EViews应用基础之怎样使用序列
EViews应用基础之怎样使用序列
EViews应用基础之怎样使用序列表达式的主要功能之一是根据已有的序列生成新序列和修改原有序列的值。
将表达式与样本结合起来使用,运用表达式对数据进行进行一些巧妙的数据变换,并将结果保存为新序列或将结果保存到已经存在的序列中。
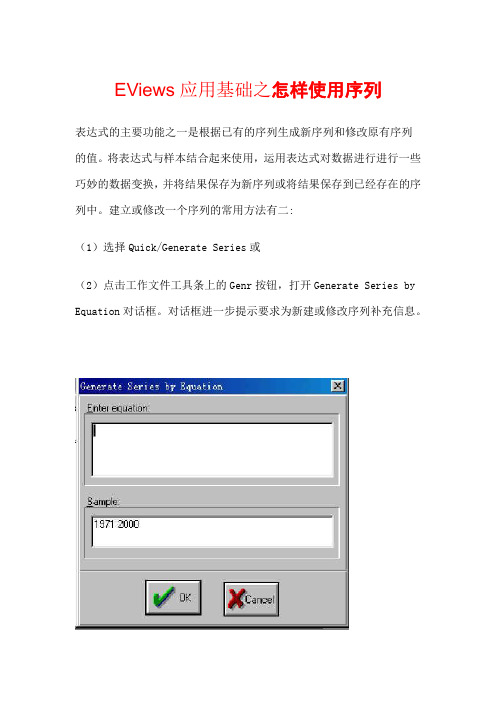
建立或修改一个序列的常用方法有二:(1)选择Quick/Generate Series或(2)点击工作文件工具条上的Genr按钮,打开Generate Series by Equation对话框。
对话框进一步提示要求为新建或修改序列补充信息。
在上面的编辑框中键入赋值语句,在下面的编辑行中键入相关的样本区间。
赋值语句实际上缺省执行的范围是整个样本区间,EViews从第一样本观察值开始,对每一个包含在样本区间中的观察值进行赋值语句的计算。
设定赋值语句的方法有几种方法。
一、基本的赋值语句(Basic Assignment)赋值语句的格式:序列名=表达式对样本中的每一个元素,EViews先计算等式右边表达式,并将计算结果赋给等式左边的的目标序列。
若目标序列名是一个新序列名,赋值语句根据要求就新建一个序列。
例如工作文件中没有名为Y的序列,执行赋值语句就建立了一个名为Y的新序列。
y = 2*x + 37*z过程是这样的,首先创建一个由NA值填充的序列,接着对当前样本的每一个观察值,用表达式的值填充。
如果Y序列已经存在,Eviews将在当前样本区间中用表达式的值替换Y原有的观察值。
注意:所有不包括在样本区间中的观察值将不会被改变。
赋值语句的一种特殊形式乃是右边表达式由一个固定的常数构成:y = 3y = 37 * 2 + 3EViews只是在样本的整个区间中依次循环一次,并将这个常数值赋给每一个观察值。
二、样本的使用(Using Samples)在Generate Series by Equation窗口,通过在赋值语句中修改观察值的样本范围,用户可以将多个GENR语句结合在一起。
例如,我们在不同的样本区间中键入三个GENR命令。
时间序列 eviews操作

1.打开EVIEWS新建一个工作文件,步骤如下:
出现如下对话框,选择数据频率为季度,开始日期为1989年1季度,结束日期为2004年4季度,即为工作文件的范围区间。
点击ok生成工作文件
2.若要改变工作文件的范围区间,双击Range,出现如下对话框
3.利用命令series 生成时间序列gdp
点击Edit+/-改变数据的编辑状态,打开EXCEL文件将数据复制粘贴到数据区域,查看数据序列的折线图,步骤如下:
结果:
从图中可看出时间序列有明显的季节波动。
4.对gdp序列进行描述统计分析:
5.对原GDP数据进行季节调整,调整后时间序列存为GDP_SA
6.做出折线图:
由图知序列受季节影响程度变小。
7.进行单位根检验,结果如下:
计算自相关函数和偏相关函数如下:
9.利用方程建立ARMA(3,3)模型
10.建立组,包括gdp gdp_sa dgdp
建组后展示如下:
11.将建组后的收据以EXCEL格式输出:
点击ok即可。
Eviews序列的操作

序列的操作2.创建数组(group)多个序列组合而成,以便对组中的所有变量同时执行某项操作。
数组和各个序列之间是一种链接关系,修改序列的数据、更改序列名、删除序列等操作,都会在数组中产生相应的变化。
1)创建完文件后,使用data建立数据组变量;若有word表格数据或excel数据,直接粘贴;或者用Import 从其它已有文件中直接导入数据。
data x y,…可以同时建立几个变量序列,变量值按列排列,同时在表单上出现新建的组及序列,且可以随时在组中添加新的序列。
利用组的优点:一旦某个序列的数据发生变化,会在组中和变量中同时更新;数组窗口可以直接关闭,因为工作文件中已保留了有关变量的数据。
2)通过已有序列建立一个需要的组:group mygroup x y可以在组中直接加入滞后变量group mygroup y x(0 to -1)3.创建标量:常数值scalar val = 10 show val 则在左下角显示该标量的值6.向量列向量对象vector、行向量对象rowvector、系数向量对象coeffvector vect:定义了一个一维且取值为0 的列向量vector(n) vect:定义一个n维且取值为0的列向量vect.fill 1, 3, 5, 7, 9 :定义了分量的值vector(n) vect=100:定义一个n维且取值为100的列向量行向量对象rowvector、系数向量对象coeff 类似4.创建变量序列series xseries ydata x yseries z = x + yseries fit = Eq1.@coef(1) + Eq1.@coef(2) * x利用两个回归系数构造了拟合值序列4)排序:在workfile窗口,执行主菜单上的procs/sort series,可选择升序或降序:Sort x:则y随之移动,即不破坏对应关系。
sort(d) x:按降序排序,注意所有的其它变量值都会随之相应移动。
如何用eviews分析时间序列课程

如何用eviews分析时间序列课程时间序列分析是一种常用的数据分析方法,通过对一系列时间上连续测量的数据进行观察、描述和分析,可以发现其中的规律和趋势,从而预测未来的发展走势。
Eviews是一种专业的时间序列分析软件,具有强大的数据处理和统计分析功能。
本文将介绍如何使用Eviews进行时间序列分析。
首先,打开Eviews软件,并导入需要分析的时间序列数据。
在Eviews的工作区中,选择“File”菜单下的“Open”选项,然后选择需要导入的数据文件,点击“Open”按钮导入数据。
导入数据后,可以在Eviews的对象浏览器中看到导入的数据对象。
接下来,对时间序列数据进行初步的观察和描述分析。
在对象浏览器中,选择需要分析的数据对象,右键点击并选择“Open as Group”选项,将数据对象打开为一个分析组。
然后,在Eviews的对象浏览器中,选择分析组,在右侧窗口中可以看到该组中包含的所有时间序列数据。
可以通过列出每个时间序列的统计概要、绘制时间序列图、查看自相关和偏自相关等方式对数据进行初步的观察和描述分析。
接下来,进行时间序列模型的构建和估计。
在Eviews的操作菜单中,选择“Quick”菜单下的“Estimate Equation”选项,打开方程估计窗口。
在方程估计窗口中,选择需要构建的时间序列模型类型,如AR、MA、ARMA等。
然后,在“Dependent Variable”栏目中选择需要分析的时间序列数据,将其作为因变量。
在“Independent Variables”栏目中选择需要作为自变量的时间序列数据,可以根据需求选择多个自变量。
点击“OK”按钮,Eviews将根据所选择的时间序列模型类型和数据进行模型的估计。
估计完成后,可以查看估计结果。
在方程估计窗口中,可以看到估计结果的统计指标、系数估计值、显著性水平等信息。
可以根据需要查看和分析各个系数的显著性水平、置信区间等信息,判断模型的有效性和可靠性。
Eviews操作教程_完整版

Eviews操作教程_完整版1.EVIEWS基础 (3)1.1. E VIEWS简介 (3)1.2. E VIEWS的启动、主界⾯和退出 (3)1.3. E VIEWS的操作⽅式 (6)1.4. E VIEWS应⽤⼊门 (6)1.5. E VIEWS常⽤的数据操作 (15)2.⼀元线性回归模型 (24)2.1. ⽤普通最⼩⼆乘估计法建⽴⼀元线性回归模型 (24) 2.2. 模型的预测 (30)2.3. 结构稳定性的C HOW检验 (34)3. 多元线性回归 (39)3.1. ⽤OLS建⽴多元线性回归模型 (39)3.2. 函数形式误设的RESET检验 (45)4. ⾮线性回归 (48)4.1. ⽤直接代换法对含有幂函数的⾮线性模型的估计 (48) 4.2. ⽤间接代换法对含有对数函数的⾮线性模型的估计 (50) 4.3. ⽤间接代换法对CD函数的⾮线性模型的估计 (53)4.4. NLS对可线性化的⾮线性模型的估计 (55)4.5. NLS对不可线性化的⾮线性模型的估计 (58)4.6. ⼆元选择模型 (62)5. 异⽅差 (68)5.1. 异⽅差的⼽得菲尔德——匡特检验 (68)5.2. 异⽅差的WHITE检验 (72)5.3. 异⽅差的处理 (75)6. ⾃相关 (79)6.1. ⾃相关的判别 (79)6.2. ⾃相关的修正 (83)7. 多重共线性 (87)7.1. 多重共线性的检验 (87)7.2. 多重共线性的处理 (92)8. 虚拟变量 (94)8.1. 虚拟⾃变量的应⽤ (94)8.2. 虚拟变量的交互作⽤ (99)8.3. ⼆值因变量:线性概率模型 (101)9. 滞后变量模型 (106)9.1. ⾃回归分布滞后模型的估计 (106)9.2. 多项式分布滞后模型的参数估计 (111)10. 联⽴⽅程模型 (116)10.1. 联⽴⽅程模型的单⽅程估计⽅法 (116)10.2. 联⽴⽅程模型的系统估计⽅法 (120)2..1.Eviews基础1.1.Eviews简介Eviews:Econometric Views(经济计量视图),是美国QMS公司(Quantitative Micro Software Co.,⽹址为/doc/8e38170bbed126fff705cc1755270722192e59b1.html )开发的运⾏于Windows环境下的经济计量分析软件。
时间序列的eview操作步骤

时间序列的eview操作步骤1.打开eviews软件,点击file-new-workfile,见对话框又三块空白处,选择时间序列dated-regular frequency。
在date specification中选择monthly,start(起始时间)输入2005M11,end(终止时间)输入2008M6(eviews的时间序列没有间隔序列输入就将时间进行调整)。
右下角为工作间取名字tmd。
点击ok。
在所创建的workfile中点击object-new object,选择series,以及填写名字tmd,点击OK。
将数据填写入内就生成了以tmd为名的数据集2. 点击view-United root test,test type选择ADF检验,滞后阶数中lag length 选择SIC检验,点击ok得结果如下:一阶差分:点击GENR命令按钮,在输入框中输入bod1=D(bod),得到一阶差分后的结果:再对一阶差分后的数据同样进行平稳性检验(单根值检验)ADF序列零均值化①在命令窗口输入如下命令(如下图所示):Scalar m=@mean(tmd)其中:Scalar命令在Eviews中表示生成标量数据(均值只是一个数,而不是序列)。
在tmd窗口下选择菜单操作方式:单击Genr在对话框中输入BOD1=BOD-m得到零均值后的新序列tmd1与之前的数据完全不同。
3. 在工作区双击序列图标tmd1,再选用菜单操作方式:View—>Correlogram,在出现的对话框点击OK。
4.估计模型中的未知参数识别透明度这组时间序列适合的模型后,需要进一步的估计模型中的具体参数,下面就用eviews软件进行估计。
由前面的图形看出:自相关系数和偏相关系数具有相似的衰减特点:衰减快,偏相关图中,2阶以后函数值趋于0,呈截尾性选AR(2);而在自相关图中,在4阶以后函数值趋于0,呈拖尾性,因此可将q取3故可选MA(3)模型。
EViews 基础(
实验一EViews 基础【实验目的】掌握数据处理的基本操作,能根据需要绘制图表【实验内容】一、数据处理基础;(1)序列对象的基本操作:创建、编辑序列对象,数据的输入输出等;(2)方程对象的组建和设定。
二、绘制图表。
(1)创建图对象、表对象;(2)复制图对象、表对象至其他的Windows程序。
【实验步骤】一、数据处理基础1、启动EViews软件:进入Windows/双击Eviews快捷方式,进入EViews窗口,或点击开始/程序/Econometrics Views,进入EViews窗口。
2、序列对象的基本操作(1)创建序列对象:①在主菜单上点击Objects/New Object,在弹出的“New Object”对话框中的“Type of object”一栏中选中“Series”;在“Name for object”文本框中给序列命名。
②点击工作文件窗口工具栏中的Genr,再在弹出的“Generate Series by Equation”对话框中输入一个表达式(如y=3*x),便可在已有序列的基础上生成一个新序列。
(2)编辑序列对象:双击序列名称或点击工作文件窗口工具栏中的Show可以显示序列数据,然后点击学列窗口工具栏中的“Edit+/-”,可切换为编辑状态。
(3)数据的输入:①键盘输入。
建立一个新序列后,利用“Edit+/-”切换到可编辑状态下,便可通过键盘输入数据。
②粘贴输入。
通过主菜单中的Edit/Copy和Edit/Paste可以复制粘贴数据,注意粘贴数据的时间区间要和表单中的时间区间保持一致。
③文件输入。
依次单击主菜单中File/Import/Read Text-Lotus-Excel,或点击工作文件窗口中的Proces,然后再弹出的快捷菜单中依次点击Import/Read Text-Lotus-Excel,将弹出Open对话框:以EXCEL 文件为例,在对话框中找到需要导入的Excel文件,单击“打开”按钮后会出现“Excel Spreadsheet Import”对话框,该对话框中有五个分组框:a. Data order(数据的排列方式):若选择“By Observation-series in columns”,则EViews将每一列视为一个序列;若选择“By Series-series in rows”,则将每一行视为一个序列。
第一讲Eviews的基本操作
Eviews的基本操作一、工作文件及建立1、主窗口介绍2、工作文件的创建3、工作文件窗口简介4、工作文件的存储与调用5、工作文件时间范围的调整二、序列对象的基本操作1、对象的类型2、序列的创建于打开3、序列数据的录入、调用与编辑三、数据分析的常用操作1、表达式2、新序列的建立3、群4、图像四、序列的描述统计分析练习:1、案例:研究我国城镇和农村居民消费与可支配收入的关系Cu=城镇居民人均消费支出(元)Yu=城镇居民人均可支配收入(元)Pu=城镇居民消费价格指数(1985年的指数为100)Cr=农村居民人均消费支出(元)Yr=农村居民人均可支配收入(元)Pr=农村居民消费价格指数(1985年的指数为100)CT=全国居民人均消费水平(元)Rpop=农村人口比例(%)P=全国居民消费价格指数(1985年的指数为100)建立crp (*100cr pr =)与yrp (*100yr pr =)的散点图,并用连线把各数据点连接起来。
估计方程ˆi crp =0ˆβ+1ˆβiyrp2、下表是1950—1987年间美国机动车汽油消费量和影响消费量的变量数值。
各变量表示:QMG —机动车汽油消费量,CAR —汽车保有量,PMG —汽油价格,POP —人口数,RGNP —按1982年美元计算的国民生产总值,PGNP —GNP 指数(1982年为100)。
以汽油消费量为因变量,其他为自变量,建立回归模型。
(1)建立工作文件,产生序列,录入数据。
(2)变量间关系分析,计算相关系数矩阵(3)绘制因变量与各自变量的散点图(4)建立模型(5)如果1988年,CAR=187921035 ,PMG=0.913 ,POP=252917,RGNP=3883,PGNP=120.3,预测88年的汽油消费量。
eviews使用指南与案例
eviews使用指南与案例EViews是一款经济统计软件,广泛应用于经济学、金融学等领域的数据分析和建模工作。
本文将为大家介绍EViews的使用指南和一些实际案例,帮助读者更好地了解和应用EViews。
一、EViews的使用指南1. EViews的安装和启动:首先,用户需要下载并安装EViews软件。
安装完成后,双击桌面上的EViews图标即可启动软件。
2. 数据导入和处理:EViews支持导入多种数据格式,如Excel、CSV等。
用户可以使用“File”菜单中的“Import”选项将数据导入EViews中,并进行必要的数据清洗和处理。
3. 数据探索和描述统计分析:在导入数据后,用户可以使用EViews提供的数据探索功能进行数据分析,包括数据的描述统计分析、数据可视化等。
4. 模型建立和估计:EViews提供了多种经济学模型的建立和估计方法,如回归分析、时间序列分析等。
用户可以通过选择相应的命令和参数来进行模型建立和估计。
5. 模型诊断和检验:在模型建立和估计完成后,用户需要对模型进行诊断和检验。
EViews提供了多种模型诊断和检验的功能,如残差分析、异方差性检验等。
6. 模型预测和模拟:EViews可以基于已建立的模型进行预测和模拟。
用户可以输入新的自变量数据,通过模型预测因变量的值,或者进行模型的蒙特卡洛模拟分析。
7. 结果输出和报告生成:EViews可以将分析结果以表格、图形等形式输出,并支持生成报告和文档。
用户可以选择相应的输出选项和格式,方便结果的展示和分享。
二、EViews的应用案例1. 时间序列分析:使用EViews可以进行时间序列数据的建模和分析。
例如,可以通过ARIMA模型对股票价格进行预测,或者通过VAR模型分析宏观经济变量之间的关系。
2. 经济政策评估:EViews可以用于评估不同经济政策对经济变量的影响。
例如,可以建立一个VAR模型,通过冲击响应分析来评估货币政策对通胀和经济增长的影响。
EViews软件教程:0板书要点第2讲-产生新序列、回归估计命令:吴庆军2015年秋季
经济计量学软件包Eviews的使用★创建新的工作文件⒈菜单方式:File/New/Workfile/⒉命令方式:CREATE时间频率类型起始期终止期例如:CREATE A 1985 1998 再如:create a 85 98 命令方式: Workfile test1可以建立名为test1的工作文件。
★建立新序列1、命令方式:DATA <序列名1> <序列名2>…<序列名n>例:DATA Y X 或DATA Y L K2、菜单方式:主窗口或工作文件窗口Objects/New Object,对象类型选择Series,给定序列名,一次只能创建一个新序列。
注:在建立对象之前必须打开工作文件而且工作文件窗口必须是激活的。
选择“Objects/New Object”在“Type of Object”中选择对象类型。
★从已经存在的序列中派生出一个新的序列,⒈菜单方式:主菜单Objects/Generate Series,键入表达式,形成新序列。
⒉命令方式:Genr 序列的名字=已存在序列函数表达式例:GENR LOGX=LOG(X)注:生成log(X)序列GENR X1=X^2 注:生成X^2序列GENR X2=1/X 注:生成1/X序列GENR T=@TREND(84)注:生成时间变量T等序列★输入数据1.键盘输入在主菜单下,选择Quick/Empty Group(Edit Serirs)打开一个新序列后,在编辑状态下,通过键盘输入数据,并给定一个序列名。
2.粘贴输入通过主菜单中的Edit/Copy和Edit/Paste功能复制—粘贴数据,注意粘贴数据的时间区间要和表单中的时间区间一致。
3.文件输入可以从其它程序建立的数据文件直接输入数据。
点击主菜单中的File/Import /Read Text—Lotus—Excel或工作文件菜单中的Procs/Import/Read Text—Lotus—Excel,可以在WINDOWS子目录中找到你的文本文件或Excel(.XLS) 文件,点击后在出现的对话框中回答序列名,点击OK即可形成新序列,注意原数据文件的时间区间。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
EViews应用基础之怎样使用序列
表达式的主要功能之一是根据已有的序列生成新序列和修改原有序列
的值。
将表达式与样本结合起来使用,运用表达式对数据进行进行一些巧妙的数据变换,并将结果保存为新序列或将结果保存到已经存在的序列中。
建立或修改一个序列的常用方法有二:
(1)选择Quick/Generate Series或
(2)点击工作文件工具条上的Genr按钮,打开Generate Series by Equation对话框。
对话框进一步提示要求为新建或修改序列补充信息。
在上面的编辑框中键入赋值语句,在下面的编辑行中键入相关的样本区间。
赋值语句实际上缺省执行的范围是整个样本区间,EViews从第一样本观察值开始,对每一个包含在样本区间中的观察值进行赋值语句的计算。
设定赋值语句的方法有几种方法。
一、基本的赋值语句(Basic Assignment)
赋值语句的格式:
序列名=表达式
对样本中的每一个元素,EViews先计算等式右边表达式,并将计算结果赋给等式左边的的目标序列。
若目标序列名是一个新序列名,赋值语句根据要求就新建一个序列。
例如工作文件中没有名为Y的序列,执行赋值语句就建立了一个名为Y的新序列。
y = 2*x + 37*z
过程是这样的,首先创建一个由NA值填充的序列,接着对当前样本的每一个观察值,用表达式的值填充。
如果Y序列已经存在,Eviews将在当前样本区间中用表达式的值替换Y原有的观察值。
注意:所有不包括在样本区间中的观察值将不会被改变。
赋值语句的一种特殊形式乃是右边表达式由一个固定的常数构成:
y = 3
y = 37 * 2 + 3
EViews只是在样本的整个区间中依次循环一次,并将这个常数值赋给每一个观察值。
二、样本的使用(Using Samples)
在Generate Series by Equation窗口,通过在赋值语句中修改观察值的样本范围,用户可以将多个GENR语句结合在一起。
例如,我们在不同的样本区间中键入三个GENR命令。
第一个
Upper window: y = z
Lower window: @all if z<=1 and z>-1
在第二个GENR语句中
Upper window: y = -2 + 3*z
Lower window: @all if z>1
第三个GENR语句中
Upper window: y = -.9 + .1*z
Lower window: @all if z<=-1
这样就将Y生成为对于Z的分段线性函数。
注意,在循环语句和IF分支语句中使用这种类型的操作是也是可行的。
只要有可能,建议在循环语句和IF分支语句中尽可能地使用GENR语句和样本陈述语句,因为这种结合使用的方法更有效。
三、动态赋值(Dynamic Assignment)
因为Eviews利用表达式进行赋值时,要对样本区间中的每一个观察值计算赋值表达式,所以可以将等式右端目标序列的滞后值置于赋值语句中进行动态赋值。
例如,我们正在处理1945年到1997年的年度数据的工作文件。
如果在序列生成对话框中键入:
Upper window: y = y + y(-1)
Lower window: 1946 1997
EViews将用Y的累计和去替换原来的Y,因为我们并没有要求对工作文件的第1个观察值(1945年)执行变换。
对1945年以后的各期的Y,用Y的当前值加上Y的滞后一期的值,并将计算结果再赋给Y。
这个赋值语句是动态的,因为当其连续地移动到下一个时期时,Y的滞后值包含的是所有前期各个Y值的累计和。
注意,这个过程将破坏原始序列中的数据。
所以,创建生成累计和新序列是分两步执行赋值语句的,首先复制原始序列,然后再执行动态赋值语句。
四、隐含赋值(mplicit Assignment)
在赋值语句等号的左端放置一个简单的公式,EViews将检查左端表达式,确定第1个有效序列名为目标序列,即赋值语句等号左端的第1个有效序列。
然后对样本中的每一个观察值通过隐含关系进行赋值。
例如,我们键入下列表达式:
log(y) = x
EViews将Y作为目标序列,然后在样本区间内,Y的每一个观察值按
y=exp(x)关系进行赋值。
下面都是有效赋值语句的例子,其中Y是目标序列:
1/y = z
log(y/x)/14.14 = z
log(@inv(y)*x) = z
2+y+3*z = 4*w
d(y) = nrnd
一般说来,EViews能够对在等号左端使用下列符号:
+, - ,*, /, ^, log(), exp(), sqr(), d(), dlog(), @inv()的方程进行求解或正则化的。
但是,Genr并不是全面的方程求解器,存在EViews不能正则化方程的可能。
例如,不能使用这样的赋值语句,
@tdist(y, 3) = x
由于@tdist()不是一EViews所能求解的方程,所以不能对Y进行潜在的赋值。
类似的,EViews也不能求解目标序列在等号左端不只出现一次的方程。
例如,EViews就不能求解下列方程:
x + 1/x = 5
在上述两种情况下,EViews将显示出不能正则化方程的错误信息。
注意,目标序列还有可能出现在等式的两端,例如
log(x) = x
就是一个合法的赋值语句,EViews将正则化这个表达式,并执行
x = exp(x)
进行赋值。
所以X将被赋给原X的指数值。
但是,EViews在这里并不是求解出满足等式log(x) = x的X的值。
五、命令窗口赋值(Command Window Assignment)可从命令窗口创建序列并给它赋值。
首先,使用smpl语句设定样本范围,再使用赋值语句。
赋值语句有两种对应的形式。
第一,如果序列并
不存在,必须既使用序列也使用关键字GENR,紧接着一个赋值表达式。
下面两个语句对于生成序列Y是等价的,
series y = exp(x)
genr y = exp(x)
一旦一个序列已经创建,在其后的赋值语句中就不需要关键字:
smpl @all
series y = exp(x)
smpl 1950 1990 if y>300
y = y/2
六、例题(Examples)
下面的例题展示一些与生成序列相关的常用任务是怎样执行的:
时间趋势time(在1987:1取0值)
series time = @trend(1987:1)
价格指数index(在1985:6取1)
series index = price/@elem(price, 1985:6)
虚拟变量(Dummy variables)
series high_inc = income>12000
右端条件成立,给赋1;否则,赋0。
使用逻辑表达式进行在编码
series newser = x*(y>30) + z*(y<=30)。