多元线性回归 数学建模经典案例
多元线性回归案例-公路客运量

计算回归系数
Intercept
X Variable 1 X Variable 2 X Variable 3 X Variable 4
Coefficient s -
3094216.283 26.63703524
3.161530019
Coefficients -3164044.02 -59.4619025 27.18225866 3.134301817 1459.857673 312.6659322
X X X X Yˆ X = - 3164044.02 - 59.46 1 + 27.18 2+ 3.13 3+ 1459.86 4+312.67 5
dL 0.49
4 dU DW d L 0.49
DW检验无结论
Excel技术支持
第二次检验总结
R检验
回归统计所得 复相关系数R 远大于查表所 得相关系数临 界值,说明数 据相关关系显 著
F检验
回归统计所得 F统计量远大 于查表所得临 界值,否定假 设,认为自变 量与因变量间 回归效果显著
综上判定:剩余四个因素均对公路客运量有显著影响
t检验通过
Excel技术支持
RESIDUAL OUTPUT
观测值 1 2 3 4 5 6 7 8 9
10 11 12 13 14 15
DW检验
预测 Y 643980.5197 638154.2071 679732.6268 752136.8213 843449.9506 959632.632 1054454.966 1134729.76 1194339.7 1236696.678 1286810.288 1336303.614 1411188.254 1459365.628 1474352.354
建模实例(多元线性回归模型)
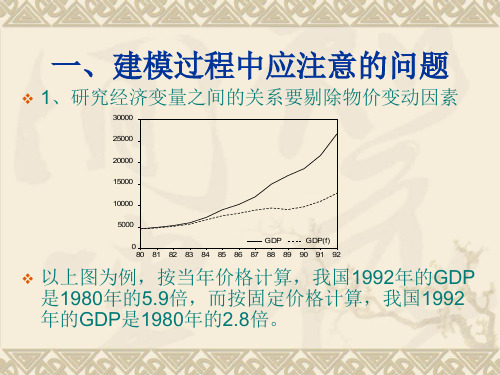
以上图为例,按当年价格计算,我国1992年的GDP 是1980年的5.9倍,而按固定价格计算,我国1992 年的GDP是80年的2.8倍。
2、依照经济理论以及对具体经济问题的深入
分析初步确定解释变量。例:关于某市的食 用油消费量,文革前常驻人口肯定是重要解 释变量。现在则不同,消费水平是重要解释 变量,因为食用油供应方式已改变。 3、当引用现成数据时,要注意数据的定义是 否与所选定的变量定义相符。例:“农业人 口”要区别是“从事农业劳动的人口”还是 相对于城市人口的“农业人口”。
t
案例2:《全国味精需求量的计量经济模型》
1.依据经济理论选择影响味精需求量变化的因素 依据经济理论初设为: 商品需求量 = f (商品价格,代用品价格,收入水 平,消费者偏好) 根据分析,针对味精需求量只考虑两个重要解释变 量,商品价格和消费者收入水平。 味精需求量 = f (商品价格,收入水平)
一建模过程中应注意的问题?1研究经济变量之间的关系要剔除物价变动因素?以上图为例按当年价格计算我国1992年的gdp是1980年的59倍而按固定价格计算我国1992年的gdp是1980年的28倍
一、建模过程中应注意的问题
1、研究经济变量之间的关系要剔除物价变动因素
30000 25000 20000 15000 10000 5000 GD P GD P(f) 0 80 81 82 83 84 85 86 87 88 89 90 91 92
4、通过散点图,相关系数,确定解释变量与
被解释变量的具体函数关系。(线性、非线 性、无关系)
5、谨慎对待离群值(outlier)。离群值可能是正常
值也可能是异常值。不能把建立模型简单化为一个纯 数学过程,目的是寻找经济规律。(欧盟对华投资和 中国从欧盟进口)
多元线性回归模型的案例讲解

多元线性回归模型的案例讲解以下是一个关于房价的案例,用多元线性回归模型来分析房价与其他变量的关系。
假设我们想研究一些城市的房价与以下变量之间的关系:房屋面积、卧室数量、厨房数量和所在区域。
我们从不同的房屋中收集了这些变量的数据,以及对应的房价。
我们希望通过构建多元线性回归模型来预测房价。
首先,我们需要收集数据。
我们找到100个不同房屋的信息,包括房屋的面积、卧室数量、厨房数量和所在区域,以及对应的房价。
接下来,我们需要进行数据处理和探索性分析。
我们可以使用统计软件,如Python的pandas库,对数据进行清洗和处理。
我们可以检查数据的缺失值、异常值和离群点,并对其进行处理。
完成数据处理后,我们可以继续进行变量的选择和模型构建。
在多元线性回归中,我们需要选择合适的自变量,并建立模型。
可以使用统计软件,如Python的statsmodels库,来进行模型的构建。
在本例中,我们使用房屋面积、卧室数量、厨房数量和所在区域作为自变量,房价作为因变量。
我们可以构建如下的多元线性回归模型:房价=β0+β1*面积+β2*卧室数量+β3*厨房数量+β4*所在区域其中,β0、β1、β2、β3和β4是回归模型的系数,表示因变量与自变量之间的关系。
我们需要对模型进行拟合和检验。
使用统计软件,在模型拟合之后,我们可以得到回归模型的系数和统计指标。
常见的指标包括回归系数的显著性、解释方差、调整R方和残差分析等。
根据回归模型的系数,我们可以解释不同自变量对因变量的影响。
例如,如果回归系数β1大于0且显著,说明房屋面积对房价有正向影响。
同理,其他自变量的系数也可以解释其对因变量的影响。
最后,我们可以使用建立的多元线性回归模型进行房价的预测。
通过输入房屋的面积、卧室数量、厨房数量和所在区域等自变量的数值,我们可以预测其对应的房价。
需要注意的是,多元线性回归模型的效果不仅取决于数据的质量,还取决于模型的选择和拟合程度。
因此,在模型选择和拟合过程中,我们需要进行多次实验和优化,以得到较好的模型。
多元线性回归模型案例(DOC)

多元线性回归模型案例分析——中国人口自然增长分析一·研究目的要求中国从1971年开始全面开展了计划生育,使中国总和生育率很快从1970年的5.8降到1980年2.24,接近世代更替水平。
此后,人口自然增长率(即人口的生育率)很大程度上与经济的发展等各方面的因素相联系,与经济生活息息相关,为了研究此后影响中国人口自然增长的主要原因,分析全国人口增长规律,与猜测中国未来的增长趋势,需要建立计量经济学模型。
影响中国人口自然增长率的因素有很多,但据分析主要因素可能有:(1)从宏观经济上看,经济整体增长是人口自然增长的基本源泉;(2)居民消费水平,它的高低可能会间接影响人口增长率。
(3)文化程度,由于教育年限的高低,相应会转变人的传统观念,可能会间接影响人口自然增长率(4)人口分布,非农业与农业人口的比率也会对人口增长率有相应的影响。
二·模型设定为了全面反映中国“人口自然增长率”的全貌,选择人口增长率作为被解释变量,以反映中国人口的增长;选择“国名收入”及“人均GDP”作为经济整体增长的代表;选择“居民消费价格指数增长率”作为居民消费水平的代表。
暂不考虑文化程度及人口分布的影响。
从《中国统计年鉴》收集到以下数据(见表1):表1 中国人口增长率及相关数据设定的线性回归模型为:1222334t t t t t Y X X X u ββββ=++++三、估计参数利用EViews 估计模型的参数,方法是:1、建立工作文件:启动EViews ,点击File\New\Workfile ,在对话框“Workfile Range ”。
在“Workfile frequency ”中选择“Annual ” (年度),并在“Start date ”中输入开始时间“1988”,在“end date ”中输入最后时间“2005”,点击“ok ”,出现“Workfile UNTITLED ”工作框。
其中已有变量:“c ”—截距项 “resid ”—剩余项。
多元线性回归模型案例

多元线性回归模型案例多元线性回归是统计学中常用的一种回归分析方法,它可以用来研究多个自变量与因变量之间的关系。
在实际应用中,多元线性回归模型可以帮助我们理解不同自变量对因变量的影响程度,从而进行预测和决策。
下面,我们将通过一个实际案例来介绍多元线性回归模型的应用。
案例背景:某电商公司希望了解其产品销售额与广告投入、季节因素和竞争对手销售额之间的关系,以便更好地制定营销策略和预测销售额。
数据收集:为了分析这一问题,我们收集了一段时间内的产品销售额、广告投入、季节因素和竞争对手销售额的数据。
这些数据将作为我们多元线性回归模型的输入变量。
模型建立:我们将建立一个多元线性回归模型,以产品销售额作为因变量,广告投入、季节因素和竞争对手销售额作为自变量。
通过对数据进行拟合和参数估计,我们可以得到一个多元线性回归方程,从而揭示不同自变量对产品销售额的影响。
模型分析:通过对模型的分析,我们可以得出以下结论:1. 广告投入对产品销售额有显著影响,广告投入越大,产品销售额越高。
2. 季节因素也对产品销售额有一定影响,不同季节的销售额存在差异。
3. 竞争对手销售额对产品销售额也有一定影响,竞争对手销售额越大,产品销售额越低。
模型预测:基于建立的多元线性回归模型,我们可以进行产品销售额的预测。
通过输入不同的广告投入、季节因素和竞争对手销售额,我们可以预测出相应的产品销售额,从而为公司的营销决策提供参考。
结论:通过以上分析,我们可以得出多元线性回归模型在分析产品销售额与广告投入、季节因素和竞争对手销售额之间关系时的应用。
这种模型不仅可以帮助我们理解不同因素对产品销售额的影响,还可以进行销售额的预测,为公司的决策提供支持。
总结:多元线性回归模型在实际应用中具有重要意义,它可以帮助我们理解复杂的变量关系,并进行有效的预测和决策。
在使用多元线性回归模型时,我们需要注意数据的选择和模型的建立,以确保模型的准确性和可靠性。
通过以上案例,我们对多元线性回归模型的应用有了更深入的理解,希望这对您有所帮助。
多元线性回归数学建模经典案例

多元线性回归黄冈职业技术学院数学建模协会胡敏作业:在农作物害虫发生趋势的预报研究中,所涉及的5个自变量及因变量的10组观测数据如下,试建立y对x1-x5的回归模型,指出那些变量对y有显著的线性贡献,贡献大小顺序。
x1 x2 x3 x4 x5 y9.200 2.732 1.471 0.332 1.138 1.1559.100 3.732 1.820 0.112 0.828 1.1468.600 4.882 1.872 0.383 2.131 1.84110.233 3.968 1.587 0.181 1.349 1.3565.600 3.732 1.841 0.297 1.815 0.8635.367 4.236 1.873 0.063 1.352 0.9036.133 3.146 1.987 0.280 1.647 0.1148.200 4.646 1.615 0.379 4.565 0.8988.800 4.378 1.543 0.744 2.073 1.9307.600 3.864 1.599 0.342 2.423 1.104编写程序如下:data ex;input x1-x5 y@@;cards;9.200 2.732 1.471 0.332 1.138 1.155 9.100 3.732 1.820 0.112 0.828 1.146 8.600 4.882 1.872 0.383 2.131 1.841 10.233 3.968 1.587 0.181 1.349 1.356 5.600 3.732 1.841 0.297 1.815 0.8635.367 4.236 1.873 0.063 1.352 0.9036.133 3.146 1.987 0.280 1.647 0.114 8.200 4.646 1.615 0.379 4.565 0.898 8.800 4.378 1.543 0.744 2.073 1.9307.600 3.864 1.599 0.342 2.423 1.104 ;proc reg;model y=x1 x2 x3 x4 x5/cli;run;运行结果如下:(1)回归方程显著性检验.Analysis of VarianceSum of MeanSource DF Squares S quare F Value Pr > FModel 5 2.252070.45041 11.63 0.0170Error 4 0.154970.03874Corrected Total 9 2.40704Root MSE 0.19683 R-Square 0.9356Dependent Mean 1.13100 Adj R-Sq 0.8551Coeff Var 17.40333由Analysis of Variance表可知,其F Value=11.63,Pr > F的值0.0170小于0.05,故拒绝原假设,接受备择假设,认为y与x1 x2 x3 x4 x5之间具有显著性相关系;由R-Square的值为0.9356可知该方程的拟合度高,样本观察值有93.6%的信息可以用回归方程进行解释,故拟合效果较好,认为y与x1 x2 x3 x4 x5之间具有显著性的相关关系。
—多元线性回归分析案例
t=(2.184942) (3.849318) (12.80847)
(7.130844)
R2 0.963517 R 2 0.959307 F 228.2846 df 26
模型检验:拟合优度可决系数 R2 0.963517 较高, 修正的可决系数 R 2 0.959307 也较高,表明模型 拟合较好。
t0025260684因为各解释变量的参数对应的t统计量均大于0684这说明在5的显著水平下斜率系数均显著不为零表明三大产业的增长率对gdp增长都有显著影响
多元线性回归分析 案例
目录
• 1.建立模型 • 2.模型参数估计 • 3.检验 • 4.预测 • 5.软件操作
1.建立模型
考察三大产业的增长对我国经济增长 的贡献
F检验: 针对H0: b1=b2=b3=0
F 228.2846
给定 0.05,得临界值F0.0(5 k,n k 1) F0.05(3,26) 2.98 由于228.2846>2.98,故拒绝H0 回归方程是显著的。
t检验: 给定 0.05,查自由度t分布表得:t0.025(26)=0.684 因为各解释变量的参数对应的t统计量均大于0.684, 这说明在5%的显著水平下,斜率系数均显著不为零, 表明三大产业的增长率对GDP增长都有显著影响。
8.3
2.8
8.4
10.3
1987 11.6
4.7
13.7
14.4 2002
9.1
2.9
9.8
10.4
1988 11.3
2.5
14.5
13.2 2003 10.0
2.5
多元线性回归模型案例
我国农民收入影响因素的回归分析本文力图应用适当的多元线性回归模型,对有关农民收入的历史数据和现状进行分析,探讨影响农民收入的主要因素,并在此基础上对如何增加农民收入提出相应的政策建议。
农民收入水平的度量常采用人均纯收入指标。
影响农民收入增长的因素是多方面的,既有结构性矛盾因素,又有体制性障碍因素。
但可以归纳为以下几个方面:一是农产品收购价格水平。
二是农业剩余劳动力转移水平。
三是城市化、工业化水平。
四是农业产业结构状况。
五是农业投入水平。
考虑到复杂性和可行性,所以对农业投入与农民收入,本文暂不作讨论。
因此,以全国为例,把农民收入与各影响因素关系进行线性回归分析,并建立数学模型。
一、计量经济模型分析 (一)、数据搜集根据以上分析,我们在影响农民收入因素中引入7个解释变量。
即: 2x -财政用于农业的支出的比重,3x -第二、三产业从业人数占全社会从业人数的比重,4x -非农村人口比重,5x -乡村从业人员占农村人口的比重,6x -农业总产值占农林牧总产值的比重,7x -农作物播种面积,8x —农村用电量。
资料来源《中国统计年鉴2006》。
(二)、计量经济学模型建立 我们设定模型为下面所示的形式:122334455667788t t Y X X X X X X X u ββββββββ=++++++++ 利用Eviews 软件进行最小二乘估计,估计结果如下表所示:Dependent Variable: Y Method: Least Squares Sample: 1986 2004 C -1102.373 375.8283 -2.933184 0.0136 X1 -6.635393 3.781349 -1.754769 0.1071 X3 18.22942 2.066617 8.820899 0.0000 X4 2.430039 8.370337 0.290316 0.7770 X5 -16.23737 5.894109 -2.754847 0.0187 X6 -2.155208 2.770834 -0.777819 0.4531 X7 0.009962 0.002328 4.278810 0.0013 R-squared0.995823 Mean dependent var 345.5232 Adjusted R-squared 0.993165 S.D. dependent var 139.7117 S.E. of regression 11.55028 Akaike info criterion 8.026857 Sum squared resid 1467.498 Schwarz criterion 8.424516 Log likelihood -68.25514 F-statistic 374.6600 表1 最小二乘估计结果回归分析报告为:()()()()()()()()()()()()()()()()23456782ˆ -1102.373-6.6354X +18.2294X +2.4300X -16.2374X -2.1552X +0.0100X +0.0634X 375.83 3.7813 2.066618.37034 5.8941 2.77080.002330.02128 -2.933 1.7558.820900.20316 2.7550.778 4.27881 2.97930.99582i Y SE t R ===---=230.99316519 1.99327374.66R Df DW F ====二、计量经济学检验(一)、多重共线性的检验及修正①、检验多重共线性(a)、直观法从“表1 最小二乘估计结果”中可以看出,虽然模型的整体拟合的很好,但是x4 x6的t统计量并不显著,所以可能存在多重共线性。
多元线性回归模型案例
多元线性回归模型案例在统计学中,多元线性回归是一种用于研究多个自变量与一个因变量之间关系的方法。
它可以帮助我们了解各个自变量对因变量的影响程度,并预测因变量的取值。
本文将通过一个实际案例来介绍多元线性回归模型的应用。
案例背景:假设我们是一家房地产公司的数据分析师,公司希望通过分析房屋的各项特征来预测房屋的销售价格。
我们收集了一批房屋的数据,包括房屋的面积、卧室数量、浴室数量、地理位置等多个自变量,以及每套房屋的销售价格作为因变量。
数据准备:首先,我们需要对收集到的数据进行清洗和处理。
这包括处理缺失值、异常值,对数据进行标准化等操作,以确保数据的质量和可靠性。
在数据准备阶段,我们还需要将数据分为训练集和测试集,以便后续模型的建立和验证。
模型建立:接下来,我们使用多元线性回归模型来建立房屋销售价格与各项特征之间的关系。
假设我们的模型为:Y = β0 + β1X1 + β2X2 + ... + βnXn + ε。
其中,Y表示房屋销售价格,X1、X2、...、Xn表示房屋的各项特征,β0、β1、β2、...、βn表示模型的系数,ε表示误差项。
模型评估:建立模型后,我们需要对模型进行评估,以验证模型的拟合程度和预测能力。
我们可以使用各项统计指标如R方、均方误差等来评估模型的拟合程度和预测能力,同时也可以通过绘制残差图、QQ图等来检验模型的假设是否成立。
模型优化:在评估模型的过程中,我们可能会发现模型存在欠拟合或过拟合的问题,需要对模型进行优化。
优化的方法包括添加交互项、引入多项式项、进行特征选择等操作,以提高模型的拟合程度和预测能力。
模型应用:最后,我们可以使用优化后的模型来预测新的房屋销售价格。
通过输入房屋的各项特征,模型可以给出相应的销售价格预测值,帮助公司进行房地产市场的决策和规划。
结论:通过本案例,我们了解了多元线性回归模型在房地产数据分析中的应用。
通过建立、评估、优化和应用模型的过程,我们可以更好地理解各项特征对房屋销售价格的影响,并进行有效的预测和决策。
多元线性回归模型的案例讲解
多元线性回归模型的案例讲解案例:房价预测在房地产市场中,了解各种因素对房屋价格的影响是非常重要的。
多元线性回归模型是一种用于预测房屋价格的常用方法。
在这个案例中,我们将使用多个特征来预测房屋的价格,例如卧室数量、浴室数量、房屋面积、地段等。
1.数据收集与预处理为了构建一个准确的多元线性回归模型,我们需要收集足够的数据。
我们可以从多个渠道收集房屋销售数据,例如房地产公司的数据库或者在线平台。
数据集应包括房屋的各种特征,例如卧室数量、浴室数量、房屋面积、地段等,以及每个房屋的实际销售价格。
在数据收集过程中,我们还需要对数据进行预处理。
这包括处理缺失值、异常值和重复值,以及进行特征工程,例如归一化或标准化数值特征,将类别特征转换为二进制变量等。
2.模型构建在数据预处理完成后,我们可以开始构建多元线性回归模型。
多元线性回归模型的基本方程可以表示为:Y=β0+β1X1+β2X2+……+βnXn其中,Y表示房屋价格,X1、X2、……、Xn表示各种特征,β0、β1、β2、……、βn表示回归系数。
在建模过程中,我们需要选择合适的特征来构建模型。
可以通过统计分析或者领域知识来确定哪些特征对房价具有显著影响。
3.模型评估与验证构建多元线性回归模型后,我们需要对模型进行评估和验证。
最常用的评估指标是均方误差(Mean Squared Error)和决定系数(R-squared)。
通过计算预测值与实际值之间的误差平方和来计算均方误差。
决定系数可以衡量模型对观测值的解释程度,取值范围为0到1,越接近1表示模型越好。
4.模型应用完成模型评估与验证后,我们可以将模型应用于新的数据进行房价预测。
通过将新数据的各个特征代入模型方程,可以得到预测的房价。
除了房价预测,多元线性回归模型还可以用于其他房地产市场相关问题的分析,例如预测租金、评估土地价格等。
总结:多元线性回归模型可以在房地产市场的房价预测中发挥重要作用。
它可以利用多个特征来解释房价的变化,并提供准确的价格预测。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
多元线性回归
黄冈职业技术学院数学建模协会胡敏
作业:
在农作物害虫发生趋势的预报研究中,所涉及的5个自变量及因变量的10组观测数据如下,试建立y对x1-x5的回归模型,指出那些变量对y有显著的线性贡献,贡献大小顺序。
x1 x2 x3 x4 x5 y
9.200 2.732 1.471 0.332 1.138 1.155
9.100 3.732 1.820 0.112 0.828 1.146
8.600 4.882 1.872 0.383 2.131 1.841
10.233 3.968 1.587 0.181 1.349 1.356
5.600 3.732 1.841 0.297 1.815 0.863
5.367 4.236 1.873 0.063 1.352 0.903
6.133 3.146 1.987 0.280 1.647 0.114
8.200 4.646 1.615 0.379 4.565 0.898
8.800 4.378 1.543 0.744 2.073 1.930
7.600 3.864 1.599 0.342 2.423 1.104
编写程序如下:
data ex;
input x1-x5 y@@;
cards;
9.200 2.732 1.471 0.332 1.138 1.155
9.100 3.732 1.820 0.112 0.828 1.146
8.600 4.882 1.872 0.383 2.131 1.841
10.233 3.968 1.587 0.181 1.349 1.356
5.600 3.732 1.841 0.297 1.815 0.863
5.367 4.236 1.873 0.063 1.352 0.903
6.133 3.146 1.987 0.280 1.647 0.114
8.200 4.646 1.615 0.379 4.565 0.898
8.800 4.378 1.543 0.744 2.073 1.930
7.600 3.864 1.599 0.342 2.423 1.104
;
proc reg;
model y=x1 x2 x3 x4 x5/cli;
run;
运行结果如下:
(1)回归方程显著性检验.
Analysis of Variance
Sum of Mean
Source DF Squares Square F Value Pr > F
Model 5 2.25207 0.45041 11.63 0.0170
Error 4 0.15497 0.03874
Corrected Total 9 2.40704
Root MSE 0.19683 R-Square 0.9356
Dependent Mean 1.13100 Adj R-Sq 0.8551
Coeff Var 17.40333
由Analysis of Variance表可知,其F Value=11.63,Pr > F的值0.0170小于0.05,故拒绝原假设,接受备择假设,认为y与x1 x2 x3 x4 x5之间具有显著性相关系;由R-Square的值为0.9356可知该方程的拟合度高,样本观察值有93.6%的信息可以用回归方程进行解释,故拟合效果较好,认为y与x1 x2 x3 x4 x5之间具有显著性的相关关系。
(2)参数显著性检验.
Parameter Estimates
Parameter Standard
Variable DF Estimate Error t Value Pr > |t|
Intercept 1 0.38113 1.31757 0.29 0.7868
x1 1 0.06054 0.05697 1.06 0.3479
x2 1 0.66119 0.13328 4.96 0.0077
x3 1 -1.14856 0.59877 -1.92 0.1275
x4 1 0.96868 0.42115 2.30 0.0829
x5 1 -0.33745 0.08628 -3.91 0.0174
由Parameter Estimates表可知,对自变量x1,t检验值为t=1.06, Pr > |t|的值等于0.3479,大于0.05,因此,接受原假设H0:β2=0,认为x1的系数为0,说明x1的系数没有通过检验。
为此,需要在程序model y=x1 x2 x3 x4 x5中去掉x1。
再次运行得到如下结果:
Parameter Estimates
Parameter Standard
Variable DF Estimate Error t Value Pr > |t|
Intercept 1 1.48612 0.81939 1.81 0.1295
x2 1 0.71294 0.12565 5.67 0.0024
x3 1 -1.58815 0.43840 -3.62 0.0152
x4 1 0.94190 0.42579 2.21 0.0779
x5 1 -0.37185 0.08100 -4.59 0.0059 由Parameter Estimates表可知,对x4检验t=2.21,Pr > |t|的值0.0779,大于0.05,因此,接受原假设H0:β2=0,认为x1的系数为0,说明x4的系数没有通过检验。
为此,需要在程序model y= x2 x3 x4 x5中去掉x4。
再次运行得到如下结果:
Parameter Estimates
Parameter Standard
Variable DF Estimate Error t Value Pr > |t|
Intercept 1 2.24871 0.95453 2.36 0.0566
x2 1 0.75463 0.15952 4.73 0.0032
x3 1 -1.99964 0.50976 -3.92 0.0078
x5 1 -0.33313 0.10156 -3.28 0.0168
以上结果表明所有变量的系数均通过检验,于是该线性模型即可得到。
(3)拟合区间.
Dependent Variable: y
Output Statistics
Dep Var Predicted Std Error
Obs y Value Mean Predict 95% CL Predict Residual
1 1.1550 0.9898 0.207
2 0.1839 1.7957 0.1652
2 1.1460 1.1498 0.1264 0.451
3 1.848
4 -0.003817
3 1.8410 1.4796 0.1668 0.7320 2.2272 0.3614
4 1.3560 1.6203 0.1332 0.9141 2.3264 -0.2643
5 0.8630 0.7790 0.1073 0.0998 1.4582 0.0840
6 0.9030 1.2496 0.1309 0.5460 1.9532 -0.3466
7 0.1140 0.1008 0.2074 -0.7054 0.9071 0.0132
8 0.8980 1.0046 0.2310 0.1608 1.8484 -0.1066
9 1.9300 1.7765 0.1454 1.0561 2.4969 0.1535
10 1.1040 1.1600 0.1070 0.4811 1.8389 -0.0560
以上为样本的拟合结果,其中Dep Var y 为因变量的原始值,Predicted Value为y的拟合值,95% CL Predict为拟合值95%的拟合区间,Residual为残差。
综合以上分析可以得到回归方程:y=0.75463x2 -1.99964x3 -0.33313x5+2.24871
故对y有显著的线性贡献大小顺序为x3 > x2 > x5。