歌曲人声后期精细效果处理的方法与
作曲中的音频后期处理技巧

作曲中的音频后期处理技巧音频后期处理是作曲过程中不可或缺的一环,它能够提升音频的质量,增强音乐的表现力。
在这篇文章中,我们将探讨一些作曲中常用的音频后期处理技巧,帮助你打造出更加出色的音乐作品。
1. 均衡器调整均衡器是音频后期处理中最基本的工具之一。
通过调整均衡器,你可以控制音频信号的频率分布,使其更加平衡和清晰。
在作曲中,你可以使用均衡器来增加某些频率范围的音量,突出乐器或声音效果的特点。
例如,如果你想突出钢琴的音色,可以适当提高高频段的音量;如果你想增强低音的韵味,可以适当提高低频段的音量。
2. 压缩器运用压缩器是音频后期处理中常用的动态处理工具。
它可以限制音频信号的动态范围,使音频更加平衡和稳定。
在作曲中,你可以使用压缩器来控制乐器或声音效果的音量变化,使其更加平滑和一致。
例如,当你使用弦乐合奏时,压缩器可以帮助你控制弦乐乐手的强弱变化,使乐曲更加连贯和和谐。
3. 混响效果添加混响效果是模拟不同环境中的音响反射和吸收的处理效果。
在作曲中,你可以使用混响效果来增加音频的空间感和深度。
通过调整混响参数,你可以模拟出不同的场景,例如大教堂、音乐厅或者房间。
选择适当的混响效果和参数,可以使音乐更加立体和自然。
4. 延迟效果运用延迟效果是一种通过延迟音频信号来创造出回响效果的音频处理工具。
在作曲中,你可以使用延迟效果来增加音乐的层次感和空间感。
通过调整延迟时间和反馈参数,你可以创造出不同的延迟效果,例如回声、立体声或者环绕声。
合理运用延迟效果,可以使音乐更加富有变化和魅力。
5. 时域处理技巧时域处理是一种改变音频信号的时间特性的处理技巧。
在作曲中,你可以使用时域处理来创造出各种特殊的音效和效果。
例如,通过使用音频反转效果,你可以创造出独特的反向音效;通过使用音频剪切和重叠技巧,你可以创造出复杂的节奏和和声效果。
时域处理技巧可以为音乐增添独特的风格和个性。
总结起来,音频后期处理技巧在作曲中起着至关重要的作用。
基本的人声后期处理步骤

基本的人声后期处理步骤进行每一步效果处理时都要用鼠标选中要处理的小节,选中后波形背景是变成白色.(1)降噪.人声之前会有一段噪音,那就是环境噪音,选中那段环境噪音,然后在菜单栏上选择“效果”,接着选择“刷新效果列表”,出现对话框,选择“是”刷新完后,接着选择菜单栏上“效果”里的“噪音消除”选项,然后选择“降噪器”,进去后选择“噪音采样”,然后按“关闭”.再重新选择菜单栏的“效果”里的“噪音消除”的“降噪器”,最后按确定,这样录音过程中的环境噪音就消除了.这只是环境噪音的消除,人声末尾的尾音这也要消除,否则会影响整首歌曲的效果消除这个噪音有专门的插件“waves”的“Rvox”效果器,这个效果器能剪除人声末尾的尾音,建议设置不要过,否则在每句话的首尾处会有明显的突然消失声音的感觉.(2)激励人声.双击人声音轨切换到波形编辑界面,选定全部波形,然后在“效果”里选择“DerectX”里的“BBESonicmaximizer”插件,然后大家会看到三个旋钮,第一个调的是低音,第二个调的是高音,第三个调的是总输出音量.大家可以根据人声来调整高低音还要总音量,开始录进去的人声不是很有力度,这就需要加高音激励起来,这样听起来就好听些,不信大家可以试试看咯.(3)压限.安装waves 4.0后,在“DerectX”选择“wavesC4”,出现调整窗口.这时候要根据自己的声音对高低频进行调节,开始使用软件的时候也许还不知道怎么调整相关数据,大家可以这样,在调整窗口选择“load”,进去后会看到很多种效果,大家可以选择倒数第四个“pop vocal”,然后按确定.压限的作用就是人声的高频不要“噪”,低频不要“浑”。
开始不知道怎么用上面的方法,以后熟练以后要根据自己的人声调整正确数据.(4)增强人声的力度和表现力.安装“Ultrafunk fx”效果器后会有名称叫“Compressor R3”的效果器,这效果器的作用就是增强人声的力度和表现力打开后会看到上面有四个小方框,不同的数据会有不同的效果,开始不知道怎么用的时候可以把这四个数据输进去,第一个输入:-20 第二个输入:4.0第三个输入:16 第四个输入:7.0 除了顶上这四个,底下还有2个,第一个输入:40 第二个输入:200 然后按确定就可以增强人声的力度和表现力了.上面提供的只是大概的数据,具体数据还要*大家去感觉,最后确定.(5)混响.安装“Ultrafunk fx”效果器后有会叫“Reverb R3”的效果器.此工作需要很细心,不同的录音环境,不同的曲风混响效果都不一样的.这需要大家不断的积累经验,容积较大、吸声不足的房间,效果器的人工混响时间要短.男声演唱时混响时间应短些;女声演唱时混响时间可长些.专业歌手混响时间应短些,否则会破坏原有音色的特征,业余歌手可用较长的混响时间,以掩盖声音的不足之处等等……开始使用这个软件的朋友可以具体我提供的数据输进去,一共有13个小方框,第一:0.0 第二:75 第三:7.1 第四:0 第五:50 第六:100 第七:1.0 第八:500 第九:2.2第十:7.8 第十一:0.0 第十二:-14.3 第十三:-12.3 .再次声明,上面提供的不是标准数据,这只是给刚开始用此软件朋友提供的,具体的数据要*自己的耳朵去感觉.(6)均衡人声.安装“Ultrafunk fx”效果器后有会叫“Equalizer”的效果器.主要作用就是均衡人声,让高频在保持不噪的前提下调整到清晰通透;低频保证不浑浊的前提下调整到清晰、自然.同样开始使用此软件朋友可以先使用我提供的这些数据,不是标准数据,具体数据还要*大家以后自己去摸索。
人声效果的精细处理

人聲效果的精細處理作者:未知來源:音燈光音響網對人聲效果的處理,大多數人都是使用反覆試探性調節的方法,以尋找音感效果最好的處理效果。
此種調音方式的不足十分明顯:(1)尋找一個理想的調音效果,需經多次猜測,所以需要較長的時間。
(2)較好的調音效果常常是偶然遇到的,這對於調音規律的歸納總結沒什麼幫助,並且以後也不易再現。
(3)不同設備的各項固定參數和可調參數都不盡相同,因而使用某一設備的經驗,通常都無法用於另一設備。
發展到目前的效果處理設備,用於改變音源音色的技術手段並不太多,其中比較常用的只有頻率等化器、延時反饋、限幅失真等3種基本方法,然而這些效果處理設備的不同參數組合所產生的音色則大相徑庭。
效果處理器的參數設置可以有很多項,尤其是延時反饋,這種模擬混響效果參數的設置理論上可達幾十項之多。
當然這些專業性極強的參數,大多數人都難以理解,也不知道如何理解。
因此,大部分效果處理設備都只設置一、二個可調參數,並且其可調範圍也比較狹窄。
這種調整簡單的效果處理設備容許人們在上面進行嘗試性調整,而不會出現太大的問題。
但對於效果處理要求更為精細的調音場合,例如在多軌錄音系統當中,則必頇使用更為專業的效果處理設備,用以做出更為精細的效果處理。
頻率等化器很明顯,頻率等化器的分段越多,效果處理的精細程度也就越高。
除了圖示等化器(Graphic Equalizers),一般調音的等化器單元通常只有三四個頻段,這顯然滿足不了精確處理音源的要求。
為了能足夠靈活的對人聲進行任意的等化器處理,我們建議使用增益(Gain)、頻點(f)和寬度(Q)都可調整的四段頻率等化器。
多數頻率等化器的可調參數只有增益一項,然而這並不意味著其他兩項參數不存在,而且這兩項參數為不可調的固定參數。
當然這兩項參數設置為可調也並非難事,但這些會增加設備的成本,並使其調整變得複雜化。
所以增益、頻點和寬度都可調整的參量等化器電路,通常只有在高檔設備上才能見到。
伴奏提取消除人声的方法

伴奏提取消除人声的方法
伴奏提取消除人声的方法是指在音乐制作过程中,使用一些技巧或工具将原始音频文件中的人声部分剔除,留下纯净的伴奏部分。
这样可以方便后期制作人员在音乐创作、混音、编曲等方面进行更精细的处理和调整。
以下是几种常见的伴奏提取消除人声的方法:
1.使用降噪工具:一些专门的降噪软件或插件,可以将原始音频中的人声、谈话等杂音部分过滤掉,留下干净的伴奏。
2.使用EQ调整频率:在音频编辑软件中,可以通过EQ调整工具将人声所在频率范围的音频信号减弱或削弱,从而实现伴奏提取。
3.反相混音:将原始音频中的人声部分提取出来,再将其反相混音,可以实现人声的消除,留下伴奏部分。
4.人工剔除:对于一些简单的伴奏提取,可以手动剔除人声部分,留下伴奏。
以上是几种常见的伴奏提取消除人声的方法,具体选择哪种方法取决于具体音频文件的特点和需要的效果。
- 1 -。
audacity人声消除参数

audacity人声消除参数使用Audacity进行人声消除是一种常见的音频处理方法。
通过调整Audacity的参数,可以有效地去除背景噪音,使人声更加清晰。
本文将介绍一些常用的Audacity人声消除参数,帮助读者在处理音频时获得更好的效果。
我们需要了解Audacity的一些基本操作。
打开音频文件后,我们可以看到波形图和控制面板。
在控制面板中,有一些参数可以调整,以达到人声消除的效果。
1. 静音区域分析(Silence Finder)在Audacity中,可以使用静音区域分析工具来自动检测音频中的静音区域。
静音区域通常是指没有人声的部分,通过分析这些区域,我们可以更好地了解背景噪音的特点。
在Audacity中,选择“效果”-“静音区域分析”可以进行静音区域分析。
2. 消除噪音(Noise Reduction)消除噪音是人声消除的核心步骤之一。
在Audacity中,可以使用噪音消除效果来处理音频文件。
选择要处理的音频段落,然后选择“效果”-“噪音消除”,在对话框中点击“获取噪音样本”,然后点击“OK”进行处理。
3. 声音增强(Amplify)在消除噪音后,有时人声可能会变得过于柔弱,这时可以使用声音增强工具来提高人声的音量。
在Audacity中,选择要处理的音频段落,然后选择“效果”-“放大”,在对话框中可以调整增益的大小。
4. 频谱编辑器(Spectral Editing)频谱编辑器是Audacity中一个非常强大的工具,它可以直接编辑音频的频谱图。
通过调整频谱图中的参数,可以对音频进行更精细的处理。
在Audacity中,选择“效果”-“频谱编辑器”,然后调整参数进行编辑。
5. 去除杂音(De-essing)有时,音频中可能存在过多的“s”音(也称为“嘶音”),这会影响人声的清晰度。
在Audacity中,可以使用去除杂音工具来处理这个问题。
选择要处理的音频段落,然后选择“效果”-“去除杂音”,在对话框中可以调整去除杂音的强度。
音乐消人声后期处理方法
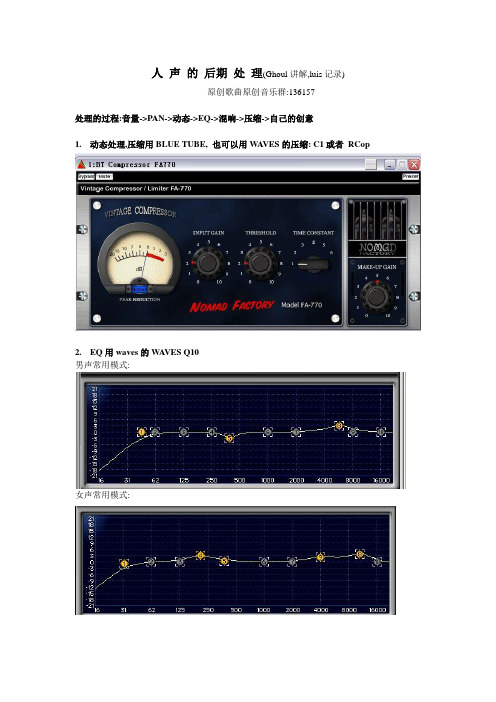
人声的后期处理(Ghoul讲解,luis记录)
原创歌曲原创音乐群:136157
处理的过程:音量->PAN->动态->EQ->混响->压缩->自己的创意
1.动态处理,压缩用BLUE TUBE, 也可以用W A VES的压缩: C1或者RCop
2.EQ用waves的W A VES Q10
男声常用模式:
女声常用模式:
3.混响: 用W A VES的RVER
PREDELAY,这个设置为3MS到5MS一般就是一个小型到重型的录音室了,如果是10ms就大点了,
TIME一般不用那么长的,一般1S前后就可以了;
SIZE这个以耳朵为准. DIFFUSION 建议50到86,其他的要自己听了,DECAY,可以不动了. TIME包含了DEcay,DECAY是TIME的一部分;
EARL Y REF是早反射;REVEB是混响中的音量
4.最后再加一次压缩,BLUE TUBE,最后的压缩是用来限制加入混响以后的声音不置于过大
一般情况下,我有的时候会这样做:
两个压缩,一个是PEAK压缩,一个是RMS压缩;
如果是PEAK压缩的话,只是针对一些比较大的声音,来压缩,流出更多空间做其他的东西RMS压缩是对整个人声,真正做到声音均匀的压缩
Tc的混响
shape 是环境;DIFFUSE是密度,COLOR是频率截至;FACTOR是两段均衡;MIX是干湿比;LEVELS是输入输出量, PERDELAYS是早反射,第二个是预反射,第三个是混响的时间。
歌曲后期的制作步骤
歌曲后期的制作步骤!1、降噪:人声之前会有一段噪音,那就是环境噪音,选中那段环境噪音,然后在菜单栏上选择“效果”,接着选择“刷新效果列表”,出现对话框,选择“是”刷新完后,接着选择菜单栏上“效果”里的“噪音消除”选项,然后选择“降噪器”,进去后选择“噪音采样”,然后按“关闭”.再重新选择菜单栏的“效果”里的“噪音消除”的“降噪器”,最后按确定,这样录音过程中的环境噪音就消除了.这只是环境噪音的消除,人声末尾的尾音这也要消除,否则会影响整首歌曲的效果消除这个噪音有专门的插件“waves”的“Rvox”效果器,这个效果器能剪除人声末尾的尾音,建议设置不要过,否则在每句话的首尾处会有明显的突然消失声音的感觉.2、激励人声:双击人声音轨切换到波形编辑界面,选定全部波形,然后在“效果”里选择“DirectX”里的“BBESonicmaximizer”插件,然后大家会看到三个旋钮,第一个调的是低音,第二个调的是高音,第三个调的是总输出音量.大家可以根据人声来调整高低音还要总音量,开始录进去的人声不是很有力度,这就需要加高音激励起来,这样听起来就好听些,不信大家可以试试看咯.3、压限:安装waves 4.0后,在“DirectX”选择“wavesC4”,出现调整窗口.这时候要根据自己的声音对高低频进行调节,开始使用软件的时候也许还不知道怎么调整相关数据,大家可以这样,在调整窗口选择“load”,进去后会看到很多种效果,大家可以选择倒数第四个“pop vocal”,然后按确定.压限的作用就是人声的高频不要“噪”,低频不要“浑”。
开始不知道怎么用上面的方法,以后熟练以后要根据自己的人声调整正确数据.4、增强人声的力度和表现力:安装“Ultrafunk fx”效果器后会有名称叫“Compressor R3”的效果器,这效果器的作用就是增强人声的力度和表现力打开后会看到上面有四个小方框,不同的数据会有不同的效果,开始不知道怎么用的时候可以把这四个数据输进去,第一个输入:-20 第二个输入:4.0第三个输入:16 第四个输入:7.0 除了顶上这四个,底下还有2个,第一个输入:40 第二个输入:200 然后按确定就可以增强人声的力度和表现力了.上面提供的只是大概的数据,具体数据还要靠大家去感觉,最后确定.5、混响:安装“Ultrafunk fx”效果器后有会叫“Reverb R3”的效果器.此工作需要很细心,不同的录音环境,不同的曲风混响效果都不一样的.这需要大家不断的积累经验,容积较大、吸声不足的房间,效果器的人工混响时间要短.男声演唱混响时间应短些;女声演唱时混响时间可长些.专业歌手混响时间应短些,否则会破坏原有音色的特征,业余歌手可用较长的混响时间,以掩盖声音的不足之处等等……开始使用这个软件的朋友可以具体我提供的数据输进去,一共有13个小方框,第一:0.0 第二:145 第三:4.5 第四:160 第五:100 第六:100 第七:2.6 第八:116 第九:1.6 第十:1.2 下面三个就按默认值吧.再次声明,上面提供的不是标准数据,这只是给刚开始用此软件朋友提供的,具体的数据要靠自己的耳朵去感觉.6、均衡人声:安装“Ultrafunk fx”效果器后有会叫“Equalizer”的效果器.主要作用就是均衡人声,让高频在保持不噪的前提下调整到清晰通透;低频保证不浑浊的前提下调整到清晰、自然.同样开始使用此软件朋友可以先使用我提供的这些数据,不是标准数据,具体数据还要靠大家以后自己去摸索。
人声处理步骤
人声处理步骤制作清唱的后期效果这个过程的所有步骤都必须在清唱音轨的单轨状态下完成。
选中“音轨2”,点击窗口左上方的绿色尖头按钮进入“音轨2”的单轨状态。
此时,可能AUDITION的3个插件安装完毕后还未被激活(这样插件的功能就无法使用),点击“效果”菜单——“刷新效果列表”,3个插件就会被激活了。
以下是对清唱加工的几个步骤,所有步骤执行后都可以返回,只要在单轨状态下,点击窗口上方的工具栏中“撤消上次*作”按钮即可。
1、去噪(作用是消除录音时录入的环境噪声)点击“效果”菜单——“噪音消除”——“降噪器”,降噪是要先噪音采样的,就是选中你清唱最前面那段没有人声的空白的部分(一、两秒种就够了),进入“降噪器”,然后选“噪音采样”,再点“关闭”,然后取消你之前选的那段空白部分(此时就等于选中了整首歌),再进入“降噪器”,设置“降噪级别”的高低,(一般不宜超过50,视具体情况而定),然后就点“确定”,完工!2、激励(作用是对人声的高音做润色,使之听起来更清脆明亮)点击“效果”菜单—“DirectX”—“BBESonicMaximizer”,出现的对话框里有三个带有刻度的圆盘,最左边的圆盘是用来对低音的调节、中间的用来调节高音,右边的用来调节总体音频。
一般情况下,对清唱的人声只作高音激励,所以,在这里我们只需要调节那个圆盘。
即拖动圆盘上的杠杆转动,刻度越大对高音的激励就越明显(一般刻度不宜超过4,视具体情况而定),然后“确定”,完成。
3、加混响(卡拉OK常用效果,作用是使人声听起来不那么干)点击“效果”菜单—“DirectX”—“Ultrafunkfx”—“Reverb”,我认为在出现的对话框里只有一点比较有实际作用,就是“Decay Time”的数值,数值越大,混响效果就越厉害。
软件默认数值是1.5,我觉得很合适,没什么必要更改了,直接“确定”即可。
4、压限(作用是把整首歌的音频均衡压缩,尽量避免显出突兀之处)点击“效果”菜单—“DirectX”—“WavesC4”,出现的对话框里有个“软件设置”的下拉框,选择“Pop vocal”,然后“确定”,这个步骤就完成了。
13个人声处理技巧,让声音具有唱片般的品质
13个人声处理技巧,让声音具有唱片般的品质如果你已经知道怎么进行EQ处理、怎么选择话筒、怎么让歌手的声音变得更加平滑…可是还想知道更多、更好、更厉害的知识。
那么,这篇文章就是你提升人声处理技术的机会。
用一轨人声做Double(叠合)你想要叠合人声部分,于是就在多条轨道上重复录制了人声,想要从里面选出较好的部分来建立两条人声。
不幸的是,某一乐句只有一次录音是出色的——另一个可能有瑕疵,或歌手在录音时爆音了。
这时候不要着急:把出色的部分拷贝到另一轨上,对音调进行微调,然后设置20到25ms的延迟就可以了。
细调混响的扩散(Diffusion)好的人声当然需要好的混响,那么试试低扩散(“密度”)的参数。
这样做的原因是:扩散控制着回声的“厚度”。
高扩散把回声放置得很近,而低扩散把它们摆得很远。
对于节奏性的声音,低扩散会制造很多密集空间的声音,像石头撞在钢铁上一样。
但是对于人声,低扩散能给你足够的混响效果,但不会引起太多反射。
细调混响衰减时间很多混响都提供了频率的交叉点,高频和低频各自带有单独的衰减时间。
为了防止与中频乐器过多的竞争,可以在低频的地方使用低的衰减时间,在高频的地方使用高的衰减时间,这样可以给人声增加“空气感”,同时也能加强唇齿音,让人声更加生动。
最后调整交叉点的位置,让人声达到较好的效果。
声像自动化(Automation)对于Double的人声,你可以把两者都放在中间,或者一个靠左,一个靠右,然后添加不同的效果。
比如,在声场里有背景人声,我通常会把它放在中间。
如果不想人声比乐器突出,我会把两个轨道放得开一点,不使之成为焦点。
简单来说:用自动化来控制声像,对于不同的部分使用不同的声像。
令人竖起汗毛的人声记得Pink Floyd曾经用的那种轻声的,令人竖起汗毛的人声吗?试着让人声尽量多一些语气,像说话,而不是唱歌,然后插入一个声码器(软件或硬件),以人声作为调制器,粉噪作为载体。
你可能不需要太多粉噪的高频。
广播剧制作服务中的音频后期处理与剪辑技巧
广播剧制作服务中的音频后期处理与剪辑技巧广播剧作为一种受众广泛、传播方式多样的媒体形式,经过多年的发展,已成为了人们生活中不可或缺的一部分。
而在广播剧的制作过程中,音频的后期处理和剪辑技巧起着至关重要的作用。
本文将重点探讨广播剧制作服务中的音频后期处理与剪辑技巧,希望对于从事广播剧制作的相关人员有所帮助。
一、音频后期处理技巧1.噪音去除:在音频后期处理中,噪音去除是一个关键环节。
通常,我们可以使用降噪软件,通过对频谱进行分析和处理,降低噪音的干扰。
同时,合理的麦克风选择和布局也能够起到减少噪音的效果。
2.音频均衡:音频均衡是调整声音频率的技术,可以改善音频的听感。
通过调整高音、中音、低音的比例,可以使声音更加清晰、细腻。
在广播剧中,不同角色扮演者的音质、音量可能存在差异,因此,在进行音频均衡处理时,应针对每一个角色进行适当调整,以保证整体音质的统一。
3.声音增加:在广播剧制作中,往往需要模拟一些特殊的音效,比如风声、雨声、车辆声等,以增加剧情的悬念和真实感。
这就需要通过音频后期处理技巧,将这些特效声音融合到广播剧中。
可以使用混响器、增益器等工具,调整声音的大小和音色,使其与原音融为一体。
4.音质改善:音频后期处理还应注重音质改善,以提高听众的听感体验。
可以使用压缩、限制、扩展等技术,调节音量波动,使得音频更加平稳流畅。
另外,要注意音频采样率和比特率的选择,以保证音频的高清晰度和还原度。
5.声道处理:广播剧通常以立体声进行播放,因此在音频后期处理中应注重声道处理。
可以通过合理的平衡、增强、定位等手段,使得广播剧的声音更具层次感和空间感。
二、音频剪辑技巧1.剧情剪辑:广播剧的剧情剪辑是指将原始素材按照剧情发展的需要进行删减、合并、调整等操作。
在音频剪辑过程中,要注意保留重要的情节和台词,同时删除冗余的部分,使得剧情更加紧凑流畅。
2.场景剪辑:广播剧通常涉及到多个场景的切换,因此在音频剪辑时,要注意场景的过渡和衔接。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
人声后期精细效果处理的方法与要点在人声效果的精细处理上,大多数人都是使用反复试探性调节的方法,以寻找音感效果最好的处理效果。
此种调音方式的不足十分明显:(1) 寻找一个理想的调音效果,需经多次猜测,所以需要较长的时间。
(2) 较好的调音效果常常是偶然遇到的,这对于调音规律的归纳总结没什么帮助,并且以后也不易再现。
(3) 不同设备的各项固定参数和可调参数都不尽相同,因而使用某一设备的经验,通常都无法用于另一设备。
发展到目前的效果处理设备,用于改变音源音色的技术手段并不太多,其中比较常用的只有频率均衡、延时反馈、限幅失真等3种基本方法,然而这些效果处理设备的不同参数组合所产生的音色则大相径庭。
效果处理器的参数设置可以有很多项,尤其是延时反馈,这种模拟混响效果参数的设置理论上可达几十项之多。
当然这些专业性极强的参数,大多数人都难以理解,也不知道如何理解。
因此,大部分效果处理设备都只设置一、二个可调参数,并且其可调范围也比较狭窄。
这种调整简单的效果处理设备容许人们在上面进行尝试性调整,而不会出现太大的问题。
但对于效果处理要求更为精细的调音场合,例如在多轨录音系统当中,则必须使用更为专业的效果处理设备,用以做出更为精细的效果处理。
频率均衡很明显,频率均衡的分段越多,效果处理的精细程度也就越高。
除了图示均衡,一般调音的均衡单元通常只有三四个频段,这显然满足不了精确处理音源的要求。
为了能足够灵活的对人声进行任意的均衡处理,我们建议使用增益、频点和宽度都可调整的四段频率均衡。
多数频率均衡的可调参数只有增益一项,然而这并不意味着其他两项参数不存在,而且这两项参数为不可调的固定参数。
当然这两项参数设置为可调也并非难事,但这些会增加设备的成本,并使其调整变得复杂化。
所以增益、频点和宽度都可调整的参量均衡电路,通常只有在高档设备上才能见到。
实际上,增益、频点和宽度都是可调整的频率均衡,几乎不可能使用胡猜乱试的方法找出一个理想的音色。
在这里我们必须研究音频信号的物理特性、技术参数以及他在人耳听感上的对应关系。
人声音源的频谱分布比较特殊,就其发音方式而言,他有三个部分:一个是由声带震动所产生的乐音,此部分的发音最为灵活,不同音高、不同发音方式所产生的频谱变化也很大;二是鼻腔的形状较为稳定,因而其共鸣所产生的谐音频谱分布变化不大;三是口腔气流在齿缝间的摩擦声,这种齿音与声带震动所产生的乐音基本无关。
频率均衡可以大致的将这三部分频谱分离出来。
用语调节鼻音的频率段在500Hz,以下均衡的中点频率一般在80~150Hz,均衡带宽为4个倍频程。
例如,可以将100Hz定为频率均衡的中点,均衡曲线应从100~400Hz平缓的过渡,均衡增益的调节范围可以为+10Db~ -6dB。
这里应提醒大家的是:进行此项调整的监听音箱不得使用低频发音很弱的小箱子,以避免鼻音被无意过分加重。
人声乐音的频谱随音调的变化也很大,所以调节乐音的均衡曲线应非常平缓,均衡的中点频率可在1000~3400Hz,均衡带宽为六个倍频程。
此一频段控制着歌唱发音的明亮感,向上调节可温和地提升人声的亮度。
然而如需降低人声的明亮度,情况就会更复杂一些。
一般音感过分明亮的人声大多都是2500Hz附近的频谱较强,这里我们可用均衡带宽为1/2倍频程,均衡增益为-4dB左右的均衡处理,在2500Hz附近寻找一个效果最好的频点即可。
人声齿音的频谱分布在4kHz以上。
由于此频段亦包含部分乐音频谱,所以建议调节齿音的频段应为6~16KHz,均衡带宽为3个倍频程,均衡中点频率一般在10~12KHz,均衡增益最大向上可调至+10Db;如需向下降低人声齿音的响度,则应使用均衡带宽为1/2倍频程,均衡中点频率为6800Hz的均衡处理,其均衡增益最低可向下降至-10Db。
由以上分析可以看出,对人声进行频率均衡处理时,为突出某一音感而进行的频段提升,都尽量使用曲线平缓的宽频带均衡。
这是为了使人声鼻音、乐音、齿音三部分的频谱分布均匀连贯,以使其发音自然、顺畅。
从理论上讲,应使人声在发任何音时,其响度都保持恒定。
为了在不破坏人生自然感的基础上对其进行特定效果的处理可以使用1/5倍频程的均衡处理,具体有以下几种情形:(1) 音感狭窄,缺乏厚度,可在800Hz处使用1/5倍频程的衰减处理,衰减的最大值可以在-3dB。
(2) 卷舌齿音的音感尖啸,"嘘"音缺乏清澈感,可在2500Hz处使用1/5倍频程的衰减处理,衰减的最大值可以在-6Db。
对音源的均衡处理,最好是使用能显示均衡曲线的均衡器。
一般数字调音台均衡器上的均衡增益调节钮用"G"来标识,均衡频率调节钮用"F"来标识,均衡带宽调节钮用"F"或"Q"来标识。
延时反馈延时反馈是效果处理当中应用最为广泛,但也是最为复杂的方式。
其中,混响、合唱、镶边、回声等效果,其基本处理方式都是延时反馈。
1、混响混响效果主要是用于增加音源的融合感。
自然音源的延时声阵列非常密集、复杂,所以模拟混响效果的程序也复杂多变。
常见参数有以下几种:混响时间:能逼真的模拟自然混响的数码混响器上都有一套复杂的程序,其上虽然有很多技术参数可调,然而对这些技术参数的调整都不会比原有的效果更为自然,尤其是混响时间。
高频滚降:此项参数用于模拟自然混响当中,空气对高频的吸收效应,以产生较为自然的混响效果。
一般高频混降的可调范围为0.1~1.0。
此值较高时,混响效果也较接近自然混响;此值较低时,混响效果则较清澈。
扩散度:此项参数可调整混响声阵密度的增长速度,其可调范围为0~10,其值较高时,混响效果比较丰厚、温暖;其值较低时,混响效果则较空旷、冷僻。
预延时:自然混响声阵的建立都会延迟一段时间,预延时即为模拟次效应而设置。
声阵密度:此项参数可调整声阵的密度,其值较高时,混响效果较为温暖,但有明显的声染色;其值较低时,混响效果较深邃,切声染色也较弱。
频率调制:这是一项技术性的参数,因为电子混响的声阵密度比自然混响稀疏,为了使混响的声音比较平滑、连贯,需要对混响声阵列的延时时间进行调制。
此项技术可以有效的消除延时声阵列的段裂声,可以增加混响声的柔和感。
调治深度:指上述调频电路的调治深度。
混响类型:不同房间的自然混响声阵列差别也较大,而这种差别也不是一两项参数就能表现的。
在数码混响器当中,不同的自然混响需要不同的程序。
其可选项一般有小厅(S-Hall)、大厅(L-Hall)、房间(Room)、随机(Random)、反混响(Reverse)、钢板(Plate)、弹簧 (Sprirg)等。
其中小厅、大厅房间混响属自然混响效果;钢板、弹簧混响则可以模拟早期机械式混响的处理效果。
房间尺寸:这是为了配合自然混响效果而设置的,很容易理解。
房间活跃度:活跃度,就是一个房间的混响强度,他与房间墙面吸声特性有关,此项参数即用于调节此特性。
早期反射声与混响声的平衡:混响的早期反射声与其处理效果特性关系密切,而混响声阵的音感则不那么变化多端,所以数码混响器的这两部分的生成是分开的,本参数就是用于调整早期反射声与混响声阵之间响度平衡。
早期反射声与混响声的延时时间:即早期反射声与混响声阵之间的延时时间控制。
此时间较长,混响效果的前段就较清澈;此时间较短,早期反射声与混响声就会重叠在一起,混响效果的前段就较浑浊。
除以上可调参数之外,混响效果还有一些其他附属参数,例如低通滤波、高通滤波、直达/混响声的响度平衡控制等。
2、延时延时就是将音源延迟一段时间后,再欲播放的效果处理。
依其延迟时间的不同,可分别产生合唱、镶边、回音等效果。
当延迟时间在3~35ms之间时人耳感觉不到滞后音的存在,并且他与原音源叠加后,会因其相位干涉而产生"梳状滤波"效应,这就是镶边效果。
如果延迟时间在50ms以上时,其延迟音就清晰可辨,此时的处理效果才是回音。
回音处理一般都是用于产生简单的混响效果。
延时、合唱、镶边、回音等效果的可调参数都差不多,具体有以下几项:延时时间(Dly),即主延时电路的延时时间调整。
反馈增益(FB Gain),即延时反馈的增益控制。
反馈高频比(Hi Ratio),即反馈回路上的高频衰减控制。
调制频率(Freq),指主延时的调频周期。
调制深度(Depth),指上述调频电路的调制深度。
高频增益(HF),指高频均衡控制。
预延时(Ini Dly),指主延时电路预延时时间调整。
均衡频率(EQ F),这里的频率均衡用于音色调整,此为均衡的中点频率选择。
由于延时产生的效果都比较复杂多变,如果不是效果处理专家,建议使用设备提供的预置参数,因为这些预置参数给出的处理效果一般都比较好。
声激励对音源信号进行浅度的限幅处理,音响便会产生一种类似"饱和"的音感效果从而使其发音在不提高其实际响度的基础上有响度增大的效果。
一些数码效果器上也配有非线性饱和效果,他就是对信号的振幅处理,模拟大电瓶信号在三极管上的饱和所引起的非线性,从而产生出"发硬"的音感效果。
由于限幅失真所引起的主要是产生额外的高次谐波成分,因而新设计的激励器,为了使其处理效果柔和一些,都是通过在音源中家置高次载波成分来模拟限幅失真,营造不那么"嘶哑"的声激励效果。
另外,通过一个用于加强高次谐波的高通滤波器对原信号进行处理,然后再叠加在经延时的原信号上,可以营造出音头清澈的声效果。
显然、这种处理方式可以产生出不那么嘈杂的激励处理。
激励处理类似于音响设备的过载失真,因而对音源的过量激励,会产生令人不悦的嘈杂感。
由于早期音响设备的保真度都不高,人们已经习惯了那种稍显嘈杂的音响,而对于音感清洁的高保真度音响,反而不太习惯,感觉其发音过分柔弱。
在人声音源当中,除了一少部分经过专门训练的人之外,大部分的发言都缺乏劲度,因而这里的激励处理是十分必要的。
对人声的激励处理有下面几种情形:(1)对人声乐音的激励处理,其频谱分布以2500Hz为中点。
此种激励的效果比较自然舒适、对增加音源突出感的作用也比较明显。
(2)对人声鼻音的激励处理,其频谱分布以500Hz为中点。
此种激励可以有效地增大人声的劲度感。
(3)对人声800Hz附近进行激励,可以增加音源的喧嚣感,当然此处理方式的使用应十分谨慎,最好是只用于摇滚乐的演唱。
(4)对人声3500-6800Hz范围内的频谱,不宜使用激励处理,因为它容易使音源产生令人不悦的嘈杂声响。
(5)对人声的齿音一般应避免使用激励处理,因为此频段的失真很容易被人察觉。
当然如果是使用激励效果比较柔和的数字式激励器,也可以对齿音做轻微的激励处理,以用于加重齿音的清析感。
其处理的频谱应在7200Hz以上。