线性回归中被测样不确定度评定的几种方法及其分歧根源
测量不确定度评定的方法以及实例

第一节有关术语的定义3.量值 value of a quantity一般由一个数乘以丈量单位所表示的特定量的大小。
例: 5.34m 或 534cm, 15kg, 10s,- 40℃。
注:对于不可以由一个乘以丈量单位所表示的量,能够参照商定参照标尺,或参照丈量程序,或二者参照的方式表示。
4.〔量的〕真值 rtue value〔of a quantity〕与给定的特定量定义一致的值。
注:(1)量的真值只有经过完美的丈量才有可能获取。
(2)真值按其天性是不确立的。
(3)与给定的特定量定义一致的值不必定只有一个。
5.〔量的〕商定真值 conventional true value〔of a quantity〕对于给定目的拥有适合不确立度的、给予特定量的值,有时该值是商定采纳的。
例: a) 在给定地址,取由参照标准复现而给予该量的值人作为给定真值。
b) 常数委员会 (CODATA)1986年介绍的阿伏加得罗常数值 6.0221367 × 1023mol-1。
注:(1)商定真值有时称为指定值、最正确预计值、商定值或参照值。
(2)经常用某量的多次丈量结果来确立商定真值。
13.影响量 influence quantity不是被丈量但对丈量结果有影响的量。
例: a) 用来丈量长度的千分尺的温度;b)沟通电位差幅值丈量中的频次;c)丈量人体血液样品血红蛋浓度时的胆红素的浓度。
14.丈量结果 result of a measurement由丈量所获取的给予被丈量的值。
注:(1)在给出丈量结果时,应说明它是示值、示修正丈量结果或已修正丈量结果,还应表示它能否为几个值的均匀。
(2)在丈量结果的完好表述中应包含丈量不确立度,必需时还应说明有关影响量的取值范围。
15.〔丈量仪器的〕示值 indication〔of a measuring instrument〕丈量仪器所给出的量的值。
注:(1)由显示器读出的值可称为直接示值,将它乘以仪器常数即为示值。
测量不确定度的评定与表示

测量不确定度评定与表示JJF1059.1--20122015.12.29南京JJF1059.1测量不确定度的评定与表示一、(测量)不确定度概念1.不确定度概念绝对测量 x y =直接测量相对测量 0x x y -= 0y U y Y ⊃±=间接测量 ),(21N x x x f y ⋅⋅⋅=定义:测量不确定度是与测量结果相联系的参数,合理地赋予被测量结果的分散性。
新定义:根据所获信息,表征赋予被测量值分散性的非负参数。
2.不确定来源表现为:(1)对被测量的定义不完整或不完善 (2)复现被测量定义的方法不理想 (3)测量所取样本的代表性不够(4)对测量过程受环境影响的认识不周全,或对环境条件的测量与控制不完善(5)对模拟式仪器的读数存在人为偏差(6)仪器计量性能上的局限性(7)赋予测量标准和标准物质的标准值的不准确 (8)引用常数或其它参量的不准确(9)与测量原理、测量方法和测量程序有关的的近似性或假定性 (10)在相同的测量条件下,被测量重复观测值的随机变化 (11)对一定系统误差的修正不完善 (12)测量列中的粗大误差因不明显而未剔除(13)在有的情况下,需要对某种测量条件变化,或者是在一个较长的规定时间内,对测量结果的变化作出评定。
应把该相应变化所赋予测量值的分散性大小,作为该测量结果的不确定度。
3.测量不确定度分类与字母表示 3.1绝对量表达A 类标准不确定度(用统计方法得到):A u 一般可统一表示 标准不确定度B 类标准不确定度(用其他方法得到):B u 为:)(x u 或i u 测量不 合成标准不确定度C u 或)(y u C 确定度扩展不确定度 U 或)(y U : C ku U = (k 为包含因子)3.2相对量表达A 类标准不确定度(用统计方法得到):rel A u . 一般可表示 相对标准不确定度B 类标准不确定度(用其他方法得到):rel B u . 为:)(x u rel 或rel i u . 相对测量 合成标准不确定度relC u . 或 )(y u rel C 不确定度相对扩展不确定度 rel U 或 )(y U rel : rel C rel ku U .= (k 为包含因子)二、测量不确定度评定与表示1.A 类标准不确定度计算A 类标准不确定度是指测量随机效应引入的标准不确定度,用A 类评定。
如何评估实验技术中的测量误差和不确定度

如何评估实验技术中的测量误差和不确定度在科学实验中,准确的数据是非常重要的,因为只有准确的数据才能得出可靠的结论和推论。
然而,在实验过程中,测量误差和不确定度是无法避免的问题。
所以,如何评估实验技术中的测量误差和不确定度,是科学家们一直在探索和研究的课题。
首先,我们需要了解什么是测量误差和不确定度。
测量误差指的是测量结果与真值之间的差异,可以由系统误差和随机误差构成。
系统误差是由于实验仪器的不准确或操作方法的不当引起的,而随机误差是由于各种随机因素造成的。
不确定度是对测量结果的不精确程度的量度,它是对测量结果的置信程度的度量。
为了评估实验技术中的测量误差和不确定度,我们可以采用以下方法:1. 重复实验法:通过进行多次实验,然后计算结果的平均值和标准差来评估测量误差和不确定度。
重复实验可以降低随机误差的影响,并提高测量结果的准确性。
在进行重复实验时,要注意控制实验条件的一致性,以减小系统误差的影响。
2. 不确定度分析法:通过分析实验技术本身的不确定度来评估整个实验结果的不确定度。
不确定度分析法主要包括以下几个步骤:确定实验技术的不确定度来源、计算各不确定度的贡献、组合不确定度以获得最终结果的不确定度。
通过这种方法,我们可以更全面地评估实验技术中的测量误差和不确定度。
3. 校准仪器:实验仪器是产生测量误差的重要原因之一,因此,定期对实验仪器进行校准是评估测量误差和不确定度的重要手段。
校准可以通过与已知准确度的标准进行对比来进行,以确定实验仪器的偏差和误差。
除了上述方法,还有一些其他的技术和方法可以用于评估实验技术中的测量误差和不确定度,例如数据处理和统计分析等。
数据处理包括数据筛选、数据平滑和数据插值等,可以减小随机误差和系统误差的影响。
统计分析可以通过假设检验、相关性分析和回归分析等方法对测量结果进行评估和解释。
总之,评估实验技术中的测量误差和不确定度是科学实验中非常重要的一环。
只有通过科学的方法和技术对测量误差和不确定度进行评估,才能得出准确可靠的实验结果,从而推动科学研究的进展。
一元线性回归系数比值不确定度的评定

礤
显然 , 上式 的成立 条件 是 。 b是线 性无 关 的.回归 系数 o b线性 无关 吗? 、 、
文献 [ ] 2 0 2 ( 0 7年 , 4版 )修 订 了上式 , 出了折合 系数 c的不 确定 度公 式 : 第 给
式 中 的相 关 系数为
, 一 一
二
:
二墨:
√∑( ∑( 一 ) √ 一2 √ 一。 一 )√ y ( y ( 夕 c ) )
进行 拟合 ( 一元 线性 回归 ) 得到 回归 方程 =o+b , x中参数 的最佳 估计 值 n b 称 为 回归 系数 )以及 它们 的 、(
标 准偏差 s 、 , 。s 然后 根据 回归 系数 比值求 出有关 物 理量.比如弹 簧振子 中弹簧 的有 效质 量 m有 效是 回归 直线
为简单 起见 , 间接 测量 量 l 直 接测量 量 , 设 厂 是 Y的函数 , 即
f =f ,) ( Y () 1
在相 同 的条件 下 , 对 , 作 了 n次测 量 : , i:1 2 … , ) 其 平均 值分 别为 , 真 值分 别为 , .则 Y Y( ,, r , b , y 问接 测量量 的真值为 F =I , ) 厂 Y. (
上式中的c (, 称为 。 y v ) 协方差,o(, :∑ ( x ( 一 ) 式() 关于标 误差的 根 合成 c ) v , ) 一 )y y, 3 是 准 方和 法
公 式.如果 和 Y彼 此独立 , 有 r =0, 时 , ( ) 则 这 式 3 可简 化为
, () ㈩+ ) y )芸 = ( ( )
() 6
作 为标 准 误差 o( 、 Y r ) ( )的估 计值 , 式 ( ) 式 ( ) 则 3 、 4 可分别 改写 为
线性回归的不确定度问题

r
c0VL d f acid f time f temp aV
-2
式中: r ---每单位面积镉溶出量 (mg﹒dm )
c 0 ---浸取液中镉含量
d ---稀释系数 V L ---浸取液体积
(mg﹒l )
-1
(l)
2
aV
----容器的表面积 (dm ) ----酸浓度的影响 ----浸泡时间的影响
3
中,溶液高度距陶瓷器皿上口 1mm;; ③ 记录 4%醋酸溶液的量,本例 VL=332ml; ④ 样品在(22±2)℃的条件下放置 24h(黑暗中) ⑤ 搅拌溶液使其均匀。取一部分溶液稀释,稀释系数为 d。 ⑥ 选用适当的波长在 AAS 上进行分析。校准直线已事先建立; 。 ⑦ 计算结果,报告在总浸取液中镉的含量(mg/dm ) 3 数学模型
ˆ ˆ) / b x0 ( y0 a s 1 1 ( x0 x ) 2 uc ( x0 ) n ˆ b p n ( x x )2
i 1 i
n为测量次数,s为标准偏差 p和u本别是什么?
1 1 ( x0 x ) 2 u c ( y0 ) s n p n ( x x )2
第 j 个响应值(观测值)
y1.m
y2.m
y3.m y
ym
y4 y2 y1
yn.m
y a b x
x1
x2
x3
xn
x
散点图(说明:由于本人在计算机上作图的能力有限,所以此 图有很多信息未表达甚至有误,请注意。 ) 用这一系列输入值与观测值, 根据最小的乘法原理可以回归出一 条最佳直线:
ˆx ˆa ˆb y
s余 ˆi )2 ( yi y s n2 n2
不确定度评估的基本方法

三、检测和校准实验室不确定度评估的基本方法1、测量过程描述:通过对测量过程的描述,找出不确定度的来源。
内容包括:测量内容;测量环境条件;测量标准;被测对象;测量方法;评定结果的使用。
不确定度来源:● 对被测量的定义不完整; ● 实现被测量的测量方法不理想;● 抽样的代表性不够,即被测样本不能代表所定义的被测量;● 对测量过程受环境影响的认识不周全,或对环境的测量与控制不完善; ● 对模拟式仪器的读数存在人为偏移;● 测量仪器的计量性能(如灵敏度、鉴别力、分辨力、死区及稳定性等)的局限性; ● 测量标准或标准物质的不确定度;● 引用的数据或其他参量(常量)的不确定度; ● 测量方法和测量程序的近似性和假设性; ● 在相同条件下被测量在重复观测中的变化。
2、建立数学模型:建立数学模型也称为测量模型化,根据被测量的定义和测量方案,确立被测量与有关量之间的函数关系。
● 被测量Y 和所有个影响量i X ),2,1(n i ,⋯=间的函数关系,一般可写为),2,1(nX X X f Y ,⋯=。
● 若被测量Y 的估计值为y ,输入量i X 的估计值为i x ,则有),x ,,x f(x y n ⋯=21。
有时为简化起见,常直接将该式作为数学模型,用输入量的估计值和输出量的估计值代替输入量和输出量。
● 建立数学模型时,应说明数学模型中各个量的含义。
● 当测量过程复杂,测量步骤和影响因素较多,不容易写成一个完整的数学模型时,可以分步评定。
● 数学模型应满足以下条件:1) 数学模型应包含对测量不确定度有显著影响的全部输入量,做到不遗漏。
2) 不重复计算不确定度分量。
3) 选取合适的输入量,以避免处理较麻烦的相关性。
● 一般根据测量原理导出初步的数学模型,然后将遗漏的输入量补充,逐步完善。
3、不确定度的A 类评定:(1)基本方法——贝塞尔公式(实验标准差)方法在重复性条件下对被测量X 做n 次独立重复测量,得到的测量结果为i x ),2,1(n i ,⋯=。
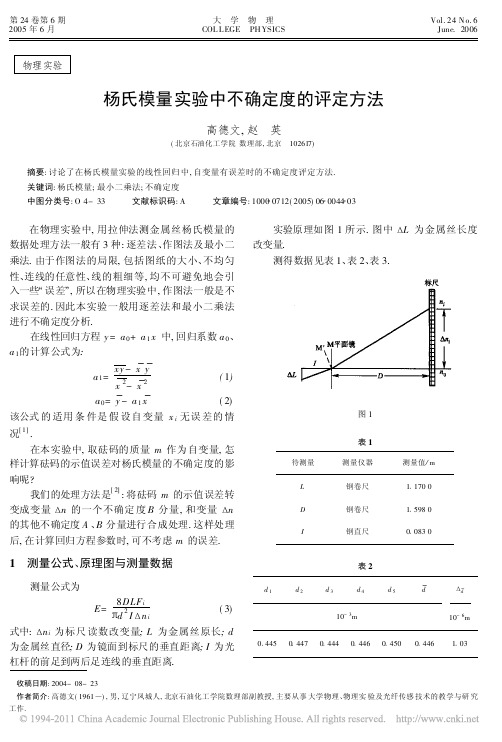
杨氏模量实验中不确定度的评定方法
Interference pattern of convergent light for a uniaxial crystal with optical axis parallel to surface
SH EN W ei min
( Department of O ptoelectronic Info rmation Eng ineering, China Jiliang U niversity , Hangzhou 310018, China)
参考文献:
[ 1] 杨述武. 普 通物理 实验 力 学及热 学部分[ M ] . 第 3 版. 北京: 高等教育出版社, 2000. 30~ 31.
[ 2] 史彭, 王占民. 一元线性回 归的不确定 度评定 方法[ J] .
西安建筑科技大学学报, 2000( 1) : 82~ 85. [ 3] 龚镇雄. 普通 物理 实验中 的数 据处 理[ M ] . 西安: 西 北
电讯工程学院出版社, 1985. 133~ 149. [ 4] 丁慎训, 张连 芳. 物 理实 验教 程[ M ] . 第 2 版. 北 京: 清
华大学出版社, 2002. 75. [ 5] 欧阳九令. 常 用物 理测量 手册 [ M ] . 北 京: 中国 工人 出
版社, 1998. 38. [ 6] 刘智敏, 刘风. 测 量不 确定度 的评 定与 表示 [ J] . 物理,
uA =
i= 1
9- 2
= 0 000 13 m
3 2 n 的不确定度B 分量
1) 标尺不确定度 uB1 标尺的误差限[ 4] :
N = 0 1 mm ( 设均匀分布)
uB1 =
(
N
3
)
有关测量不确定度的若干见解

有关测量不确定度的若干见解陈建志(厦门市计量检定测试院,福建厦门361004)摘 要:文章介绍了测量不确定度区间表达方式使用中注意的事项;阐述了不确定度预评定过程时应注意的问题,并以电测仪表为例,介绍如何运用线性回归计算给出区间不确定度的表达方式;结合实际工作经验,给出不确定度使用过程中需要注意的几个问题。
关键词:测量不确定度;预评定;B类评定;线性回归中图分类号:TB9 文献标识码:A 国家标准学科分类代码:410 55DOI:10.15988/j.cnki.1004-6941.2020.9.025SomeComprehensionsaboutMeasurementUncertaintyCHENJianzhiAbstract:Thispaperintroducessomeproblemsthatshouldbepaidattentiontointheexpressionofmeasurementuncertainty;expoundstheproblemsthatshouldbepaidattentiontointheprocessofuncertaintypre-evaluation,andtakingtheelectricmeasuringinstrumentasanexample,introducestheevaluationofuncertaintybylinearre gressioncalculation Basedonexperience,givesomepointstobenotedintheuseofmeasurementuncertaintyKeywords:measurementuncertainty;pre-evaluation;evaluationofBuncertainty;linearregression0 引言不确定度是计量学中的一个非常重要的概念,它的定义是用来表征合理地赋予被测量之值的分散性,与测得值相联系的参数。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
线性回归引入的不确定度
一般化学检测中,是通过观察激励值(例如浓
度)戈和响应值(信号)),之间的关系,来实现被测样 戈。。。的间接检测的。在大多数情况下,菇和y认为是 线性关系(限于直线线性段),即
y=口+k
(1)
前,对拟合直线中的参数,斜率6和截距口的不确 定度公式基本无分歧,但对线性回归结果不确定 度M(石。。)的评定,分歧较大,也是本文讨论的
[8]龚思维,等.分光光度法测定磷的测量不确定度的评定[J].化
学分析计量,2004,13(6) [9]郭兰典,等.仪器分析中线性回归标准曲线法分析结果不确定 度评估[J].检验检疫科学,200l(4) [10]罗颖.一元线性回归系数比值不确定度的评定[J].赣南师范 学院学报,2011(6) [11]唐象能,戴俭华.数理统计[M].北京:机械工业出版 社,1994 [12]宋妲音,等.化学检测实验室线性最小二乘法校准的不确定度 评定[J].环境监测管理与技术,2003(6) [13]金正一,李风岐.一元线性参数最小二乘法中斜率及截距的不 确定度.沈阳工业学院学报,2000,19(1)
(o,6)=一1。
由于方法I中截距口和斜率6的相关性是通过 统计学推导得出的,由式(7)得到的线性回归不确 定度也更为科学合理,为《指南》等权威参考资料所 采用。而方法Ⅱ和方法Ⅲ中,在缺乏理论依据的基 础上,为了方便计算分别直接采用截距口和斜率6 为正强相关或不相关,这是不科学的,需要摒弃。
・65・
简化为:
方法I
《化学分析中不确定度评估指南(CNAS・GL 的被测样戈删的不确定度Ⅱ(z删)为[1’3]:
2:
2006)》(下文简称《指南》)指出,由线性回归引人
咖一=刮寺+杰+竿(14)
在有些文献中,甚至认为线性回归引入的不确 定度只包括截距口和截距6所引入的不确定度,所 以,式(13)中不包括M(y)部分‘7’81。 除了以上三种方法,郭兰典等人一。将最小二乘 法中n和6的计算公式分别代人式(8),然后,再按 照方法II的步骤,展开计算M(戈涮),但该方法计算 过程非常复杂,缺少可读性,应用实例很少,这里不
M2
3几种评定方法的区别
《材料》案例归纳的三种方法,也是广泛应用于 各类线性回归不确定度评定参考文献的方法,但三 种方法的结果是否有差异,并未引起大家的重视。 从式(7)、式(12)和式(14)可以看出,三种方法得 到的u(髫。。。)的计算公式结构相似,但内容不完全相 同,导致数值和变化趋势上存在显著差异。
1
。∑洲 。∑H
,L
鬈 一V
一 一筇
2
、,
=
mLeabharlann 。∑川,k筇
一
一X
、,
m【弦一告c和2】
㈤
值得注意的是,很多参考资料中计算公式的不 统一和错误,是由于混淆了式(2)和式(3)而引起 的。下面讨论的情景,都针对每个溶液测量m次的 情况,即下面涉及的L。。计算公式均选用式(3)。利 用式(1)确认的线性关系,根据被测样品中被分析 物产生的响应值(用y。h表示),可求得其对应的浓
doi:10.3969/i.issn.1000一0771.2016.11.20
O
引言
基于最小二乘法原理的线性回归是化学分析
£。为戈的方差,则‘1 3|:
k。;(戈i一习2 2荟zi2一寺(善菇i)2
(2)
中常用的一种方法,通过建立被测样与响应值的线 性关系,可快速实现被测样的间接测量。由最小二 乘法拟合得到曲线和相关参数的不确定度,是评定
参考文献
[1]中国合格评定国家认可中心,等.材料理化检验测量不确定度 评估指南及实例(cNAs—GL 10:2006)[M].北京:中国计量出版 社,2007 [2]李慎安,等.化学实验室测量不确定度[M].北京:化学工业出 版社,2006
(cNAs.GL 2:2006)[s]
[4]cn’Ac/EuRACHEM istry[S].2002
唧¨p圳一———————1厂—————一
(15)
,、var(儿bs)+var(a)+菇■・var(6)+‰・covar(口,6)
其中:M(石,red)=√var(戈畔。),M(口)=/var(口),
u(6)=√var(6)。 该步骤和方法Ⅱ一样,是通过对式(8)展开,再 利用已有的u(o)、u(6)公式代人,但是不同的是, 关于a、6的相关性部分,是利用协方差来表示,且统 计学表明,他们之间的协方差¨0。11]:
万方数据
■瞄目甚圈翟圈
[3]中国合格评定国家认可委员会.化学分析中不确定度评估指南
5结论
目前,线性回归引起的线性回归结果不确定度 的评定存在至少三种方法,这些方法评定结果的大 小、变化趋势都明显不同。分析表明,这些方法都 是基于截距。和斜率6不确定度统计结果基础上, 对z的计算公式通过传统的不确定度分析方法展开 得到的,产生分歧的根源在于对截距口和斜率6的 相关性取值不同。简单认为两者正强相关或不相 关都是不科学的;统计学表明二者负相关,且相关 程度与戈的取值有关,在此基础之上建立的线性回 归结果不确定度M(戈。。。)公式才更为科学的。
(薏)u(。)×(嘉)M(6)>o,所以式(12)的数值>式
(14)的数值,又显然式(14)的数值>式(7)的数 值,所以,在戈≥0的条件下,可以得到不确定度数值 大小:方法Ⅱ>方法Ⅲ>方法I。 3.2变化趋势的差异 根据方法I对应的式(7),菇。捌越接近校准曲线 中点i时,Ⅱ(石。。。)越小;当被测样品的浓度越偏离 校准曲线中点时,由线性回归得到的样品浓度值的 不确定度将增大,如图1所示。这与实践经验相吻 合,为了提高测量准确性,需要对样品进行稀释或 浓缩,或根据目标浓度重新制定校准曲线,使得被 测样尽量落在校准曲线的中部。 相比之下,方法Ⅱ对应的式(12)和方法Ⅲ对应 的式(14),当x。捌>0时,戈,酬越接近于0,u(戈删)越 小,如图l所示。
(4) 利用统计方法经数学推导可得,回归方程的斜 率6和截距n的不确定度为m2,13]:
再嘻互孕㈣,
一般认为,),残差的标准差s,是u(y)的重要组 成部分。因为本文只讨论线性回归引人的不确定 度,所以,可认为“(y)=s,;如果测量结果取p次观 测值的平均值作为菇删时㈨,则可认为
啪)剐,去
厂丁——歹
重点。
・63・
其中n和6分别为校准曲线的截距和斜率,其 值可通过各校准点(石i,),;)由最小二乘法获得。如 果校准曲线共有n个溶液,每个溶液测量1次,若设
万方数据
2线性回归结果不确定度的几种评定方法
回归曲线的标准差(也称为,,残差的标准差) s。为‘l'2]: 得到:
÷×H(口)】2
(9)
如果将式(5)和式(6)代人式(9),则可以
c戈,=(雾)‘“2 cy,+(薏)‘M2 cⅡ,+(嘉)‘Ⅱ2 c6,+ 2×r(小)×(薏)u㈤×㈢M(6)
=[寺州y)]2+[一铲×u(6)-
・64・
万方数据
■豳冒重豳圜盈■
3.1数值大小的差异 由于方法Ⅱ认为r(口,6)=1,2×r(口,6)× 差var(o)、var(6)以及它们的协方差covar(口,6)是 由最小二乘法获得,戈的方差var(z)通过式(8)展开 得到"j:
10:
和方法Ⅱ一样,对式(8)展开,但是认为口和6 不相关,即r(口,6)=O,得到¨’61:
M2(髫)=(考)‘u2(y)+(耋)‘M2(口)+(嘉)‘M2(6)
(13)
2006)》¨o为例,其第五章给出了多个涉及线性回归 不确定度的评定案例,就可归纳出三种评定方法。
2.1
结合式(5)、式(6)和式(11),式(13)可进一步
covar(口,6)=一}・s; L“
(16)
如果对数据以及var(y。。。)是基于s,的p次测 量(式(12)),则式(15)变为:
V吣删,=吾睁忐+与≠】(17,
由于“(戈pfed)=√var(z,州),所以式(17)等同
于式(7)。因此,式(7)也是通过对式(8)利用传统 的不确定度分析方法展开后得到的,只是根据统计 学结论,口和6相关,但r(o,6)并不简单的取1或 0。根据式(7)和式(9)(前部分)推导得到:
r(o,6)=一亡
√石‘
(18)
图l
三种方法中线性回归结果不确定度变化趋势
K
为了判断r(口,6)值的大小,令K=戈2一孑,则
4几种评定方法分歧的根源
对于存在几种线性回归不确定度评定方法的 原因,文献[12]认为,这是由于应用者简单的对标 准不确定度分量进行了合成,而未考虑其相关性, 如斜率6与(戈,),)值有关,测量标准溶液和实际样 品时使用同一台测量仪器等。该观点过于简单,并 未能真正揭示几种方法区别的根源。 《指南》附录E旧。中给出了式(7)的简单推导步 骤,但是,由于使用了大量统计学公式和方法,推导 过程深奥,且省略了若干重要的统计学公式,对于 未专业学过统计学的化学分析和计量工作者来说, 较难理解。不过,我们发现正是这个推导过程,可 以揭示三种方法分歧的根源。 根据《指南》附录E,假设n和6的值,它们的方
㈣
“(y):芒
~p
(11)
则式(10)可进一步简化为:
一,√;再五+瓦
(6)
咄一鲁乒+电乎m,
2.3方法Ⅲ
其中式(4)~式(6)是基于统计学得到的结果, 为大部分参考文献¨‘12 3所认同和引用。但对于线 性回归引人的被测样石删的不确定度的评定方法 上,不同参考文献产生了分歧,以《材料理化检验测 量不确定度评估指南及实例(CNAS.GL
础删,=詈√古+杰+%}㈩
其中,p为被测样测量次数。
2.2方法Ⅱ
根据式(1)可得
戈=2亍(或铀=竿)
,)
…
D
(8)
进行讨论。本文将重点讨论方法I~方法Ⅲ的