数据结构第七章图1
数据结构-chap7 (1)图的存储结构

V2
V4 G2图示
无向图:在图G中,若所有边是无向边,则称G为无向图。
有向图:在图G中,若所有边是有向边,则称G为有向图。
二、图的基本术语
有向完全图: n个顶点的有向图最大边数是n(n-1) 无向完全图: n个顶点的无向图最大边数是n(n-1)/2 1、邻接点及关联边
主要内容
知识点
– – – – 1.图的定义,概念、术语及基本操作。 2.图的存储结构,特别是邻接矩阵和邻接表。 3.图的深度优先遍历和宽度优先遍历。 4.图的应用(连通分量,最小生成树,拓扑排序,关键路经,最短 路经)。 1.基本概念中,完全图、连通分量、生成树和邻接点是重点。 2.建立图的各种存储结构的算法。 3.图的遍历算法及其应用。 4.通过遍历求出连通分量的个数,深(宽)度优先生成树。 5.最小生成树的生成过程。 6.拓扑排序的求法。关键路经的求法。 7.最短路径的手工模拟。
自测题 2
设无向图的顶点个数为n,则该图最多有( )条边。 A.n-1
B.n(n-1)/2
C.n(n+1)/2 D.0 E.N2 【清华大学1998一.5(分)】
自测题 3
一个有n个结点的图,最少有( )个连通分量,最多有( )个 连通分量。
A. 0
B.1 C.n-1 D.n 【北京邮电大学 2000 二.5 (20/8分)】
0
V1 e1 V3 V4 V5 V2 1 0 1 0 1
否则
0 1 0 1 1 1 0 1 0 0 0 1 1 0 0 V1 V2 0 1 1 0 0 0 0 0 0 1 0 0 0 0 1 0
数据结构第七章-图

*
V0
V7
V6
V5
V4
V3
V2
V1
若图的存储结构为邻接表,则 访问邻接点的顺序不唯一, 深度优先序列不是唯一的
V0
V1
V3
V2
V7
V6
V5
V4
V0,V1,V3,V4,V7,V2,V5,V6,
※求图G以V0为起点的的深度优先序列(设存储结构为邻接矩阵)
void DFSAL(ALGraph G, int i) {/*从第v个顶点出发,递归地深度优先遍历图G*/ /* v是顶点的序号,假设G是用邻接表存储*/ EdgeNode *p; int w; visited[i] =1; Visit(i); /*访问第v个顶点*/ for (p=G.vertices[i].firstarc;p;p=p->nextarc) {w=p->adjvex; /*w是v的邻接顶点的序号*/ if (!visited[w]) DFSAL(G, w); /*若w尚未访问, 递归调用DFS*/ } }/*DFSAL*/
在邻接表存储结构上的广度优先搜索
*
Q
V0
V1
V2
V3
V4
V7
V5
V6
V1
V2
V3
V0
V4
V7
V5
V6
V0
V7
V6
V5
V4
V3
V2
V1
7.3 图的遍历
7
0
1
2
V0
V2
V3
V1
data
firstarc
0
1
^
^
adjvex
next
3
《数据结构》第二版严蔚敏课后习题作业参考答案(1-7章)

《数据结构》第二版严蔚敏课后习题作业参考答案(1-7章)【第一章绪论】1. 数据结构是计算机科学中的重要基础知识,它研究的是如何组织和存储数据,以及如何通过高效的算法进行数据的操作和处理。
本章主要介绍了数据结构的基本概念和发展历程。
【第二章线性表】1. 线性表是由一组数据元素组成的数据结构,它的特点是元素之间存在着一对一的线性关系。
本章主要介绍了线性表的顺序存储结构和链式存储结构,以及它们的操作和应用。
【第三章栈与队列】1. 栈是一种特殊的线性表,它的特点是只能在表的一端进行插入和删除操作。
本章主要介绍了栈的顺序存储结构和链式存储结构,以及栈的应用场景。
2. 队列也是一种特殊的线性表,它的特点是只能在表的一端进行插入操作,而在另一端进行删除操作。
本章主要介绍了队列的顺序存储结构和链式存储结构,以及队列的应用场景。
【第四章串】1. 串是由零个或多个字符组成的有限序列,它是一种线性表的特例。
本章主要介绍了串的存储结构和基本操作,以及串的模式匹配算法。
【第五章数组与广义表】1. 数组是一种线性表的顺序存储结构,它的特点是所有元素都具有相同数据类型。
本章主要介绍了一维数组和多维数组的存储结构和基本操作,以及广义表的概念和表示方法。
【第六章树与二叉树】1. 树是一种非线性的数据结构,它的特点是一个节点可以有多个子节点。
本章主要介绍了树的基本概念和属性,以及树的存储结构和遍历算法。
2. 二叉树是一种特殊的树,它的每个节点最多只有两个子节点。
本章主要介绍了二叉树的存储结构和遍历算法,以及一些特殊的二叉树。
【第七章图】1. 图是一种非线性的数据结构,它由顶点集合和边集合组成。
本章主要介绍了图的基本概念和属性,以及图的存储结构和遍历算法。
【总结】1. 数据结构是计算机科学中非常重要的一门基础课程,它关注的是如何高效地组织和存储数据,以及如何通过算法进行数据的操作和处理。
本文对《数据结构》第二版严蔚敏的课后习题作业提供了参考答案,涵盖了第1-7章的内容。
数据结构课后习题答案第七章
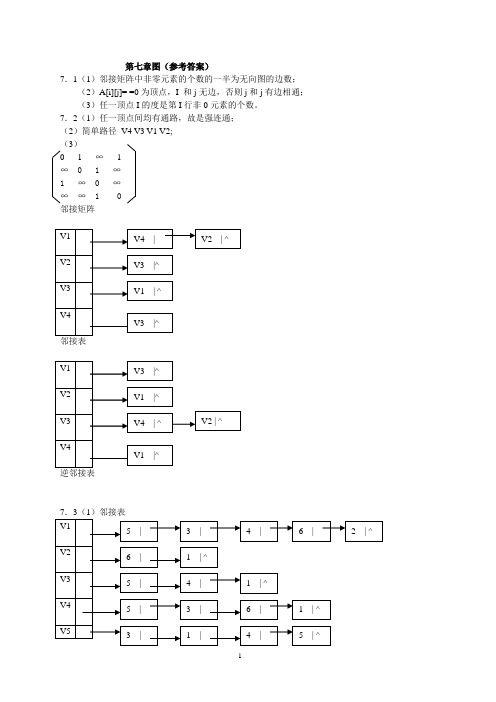
第七章图(参考答案)7.1(1)邻接矩阵中非零元素的个数的一半为无向图的边数;(2)A[i][j]= =0为顶点,I 和j无边,否则j和j有边相通;(3)任一顶点I的度是第I行非0元素的个数。
7.2(1)任一顶点间均有通路,故是强连通;(2)简单路径V4 V3 V1 V2;(3)0 1 ∞ 1∞ 0 1 ∞1 ∞ 0 ∞∞∞ 1 0邻接矩阵邻接表(2)从顶点4开始的DFS序列:V5,V3,V4,V6,V2,V1(3)从顶点4开始的BFS序列:V4,V5,V3,V6,V1,V27.4(1)①adjlisttp g; vtxptr i,j; //全程变量② void dfs(vtxptr x)//从顶点x开始深度优先遍历图g。
在遍历中若发现顶点j,则说明顶点i和j间有路径。
{ visited[x]=1; //置访问标记if (y= =j){ found=1;exit(0);}//有通路,退出else { p=g[x].firstarc;//找x的第一邻接点while (p!=null){ k=p->adjvex;if (!visited[k])dfs(k);p=p->nextarc;//下一邻接点}}③ void connect_DFS (adjlisttp g)//基于图的深度优先遍历策略,本算法判断一邻接表为存储结构的图g种,是否存在顶点i //到顶点j的路径。
设 1<=i ,j<=n,i<>j.{ visited[1..n]=0;found=0;scanf (&i,&j);dfs (i);if (found) printf (” 顶点”,i,”和顶点”,j,”有路径”);else printf (” 顶点”,i,”和顶点”,j,”无路径”);}// void connect_DFS(2)宽度优先遍历全程变量,调用函数与(1)相同,下面仅写宽度优先遍历部分。
王道数据结构 第七章 查找思维导图-高清脑图模板
每次调整的对象都是“最小不平衡子树”
插入操作
在插入操作,只要将最小不平衡子树调整平衡,则其他祖先结点都会恢复平衡
在A的左孩子的左子树中插入导致不平衡
由于在结点A的左孩子(L)的左子树(L)上插入了新结点,A的平衡因子由1增
至2,导致以A为根的子树失去平衡,需要一次向右的旋转操作。
LL
将A的左孩子B向右上旋转代替A成为根节点 将A结点向右下旋转成为B的右子树的根结点
RR平衡旋转(左单旋转)
而B的原左子树则作为A结点的右子树
在A的左孩子的右子树中插入导致不平衡
由于在结点A的左孩子(L)的右子树(R)上插入了新结点,A的平衡因子由1增
LR
至2,导致以A为根的子树失去平衡,需要两次旋转操作,先左旋转再右旋转。
将A的左孩子B的右子树的根结点C向左上旋转提升至B结点的位置
本质:永远保证 子树0<关键字1<子树1<关键字2<子树2<...
当左兄弟很宽裕时,用当前结点的前驱、前驱的前驱来填补空缺 当右兄弟很宽裕时,用当前结点的后继、后继的后继来填补空缺
兄弟够借。若被删除关键字所在结点删除前的关键字个数低于下限,且与此结点 右(或左)兄弟结点的关键字还很宽裕,则需要调整该结点、右(或左)兄弟结 点及其双亲结点及其双亲结点(父子换位法)
LL平衡旋转(右单旋转)
而B的原右子树则作为A结点的左子树
在A的右孩子的右子树中插入导致不平衡
由于在结点A的右孩子(R)的右子树(R)上插入了新结点,A的平衡因子由-1
减至-2,导致以A为根的子树失去平衡,需要一次向左的旋转操作。
RR
将A的右孩子B向左上旋转代替A成为根节点 将A结点向左下旋转成为B的左子树的根结点
湖经数据结构 7-图

计算机科学与技术学院 软件工程系 邓沌华
基于邻接矩阵的图的深度优先遍历算法
typedef struct vertextype
void DFS (MGraph G,int v )
{ int no;
char data; }VertexType; typedef struct mgraph
{ int w;
4
8
5
6
7
是一个递归的过程,类似于树的先序遍历。
遍历结果:
1
2
4
8
5
3
6
7
计算机科学与技术学院 软件工程系 邓沌华
例 1: 1
深度优先遍历
答案一: 1
2 5 4 3 答案二: 6
2
4
8
5
6
3
7
7 8
1
2
5
8
4
7
3
6
答案三:
1 3 6 8 7 4 2 5
计算机科学与技术学院 软件工程系 邓沌华
例 2: 已知图的邻接表如下所示,根据算法,则从顶点0出 发按深度优先遍历的结点序列是 A. 0 1 3 2 C. 0 3 2 1 B. 0 2 3 1 D. 0 1 2 3 √
计算机科学与技术学院 软件工程系 邓沌华
引言 图是比线性表和树更为复杂的非线性的数据结构。 线性表:前后相继、序列;
树:层次、分支;
图:结点之间 的关系可以是任意的,任意两个数 据元素之间都可能相关。 线性表和树都可以看成是简单的图。 图的应用领域:电路网络分析、交通运输、管理 与线路的铺设、印刷电路板与集成电路的布线等; 工作的分配、工程进度的安排、课程表的制订、 关系数据库的设计等。
数据结构第七章课后习题答案 (1)
7_1对于图题7.1(P235)的无向图,给出:(1)表示该图的邻接矩阵。
(2)表示该图的邻接表。
(3)图中每个顶点的度。
解:(1)邻接矩阵:0111000100110010010101110111010100100110010001110(2)邻接表:1:2----3----4----NULL;2: 1----4----5----NULL;3: 1----4----6----NULL;4: 1----2----3----5----6----7----NULL;5: 2----4----7----NULL;6: 3----4----7----NULL;7: 4----5----6----NULL;(3)图中每个顶点的度分别为:3,3,3,6,3,3,3。
7_2对于图题7.1的无向图,给出:(1)从顶点1出发,按深度优先搜索法遍历图时所得到的顶点序(2)从顶点1出发,按广度优先法搜索法遍历图时所得到的顶点序列。
(1)DFS法:存储结构:本题采用邻接表作为图的存储结构,邻接表中的各个链表的结点形式由类型L_NODE规定,而各个链表的头指针存放在数组head中。
数组e中的元素e[0],e[1],…..,e[m-1]给出图中的m条边,e中结点形式由类型E_NODE规定。
visit[i]数组用来表示顶点i是否被访问过。
遍历前置visit各元素为0,若顶点i被访问过,则置visit[i]为1.算法分析:首先访问出发顶点v.接着,选择一个与v相邻接且未被访问过的的顶点w访问之,再从w 开始进行深度优先搜索。
每当到达一个其所有相邻接的顶点都被访问过的顶点,就从最后访问的顶点开始,依次退回到尚有邻接顶点未曾访问过的顶点u,并从u开始进行深度优先搜索。
这个过程进行到所有顶点都被访问过,或从任何一个已访问过的顶点出发,再也无法到达未曾访问过的顶点,则搜索过程就结束。
另一方面,先建立一个相应的具有n个顶点,m条边的无向图的邻接表。
数据结构(C语言版)_第7章 图及其应用
实现代码详见教材P208
7.4 图的遍历
图的遍历是对具有图状结构的数据线性化的过程。从图中任 一顶点出发,访问输出图中各个顶点,并且使每个顶点仅被访 问一次,这样得到顶点的一个线性序列,这一过程叫做图的遍 历。
图的遍历是个很重要的算法,图的连通性和拓扑排序等算法 都是以图的遍历算法为基础的。
V1
V1
V2
V3
V2
V3
V4
V4
V5
图9.1(a)
图7-2 图的逻辑结构示意图
7.2.2 图的相关术语
1.有向图与无向图 2.完全图 (1)有向完全图 (2)无向完全图 3.顶点的度 4.路径、路径长度、回路、简单路径 5.子图 6.连通、连通图、连通分量 7.边的权和网 8.生成树
2. while(U≠V) { (u,v)=min(wuv;u∈U,v∈V-U); U=U+{v}; T=T+{(u,v)}; }
3.结束
7.5.1 普里姆(prim)算法
【例7-10】采用Prim方法从顶点v1出发构造图7-11中网所对 应的最小生成树。
构造过程如图7-12所示。
16
V1
V1
V2
7.4.2 广度优先遍历
【例7-9】对于图7-10所示的有向图G4,写出从顶点A出发 进行广度优先遍历的过程。
访问过程如下:首先访问起始顶点A,再访问与A相邻的未被 访问过的顶点E、F,再依次访问与E、F相邻未被访问过的顶 点D、C,最后访问与D相邻的未被访问过的顶点B。由此得到 的搜索序列AEFDCB。此时所有顶点均已访问过, 遍历过程结束。
【例7-1】有向图G1的逻辑结构为:G1=(V1,E1) V1={v1,v2,v3,v4},E1={<v1,v2>,<v2,v3>,<v2,v4>,<v3,v4>,<v4,v1>,<v4,v3>}
数据结构第七章--图(严蔚敏版)
8个顶点的无向图最多有 条边且该图为连通图 个顶点的无向图最多有28条边且该图为连通图 个顶点的无向图最多有 连通无向图构成条件:边 顶点数 顶点数-1)/2 顶点数*(顶点数 连通无向图构成条件 边=顶点数 顶点数 顶点数>=1,所以该函数存在单调递增的单值反 顶点数 所以该函数存在单调递增的单值反 函数,所以边与顶点为增函数关系 所以28个条边 函数 所以边与顶点为增函数关系 所以 个条边 的连通无向图顶点数最少为8个 所以28条边的 的连通无向图顶点数最少为 个 所以 条边的 非连通无向图为9个 加入一个孤立点 加入一个孤立点) 非连通无向图为 个(加入一个孤立点
28
无向图的邻接矩阵为对称矩阵
2011-10-13
7.2
图的存储结构
Wij 若< vi,vj > 或<vj,v i > ∈E(G)
若G是网(有权图),邻接矩阵定义为 是网(有权图), ),邻接矩阵定义为
A [ i,j ] = , 0或 ∞
如图: 如图:
V1
若其它
V2
3 4
2
V3
2011-10-13
C
A
B
D 2011-10-13 (a )
3
Königsberg七桥问题
• Königsberg七桥问题就是说,能否从某点出发 通过每桥恰好一次回到原地?
C
C
A B
.
A D
B
D (a)
2011-10-13
(b)
4
第七章 图
7.1 图的定义 7.2 图的存储结构 7.3 图的遍历 7.4 图的连通性问题 7.5 有向无环图及其应用 7.6 最短路径
2011-10-13
数据结构 习题 第七章 图 答案
第7章图二.判断题部分答案解释如下。
2. 不一定是连通图,可能有若干连通分量 11. 对称矩阵可存储上(下)三角矩阵14.只有有向完全图的邻接矩阵是对称的 16. 邻接矩阵中元素值可以存储权值21. 只有无向连通图才有生成树 22. 最小生成树不唯一,但最小生成树上权值之和相等26. 是自由树,即根结点不确定35. 对有向无环图,拓扑排序成功;否则,图中有环,不能说算法不适合。
42. AOV网是用顶点代表活动,弧表示活动间的优先关系的有向图,叫顶点表示活动的网。
45. 能求出关键路径的AOE网一定是有向无环图46. 只有该关键活动为各关键路径所共有,且减少它尚不能改变关键路径的前提下,才可缩短工期。
48.按着定义,AOE网中关键路径是从“源点”到“汇点”路径长度最长的路径。
自然,关键路径上活动的时间延长多少,整个工程的时间也就随之延长多少。
三.填空题1.有n个顶点,n-1条边的无向连通图2.有向图的极大强连通子图3. 生成树9. 2(n-1) 10. N-1 11. n-1 12. n 13. N-1 14. n15. N16. 3 17. 2(N-1) 18. 度出度 19. 第I列非零元素个数 20.n 2e21.(1)查找顶点的邻接点的过程 (2)O(n+e) (3)O(n+e) (4)访问顶点的顺序不同 (5)队列和栈22. 深度优先 23.宽度优先遍历 24.队列25.因未给出存储结构,答案不唯一。
本题按邻接表存储结构,邻接点按字典序排列。
25题(1) 25题(2) 26.普里姆(prim )算法和克鲁斯卡尔(Kruskal )算法 27.克鲁斯卡尔28.边稠密 边稀疏 29. O(eloge ) 边稀疏 30.O(n 2) O(eloge) 31.(1)(V i ,V j )边上的权值 都大的数 (2)1 负值 (3)为负 边32.(1)n-1 (2)普里姆 (3)最小生成树 33.不存在环 34.递增 负值 35.16036.O(n 2) 37. 50,经过中间顶点④ 38. 75 39.O(n+e )40.(1)活动 (2)活动间的优先关系 (3)事件 (4)活动 边上的权代表活动持续时间41.关键路径 42.(1)某项活动以自己为先决条件 (2)荒谬 (3)死循环 43.(1)零 (2)V k 度减1,若V k 入度己减到零,则V k 顶点入栈 (3)环44.(1)p<>nil (2)visited[v]=true (3)p=g[v].firstarc (4)p=p^.nextarc45.(1)g[0].vexdata=v (2)g[j].firstin (3)g[j].firstin (4)g[i].firstout (5)g[i].firstout (6)p^.vexj (7)g[i].firstout (8)p:=p^.nexti (9)p<>nil (10)p^.vexj=j(11)firstadj(g,v 0) (12)not visited[w] (13)nextadj(g,v 0,w)46.(1)0 (2)j (3)i (4)0 (5)indegree[i]==0 (6)[vex][i] (7)k==1 (8)indegree[i]==047.(1)p^.link:=ch[u ].head (2)ch[u ].head:=p (3)top<>0 (4)j:=top (5)top:=ch[j].count(6)t:=t^.link48.(1)V1 V4 V3 V6 V2 V5(尽管图以邻接表为存储结构,但因没规定邻接点的排列,所以结果是不唯一的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
DFS(G,v); printf("\n"); } #include"E:\SourceCode\DS\实验\第三章\循环队列.c" //算法7.6 void BFSTraverse(MGraph G,Status(*Visit)(VertexType)) { int v,u,w; VertexType w1,u1; SqQueue *Q; for(v=0;v<G.vexnum;v++) visited[v]=FALSE; Q=InitQueue(Q); for(v=0;v<G.vexnum;v++) if(!visited[v]) { visited[v]=TRUE; Visit(G.vexs[v]); EnQueue(Q,v); while(!QueueEmpty(Q)) { u=DeQueue(Q); strcpy(u1,*GetVex(G,u)); for(w=FirstAdjVex(G,u1);w>=0;w=NextAdjVex(G,u1,strcpy(w1,*GetVex(G,w)))) if(!visited[w]) { visited[w]=TRUE; Visit(G.vexs[w]); EnQueue(Q,w); } } } printf("\n"); }
Байду номын сангаас
void main() { MGraph g; printf("----------------------------------------------------------------------\n"); printf(" 利用图的邻接矩阵进行图的遍历 \n"); printf(" Algorithm 7.4,7.5,7.6 \n"); printf("----------------------------------------------------------------------\n"); CreateUDN(&g); Display(g); printf("深度优先搜索的结果:\n"); DFSTraverse(g,visit); printf("广度优先搜索的结果:\n"); BFSTraverse(g,visit); } //------------------图的邻接表存储表示-----------------#include<stdio.h> #include<malloc.h> #include<string.h> #define OK 1 #define ERROR 0 typedef int Status; #define MAX_VERTEX_NUM 20 #define MAX_NAME 3 typedef int InfoType; typedef char VertexType[MAX_NAME]; typedef enum{DG,DN,UDG,UDN}GraphKind;//{有向图,有向网,无向图,无向 网} typedef struct ArcNode { int adjvex; struct ArcNode *nextarc;
InfoType *info;//该弧有关信息的指针 }ArcNode; typedef struct VNode { VertexType data; ArcNode *firstarc; }VNode,AdjList[MAX_VERTEX_NUM]; typedef struct { AdjList vertices; int vexnum,arcnum; int kind; }ALGraph; //求顶点在图中的位置 int LocateVex(ALGraph G,VertexType u) { int i; for(i=0;i<G.vexnum;i++) if(strcmp(u,G.vertices[i].data)==0) return i; return -1; } //建图 Status CreateGraph(ALGraph *G) { int i,j,k,w; VertexType v1,v2; ArcNode *p; printf("请输入图的类型(有向图:0,有向网:1,无向图:2,无向网:3):"); scanf("%d",&(*G).kind); printf("请输入图的顶点数,边数:"); scanf("%d,%d",&(*G).vexnum,&(*G).arcnum);
p->info=(int*)malloc(sizeof(int)); *(p->info)=w; } else p->info=NULL; p->nextarc=(*G).vertices[j].firstarc; (*G).vertices[j].firstarc=p; } } return OK; } //输出 void Display(ALGraph G) { int i; ArcNode *p; switch(G.kind) { case DG: printf("建立的是有向图:\n"); break; case DN: printf("建立的是有向网:\n"); break; case UDG: printf("建立的是无向图:\n"); break; case UDN: printf("建立的是无向网:\n"); } printf("%d个顶点:\n",G.vexnum); for(i=0;i<G.vexnum;++i) printf("%s ",G.vertices[i].data); printf("\n%d条弧(边):\n",G.arcnum); for(i=0;i<G.vexnum;i++) { p=G.vertices[i].firstarc; while(p) {
printf("请输入%d个顶点的值(最大命名为%d个字符):\n", (*G).vexnum,MAX_NAME); for(i=0;i<(*G).vexnum;++i) { scanf("%s",(*G).vertices[i].data); (*G).vertices[i].firstarc=NULL; } if((*G).kind==1||(*G).kind==3) printf("输入每条边的权值+弧尾+弧头:\n"); else printf("输入每条边的弧尾+弧头:\n"); for(k=0;k<(*G).arcnum;++k) { if((*G).kind==1||(*G).kind==3) scanf("%d%s%s",&w,v1,v2); else scanf("%s%s",v1,v2); i=LocateVex(*G,v1); j=LocateVex(*G,v2); p=(ArcNode*)malloc(sizeof(ArcNode)); p->adjvex=j; if((*G).kind==1||(*G).kind==3) { p->info=(int *)malloc(sizeof(int)); *(p->info)=w; } else p->info=NULL; p->nextarc=(*G).vertices[i].firstarc; (*G).vertices[i].firstarc=p; if((*G).kind>=2) { p=(ArcNode*)malloc(sizeof(ArcNode)); p->adjvex=i; if((*G).kind==3) {
//-----------------------使用数组结构的BFS_DFS遍历----------------------//-----------------------在调用main函数时要把其他的main函数注释掉------------------#include"图的邻接矩阵存储表示.c" #include<process.h> #define TRUE 1 #define FALSE 0 typedef int Boolean; Boolean visited[MAX_VERTEX_NUM]; Status(*VisitFunc)(VertexType); //访问函数 Status visit(VertexType i) { printf("%s ",i); return OK; } //返回顶点的值 VertexType* GetVex(MGraph G,int v) { if(v>=G.vexnum||v<0) exit(ERROR); return &G.vexs[v]; } //求第一个邻接点的位置 int FirstAdjVex(MGraph G,VertexType v) { int i,j=0,k; k=LocateVex(G,v); for(i=0;i<G.vexnum;i++) if(G.arcs[k][i].adj!=j) return i; return -1;
} //下一个邻接点的位置 int NextAdjVex(MGraph G,VertexType v,VertexType w) { int i,j=0,k1,k2; k1=LocateVex(G,v); k2=LocateVex(G,w); for(i=k2+1;i<G.vexnum;i++) if(G.arcs[k1][i].adj!=j) return i; return -1; } //算法7.5 void DFS(MGraph G,int v) { VertexType w1,v1; int w; visited[v]=TRUE; VisitFunc(G.vexs[v]); strcpy(v1,*GetVex(G,v)); for(w=FirstAdjVex(G,v1);w>=0;w=NextAdjVex(G,v1,strcpy(w1,*GetVex(G,w)))) if(!visited[w]) DFS(G,w); } //算法7.4 void DFSTraverse(MGraph G,Status(*Visit)(VertexType)) { int v; VisitFunc=Visit; for(v=0;v<G.vexnum;v++) visited[v]=FALSE; for(v=0;v<G.vexnum;v++) if(!visited[v])