实际误差,也不是误差范围,它只是对一组测量数据可靠性的估计。
标准误差小,测量的可靠性大一些,反之,测量就不大可靠抽样研究的目的之一,是用样本指标来估计总体指标。
例如:用样本均数来估计总体均数。
由于两者间存在抽样误差,且不同的样本可能得到不同的估计值,因此,常用“区间估计”的方法,来估计总体均数的范围。
即: X ±1.96Sx表示总体均数的95%可信区间; X±2.58Sx表示总体均数的99%可信区间。
95%可信区间指的是:在X±1.96Sx范围中,包括总体均数的可能性为95% ,也就是说,在100次抽样估计中,可能有95次正确(包括总体均数) ,有5次错误(不包括总体均数)。
99%可信区间也是这个道理,只是包括的范围更大。
在实际工作中,由于抽取的样本较小,不呈标准正态分布,而遵从t分布,所以常用t 值代替1.96或2.58。
可在t值表上查出不同自由度下不同界值时的t值。
可见到自由度越小, t值越大,当自由度逐渐增大时, t值也逐渐接近1.96或2.58,当自由度= ∞时, t 值就完全被其代替了。
所以,我们常用X±t 0.05Sx表示总体均数的95%可信区间,用x ±t0.01Sx表示总体均数的99%可信区间。
综上所述,标准差与标准误尽管都是反映变异程度的指标,但这是两个不同的统计学概念。
标准差描述的是样本中各观察值间的变异程度,而标准误表示每个样本均数间的变异程度,描述样本均数的抽样误差,即样本均数与总体均数的接近程度,也可以称为样本均数的标准差。
二者不可混淆。
配对设计主要有四种情况:①同一受试对象处理前后的数据;②同一受试对象两个部位的数据;③同一样品用两种方法(仪器等)检验的结果;④配对的两个受试对象分别接受两种处理后的数据。
P、F、t值的意义【范本模板】

P值的意义:有显著性差异统计学意义(P值)结果的统计学意义是结果真实程度(能够代表总体)的一种估计方法.专业上,P值为结果可信程度的一个递减指标,P值越大,我们越不能认为样本中变量的关联是总体中各变量关联的可靠指标。
P值是将观察结果认为有效即具有总体代表性的犯错概率.如P=0。
05提示样本中变量关联有5%的可能是由于偶然性造成的。
即假设总体中任意变量间均无关联,我们重复类似实验,会发现约20个实验中有一个实验,我们所研究的变量关联将等于或强于我们的实验结果.(这并不是说如果变量间存在关联,我们可得到5%或95%次数的相同结果,当总体中的变量存在关联,重复研究和发现关联的可能性与设计的统计学效力有关。
)在许多研究领域,0.05的P值通常被认为是可接受错误的边界水平。
如何判定结果具有真实的显著性在最后结论中判断什么样的显著性水平具有统计学意义,不可避免地带有武断性。
换句话说,认为结果无效而被拒绝接受的水平的选择具有武断性。
实践中,最后的决定通常依赖于数据集比较和分析过程中结果是先验性还是仅仅为均数之间的两两〉比较,依赖于总体数据集里结论一致的支持性证据的数量,依赖于以往该研究领域的惯例。
通常,许多的科学领域中产生P值的结果≤0。
05被认为是统计学意义的边界线,但是这显著性水平还包含了相当高的犯错可能性。
结果0。
05≥P>0.01被认为是具有统计学意义,而0。
01≥P≥0.001被认为具有高度统计学意义。
但要注意这种分类仅仅是研究基础上非正规的判断常规。
所有的检验统计都是正态分布的吗?并不完全如此,但大多数检验都直接或间接与之有关,可以从正态分布中推导出来,如t 检验、f检验或卡方检验。
这些检验一般都要求:所分析变量在总体中呈正态分布,即满足所谓的正态假设。
许多观察变量的确是呈正态分布的,这也是正态分布是现实世界的基本特征的原因.当人们用在正态分布基础上建立的检验分析非正态分布变量的数据时问题就产生了,(参阅非参数和方差分析的正态性检验)。
t值_精品文档

t值t值是统计学中常用的一种统计量,通常用于进行两个样本均值之差的假设检验或区间估计。
t值的计算方法主要针对小样本情况下的数据,不适用于大样本。
在进行t值的计算之前,需要明确以下几个概念:总体与样本总体是指我们研究的整体对象,包含了我们感兴趣的所有个体或元素。
样本则是从总体中抽取出来的部分个体或元素的集合。
样本均值与总体均值样本均值是从样本中计算出来的数据集合的平均值。
总体均值是我们希望了解的总体的平均值。
样本方差与总体方差样本方差是从样本中计算出来的数据集合的方差。
总体方差是我们希望了解的总体的方差。
样本大小与自由度样本大小指的是样本中的观测数量。
自由度是用于计算t值的参数,通常与样本大小有关。
有了以上的概念,我们可以开始计算t值了。
t值的计算公式t值的计算公式如下:t = (样本均值 - 总体均值) / (样本标准差/ √(样本大小))在计算中,我们需要先计算样本均值和样本标准差。
样本均值的计算公式如下:样本均值= Σ(样本观测) / 样本大小样本标准差的计算公式如下:样本标准差= √(Σ((样本观测 - 样本均值)²) / (样本大小 - 1))然后,我们可以代入这些计算结果,根据t值的计算公式计算出最终的t值。
t值的应用t值的主要应用是进行两个样本均值之差的假设检验或区间估计。
在进行假设检验时,我们通常设置一个显著性水平,比如0.05或0.01,然后根据t值和自由度查表得到拒绝域的临界值,与计算得到的t值进行比较,从而判断是否接受或拒绝原假设。
区间估计则是用来估计两个样本均值之间的差异的范围。
根据计算得到的t值和自由度,我们可以查表得到置信区间的临界值,从而得到两个样本均值差异的估计范围。
t值的局限性t值的计算方法是在一些限定条件下进行的,因此有其局限性。
首先,t值要求样本是来自正态分布的数据;其次,还要求样本之间是独立的;最后,适用于小样本。
当样本符合这些条件时,t值是一种有效的工具。
(完整word版)应用EViews进行Chow检验法
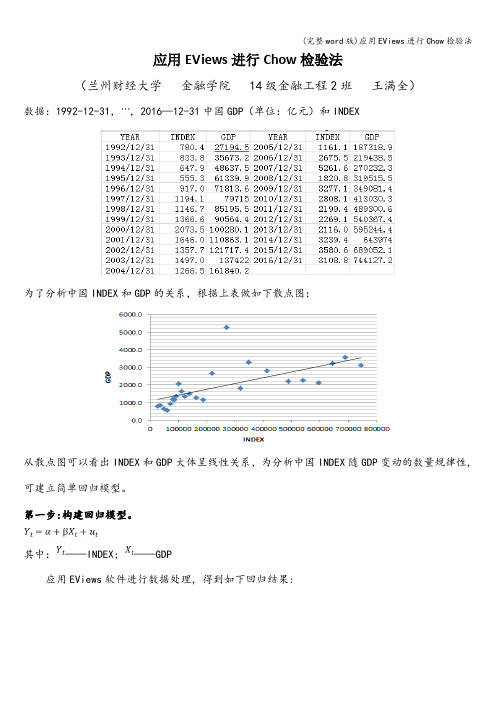
应用EViews进行Chow检验法(兰州财经大学金融学院 14级金融工程2班王满全)数据:1992-12-31,,2016—12-31中国GDP(单位:亿元)和INDEX为了分析中国INDEX和GDP的关系,根据上表做如下散点图:从散点图可以看出INDEX和GDP大体呈线性关系,为分析中国INDEX随GDP变动的数量规律性,可建立简单回归模型。
第一步:构建回归模型。
其中:——INDEX;——GDP应用EViews软件进行数据处理,得到如下回归结果:对回归结果的几点说明:1.经济意义:所估计的参数â=1085。
150,=0。
003287,说明GDP每增加1亿元,可导致INDEX平均增加0。
003287点。
2.拟合优度:R-squared=0.445876说明所建模型整体上对样本数据拟合可以,即解释变量GDP对被解释变量INDEX的部分差异做出了解释。
3.回归系数的t检验:取,因为t(â)=4。
101768〉,t()=4.301969〉,所以可得出GDP对INDEX确有影响。
4.F值(模型总体显著性检验的指标,数值越大,模型越好):因为Prob(F-ststistic)=0。
000265<0。
01,所以通过了0.01水平的显著性检验,说明模型总体显著。
5.Durbin—Watson检验:因为<Durbin—Watson stat=1。
572790<,所以不拒绝零假设,并且没有显著的残差自相关。
第二步:进行Chow氏稳定性检验。
第三步:确定结构变化的转折点(如2004年12月31日),进行检验。
可得:从输出结果看,发现在0.1的水平上拒绝模型稳定原假设,说明2004年12月31日以后的中国股市发生了结构性变化.。
(完整word版)利用Excel进行线性回归分析汇总

文档内容1. 利用Excel进行一元线性回归分析2. 利用Excel进行多元线性回归分析1. 利用Excel进行一元线性回归分析第一步,录入数据以连续10年最大积雪深度和灌溉面积关系数据为例予以说明。
录入结果见下图(图1)。
图1第二步,作散点图如图2所示,选中数据(包括自变量和因变量),点击“图表向导”图标;或者在“插入”菜单中打开“图表(H)”。
图表向导的图标为。
选中数据后,数据变为蓝色(图2)。
图2点击“图表向导”以后,弹出如下对话框(图3):图3在左边一栏中选中“XY散点图”,点击“完成”按钮,立即出现散点图的原始形式(图4):灌溉面积y(千亩)01020304050600102030灌溉面积y(千亩)图4第三步,回归观察散点图,判断点列分布是否具有线性趋势。
只有当数据具有线性分布特征时,才能采用线性回归分析方法。
从图中可以看出,本例数据具有线性分布趋势,可以进行线性回归。
回归的步骤如下:1. 首先,打开“工具”下拉菜单,可见数据分析选项(见图5):图5用鼠标双击“数据分析”选项,弹出“数据分析”对话框(图6):图62.然后,选择“回归”,确定,弹出如下选项表(图7):图7进行如下选择:X、Y值的输入区域(B1:B11,C1:C11),标志,置信度(95%),新工作表组,残差,线性拟合图(图8-1)。
或者:X、Y值的输入区域(B2:B11,C2:C11),置信度(95%),新工作表组,残差,线性拟合图(图8-2)。
注意:选中数据“标志”和不选“标志”,X、Y值的输入区域是不一样的:前者包括数据标志:最大积雪深度x(米) 灌溉面积y(千亩)后者不包括。
这一点务请注意(图8)。
图8-1包括数据“标志”图8-2不包括数据“标志”3.再后,确定,取得回归结果(图9)。
图9线性回归结果4. 最后,读取回归结果如下:截距:356.2=a ;斜率:813.1=b ;相关系数:989.0=R ;测定系数:979.02=R ;F 值:945.371=F ;t 值:286.19=t ;标准离差(标准误差):419.1=s ;回归平方和:854.748SSr =;剩余平方和:107.16SSe =;y 的误差平方和即总平方和:961.764SSt =。
(完整word版)家庭环境量表中文版及其评分标准_(FES-CV)(word文档良心出品)
家庭环境量表中文版 (FES-CV)家庭环境量表中文版(FES-CV)由费立鹏等人于1991年在美国心理学家MossR.H.编制的“家庭环境量表(FES)”的基础上修订改写而成。
该量表含有10个分量表,分别评价10个不同的家庭社会和环境特征:(1)亲密度;(2)情感表达;(3)矛盾性;(4)独立性;(5)成功性;(6)知识性;(7)娱乐性;(8)道德宗教观;(9)组织性;(10)控制性。
该量表含有90个是非题,答题时间约30分钟,要求受试者具有初等以上教育程度。
量表具有较好的效度和重测信度。
但在内部一致性信度上有一定的问题。
亲密度、矛盾性、知识性和组织性4个分量表的内部一致性信度较高,成功性、娱乐性和控制性3个分量表的一致性稍差,独立性、道德宗教观和情感表达3个分量表的内部一致性信度很差。
可能是因为这些分量表的内容不太适合中国文化。
在应用量表做解释时应该慎重。
问卷使用要求受试者具有初等以上教育程度,主试应监控受试者完成量表的全过程,在受试者不能理解多个项目时应中止测试并确认答卷无效。
指导语:该问卷用于了解您对您的家庭的看法。
请您确定以下问题是否符合你家里的实际情况,如果您认为某一问题符合您家庭的实际情况请答“是”,如不符合或基本上不符合,请答“否”。
如果难以判断是否符合,您应该按多数家庭成员的表现或者经常出现的情况作答。
如果仍无法确定,就按自己的估计回答。
请务必回答每一个问题。
有些问句带有“★”,表示此句有否定的含义,请注意正确理解句子内容。
记住,该问卷所说的“家庭”是指与您共同食宿的小家庭。
在回答问卷时不要推测别人对您的家庭的看法,请一定按实际情况回答。
请将答案写在()内。
您的姓名()性别()职业()出生日期()文化程度()注:本问卷中,1表示“是”,2表示“否”,请用1或者2作答。
1()我们家庭成员都总是互相给予最大的帮助和支持。
2()家庭成员总是把自己的感情藏在心里,不向其他家庭成员透露。
(完整word版)计量经济学主要公式
序公式名称计算公式号y t = β0 + β1 x t + u t1真实的回归模型2估计的回归模型y t =+x t +E(y t) = β0 + β1 x t3真实的回归函数4估计的回归函数=+x t5最小二乘估计公式6和的方差7σ2的无偏估计量= s2 =8和估计的方差9总平方和∑(y t -) 210回归平方和∑(-) 211误差平方和∑(y t -)2 = ∑()212可决系数(确定系数)13检验β0,β1 是否为零的t统计量14β1的置信区间-tα(T-2) ≤β1≤+tα(T-2)15单个y T+1的点预测=+x T+116E(yT+1)的区间预测17单个yT+1的区间预测18样本相关系数表3.4 多元线性回归模型的主要计算公式+= X= (X 'X)-1X 'YVar(= s2 ='/ (T - k)() =(X 'X)-1= '= '= +… +C s==是控制z t不变条件下的x t, y t的简单相关系数。
是y t与的简单相关系数。
其中是y t对x t1,x t2,…x tk–12:随机误差项的性质(1)误差项代表了未纳入模型变量的影响;(2)即使模型中包括了决定数学分数的所有变量,其内在随机性也不可避免,这是做任何努力都无法解释的;(3)u代表了度量误差;(4)“奥卡姆剃刀原则”,即描述应该尽可能简单,只要不遗漏重要的信息。
3:解释回归结果的步骤(1)看整个模型的显著性,看F统计量的值;(2)看单个参数的显著性;(3)解释斜率的经济含义;(4)解释R²。
4:古典线性回归模型的基本假定(同多元线性回归模型的基本假定相同)(1)所有自变量是确定性变量; (2)(3)自变量之间不存在完全多重共线性。
12:样本回归方程,i e 为残差项,i i i e X b b Y ++=21总体回归方程,i u 为随机误差项i i i u X B B Y ++=215:样本回归函数:随机样本回归函数:总体回归函数:随机总体回归方程:观察值可表示为: 6:普通最小二乘法就是要选择参数1b 、2b ,使得参差平方和最小。
(完整word版)t值、f值与r方的区别
(1)t值、F值与R方的区别
t值是对单个变量显著性的检验,t值的绝对值大于临界值说明该变量是显著的,要注意的是t检验是对总体当中变量是否是真正影响因变量的一个变量的检验,即检验总体中该变量的参数是否为零,只不过总体中变量的参数永远未知,只能用其无偏估量(参数的样本估计量)来代替进行检验.F值是对所有解释变量整体显著性的检验,其原假设是所有的解释变量的参数都为零,而只要其中至少有一个解释变量的参数不为零就说明解释变量在整体上对因变量有显著
性的影响,但仅依靠F检验是无法判断究竟哪个自变量对因变量有显著性的影响,必须进一步对每一个变量进行t检验。
R平方值表明了模型对样本数据的拟合程度,其值越高说明模型对样本数据拟合得更好,要注意R平方值是样本依赖的,就是说R平方值判别模型的一个潜在的假设是你所抽取的样本是真正来自于你所研究的总体,而现实当中这一点往往难以做到。
我们进行计量经济分析的最终目的是要依据样本数据来研究总体的规律性,那么相应的检验也是要对总体进行,而R平房值的高低仅代表模型对样本数据的拟合程度,并不能说明总体当中变量的显著性,虽然F统计量和R平方值有换算关系,但是二者的构造机理是完全不同的,包括t 检验都是针对总体的检验所以在现实中我们一般不对R平方
值的大小给与太大的关注,而更看重t检验的结果,试想如果你抽取的一组样本不是来自于你真正要研究的对象的总体,即使R平方值再高、那也说明不了问题。
(完整word版)《商务统计》期末总结要点(良心出品必属精品)
《商务统计》期末总结目录第二章表格和图表中的数据表示 (4)1.对数据排序 (4)2.制作数据的茎叶图 (1)3.制作数据的帕累托图 (2)4.统计频数 (5)5.制作散点图及添加趋势线 (6)第三章数值型描述度量 (10)1.计算各描述性统计量 (6)2.画箱线图 (6)3.计算协方差 (9)第五章离散型随机变量的概率分布 (14)1.计算期望收益和风险 (9)2.二项分布预测 (10)3.泊松分布预测 (10)4.超几何分布预测 (10)第六章正态分布和其他连续型分布 (16)1.求正态分布概率及相应概率的取值 (11)2.指数分布 (11)第七章抽样与抽样分布 (17)1.各种抽样方法的选择 (11)2.样本均值的抽样分布 (12)3.比例的抽样分布 (12)第八章置信区间估计 (18)1.求总体均值的置信区间 (18)2.确定样本容量 (18)3.置信区间估计在审计中的应用 (13)第九章假设检验基础: 单样本检验 (14)1.均值的假设检验、Z检验(σ已知) (14)2.均值的t假设检验(σ未知) (20)3.比例假设检验 (21)第十章双样本检验 (21)1.两个独立总体均值的比较 (15)2.两个均值差的置信区间估计 (15)3.两个相关总体均值的比较 (16)4.两个独立总体比例差异的检验 (22)5.两个方差的F检验 (16)第十一章方差分析 (23)1.齐性检验 (17)2.单因素方差检验 (18)3.单因素多元比较 (18)4.双因素方差分析 (19)5.双因素多重比较 (27)第十二章卡方检验和非参数检验 (28)第二章表格和图表中的数据表示1.对数据排序数值排序, 选中要排序的数值, 开始-排序和筛选-升序/降序依照某一个或几个条件的排序, 选中所有要排序的数据(包括非数值数据)开始-排序-自定义排序-添加排序的条件。
2.制作数据的茎叶图叶将数据排序后手动绘制。
绘制结果如下:茎1 55882 122555556893 0003.制作数据的帕累托图(1)原数据格式为合计80选择红框内数据插入-图表-柱状图得到如下图所示:(2)选择累积百分比柱子, 右键更改系列图表类型选择折线图第一个得到如下图右键红色的线, 选择设置数据系列格式, 选择次坐标轴, 如下图所示(4)右键左侧坐标轴, 选择设置坐标轴格式, 将最大值设为合计数值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
(1)t 值、 F 值与 R 方的区别
t 值是对单个变量显著性的检验,t 值的绝对值大于临界值说明该变量是显著的,要注意的是t 检验是对总体当中变
量是否是真正影响因变量的一个变量的检验,即检验总体中
该变量的参数是否为零,只不过总体中变量的参数永远未
知,只能用其无偏估量(参数的样本估计量)来代替进行检
验.F 值是对所有解释变量整体显著性的检验,其原假设是所
有的解释变量的参数都为零,而只要其中至少有一个解释变
量的参数不为零就说明解释变量在整体上对因变量有显著
性的影响,但仅依靠 F 检验是无法判断究竟哪个自变量对因
变量有显著性的影响,必须进一步对每一个变量进行t 检验。
R平方值表明了模型对样本数据的拟合程度,其值越高说明
模型对样本数据拟合得更好,要注意 R 平方值是样本依赖的,
就是说 R 平方值判别模型的一个潜在的假设是你所抽取的样
本是真正来自于你所研究的总体,而现实当中这一点往往难
以做到。
我们进行计量经济分析的最终目的是要依据样本数
据来研究总体的规律性,那么相应的检验也是要对总体进行,
而 R 平房值的高低仅代表模型对样本数据的拟合程度,
并不能说明总体当中变量的显著性,虽然 F 统计量和R 平方值有换算关系,但是二者的构造机理是完全不同的,包括t
检验都是针对总体的检验所以在现实中我们一般不对R 平方
值的大小给与太大的关注,而更看重t 检验的结果,试想如果你抽取的一组样本不是来自于你真正要研究的对象的总
体,即使 R 平方值再高、那也说明不了问题。