基于多元线性回归的公路客运量发展预测模型
多元线性回归案例-公路客运量

计算回归系数
Intercept
X Variable 1 X Variable 2 X Variable 3 X Variable 4
Coefficient s -
3094216.283 26.63703524
3.161530019
Coefficients -3164044.02 -59.4619025 27.18225866 3.134301817 1459.857673 312.6659322
X X X X Yˆ X = - 3164044.02 - 59.46 1 + 27.18 2+ 3.13 3+ 1459.86 4+312.67 5
dL 0.49
4 dU DW d L 0.49
DW检验无结论
Excel技术支持
第二次检验总结
R检验
回归统计所得 复相关系数R 远大于查表所 得相关系数临 界值,说明数 据相关关系显 著
F检验
回归统计所得 F统计量远大 于查表所得临 界值,否定假 设,认为自变 量与因变量间 回归效果显著
综上判定:剩余四个因素均对公路客运量有显著影响
t检验通过
Excel技术支持
RESIDUAL OUTPUT
观测值 1 2 3 4 5 6 7 8 9
10 11 12 13 14 15
DW检验
预测 Y 643980.5197 638154.2071 679732.6268 752136.8213 843449.9506 959632.632 1054454.966 1134729.76 1194339.7 1236696.678 1286810.288 1336303.614 1411188.254 1459365.628 1474352.354
基于多元线性回归的客车销售量影响因素信息化分析
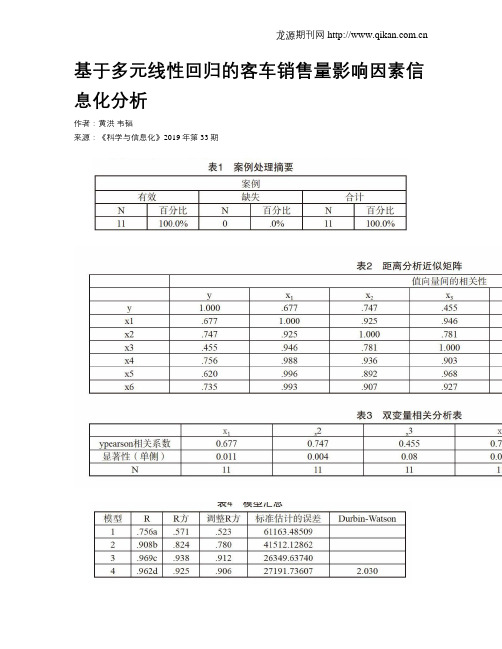
基于多元线性回归的客车销售量影响因素信息化分析作者:黄洪韦韬来源:《科学与信息化》2019年第33期摘要本文通过回归分析的方法对2008~2018年的相关数据进行分析,以客车销售量为因变量构建多元线性回归方程。
分析结果表明,民用汽车保有量和公路总里程对客车销量有着较大影响,变量间存在着线性关系。
客车生产企业在制定中长期计划和发展策略时,应重点考虑这两个变量对销量的影响。
关键词客车;销量;变量;回归分析我国客车工业起步较晚,直到20世纪90年代初,仍停留卡车底盘改装阶段,但随着经济发展和技术进步,客车行业的技术水平取得了长足的进步,随之而来的是产品产量和销量井喷式发展,逐渐成为客车生产和出口第一大国。
2005~2014年十年间,年均复合增速约10%,2014年客车销售量达到了顶峰的606918辆。
然而从2015年开始,国内客车市场容量接近饱和,销量增速转负。
2016年中国客车销售53.92万辆,同比减少9.9%。
之后更是一路下滑,2017年国内客车市场累计销售543413辆,同比下降2.98%,客车业的“严冬”仍将继续。
本文通过对中国客车销量影响因素进行研究,希望研究结果能够对客车行业的发展以及客车企业经营策略的制定提供借鉴。
1 客车销售影响因素分析我国汽车运输行业的发展与经济的发展既相互促进又相互制约,客运发展比货运发展受经济发展的影响更大,国内生产总值和汽车保有量的增长二者之间呈正相关的规律[1]。
经济的增长对客车行业发展的促进作用显著,2008年国家的“四万亿”政策大量投资导致2009年中国新建公路、改建公路分别增长23%和18%,国内客车需求在2010年得到集中释放,销量与2009年相比增长了25%[2]。
2018年前6月,累计出口客车30198辆,累计同比增长5.98%[3]。
世界經济的增长对我国客车出口的影响也不容忽视,尤其是客车出口权重最大的亚洲、美洲和非洲地区。
对美国、德国、日本、韩国等国家汽车产量增长率与实际GDP增长率都具有显著的正向相关性[4]。
交通流量预测的数学模型构建与应用

交通流量预测的数学模型构建与应用第一章:引言在当今城市化程度日益高涨的情况下,交通流量预测已经成为了一项重要的任务。
在城市交通管理中人们常常需要了解未来的交通流量,以便合理规划道路资源,制定出更加有效的交通管理策略。
因此,构建一个可靠的交通流量预测数学模型对于城市交通管理至关重要。
本文将从数学模型构建与应用两个方面探讨交通流量预测。
第二章:交通流量预测的数学模型构建2.1 多元线性回归模型多元线性回归模型是一种比较常用的交通流量预测模型,它可以分析影响预测变量的多种因素。
多元线性回归模型的基本形式为:y=a0+a1x1+a2x2+……+anxn+ε其中,y为预测变量,a是回归系数,x是自变量,ε是误差项。
对于交通流量预测模型而言,预测变量为交通流量,自变量可以是天气、时间、历史数据等。
2.2 时间序列模型时间序列模型是另一种常用的交通流量预测模型。
它根据历史数据的时间序列规律,预测未来交通流量的模型。
时间序列模型的基本形式为:yt=f(yt-1,yt-2,……)+εt其中,f是时间序列模型的函数,ε是误差项。
在时间序列模型中,yt表示当前的交通流量,yt-1、yt-2等表示过去的交通流量值。
2.3 神经网络模型神经网络模型是一种非线性模型,可以有效地逼近交通流量的复杂规律。
神经网络模型的基本结构包括输入层、隐藏层和输出层。
输入层接收交通流量的相关因素,隐藏层进行运算并产生新的变量,输出层给出预测结果。
第三章:交通流量预测的应用3.1 基于交通流量预测的交通管理策略制定交通流量预测可以帮助城市交通管理人员分析和评估不同策略对交通流量的影响。
这有助于制定更有效的交通管理策略,包括优化巡逻或巡视的时间和路线,调整交通信号灯的时间设置,优化公共交通路线等。
3.2 基于交通流量预测的交通调度基于交通流量预测的交通调度可以使交通运输更加高效。
例如,在公共交通领域,公交车可以根据预测交通流量调整开车时间和路线,保证车辆不过度拥挤,在不同高峰期合理配置车辆。
基于多元线性回归方法的城市汽车保有量预测研究以天津市为例

(2)异方差检验 对模型进行怀特检验,应用STATA软件 计算得到nR2=3.867919,在显著性水平0.05下 得到x20m(7)=14.25,因为nR2=3.867919<
x‰(7)=14.25,所以原假设成立,该模型
不存在异方差。 (3)自相关检验 应用D.w.法进行自相关检验,依据修正 后的多重共线性的结果可得DW=1.846879,
圈圜墨亘
DOI:10.3969/j.issn.1009-847X.2013.09.009 众的购买力有密切关系,因此本 文将城镇居民家庭人均可支配收
譬/B息
么丽欣 张海波 白 辰
入、燃料动力购进价格指数、城 区建成面积、公路里程以及政策 因素等几个与民众购买力关系密 切的指标作为模型的解释变量。 城镇居民人均可支配收入: 居民收入的高低对于民用车辆的 购买有着直接的影响,目前我国
从回归结果来看,解释变量x,的参数t检 验不显著。因此我们需要对上述模型进行计 量经济学检验并进行修正,从而使得模型能 够得到改进。因此剔除x,重新进行计算,得 到修正后的回归方程:
是因为天津市高峰时段的拥堵路段主要集中 在商业区和火车站等市区地段,新修建的公 路虽然能在一定程度上缓解道路拥堵,但是 并不能从根本上解决城市交通的堵塞问题, 因此新建公路并不能有效地激励普通市民购
[4】古继宝,亓芳芳,吴剑琳.基于Gompertz模型的中 国民用汽车保有量预测.技术经济,2010(1):57—62. [5】天津市社科院.天津市经济社会形势分析与预 测:2012年经济社会蓝皮书,天津社会科学院出版社,
2】3
2008年前杂志
逛街血拼、淘宝下单 不如买《汽车工业研多黔杂志回家。
42汽车工业研究・月刊2013年第9期
高速公路客流预测模型研究

高速公路客流预测模型研究近年来,高速公路建设进展迅速,交通的便利性也得到了大幅提升。
随着人们生活水平的提高,越来越多的人选择自驾出游。
高速公路客流量也随之增长,而如何对未来的客流进行准确预测,成为了一个重要的研究方向。
客流预测模型是指根据历史的交通量以及当日的天气、地理位置等多种因素,预测未来一段时间内通过某一交通节点的人数。
在这个模型中,历史数据是一个非常关键的因素,因为历史数据中包含了大量的交通信息,是对未来交通变化的一个参考。
目前,对于交通预测模型的研究主要分为两种方法,一种是基于传统的统计学方法,另一种则是基于机器学习。
传统的统计学方法主要是通过多元线性回归、时间序列分析等方式,来对交通数据进行分析和预测。
其优点在于精度较高、能够充分利用历史数据,但其缺点也比较明显,由于无法处理非线性关系以及大量的干扰因素,导致其预测精度与实际数据有差距。
另一种则是机器学习方法,其基本思想是通过大量的数据训练算法模型,来预测未来的数据,其优点在于具有能够处理非线性关系和承载大量样本数据的能力。
与传统的预测方法相比,机器学习方法在处理大量数据时,具有更高的准确度和时间效率。
在机器学习方法中,神经网络是目前比较常见的一种方法,其基本思想是通过输入历史数据进行训练,让算法学会相关规律。
在预测时,算法会根据输入的天气、时间以及经纬度等因素,预测未来的车流量。
不过神经网络模型也没有完美的解决方案。
一方面,神经网络算法需要大量的数据以及训练时间;而另一方面,当出现异常情况时,模型也容易失灵。
因此,在当前的研究中,更多的学者将目光聚焦在多种方法的结合上。
例如,神经网络算法与时间序列方法相结合,不仅增加了算法的精准度,还能够更好地处理复杂的数据关系。
在这种方法中,时间序列不仅仅只是为了预测未来的数据,还可以用来对历史数据进行分类和优化。
此外,人工智能与大数据处理的结合也为客流预测提供了新的思路。
在这一领域,数据的处理和分析能力至关重要,而大型数据库和云计算技术的应用,则能够显著提升数据处理的速度和精度。
一种基于多元线性回归算法的车流量预测模型研究

一种基于多元线性回归算法的车流量预测模型研究作者:刘畅马韵洁黄翔来源:《电子技术与软件工程》2016年第21期摘要城市交通问题已经成为国民经济进一步发展的瓶颈问题。
在城市交通系统中,道路的机动车拥堵是一种常见的严重情况,它对正常交通运行的危害性极大。
机动车拥堵是指,道路交通中,由于车辆过多,运行混乱而造成的非正常的使大批车辆长时间停滞,而无法到达目的地的现象。
拥堵现象具有突变性和趋恶性,对于道路拥堵的治理,要防重于治,能事先发出预警信号,采取预防措施,诱导车辆进行合理道路分配行驶,加强秩序管理等,来防止拥堵的产生与缓解拥堵程度。
【关键词】城市交通道路拥堵拥堵预警据专家分析,在未来城市化过程中,以大城市人口为主体的格局将会持续下去。
由于人口激增导致交通需求的不断增加,我国机动车拥有量及道路交通量也在急剧增加。
交通供需的不平衡导致了交通拥挤,甚至是交通阻塞。
交通拥挤的直接危害是使交通延误增大,行车速度降低,带来时间损失;低速行驶增加耗油量,导致燃料费用的增加和汽车尾气排污量的增加。
同时,交通拥挤也使事故增多,而交通事故的发生又使交通阻塞加剧,形成恶性循环。
交通拥挤的加剧,不仅造成巨额的直接或间接经济损失,而且在严重时会造成城市交通功能的瘫痪。
本文采用线性回归方法实现对某条道路或者某片区域内的车流量及拥堵情况的预测,为道路交通的管理决策提供参考依据,为出行者的行车路线进行前期规划,亦可为道路设计、红绿灯时间设置等提供设计依据。
1 车流量预测模型1.1 系统综述如图1所示,用户首先输入所要预测区域的卡口编号,然后输入所要预测流量变化的时间区间,即可实现车流量的预测,并将车流量的预测结果展示在页面上,方面使用者直观的查看。
具体如下:输入:输入用户需要查询的卡口号、起止时间及时间间隔,对过车的平均速度进行查询。
选择卡口:通过在GIS上选择要查看的卡口,将卡口号代入到流量预测页面的卡口输入框中。
选择要预测的卡口号,点击确定按钮进入过车流量预测页面;点击取消按钮重新选择卡口。
多元线性回归分析预测法

多元线性回归分析预测法(重定向自多元线性回归预测法)多元线性回归分析预测法(Multi factor line regression method,多元线性回归分析法)[编辑]多元线性回归分析预测法概述在市场的经济活动中,经常会遇到某一市场现象的发展和变化取决于几个影响因素的情况,也就是一个因变量和几个自变量有依存关系的情况。
而且有时几个影响因素主次难以区分,或者有的因素虽属次要,但也不能略去其作用。
例如,某一商品的销售量既与人口的增长变化有关,也与商品价格变化有关。
这时采用一元回归分析预测法进行预测是难以奏效的,需要采用多元回归分析预测法。
多元回归分析预测法,是指通过对两上或两个以上的自变量与一个因变量的相关分析,建立预测模型进行预测的方法。
当自变量与因变量之间存在线性关系时,称为多元线性回归分析。
[编辑]多元线性回归的计算模型[1]一元线性回归是一个主要影响因素作为自变量来解释因变量的变化,在现实问题研究中,因变量的变化往往受几个重要因素的影响,此时就需要用两个或两个以上的影响因素作为自变量来解释因变量的变化,这就是多元回归亦称多重回归。
当多个自变量与因变量之间是线性关系时,所进行的回归分析就是多元性回归。
设y为因变量,为自变量,并且自变量与因变量之间为线性关系时,则多元线性回归模型为:其中,b0为常数项,为回归系数,b1为固定时,x1每增加一个单位对y的效应,即x1对y的偏回归系数;同理b2为固定时,x2每增加一个单位对y的效应,即,x2对y的偏回归系数,等等。
如果两个自变量x1,x2同一个因变量y呈线相关时,可用二元线性回归模型描述为:其中,b0为常数项,为回归系数,b1为固定时,x2每增加一个单位对y的效应,即x2对y的偏回归系数,等等。
如果两个自变量x1,x2同一个因变量y呈线相关时,可用二元线性回归模型描述为:y = b0 + b1x1 + b2x2 + e建立多元性回归模型时,为了保证回归模型具有优良的解释能力和预测效果,应首先注意自变量的选择,其准则是:(1)自变量对因变量必须有显著的影响,并呈密切的线性相关;(2)自变量与因变量之间的线性相关必须是真实的,而不是形式上的;(3)自变量之彰应具有一定的互斥性,即自变量之彰的相关程度不应高于自变量与因变量之因的相关程度;(4)自变量应具有完整的统计数据,其预测值容易确定。
基于多元线性回归模型的澜沧江—湄公河客运量预测

基于多元线性回归模型的澜沧江—湄公河客运量预测作者:谭家万等来源:《水运管理》2015年第02期【摘要】选取2005―2013年澜沧江流域客运量及云南省相关统计数据为样本数据,建立澜沧江-湄公河客运量多元线性回归预测模型,对模型精度进行检验。
根据澜沧江水路客运量预测结果,历史实际值与拟合值贴合较好,表明所建立的模型具有较高的实用性和可靠性,对澜沧江-湄公河水路客运及相关行业的发展具有一定的导向作用。
【关键词】澜沧江;水路客运量;多元线性回归预测模型0 背景水路客货运量预测分析工作是航运生产经营活动的重要环节,是航运规划、统计工作的重要组成部分。
加强水路客运量预测分析工作,及时掌握水路运输市场发展动态和需求,是水路运输业积极适应市场环境、在竞争中找准发展方向的有效途径,也是实现跨越式发展、制定相应措施、使有限的水上运输资源发挥更大作用的基础和重要环节。
澜沧江-湄公河作为一条流经东南亚6个国家的重要国际河流,不仅是我国通向中南半岛乃至东南亚的中轴线,而且是连接东盟与我国的重要水路通道,又是发展潜力最大、运输成本最低的黄金水道。
澜沧江-湄公河区域各国之间的经济、文化合作如火如荼地开展,水上运输发展迅速,加快该水运大通道建设对促进沿岸各国深化合作、巩固长久的睦邻友好关系具有重大而深远的意义。
因此,为了满足该区域经济社会发展对水上交通运输的需求,科学、准确地预测客运量成为一项重要的研究课题,可以作为我国加快澜沧江航运开发建设决策、综合交通运输布局的重要依据,可以为区域水运交通规划和管理提供必要的依据。
本文通过建立澜沧江-湄公河客运量多元线性回归模型,利用模型进行预测,并对模型精度进行检验。
1 澜沧江-湄公河客运量多元线性回归预测模型的构建目前,预测水运客运量的方法有很多种,如回归分析法、指数平滑法、灰色预测法等。
多元线性回归预测模型因具有模型简洁、预测精度较高等优点而最为常用,本文将利用多元线性回归模型预测澜沧江-湄公河客货运量。