计量经济学 (第二版)庞皓 科学出版社 第八章练习题答案
计量经济学课后习题答案第八章_答案

第八章虚拟变量模型1. 回归模型中引入虚拟变量的作用是什么?答:在模型中引入虚拟变量,主要是为了寻找某(些)定性因素对解释变量的影响。
加法方式与乘法方式是最主要的引入方式,前者主要适用于定性因素对截距项产生影响的情况,后者主要适用于定性因素对斜率项产生影响的情况。
除此外,还可以加法与乘法组合的方式引入虚拟变量,这时可测度定性因素对截距项与斜率项同时产生影响的情况。
2. 虚拟变量有哪几种基本的引入方式?它们各适用于什么情况?答:在模型中引入虚拟变量的主要方式有加法方式与乘法方式,前者主要适用于定性因素对截距项产生影响的情况,后者主要适用于定性因素对斜率项产生影响的情况。
除此外,还可以加法与乘法组合的方式引入虚拟变量,这时可测度定性因素对截距项与斜率项同时产生影响的情况。
3.什么是虚拟变量陷阱?答:根据虚拟变量的设置原则,一般情况下,如果定性变量有m个类别,则需在模型中引入m-1个变量。
如果引入了m个变量,就会导致模型解释变量出现完全的共线性问题,从而导致模型无法估计。
这种由于引入虚拟变量个数与类别个数相等导致的模型无法估计的问题,称为“虚拟变量陷阱”。
4.在一项对北京某大学学生月消费支出的研究中,认为学生的消费支出除受其家庭的每月收入水平外,还受在学校中是否得到奖学金,来自农村还是城市,是经济发达地区还是欠发达地区,以及性别等因素的影响。
试设定适当的模型,并导出如下情形下学生消费支出的平均水平:(1) 来自欠发达农村地区的女生,未得到奖学金;(2)来自欠发达城市地区的男生,得到奖学金;(3)来自发达地区的农村女生,得到奖学金;(4)来自发达地区的城市男生,未得到奖学金。
解答:记学生月消费支出为Y,其家庭月收入水平为X,则在不考虑其他因素的影响时,有如下基本回归模型:Y i=β0+β1X i+μi有奖学金1 来自城市无奖学金来自农村来自发达地区 1 男性0 来自欠发达地区0 女性Y i=β0+β1X i+α1D1i+α2D2i+α3D3i+α4D4i+μi由此回归模型,可得如下各种情形下学生的平均消费支出:(1)来自欠发达农村地区的女生,未得到奖学金时的月消费支出:E(Y i|=X i,D1i=D2i=D3i=D4i=0)=β0+β1X i(2)来自欠发达城市地区的男生,得到奖学金时的月消费支出:E(Y i|=X i,D1i=D4i=1,D2i=D3i=0)=(β0+α1+α4)+β1X i(3)来自发达地区的农村女生,得到奖学金时的月消费支出:E(Y i |=X i ,D 1i =D 3i =1,D 2i =D 4i =0)=(β0+α1+α3)+β1X i (4)来自发达地区的城市男生,未得到奖学金时的月消费支出: E(Y i |=X i ,D 2i =D 3i =D 4i =1,D 1i =0)=(β0+α2+α3+α4)+β1X i5. 研究进口消费品的数量Y 与国民收入X 的模型关系时,由数据散点图显示1979年前后Y 对X 的回归关系明显不同,进口消费函数发生了结构性变化:基本消费部分下降了,而边际消费倾向变大了。
计量经济学庞皓第二版第八章练习题及参考答案

第八章练习题及参考解答8.1 Sen 和Srivastava (1971)在研究贫富国之间期望寿命的差异时,利用101个国家的数据,建立了如下的回归模型:2.409.39ln3.36((ln 7))i i i i Y X D X =-+--(4.37) (0.857) (2.42) R 2=0.752其中:X 是以美元计的人均收入;Y 是以年计的期望寿命;Sen 和Srivastava 认为人均收入的临界值为1097美元(ln10977=),若人均收入超过1097美元,则被认定为富国;若人均收入低于1097美元,被认定为贫穷国。
括号内的数值为对应参数估计值的t-值。
1)解释这些计算结果。
2)回归方程中引入()ln 7i i D X -的原因是什么?如何解释这个回归解释变量? 3)如何对贫穷国进行回归?又如何对富国进行回归? 4)从这个回归结果中可得到的一般结论是什么? 练习题8.1参考解答: 1. 结果解释依据给定的估计检验结果数据,对数人均收入对期望寿命在统计上并没有显著影响,截距和变量()ln 7i i D X -在统计上对期望寿命有显著影响;同时,()()2.40 3.3679.39 3.36ln ((ln 7)) 1 2.409.39ln 0 i i i i i i i X D X D Y X D ⎧-+⨯+---==⎨-+=⎩富国时穷国时 表明贫富国之间的期望寿命存在差异。
2. 回归方程中引入()ln 7i i D X -的原因是从截距和斜率两个方面考证收入因素对期望寿命的影响。
这个回归解释变量可解释为对期望寿命的影响存在截距差异和斜率差异的共同因素。
3. 对穷国进行回归时,回归模型为12ln 1097i i i i i i Y X Y X αα=+≤,其中,为美元时的寿命; 对富国进行回归时,回归模型为12ln 1097i i i i i i Y X Y X ββ=+>,其中,为美元时的寿命;4. 一般的结论为富国的期望寿命药高于穷国的期望寿命,并且随着收入的增加,在平均意义上,富国的期望寿命的增加变化趋势优于穷国,贫富国之间的期望寿命的确存在显著差异。
庞皓《计量经济学》笔记和课后习题详解(虚拟变量回归)【圣才出品】

1.用虚拟变量表示不同截距的回归——加法方式 以加法方式将虚拟变量引入模型,只会改变模型在不同情况下的截距,不会影响斜率。 按照变量的种类和数量进行分类,可以分成四种情况,具体如表 8-2 所示。
2 / 27
圣才电子书 十万种考研考证电子书、题库视频学习平台
2.用虚拟变量表示不同斜率的回归——乘法方式 以乘法形式引入虚拟解释变量,会改变模型的截距和斜率。用乘法方式引入虚拟变量的 作用是:①进行两个回归模型的比较,即结构变化检验;②进行因素间的交互影响分析;③ 使模型更加符合现实经济现象。按照不同的作用,可以将乘法方式分成三种,具体如表 8-3 所示。
表 8-3 以乘法方式引入虚拟变量的三种类型
2.虚拟变量的作用及模型的类型 (1)虚拟变量的作用 ①可以作为性别、所有制等属性因素的代表。 ②可以作为受教育程度、管理者素质等非精确计量的数量因素的代表。 ③可以作为战争、灾害、改革前后等偶然因素或政策因素的代表。 ④可以作为时间序列分析中季节(月份)的代表。 ⑤可以实现分段回归,研究斜率、截距的变动,或比较两个回归模型的结构差异等。 (2)虚拟变量模型的类型(见表 8-1)
考点三:虚拟被解释变量 ★★★★
1.线性概率模型(LPM) (1)线性概率模型含义 当被解释变量是虚拟变量,并且模型的函数形式为线性时,即 Yi=β1+β2Xi+ui,该模 型就是线性概率模型。 由于 E(Yi)=0·(1-pi)+1·pi=pi,其中 pi 表示 Yi=1 的概率,所以系数 β2 可解释 为:当其他条件不变时,X 每增加 1 单位,Y=1 的概率增加值。 (2)线性概率模型的估计 ①线性概率模型不能直接用普通最小二乘进行估计,因为存在如下问题: a.随机扰动项 ui 的非正态性。在线性概率模型中,ui 不再服从正态分布,但是对参数 的假设检验和区间估计要求随机扰动项 ui 服从正态分布。当对大样本进行估计时,OLS 估 计量的概率分布将会趋近于正态分布,估计值不会因为非正态性而产生很大的误差。
计量经济学第二版课后习题答案1-8章 - 编辑版
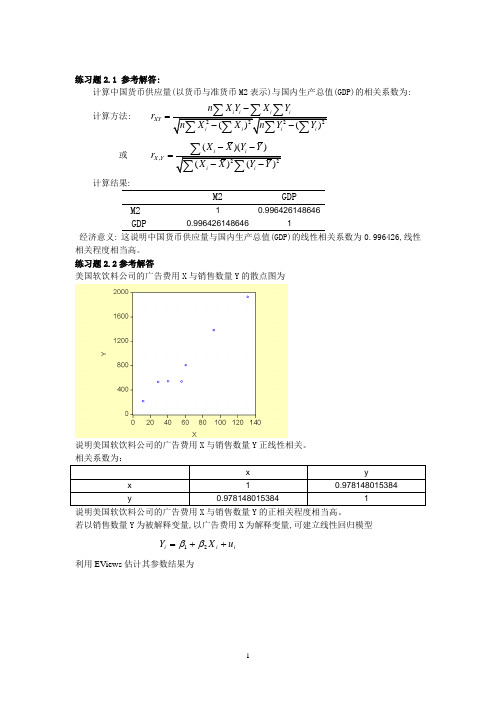
练习题2.1 参考解答:计算中国货币供应量(以货币与准货币M2表示)与国内生产总值(GDP)的相关系数为:计算方法: XY n X Y X Y r -=或,()()X Y X X Y Y r --=计算结果:M2GDPM2 10.996426148646GDP0.9964261486461经济意义: 这说明中国货币供应量与国内生产总值(GDP)的线性相关系数为0.996426,线性相关程度相当高。
练习题2.2参考解答美国软饮料公司的广告费用X 与销售数量Y 的散点图为说明美国软饮料公司的广告费用X 与销售数量Y 正线性相关。
相关系数为:说明美国软饮料公司的广告费用X 与销售数量Y 的正相关程度相当高。
若以销售数量Y 为被解释变量,以广告费用X 为解释变量,可建立线性回归模型 i i i u X Y ++=21ββ 利用EViews 估计其参数结果为经t 检验表明, 广告费用X 对美国软饮料公司的销售数量Y 确有显著影响。
回归结果表明,广告费用X 每增加1百万美元, 平均说来软饮料公司的销售数量将增加14.40359(百万箱)。
练习题2.3参考解答: 1、 建立深圳地方预算内财政收入对GDP 的回归模型,建立EViews 文件,利用地方预算内财政收入(Y )和GDP 的数据表,作散点图可看出地方预算内财政收入(Y )和GDP 的关系近似直线关系,可建立线性回归模型: t t t u GDP Y ++=21ββ 利用EViews 估计其参数结果为即 ˆ20.46110.0850t tY GDP =+ (9.8674) (0.0033)t=(2.0736) (26.1038) R 2=0.9771 F=681.4064经检验说明,深圳市的GDP 对地方财政收入确有显著影响。
20.9771R =,说明GDP 解释了地方财政收入变动的近98%,模型拟合程度较好。
模型说明当GDP 每增长1亿元时,平均说来地方财政收入将增长0.0850亿元。
计量经济学(庞皓)课后思考题答案

思考题答案第一章绪论思考题1.1怎样理解产生于西方国家的计量经济学能够在中国的经济理论研究和现代化建设中发挥重要作用?答:计量经济学的产生源于对经济问题的定量研究,这是社会经济发展到一定阶段的客观需要。
计量经济学的发展是与现代科学技术成就结合在一起的,它反映了社会化大生产对各种经济因素和经济活动进行数量分析的客观要求。
经济学从定性研究向定量分析的发展,是经济学逐步向更加精密、更加科学发展的表现。
我们只要坚持以科学的经济理论为指导,紧密结合中国经济的实际,就能够使计量经济学的理论与方法在中国的经济理论研究和现代化建设中发挥重要作用。
1.2理论计量经济学和应用计量经济学的区别和联系是什么?答:计量经济学不仅要寻求经济计量分析的方法,而且要对实际经济问题加以研究,分为理论计量经济学和应用计量经济学两个方面。
理论计量经济学是以计量经济学理论与方法技术为研究内容,目的在于为应用计量经济学提供方法论。
所谓计量经济学理论与方法技术的研究,实质上是指研究如何运用、改造和发展数理统计方法,使之成为适合测定随机经济关系的特殊方法。
应用计量经济学是在一定的经济理论的指导下,以反映经济事实的统计数据为依据,用计量经济方法技术研究计量经济模型的实用化或探索实证经济规律、分析经济现象和预测经济行为以及对经济政策作定量评价。
1.3怎样理解计量经济学与理论经济学、经济统计学的关系?答:1、计量经济学与经济学的关系。
联系:计量经济学研究的主体—经济现象和经济关系的数量规律;计量经济学必须以经济学提供的理论原则和经济运行规律为依据;经济计量分析的结果:对经济理论确定的原则加以验证、充实、完善。
区别:经济理论重在定性分析,并不对经济关系提供数量上的具体度量;计量经济学对经济关系要作出定量的估计,对经济理论提出经验的内容。
2、计量经济学与经济统计学的关系。
联系:经济统计侧重于对社会经济现象的描述性计量;经济统计提供的数据是计量经济学据以估计参数、验证经济理论的基本依据;经济现象不能作实验,只能被动地观测客观经济现象变动的既成事实,只能依赖于经济统计数据。
计量经济学第二版第八章答案

计量经济学第二版第八章答案【篇一:庞皓计量经济学课后答案第八章】业1、①在给定的数据中可以看出人均收入的系数的t值t(?2)?0.857,di(lnxi?7)系数的t值t(?3)?2.42,在给定显著性水平??0.05下n=101,t0.025(101)?1.984。
所以人均收入对期望寿命并没有显著影响。
而di(lnxi?7)对期望寿命有显著影响。
当人均收入超过1097美元时,即di=1为富国时:???2.40?9.39lnx?3.36(lnx?7)?21.12?6.03lnx yiiii当人均收入未超过1097美元时,即di=0为穷国时:???2.40?9.39lnx yii②引入di(lnxi?7)的原因是从截距和斜率两个方面来考虑收入对期望寿命的影响。
③对穷国进行回归时,yi取xi?1097时的值。
对富国进行回归时,yi取xi?1097时的值④结论:富国的期望寿命高于穷国的期望寿命。
贫富国之间的期望寿命的确存在显著差异。
2、①d1t???1,t为1987年及以后?0,t为1987年以前 d2t??年及以后?1,t为1994年以前?0,t为1994年及以后年及以后?1,t为2006?1,t为2008 d3t?? d4t?? 0,t为2006年以前0,t为2008年以前??②从图形上看。
consume和income 及employment存在线性相关关系。
而与burden从图形上看不出线性关系。
所以对模型的设定保持怀疑态度。
③?umecons.16?0.63incomeconsume.51employmentt?1674t?0.0 86t?1?537t?202.50burden.27d2t?127.04d3t?172.2d4tt?7.22d1t?194r2?0.9998672?0.99979 2 f=13189.98 dw=2.921拟合效果好,且通过dw检验由回归可知consumet,d1td3t的系数未能通过显著性水平??0.05下的tt?1,burden检验。
计量经济学(庞皓)课后思考题规范标准答案

2.4为什么在对参数作最小二乘估计之前,要对模型提出古典假设?
答:在对参数作最小二乘估计之前,要对模型提出古典假设。因为模型中有随机扰动,估计的参数是随机变量,只有对随机扰动的分布作出假定,才能确定所估计参数的分布性质,也才可能进行假设检验和区间估计。只有具备一定的假定条件,所作出的估计才具有较好的统计性质。
在简单线性回归中,可决系数越大,说明在总变差中由模型作出了解释的部分占的比重越大,X对Y的解释能力越强,模型拟合优度越好。对参数的t检验是判断解释变量X是否是被解释变量Y的显著影响因素。二者的目的作用是一致的。
2.7有人说:“得到参数区间估计的上下限后,说明参数的真实值落入这个区间的概率为 。”如何评论这种说法?
一般来说参数是未知的,又是不可直接观测的。由于随机误差项的存在,参数也不能通过变量值去精确计算。只能通过变量样本观测值选择适当方法去估计。
1.10你能分别举出三个时间序列数据、截面数据、面板数据、虚拟变量数据的实际例子,并分别说明这些数据的来源吗?
答:时间序列数据:中国1981年至2010年国内生产总值,可从中国统计年鉴查得数据。
计量经济学(庞浩)第二版课后习题答案(全)
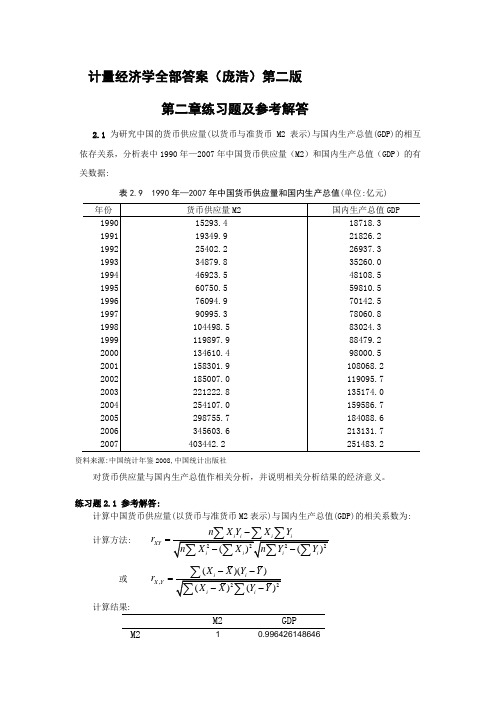
计量经济学全部答案(庞浩)第二版第二章练习题及参考解答2.1 为研究中国的货币供应量(以货币与准货币M2表示)与国内生产总值(GDP)的相互依存关系,分析表中1990年—2007年中国货币供应量(M2)和国内生产总值(GDP )的有关数据:表2.9 1990年—2007年中国货币供应量和国内生产总值(单位:亿元)资料来源:中国统计年鉴2008,中国统计出版社对货币供应量与国内生产总值作相关分析,并说明相关分析结果的经济意义。
练习题2.1 参考解答:计算中国货币供应量(以货币与准货币M2表示)与国内生产总值(GDP)的相关系数为:计算方法: XY n X Y X Y r -=或 ,()()X Y X X Y Y r --=计算结果:M2GDPM210.996426148646GDP 0.996426148646 1经济意义: 这说明中国货币供应量与国内生产总值(GDP)的线性相关系数为0.996426,线性相关程度相当高。
2.2 为研究美国软饮料公司的广告费用X与销售数量Y的关系,分析七种主要品牌软饮料公司的有关数据表2.10 美国软饮料公司广告费用与销售数量品牌名称广告费用X(百万美元) 销售数量Y(百万箱) Coca-Cola Classic 131.3 1929.2Pepsi-Cola 92.4 1384.6Diet-Coke 60.4 811.4Sprite 55.7 541.5Dr.Pepper 40.2 546.9Moutain Dew 29.0 535.67-Up 11.6 219.5 资料来源:(美) Anderson D R等. 商务与经济统计.机械工业出版社.1998. 405绘制美国软饮料公司广告费用与销售数量的相关图, 并计算相关系数,分析其相关程度。
能否在此基础上建立回归模型作回归分析?练习题2.2参考解答美国软饮料公司的广告费用X与销售数量Y的散点图为说明美国软饮料公司的广告费用X与销售数量Y正线性相关。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第八章8.1 Sen 和Srivastava (1971)在研究贫富国之间期望寿命的差异时,利用101个国家的数据,建立了如下的回归模型:2.409.39ln3.36((ln 7))i i i i Y X D X =-+--(4.37) (0.857) (2.42) R 2=0.752其中:X 是以美元计的人均收入;Y 是以年计的期望寿命;Sen 和Srivastava 认为人均收入的临界值为1097美元(ln 10977=),若人均收入超过1097美元,则被认定为富国;若人均收入低于1097美元,被认定为贫穷国。
括号内的数值为对应参数估计值的t-值。
1)解释这些计算结果。
2)回归方程中引入()ln 7i i D X -的原因是什么?如何解释这个回归解释变量? 3)如何对贫穷国进行回归?又如何对富国进行回归? 4)从这个回归结果中可得到的一般结论是什么? 练习题8.1参考解答: 1. 结果解释依据给定的估计检验结果数据,对数人均收入对期望寿命在统计上并没有显著影响,截距和变量()ln 7i i D X -在统计上对期望寿命有显著影响;同时,()()2.40 3.3679.39 3.36ln ((ln 7)) 1 2.409.39ln 0 i i i i i i i X D X D Y X D ⎧-+⨯+---==⎨-+=⎩富国时穷国时表明贫富国之间的期望寿命存在差异。
2. 回归方程中引入()ln 7i i D X -的原因是从截距和斜率两个方面考证收入因素对期望寿命的影响。
这个回归解释变量可解释为对期望寿命的影响存在截距差异和斜率差异的共同因素。
3. 对穷国进行回归时,回归模型为12ln 1097i i i i i i Y X Y X αα=+≤,其中,为美元时的寿命; 对富国进行回归时,回归模型为12ln 1097i i i i i i Y X Y X ββ=+>,其中,为美元时的寿命;4. 一般的结论为富国的期望寿命药高于穷国的期望寿命,并且随着收入的增加,在平均意义上,富国的期望寿命的增加变化趋势优于穷国,贫富国之间的期望寿命的确存在显著差异。
8.2个人所得税起征点调整对居民消费支出会产生重要的影响。
为研究个人所得税起征点调整对城镇居民个人消费支出行为的效应,收集相关的数据如表8.4和表8.5所示。
表8.4 个人所得税起征点调整情况表8.5 城镇居民收入与消费的有关数据若模型设定为:Consume t=C t+α1Income t+α2Consume t-1+α3Employment t+α4Burden t+α5d1t+α6d2t+α7d3t+α8d4t+εt其中Consume t表示t期城镇居民家庭人均消费支出,Income t表示t期城镇居民家庭人均可支配收入,Employment t表示t期城镇居民家庭平均每户就业人口, Burden t表示t期城镇居民家庭平均每一就业者负担人数,d it(i=1,2,3,4)相应的虚拟变量。
1)构造用于描述个人所得税调整的虚拟变量,并简要说明其理由;2)用散点图描述两两变量之间的关系,并给出你对模型设定的结论;3)依据测算,选择你认为更能描述客观实际的模型,并简要说明其理由;4)根据分析结果,你对提高个人所得税起征点影响居民消费的有效性能得出什么结论? 练习题8.2参考解答:录入如下数据Dependent Variable: CONSUMEMethod: Least SquaresDate: 08/24/09 Time: 13:14Sample (adjusted): 1986 2008Included observations: 23 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.C 744.7966 378.0662 1.970017 0.0676CONSUME(-1) 0.084873 0.050907 1.667221 0.1162 INCOME 0.633118 0.035198 17.98729 0.0000 LOG(EMPLOYMENT) -762.9720 478.5280 -1.594414 0.1317 D1 37.43460 50.23445 0.745198 0.4677D2 221.0765 38.30840 5.770966 0.0000D3 -122.0493 73.81439 -1.653461 0.1190D4 -178.8688 65.87071 -2.715452 0.0160R-squared 0.999861 Mean dependent var 4428.906 Adjusted R-squared 0.999796 S.D. dependent var 3060.917 S.E. of regression 43.70477 Akaike info criterion 10.66100 Sum squared resid 28651.61 Schwarz criterion 11.05595 Log likelihood -114.6015 F-statistic 15413.79 Durbin-Watson stat 2.977604 Prob(F-statistic) 0.000000Dependent Variable: CONSUMEMethod: Least SquaresDate: 08/24/09 Time: 13:14Sample (adjusted): 1986 2008Included observations: 23 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.C 871.9310 332.6627 2.621067 0.0185CONSUME(-1) 0.083576 0.050165 1.666017 0.1152 INCOME 0.629922 0.034447 18.28676 0.0000 LOG(EMPLOYMENT) -889.4616 441.1508 -2.016230 0.0609 D2 226.0361 37.19791 6.076579 0.0000D3 -110.8884 71.26752 -1.555946 0.1393D4 -171.6924 64.25105 -2.672211 0.0167R-squared 0.999856 Mean dependent var 4428.906 Adjusted R-squared 0.999802 S.D. dependent var 3060.917 S.E. of regression 43.09316 Akaike info criterion 10.61040 Sum squared resid 29712.33 Schwarz criterion 10.95598 Log likelihood -115.0196 F-statistic 18496.74 Durbin-Watson stat 2.787479 Prob(F-statistic) 0.000000Dependent Variable: CONSUMEMethod: Least SquaresDate: 08/24/09 Time: 13:15Sample (adjusted): 1986 2008Included observations: 23 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.C 1204.936 265.1054 4.545122 0.0003CONSUME(-1) 0.099314 0.051147 1.941709 0.0689 INCOME 0.599165 0.029366 20.40320 0.0000 LOG(EMPLOYMENT) -1325.942 354.4143 -3.741222 0.0016 D2 251.3675 34.81573 7.219940 0.0000D4 -141.7710 63.81647 -2.221543 0.0402R-squared 0.999834 Mean dependent var 4428.906 Adjusted R-squared 0.999785 S.D. dependent var 3060.917 S.E. of regression 44.85802 Akaike info criterion 10.66434 Sum squared resid 34208.12 Schwarz criterion 10.96056 Log likelihood -116.6399 F-statistic 20483.46 Durbin-Watson stat 2.638666 Prob(F-statistic) 0.000000Dependent Variable: CONSUMEMethod: Least SquaresDate: 08/24/09 Time: 13:16Sample: 1985 2008Included observations: 24Variable Coefficient Std. Error t-Statistic Prob.C 1460.937 233.2922 6.262263 0.0000INCOME 0.653101 0.009132 71.51539 0.0000LOG(EMPLOYMENT) -1651.937 314.1501 -5.2584310.0000D2 277.4048 33.62783 8.249261 0.0000 D4 -154.2742 66.05969 -2.335377 0.0306R-squared 0.999810 Mean dependent var 4272.418 Adjusted R-squared 0.999769 S.D. dependent var 3090.239 S.E. of regression 46.92598 Akaike info criterion 10.71807 Sum squared resid 41838.91 Schwarz criterion 10.96350 Log likelihood -123.6169 F-statistic 24931.15 Durbin-Watson stat 2.292463 Prob(F-statistic)0.0000008.3 在统计学教材中,采用了方差分析方法分析了不同班次对劳动效率的影响,其样本数据为表8.6 不同班次的劳动效率试采用虚拟解释变量回归的方法对上述数据进行方差分析。