贾俊平 统计学 第9章 一元线性回归
第9章多元线性回归-PPT精品文档

统计学
STATISTICS (第三版)
学习目标
多元线性回归模型、回归方程与估计的回 归方程 回归方程的拟合优度与显著性检验 多重共线性问题及其处理 利用回归方程进行预测 虚拟自变量的回归 用Excel和SPSS进行回归分析
统 计 学
(第三版)
2019
作者 贾俊平
统计学
STATISTICS (第三版)
统计名言
上好的模型选择可遵循一个称为奥 克姆剃刀(Occam’s Razor)的基本原 理:最好的科学模型往往最简单, 且能解释所观察到的事实。
——William Navidi
9-2 2019年8月
第 9 章 多元线性回归
b1,b假定其他变量不变,当 xi 每变 动一个单位时,y 的平均变动值
9 - 10
2019年8月
统计学
STATISTICS (第三版)
估计的多元线性回归的方程
(estimated multiple linear regression equation)
9 - 11 2019年8月
9.1 多元线性回归模型 9.1.2 参数的最小二乘估计
统计学
STATISTICS (第三版)
参数的最小二乘估计
1. 使因变量的观察值与估计值之间的离差平方和 ˆ ,b ˆ ,b ˆ ,, b ˆ 。即 达到最小来求得 b 0 1 2 k
2 2 ˆ ,b ˆ ,b ˆ ,, b ˆ ) (y y ˆ Q( b ) e i i i 最小 0 1 2 k i 1 i 1 n n
统计学第四版贾俊平人大-回归与时间序列stata

回归分析与时间序列一、一元线性回归11。
1 (1)编辑数据集,命名为linehuigui1.dat输入命令scatter cost product,xlabel(#10,grid) ylabel(#10,grid),得到如下散点图,可以看到,产量和生产费用是正线性相关的关系。
(2)输入命令regcost product,得到如下图:可得线性函数(product为自变量,cost为因变量):y=0。
4206832x+124。
15,即β0=124。
15,β1=0。
4206832(3)对相关系数的显著性进行检验,可输入命令pwcorr cost product,sig star (.05) print(。
05),得到下图:可见,在α=0。
05的显著性水平下,P=0。
0000<α=0。
05,故拒绝原假设,即产量和生产费用之间存在显著的正相关性。
11。
2 (1)编辑数据集,命名为linehuigui2。
dat输入命令scatterfenshu time,xlabel(#4, grid) ylabel(#4,grid),得到如下散点图,可以看到,分数和复习时间是正线性相关的关系。
2)输入命令cor fenshu time计算相关系数,得下图:可见,r=0.8621,可见分数和复习时间之间存在高度的正相关性。
11.3 (1)(2)对于线性回归方程y=10-0。
5x,其中β0=10,表示回归直线的截距为10;β1=—0.5,表示x变化一单位引起y的变化为—0.5。
(3)x=6时,E(y)=10-0.5*6=7.11.4(1)R2=SSRSST =SSRSSR+SSE=3636+4=0.9,判定系数R2测度了回归直线对观测数据的拟合程度,即在分数的变差中,有90%可以由分数与复习时间之间的线性关系解释,或者说,在分数取值的变动中,有90%由复习时间决定。
可见,两者之间有很强的线性关系.(2)估计标准误差S e=√SSEn−2=√418−2=0.25分,即根据复习时间来估计分数时,平均的估计误差为0.25分.11.5 (1)编辑数据集,命名为linehuigui3。
贾俊平《统计学》配套题库 【课后习题】详解 第9章~第10章【圣才出品】
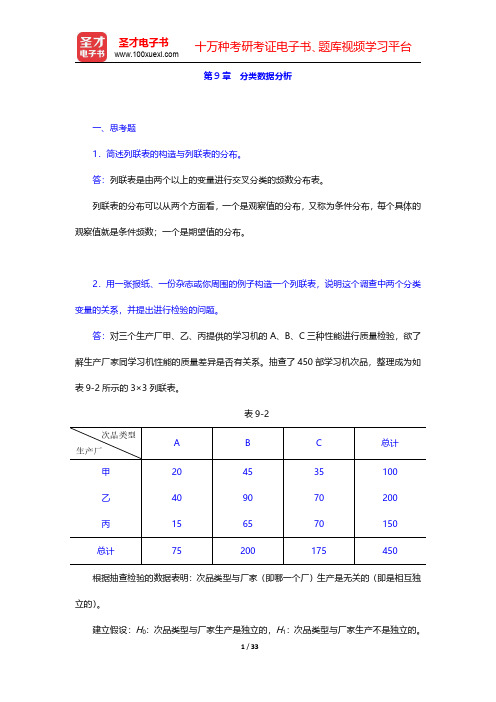
第9章分类数据分析一、思考题1.简述列联表的构造与列联表的分布。
答:列联表是由两个以上的变量进行交叉分类的频数分布表。
列联表的分布可以从两个方面看,一个是观察值的分布,又称为条件分布,每个具体的观察值就是条件频数;一个是期望值的分布。
2.用一张报纸、一份杂志或你周围的例子构造一个列联表,说明这个调查中两个分类变量的关系,并提出进行检验的问题。
答:对三个生产厂甲、乙、丙提供的学习机的A、B、C 三种性能进行质量检验,欲了解生产厂家同学习机性能的质量差异是否有关系。
抽查了450部学习机次品,整理成为如表9-2所示的3×3列联表。
表9-2A B C 总计甲乙丙204015459065357070100200150总计75200175450根据抽查检验的数据表明:次品类型与厂家(即哪一个厂)生产是无关的(即是相互独立的)。
建立假设:H 0:次品类型与厂家生产是独立的,H 1:次品类型与厂家生产不是独立的。
次品类型生产厂可以计算各组的期望值,如表9-3所示(表中括号内的数值为期望值)。
表9-3各组的期望值计算表A B C 总计甲乙丙20(17)40(33)15(25)45(44)90(89)65(67)35(39)70(78)70(58)100200150总计75200175450所以2222(2017)(4033)(7058)9.821173358χ---=+++=…。
而自由度等于(R -1)(C -1)=(3-1)×(3-1)=4,若以0.01的显著性水平进行检验,查χ2分布表得20.01(4)13.277χ=。
由于220.019.821(4)13.277χχ=<=,故接受原假设H 0,即次品类型与厂家生产是独立的。
3.说明计算2χ统计量的步骤。
答:计算2χ统计量的步骤:(1)用观察值o f 减去期望值e f ;(2)将(o f -e f )之差平方;(3)将平方结果2)(e o f f -除以e f ;(4)将步骤(3)的结果加总,即得:22()o e ef f f χ-=∑。
贾俊平《统计学》(第5版)课后习题-第9章 分类数据分析【圣才出品】

第9章 分类数据分析一、思考题1.简述列联表的构造与列联表的分布。
答:列联表是由两个以上的变量进行交叉分类的频数分布表。
列联表的分布可以从两个方面看,一个是观察值的分布,又称为条件分布,每个具体的观察值就是条件频数;一个是期望值的分布。
2.用一张报纸、一份杂志或你周围的例子构造一个列联表,说明这个调查中两个分类变量的关系,并提出进行检验的问题。
答:对三个生产厂甲、乙、丙提供的学习机的A、B、C三种性能进行质量检验,欲了解生产厂家同学习机性能的质量差异是否有关系。
抽查了450部学习机次品,整理成为如表9-2所示的3×3列联表。
表9-2根据抽查检验的数据表明:次品类型与厂家(即哪一个厂)生产是无关的(即是相互独立的)。
建立假设:H0:次品类型与厂家生产是独立的,H1:次品类型与厂家生产不是独立的。
可以计算各组的期望值,如表9-3所示(表中括号内的数值为期望值)。
表9-3 各组的期望值计算表所以2222(2017)(4033)(7058)9.821173358χ---=+++=…。
而自由度等于(R -1)(C -1)=(3-1)×(3-1)=4,若以0.01的显著性水平进行检验,查χ2分布表得20.01(4)13.277χ=。
由于220.019.821(4)13.277χχ=<=,故接受原假设H 0,即次品类型与厂家生产是独立的。
3.说明计算2χ统计量的步骤。
答:计算2χ统计量的步骤:(1)用观察值o f 减去期望值e f ;(2)将(o f -e f )之差平方;(3)将平方结果2)(e o f f -除以e f ;(4)将步骤(3)的结果加总,即得:22()o e ef f f χ-=∑。
4.简述ϕ系数、c 系数、V 系数的各自特点。
答:(1)ϕ相关系数是描述2×2列联表数据相关程度最常用的一种相关系数。
它的计算公式为:ϕ,式中,∑-=ee of f f 22)(χ;n 为列联表中的总频数,也即样本量。
贾俊平《统计学》(第五版)考研真题(含复试)与典型习题详解 分类数据分析

合计
赞成
35
30
65
反对
15
20
35
合计
50
50
100
如果要检验男女教师对教师体制改革的看法是否相同,提出的原假设为( )。
A.H0:π1=π2=35 B.H0:π1=π2=50 C.H0:π1=π2=65
6 / 19
圣才电子书
D.H0:π1=π2=0.65
十万种考研考证电子书、题库视频学习平台
156 162
圣才电子书
A.0.6176
十万种考研考证电子书、题库视频学习平台
B.1.2352
C.2.6176
D.3.2352
【答案】B
【解析】 2 检验可以用于变量间拟合优度检验和独立性检验,可以用于测定两个分类 变量之间的相关程度。用 fo 表示观察值频数,用 fe 表示期望值频数,则 2 统计量为:
圣才电子书
十万种考研考证电子书、题库视频学习平台
第 9 章 分类数据分析
一、单项选择题
1.列联分析是利用列联表来研究( )。
A.两个数值型变量的关系
B.两个分类变量的关系
C.两个数值型变量的分布
D.一个分类变量和一个数值型变量的关系
【答案】B
【解析】列联表是由两个以上的变量进行交叉分类的频数分布表,列联分析是利用列联
【解析】表中的行是态度变量,这里划分为三类,即赞成,中立和反对;表中的列是单 位变量,这里划分为两类,即男同学和女同学,即 3×2 列联表。
5.一所大学为了解男女学生对后勤服务质量的评价,分别抽取了 300 名男学生和 240
名女学生进行调查,得到的结果如表 9-2 所示。
表 9-2 关于后勤服务质量评价的调查结果
统计学第六版贾俊平

精品教材
统计学
拟合优度检验
(例题分析)
H0: 1= 2= 3= 4 H1: 1234 不全相等 = 0.1 df = (2-1)(4-1)= 3 临界值(s):
=0.1
0 3.0319 6.215 c2
9 - 27
统计量:
r
c2
c (fij eij)2 3.0319
i1 j1
eij
结论:
可以认为广告后各公司产品
0
5.99 8.18 c
市场占有率发生显著变化
9 - 29
精品教材
统计学
拟合优度检验
(例题分析—用P值检验)
第1步:将观察值输入一列,将期望值输入一列 第2步:选择“函数”选项 第3步:在函数分类中选“统计”,在函数名中选
“CHITEST”,点击“确定” 第4步:在对话框“Actual_range”输入观察数据区域
的百分比,称为百分比分布
行百分比:行的每一个观察频数除以相应的行 合计数(fij / ri)
列百分比:列的每一个观察频数除以相应的列 合计数( fij / cj )
总百分比:每一个观察值除以观察值的总个数( fij / n )
9 - 15
精品教材
统计学
百分比分布
(图示)
行百分比
列百分比
总百分比
0.3000
e
36 0.9730 3.0319
合计:3.0319
精品教材
统计学
拟合优度检验
9 - 24
精品教材
统计学
品质数据的假设检验
品质数据
比例检验
一个总体 两个以上总体
Z 检验 Z 检验 c 检验
贾俊平《统计学》复习笔记课后习题详解及典型题详解 第9章~第10章【圣才出品】
第9章分类数据分析9.1复习笔记一、分类数据与χ2统计量1.分类数据按照所采用的计量尺度不同,可以将统计数据分为分类数据、顺序数据和数值型数据。
分类数据和顺序数据都是只能归于某一类别的非数字型数据,它们是对事物进行分类的结果,其结果均表现为类别,用文字来表述,不过顺序数据的类别是有序的;数值型数据是按数字尺度测量的观测值,其结果表现为具体的数值。
分类数据是对事物进行分类的结果,其特征是,调查结果虽然用数值表示,但不同数值描述了调查对象的不同特征。
数值型数据可以转化为分类数据。
分类数据的结果是频数,χ2检验是对分类数据的频数进行分析的统计方法。
2.χ2统计量χ2统计量可以对分类数据做拟合优度检验和独立性检验,可以用于测定两个分类变量之间的相关程度。
若用f o 表示观察值频数,用f e 表示期望值频数,则χ2统计量可以写为:22()o e e f f f χ-=∑χ2检验:χ2检验是利用随机样本对总体分布与某种特定分布拟合程度的检验,也就是检验观察值与理论值之间的紧密程度。
χ2检验主要用于拟合优度检验和独立性检验。
(1)χ2统计量的特征①χ2≥0,因为它是对平方值结果的汇总;②χ2统计量的分布与自由度有关;③χ2统计量描述了观察值与期望值的接近程度。
两者越接近,即f o-f e的绝对值越小,计算出的χ2值越小;反之,f o-f e的绝对值越大,计算出的χ2值也越大。
χ2检验正是通过对χ2的计算结果与χ2分布中的临界值进行比较,做出是否拒绝原假设的统计决策。
(2)χ2分布与自由度的密切关系自由度越小,χ2的分布就越向左边倾斜;随着自由度的增加,χ2分布的偏斜程度趋于缓解,逐渐显露出对称性,随着自由度的继续增大,χ2分布将趋近于对称的正态分布。
(3)应用χ2检验统计量的注意事项①各组的理论频数f e不得小于总频数n;②总频数应较大,至少大于50;③如果某组理论频数小于5,可将相邻的若干组合并,直至理论频数大于5为止;④倘若有两个以上的单元,如果20%的单元期望频数f e小于5,则不能应用χ2检验。
应用统计学9-一元线性回归
一、 b1的抽样分布
b1是观测值Yi的线性组合 Yi服从正态分布且相互独立 均值 E(b1) = β1
n
b1也服从正态分布
方差
n
证明:D (b1 ) = ∑ D (CiYi ) = ∑ Ci2 D (Yi ) =
i =1 i =1
σ2
2 − X X ( ) ∑ i i =1 n
二、 F 检验
H0:β1=0 H1:β1≠0
三、一元线性回归模型
Yi = β0+ β1 Xi + εi
i=1 , 2 , ··· , n
(9-1)
其中: (X i , Yi )表示(X , Y )的第i个观测值, β0 , β1为参数, β0+β1Xi为反映统计关系直线的分量, εi为反映在统计关系直线周围散布的随机分量, εi~N (0,σ2)且相互独立。
残差平方和(SSE)
fE=n-2
反映除 x 以外的其他因素对 y 取值的影响,也称 为不可解释的平方和或剩余平方和
自由度分解公式 回归均方
fT=fR+fE MSE=SSE/n-2
MSR=SSR/1 误差均方
9.4 样本确定系数与样本相关系数
样本确定系数 r2
回归平方和占总离差平方和的比例
反映回归直线的拟合程度 取值范围在 [ 0 , 1 ] 之间, R2 →1,说明回归方 程的拟合程度越好,R2→0,说明回归方程的拟 合程度越差
例如,某种商品的销售额(y)与销售量(x) y = p x (p 为单价) y x
相关关系(或统计关系)
当X值确定后,Y值不是唯一确定, 但大量统计资料表明,这些变量之间 还是存在着某种客观的联系。
(09)第9章 一元线性回归(2011年)
变量之间是否存在关系? 如果存在,它们之间是什么样的关系? 变量之间的关系强度如何? 样本所反映的变量之间的关系能否代表总体 变量之间的关系?
9-9 *
9.1 变量间的关系 9.1.1 变量间是什么样的关系?
统计学 STATIS TICS
函数关系
(第四版) 1. 是一一对应的确定关系 2. 设有两个变量 x 和 y ,变量 y y 随变量 x 一起变化,并完 全依赖于 x ,当变量 x 取某 个数值时, y 依确定的关系 取相应的值,则称 y 是 x 的 函数,记为 y = f (x),其中 x 称为自变量,y 称为因变量 x 3. 各观测点落在一条线上
y 是 x 的线性函数(部分)加上误差项 线性部分反映了由于 x 的变化而引起的 y 的变化 误差项 是随机变量 反映了除 x 和 y 之间的线性关系之外的随机因素 对 y 的影响 是不能由 x 和 y 之间的线性关系所解释的变异性 0 和 1 称为模型的参数
9 - 30 *
统 计 学 数据分析 (方法与案例)
作者 贾俊平
统计学 STATIS TICS
(第四版)
统计名言
不要过于教条地对待研究的结果, 尤其当数据的质量受到怀疑时。
——Damodar N.Gujarati
9-2 *
第 9 章 一元线性回归
9.1 9.2 9.3 9.4 变量间关系的度量 一元线性回归的估计和检验 利用回归方程进行预测 用残差检验模型的假定
9-7
*
第 9 章 一元线性回归
9.1 变量间的关系
9.1.1 变量间是什么样的关系? 9.1.2 用散点图描述相关关系 9.1.3 用相关系数度量关系强度
贾俊平《统计学》章节题库(分类数据分析)【圣才出品】
观察值
105
78
期望值
102
8l
根据这个列联表计算的 Χ2 统计量为( )。
A.0.6176
B.1.6176
C.0.3088
D.1.3088
【答案】A
【解析】 2 f0 fe 2 45 482 42 392 105 1022 78 812
87
反对
105
78
183
合计
150
120
270
这个列联表的最下边一行称为( )。
A.列边缘频数
B.行边缘频数
3 / 25
圣才电子书
C.条件频数
十万种考研考证电子书、题库视频学习平台
D.总频数
【答案】A
7.一所大学准备采取一项学生在宿舍上网收费的措施,为了解男女学生对这一措施的
2.设 R 为列联表的行数,C 为列联表的列数,则 Χ2 分布的自由度为( )。 A.R B.C C.R×C D.(R-1)×(C-1) 【答案】D
【解析】 2 检验的自由度=(行数-1)(列数-1)=(R-1)(C-1)。
1 / 25
圣才电子书 十万种考研考证电子书、题库视频学习平台
看法,分别抽取了 150 名男学生和 120 名女学生进行调查,得到的结果如下:
男学生
女学生
合计
赞成
45
42
87
反对
105
78
183
合计
150
120
270
根据这个列联表计算的赞成上网收费的行百分比分别为( )。
A.51.7%和 48.3%
B.57.4%和 42.6%
C.30%和 70%
D.35%和 65%
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
统计学
STATISTICS (第四版)
学习目标
相关关系的分析 参数的最小二乘估计 回归直线的拟合优度 回归方程的显著性检验 利用回归方程进行预测 用残差证实模型的假定 用 Excel 和SPSS进行回归
9-4
2019-8-31
统计学
STATISTICS (第四版)
子代与父代一样吗?
9-5
2019-8-31
统计学
STATISTICS (第四版)
子代与父代一样吗?
正如Galton进一步发现的那样,平均来说,非常矮小的父 辈倾向于有偏高的子代;而非常高大的父辈则倾向于有偏 矮的子代。在第一次考试中成绩最差的那些学生在第二次 考试中倾向于有更好的成绩(比较接近所有学生的平均成绩), 而第一次考试中成绩最好的那些学生在第二次考试中则倾 向于有较差的成绩(同样比较接近所有学生的平均成绩)。同 样,平均来说,第一年利润最低的公司第二年不会最差, 而第一年利润最高的公司第二年则不会是最好的
9 - 28
2019-8-31
统计学
STATISTICS (第四版)
一元线性回归
1. 涉及一个自变量的回归
2. 因变量y与自变量x之间为线性关系
被预测或被解释的变量称为因变量 (dependent variable),用y表示
用来预测或用来解释因变量的一个或多个变 量称为自变量(independent variable),用x 表示
收入水平相同的人,他们受教育的程度也不可能不同,而受 教育程度相同的人,他们的收入水平也往往不同。因为收入 水平虽然与受教育程度有关系,但它并不是决定收入的惟一 因素,还有职业、工作年限等诸多因素的影响
农作物的单位面积产量与降雨量之间的关系
在一定条件下,降雨量越多,单位面积产量就越高。但产量 并不是由降雨量一个因素决定的,还有施肥量、温度、管理 水平等其他许多因素的影响
3. 因变量与自变量之间的关系用一个线性方 程来表示
9 - 29
2019-8-31
统计学
STATISTICS (第四版)
一元线性回归模型
(linear regression model)
1. 描述因变量 y 如何依赖于自变量 x 和误差项 的 方程称为回归模型
2. 一元线性回归模型可表示为
y = b + b1 x +
假定因变量与自变量之间有某种关系,并把这种关系用 适当的数学模型表达出来,那么,就可以利用这一模型 根据给定的自变量来预测因变量,这就是回归要解决的 问题
在回归分析中,只涉及一个自变量时称为一元回归,涉 及多个自变量时则称为多元回归。如果因变量与自变量 之间是线性关系,则称为线性回归(linear regression); 如果因变量与自变量之间是非线性关系则称为非线性回 归(nonlinear regression)
r = 0,不存在线性相关关系
-1r<0,为负相关 0<r1,为正相关 |r|越趋于1表示关系越强;|r|越趋于0表示关
系越弱
9 - 20
2019-8-31
统计学
STATISTICS (第四版)
相关系数的性质
性质2:r具有对称性。即x与y之间的相关系数和y与x之间 的相关系数相等,即rxy= ryx
9-7
2019-8-31
第 9 章 一元线性回归
9.1 变量间的关系
9.1.1 变量间是什么样的关系? 9.1.2 用散点图描述相关关系 9.1.3 用相关系数度量关系强度
统计学
STATISTICS (第四版)
怎样分析变量间的关系?
建立回归模型时,首先需要弄清楚变量之 间的关系。分析变量之间的关系需要解决 下面的问题
变量之间是否存在关系?
如果存在,它们之间是什么样的关系?
变量之间的关系强度如何?
样本所反映的变量之间的关系能否代表总体 变量之间的关系?
9-9
2019-8-31
9.1 变量间的关系 9.1.1 变量间是什么样的关系?
统计学
STATISTICS (第四版)
函数关系
1. 是一一对应的确定关系
2019-8-31
第 9 章 一元线性回归
9.2 一元线性回归的估计和检验
9.2.1 9.2.2 9.2.3 9.2.4
一元线性回归模型 参数的最小二乘估计 回归直线的拟合优度 显著性检验
9.2 一元线性回归的估计和检验 9.2.1 一元线性回归模型
统计学
STATISTICS (第四版)
什么是回归分析?
9 - 16
原始数据
2019-8-31
统计学
STATISTICS (第四版)
散点图
(销售收入和广告费用的散点图)
9 - 17
2019-8-31
9.1 变量间的关系 9.1.3 用相关系数度量关系强度
统计学
STATISTICS (第四版)
相关系数
(correlation coefficient)
r (x x)( y y) (x x)2 (y y)2
9 - 19
计算相关系数
2019-8-31
统计学
STATISTICS (第四版)
相关系数的性质
性质1:r 的取值范围是 [-1,1]
|r|=1,为完全相关
r =1,为完全正相关 r =-1,为完全负正相关
9 - 21
2019-8-31
统计学
STATISTICS (第四版)
相关系数的经验解释
1. |r|0.8时,可视为两个变量之间高度相关 2. 0.5|r|<0.8时,可视为中度相关 3. 0.3|r|<0.5时,视为低度相关 4. |r|<0.3时,说明两个变量之间的相关程度
极弱,可视为不相关
Galton被誉为现代回归和相关技术的创始人。1875年, Galton利用豌豆实验来确定尺寸的遗传规律。他挑选了7组 不同尺寸的豌豆,并说服他在英国不同地区的朋友每一组 种植10粒种子,最后把原始的豌豆种子(父代)与新长的豌 豆种子(子代)进行尺寸比较
当结果被绘制出来之后,他发现并非每一个子代都与父代 一样,不同的是,尺寸小的豌豆会得到更大的子代,而尺 寸 大 的 豌 豆 却 得 到 较 小 的 子 代 。 Galton 把 这 一 现 象 叫 做 “返祖”(趋向于祖先的某种平均类型),后来又称之为“向 平均回归”。一个总体中在某一时期具有某一极端特征(低 于或高于总体均值)的个体在未来的某一时期将减弱它的极 端性(或者是单个个体或者是整个子代),这一趋势现在被称 作“回归效应”。人们发现它的应用很广,而不仅限于从 一代到下一代豌豆大小问题
(regression analysis)
1. 重点考察考察一个特定的变量(因变量), 而把其他变量(自变量)看作是影响这一变 量的因素,并通过适当的数学模型将变量 间的关系表达出来
2. 利用样本数据建立模型的估计方程
3. 对模型进行显著性检验
4. 进而通过一个或几个自变量的取值来估计 或预测因变量的取值
如果把父代和子代看作两个变量,找出这两个变量的关系, 并根据这种关系建立适当的数学模型,就可以根据父代的 数值预测子代的取值,这就是经典的回归方法要解决的问 题。学完本章的内容你会对回归问题有更深入的理解
9-6
2019-8-31
统计学
STATISTICS (第四版)
回归分析研究什么?
研究某些实际问题时往往涉及到多个变量。在这些变量 中,有一个变量是研究中特别关注的,称为因变量,而 其他变量则看成是影响这一变量的因素,称为自变量
y 是 x 的线性函数(部分)加上误差项 线性部分反映了由于 x 的变化而引起的 y 的变化
误差项 是随机变量
反映了除 x 和 y 之间的线性关系之外的随机因素 对 y 的影响
9 - 12
2019-8-31
统计学
STATISTICS (第四版)
相关关系
(correlation)
1. 一 个 变 量 的 取 值 不 能
由另一个变量唯一确
定
y
2. 当变量 x 取某个值时, 变量 y 的取值对应着 一个分布
3. 各 观 测 点 分 布 在 直 线 周围
x
统计学
STATISTICS (第四版)
相关关系
(几个例子)
子女的身高与其父母身高的关系
从遗传学角度看,父母身高较高时,其子女的身高一般也比 较高。但实际情况并不完全是这样,因为子女的身高并不完 全是由父母身高一个因素所决定的,还有其他许多因素的影 响
一个人的收入水平同他受教育程度的关系
9 - 13
2019-8-31
9.1 变量间的关系 9.1.2 用散点图描述相关关系
统计学
STATISTICS (第四版)
完全正线性相关
正线性相关
9 - 15
散点图
(scatter diagram)
完全负线性相关
负线性相关
计算检验的统计量
t r n 2 ~ t(n 2) 1 r2
用Excel中的【TDIST】函数得双尾计算P值,并于 显著性水平比较,并作出决策
• 若P<,拒绝H0
9 - 23
2019-8-31
统计学
STATISTICS (第四版)
相关系数的显著性检验
(例题分析)
【例9-3】检验销售收入与广告费用之间的相关系数是
统计学 数据STICS (第四版)
统计名言