一元线性回归方程概述
1一元线性回归方程
i =1 n
i =1 n
2
Lxy = ∑( Xi − X ) (Yi −Y )
i=1
ˆ ˆ β0 = Y − β1 X ˆ Lxy β1 = Lxx
二、OLS回归直线的性质 回归直线的性质
ˆ (1)估计的回归直线 Yi )
(2) )
ˆ ˆ = β 0 + β 1X i
前三个条件称为G-M条件 条件 前三个条件称为
§1.2 一元线性回归模型的参数估计
普通最小二乘法( Squares) 普通最小二乘法(Ordinary Least Squares) OLS回归直线的性质 OLS回归直线的性质 OLSE的性质 OLSE的性质
一、普通最小二乘法
对于所研究的问题, 对于所研究的问题,通常真实的回归直线 E(Yi|Xi) = β0 + β1Xi 是观 测不到的。可以通过收集样本来对真实的回归直线做出估计。 测不到的。可以通过收集样本来对真实的回归直线做出估计。
Y
55 80 100 120140 160
X
二、随机误差项εi的假定条件 随机误差项
为了估计总体回归模型中的参数,需对随机误差项作出如下假定: 为了估计总体回归模型中的参数,需对随机误差项作出如下假定: 假定1: 假定 :零期望假定:E(εi) = 0。 。 假定2: 假定 :同方差性假定:Var(εi) = σ 2。 假定3: 假定 :无序列相关假定:Cov(εi, εj) = 0, (i ≠ j )。 。 假定4: 假定 : εi 服从正态分布,即εi ∼ N (0, σ 2 )。 。
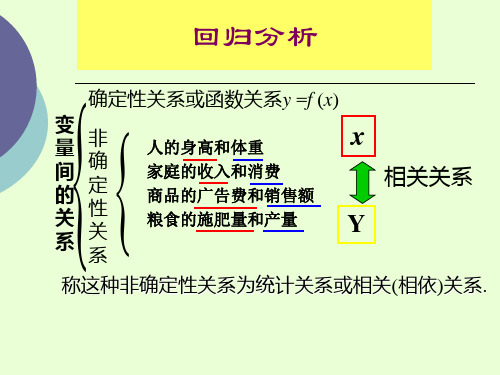
以下设 x 为自变量(普通变量 Y 为因变量(随机变 普通变量) 普通变量 随机变 量) .现给定 x 的 n 个值 x1,…, xn, 观察 Y 得到相应的 n 个 值 y1,…,yn, (xi ,yi) i=1,2,…, n 称为样本点 样本点. 样本点 以 (xi ,yi) 为坐标在平面直角坐标系中描点,所得到 的这张图便称之为散点图 散点图. 散点图
计量经济学【一元线性回归模型——回归分析概述】

四、随机误差项的涵义
随机误差项是在模型设定中省略下来而又集体的
影响着被解释变量 Y 的全部变量的替代物。涵义如
下: 1、在解释变量中被忽略的因素的影响; 2、变量观测值观测误差的影响; 3、模型关系的设定误差的影响; 4、其它随机因素的影响。 设定随机误差项的主要原因: 1、理论的含糊性; 2、数据的欠缺; 3、节省的原则。
➢ 例如:
二、总体回归函数(方程)PRF Population regression function
由于变量间统计相关关系的随机性(非确定性),回归 分析关心的是根据解释变量的已知或给定值,考察被解 释变量的总体均值,即当解释变量取某个确定值时,与 之统计相关的被解释变量所有可能出现的对应值的平均 值。
样本回归函数的随机形式:
其中 为(样本)残差(Residual),可看成是随机误差项 的 的具体估计值。由于引入随机项,称为样本回归 模型。
总体回归线与样本回归线的基本关系
例2.1:一个假想的社区是由60户家庭组成的总体,要
研究该社区每月家庭消费支出Y 与每月家庭可支配收入 X 的关系;即知道了家庭的每月收入,预测该社区家庭
每月消费支出的 (总体) 平均水平。为达到此目的,将该 60户家庭划分为组内收入差不多的10组,以分析每一收 入组的家庭消费支出。
表2.1 某社区家庭每月收入与消费支出调查统计表
回归分析是研究因果相关,也就是有因果关系的相关关 系;既然回归分析是研究变量之间的因果关系,因此回归 分析对变量的处理方法存在不对称性,也就是说,回归分 析将变量区分为被解释变量和解释变量,其中被解释变量 是“结果”,解释变量是“原因”,并且回归分析方法认为作 为“原因”的解释变量属于非随机变量,作为“结果”的被解 释变量为随机变量;也就是说,作为“原因”的解释变量取 确定值时,作为“结果”的被解释变量取值是随机的。
一元线性回归方程

北京市城市居民家庭生活抽样调查表1 14 12 10 8 6 4 2 0 1976 1978 1980 1982 1984 1986 1988
Y: 人 均 收 入
x:年份
北京市城市居民家庭生活抽样调查图表 2 10 8 6 4 2 0 0 2 4 6 8
Y:人均食品支出
10 12 14 16 18
Fα (1,n-2),得否定域为F >Fα (1,n-2);
4.代入样本信息,F落入否定域则否定原假设, 线性关系显著;落入接受域则接受原假设, 线性关系不显著.
相关系数检验法: 相关系数检验法:
1.提出原假设:H0:b=0; lxy 2.选择统计量 R = lxxl yy 3.对给定的显著性水平α,查临界值rα (n-2), 得否定域为R >rα (n-2); 4.代入样本信息,R落入否定域则否定原假设,线性关 系显著;落入接受域则接受原假设,线性关系不显著.
第二节
一元线性回归方程
一 回归直线方程
两个变量之间的线性关系,其回归模型为: 两个变量之间的线性关系,其回归模型为:
yi = a + bxi + εi
ε 称为 y称为因变量,x称为自变量,
随机扰动,a,b称为待估计的回归参 数,下标i表示第i个观测值。
对于回归模型,我们假设:
εi ~ N( 0,σ ),i = 1,2,⋯,n E( εiε j ) = 0,i ≠ j
pt
qt
概率 0.25 0.50 0.25 0.25 0.50 0.25 … 0.25 0.50 0.25
qt = 11 − 4 pt+ εt
其中
这时, 这时,方程的形式为
εt
为随机变量. 为随机变量
一元线性回归
i
x )Yi
l xx
,
3
一元回归方程检验
⑴ F检验法:
当H0为真时,
SSE
SSE
2
2
~ 2 ( n 2),
2
~ (1);
且SSR与SSE相互独立;因此,当H0为真时,
SSR F ~ F (1, n 2), SSE ( n 2)
当F≥F1-α(1,n-2)时应该放弃原假设H0。
Y0的观测值y0的点预测是无偏的。
⑵ 当x=x0时,用适合不等式P{Y0∈(G,H)}≥ 1-α的统计量G和H所确定的随机区间(G,H) 预测Y0的取值范围称为区间预测,而(G,H)称 为Y0的1-α预测区间。 若Y与样本中的各Y相互独立,则根据 Z=Y0-(a+bx0)服从正态分布,E(Z)=0, 2 1 ( x0 x ) 2 D( Z ) (1 ), n l xx SSE 及 2 ~ 2 ( n 2), Z与SSE相互独立,
Q 2 ˆ 是 的无偏估计。 n2
2
2. 总体中未知参数的估计 根据最小二乘法的要求由
Q Q 0, 0, 得 a b
n
2 [ y i (a bx i )] 0, i 1 n 2 [ y i (a bx i )] x i 0, i 1
(2)t检验法:
b ~ N ( ,
2
l xx
),
SSE
2
~ 2 (n 2),
当H0为真时,
l xx t b ~ T (n 2), SSE (n 2)
当|t|≥t1-0.5α(n-2)时应该放弃原假设H0。
根据x与Y的观测值的相关系数 (3)r检验法:
一元线性回归方程

一元线性回归方程
一元线性回归方程:当直线方程Y'=a+bx的a和b确定时,即为一元回归线性方程。
一元线性回归方程反映一个因变量与一个自变量之间的线性关系
一元线性回归方程反映一个因变量与一个自变量之间的线性关系,当直线方程Y'=a+bx的a和b确定时,即为一元回归线性方程。
经过相关分析后,在直角坐标系中将大量数据绘制成散点图,这些点不在一条直线上,但可以从中找到一条合适的直线,使各散点到这条直线的纵向距离之和最小,这条直线就是回归直线,这条直线的方程叫作直线回归方程。
注意:一元线性回归方程与函数的直线方程有区别,一元线性回归方程中的自变量X对应的是因变量Y的一个取值范围。
1. 根据提供的n对数据在直角坐标系中作散点图,从直观上看有无成直线分布的趋势。
即两变量具有直线关系时,才能建立一元线性回归方程。
2. 依据两个变量之间的数据关系构建直线回归方程:Y=a+bx。
简单线性回归(Simple linear regression)也称为一元线性回归,是分析一个自变量(x)与因变量(y)之间线性关系的方法,它的目的是拟合出一个线性函数或公式来描述x与y之间的关系。
计量经济学第二章一元线性回归模型

回归分析概述 一元线性回归模型的参数估计 一元线性回归模型的检验 一元线性回归模型的预测 实例
§2.1 回归分析概述
一、变量间的关系及回归分析的基本概念 二、总体回归函数(PRF) 三、随机扰动项 四、样本回归函数(SRF)
2020/3/6
LOU YONG
表 2.1.3 家庭消费支出与可支配收入的一个随机样本 Y 800 1100 1400 1700 2000 2300 2600 2900 3200 3500 X 594 638 1122 1155 1408 1595 1969 2078 2585 2530
2020/3/6
LOU YONG
20
• 该样本的散点图(scatter diagram):
分i。
2020/3/6
LOU YONG
17
上式称为总体回归函数(PRF)的随机 设定形式。表明被解释变量除了受解释 变量的系统性影响外,还受其他因素的 随机性影响。
由于方程中引入了随机项,成为计量经 济学模型,因此也称为总体回归模型。
2020/3/6
LOU YONG
18
随机误差项主要包括下列因素 在解释变量中被忽略的因素的影响; 变量观测值的观测误差的影响; 模型关系的设定误差的影响; 其他随机因素的影响。
回归系数(regression coefficients)。
2020/3/6
LOU YONG
15
三、随机扰动项
总体回归函数说明在给定的收入水平Xi下,该社 区家庭平均的消费支出水平。
但对某一个别的家庭,其消费支出可能与该平 均水平有偏差。
称为观察值围绕它的期望值的离差 (deviation),是一个不可观测的随机变量, 又称为随机干扰项(stochastic disturbance)或 随机误差项(stochastic error)。
从统计学看线性回归(1)——一元线性回归

从统计学看线性回归(1)——⼀元线性回归⽬录1. ⼀元线性回归模型的数学形式2. 回归参数β0 , β1的估计3. 最⼩⼆乘估计的性质 线性性 ⽆偏性 最⼩⽅差性⼀、⼀元线性回归模型的数学形式 ⼀元线性回归是描述两个变量之间相关关系的最简单的回归模型。
⾃变量与因变量间的线性关系的数学结构通常⽤式(1)的形式:y = β0 + β1x + ε (1)其中两个变量y与x之间的关系⽤两部分描述。
⼀部分是由于x的变化引起y线性变化的部分,即β0+ β1x,另⼀部分是由其他⼀切随机因素引起的,记为ε。
该式确切的表达了变量x与y之间密切关系,但密切的程度⼜没有到x唯⼀确定y的这种特殊关系。
式(1)称为变量y对x的⼀元线性回归理论模型。
⼀般称y为被解释变量(因变量),x为解释变量(⾃变量),β0和β1是未知参数,成β0为回归常数,β1为回归系数。
ε表⽰其他随机因素的影响。
⼀般假定ε是不可观测的随机误差,它是⼀个随机变量,通常假定ε满⾜:(2)对式(1)两边求期望,得E(y) = β0 + β1x, (3)称式(3)为回归⽅程。
E(ε) = 0 可以理解为ε对 y 的总体影响期望为 0,也就是说在给定 x 下,由x确定的线性部分β0 + β1x 已经确定,现在只有ε对 y 产⽣影响,在 x = x0,ε = 0即除x以外其他⼀切因素对 y 的影响为0时,设 y = y0,经过多次采样,y 的值在 y0 上下波动(因为采样中ε不恒等于0),若 E(ε) = 0 则说明综合多次采样的结果,ε对 y 的综合影响为0,则可以很好的分析 x 对 y 的影响(因为其他⼀切因素的综合影响为0,但要保证样本量不能太少);若 E(ε) = c ≠ 0,即ε对 y 的综合影响是⼀个不为0的常数,则E(y) = β0 + β1x + E(ε),那么 E(ε) 这个常数可以直接被β0 捕获,从⽽变为公式(3);若 E(ε) = 变量,则说明ε在不同的 x 下对 y 的影响不同,那么说明存在其他变量也对 y 有显著作⽤。
一元线性回归方程

n
n
避免其偏离差(有正误差、负误差)相互抵消,采用偏离差平方和 Q(a ,b) ( yi yi )2
i 1
i 1
( yi a bxi )2(也称残差平方和)来刻画观测值(xi ,yi )与直线 y a bx 的偏离程度 . 一般
所说的回归直线就是使 Q(a ,b) 最小的直线,求所需回归直线的截距和斜率,就转化成了求使
Lxx (4)写出回归(估计)方程 y a bx .
一元线性回归方程
1.2 线性相关关系的显著性检验
从以上建立回归直线方程的过程不难看出,用最小二乘法所建立的回归直线方程,只是通 过一组样本观察值 (xi ,yi ) (i 1,2 , ,n) 来建立的 . 变量 x 与 y 之间是否存在线性关系,或者 其线性关系是否显著,还需进行检验.常用的线性相关关系的显著性检验有两种方法,即 F 检 验法和相关系数检验法 . 在此仅介绍相关系数检验法 .
0, 0.
即nan b a i1 xi
n
n
xi yi ,
i 1
i 1
n
n
b xi2 xi
i 1
i 1
yi
,取
x
y
1 n 1 n
n
i 1 n
i 1
xi , yi .
一元线性回归方程
n
n
n
n xi yi xi yi
n
xi yi nx y
b
解之得
i 1
,
即Q(a ,b) Lyy (1 R2 ) .
一元线性回归方程
n
n
因为Q(a ,b) ( yi yi )2 0 ,Lyy ( yi y)2 0 ,
i 1
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
我们可以通过建立一个如下的关于Y和X的方程来解决上述三个问 题
总体回归模型
Y= 0 + 1 X+ u
其中: Y——被解释变量; X——解释变量; u——随机误差项;表示除X之外其他影响Y的因素,一元回 归分析 将除X之外的其他所有影响Y的因素都看成了无法观测 的因素
0,1—回归系数(待定系数或待估参数) 1是斜率系数,是主要的研究对象 0 是常数项,也被称作截距参数,很少被当做分析的核心
根据上面的假定对原模型取期望得: E(Y|X)=E[(0+1X+u)|X] =0+1X+E(u|X)= 0+1X
总体回归函数 (直线)
E(Y|Xi) = 0+1X
总体回归函数E(Y|X)是X的
一个线性函数,它表示Y中可以 由X解释的部分,线性意味着X 变化一个单位,Y的期望改变β1 个单位。对于任意给定的X值, Y的分布都是以E(Y|X)为中心的。
(估计的)样本回归函数:
ˆ ˆX ˆ Y i 0 1 i
(估计的)样本回归模型:
ˆ ˆ X e Yi 0 1 i i
其中ei是第i次观测的残差
Y1
u2 e1
e2
ˆ ˆX ˆ Y i 0 1 i
u3
Y3
e3
u1
Xi
三、参数估计——最小二乘法
对于所研究的经济问题,通常总体回归直线 E(Yi|Xi) = 0 + 1Xi 是 观测不到的。可以通过收集样本来对总体(真实的)回归直线做出估计。
通常总体回归函数E(Y) = 0+ 1X是观测不到的,利用样本得到的是
对它的估计,即对0和1的估计。令{(Xi,Yi):i=1,…,n}表示从总体中抽取 的一个样本容量为n的随机样本,对于每个i,可以写出:
Yi ห้องสมุดไป่ตู้0 1 X i ui
其中ui是第i次观测的误差项
Yi
Y2
E(Y|Xi) = 0 + 1 Xi
被预测变量(predicted variable) 回归子(regressand)
控制变量(control variable)
预测变量(predictor variable) 回归元(regressor)。
回归分析中的因果关系和其他条件不变的概念
在多数对经济理论的检验中(包括对公共政策的评价),经济 学家的目标就是要退订一个变量(比如受教育程度)对另一个 变量(如犯罪率或工人的生产率)具有因果效应(causal effect)。有时可能会很简单就能发现两个或多个变量之间存 在很强的联系,但除非能得到某种因果关系,否则这种联系很 难令人信服。
回归的现代释义
回归分析用于研究一个变量关于另一个(些)变量的具 体依赖关系的计算方法和理论。
inflation a b 1 unem ploymnt e
商品需求函数: Q a bP 生产函数:
ln Q ln A ln K ln L
菲利普斯曲线:
2 Tax a b ( TR ) 拉弗曲线:
为解决上面提到的第三个问题,及如何在忽略其他因素的同时, 又得到其他因素不变情况下X对Y的影响呢?这需要我们对无法观测 的u和X之间的关系加以约束,并且只有如此,才能从一个随机样本 数据中获得β0和β1的可靠估计量。 E(u)=0 即无法观测的因素的平均值为零,不会对结果产生影响 E(u|X)=0 根据X的不同把总体划分为若干部分,每个部分中无法 观测的因素都具有想通的平均值,且这个共同的平均值 必然等于整个总体中u的平均值,即u是均值独立的。
其他条件不变(ceteris paribus):意味着“其他(相关因 素保持不变)”的概念,它在因果分析中有重要的作用。
这个概念看似简单,但是除非在极为特殊的条件下,很难实现 多数经验研究中的一个关键问题是:要做出一个因果推断,是 否能使其他足够多的因素保持不变呢? 只要方法得当,用计量经济方法可以模拟一个其他条件不变的 实验——通过对模型进行假定。
第二章 一元线性回归模型
回归的含义 一元回归模型的建立 参数估计——最小二乘法 随机误差项的古典假定 最小二乘估计量的性质 最小二乘估计量的概率分布 回归系数的显著性检验与置信区间 用样本可决系数检验回归方程的拟合优度 案例分析
一、回归的含义
回归概念的提出
Francis Galton最先使用“回归(regression)”。 F.加尔顿是达尔文的表弟,是研究智力的先驱者之一,他非常严肃, 非常聪明,但也有些疯狂,他出生在一个贵格教徒家庭中,祖上是著名 的和平主义者,有趣的是,他家的名下却有生产枪支的企业。高尔顿是 个申通,6岁便能阅读和背诵莎士比亚的作品,他在更小的时候已经会 说了希腊语和拉丁语。他似乎对什么事情都感兴趣,成年后的高尔顿在 气象学、心理学、摄影学,甚至是刑事司法领域都有所建树(他倡导使 用指纹分析的科学方法来确定罪犯身份)。此外,他还发明了“标准差” 这一统计概念及线性回归法,并用这些数学工具来研究人类的行为。 父母高,子女也高;父母矮,子女也矮。给定父母的身高,子女 平均身高趋向于“回归”到 全体人口的平均身高。
回归的现代释义
等式左边的变量被称为 被解释变量(explained variable) 因变量 (dependent variable)
等式右边的变量被称为 解释变量(explanatory variable) 自变量(independent variable)
响应变量(response variable)
样本回归模型:
ˆ ˆ X e Yi 0 1 i i
ˆ ˆX ˆ 样本回归直线: Y i 0 1 i
二、一元线性回归模型
回归分析都是从如下假设前提开始的:Y和X是代表某个总
体的变量,我们感兴趣的是“用X解释Y”或“研究Y如何随 X而变化”在写出用X解释Y的模型时,面临三个问题
Y和X的函数关系是怎么样的?
如何考虑其他影响Y的因素呢?
我们如何才能确信我们得到的是,是在其他条件不变情况下
的Y和X之间的关系?