分布式共享存储器
分布式(计算机的一种算法)

分布式存储系统
P2P数据存储 系统
云存储系统
P2P数据存储系统采用 P2P网络的特点,即每个用户都是数据的获取者和提供者,没有中心节点,所以每个 用户都是对等存在的。利用这种特点建立而成的P2P数据存储系统可以将数据存放于多个对等节点上,当需要数 据时,可以利用固定的资源搜索算法寻找数据资源,从而获取想要的数据。
分布式(计算机的一种算法)
计算机的一种算法
目录
01 分布式计算
03 应用方向,它研究如何把一个需要非常巨大的计算能力才能解决的问题分成 许多小的部分,然后把这些部分分配给多个计算机进行处理,最后把这些计算结果综合起来得到最终的结果。分 布式网络存储技术是将数据分散地存储于多台独立的机器设备上。分布式网络存储系统采用可扩展的系统结构, 利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,不但解决了传统集中式存储系统中单存储服 务器的瓶颈问题,还提高了系统的可靠性、可用性和扩展性。
传统的集中式GIS起码对两大类地理信息系统难以适用,需用分布式计算模型。第一类是大范围的专业地理 信息系统、专题地理信息系统或区域地理信息系统。这些信息系统的时空数据来源、类型、结构多种多样,只有 靠分布式才能实现数据资源共享和数据处理的分工合作。比如综合市政地下管网系统,自来水、燃气、污水的数 据都分布在各自的管理机构,要对这些数据进行采集、编辑、入库、提取、分析等计算处理就必须采用分布式, 让这些工作都在各自机构中进行,并建立各自的管理系统作为综合系统的子系统去完成管理工作。而传统的集中 式提供不了这种工作上的必要性的分工。第二类是在一个范围内的综合信息管理系统。城市地理信息系统就是这 种系统中一个很有代表性的例子。世界各国管理工作城市市政管理占很大比例,城市信息的分布特性及城市信息 管理部门在地域上的分散性决定了多层次、多成份、多内容的城市信息必须采用分布式的处理模式。
ONEStor分布式存储系统介绍
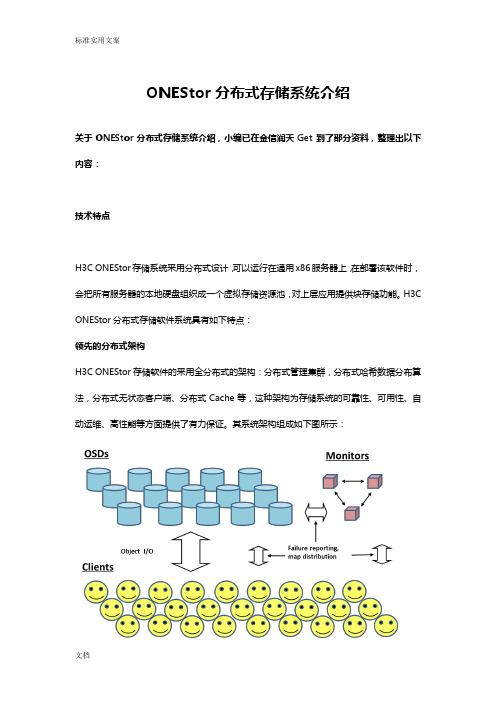
ONEStor分布式存储系统介绍关于ONEStor分布式存储系统介绍,小编已在金信润天Get到了部分资料,整理出以下内容:技术特点H3C ONEStor存储系统采用分布式设计,可以运行在通用x86服务器上,在部署该软件时,会把所有服务器的本地硬盘组织成一个虚拟存储资源池,对上层应用提供块存储功能。
H3C ONEStor分布式存储软件系统具有如下特点:领先的分布式架构H3C ONEStor存储软件的采用全分布式的架构:分布式管理集群,分布式哈希数据分布算法,分布式无状态客户端、分布式Cache等,这种架构为存储系统的可靠性、可用性、自动运维、高性能等方面提供了有力保证。
其系统架构组成如下图所示:上图中,ONEStor逻辑上可分为三部分:OSD、Monitor、Client。
在实际部署中,这些逻辑组件可灵活部署,也就是说既可以部署在相同的物理服务器上,也可以根据性能和可靠性等方面的考虑,部署在不同的硬件设备上。
下面对每一部分作一简要说明。
OSD:Object-based Storage DeviceOSD由系统部分和守护进程(OSD deamon)两部分组成。
OSD系统部分可看作安装了操作系统和文件系统的计算机,其硬件部分包括处理器、内存、硬盘以及网卡等。
守护进程即运行在内存中的程序。
在实际应用中,通常将每块硬盘(SSD或HDD)对应一个OSD,并将其视为OSD的硬盘部分,其余处理器、内存、网卡等在多个OSD之间进行复用。
ONEStor存储集群中的用户都保存在这些OSD中。
OSD deamon负责完成OSD的所有逻辑功能,包括与monitor和其他OSD(事实上是其他OSD的deamon)通信以维护更新系统状态,与其他OSD共同完成数据的存储和维护,与client通信完成各种数据对象操作等等。
Monitor:Monitor是集群监控节点。
Monitor持有cluster map信息。
所谓Cluster Map,粗略的说就是关于集群本身的逻辑状态和存储策略的数据表示。
分布式存储管理在多核设计中的高层建模

,
摘
要 :该文提 出了将分布式存储管理系统融入基 于 Smuik的多核设计流程 的方法,改变 了多核设计中数据通 i l n
信部分采用全局存储a( FF ) G IO 来完成的做法,提高了系统问通信的效率。针对 Moi E t n P G解码器的实验结果 oJ
表明, 分布式存储管理系统使各个子系统之间的通信效率相对于 GF F I O提高了 5 %, 0 解码时间降低 了 3 %。 0 同时, 分布式存储管理系统 作为库单元加入到多核设计流程中,为高效、快速地完成高性能多核 设计提供 了便利 。 关键词 :分布式存储管理 :多核设计;MoinJ EG解码器 t —P o
第 3 卷 第 1 期 0 1
电
子
与
信
息
学
报
Vl .0 . 1 0 3 No 1 1 NO 2 0 V. 0 8
20 年 1 月 08 1
J u n l f e t o is& I f r to c n lg o r a c r n c o El n o ma i n Te h o o y
中图分类号 :T 36 P 3
文献标识码 :A
文章编号:10. 9( 0)1 70 5 095 62 81— 5— 8 0 2 0
Dit i t d M e o y S r ie M o ei g i u t・ o e s rD e i n srbu e m r e v c d ln n M liPr c s o sg
XSKY 分布式存储解决方案

XSKY 2016 年 10 月 将 Ceph 的 InfiniBand/RDMA互联共享给upstream。
产品以Ceph为引擎,构建企业级分布式存储产品
• 企业级接口,FC和iSCSI,多路径 • 高性能,低延时、百亿级文件对象 • 持续服务,高水平SLA和业务QoS保证 • 易运维,全图形化操作,0命令行运维 • 内置数据保护功能,一站式解决数据安全问题
X-EBS 是专门为大并发,高性能,高 压力,弹性扩展需求的客户所量身定 做的解决方案产品。
应用场景:虚拟化 / 数据库 / 结构化 数据 / 部分替代SAN
X-EDP是一个真正的统一存储,实现 了同一套存储系统向上层应用同时提 供块、文件和对象三种数据服务,满 足业务对结构化、半结构化、非结构 化数据的存放需求。
全球存储市场发展趋势:分布式存储快速成长
当前
基于标准服务器的软件定义存储(SDS)逐渐取代专用存储
未来10年全球企业分布式存储市场快速增长,预计2027将占存储市场的70%份额
XSKY 产品介绍
融合架构 – Software Defined Device
Radio
PSP
MP3 Games Camera Video
性能优化: • 4K随机写IOPS提升20%; • IO延时降低15% • CPU利用率降低40% • 内存使用至少减少2/3 支持在线升级
支持Xen、Hyper-V
完美的支持Xen、Hyper-V
全图形化运维
准备硬件
安装OS 安全与密钥配置
NTP配置
安装XSKY软件包 Web集中配置集群
集群其他节 点就绪
Bigtable结构化数据的分布式存储系统

Bigtable结构化数据的分布式存储系统摘要Bigtable是设计用来管理那些可能达到很大大小(比如可能是存储在数千台服务器上的数PB的数据)的结构化数据的分布式存储系统。
Google的很多项目都将数据存储在Bigtable 中,比如网页索引,google 地球,google金融。
这些应用对Bigtable提出了很多不同的要求,无论是数据大小(从单纯的URL到包含图片附件的网页)还是延时需求。
尽管存在这些各种不同的需求,Bigtable成功地为google的所有这些产品提供了一个灵活的,高性能的解决方案。
在这篇论文中,我们将描述Bigtable所提供的允许客户端动态控制数据分布和格式的简单数据模型,此外还会描述Bigtable的设计和实现。
1.导引在过去的2年半时间里,我们设计,实现,部署了一个称为Bigtable的用来管理google 的数据的分布式存储系统。
Bigtable的设计使它可以可靠地扩展到成PB的数据以及数千台机器上。
Bigtable成功的实现了这几个目标:广泛的适用性,可扩展性,高性能以及高可用性。
目前,Bigtable已经被包括Google分析,google金融,Orkut,个性化搜索,Writely 和google地球在内的60多个google产品和项目所使用。
这些产品使用Bigtable用于处理各种不同的工作负载类型,从面向吞吐率的批处理任务到时延敏感的面向终端用户的数据服务。
这些产品所使用的Bigtable集群也跨越了广泛的配置规模,从几台机器到存储了几百TB数据的上千台服务器。
在很多方面,Bigtable都类似于数据库:它与数据库采用了很多相同的实现策略。
目前的并行数据库和主存数据库已经成功实现了可扩展性和高性能,但是Bigtable提供了与这些系统不同的接口。
Bigtable并不支持一个完整的关系数据模型,而是给用户提供了一个可以动态控制数据分布和格式的简单数据模型,允许用户将数据的局部性属性体现在底层的数据存储上。
FusionStorage分布式存储方案建议书

FusionStorage分布式存储系统基于分布式处理技术、虚拟化技术和集群技术实现,作为云计算资源池存储资源池的一部分,为计算资源池提供高速、可靠、安全的块存储服务。
1.2
XXX单位,对存储性能、可靠性、备份的需求如下,需要根据具体的项目进行修改:
承载的业务类型需求
本次项目要求分布式存储基于通用的X86服务器,将服务器上物理硬盘,通过多副本的技术组成存储资源池。该资源池可以为下面两类计算资源池提供块存储服务
存储块512KB的情况下,IOPS不小于XXXIOPS
CPU利用率:<=60%
内存利用率:<=60%
可靠性需求
副本要求:2/3副本
支持服务器级安全及机柜级安全
网络与硬件设备需求
本项目资源池的设备包含XXX
数据备份恢复需求
提供对分布式存储节点设备内的配置信息、管理信息、日志数据、用户信息、设备管理信息等需要备份的数据备份。
VBS
Virtual Block System
虚拟块存储管理组件,负责卷元数据的管理,提供分布式集群接入点服务,使计算资源能够通过VBS访问分布式存储资源。每个节点上默认部署一个VBS进程,形成VBS集群。节点上也可以通过部署多个VBS来提升IO性能。
oracle实现分布式数据存储的方法

oracle实现分布式数据存储的方法以Oracle实现分布式数据存储的方法随着大数据时代的到来,数据存储和处理的需求越来越复杂。
传统的单机存储方案已经无法满足大规模数据的处理需求,因此分布式数据存储成为了一种重要的解决方案。
Oracle作为一种主流的数据库管理系统,也提供了丰富的功能和工具来支持分布式数据存储。
一、概述分布式数据存储是将数据分散存储在多个计算节点上,实现数据的分布式管理和处理。
在Oracle中,可以使用以下方法来实现分布式数据存储:1. 分区表(Partitioning):通过将表按照某个列进行分区,将数据分散存储在不同的分区中。
这样可以提高查询性能,同时也方便数据的管理和维护。
2. 集群(Cluster):将多个计算节点组成一个集群,共享存储资源和计算资源。
Oracle提供了Real Application Clusters(RAC)来支持数据的并行处理和高可用性。
3. 数据复制(Data Replication):将数据复制到多个节点上,实现数据的冗余存储和故障恢复。
Oracle提供了Streams和GoldenGate等工具来支持数据的复制和同步。
4. 分布式数据库(Distributed Database):将数据分布在多个数据库中,实现数据的分布式管理和跨节点查询。
Oracle提供了Database Links和Transparent Gateways等工具来支持分布式数据库的搭建和管理。
二、分区表的实现分区表是将表按照某个列进行划分,将数据分散存储在不同的分区中。
Oracle提供了多种分区方式,包括范围分区、列表分区、哈希分区和复合分区等。
通过分区表,可以实现数据的快速查询和管理。
例如,可以根据时间范围对表进行分区,将不同时间段的数据存储在不同的分区中。
这样可以提高查询性能,同时也方便数据的归档和删除。
三、集群的搭建集群是将多个计算节点组成一个集群,共享存储资源和计算资源。
02325自考计算机系统结构知识点整理脑图
寻址方式
寻址技术
堆栈寻址
直接定位方式 静态定位方式 动态定位方式
定位方式
固定长操作码
huffman编码法
扩展编码法
零、一、二、三
地址码个数
用间接寻址
用变址寻址
缩短地址码长度方法
用寄存器间接地址
操作码 地址码
指令格式设计
传送类指令 运算类指令 程序控制类指令 输入输出指令 控制、调试指令
基本指令系统
传送类指令
全cache
提高主存容量
总线系统
专用总线
控制方式
非专用总线 通信技术
同步通信 异步通信
分布式 集中式
串行链接 定时查询 独立请求
单向源控 单向目控 双向非互锁 双向互锁
中断系统: 中断处理程序和中断 响应硬件的功能分配
中断的概念: CPU中止正在执行的程序,转去处理随机提出的请求,待处理完后,再回到原先被打断 的程序继续恢复执行的过程
访主存冲突
分析与执行操作的并行
分析与执行操作控制上的同步
重叠
计算机组成上需满足的条件
转移指令
指令间相关处理
指令相关 主存空间数相关
通用寄存器组相关
流水介绍 性能参数 流水 相关处理
高度并行超处理机
局部相关处理
猜测法
全局相关处理
提前形成条件码 采取延迟
加快短循环程序处理
流水机器的中断处理
非线性流水线的调度
运算类指令
目标程序的优化
程序控制指令
高级语言和编译程序的优化
操作系统的优化
延时转移技术
指令取消技术
重叠寄存器窗口技术
关键技术
指令流调整技术
硬件为主固件为辅