随机分组程序
电脑产生随机数的分组方法
假设需将10个样本随机分组为两组group1,group2。
1:将十个样本标号1-10
2:打开SPSS‘数据录入’输入标号1-10(可在excel中写好后粘入)
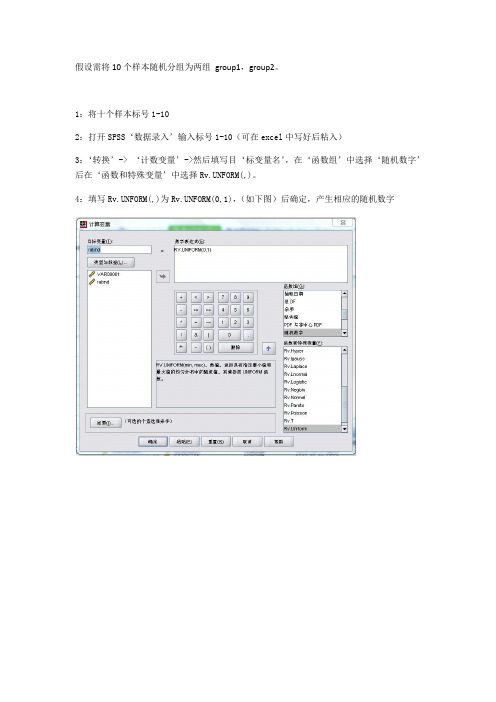
3:‘转换’-> ‘计数变量’->然后填写目‘标变量名’,在‘函数组’中选择‘随机数字’后在‘函数和特殊变量’中选择Rv.UNFORM(,)。
4:填写Rv.UNFORM(,)为Rv.UNFORM(0,1),(如下图)后确定,产生相应的随机数字
5:返回‘数据编辑器’
6:‘数据’->‘排序个案’将新产生的随机数字放入排序依据中,后确定。
7:结果解读
排在前面的1/2的样本就被分到group1,其余分到group2
(注:专业文档是经验性极强的领域,无法思考和涵盖全面,素材和资料部分来自网络,供参考。
可复制、编制,期待你的好评与关注)。
SAS随机分组方法及实现

随机分组方法包括:∙简单随机化(simple randomization)∙区组随机化(block randomization)∙分段(或分层)随机化(stratified randomization)∙分层区组随机化(stratified block randomization)∙动态随机化(dynamic randomization)一、简单随机化,又称完全随机化1、定义:在事先或者实施过程中不作任何限制和干预或调整,对研究对象直接进行随机分组。
通常,通过掷硬币、随机数字表、计算机产生随机数来进行随机化。
2、适用条件:在研究例数较少、总体中个体差异较小时,采用此法。
3、缺点:在研究对象例数较少时,由于随机误差难以保证组间病例数的均衡,各组例数可能会出现不平衡现象。
4、解决办法:随机数表法、随机数余数分组法。
随机数余数分组法的具体操作:编号:研究对象(动物按体重大小、患者按预计样本量编号)从1 到N 编号;获取随机数字:从随机数字表中任意一个数开始,沿同一方向顺序每个研究对象对应取一个随机数字;求余数:随机数除以组数求余数。
若整除,则取组数作为余数;分组:按余数数值分组;调整:假如某组待调整,该组共有n 例。
从中抽取1 例,就取下一个随机数,随机数除以n。
除以n 的余数(若整除则余数为n )作为在该组中所抽研究对象的序号,调整到其他组。
例1-1:两组对心脑病区观察20例(编号1~20)心血管病患者分为2组,一组以灯盏花注射液为治疗组,另一组给予瓜蒌薤白汤。
从随机数字表任一行开始(以第11行第1个数(57)计),按序查找,凡小于或等于20的数标记,查够10个数;将与这10个数对应编号患者列为一组,余下患者为另一组。
第一组:9,10,4,6,15,20,11,12,3,7;第二组:1,2,5,8,13,14,16,17,18,19。
例1-2:多组(≥3组)将15名血栓性血瘀证患者分为3组。
第一次分组后,甲组6例,乙组5例,丙组4例。
使用Python进行随机生成、随机抽取、随机分组

使用Python进行随机生成、随机抽取、随机分组日常办公中,我们经常会遇到诸如:随机抽取,随机分配,随机数生成等问题,这些都和“随机”这个概念相关,在Python中主要通过random库内的方法来解决。
今天我们通过一些常用的库方法和简单案例,来掌握Python中随机数的使用方法。
首先,我们须要来了解一下在random库中,最高频使用的方法有哪些,而他们又有什么作用?一、Python中Random的常用的7个方法的简介①random():随机生成一个0~1之间小数,精确到小数点后18位,含0不含1②uniform(x,y):随机生成一个[x,y]之间的小数,包含x和y本身,含16位有效数字③randint(x,y):随机生成一个[x,y]之间的整数,包含整数x和y本身④randrange(a,b,[c]):随机生成一个a~b之间整数,含a不含b,其中c可选参数,表示步长值⑤choice(seqtype):随机从序列类型(如字典、元组、列表等)中返回1个元素⑥shuffle(seqtype):将序列类型(同上)中元素随机洗牌乱序,返回乱序后序列⑦sample(seq,m):从序列类型中随机选取m个元素返回(以列表形式)关于开区间和闭区间的问题小结:random和randrange方法右侧区间为开区间,取不到端点数值;randint和uniform方法右侧是闭区间,可以取到端点数值。
在了解了以上的一些random库的基本方法以后,下面我们结合一些实际案例来看一下如何使用它们。
【案例1:生成验证码(数字和字母组成)(randrange方法)】①生成纯数字:随机生成6个0~10的整数(不含10)import randomlistA=[]for i in range(6):num=random.randrange(0,10)listA.append(num)s="".join(listA)print(s)注:1.join方法为字符串合并方法,即把listA中的所有元素连接起来,双引号内为分隔符,这里为空值,意为直接把所有的列表元素连接起来,不用任何分隔符;2.所有随机方法都为random库中的方法,所以在使用前须要导入random库,而且在调用其中的方法时,须要添加random前缀,如random.randrange(1,10)。
SPSS随机分组操作步骤

SPSS随机分组操作步骤SPSS(19.0)随机分组操作步骤1.输入原始数据纵向输入原始数据,包括原编号、分组依据的变量,变量列降序排列(Sort Descending)。
2.生成随机种子转换(Transform)→随机数字生成器(Random Number Generators)勾选“活动生成器初始化(Active Generator Initialization)”中的“设置起点(Set Starting Value)”,选中“固定值(Fixed Value)”,默认2,000,000,单击“确定(OK)”。
3.生成随机数字转换(Transform)→计算变量(Compute Variable)目标变量(Target Variable):random函数组(Function Group):随机数字(Random Number)函数和随机变量(Functions and Special Variables):Rv.Uniform,双击选中数字表达式(Numberic Expression):RV.UNIFORM(1,100)→单击“确定(OK)”。
4.输入分组后新编号假设分为a个组,每组n个样本,输入a个1,a个2,……a个n。
5.分组转换(Transform)→个案排秩(Rank Cases)变量(Variable(s)):random排序标准(By):新编号列将秩1指定给(Assign Rank 1 to )“最大值”(Largest value)→单击“确定(OK)”。
“Rrandom”列升序排列(Sort Ascending)。
“Rrandom”列即分组后的组别,“新编号”列即分组后的编号。
临床研究中的随机分组流程

临床研究中的随机分组流程在临床研究中,随机分组流程是非常重要的步骤,它能够有效地避免研究结果的偏倚,提高研究结果的可靠性和准确性。
随机分组流程的主要目的是将研究对象随机地分配到不同的实验组或对照组中,以消除干扰因素对研究结果的影响,确保研究结果的科学性和可靠性。
一、确定研究对象在进行临床研究时,首先需要确定研究对象,包括研究的目的、研究的对象群体及研究的具体内容。
确定研究对象是进行随机分组流程的前提,只有明确了研究对象才能有效地进行随机分组。
二、制定随机化方案制定随机化方案是随机分组流程中的关键步骤,需要根据研究的具体情况和要求确定随机化的方法和方式。
常见的随机化方法包括简单随机化、分层随机化和区组随机化等,研究人员可以根据具体情况选择合适的随机化方法。
三、实施随机分组在确定了随机化方案之后,研究人员需要按照方案要求进行随机分组,将研究对象随机分配到不同的实验组或对照组中。
在实施随机分组过程中,需要确保随机分组的公平性和随机性,避免人为干预和偏倚。
四、监控随机分组流程随机分组流程的监控是确保研究结果可靠性的关键环节,研究人员需要对随机分组流程进行严格的监控和管理。
监控随机分组流程包括确定随机化的准确性、记录随机化的过程和结果、监测随机分组的实施情况等,以确保随机分组流程的顺利进行。
五、分析研究结果随机分组流程完成后,研究人员需要对研究结果进行分析和总结,比较不同组别之间的研究结果,评估研究的效果和可靠性。
通过分析研究结果,可以验证研究的假设和结论,为进一步的临床研究提供参考和指导。
在临床研究中,随机分组流程是保证研究结果可靠性和科学性的重要步骤,研究人员应该重视随机分组的实施和管理,确保研究结果的准确性和可靠性。
通过严格遵循随机分组流程和方法,可以避免研究结果的偏倚和误导,为临床研究的开展和发展提供有力支持。
用Excel达成随机分组(简化版)

通过Excel达成随机分组声明:此教程通过office2016的excel过程,wps与其它版本的office 套件可自行寻找相应位置。
需要了解本功能根本操作:“递增数列〞“随机函数〞“单元格复制〞“选择性粘贴〞“排序与筛选-自定义排序〞1,弄出递增数列。
在第一个单元格输入数字,单击单元格,其右下角出现小黑点,先按住“Ctrl〞键,再按住右下角小黑点不放往下拉,可完成递增效果。
〔呐,小黑点/小绿点?,总之是个实心小点〕(这时候我进展的操作是,按住Crtl同时按住小黑点往下拉,右下角可见当前递增的格数)〔这是效果图O(∩_∩)O~〕2,“=RAND()〞,等号不可少,大小写限定,空括号不可少。
(此时假如回车可出现随机数字)3,复制函数。
单击单元格,其右下角出现小黑点,按住不放往下拉,即可完成复制效果。
〔一般复制时不需要按ctrl键,否如此会达成递增效果。
但在函数应用上是否按住ctrl键并无区别〕〔这是效果图,别看B列此时是一堆数字,但是看图片右上方的单元格其实它本质还是“=RAND()〞函数,你进展简单的复制的话其数值是一直在改变的。
〕4,选中所有数据,“Ctrl+C〞复制,粘贴时需使用右键呼出菜单-选择性粘贴-粘贴“值〞。
假如直接粘贴,会出现一直变化的随机函数。
〔嘛,那个白板板上有数字123的就是只粘贴数值了。
从此之后,函数功能被废弃,我们得到的就是一串随机数值。
〕〔效果图,此时单元格已变为数字〕5,选中所有复制后的数据,找到excel开始菜单,工具栏中的“排序和筛选〞中的“自定义排序〞。
需注意,由于需要按照随机数大小排序,所以主要关键字必须选择随机数所在那一列。
由小到大排列需要使用“升序〞排列。
然后就是如下界面:〔主要关键字选随机数在的那一列,例如我粘贴以后是F和G列,所以主要关键字选择G列,依据是数值,由小到大排列是升序。
完成后点击确定,效果图如下:〕然后就是放心大胆地分组。
完毕。
叫我红领巾。
随机分组程序

c程序-实现随机分组

//struct student * head表示参数的 student结构体的指针类型head,head 表示头指针,也就是指向student链表 中第一个节点
//srand是产生随机数的种子,调用 rand()函数时,保证每次随时间不同产 生的随机数不一样
//保证随机 取过的数 不再出现
char ch; do{ printf("\n一共有%d位学生,请输入你需要分的组数:",Student); scanf("%d",&Group); m=0; if(Group<=Student&&Group>0) //排除输入组数不在正确范围内 { for(b=0,k=Student%Group;b<Group;) //k 为余数,b是判断组数是否已达上限 { printf("\n第%d组:\n",++b); for(n=0;n<(Student/Group);n++) /*按每组的人数截取输出成员*/ { printf("\t%-8s%s\n",Head[Mark1[m]].Name,Head[Mark1[m]].Snum); m++; } if(k-->0) { printf("\t%-8s%s\n",Head[Mark1[m]].Name,Head[Mark1[m]].Snum); m++; } } printf("\n"); } else printf("\n要分的组数大于人数或小于等于零,"); printf(“如果想重新分组请按1并确认,或者按其它键退出:"); scanf("%d",&ch); }while(ch==1);