PCIE学习笔记
PCIE基础知识

PCIe总线概述随着现代处理器技术得发展,在互连领域中,使用高速差分总线替代并行总线就是大势所趋。
与单端并行信号相比,高速差分信号可以使用更高得时钟频率,从而使用更少得信号线,完成之前需要许多单端并行数据信号才能达到得总线带宽。
PCI总线使用并行总线结构,在同一条总线上得所有外部设备共享总线带宽,而PCIe总线使用了高速差分总线,并采用端到端得连接方式,因此在每一条PCIe链路中只能连接两个设备。
这使得PCIe与PCI总线采用得拓扑结构有所不同。
PCIe总线除了在连接方式上与PCI 总线不同之外,还使用了一些在网络通信中使用得技术,如支持多种数据路由方式,基于多通路得数据传递方式,与基于报文得数据传送方式,并充分考虑了在数据传送中出现服务质量QoS (Quality of Service)问题。
PCIe总线得基础知识与PCI总线不同,PCIe总线使用端到端得连接方式,在一条PCIe链路得两端只能各连接一个设备,这两个设备互为就是数据发送端与数据接收端。
PCIe总线除了总线链路外,还具有多个层次,发送端发送数据时将通过这些层次,而接收端接收数据时也使用这些层次。
PCIe总线使用得层次结构与网络协议栈较为类似。
1、1 端到端得数据传递PCIe链路使用“端到端得数据传送方式”,发送端与接收端中都含有TX(发送逻辑)与RX(接收逻辑),其结构如图4-1所示。
由上图所示,在PCIe总线得物理链路得一个数据通路(Lane)中,由两组差分信号,共4根信号线组成。
其中发送端得TX部件与接收端得RX部件使用一组差分信号连接,该链路也被称为发送端得发送链路,也就是接收端得接收链路;而发送端得RX部件与接收端得TX部件使用另一组差分信号连接,该链路也被称为发送端得接收链路,也就是接收端得发送链路。
一个PCIe链路可以由多个Lane组成。
高速差分信号电气规范要求其发送端串接一个电容,以进行AC耦合。
该电容也被称为AC耦合电容。
PCIe_XAPP859_学习笔记(1)_待更新

TX Engine发送器负责发送并传输posted,non_posted和完成包。
本参考设计可以产生并传输MWR,MRd 和完成包,用来满足存储器读和DMA写请求。
消息和错误报告包,如不在支持范围内的请求,完成包超时和中断请求。
都由硬核通过一定的信号机制产生。
因此不需要用户逻辑去产生与这些类型的TLPs相对应的header;用户逻辑只需要监视这些情况是否发生了,一旦他们其中之一发生了,便通知硬核。
完成包超时的逻辑在本参考设计中将不会涉及到。
另外,I/O包在本参考设计中也不予支持。
数据包依靠来自 DMA Control/Status Register File的请求而产生,它们通过 TRN的TX 接口被传输到硬核上。
Posted Packet GeneratorPosted包生成器接受来自DMA Control/Status Register File的写DMA请求,并产生可以用来完成本次写DMA操作的header。
这些包头被放置在一个小的FIFO中,以便被TRN状态机读取。
该生成器由两个模块组成:●Posted包分割器●Posted合成器Posted包分割器分割器从DMA Control/Status Register File 接受写DMA请求,并根据PCIe总线协议把这些请求分割成多个数据包。
实际上,该分割器按照以下两个原则对写DMA请求进行分解:●包的有效载荷长度不能超过设备控制寄存器中的Max_Payload_Size。
●地址/数据的组合不能超过4KB地址界限。
分割器利用简单的握手协议把长度(Length[9:0])和地址(dmawad_reg[63:0])传给posted Pactet Builder。
源和目的地址必须分布在128字节的地址界限内。
Receive TRN State Machine事务层数据接收状态机模块执行以下功能:●接收来自PCIe事务层的数据,并在需要的时候把事务层接口throttle●传输64位的数据以及字节有效位●传输 data_valid位,用来对数据和字节使能●解码,寄存和验证包头信息在实现中,64bit宽度的数据直接连接到 memory fifo 上,并有data_valid信号用来标示数据的可写入性。
存储随笔《PCIe科普教程》

微信公众号【存储随笔】荣誉出品《PCIe科普教程》2017.6PCIe 科普教程古猫著目录1.0PCIe概述_______________________________________________________42.0Transaction layer事务层概述____________________________________7 2.1TLP的前世今生__________________________________________________9 2.2TLP事务处理方式_______________________________________________12 2.3TLP结构解析___________________________________________________16 2.4Flow Control机制概述__________________________________________21 2.5Flow Control缓存架构及信用积分________________________________22 2.6Flow Control初始化____________________________________________23 2.7Flow Control的实现过程________________________________________282.8事务排序机制___________________________________________________323.0数据链路层概述_________________________________________________35 3.1数据链路层DLLP结构及类型______________________________________363.2数据链路层Ack/Nak机制_________________________________________404.0物理层结构解析_________________________________________________544.1物理层数据流解析_______________________________________________595.0PCIe总线电源管理______________________________________________656.0PCIe系统复位方式______________________________________________727.0PCIe热插拔____________________________________________________78微信公众号平台:PCIe专题文章列表(点击即可跳转) PCIe系列专题之一:PCIe技术概述PCIe系列专题之二:2.0Transaction layer事务层概述PCIe系列专题之二:2.1TLP的前世今生PCIe系列专题之二:2.2TLP事务处理方式解析PCIe系列专题之二:2.3TLP结构解析PCIe系列专题之二:2.4Flow Control机制概述PCIe系列专题之二:2.5Flow Control缓存架构及信用积分PCIe系列专题之二:2.6Flow Control初始化PCIe系列专题之二:2.7Flow Control的实现过程PCIe系列专题之二:2.8事务排序机制PCIe系列专题之三:3.0数据链路层概述PCIe系列专题之三:3.1数据链路层DLLP结构及类型PCIe系列专题之三:3.2数据链路层Ack/Nak机制解析PCIe系列专题之四:4.0物理层结构解析PCIe系列专题之四:4.1物理层数据流解析PCIe系列专题之五:PCIe总线电源管理PCIe系列专题之六:PCIe系统复位方式PCIe系列专题之七:PCIe热插拔1.0PCIe概述SSD的协议标准除了SATA,还有一个更先进的协议标准,就是PCIe。
PCIe协议相关资料要点

PCIe协议相关资料要点PCIe(Peripheral Component Interconnect Express)是一种计算机总线标准,用于连接计算机系统的外部设备。
它在现代计算机中广泛应用于图形卡、存储卡和扩展卡等设备的连接。
下面是PCIe协议的相关资料要点。
一、PCIe协议概述PCIe协议是一种高速串行通信协议,用于在计算机系统中传输数据。
它取代了传统的PCI总线,提供更高的带宽和更可靠的性能。
PCIe协议具有以下特点:1. 高速性能:PCIe协议支持多个通道和多个数据传输通路,并且每个通道都可以达到多Gbps的传输速度。
2. 点对点连接:PCIe协议采用点对点连接方式,每个设备都直接连接到主机,并且不会与其他设备共享带宽。
3. 热插拔支持:PCIe协议支持热插拔功能,可以在计算机运行时插入或拔出设备,而无需重新启动系统。
4. 多功率状态支持:PCIe协议支持多功率状态,可以有效地管理设备的能耗。
二、PCIe协议架构PCIe协议的架构包括物理层、数据链路层和传输层。
每个层级都有不同的功能和责任。
1. 物理层(Physical Layer):物理层负责在发送和接收设备之间传输数据。
它定义了数据传输的电气特性、传输速度和功耗等参数。
2. 数据链路层(Data Link Layer):数据链路层负责在发送和接收设备之间建立可靠的数据传输连接。
它通过发送和接收数据包来确保数据的完整性和可靠性。
3. 传输层(Transport Layer):传输层负责数据的路由和传输。
它根据设备的地址和标识符来确定数据的发送和接收。
三、PCIe协议数据传输PCIe协议的数据传输分为读取和写入两种方式。
1. 读取(Read):读取是指从PCIe设备读取数据到主机内存。
读取传输由主机启动,并且主机提供要读取的目标地址。
读取过程中,设备将数据传输到主机内存中的指定地址。
2. 写入(Write):写入是指将数据从主机内存写入到PCIe设备。
PCI-Express协议传输层读书笔记

处理层协议(transaction Layer specification)整理:捷马联系我:giema@2011-12-02目录1.TLP概况 (2)1.1四种空间: (2)1.2 三种处理类型: (2)1.3 两种属性: (3)1.4 主要包格式: (3)1.5 TLP通用包头 (4)2.TLP打包地址和路由导向方式 (7)2.1 Address寻址 (7)2.2 ID寻址方式 (8)2.3 处理层描述符(transaction Descriptor): (10)3.i/o,memory,configuration,message request、completetion详解。
(11)3.1 Memory Request Package (11)3.2 I/O Request 包 (12)3.3 Configuration Request包 (13)3.4 Message 包: (13)3.5 Completion Rules(应答机制) (15)4.请求和应答处理机制 (16)4.1 Request Handling Rules (17)4.2 Completion Handling (18)5 .virtual channel(vc)Mechanism虚拟通道机制。
(19)5.1 TC/VC映射 (20)5.2 Flow Control (21)6.Data Integrity数据完整性 (22)1.TLP概况处理层(transaction Layer specification)是请求和响应信息形成的基础。
包括四种地址空间,三种处理类型,从下图可以看出在transaction Layer 中形成的包的基本概括。
1.1四种空间:1.2 三种处理类型:◆i/o口和memory的读写包(TLPS:transaction Layers packages),◆配置寄存器的读写设置包◆信息包,描述通信状态。
PCIE学习笔记
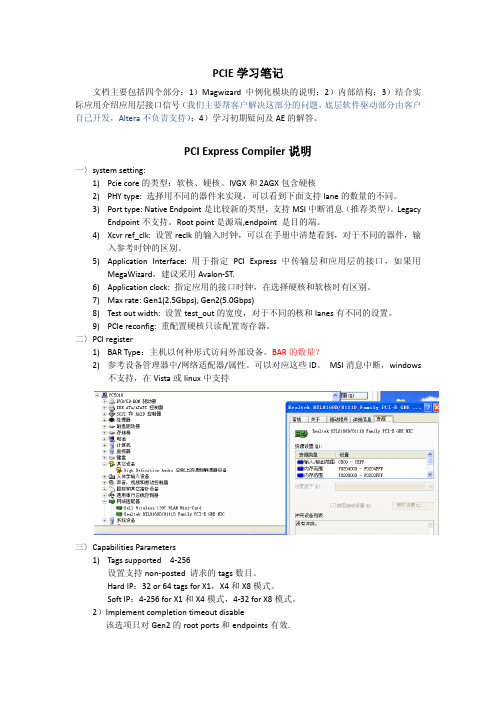
PCIE学习笔记文档主要包括四个部分:1)Magwizard中例化模块的说明;2)内部结构;3)结合实际应用介绍应用层接口信号(我们主要帮客户解决这部分的问题,底层软件驱动部分由客户自己开发,Altera不负责支持);4)学习初期疑问及AE的解答。
PCI Express Compiler说明一〉system setting:1)Pcie core的类型:软核、硬核。
IVGX和2AGX包含硬核2)PHY type: 选择用不同的器件来实现,可以看到下面支持lane的数量的不同。
3)Port type: Native Endpoint是比较新的类型,支持MSI中断消息(推荐类型)。
LegacyEndpoint不支持。
Root point是源端,endpoint 是目的端。
4)Xcvr ref_clk: 设置reclk的输入时钟,可以在手册中清楚看到,对于不同的器件,输入参考时钟的区别。
5)Application Interface: 用于指定PCI Express中传输层和应用层的接口,如果用MegaWizard,建议采用Avalon-ST.6)Application clock: 指定应用的接口时钟,在选择硬核和软核时有区别。
7)Max rate: Gen1(2.5Gbps), Gen2(5.0Gbps)8)Test out width: 设置test_out的宽度,对于不同的核和lanes有不同的设置。
9)PCIe reconfig: 重配置硬核只读配置寄存器。
二〉PCI register1)BAR Type:主机以何种形式访问外部设备。
BAR的数量?2)参考设备管理器中/网络适配器/属性。
可以对应这些ID。
MSI消息中断,windows不支持,在Vista或linux中支持三〉Capabilities Parameters1)Tags supported 4-256设置支持non-posted 请求的tags数目。
PCIE基础知识
PCIe总线概述随着现代处理器技术的发展,在互连领域中,使用高速差分总线替代并行总线是大势所趋。
与单端并行信号相比,高速差分信号可以使用更高的时钟频率,从而使用更少的信号线,完成之前需要许多单端并行数据信号才能达到的总线带宽。
PCI总线使用并行总线结构,在同一条总线上的所有外部设备共享总线带宽,而PCIe 总线使用了高速差分总线,并采用端到端的连接方式,因此在每一条PCIe链路中只能连接两个设备。
这使得PCIe与PCI总线采用的拓扑结构有所不同。
PCIe总线除了在连接方式上与PCI总线不同之外,还使用了一些在网络通信中使用的技术,如支持多种数据路由方式,基于多通路的数据传递方式,和基于报文的数据传送方式,并充分考虑了在数据传送中出现服务质量QoS (Quality of Service)问题。
PCIe总线的基础知识与PCI总线不同,PCIe总线使用端到端的连接方式,在一条PCIe链路的两端只能各连接一个设备,这两个设备互为是数据发送端和数据接收端。
PCIe总线除了总线链路外,还具有多个层次,发送端发送数据时将通过这些层次,而接收端接收数据时也使用这些层次。
PCIe 总线使用的层次结构与网络协议栈较为类似。
1.1 端到端的数据传递PCIe链路使用“端到端的数据传送方式”,发送端和接收端中都含有TX(发送逻辑)和RX(接收逻辑),其结构如图4-1所示。
由上图所示,在PCIe总线的物理链路的一个数据通路(Lane)中,由两组差分信号,共4根信号线组成。
其中发送端的TX部件与接收端的RX部件使用一组差分信号连接,该链路也被称为发送端的发送链路,也是接收端的接收链路;而发送端的RX部件与接收端的TX部件使用另一组差分信号连接,该链路也被称为发送端的接收链路,也是接收端的发送链路。
一个PCIe链路可以由多个Lane组成。
高速差分信号电气规范要求其发送端串接一个电容,以进行AC耦合。
该电容也被称为AC 耦合电容。
pcie基础知识(二)
pcie基础知识(二)本文主要讲述PCIE的相关缩写、术语;不同模式、配置;枚举等基础知识。
一、designware pcie产品:Dual Mode coreRC coreEP coreSwitch core二、架构:Common Xpress Port Logic (CXPL)实现大部分的传输层逻辑,所有的数据链路层逻辑,物理层的MAC部分(包括LTSSM)。
这个module就是所说的core。
XADM和RADM都是针对传输应用添加的模块。
比如说添加传输队列,仲裁TLP transmmision。
Transmit Application-Dependent Module (XADM)Receive Application-Dependent Module (RADM)Configuration-Dependent Module (CDM)Power Management Controller (PMC)Local Bus Controller (LBC)Message Generation (MSG_GEN)Hot Plug Control (hotplug_ctrl)三、核心(CXPL)操作3.1 DM/RC/EP 模式下的初始化在reset之后,通过检测device_type输入进入到RC或者EP模式,CDM内部配置寄存器为复位值。
LTSSM前配置:keep the app_ltssm_enable signal deasserted after reset until the application is ready to establish a Link and start receiving and transmitting TLPs,在这个阶段通过DBI配置好配置寄存器。
开始LTSSM:assert app_ltssm_enable to allow the LTSSM to begin Link establishment3.2 Link EstablishmentPIPE口,和usb3.0一样。
PCIe的原理及体系架构_学习笔记
IO总线的三个阶段:第一代并行ISA 、EISA、MC、VESA.共同特点:信号的功能与时序与处理器引脚密切相关,几乎是微处理器信号的延伸和扩展,有些信号还与主板上的硬件资源有关系.第二代并行PCI、AGP、PCI-XPCI总线是一个标准的、与处理器无关的局部外围总线,不受限于系统所使用的处理器的种类,通用性更强. 图形端口,将PCI总线从图形数据传输中解放出来,改善带宽.第三代PCI Express高性能IO串行总线在总线结构上采取了根本性的变革,主要体现在两个方面:一是有并行总线变位串行总线;二是采用点到点的互连独享带宽.将原并行总线结构中桥下面挂连设备的一条总线变成了一条链路,一条链路可包含一条或多条通路.没有专用的数据、地址、控制和时钟线,总线上各种事务组织成信息包来传送.地址空间、配置机制及软件上均保持与传统PCI总线兼容.第一代和第二代都是并行总线,有多条地址线、数据线和控制线,挂接多个设备,称为下挂式总线(Multi-Drop),总线带宽由多个设备共享.通过提高数据宽度和频率来改善带宽的代价是挂接的电器负载减少(由于功耗增加和静态定时减少).PCIx与PCI相比:由于采用了PLL,频率更高性能更好;在地址和数据的基础上增加属性,从而可以高效管理缓冲区;分离事务协议相对延迟事务协议来说,提高了总线利用效率;可不需要中断引脚,改用消息信号中断(带内)体系结构,中断效率更高.基于PCI总线的结构最基本的PCI总线平台包含三级总线:FSB(Front-Side Bus)、PCI和ISA,FSB是处理器子系统的总线(Host总线),总线定义完全取决于系统所用的处理器;PCI局部总线是一个完全与处理器无关的总线,不受限微处理器的种类;ISA总线(IO扩展总线),也有采用EISA或MC总线的.不同的总线之间通过相应的桥芯片来连接.平台中两极桥是必须的,一是Host到PCI的(常称为主桥——Host桥),即北桥;另一个是PCI总线的桥(常称为扩展总线桥),即南桥.最基本的基于PCI总线的平台PCI地址空间映射x86 CPU的内存与I/O独立编址,I/O对应寄存器,内存对应RAM.因此,访问IO空间用IO读写指令,访问内存空间用内存读写指令.IO读写一般用于低速传输一些状态、控制寄存器的读写等。
第1章PCI总线的基本知识
PCI(Peripheral Component Interconnect)总线的诞生与PC(Personal Computer)的蓬勃发展密切相关。
在处理器体系结构中,PCI总线属于局部总线(LocalBus)- M部总线作为系统总线的延伸,主要功能是为了连接外部设备。
处理器主频的不断提升,要求速度更快,带宽更高的局部总线。
起初PC使用8位的XT总纟戈作为局部总线,并很快升级到16位的ISA(Industry Staiidaid Aiclutcctuie)总线,逐步发展到32 位的EISA(Extended Industry Standard Architecture)VESA(Video Electronics Standards Association)和MCA(Micro Chamiel Aichitecrure)总线。
PCI总线规范在上世纪九十年代提出。
这条总线推出之后,很快得到了各大主流半导体厂商的认同,迅速统一了当时并存的各类局部总线。
EISA、VESA等其他32位总线很快就被PCI总线淘汰了。
从那时起,PCI总线一直在处理器体系结构中占有重要地位。
在此后相当长的一段时间里,PC处理器系统的人多数外部设备都是直接或着间接地与PCI总线相连。
即使目前PCI Express总线逐步取代了PCI总线成为PC局部总线的主流,也不能掩盖PCI总线的光芒。
从软件层而上看,PCI Express总线与PCI总线基本兼容:从磯件层面上看,PCI Express总线在很犬程度上继承了PCI总线的设计思路。
因此PCI总线依然是软硬件工程师在进行处理器系统的开发与设计时,必须要掌握的一条局部总线。
PCI总线V1.0规范仅针对在一个PCB(Prmted Cucuit Board)环境内的,器件Z间的互连, 而1993年4月30 口发布的V2.0规范增加了对PCI插槽的支持。
1995年6月1日,PCIV2.1 总线规范发布,这个规范具有里程碑总义。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
PCIE学习笔记文档主要包括四个部分:1)Magwizard中例化模块的说明;2)内部结构;3)结合实际应用介绍应用层接口信号(我们主要帮客户解决这部分的问题,底层软件驱动部分由客户自己开发,Altera不负责支持);4)学习初期疑问及AE的解答。
PCI Express Compiler说明一〉system setting:1)Pcie core的类型:软核、硬核。
IVGX和2AGX包含硬核2)PHY type: 选择用不同的器件来实现,可以看到下面支持lane的数量的不同。
3)Port type: Native Endpoint是比较新的类型,支持MSI中断消息(推荐类型)。
LegacyEndpoint不支持。
Root point是源端,endpoint 是目的端。
4)Xcvr ref_clk: 设置reclk的输入时钟,可以在手册中清楚看到,对于不同的器件,输入参考时钟的区别。
5)Application Interface: 用于指定PCI Express中传输层和应用层的接口,如果用MegaWizard,建议采用Avalon-ST.6)Application clock: 指定应用的接口时钟,在选择硬核和软核时有区别。
7)Max rate: Gen1(2.5Gbps), Gen2(5.0Gbps)8)Test out width: 设置test_out的宽度,对于不同的核和lanes有不同的设置。
9)PCIe reconfig: 重配置硬核只读配置寄存器。
二〉PCI register1)BAR Type:主机以何种形式访问外部设备。
BAR的数量?2)参考设备管理器中/网络适配器/属性。
可以对应这些ID。
MSI消息中断,windows不支持,在Vista或linux中支持三〉Capabilities Parameters1)Tags supported 4-256设置支持non-posted 请求的tags数目。
Hard IP:32 or 64 tags for X1,X4和X8模式。
Soft IP:4-256 for X1和X4模式,4-32 for X8模式。
2)Implement completion timeout disable该选项只对Gen2的root ports和endpoints有效.3)Completion Time out range你可以选择ABCD,分别对应不同的时间范围。
4)Error Reporting就是你是否想显示这些错误信息。
5)MSI Capabilities用来设置应用层请求数量,将此值设置给消息控制寄存器。
SOPC只支持1个MSI。
6)link CapabilitiesLink common clock:是否用系统提供的普通参考时钟给PHY来做参考时钟,建议选用。
Data link layer active reporting:只在root port有效Link port number: 将只读端口数目设置到link Capabilities寄存器中。
7)Slot CapabilityTable 3-3中详细介绍了Slot capability寄存器中各个值对应的意义。
8)MSI-X capabilities此中断只对Hard IP有效MSI-X Table size:只读信号,系统软件读这个地方来确定MSI-X Table Size。
(主要+1的关系)MSI-X Table Offset: 指向MSI-X table的基地址。
只读。
BAR Indicator: 用来将MSI-Xtable映射到memory空间,只读。
四)Buffer Setup该页包括了接收和重试buffer的设置。
Maximum payload size: 设置最大的有效载荷大小,对于不同的器件有不同的上限值。
Number of virtual channels: 设置虚拟通道数。
Number of low-priority VCs:设置虚拟通道在低优先级仲裁组的数量。
该值只能小于或等于虚拟通道数。
Retry buffer size:设置重试Buffer的深度,用来存储发射PCI Express 包直到被确认。
(Hard IP时默认值)Maximum retry packets: 设置重试包的大小。
(Hard IP时默认值)结构:如果调用Magwizard,完整的可以实现如下几层:一〉应用接口有Avalon-ST接口、descriptor/data(soft IP only)、Avalon-MM接口。
Avalon接口分成两种,一种是Avalon-MM接口,另一种是Avalon-ST接口。
MM接口是通过地址来读写数据,更多的用在控制逻辑上面。
ST接口是用于点到点的数据流接口,更多的用在高速通过率的模块中间。
RX Datapath接收数据路径将传输层的数据发给Avalon-ST接口。
有一个FIFO用来buffer传输层的数据直到流接口接受它。
Avalon-ST RX datapath 有3到6个pld_clk周期的延迟。
TX Datapath发射数据路径将Avalon-ST接口的数据发给传输层,有一个FIFO用来buffer传输层的数据传输层接受它二〉处理层处理层在应用层和数据链路层之间,它来产生和接收传输层的包。
处理层包括:发射数据路径,配置空间和接收路径。
你可以在IVGX中例化1,2个虚拟通道,在2AGX中只可以例化一个虚拟通道。
接收数据流程:1)处理层收到从数据链路层来的TLP。
2)配置空间用来确定处理层的包是否正确。
3)在每个虚拟通道,处理层的包被存在接收buffer中一个特定的部分(由收发类型确定:posted,non-posted,completion)4)处理层packet FIFO 块用来存储buffer传输层包的地址。
发射数据流程:1)MegaCore通过tx_cred[21:0](for soft IP)或tx_cred[35:0](for hard IP)来给应用层提供信息2)应用层会请求传输层给它包,此时应用层需要提供提供PCI Express传输字头在tx_desc[127:0]中,已经数据在tx_data[63:0]中。
3)Megacore会确认suffiicient flow control credits,并确定是相应还是延迟请求。
4)处理层的数据被应用层转发。
处理层仲裁各虚拟通道,然后选择优先级高的数据给数据链路层(在PCI Express Base Specification 1.0a,1.1或2.0中,可以定义虚拟通道的优先级)。
三)数据链路层链路层在处理层和物理层之间,它主要负责包的信号完整性。
Figure4-9给出了数据链路层和与它相连的两层之间的接口信号。
四)物理层物理层在Megacore的最底层,它通过高速Serdes和link相连。
实际应用(about chaining DMA)下图是客户这边的一个实际应用结构简图。
我们主要需要帮工程师了解用户逻辑和MegaCore相连的的用法,软件部分主要由客户自己完成。
Altera建议新的设计不要采用Descriptor/Data接口,而是采用Avalon_ST。
硬核和软核的主要功能区别就在于用Avalon_ST接口做配置和时钟管理。
在128-bits模式,流接口时钟pld_clk是core_clk的一半;在64bits模式,两者相等。
Figure 5-1和Figure 5-2分别给出了用Avalon_ST接口实现Rootpoint和Endpoint模式的信号。
Table 5-2和Table 5-4给出了64/128 bits Avalon-ST接收数据路径和发射数据路径中的信号。
由于客户实际应用采用硬核,所以这里主要介绍硬核。
1)64/128 bits Avalon_ST接收端口rx_st_ready: 用来指示应用层是否准备好接收数据。
Rx_st_valid: 和rx_st_ready之间的时序关系参考Figure 5-13。
Rx_st_data: 接收数据总线。
Rx_st_sop: 包起始标志位Rx_st_eop: 包结束标志位Rx_st_empty:在rx_st_data数据低64bits结束传输时给出确认信号。
该信号只在使用硬核的128bits模式时有效。
Rx_st_err:当一个无法纠正的ECC错误被检测到,rx_st_err会被拉高至少一个周期。
(只在硬核中存在,并在ECC被使能时才有效)Rx_st_mask: Application使能这个信号来告诉megacore来停止发送non-posted 请求。
Rx_st_bardec:Rx_st_be: 参考page137页可以知道rx_st_data和rx_st_be之间的关系。
Root Port Mode Configuration Requests:为了保证在root port模式时正常发送CFG0包,应用层需要等待,一直等到CFG0被发送到Megacore的配置空间,你可以在CFG0 SOP被发送到Avalon-ST后等至少10个周期,然后检查tx_fifo_empty是否为0,再来确定是否发下一个包。
应用层可以执行ECRC forwarding,但是对于CFG0包不需要执行ECRC,此时TLP头中的TDbits 会被置0,因为这些包不需要传送到PCI Express link 中2)Clock Signals – Hard IP Implementrefclk : 模块的输入参考时钟,由Parameter Settings中确定。
Pld_clk: 应用层时钟,你必须用core_clk_out来驱动它。
Core_clk_out: 根据link Width和Avalon-ST width等来确定Core_clk_out的值,参考Table 4-41。
P_clk: 只在仿真时采用Clk250_out: 只在仿真时采用Clk500_out: 只在仿真时采用3)Reset SignalRstn: 配置空间的异步复位,只在X8的soft IP下使用。
Npor: 上电复位。
Srst: 同步数据路径复位,高有效。
在X1和X4模式下有效。
Crst: 同步数据复位,高有效,用来复位nonstickly配置空间寄存器。
剩下一些复位输出状态信号不一一介绍了。
Figure5-23和Figure5-24给出了各种复位信号之间的时序关系。
4)ECC错误信号Derr_cor_ext_rcv[1:0]: 显示接收buffer有一个可改正的错误Derr_rpl: 显示重试buffer有一个不可更正的错误Derr_cor_ext_rpl:显示重试buffer有一个可更正的错误5)PCI express中断(for endpoints)当模块被配置成endpoint时,支持legacy中断、MSI中断和MSI-X中断(该中断只在硬核有效)。