回归分析实验1 Eviews基本操作及一元线性回归
计量经济学实验一 一元回归模型
实验二一元回归模型【实验目的】掌握一元线性、非线性回归模型的建模方法【实验内容】建立我国税收预测模型【实验步骤】【例1】建立我国税收预测模型。
表1列出了我国1985-1998年间税收收入Y和国内生产总值(GDP)x的时间序列数据,请利用统计软件Eviews建立一元线性回归模型。
一、建立工作文件⒈菜单方式在录入和分析数据之前,应先创建一个工作文件(Workfile)。
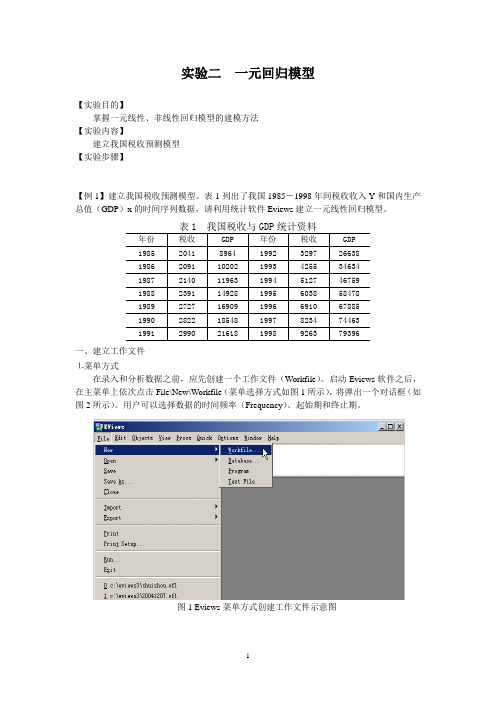
启动Eviews软件之后,在主菜单上依次点击File\New\Workfile(菜单选择方式如图1所示),将弹出一个对话框(如图2所示)。
用户可以选择数据的时间频率(Frequency)、起始期和终止期。
图1 Eviews菜单方式创建工作文件示意图图2 工作文件定义对话框本例中选择时间频率为Annual(年度数据),在起始栏和终止栏分别输入相应的日期85和98。
然后点击OK,在Eviews软件的主显示窗口将显示相应的工作文件窗口(如图3所示)。
图3 Eviews工作文件窗口一个新建的工作文件窗口内只有2个对象(Object),分别为c(系数向量)和resid(残差)。
它们当前的取值分别是0和NA(空值)。
可以通过鼠标左键双击对象名打开该对象查看其数据,也可以用相同的方法查看工作文件窗口中其它对象的数值。
⒉命令方式还可以用输入命令的方式建立工作文件。
在Eviews软件的命令窗口中直接键入CREATE命令,其格式为:CREATE 时间频率类型起始期终止期本例应为:CREATE A 85 98二、输入数据在Eviews软件的命令窗口中键入数据输入/编辑命令:DA TA Y X此时将显示一个数组窗口(如图4所示),即可以输入每个变量的数值图4 Eviews数组窗口三、图形分析借助图形分析可以直观地观察经济变量的变动规律和相关关系,以便合理地确定模型的数学形式。
⒈趋势图分析命令格式:PLOT 变量1 变量2 ……变量K作用:⑴分析经济变量的发展变化趋势⑵观察是否存在异常值本例为:PLOT Y X⒉相关图分析命令格式:SCAT 变量1 变量2作用:⑴观察变量之间的相关程度⑵观察变量之间的相关类型,即为线性相关还是曲线相关,曲线相关时大致是哪种类型的曲线说明:⑴SCAT命令中,第一个变量为横轴变量,一般取为解释变量;第二个变量为纵轴变量,一般取为被解释变量⑵SCAT命令每次只能显示两个变量之间的相关图,若模型中含有多个解释变量,可以逐个进行分析⑶通过改变图形的类型,可以将趋势图转变为相关图本例为:SCA T Y X图5 税收与GDP趋势图图5、图6分别是我国税收与GDP时间序列趋势图和相关图分析结果。
Eviews基本操作(3.1版本)

Eviews基本操作(3.1版本)一、创建工作文件一种创建方法为点击file/new/workfile,然后输入frequency,以及开始(start)日期和结束(end) 日期.(注:如果是截面数据,要选undated or irregular项,然后在start中输入1,end中输入样本容量)。
输入完毕后,点击OK就可以得到工作文件窗口。
二、导入excel文件中的数据1)在excel中先建立数据文件2)然后创建eviews工作文件3)点击file/import/read text-lotus-excel选项,在对话框中选择已建立的excel文件4)打开后,在新的对话框中输入想要分析的变量名称,然后点击OK即可。
此时工作文件中出现变量图标。
三、直接输入数据1)创建一个工作文件(方法同一)2)点击quick/empty group,打开一个空白表格3)点击ser01,把第一列全选,在命令栏中输入变量名称后回车,即可改变变量名称,按此方法命名每一变量4)删除group对话框后,会发现工作文件中多了新变量四、画图有两种方法可以将数据绘成曲线,第一种方法是:1)首先在工作文件中选中所要分析的变量,点击右键open/as group项,打开数据文件2)点击view/graph/scatter(或其它图形)后,即可画出图形3)在选中图表窗口后,在工作文件窗口点击edit/copy,在对话框中点击copy to clipboard,然后可将图表粘贴到word文档中,还可进行编辑第二种方法是:1)在工作文件窗口中点击quick/graph2)在弹出的对话框中输入想要分析的变量3)选择图表的类型及选项即可输出图表4)可将图表移动到word文档中并进行编辑(方法同上)五、数据的描述性统计量1)在工作文件中选中变量后,点击右键点open group,打开数据文件2)点击view/descriptive stats/common sample,就会出现描述性统计量3)在选中若干行统计量数据后,点击edit/copy,在弹出的对话框中点OK,然后可将其粘贴到word文档中注:Mean 样本均值Median 中位数Maximum 最大值Minimum 最小值Std. Dev. 标准差Skewness 偏度Kurtosis 峰度Jarque-Bera 正态性检验Probability P值Observations样本容量六、一元线性回归模型的估计1)建立变量的工作文件2)在主菜单上选择quick/estimate equation,出现对话框3) 在对话框的equation specification框中,按被解释变量、常数项、解释变量的顺序输入,中间用空格空开4)在对话框的estimation settings框中,在method栏中选择估计方法,点击OK即可5)在工具栏中,点击name,在name to identify object框中输入方程的新名字,点击OK 后,工作文件中将出现方程的图标注:R-squared 拟合优度Mean dependent var 被解释变量均值Adjusted R-squared 修正的拟合优度S.D. dependent var 被解释变量标准差S.E. of regression 回归方程标准差Akaike info criterion 赤池信息准则Sum squared resid 残差平方和Schwarz criterion 施瓦兹信息准则Log likelihood 似然函数的对数F-statistic F统计量Durbin-Watson stat DW统计量Prob(F-statistic) F统计量的P值6)在第四步输出估计结果后,在结果窗口中点击view/actual,fitted,residual/相应的残差图,可出现被解释变量的实际值、估计值、残差以及残差图。
经验分享使用eviews做回归分析

[经验分享] 使用eview s做线性回归分析Glossa ry:ls(least square s)最小二乘法R-sequar ed样本决定系数(R2):值为0-1,越接近1表示拟合越好,>0.8认为可以接受,但是R2随因变量的增多而增大,解决这个问题使用来调整Adjust R-seqaur ed()S.E of regression回归标准误差Log likelihood对数似然比:残差越小,L值越大,越大说明模型越正确Durbin-Watson stat:DW统计量,0-4之间Mean dependent var因变量的均值S.D. dependent var因变量的标准差Akaike info criter ion赤池信息量(AIC)(越小说明模型越精确)Schwar z ctiter ion:施瓦兹信息量(SC)(越小说明模型越精确)Prob(F-statis t ic)相伴概率fitted(拟合值)线性回归的基本假设:1.自变量之间不相关2.随机误差相互独立,且服从期望为0,标准差为σ的正态分布3.样本个数多于参数个数建模方法:ls y c x1 x2 x3 ...x1 x2 x3的选择先做各序列之间的简单相关系数计算,选择同因变量相关系数大而自变量相关系数小的一些变量。
模型的实际业务含义也有指导意义,比如m1同g dp肯定是相关的。
模型的建立是简单的,复杂的是模型的检验、评价和之后的调整、择优。
模型检验:1)方程显著性检验(F检验):模型拟合样本的效果,即选择的所有自变量对因变量的解释力度F大于临界值则说明拒绝0假设。
Eviews给出了拒绝0假设(所有系统为0的假设)犯错误(第一类错误或α错误)的概率(收尾概率或相伴概率)p 值,若p小于置信度(如0.05)则可以拒绝0假设,即认为方程显著性明显。
eviews一元线性回归案例

小组成员:Page1来自经典计量经济学模型建立过程
1. 理论模型的设置
2. 模型参数的最小二乘估计 3. 计量经济学模型的四级检验 3.1 经济意义检验 3.2 统计检验
3.2.1 拟合优度检验:R2 检验
3.2.2 模型总体的显著性检验:F检验
3.2.3 变量的显著性检验:t 检验
Y与X的变化趋势是线性的。 Yi 因此建立Y与X之间的一元线性回归模型:
5
0 1 X i ui
最小二乘回归法
最小二 乘回归 法
α=0.05, 查自由度 v=19-2=17的t 分布表,得临 界值 t0.025(17)=2.11
Y t 0.599781X t 106.7574
引入自相关误差矫正项AR(1)
dL=1.18<DW=1.39<dU=1.40,依据判别准则,随机误差项尚未消除自相关
12
引入自相关误差矫正项AR(1)和AR(2)
dU=1.40<DW=2.14<(4-dU)=2.82,依据判别准则,随机误差项已消除自相关
13
ˆ 115.3205 0.5876 X 0.7819 AR (1) - 0.4194 AR (2) Y t t
2
3.3 计量经济学检验 3.3.1 异方差性检验 3.3.2 自相关性(序列相关性)检验 3.3.3 多重共线性检验 3.4 预测检验(可选项目) 4. 模型的修正与再检验 4.1 模型的修正 4.2 修正模型的再检验 5. 模型的应用 5.1 结构分析 5.2 经济预测
3
4
19个样本, 1个解释变 量
整理、变换:
ˆ 0
115.3205 180.8949 1 0.7819 0.4194
Eviews线性回归教程

工资差别
为了解工作妇女是否受到了歧视,可以用美国统计局的“当前人口调查” 中的截面数据研究男女工资有没有差别。这项多元回归分析研究所用到的变 量有:
W — 雇员的工资(美元/小时)
1;若雇员为妇女 SEX =
0;其他
ED — 受教育的年数 AGE — 雇员的年龄
1;若雇员不是西班牙裔也不是白人
NONWH = 0;其他
l T (1 log( 2 π) log( uˆuˆ / T )) 2
第22页/共41页
(6) Durbin-Watson 统计量
D-W 统计量衡量残差的序列相关性,计算方法如下:
T
T
DW (uˆt uˆt1)2
uˆt2
t2
t 1
作为一个规则,如果DW值小于2,证明存在正序列相关。 在例1的结果中,DW值很小,表明残差中存在序列相关。关 于 Durbin-Watson 统 计 量 和 残 差 序 列 相 关 更 详 细 的 内 容 参 见 “序列相关理论”。
第18页/共41页
2 方程统计量
(1) R2 统计量
R2 统计量衡量在样本内预测因变量值的回归是否成功。R2
是自变量所解释的因变量的方差。如果回归完全符合,统计值
会等于1。如果结果不比因变量的均值好,统计值会等于0。R2
可能会由于一些原因成为负值。例如,回归没有截距或常数,
或回归包含系数约束,或估计方法采用二阶段最小二乘法或
第1页/共41页
打开工作文件,双击一个序列名,即进入序列的对话 框。单击“view”可看到菜单分为四个区,第一部分为序列 显示形式,第二和第三部分提供数据统计方法,第四部分是 转换选项和标签。
第2页/共41页
描述统计量
eviews实验报告总结(范本)

eviews实验报告总结eviews实验报告总结篇一:Evies实验报告实验报告一、实验数据:1994至201X年天津市城镇居民人均全年可支配收入数据 1994至201X年天津市城镇居民人均全年消费性支出数据 1994至201X年天津市居民消费价格总指数二、实验内容:对搜集的数据进行回归,研究天津市城镇居民人均消费和人均可支配收入的关系。
三、实验步骤:1、百度进入“中华人民共和国国家统计局”中的“统计数据”,找到相关数据并输入Exc el,统计结果如下表1:表11994年--201X年天津市城镇居民消费支出与人均可支配收入数据2、先定义不变价格(1994=1)的人均消费性支出(Yt)和人均可支配收入(Xt)令:Yt=cn sum/priceXt=ine/pri ce 得出Yt与Xt的散点图,如图1.很明显,Yt和X t服从线性相关。
图1 Yt和Xt散点图3、应用统计软件EVies完成线性回归解:根据经济理论和对实际情况的分析也都可以知道,城镇居民人均全年耐用消费品支出Yt依赖于人均全年可支配收入Xt的变化,因此设定回归模型为 Yt=β0+β?Xt﹢μt(1)打开E Vies软件,首先建立工作文件, Fil e rkfile ,然后通过bject建立 Y、X系列,并得到相应数据。
(2)在工作文件窗口输入命令:l s y c x,按E nter键,回归结果如表2 :表2 回归结果根据输出结果,得到如下回归方程:Y t=977.908+0.670Xt s=(172.3797) (0.0122) t=(5.673) (54.950) R2=0.995385 Adjust ed R2=0.995055 F-sta tistic=3019.551 残差平方和Sum sq uared resi d =1254108回归标准差S.E.f regressi n=299.2978(3)根据回归方程进行统计检验:拟合优度检验由上表2中的数分别为0.995385和0.995055,计算结果表明,估计的样本回归方程较好地拟合了样本观测值。
Eviews操作教程_完整版
Eviews操作教程_完整版1.EVIEWS基础 (3)1.1. E VIEWS简介 (3)1.2. E VIEWS的启动、主界⾯和退出 (3)1.3. E VIEWS的操作⽅式 (6)1.4. E VIEWS应⽤⼊门 (6)1.5. E VIEWS常⽤的数据操作 (15)2.⼀元线性回归模型 (24)2.1. ⽤普通最⼩⼆乘估计法建⽴⼀元线性回归模型 (24) 2.2. 模型的预测 (30)2.3. 结构稳定性的C HOW检验 (34)3. 多元线性回归 (39)3.1. ⽤OLS建⽴多元线性回归模型 (39)3.2. 函数形式误设的RESET检验 (45)4. ⾮线性回归 (48)4.1. ⽤直接代换法对含有幂函数的⾮线性模型的估计 (48) 4.2. ⽤间接代换法对含有对数函数的⾮线性模型的估计 (50) 4.3. ⽤间接代换法对CD函数的⾮线性模型的估计 (53)4.4. NLS对可线性化的⾮线性模型的估计 (55)4.5. NLS对不可线性化的⾮线性模型的估计 (58)4.6. ⼆元选择模型 (62)5. 异⽅差 (68)5.1. 异⽅差的⼽得菲尔德——匡特检验 (68)5.2. 异⽅差的WHITE检验 (72)5.3. 异⽅差的处理 (75)6. ⾃相关 (79)6.1. ⾃相关的判别 (79)6.2. ⾃相关的修正 (83)7. 多重共线性 (87)7.1. 多重共线性的检验 (87)7.2. 多重共线性的处理 (92)8. 虚拟变量 (94)8.1. 虚拟⾃变量的应⽤ (94)8.2. 虚拟变量的交互作⽤ (99)8.3. ⼆值因变量:线性概率模型 (101)9. 滞后变量模型 (106)9.1. ⾃回归分布滞后模型的估计 (106)9.2. 多项式分布滞后模型的参数估计 (111)10. 联⽴⽅程模型 (116)10.1. 联⽴⽅程模型的单⽅程估计⽅法 (116)10.2. 联⽴⽅程模型的系统估计⽅法 (120)2..1.Eviews基础1.1.Eviews简介Eviews:Econometric Views(经济计量视图),是美国QMS公司(Quantitative Micro Software Co.,⽹址为/doc/8e38170bbed126fff705cc1755270722192e59b1.html )开发的运⾏于Windows环境下的经济计量分析软件。
eviews建模方法之回归分析简介
建模方法之回归分析简介数学模型一元线性回归分析模型:),,0(~,2σεεN bx a Y ++= 多元线性回归分析模型:ε+++++=p p x b x b x b a Y Λ2211设随机变量Y 与X 有相关关系,就是说当X 取一确定值时,随机变量Y 有一个确定的分布.这个分布大多数情况下不能具体知道,但在实践中只需要的观测值.而数学期望(假设存在)在一定程度上能反映出其观测值的大小,所以人们感兴趣的是当X 取确定值x 时, Y 的数学期望)(x μ是多少.称)(x μ为Y 对X 的回归函数.在实际问题中,回归函数是未知的,需要我们根据实测样本以及以往的经验来确定回归函数的类型及求出函数中的未知参数的估计,得到经验公式.例1 20℃时在铜线含碳量%x 对于电阻Y (为一正态变量,单位:微欧)变化的研究中,得到如下一测试结果表明,随着铜线含碳量的增加,其电阻有增大的趋势.为了确定回归函数)(x μ的类型, 我们将这9组数据作为坐标在平面直角坐标系中描出它们相应的点,这种图称为散点图。
变量X -Y 的散点图因此估计)(x μ大致具有线性函数bx a +的形式,即可认为X 与Y 具有如下关系:),,0(~,2σεεN bx a Y ++= (1)其中b a ,及2σ是常数.这就是X 、Y 之间的(一元正态线性)回归模型.对n 根铜线进行独立观测,能得到n 个含碳量n x x x ,,,21Λ及对应的n Y Y Y ,,,21Λ,把i Y 看成随即变量,则它们可以表示成⎭⎬⎫=++=.,,,),,0(~,,,2,1,212相互独立n i i i i N n i bx a Y εεεσεεΛΛ (2)记⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡=n x x x X 11121M M ,⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡=n Y Y Y Y M 21,⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡=n εεεεM 21, 则(2)式也可表示为ε+⎪⎪⎭⎫⎝⎛=b a X Y .在一元线性回归中主要解决下列问题: (I ) 对未知参数b a ,及2σ进行估计; (II ) 对线性模型的假设进行检验; (III ) 对Y 进行预测和控制.参数的估计:对未知参数b a ,的估计,一个直观的想法便是希望选取这样的a 与b ,使得他们在n x x x ,,,21Λ各处计算的理论值i bx a +与实测值i y 的偏离达到最小.为此人们常用最小二乘法:求b a ,使∑=−−=ni i ibx a yQ 12)(为最小.在几何上,即是在平面上选取一条直线,使直线在横坐标为n x x x ,,,21Λ处的纵坐标与相应的实测点的纵坐标之差的平方和为最小.利用求极值的方法求b a ,,令⎪⎪⎩⎪⎪⎨⎧=−−−=∂∂=−−−=∂∂∑∑==.0)(2,0)(211ni i i i ni i i x bx a y b Q bx a y a Q整理得⎪⎪⎩⎪⎪⎨⎧=+=+∑∑∑∑∑=====ni i i n i i n i i ni i n i i y x x b x a y x b na 112111解此方程组得到的不是b a ,的真值,而是b a ,的估计值,ˆ,ˆb a它们为 ,)())((ˆ1212121∑∑∑∑====−−−=−−=ni ini i ini ini ii x xy y x xx n xyx n yx b(3),ˆˆx b y a−= (4) 其中.,111∑∑====ni i ni i y y x n x 具体计算得Y 对X 的线性回归方程为.59.1297.13ˆx y+= 等价公式:Y X X X ba TT 1)(ˆˆ−=⎥⎦⎤⎢⎣⎡. (5)方差分析:总平方和:,)(12∑=−=ni iT Y YQ 自由度为1−n回归平方和:∑=−=ni iR Y Y Q 12)ˆ(,)(ˆ122∑=−=ni i x x b 自由度为1=p 残差平方和:,)ˆ(12∑=−=ni iiE Y YQ 自由度为1−−p n 关系式:.E R T Q Q Q += 性质:2)1(σ=−−p n Q E E 。
Eviews实验课讲义_3一元多元线性回归-上机课
第三课一元及多元线性回归模型3.1一元线性回归模型一、做两个变量的散点图,从而看两个变量是否具有线性关系。
案例数据:1985-2002年我国人均钢产量与人均GDP的时间序列数据(数据3_1_1)。
操作方法:通过序列组的形式右键单击打开后,在group窗口下view——graph---scatter,通过对散点图结同样的操作可以检验其它案例数据(3_1_2和3_1_3)的特征:案例数据2、3、4、5:10个家庭人均收入与消费支出的横截面数据;1978-2000年中国人均消费模型;1978年-2008年北京市城镇居民年家庭收入和年消费性支出数据(case1_1的数据); 1970年-1980年美国的咖啡平均真实零售价格(每磅美元)与消费量(每人每日杯数)(其中,零售价格是已经经过物价调整的)二、通过建立方程对象的方式来估计一个方程,并保存我们建立的方程对象。
Workfile窗口下建立新的对象---equation对象并命名,在equation estimation 窗口下的specification 选项卡下的equation specification对话框中设置因变量、自变量及常数项,在estimation settings对话框中注意:建模途径:command: quick\estimation equation回车,或object\equation object,设置。
命令行形式:(1)列表法:consp c gdpp 或(2)公式法:consp=c(1)+c(2)*gdpp三、方程估计结果的解释、评价及模型检验(拟合优度评价,估计参数和方程的显著性检验)消费方程中,C为自发性消费,x(gdpp)的系数为经济参数,关注其意义;通过拟合优度、调整后的拟合优度、t统计量后的精确显著性水平p(相伴概率);f统计量的p来判断对原假设接受与否四、在回归估计结果中显示方程的三种形式(即估计命令,回归方程的一般表达式,带有系数估计值的表达式)Estimation Command:LS GDPP STEELP CEstimation Equation:GDPP = C(1)*STEELP + C(2)Substituted Coefficients:GDPP = 93.6876362857*STEELP - 3394.97191614五、如何查看因变量的实际值、拟合值和回归方程的残差(包括表的形式和图的形式)通过方程窗口下的view去实现实际值、拟合值和回归方程的残差;单独显示残差及标准化后的对于案例数据1978年-2008年北京市城镇居民年家庭收入和年消费性支出数据,进行样本内与外的预测。
用excel进行一元线性回归分析
用excel进行一元线性回归分析在Excel中进行一元线性回归分析可以遵循以下步骤:1.打开Excel并输入你的数据。
在A列和B列分别输入x和y的值。
例如,如果你在研究体重(x)和血压(y)的关系,你的数据可能会像这样:A列是体重,B列是血压。
2.在Excel中打开“数据”菜单,然后选择“数据分析”工具。
如果你没有看到这个选项,那么可能需要先在“文件”>“选项”>“加载项”中启用它。
3.在“数据分析”工具中,选择“回归”选项。
这会打开一个新的对话框,其中包含几个选项。
4.在“回归”对话框中,你将看到几个选项。
在“Y值输入区域”中,选择你的y值(在上面的例子中是B列)。
在“X值输入区域”中,选择你的x值(在上面的例子中是A列)。
确保勾选“标志”选项,这样你的模型就会包括截距项。
5.点击“确定”按钮。
Excel会在C列和D列中输出回归结果。
C列包含回归系数,D列包含标准误差和R平方等统计信息。
6.解读结果。
如果回归系数(C列)的P值小于你选择的显著性水平(如0.05),那么你就可以认为这个因素是显著的。
R平方值越接近1,说明模型的解释力度越高。
以上就是在Excel中进行一元线性回归分析的基本步骤。
需要注意的是,虽然Excel提供了一个方便的工具来做这个分析,但是它并不能提供高级的统计测试或者复杂的模型。
如果你需要更复杂的分析,可能需要使用专门的统计软件,如SPSS、SAS或R等。
在进行回归分析时,还要注意几个关键点。
首先,你需要确保你的数据满足线性回归的假设,包括误差的正态性和独立性、线性关系以及合理的异方差性等。
其次,如果你的样本量很小,那么你可能需要更谨慎地解释结果,因为小样本可能会导致较大的误差和偏差。
最后,记住回归分析只能告诉你变量之间的关系,并不能告诉你因果关系。
例如,体重可能和血压有关系,但并不意味着体重是导致血压升高的原因。
在进行回归分析时,还可以使用一些额外的工具和技巧来改进你的分析。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第一部分 EViews基本操作 第一章 预备知识
一、什么是EViews EViews (Econometric Views)软件是QMS(Quantitative Micro Software)公司开发的、基于Windows平台下的应用软件,其前身是DOS操作系统下的TSP软件。EViews具有现代Windows软件可视化操作的优良性。可以使用鼠标对标准的Windows菜单和对话框进行操作。操作结果出现在窗口中并能采用标准的Windows技术对操作结果进行处理。EViews还拥有强大的命令功能和批处理语言功能。在EViews的命令行中输入、编辑和执行命令。在程序文件中建立和存储命令,以便在后续的研究项目中使用这些程序。 EViews是Econometrics Views的缩写,直译为计量经济学观察,通常称为计量经济学软件包,是专门从事数据分析、回归分析和预测的工具,在科学数据分析与评价、金融分析、经济预测、销售预测和成本分析等领域应用非常广泛。 应用领域 ■ 应用经济计量学 ■ 总体经济的研究和预测 ■ 销售预测 ■ 财务分析 ■ 成本分析和预测 ■ 蒙特卡罗模拟 ■ 经济模型的估计和仿真 ■ 利率与外汇预测 EViews引入了流行的对象概念,操作灵活简便,可采用多种操作方式进行各种计量分析和统计分析,数据管理简单方便。其主要功能有: (1)采用统一的方式管理数据,通过对象、视图和过程实现对数据的各种操作; (2)输入、扩展和修改时间序列数据或截面数据,依据已有序列按任意复杂的公式生成新的序列; (3)计算描述统计量:相关系数、协方差、自相关系数、互相关系数和直方图; (4)进行T 检验、方差分析、协整检验、Granger 因果检验; (5)执行普通最小二乘法、带有自回归校正的最小二乘法、两阶段最小二乘法和三阶段最小二乘法、非线性最小二乘法、广义矩估计法、ARCH 模型估计法等; (6)对选择模型进行Probit、Logit 和Gompit 估计; (7)对联立方程进行线性和非线性的估计; (8)估计和分析向量自回归系统; (9)多项式分布滞后模型的估计; (10)回归方程的预测; (11)模型的求解和模拟; (12)数据库管理; (13)与外部软件进行数据交换 EViews可用于回归分析与预测(regression and forecasting)、时间序列(Time Series)以及横截面数据(cross-sectional data )分析。与其他统计软件(如EXCEL、SAS、SPSS)相比,EViews功能优势是回归分析与预测,其功能框架见表1.1.1。 本手册以EViews5.1版本为蓝本介绍该软件的使用。 表1.1.1 EViews功能框架 Descriptive statistics 描述统计
Correlogram View(相关分析) 主要有:Autocorrelations(自相关)、Partial Autocorrelations(偏自相关)、Cross Correlation(交叉相关)、Q-Statistics(Q统计量)等
Regression 回归 Standard Regression Output
标准回归输出 Regression Coefficients(回归系数)t-Statistics(T统计量)2R(判定系数)等 Actual and Fitted Values and Residuals 实际值、拟合值、残差 Actual Values(实际值)、Fitted Values(拟合值)、Residuals(残差)
Collinearity(共线性)、Heteroskedasticity(异方差性)、Weighted Least Squares(加权最小二乘法)、Two-Stage Least Squares(二段最小二乘法)、 Polynomial Distributed Lags(多项式分布滞后)、Nonlinear Least Squares(非线性最小二乘法)、Logit and Probit Models(对数概率单位模型)、Granger Causality(葛兰杰因果检验)、Forecast Variances(预测方差)、Exponential Smoothing(指数平滑)等
Histogram and Statistics View of a Single Series Multiple Series 一个变量或多个变量的统计与图形 主要有:图形包括线型图、条形图、多种散点图等;指标有均值、方差、偏度(Skewness)、峰度(Kurtosis)、Jarque-Bera Statistic(雅克-贝拉统计量)
Serial Correlation 序列相关 Durbin-Watson Statistic(德宾-沃森统计量)
ARIMA Models(自回归求积移动平均模型) Unit Root Tests(单位根检验) Estimation of Difference Models(差分模型的估计) Two-Stage Least Squares With Serial Correlation(有自相关的二段最小二乘 Systems 系统方法 System Estimation(系统估计法)
Vector Autoregression(VAR向量自回归) Vector Error Correction Models and Cointegration Tests(向量误差校正模型与协整检验)等
Specification and Diagnostic Tests 模型设定与诊断检验
Test on Coefficient (对系数的检验) Wald Test of Coefficient Restriction(Wald检验) Omitted Variable(遗漏变量的检验) Redundant Variable(冗余的检验)等
Tests on Residuals (对残差的检验) Histogram and Normality Test(相关图与正态性检验)、Series Correlation LM Test(拉格朗日乘数检验)、White Hereoskedasticity Test(怀特检验)等
Specification and Stability Tests (模型设定与稳定性检验)如Chow`s Breakpoint Test(邹氏检验) Ramsey`s RESET Test(拉姆齐RESETJ检验)
Recursive Least Squares(递归最小二乘) 二、EViews安装 打开EViews5.1文件所在文件夹,点击Setup安装,安装过程与其他软件安装类似。安装完毕后,电脑桌面和文件安装位置都有EViews5图标。双击EViews5图标即可启动该软件,如下图(图1.1.1)。
图1.1.1 三、EViews工作特点 (一) EViews软件的具体操作是在Workfile中进行。如果想用EViews进行某项具体 的操作,必须先新建一个Workfile或打开一个已经存在硬盘(或软盘)上的Workfile,然后才能够定义变量、输入数据、建造模型等操作; (二) EViews处理的对象及运行结果都称之为Object(对象),如序列(Series)、方程(Equation)、如表格(Spreadsheet)、图(Graph)、描述统计(Descriptive Statistics)、模型(Models)、系数(Coefficients)等Object,可以用不同形式查看(View)Object,比如表格(Spreadsheet)、图(Graph)、描述统计(Descriptive Statistics)等,但这些查看(View)结果不是独立的Object,他们随原变量序列的改变而改变。如果想将某个查看(View)结果转换成一个独立的Object,可使用Freeze命令将该结果“冻结”,从而形成一个独立的Object,然后可对其进行编辑或存储。 (三)EViews中建立的Object的命名不区分大小写,其中c、resid为参数向量和残差序列两Object的专用名称,不能用来对其他对象命名。
四、一个示例 在这里,我们通过一个简单的回归分析例子来显示一个EViews过程,不对EViews的详细功能展开讨论,目的是使读者先对EViews有个概括了解。该例子是四川省人均可支配收入与人均年消费支出的数量关系分析(数据见下表1.1.2),共分九步。
表1.1.2 年份 人均年消费支出Y 人均可支配收入X 1978 314 338 1979 340 369 1980 364 391 1981 396 412 1982 407 445
命令窗口 主显示窗口
菜单栏 1983 457 493 1984 517 581 1985 680 695 1986 787 849 1987 889 948 1988 1086 1130 1989 1184 1349 1990 1281 1490 1991 1488 1691 1992 1651 1989 1993 2034 2408 1994 2806 3297 1995 3429 4003 1996 3733 4406 1997 4093 4763 1998 4383 5127
设定模型为 tttYXu STEP1 启动程序。 双击桌面上EViews快捷图标,打开EViews(参见在图1.1.1)。 STEP2 建立Workfile。 点击EViews主窗口顶部命令菜单file\new\Workfile (如图1.1.2),弹出Workfile Create对话框(图1.1.3)。在右边frequency下拉菜单中可选数据类型,Annual为默认的数据类型。因为这次数据是年度时间序列数据(1978年~1998年的年度数据),故不需做调整(若是别的数据类型则需另选相应选项)。在Start 和End 的文本框中分别输入1978和1998,在右下角文本框中输入新建的这个Workfile的名字,例如shili。点击OK,出现图1.1.4画面,Workfile建立完毕。 此时可以看到Workfile中有两个默认的对象,名称分别为c 、resid,分别为参数估计值向量和残差序列。在没做回归估计之前,向量c的每个元素的值都为0,残差序列的每个值为NA,表示还没有赋值。以后每做一次回归估计,c和resid就会被重新赋值(被分别赋予最新回归估计的参数估计值向量和残差序列)。