虚拟数据库的实现方法
内存当硬盘用的方法

内存当硬盘用的方法引言随着计算机技术的发展,存储设备也得到了极大的改进和提升。
传统的硬盘作为主要的存储介质逐渐受到限制,而内存作为临时存储器的作用也受到了广泛关注。
本文将介绍一些将内存用作硬盘的方法,通过优化内存的使用,提高计算机的性能和效率。
1. 使用虚拟内存虚拟内存是一种将硬盘空间扩展到内存的方法,通过将内存中暂时不使用的数据交换到硬盘上,以释放内存空间。
虚拟内存的使用可以提高计算机的性能,但也存在一定的缺点,如访问速度较慢等。
1.1 设置虚拟内存大小在Windows系统中,可以通过调整虚拟内存的大小来提高计算机的性能。
通常,将虚拟内存的初始大小设置为物理内存的1到1.5倍,将最大大小设置为物理内存的2到3倍。
1.2 调整虚拟内存的位置将虚拟内存设置在不同的物理硬盘上可以分散IO负载,从而提高计算机的性能。
可以通过更改Windows系统的设置来调整虚拟内存的位置。
2. 使用内存缓存内存缓存是一种将部分数据存储在内存中的方法,以加快数据的读取速度。
通过将经常访问的数据放在内存中,可以减少硬盘IO操作,提高计算机的响应速度。
2.1 优化操作系统的内存缓存设置在Windows系统中,可以通过更改注册表来优化系统的内存缓存设置。
例如,可以调整文件系统缓存的大小,提高系统的读取速度。
2.2 使用缓存软件除了操作系统的内存缓存外,还可以通过使用专门的缓存软件来加速计算机的读写操作。
这些软件通常具有高速缓存和一些智能算法,可以根据访问模式和数据类型来优化缓存效果。
3. 使用内存数据库内存数据库是一种将数据存储在内存中的数据库管理系统。
与传统的磁盘数据库相比,内存数据库具有更快的读写速度和更低的延迟。
3.1 内存数据库的应用场景内存数据库适用于对读写性能要求较高的应用场景,如金融交易系统、实时分析系统等。
由于内存数据库的读写速度非常快,可以大大提高系统的响应速度。
3.2 内存数据库的优势和挑战内存数据库具有许多优势,如快速读写、低延迟、高并发性等。
用LabVIEW实现虚拟仪器测试系统与数据库之间的数据交换

0 引 言
中必 须解 决 专业软 件 和数 据 库 之间 的数 据 传输 和 调
用 问题 。
传 统 的测试系统 由模 拟仪 表或数 字仪表 组成 . 难
以适应 目前科 技开发及 工业 领域 提出 的快 速 、准确 、
高 精 度 测 量 的 需 要 。 目前 , 测试 技 术 和 计 算 机 技 术 结
统 . 提 供 了 一种 全 新 的程 序 编 写 方 法 . 对 被 称 之 它 即
L b IW 软 件与 数据 库有 两种数 据 交换 方式 : a VE ① 将 L b IW 生 成 的 文本 文 件 中 的数 据 和以 其 生 成 a VE 的 以电子表格 形式存储 的数据 导人数 据库 中 : 从 数 ② 据库里 导 出数 据到 L b E 程序 中。这两 种不 同的 a VlW 交换方式 各有 其 自身 的特点 , 面分别加 以介 绍 。 下 11 将 文本文件 中 的数据 和 以电子 表格形 式存 储 的 数 据导 人数据库 L b IW 软 件的强 大 功能 归因 于它 的层 次化结 a VE 构, 用户 可以把创 建 的 V 程 序 当作子 程序 调用 . l 以创 建更 复杂 的程序 .而这 种调 用的层 次是 没有 限制的 。 因此 在将数 据写人 数据 库 时 . 可以调 用三 个子 程序来 完 成。这 三个子 程序分 别为 DD e o v a E Op n C n es — r
摘
要
盘 文 绍 了虚 拟 仪 器信 号 检 测 系统 调 用数 据库 方 面 的应 用 具体 内客 包括 用 L b IW 将 数 据 文 件 导凡 数 据 库 和 a VE 将 数据 库 中的 数 据 文件 导 出到 L b IW 程序 中 一 奉文 同寸 介 绍 了 L b fW 软 件 和 数 据库 中宏 的使 用 a VE a VE 关 键 词 : 试 , 社 扭 器 . 括 库 测 虚 数
数据库灾备方案的实现

数据库灾备方案的实现数据库灾备是指为了保障数据库系统的正常运行和数据的安全性,在遭受灾难性事件影响时能够快速恢复数据库系统的正常运行,保证业务的连续性和数据的完整性。
在现代信息化时代,数据库灾备方案的实现显得尤为重要,本文将介绍数据库灾备方案的基本原理和常见的实现方法。
一、数据库灾备方案的基本原理数据库灾备方案的实现基于以下基本原理:1. 数据备份与恢复:数据库灾备方案的核心是对数据库进行定期备份,并能在遭受灾难性事件后迅速恢复数据。
数据备份可以通过物理备份、逻辑备份或快照技术实现。
2. 数据同步与复制:为了保证备份数据的实时性和一致性,数据库灾备方案通常采用主备或主从复制的方式,将主数据库的数据实时同步到备份数据库,以保证备份数据的及时性和准确性。
3. 故障切换与恢复:当主数据库发生故障,数据库灾备方案需要能够自动或手动触发故障切换,将备份数据库切换为主数据库,以确保业务的连续性和数据的可用性。
4. 灾难恢复与测试:数据库灾备方案还需要包括针对不同灾难情景的恢复计划和测试方案,以保证在实际灾难发生时能够快速、准确地进行灾难恢复。
二、数据库灾备方案的实现方法根据数据库系统的特点和实际需求,可以采用多种不同的数据库灾备方案。
以下是常见的数据库灾备方案实现方法:1. 冷备份与热备份:冷备份是指将数据库停用后进行备份,而热备份则是在线备份。
冷备份相对简单,但会造成业务中断;热备份需要使用数据库系统的高可用特性,可以在备份过程中保持数据库的正常运行。
2. 数据镜像与复制:数据镜像是指将主数据库的数据实时复制到备份数据库,以保证数据的完整性和实时性。
常见的数据库镜像技术有数据库的物理复制和逻辑复制。
3. 容灾备份与异地备份:容灾备份是将主数据库的备份数据存储在多个不同地点的备份设备上,以防止地域性的灾难;异地备份是将备份数据库部署在不同地域的数据中心,以提高灾备能力。
4. 高可用集群与故障切换:高可用集群是指通过多台数据库服务器组成集群,在主节点故障时自动切换到备用节点保持业务的连续性。
基于Oracle虚拟专用数据库的用户管理设计

( 州 大 学 计 算 机 科 学 与 技 术 学 院 ,贵 阳 5 0 2 ) 贵 5 0 5
摘 要 : al 虚拟 专 用数据 库通 过提 供 细粒 度访 问控 制保持 了信 息 的私 密性 . 文 介 绍 了 Or Orce 本 — a l 虚拟 专用数 据库 的特 点及 实现 过程 , 重 阐述 了在 基 于虚拟 专 用数 据库 的 管理 信 息 系统 中 ce 着
登 录 , 法 的用户 通过 E ly eI 和 C mp n — 合 mpo e—D o a y I D作 为 联 合 主 键 与 C so r 建 立 了一 多 关 u tmes表
系 , C so r 表 中就能 找到 每个雇 员 自己的客 在 u tmes 户 信息.
2 2 定 义 安 全 策 略 目标 .
维普资讯
第 2 卷 第 3 6 期
20 0 8年 6月
凯 里 学 院 学 报
J u n l fKalUnv riy o ra i iest o i
VoL 26 N O .3
Jn 2 0 u.08
基 于 Orce 拟 专 用数 据库 的 用户 管理 设 计 al 虚
0 引 言
中来 设置 用户 对数 据 的访 问策 略. 因为应 用程序 用 户不 是数 据库 用户 , 以这 种方 法不 能直 接利 用大 所 型数 据库 本 身提 供 的安 全 机 制 来 保 证 数据 的安 全 性; 但是 , Orc 在 al e中可 以通 过 创建 自己的应 用 程 序 上下文 , 安全 策 略 直 接 绑 定 在数 据 表 上 . 果 将 如 设 置得 当 , 们 同样 可 以使 用 VP 实 现 细粒 度 访 我 D 问控 制 , 并且 在 这种 用 户 管 理模 式下 , 数据 库 用 户 对 于应 用程 序用 户 来说 是 透 明 的 , 安全 性 更 好 , 应 用 程序 的灵 活性也 更 强 , 大减 轻 D A 的负担 . 大 B 2 虚拟 专用 数据 库 中一 多对应 的用 户管 理设 计
3D网络虚拟形象的设计与实现

3D网络虚拟形象的设计与实现3D A V ATAR系统是为了满足网络用户在虚拟世界中按自己的要求任意塑造一个全新的自我以及用自己的个性化形象来展示自我的需求而设计的系统。
本文比较详细的分析与介绍了该系统,该系统采用三层网络结构的模式,即应用层,接口层和系统存储层。
运用了VET、CGI、API、CACHE等技术和MYSQL数据库,实现了一个网络商城和一个能展现个性化形象的平台。
标签:A V ATAR;ITEM;换装;CGI;APIAbstract: 3D A V ATAR system is designed to meet the users in a virtual world in accordance with the requirements of their own arbitrary shape, as well as a new self-personalized with their own image to show the demand for self-designed system. In this paper, a more detailed analysis and introduced the system, the system uses a three-tier model of network structure, namely, application layer, interface layer and system storage layer, the use of the VET, CGI, API, CACHE, such as technology and MYSQL databases, to achieve a Internet Shopping Mall and a personalized image to show the platform.Key words: A V ATAR; ITEM; Change; CGI; APIAvatar指的是起源于韩国的一种叫做“网络化身”的在线娱乐项目,用户可以通过挑选服装、饰品、房屋、背景、宠物等自由变换自己的网络虚拟形象,用各种各样个性的物品来展现自我。
ODA七种应用场景分析v
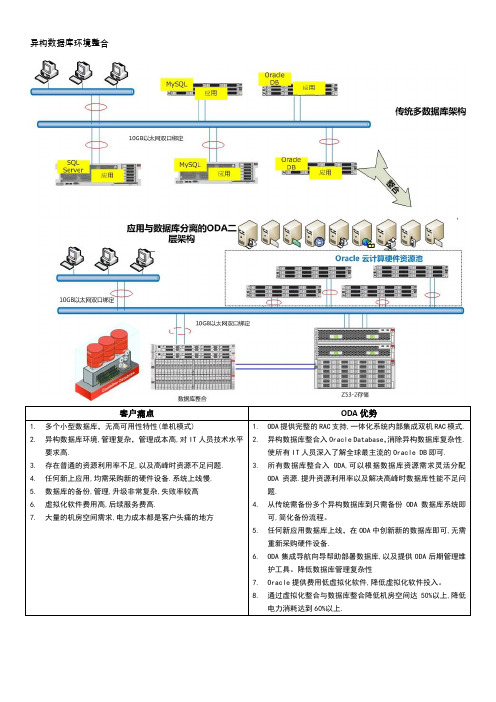
ODA 优势
客户可以将整个应用系统部署进一个 ODA 中.极致简化,二期容灾 需求中只需再购买一台 ODA 即可实现异地同步容灾. 1. 客户的容灾只需再购买一台 ODA 即可实现两台 ODA 的异地同
步/异步容灾. 2. 容灾项目中只需要购买 Oracle Database Active Data Guard 功能
总部工程师经常出差维护费用太高.
要 4U 空间.
3. 希望分支机构的 IT 硬件设备数量越少越好。节约开支.
3. 相对传统方式需要管理 9 个设备简化到只需管理 1 个设备即
4. 不希望给每个分支机构配置一个备份系统.希望集中备份
可.
4. ODA 具体极强的虚拟化能力,用户可以将应用与数据库整合在
一起,单一设备即可完成分支机构大部分 IT 应用的部署。
客户痛点
ODA 优势
客户需要新建一个小型应用系统(校园一卡通,HIS,中小型 ERP,中小 客户可以将整个应用系统部署进一个 ODA 中.极致简化
型 CRM 系统)
1. ODA 仅需 4U 空间,将 22U 的传统架构整合进去.节约了 80%空
1. 新系统需要占用 22U 机房空间,电力消耗成本过高.
高成长性客户应用分析
IBM 传统解决方案
Oracle 集成化解决方案
客户需要上一套新的业务系统,该业务系统具有以下特点 1. 客户的业务弹性非常大,即在未来可能会出现爆发性增长.传统的 IT 架构可能无法满足客户未来的业务需求.(需求) 2. 未来可能需要在每个分支机构部署该系统。并需要将数据上传至总部.(需求) 3. 总部需要将对所有分支机构进行异地容灾,并对安全性要求极高.(可能需求) 4. 未来可能需要在总部进行业务智能分析,为战略决策提供支撑.(可能需求) IBM 解决方案
labview数据库
LabVIEW中访问数据库的几种不同方法虚拟仪器VI(Virtual Instruments)是National Instruments公司在其产品LabVIEW中首先提出的创新概念[1]。
虚拟仪器系统的概念是测控系统的抽象。
不管是传统的还是虚拟的仪器,它们的功能都是相同的:采集数据并进行分析处理,然后显示处理的结果。
它们之间的不同主要体现在灵活性方面。
虚拟仪器由用户自己定义功能,可以自由地组合计算机平台、硬件、软件以及完成应用系统所需要的各种功能。
另外,虚拟仪器开发周期短、成本低、维护方便,易于应用新理论和新技术实现仪器的换代升级[2]。
现代的测试测量系统大多数需要对被测对象进行全方位检测,这必然会使获取的数据量急剧增长。
面对大量的数据信息,采用数据库技术,可准确反映各类数据之间的密切联系,能够有效地管理和组织数据,是现代测试测量系统的发展趋势。
但是现有的LabVIEW版本本身并不具备数据库访问功能,不能像VB、VC++、Delphi、PowerBuilder那样非常方便的进行数据库程序的开发。
因此以LabVIEW编制的虚拟仪器系统需要其它辅助的方法来进行数据库访问。
1、在LabVIEW中访问数据库的方式(1)利用NI公司的附加工具包中的数据库接口工具包LabVIEW SQL Toolkit进行数据库访问。
该工具包集成了一系列的高级功能模块,这些模块封装了大多数的数据库操作和一些高级的数据库访问功能。
它的优点是易于理解,操作简单,用户可以不学习SQL语法。
缺点是需要另外购买且价格昂贵,无疑会增加系统成本。
(2)利用LabVIEW的ActiveX功能,调用Microsoft ADO对象,利用SQL语言实现数据库的访问。
使用这种方法需要用户对Microsoft ADO以及SQL语言有较深的了解。
(3)通过第三方开发的免费工具包LabSQL访问。
LabSQL利用Microsoft ADO以及SQL语言来完成数据库访问,将复杂的底层ADO及SQL操作封装成一系列的LabSQL VIs,简单易用。
数据库常用的备份和恢复方法
数据库常用的备份和恢复方法1. 备份方法:使用数据库管理系统自带的备份工具,如MySQL的mysqldump命令或SQL Server的Backup Database语句。
描述:数据库管理系统提供了备份工具,可以将数据库的数据和结构导出为一个备份文件,通常以.sql格式保存。
用户可以定期使用这些备份工具进行全量备份或增量备份。
2. 备份方法:使用文件系统级别的数据复制工具进行备份,如使用rsync或Windows 的文件复制功能。
描述:可以通过文件系统级别的复制工具将数据库的文件直接复制到其他存储设备上,实现备份目的。
这种备份方法适用于非常大的数据库,因为它可以减少备份和恢复所需的时间。
3. 备份方法:使用虚拟机快照进行备份。
描述:如果数据库运行在虚拟机上,可以使用虚拟机快照功能来创建数据库的备份。
快照是虚拟机当前状态的拷贝,可以在需要的时候还原到该状态。
4. 备份方法:使用存储级别的快照功能进行备份。
描述:一些存储设备提供了快照功能,可以在存储级别对数据库进行备份。
这种备份方法通常能够在不影响数据库性能的情况下实现备份,而且可以实现非常快速的恢复。
5. 备份方法:使用第三方备份工具进行备份。
描述:市面上有许多第三方备份工具,可以根据实际需求选择适合自己数据库的备份工具。
这些备份工具通常提供更加灵活和高级的备份和恢复功能。
6. 恢复方法:使用数据库管理系统自带的恢复工具进行数据库的还原。
描述:数据库管理系统自带的恢复工具可以将备份文件中的数据和结构导入到数据库中,还原成原来的状态。
7. 恢复方法:使用事务日志进行数据库的恢复。
描述:数据库管理系统中的事务日志记录了数据库的变更历史,可以利用事务日志进行数据库的恢复,还原到数据库崩溃前的状态。
8. 恢复方法:使用数据库管理系统提供的点对点恢复工具进行数据库的恢复。
描述:一些数据库管理系统提供了特殊的恢复工具,可以直接从备份文件中进行点对点恢复,即将备份数据直接还原到生产环境中。
一种实现Apache Kylin数据脱敏的方法和系统
一种实现Apache Kylin数据脱敏的方法和系统Apache Kylin是一个开源的分布式分析引擎,专门用来处理大数据量的OLAP工作负载。
在实际生产环境中,处理敏感数据时往往需要对数据进行脱敏处理,以保护数据的隐私和安全。
本文将介绍一种实现Apache Kylin数据脱敏的方法和系统。
一种实现Apache Kylin数据脱敏的方法是使用数据库视图。
通过创建数据库视图,可以根据需要选择性地对数据进行脱敏处理。
视图是数据库中的一个虚拟表,它是由一个或多个表的字段组成的,这些字段来自于一个或多个基本表。
视图的数据是从基本表中获取的,可以对视图进行增删改查等操作,而且视图的数据与基本表的数据是一致的。
使用数据库视图对数据进行脱敏处理是一种简单且灵活的方法。
实现Apache Kylin数据脱敏的系统由以下几个部分组成:数据源、脱敏规则、数据库视图和Kylin Cube。
首先是数据源,数据源是指需要进行脱敏处理的数据所在的数据库表。
在实际应用中,数据源可以是关系型数据库(如MySQL、Oracle等)、NoSQL数据库(如HBase、Cassandra 等)或者数据仓库(如Hive、SparkSQL等)中的表。
其次是脱敏规则,脱敏规则是指对数据进行脱敏处理的具体规则。
常见的脱敏规则包括:身份证号脱敏(部分隐藏除最后四位外的数字)、手机号脱敏(部分隐藏除前三位和后四位外的数字)、银行卡号脱敏(部分隐藏除前四位和后四位外的数字)等。
根据不同的需求和场景,可以针对不同的字段应用不同的脱敏规则。
接下来是数据库视图,数据库视图是应用脱敏规则后的数据展现形式。
通过创建数据库视图,并在视图中应用脱敏规则,可以实现对数据的脱敏处理。
在创建数据库视图时,需要根据需求选择性地对字段进行脱敏处理,以保护数据的隐私和安全。
最后是Kylin Cube,Kylin Cube是Apache Kylin中的核心概念,它用于存储和管理数据的多维模型。
SQLite嵌入式数据库系统的研究与实现
实 现 的 一 种 强 有 力 的嵌 入 式 关 系 数 据 库 管 理 体 制 。 它 提 供 对 S L 2的 大 多数 支 持 :多 表 、 引 、 务 、 图 、 发 Q 9 索 事 视 触
S ie可 以分 成 8个 主 要 子 系 统 , 图 1所 示 。顶 层 QL t 如
的 限 制 , 以 随 时 随地 处 理 业 务 、 递 信 息 口 。 可 以 说 , 可 传 嵌 入 式 数 据库 的 发展 提 高 了数 据信 息 接 入 的 普 遍 性 , 人 们 使
随 时 随地 获 取 信 息 的愿 望 成 为 可能 。
和 一 系列 的 用 户 接 口及 驱 动 ] 。
用 在 掌 上 电脑 、 D 车 载 设 备 、 动 电 话 等 嵌 入 式 设 备 P A、 移
中 。这 种数 据 库 技 术 的 兴 起 使 人 们 不 再 受 单 一 操 作 系 统
21 S i . QLt 体 系结构 [ e的 3 ]
虚拟机
●
B 树驱动
●
列 指 令 。 如 此 往 复 , B 执 行 每 VD E 条 指令 , 终 完 成 S 最 QL语 句 指 定 的
页面缓冲
●
交 互 界 面 来 实 现嵌 入 式 终 端 上 的 人 机 交 互 , 通 过 串 口实 并
现和 P C机 上 主 数 据 源 之 间的 数 据 交 换 , 现 系 统 服 务 器 实
cd ) 成 。 对 于 打 开 表 、 询 索 oe 组 查
Pr r 们 刚 P … t
ቤተ መጻሕፍቲ ባይዱ
nr 薅 击 田 、 坶
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
计算机工程与设计ComputerEngineering andDesign 2010,31(14) 3201 ・软件与算法・ 虚拟数据库的实现方法
杜威 , 邹先霞 , 潘久辉 (1.广东警官学院计算机系,广东广州510232;2.暨南大学计算机系,广东广州510632) 摘要:虚拟数据库是目前信息集成的主要方法之一,但目前的虚拟数据库产品很难做到对数据源结构的屏蔽,使得系统 配置和使用不是十分方便,查询定义过程要求用户了解各个数据源及其组织结构。基于超图理论提出了一种简单可行的模 式集成方法,解决了同名异义及异名同义等问题。通过元数据库管理系统,数据库管理员可定义各种视图来屏蔽信息源的 结构,大大简化了用户的查询定义过程。同时,给出了虚拟数据库系统的主要实现技术。 关键词:虚拟数据库;协调器;超图;查询代理;无损连接 中图法分类号:TP311.131 文献标识码:A 文章编号:1000.7024(2010)14.3201.06
Implementation methods of virtual database DU Wlei , ZOU Xian.xia2,PAN Jiu.hui2 (1.Department ofComputer Science,Guandong Police College,Guangzhou 510232,China; 2.Department of Computer Science,Jinan University,Guangzhou 5 1 0632,China)
Abstract:Virtual database system is a main me ̄od ofinformation integration,but the schema ofdata source is not transparent for end user,therefore it is not convenient to configure and use,and is a challenging task to create a query in virtual database systems.The simple applied schema integration based on a theory ofhypergraph is proposed,and homonymy and synonym are resolved.DBA could define all kinds ofview based on metadata which made the users only have a cursory knowledge ofthe structure ofthe data sources.The main implementation technology ofthe system is presented. Key words:virtual database;mediator;hyper graph;query agent;lossless join
O引 言 为了对数据进行有效的集成管理成为增强企业商业竞争 力的有力手段,提出了虚拟集成和实化集成等集成技术[1-2]。 数据仓库技术实际存储各个数据源的数据,因此对用户的查 询响应快,但由于数据源的并发性和异构性,集成数据的更新 和一致性维护变得复杂 。虚拟集成通过对各个数据源的无 缝访问实现数据的集成,不存在复杂的维护过程,在企业信息 集成中受到广泛的关注。但现有虚拟集成技术如联邦数据库 主要通过维护一个全局的数据字典来保存数据源的配置信 息、数据源表的结构、字段数据类型等Ⅲ,用户基于数据字典的 内容提出各种查询,对普通用户来说,这是一个相当复杂的过 程,解决模式集成可以大大简化用户的工作 ,已有的文献侧 重于集成系统框架和理论研究 ,未能给出虚拟集成系统的整 体实现。本文基于泛关系假设和超图理论实现了一种简单有 效的模式集成方法 ,给出了虚拟集成系统的整体实现。本 系统的主要特点: (1)系统对查询用户屏蔽了底层信息源及其数据结构; (2)解决了数据库结构异构性和数据访问控制的差异; (3)实现了跨操作平台和数据库管理平台的虚拟集成。 本文介绍泛关系假设和超图的相关概念,然后叙述了虚 拟数据库的整体结构,介绍了虚拟数据库用户接口的实现,最 后给出了虚拟数据库执行引擎的实现。
1基本概念 定义1超图的数学定义如下” : 令N=ln1 ̄12,… I是一个有限集,关于N上的一个超图H= (E ,E2,'--,Em)是N上一个有限子集簇,使得: (1)层≠ ( 1,2,…, ) m (2)UE=N
J=1 为了能更清楚地描述关系模式,将超图的定义修改为:一
个超图H是一个有序对H=(N,E),其中N是顶点的集合,E是 边的集合,每条边是N的非空子集。 定义2超图的Y环定义。 超图H中的一个.r循环是一个交替序列(E n,E:,n ,…,E ,
收稿日期:2009.07.13;修订日期:2009.10.09。 基金项目:2008公安部应用创新计划基金项目(2008YYcxGDST081)。 作者简介:杜威(1974一),男,硕士,副教授,研究方向为数据集成与数据挖掘; 邹先霞(1975一),女,博士研究生,研究方向为数据库、数 据流处理等; 潘久辉(1956--),男,博士生导师,教授,研究方向为数据库、信息集成与网格计算等。E—mail:weiduzxx@163.COrn 3202 2010,31(14) 计算机工程与设计Computer Engineering and Design n ,E叶H),其中: (1)“b ̄-' ̄nm是H中不同的点; (2)E “,Em是H中不同的边,但E。=Em+。; (3)m≥3(即至少有3条边): (4)N ∈E。nE¨(1≤i≤m); (5)对于Vi,vj,l≤i≤m,1<j≤m+1,j ̄i,j ̄i+l,有n, ̄Ej。 不含Y环的数据库有一个很重要的性质:1by循环的数据 库的泛关系模式中任意的关联子模式定义了一个内嵌的连接 依赖。设R是一个关系模式(包括泛关系模式),P={x ”, )(Ⅱ),其中:Xi R(i=1,…,n),则一个内嵌的连接依赖 [p】蕴涵 了“P的每个连通子集都是无损连接的”,证明见文献[8-9]。也 就是说如果一个泛关系模式的超图是非_r循环的,那么该泛关 系模式的“分解”是无损的,对这个泛关系模式的关系实例进 行查询时,所有的查询路径(连接序列)是无损的。超图^r环定 义及判断方法为虚拟数据库的查询分解提供了理论基础。 定义3假设H=(N,E)是一个超图,其中U={a ,a2,…,ap) 是一个属性集合或泛关系模式,R={R , ,…, }是基于U的 关系模式集。完全交集图(complete intersection graph,CIG) 是 一个无向图(R,S),其中S={I =( , ): n ≠ ,R∈R, ∈ R,iCj}。其中点 和 存在边(民, )当且仅当R和 至少有 一个公共属性。完全交集图是查询分解的一种数据结构。 2虚拟数据库的结构 各大数据库厂商正在发展或已经提供了数据仓库或联邦 数据库等产品,但这些产品都是从数据源表到集成系统表之 问的映射,用户在集成系统上定义查询必须了解存在哪些信 息源及信息源的数据结构,人工判断属性间的同名异义和异 名同义等问题,使用户的一次查询过程变得非常复杂。根据 泛关系假设,我们可以将所有信息源表的属性看作一个虚拟 表,利用超图理论消除其二义性并进行无损分解,建立各种虚 拟视图。用户基于这些虚拟视图提出的各种查询,完全类似 于本地数据库的查询。虚拟数据库的结构图如图1所示。 r 数据源 、 虚拟数据库 、 I查询结果l ,[v √一J l _—— 。_1 8 8 图1虚拟数据库的结构 虚拟数据库的数据源可以是位于不同操作系统的不同数 据库系统,如Oracle for Linux、Oracle for Solaris、IBM DB2 for Windows、SQL Server等。虚拟数据库也可以放在不同的操作 系统上。 数据源通过包装器将元数据以XML文件格式集成到虚 拟数据库的元数据库。包装器用来消除各个数据库管理系统 的结构差异,如数据类型。 元数据库管理系统对接受的所有元数据信息通过泛关系 理论和超图丫环检测来消除查询二义性等问题。 查询代理实质上是一个中介器,查询代理客户端负责将 用户的查询分解到各个数据源上的子查询,由查询代理服务 器执行查询和转换,查询结果经FTP传送到虚拟数据库,查询 代理客户端对返回的结果进行合成,最后以文件或其它形式 提交给用户。
3接口设计与实现 虚拟数据库系统主要由元数据库管理系统、查询代理和 用户查询3个模块组成。 元数据库管理子系统主要对各个信息源的元数据进行管 理,检查异名同义和同名异义等二义性,并提供管理界面给系 统管理员定义各种虚拟视图。查询用户则直接在虚拟视图上 定义查询,对查询用户来说这个过程与在本地数据库定义查 询一样,而无需关心从哪个底层信息源定制信息,也无需了解 底层信息源的数据结构,因为这些结构对查询用户都是透明 的,从而大大减轻一般用户的查询复杂性。系统管理员承担 了信息集成的需求分析任务,并通过对底层数据源的分析,对 异名同义和同名异义等查询二义性进行人工干预。元数据库 管理界面和虚拟视图定义界面如图2和图3所示。
图2元数据库管理界面 图3 C/S结构的虚拟视图定义界面 查询代理完成一般用户的查询请求,由于是虚拟数据库, 一次用户查询执行要经过语法和语义检查,查询转换、查询分 解,查询执行及结果的合成等过程。词法和语法检查与数据 库系统实现过程一样,查询转换则要将用户在虚拟视图上定 义的查询转换成底层数据源上的查询,再通过查询分解模块