第六部分异方差与自相关讲解
第六章 自相关(序列相关)

2 横截面数据中的自相关:一般来说截面数据不容
易出现自相关,但相邻的观测单位之间也可能存在 “溢出效应”(neighborhood effect)。例如,相邻 省份、国家之间的经济活动相互影响(通过贸易、 投资、劳动力流动等);相邻地区的农业产量受到 类似的天气影响而相关;同一社区内的房屋价格存 在相关性;相邻地区的消费倾向有相关性
图 中 实 线 表 示 真 实 的 总 体 回 归 线 。 假 设 扰 动 项 存 在
正 自 相 关 , 即 E ij X >0 , 若 1>0 ( 图 中 左 边 小 椭 圆 形 ) 由 于 存 在 正 自 相 关 , 则 2 >0 的 可 能 性 也 就 很 大 ; 而 若
n-1<0 ( 图 中 右 边 小 椭 圆 形 ) 则 n <0 的 可 能 性 也 就 很 大
此 检 验 被 称 为 B GB 检 验 ( r e u s c h - G o d f r e y )
3B 、 o x P i e r c e Q 检 验
定义残差的各阶样本自相关系数为
t=j+1 ˆ j n
e e
t=1
n
t t-j
2 e t
(j=1,2, ,p)
d ˆ 且 n 正 态 分 布 , j = 1 , 2 , , p j
3 设 定 误 差 m i s s p e c i f i c a t i o n : 如 果 模 型 设 定 中 遗 漏 会 引 起 扰 动 项 的 自 相 关 。
了 某 个 自 相 关 的 解 释 变 量 , 并 被 纳 入 到 扰 动 项 中 , 则
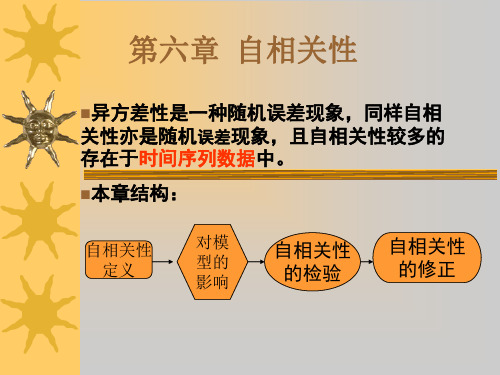
三 、 自 相 关 的 检 验
X X X X n 1 j ˆ ˆ Q = S+ 1 - etet-j xt x + xt-jx t-j t n j= p+1 1i=j+1 p
自相关和异方差处理顺序

自相关和异方差处理顺序引言自相关和异方差是时间序列分析中常见的两种问题,它们影响了模型的准确性和可靠性。
在进行时间序列建模时,需要处理这些问题,以确保模型的有效性。
本文将深入探讨自相关和异方差处理的顺序,并讨论不同处理顺序的影响。
什么是自相关和异方差自相关自相关是指时间序列中当前观测值与之前观测值之间的相关性。
它衡量的是时间序列中各个观测值之间的依赖关系。
自相关可以用自相关函数(ACF)图来表示,通过观察ACF图,可以判断时间序列是否存在自相关。
异方差异方差是指时间序列中方差不稳定的特征。
在时间序列中,方差可能随着时间的推移发生变化,这会导致模型的拟合不准确。
异方差可以用方差函数(VCF)图来表示,通过观察VCF图,可以判断时间序列是否存在异方差。
自相关和异方差处理的重要性自相关和异方差对时间序列建模的准确性和可靠性有重要影响,它们需要被处理以获得可靠的模型结果。
•自相关的存在会导致参数估计不准确,预测结果失真。
如果存在自相关,模型会无法捕捉到序列的真实动态,导致预测结果不准确。
•异方差使得模型的残差不符合正态分布,违背了建模的基本假设。
这会使得模型的显著性检验和置信区间估计不可靠,影响模型的有效性。
因此,为了获得可靠的模型结果,需要对自相关和异方差进行处理。
自相关和异方差处理顺序的影响自相关和异方差的处理顺序会对最终的模型结果产生影响。
不同的处理顺序可能导致不同的模型结构和参数估计。
先处理自相关后处理异方差如果先处理自相关再处理异方差,可能会导致如下影响:1.自相关处理可能会改变时间序列的动态特征。
当我们去除自相关时,可能会削弱序列中的一些重要信息,导致模型无法准确捕捉到序列的动态变化。
2.异方差处理可能会影响自相关的结构。
当我们对残差进行异方差处理时,可能会改变残差序列的结构,从而使得自相关的估计失真。
先处理异方差后处理自相关如果先处理异方差再处理自相关,可能会产生如下影响:1.异方差处理可能改变原始序列的动态特征。
计量经济学第六章自相关

计量经济学第六章自相关自相关是计量经济学中一种重要的现象,它指的是一个变量与其自己在过去时间点上的相关性。
自相关在实证研究中十分常见,对经济学家来说,了解和掌握自相关性质是至关重要的。
1. 引言自相关作为计量经济学的一项基础概念,是经济学研究中不可或缺的一个重要方法。
自相关性的存在通常会引起回归结果的偏误,而忽略自相关性可能导致估计不准确的结果。
因此,探讨自相关性的性质和应对方法是计量经济学的重点之一。
2. 自相关的定义和表示自相关是指一个变量与其自身在过去时间点上的相关性。
假设我们有一个时间序列数据集,其中变量yt表示一个时间点上的观测值,t表示时间索引。
自相关系数可以通过计算观测值yt与其在过去某一时间点上的观测值yt-k(k为时间滞后期数)的相关性来得到。
数学上,自相关系数可以用公式表示为:ρ(k) = Cov(yt, yt-k) / (σ(yt) * σ(yt-k))其中,ρ(k)表示第k期的自相关系数,Cov表示协方差,σ表示标准差。
3. 自相关性的性质自相关性具有以下几个性质:3.1 一阶自相关性一阶自相关性是指变量值yt与前一期的观测值yt-1之间的相关性。
一阶自相关系数ρ(1)通常用来检验时间序列数据是否存在自相关性。
若ρ(1)大于零且显著,则表明存在正的一阶自相关性;若ρ(1)小于零且显著,则表明存在负的一阶自相关性。
3.2 高阶自相关性除了一阶自相关性,时间序列数据还可能存在高阶自相关性。
高阶自相关性是指变量值yt与过去第k期的观测值yt-k之间的相关性。
通过计算不同滞后期的自相关系数ρ(k),可以了解数据在不同时间跨度上的自相关性情况。
3.3 异方差自相关性异方差自相关性是指时间序列数据中的方差不仅与自身相关,还与过去观测值的相关性有关。
异方差自相关性可能导致在回归分析中的标准误差失效,从而产生无效的回归结果。
因此,在处理存在异方差自相关性的数据时要采取合适的修正方法。
4. 自相关性的检验方法在实证研究中,经济学家通常使用多种方法来检验数据中的自相关性,常用的方法包括:4.1 Durbin-Watson检验Durbin-Watson检验是一种常用的检验自相关性的方法,其基本思想是通过检验误差项的相关性来判断自相关是否存在。
第六章 自相关性
进一步,如果
ut ut 1 t
其中
1,t满足E(t ) 0,Var(t )
2
,
cov(t , s ) 0, (t s)
则称ut是一阶线性自相关。
二、自相关性产生的原因
1、经济变量惯性的作用 2、经济行为的滞后性 3、一些随机偶然因素的干扰或影响 4、模型设定的偏误 5、蛛网现象模型
例如:“真实”的边际成本与产量之间的函数关
系式应为:
Yt
1
2 X t
3 X
2 t
ut
其中Yt表示边际成本,X t表示产量,由于认识上的偏
误可能建立如下模型: Yt 1 2 X t vt
其中vt
3
X
2 t
ut,这时由于vt中包含了带有X
2对边
t
际成本的系统影响,使得vt很有可能出现自相关性。
3、一些随机偶然因素的干扰或影响 通常偶然因素是指战争、自然灾害、政策制定
的错误后果、面对一些现象人们的心理因素等等, 这些因素可能影响若干时期,反映在模型中很容 易形成随机误差序列的自相关。
4、设定偏误:
所谓设定偏误是指所建模型“不真实”或“不正 确”。引起设定偏误的主要原因有:模型函数的形式 不正确或遗漏了主要变量。
1、经济变量惯性的作用 大多数经济时间数据都有一个明显的特点,就是
它的惯性,表现在时间序列数据不同时间的前后关联 上。
例如,绝对收入假设下居民总消费函数模型:
Ct=0+1Yt+t
t=1,2,…,n
由于消费习惯的影响被包含在随机误差项中, 则可能出现序列相关性(往往是正相关 )。
异方差自相关豪斯曼检验

异方差自相关豪斯曼检验异方差性(Heteroscedasticity)是指数据的方差不是常数,而是随着自变量的变化而变化。
当数据呈现异方差性时,固定效应模型可能会产生无偏但不一致的估计,而随机效应模型通常能够更好地处理异方差性。
因此,豪斯曼检验可以帮助确定在存在异方差性时应该选择哪种模型。
同时,时间序列数据中还可能存在自相关性(Autocorrelation),即误差项之间存在相关性。
如果数据中存在自相关性,那么OLS估计量可能不再是最佳线性无偏估计。
通过进行豪斯曼检验,可以确定在存在自相关性时是否需要使用修正的OLS估计方法。
要进行豪斯曼检验,首先需要建立两个模型:一个固定效应模型和一个随机效应模型。
然后通过计算两个模型的估计值的差异来进行检验。
在检验中,我们感兴趣的是这个差异是否由异方差性或自相关性引起的。
具体来说,豪斯曼检验的原假设是两个模型没有系统性的差异。
如果原假设被拒绝,说明两个模型之间存在显著差异,这可能是由于异方差性或自相关性导致的。
为了说明豪斯曼检验的方法和步骤,我们将考虑一个实际的研究示例。
假设我们对一个国家的 GDP 进行研究,我们想分析GDP 与劳动力投入之间的关系。
我们建立了一个固定效应模型和一个随机效应模型,用来估计 GDP 对劳动力投入的影响。
在固定效应模型中,我们假设不同国家之间的劳动力投入是不同的,即随着时间的推移,劳动力投入在各国之间也可能存在差异。
而在随机效应模型中,我们假设劳动力投入在各国之间是同质的,即不同的劳动力投入只是由于随机误差所致。
接下来,我们用豪斯曼检验来检验这两个模型之间的差异。
我们首先估计这两个模型,并计算它们之间的差异。
接着,我们对这些差异进行统计检验,以确定差异是否显著。
如果实证结果表明固定效应模型比随机效应模型更好,那么我们可以得出结论,数据中存在异方差性和自相关性。
在这种情况下,我们可能需要对模型进行修正,以更准确地描述数据。
总的来说,豪斯曼检验是一种在经济学和其他社会科学研究中经常使用的方法,用于检验两个模型之间的差异。
第五讲-多重共线性、异方差、自相关

表 4.3.3 中国粮食生产与相关投入资料
农业化肥施 粮食播种面 受灾面积 农业机械总
用量 X 1
(万公斤)
积X 2
(千公顷)
X3
(公顷)
动力X 4
(万千瓦)
1659.8
114047 16209.3
18022
1739.8
11288பைடு நூலகம் 15264.0
19497
1775.8
108845 22705.3
20913
0.9752 1.53
t值
0.85
19.6 3.35 -3.57
Y=f(X1,X2,X3,X4) -13056 6.17 0.42 -0.17 -0.09
0.9775 1.80
t值
-0.97 9.61 3.57 -3.09 -1.55
Y=f(X1,X3,X4,X5) -12690 5.22 0.40 -0.20
含义:解释变量的样本向量近似线性相关。
多重共线性来源:
(1)解释变量x受到同一个因素的影响; 例如:政治事件对很多变量都产生影响,这些变量同时上升 或同时下降。
(2)解释变量x自己的当期和滞后期;
(3)错误设定。
二、多重共线性的后果
1、完全共线性下参数估计量不存在
Y X
的OLS估计量为: βˆ (XX) 1 XY
1、检验多重共线性是否存在
(1)对两个解释变量的模型,采用简单相关系数法 求出X1与X2的简单相关系数r,若|r|接近1,则说
明两变量存在较强的多重共线性。
(2)对多个解释变量的模型,采用综合统计检验法
若 在OLS法下:R2与F值较大,但t检验值较小, 说明各解释变量对Y的联合线性作用显著,但各解 释变量间存在共线性而使得它们对Y的独立作用不 能分辨,故t检验不显著。
统计分析与方法-第七章 回归分析2-异方差与自相关

1.000 . 15 .443 .098 15 .721** .002 15
**. Correlation is significant at the 0.01 level (2-tailed).
因此选取注册资本构造权函数
最优权数的幂指数确定
Source variable.. 注册资本 Dependent variable.. 销销收收 Log-likelihood Function = -125.581891 POWER value = -2.000 Log-likelihood Function = -122.148284 POWER value = -1.500 Log-likelihood Function = -118.756247 POWER value = -1.000 Log-likelihood Function = -115.440464 POWER value = -.500 Log-likelihood Function = -112.257523 POWER value = .000 Log-likelihood Function = -109.297553 POWER value = .500 Log-likelihood Function = -106.695645 POWER value = 1.000 Log-likelihood Function = -104.627066 POWER value = 1.500 Log-likelihood Function = -103.261903 POWER value = 2.000 Log-likelihood Function = -102.682848 POWER value = 2.500 Log-likelihood Function = -102.833168 POWER value = 3.000 The Value of POWER Maximizing Log-likelihood Function = 2.500
eviews异方差、自相关检验与解决办法

eviews异方差、自相关检验与解决办法一、异方差检验:1.相关图检验法LS Y C X 对模型进行参数估计GENR E=RESID 求出残差序列GENR E2=E^2 求出残差的平方序列SORT X 对解释变量X排序SCAT X E2 画出残差平方与解释变量X的相关图2.戈德菲尔德——匡特检验已知样本容量n=26,去掉中间6个样本点(即约n/4),形成两个样本容量均为10的子样本。
SORT X 将样本数据关于X排序SMPL 1 10 确定子样本1LS Y C X 求出子样本1的回归平方和RSS1SMPL 17 26 确定子样本2LS Y C X 求出子样本2的回归平方和RSS2计算F统计量并做出判断。
解决办法3.加权最小二乘法LS Y C X 最小二乘法估计,得到残差序列GRNR E1=ABS(RESID) 生成残差绝对值序列LS(W=1/E1) Y C X 以E1为权数进行加权最小二成估计二、自相关1.图示法检验LS Y C X 最小二乘法估计,得到残差序列GENR E=RESID 生成残差序列SCAT E(-1) E et—et-1的散点图PLOT E 还可绘制et的趋势图2.广义差分法LS Y C X AR(1) AR(2)首先,你要对广义差分法熟悉,不是了解,如果你是外行,我奉劝你还是用eviews来做就行了,其实我想老师要你用spss无非是想看你是否掌握广义差分,好了,废话不多说了。
接着,使用spss16来解决自相关。
第一步,输入变量,做线性回归,注意在Liner Regression 中的Statistics中勾上DW,在save中勾Standardized,查看结果,显然肯定是有自相关的(看dw值)。
第二步,做滞后一期的残差,直接COPY数据(别告诉我不会啊),然后将残差和滞后一期的残差做回归,记下它们之间的B指(就是斜率)。
第三步,再做滞后一期的X1和Y1,即自变量和因变量的滞后一期的值,也是直接COPY。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
七、 异方差与自相关一、背景我们讨论如果古典假定中的同方差和无自相关假定不能得到满足,会引起什么样的估计问题呢?另一方面,如何发现问题,也就是发现和检验异方差以及自相关的存在性也是一个重要的方面,这个部分就是就这个问题进行讨论。
二、知识要点1、引起异方差的原因及其对参数估计的影响2、异方差的检验(发现异方差)3、异方差问题的解决办法4、引起自相关的原因及其对参数估计的影响5、自相关的检验(发现自相关)6、自相关问题的解决办法 (时间序列部分讲解) 三、要点细纲1、引起异方差的原因及其对参数估计的影响原因:引起异方差的众多原因中,我们讨论两个主要的原因,一是模型的设定偏误,主要指的是遗漏变量的影响。
这样,遗漏的变量就进入了模型的残差项中。
当省略的变量与回归方程中的变量有相关关系的时候,不仅会引起内生性问题,还会引起异方差。
二是截面数据中总体各单位的差异。
后果:异方差对参数估计的影响主要是对参数估计有效性的影响。
在存在异方差的情况下,OLS 方法得到的参数估计仍然是无偏的,但是已经不具备最小方差性质。
一般而言,异方差会引起真实方差的低估,从而夸大参数估计的显著性,即是参数估计的t 统计量偏大,使得本应该被接受的原假设被错误的拒绝。
2、异方差的检验 (1)图示检验法由于异方差通常被认为是由于残差的大小随自变量的大小而变化,因此,可以通过散点图的方式来简单的判断是否存在异方差。
具体的做法是,以回归的残差的平方2i e 为纵坐标,回归式中的某个解释变量i x 为横坐标,画散点图。
如果散点图表现出一定的趋势,则可以判断存在异方差。
(2)Goldfeld-Quandt 检验Goldfeld-Quandt 检验又称为样本分段法、集团法,由Goldfeld 和Quandt 1965年提出。
这种检验的思想是以引起异方差的解释变量的大小为顺序,去掉中间若干个值,从而把整个样本分为两个子样本。
用两个子样本分别进行回归,并计算残差平方和。
用两个残差平方和构造检验异方差的统计量。
Goldfeld-Quandt 检验有两个前提条件,一是该检验只应用于大样本(n>30),并且要求满足条件:观测值的数目至少是参数的二倍; 二是除了同方差假定不成立以外,要求其他假设都成立,随机项没有自相关并且服从正态分布。
Goldfeld-Quandt 检验假设检验设定为:H 0:具有同方差, H 1:具有递增型异方差。
具体实施步骤为:①将观测值按照解释变量x 的大小顺序排列。
②将排在中间部分的c 个(约n/4)观测值删去,再将剩余的观测值分成两个部分,每个部分的个数分别为n 1、n 2。
③分别对上述两个部分的观测值进行回归,得到两个部分的回归残差平方和。
④构造F 统计量222111/()/()e e n k F e e n k '-='-,其中 k 为模型中被估参数个数。
在H 0成立条件下,21(,)FF n k n k --⑤判别规则如下,若 F ≤ F α (n 2 - k , n 1 - k ), 接受H 0(具有同方差) 若 F > F α(n 2 - k , n 1 - k ), 拒绝H 0(递增型异方差)注意:① 当摸型含有多个解释变量时,应以每一个解释变量为基准检验异方差。
② 此法只适用于递增型异方差。
(3)Breusch -Pagan/Godfrey LM 检验该方法的基本思想是构造残差平方序列与解释变量之间的辅助函数,得到回归平方和ESS ,从而判断异方差性存在的显著性。
该检验假设异方差的形式为:220()i f σσα'=+i αz 其中i z 是解释变量构成的向量,当=α0时,模型是同方差的。
具体设模型为:表示是某个解释变量或全部。
同样,该检验也可以通过一个简单的回归来实现。
提出原假设为, 01234567050100150200X Y Y12233i i i k ik i Y u ββββ=+X +X +⋅⋅⋅+X +201122var()i i i i p ip i u v σαααα==+Z +Z +⋅⋅⋅+Z +12,,p Z Z ⋅⋅⋅⋅⋅⋅Z 012:0p αααH ==⋅⋅⋅==具体步骤如下:①构造变量2()i e n 'e e :用OLS 方法估计方程中的未知参数,得和 (n 为样本容量) ②以2()i e n 'e e 为被解释变量,i z 为解释变量进行回归,并计算回归平方和ESS 。
构造辅助回归函数③构造LM 统计量为:LM =12ESS当有同方差性,且n 无限增大时有 ④对于给定显著性水平 ,如果2()2ESS p αχ>,则拒绝原假设,表明模型中存在异方差。
为了计算的简便,LM 统计量的构造也可以采取如下形式:1[]2LM '''=-1g Z(Z Z)Z g其中,Z 是关于(1,)i z 的n P ⨯观测值矩阵, g 是观测值21()i i e g n =-'e e 排成的列向量。
由于上述统计量的构造过分依赖于残差的正态性假定,因此,Koenker 和Bassett 对该统计量进行了修正,令2211()n i i V e n n ='⎡⎤=-⎣⎦∑e e u ()n '=e e 则1()LM V ⎡⎤'''=⎢⎥⎣⎦-1u -u)Z(Z Z)Z (u -u(4)White 检验White 检验由H. White 1980年提出。
和Goldfeld-Quandt 检验相比,White 检验不需要对观测值排序,也不依赖于随机误差项服从正态分布,它是通过一个辅助回归式构造 χ2 统计量进行异方差检验。
White 检验的提出避免了122ˆˆˆi i i k ik e Y βββ=--X -⋅⋅⋅-X 22ˆi e nσ∑=2011222ˆi i i p ip ie v αααασ=+Z +Z +⋅⋅⋅+Z +2~2p ESS χαBreusch-Pagan 检验一定要已知随机误差的方差产生的原因且要求随机误差服从正态分布。
White 检验与Breusch-Pagan 检验很相似,但它不需要关于异方差的任何先验知识,只要求在大样本的情况下。
White 的检验的思想直接来源于其异方差一致估计。
当存在异方差时,传统的方差估计式21(|)()Var b X X X σ-'=不再是估计量方差的一致估计,而应该使用White 一致性估计:21()ni i i i e =''∑-1-1(X X)(X X)x 'x 。
通过检验21()X X σ-'是不是参数估计方差的一致估计,可以检验是否存在异方差。
在实际的应用过程中,可以通过回归的步骤来简单的实现上述思想。
以二元回归模型y i = β0 +β1 x i 1 +β2 x i 2 + u i 为例,White 检验的具体步骤如下: ①首先对上式进行OLS 回归,求残差平方2i e 。
②做如下辅助回归式,2i e = α0 +α1 x i 1 +α2 x i 2 + α3 x i 12 +α4 x i 22 + α5 x i 1 x i 2 + v i 即用残差平方2i e 对原回归式中的各解释变量、解释变量的平方项、交叉乘积项进行OLS 回归。
注意,上式中要保留常数项。
求辅助回归式的可决系数R 2。
③White 检验的原假设和备择假设是H 0:u i 不存在异方差, H 1:u i 存在异方差④利用回归②得到的2R ,计算统计量2nR 。
在同方差假设条件下,统计量 nR 2 ~ χ 2(5)其中n 表示样本容量,R 2是辅助回归式的OLS 估计的可决系数。
自由度5表示辅助回归式中解释变量项数(注意,不计算常数项)。
n R 2属于LM 统计量。
统计量2nR 渐进服从自由度为1k -的卡方分布,其中k 是辅助回归中参数的个数(包括常数项)。
⑤判别规则是若 n R 2 ≤ χ2α (5), 接受H 0(u i 具有同方差) 若 n R 2 > χ2α (5), 拒绝H 0(u i 具有异方差)(5)ARCH 检验自回归条件异方差(ARCH )检验主要用于检验时间序列中存在的异方差。
ARCH 检验的思想是,在时间序列数据中,可认为存在的异方差性为ARCH 过程,并通过检验这一过程是否成立来判断时间序列是否存在异方差。
ARCH 过程可以表述为:222011t t p t p t v σαασασ--=++++其中p 是ARCH 过程的阶数,并且00α>,0,(1,2,)i i p α≥=;t v 为随机误差。
ARCH 检验的基本步骤如下: ①提出假设:012:0;p H ααα===1:(1,2,)j H j p α=中至少一个不为零。
②对原模型做OLS 估计,求出残差t e ,并计算残差平方序列2(1,2,)t e t T =,分别作为对2t σ的估计。
③作辅助回归222011ˆˆˆt t p t p e e e ααα--=+++ 并计算上式的可决系数2R ,可以证明,在原假设成立的情况下,基于大样本,有2()T p R -近似服从自由度为p 的卡方分布。
如果22()()T p R p αχ->,则拒绝原假设,表明原模型的误差项存在异方差。
(6)Park 检验法Park 检验法就是将残差图法公式化,提出 是解释变量 的某个函数,然后通过检验这个函数形式是否显著,来判定是否具有异方差性及其异方差性的函数结构。
(7)Glejser 检验法这种方法类似于Park 检验。
首先从OLS 回归取得残差 i e 之后,用 i e 的绝对值对被认为与方差密切相关的X 变量作回归。
3、异方差的解决办法 (详细见板书)对异方差的传统解决办法是通过加权最小二乘WLS 将残差向同方差转换。
2i σi x一般认为,异方差的产生是由于残差项中包含了解释变量的相关信息,也就是说,可以将残差项e表达成解释变量x的函数:e g x=()其中x是1kg可以是关于x的线性函数,也可以是非线性的。
如果⨯的向量,()知道()g x的函数形式,那么可以通过加权最小二乘的方法对模型进行修正,在不存在自相关的假定下,在回归方程()=+两边同乘以y f xε差进行修正,从而消除残差的异方差性使得OLS估计量仍然具有有效性。
但是,这样的方法却有两个方面的问题——首先,是()g的形式难以确定(为了简便,我们往往假设()g是关于x的线性函数,但实际上真实的函数形式很可能是非线性的),从而相应的WLS的权重设定也就往往是不正确的了;其次,即使知道()g x 的真实函数形式,通过加权得出的参数估计也已经不是原来的关注参数了;最后,ε=不满足的条件下,WLS估计量也往往是不一致的。