《应用多元统计分析》第六章主成分分析实验报告
主成分分析报告

主成分分析报告第一点:主成分分析的定义与重要性主成分分析(Principal Component Analysis,PCA)是一种统计方法,它通过正交变换将一组可能相关的变量转换为一组线性不相关的变量,这组变量称为主成分。
这种方法在多变量数据分析中至关重要,尤其是在数据的降维和可视化方面。
在实际应用中,数据往往包含多个变量,这些变量可能存在一定的相关性。
这样的数据集很难直接进行分析和理解。
主成分分析通过提取数据中的主要特征,将原始的多维数据转化为少数几个互相独立的主成分,使得我们能够更加清晰地看到数据背后的结构和模式。
主成分分析的重要性体现在以下几个方面:1.降维:在数据集中存在大量变量时,通过PCA可以减少数据的维度,简化模型的复杂性,从而降低计算成本,并提高模型的预测速度。
2.去除相关性:PCA能够帮助我们识别和去除变量间的线性相关性,使得我们分析的是更加纯净的独立信息。
3.数据可视化:通过将多维数据映射到二维或三维空间中,PCA使得数据的可视化成为可能,有助于我们直观地理解数据的结构和模式。
4.特征提取:在机器学习中,PCA可以作为一种特征提取工具,提高模型的性能和泛化能力。
第二点:主成分分析的应用案例主成分分析在各个领域都有广泛的应用,下面列举几个典型的案例:1.图像处理:在图像处理领域,PCA被用于图像压缩和特征提取。
通过将图像转换到主成分空间,可以大幅度减少数据的存储空间,同时保留图像的主要信息。
2.金融市场分析:在金融领域,PCA可以用来分析股票或证券的价格动向,通过识别影响市场变化的主要因素,帮助投资者做出更明智的投资决策。
3.基因数据分析:在生物信息学领域,PCA被用于基因表达数据的分析。
通过识别和解释基因间的相关性,PCA有助于揭示生物过程中的关键基因和分子机制。
4.客户细分:在市场营销中,PCA可以用来分析客户的购买行为和偏好,通过识别不同客户群的主要特征,企业可以更有效地制定市场策略和个性化推荐。
主成分分析

主成分分析法实验报告一、实验名称:主成分分析二、实验目的:利用计算机实现主成分分析,完成综合评价。
三、实验原理:四、实验过程:(一)数据录入:将相关指标数据录入如下表(二)数据标准化:为避免不同量纲引起的大数吃小数问题,我们对相关数据进行标准化,结果如下:表1:标准化后的数据录入表表2:描述统计量表表1是标准化后的相关数据,表2给出了标准化过程中涉及到的均值、标准差等数值。
(三)分析表3:公因子方差表表3给出了该次分析从每个原始变量中提取的信息,表格下的表注表明,该次分析使用主成分分析完成的。
可以看出除百元销售收入实现利税信息损失较大外,主成分几乎包含了各个原始变量至少85%的信息。
表4:相关矩阵表4为各指标因素量化后的相关矩阵。
表5:解释的总方差表由输出结果表5可以看出,前两个主成分y1,y2的方差和占全部方差的的比例为84.7%。
我们就选取y1为第一主成分,y2为第二主成分,且这两个主成分的方差和占全部方差的84.7%,即基本上保留了原来的指标的信息,这样由原来的9个指标转化为2个新指标,起到了降维的作用。
表6:因子载荷矩阵因子载荷矩阵(表6)是主成分和变量间的因子负荷量,即相关系数,代表相关度。
并非主成分的系数;所以我们要通过该成分矩阵计算出主成分的系数,计算结果如表7:表7:主成分系数表7中,a1代表第一主成分与各变量间的因子负荷量,a2代表第二主成分与各变量间的因子负荷量;u1代表y1的系数,u2代表y2的相应系数。
由此可得到两个主成分y1、y2的线性组合。
(四)主成分得分及分类表8:主成分得分为了分析各样品在主成分所反映的经济意义方面的情况,还将标准化后的原始数据代入主成分表达式中计算出各样品的主成分得分,如表8,得到28个省的、直辖市、自治区的主成分的分。
将这28个样品在平面直角坐标系上描出来,进而得到样品分类,如下图所示:由上图可以看出,分布在第一象限的是上海、北京、天津、广西四个省区,这四个省区的经济效益在全国来说属于较好的,上海经济效益最好。
多元统计分析 实验报告

多元统计分析实验报告1. 引言多元统计分析是一种用于研究多个变量之间关系的统计方法。
在实验中,我们使用了多元统计分析方法来探索一组数据中的变量之间的关系。
本报告将介绍我们的实验设计、数据收集和分析方法以及结果和讨论。
2. 实验设计为了进行多元统计分析,我们设计了一个实验,收集了一组相关变量的数据。
我们选择了X、Y和Z这三个变量作为我们的研究对象。
为了获得准确的结果,我们采用了以下实验设计:1.确定研究目的:我们的目标是探索X、Y和Z之间的关系,并确定它们之间是否存在任何相关性。
2.数据收集:我们通过调查问卷的方式收集了一组数据。
我们请参与者回答与X、Y和Z相关的问题,以获得关于这些变量的定量数据。
3.数据整理:在收集完数据后,我们将数据进行整理,将其转化为适合多元统计分析的格式。
我们使用Excel等工具进行数据整理和清洗。
4.数据验证:为了确保数据的准确性,我们对数据进行验证。
我们检查数据的有效性,比较数据之间的一致性,并排除任何异常值。
3. 数据分析在数据收集和整理完毕后,我们使用了一些常见的多元统计分析方法来分析我们的数据。
以下是我们使用的方法和步骤:1.描述统计分析:我们首先对数据进行了描述性统计分析。
我们计算了X、Y和Z的均值、标准差、最大值和最小值等。
这些统计量帮助我们了解数据的基本特征。
2.相关性分析:接下来,我们进行了相关性分析,以确定X、Y和Z之间是否存在相关关系。
我们计算了变量之间的相关系数,并绘制了相关系数矩阵。
这帮助我们确定变量之间的线性关系。
3.回归分析:为了更进一步地研究X、Y和Z之间的关系,我们进行了回归分析。
我们建立了一个多元回归模型,通过回归方程来预测因变量。
同时,我们还计算了回归系数和R方值,以评估模型的拟合度和预测能力。
4. 结果和讨论根据我们的实验设计和数据分析,我们得出了以下结果和讨论:1.描述统计分析结果显示,X的平均值为x,标准差为s;Y的平均值为y,标准差为s;Z的平均值为z,标准差为s。
主成分分析实验报告

主成分分析地信0901班陈任翔010******* 【实验目的及要求】掌握主成分分析与因子分析的思想和具体步骤。
掌握SPSS实现主成分分析与因子分析的具体操作。
【实验原理】1.主成分分析的主要目的是希望用较少的变量去解释原来资料中的大部分变异,将我们手中许多相关性很高的变量转化成彼此相互独立或不相关的变量。
通常是选出比原始变量个数少,能解释大部分资料中的变异的几个新变量,即所谓主成分,并用以解释资料的综合性指标。
由此可见,主成分分析实际上是一种降维方法。
2.因子分析研究相关矩阵或协方差矩阵的内部依赖关系,它将多个变量综合为少数几个因子,以再现原始变量与因子之间的相关关系。
【实验步骤】1.数据准备●1)首先在Excel中打开“水样元素成分分析数据”,删除表名“水样元素成分分析数据”,保存数据。
●3)数据格式转换。
2.数据描述分析操作1)Descriptives过程点击Analyze下的Descriptive Statistics选项,选择该选项下的Descriptives●选中待处理的变量(左侧的As…..Hg等);●点击使变量As…..Hg 移至Variable(s)中;●选中Save standrdized values as variables;●点击Options2)数据标准化标准化处理后的结果2.主成分分析1)点击Analyze下的Data Reduction选项,选择该选项下的Factor过程。
选中待处理的变量,移至Variables2)点击Descriptives判断是否有进行因子分析的必要Coefficients(计算相关系数矩阵)Significance levels(显著水平)KMO and Bartlett’s test of sphericity (对相关系数矩阵进行统计学检验)Inverse(倒数模式):求出相关矩阵的反矩阵;Reproduced(重制的):显示重制相关矩阵,上三角形矩阵代表残差值,而主对角线及下三角形代表相关系数;Determinant(行列式):求出前述相关矩阵的行列式值;Anti-image(反映像):求出反映像的共同量及相关矩阵。
主成份分析实验报告
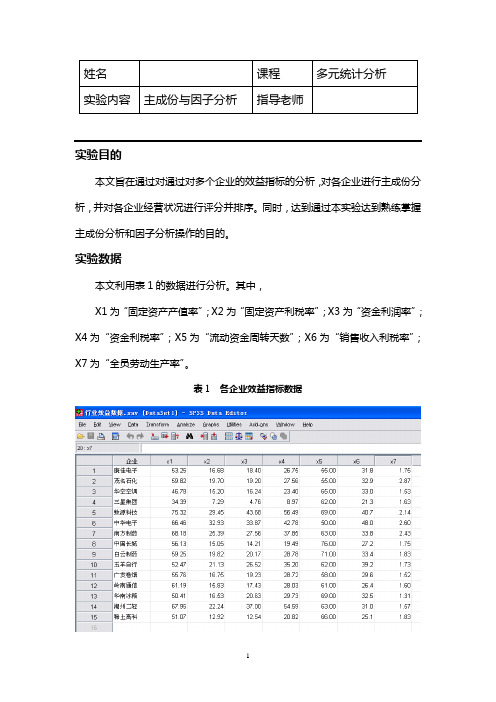
姓名课程多元统计分析实验内容主成份与因子分析指导老师实验目的本文旨在通过对通过对多个企业的效益指标的分析,对各企业进行主成份分析,并对各企业经营状况进行评分并排序。
同时,达到通过本实验达到熟练掌握主成份分析和因子分析操作的目的。
实验数据本文利用表1的数据进行分析。
其中,X1为“固定资产产值率”;X2为“固定资产利税率”;X3为“资金利润率”;X4为“资金利税率”;X5为“流动资金周转天数”;X6为“销售收入利税率”;X7为“全员劳动生产率”。
表1 各企业效益指标数据实验步骤选择【Analyze】-【Date Reduction】-【Factor】,如图2。
图2 主成份分析操作在主成份分析对话框中进行设置,将变量X1—X6选入Variables,如图3。
图3 主成份分析对话框选择【Descriptives】,弹出对话框如图4,保留默认设置。
图4 Descriptives对话框选择【Extraction】,弹出对话框如图5所示。
方法(method)默认为Principal components,即主成份分析,保留默认设置。
在提取Extract项下选Number of factors,填入6,即提取6个主成份。
图5 提取主成分设置选择【Rotation】,弹出对话框如图6所示,因子旋转采用Varimax方法,如图6所示。
图6 因子旋转对话框选择【Scores】,弹出对话框如图7所示。
选择将主成份保存成变量(Save as variables),方法(method)为回归(Regression)。
图7 主成份得分设置点击【OK】,即可得到主成份分析和因子分析结果。
实验结果表8为变量共同度,表中显示原始数据所有信息都被提取出来了。
表8 变量共同度CommunalitiesInitial Extraction固定资产产值率 1.000 1.000固定资产利税率 1.000 1.000资金利润率 1.000 1.000资金利税率 1.000 1.000流动资金周转天数 1.000 1.000销售收入利税率 1.000 1.000Extraction Method: Principal ComponentAnalysis.表9为各主成份特征根和累计贡献率。
主成分分析、因子分析实验报告--SPSS

主成分分析、因子分析实验报告--SPSS主成分分析、因子分析实验报告SPSS一、实验目的主成分分析(Principal Component Analysis,PCA)和因子分析(Factor Analysis,FA)是多元统计分析中常用的两种方法,旨在简化数据结构、提取主要信息和解释变量之间的关系。
本次实验的目的是通过使用 SPSS 软件对给定的数据集进行主成分分析和因子分析,深入理解这两种方法的原理和应用,并比较它们的结果和差异。
二、实验原理(一)主成分分析主成分分析是一种通过线性变换将多个相关变量转换为一组较少的不相关综合变量(即主成分)的方法。
这些主成分是原始变量的线性组合,且按照方差递减的顺序排列。
主成分分析的主要目标是在保留尽可能多的数据信息的前提下,减少变量的数量,从而简化数据分析和解释。
(二)因子分析因子分析则是一种探索潜在结构的方法,它假设观测变量是由少数几个不可观测的公共因子和特殊因子线性组合而成。
公共因子解释了变量之间的相关性,而特殊因子则代表了每个变量特有的部分。
因子分析的目的是找出这些公共因子,并估计它们对观测变量的影响程度。
三、实验数据本次实验使用了一份包含多个变量的数据集,这些变量涵盖了不同的领域和特征。
数据集中的变量包括具体变量 1、具体变量 2、具体变量 3等,共X个观测样本。
四、实验步骤(一)主成分分析1、打开 SPSS 软件,导入数据集。
2、选择“分析”>“降维”>“主成分分析”。
3、将需要分析的变量选入“变量”框。
4、在“抽取”选项中,选择主成分的提取方法,如基于特征值大于1 或指定提取的主成分个数。
5、点击“确定”,运行主成分分析。
(二)因子分析1、同样在 SPSS 中,选择“分析”>“降维”>“因子分析”。
2、选入变量。
3、在“描述”选项中,选择相关统计量,如 KMO 检验和巴特利特球形检验。
4、在“抽取”选项中,选择因子提取方法,如主成分法或主轴因子法。
多元统计分析实验报告(精选多篇)

多元统计分析实验报告(精选多篇)第一篇:多元统计分析实验报告多元统计分析得实验报告院系:数学系班级:13级 B 班姓名:陈翔学号:20131611233 实验目得:比较三大行业得优劣性实验过程有如下得内容:(1)正态性检验;(2)主体间因子,多变量检验a;(3)主体间效应得检验;(4)对比结果(K 矩阵);(5)多变量检验结果;(6)单变量检验结果;(7)协方差矩阵等同性得Box 检验a,误差方差等同性得Levene 检验 a;(8)估计;(9)成对比较,多变量检验;(10)单变量检验。
实验结果:综上所述,我们对三个行业得运营能力进行了具体得比较分析,所得数据表明,从总体来瞧,信息技术业要稍好于电力、煤气及水得生产与供应业以及房地产业。
1。
正态性检验Kolmogorov-SmirnovaShapir o—Wilk 统计量 df Sig.统计量df Sig、净资产收益率。
113 35、200*。
978 35。
677 总资产报酬率。
121 35、200*。
964 35、298 资产负债率。
086 35。
200*.962 35、265 总资产周转率.180 35、006。
864 35。
000流动资产周转率、164 35、018.88535、002 已获利息倍数、28135.000。
55135、000 销售增长率.103 35、200*。
949 35、104 资本积累率。
251 35。
000、655 35。
000 *。
这就是真实显著水平得下限。
a。
Lilliefors显著水平修正此表给出了对每一个变量进行正态性检验得结果,因为该例中样本中n=35<2000,所以此处选用 Shapiro—W ilk 统计量。
由 Sig。
值可以瞧到,总资产周转率、流动资产周转率、已获利息倍数及资本积累率均明显不遵从正态分布,因此,在下面得分析中,我们只对净资产收益率、总资产报酬率、资产负债率及销售增长率这四个指标进行比较,并认为这四个变量组成得向量遵从正态分布(尽管事实上并非如此)。
多元统计分析之主成分分析(2016)

(3) 如何解释主成分所包含的经济意义。
§2 数学模型与几何解释
假设我们所讨论的实际问题中,有p个指标,我们把 这p个指标看作p个随机变量,记为X1,X2,…,Xp,主成 分分析就是要把这p个指标的问题,转变为讨论p个指标 的线性组合的问题,而这些新的指标F1,F2,…, Fk(k≤p),按照保留主要信息量的原则充分反映原指标 的信息,并且相互无关。这种由讨论多个指标降为少数 几个综合指标的过程在数学上就叫做降维。主成分分析 通常的做法是,寻求原指标的线性组合Fi。
•• •
•
• • •• •
•• • •
•
•
•• •
•• •
•• • • • • •
•
•• •
•
•
•
• ••
• • ••
•
•• • •
•
•• •
•• •
•
x1
释
•
••
• •
•
上面的四张图中,哪一种有更高的精度? 原始变量的信息损失最少?
如果我们将xl 轴和x2轴先平移,再同时按 逆时针方向旋转角度,得到新坐标轴yl和y2。 yl和y2是两个新变量。根据旋转变换公式:
F1
F2
F3
i
i
t
F1
1
F2
0
1
F3
0
0
1
i 0.995 -0.041 0.057
l
Δi -0.056 0.948 -0.124 -0.102 l
t -0.369 -0.282 -0.836 -0.414 -0.112 1
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Total Variance Explained
Component
Initial Eigenvalues
Extraction Sums of Squared Loa
ings
Total
% of Varianc
Cumulative %
Total
% of Vari
nce
Cumulative %
《应用多元统计分析》第六章主成分分析实验报告
第六章主成分分析实验报告
实验项目
名称
主成分分析的上机实现
实验
目的及要求
目的:通过本次实验,培养学生如下几方面的能力:
1、使学生能够借助于SPSS的因子分析功能,实现主成分分析的方法。
2、使学生对主成分分析的基本原理有更深入的理解。
3、培养学生灵活运用所学知识的能力和分析问题、解决问题的能力。
0.427
-0.21
-0.154
Dodge
-0.706
-0.196
0.481
0.145
-0.154
Eagle
-0.614
1.218
-4.199
-0.21
-0.677
Ford
-0.706
-1.542
0.987
0.145
-1.724
Honda
-0.429
0.41
-0.007
0.027
0.369
Isuzu
实验步骤
1. (一)利用SPSS进行因子分析
将原始数据输入SPSS数据编辑窗口,将4个变量分别命名为X1~X4。在SPSS窗口中选择Analyze→Data Reduction→Factor菜单项,调出因子分析主对话框,并将变量X1~X4移入Variables框中,其他均保持系统默认选项,单击OK按钮,执行因子分析过程,得到如表1所示的特征根和方差贡献表以及表2所示的因子载荷阵。
2. 计算特征向量矩阵
为了计算第一个特征向量,我们利用因子载荷与特征向量元素间的关系,点击菜单项中的Transform→Compute,调出Compute variable对话框,如图4所示,在对话框中输入等式:“z1=a1 / SQRT(3.541)”。点击OK按钮,即可在数据编辑窗口中得到以t1为变量名的第一特征向量。再次调出Compute variable对话框,在对话框中输入等式:“z2=a2 / SQRT(0.313)”,运行后得到以t2为变量名第二特征向量。
2.079
Audi
0.866
0.208
0.319
-0.091
-0.677
BMW
0.496
-0.802
0.192
-0.091
-0.154
Buick
-0.614
1.689
0.933
-0.21
-0.154
Corvette
1.235
-1.811
-0.494
0.973
-0.677
Chrysler
-0.614
0.073
要求:要求学生熟练正确将Excel数据导入SPSS软件,熟练运用SPSS的因子分析功能和Computer功能实现主成分分析,并对输出结果做出正确解读和判断。
实验
内容
在某中学随机抽取某年级30名学生,测量其身高(x1),体重(x2),胸围(x3)和坐高(x4),数据见附录。试对这30名中学生身体4项指标数据做主成分分析,写出操作过程及结果分析
Windows xp、Windows vista、Windows 7等,软件SPSS 11.0版本及以上。
实验结果与
分析
各个变量主成分得分
教师评语
注:可根据实际情况加页
附表:
name
price
accelera
braking
handling
mileage
Acura
-0.521
0.477
-0.007
0.382
Component Matrixa
Component
1
2
身高
.935
-.304
体重
.968
.118
胸围
.905
.406
坐高
.954
-.206
Extraction Method: Principal Component Analysis.
二)利用因子分析结果进行主成分分析
1. 将表1中的因子载荷阵中的数据输入SPSS数据编辑窗口,两个变量分别命名为a1和a2。
-0.798
0.41
-0.061
-4.23
1.067
Mazda
0.126
0.679
-0.133
0.5
-1.724
Mercedes
1.051
0.006
0.12
-0.091
-0.154
Mitsub.
-0.614
-1.003
0.084
0.382
0.718
Nissan
-0.429
0.073
-0.007
0.263
得到了如表3所示的特征向量矩阵。
表3特征向量矩阵
0.49687671785646326-0.5433772041064034
0.51441354319257370.2109161515939329
0.480934149369090070.7256945554842099
0.5069736778984661-0.3682095527826286
0.997
Olds
-0.614
-0.734
0.409
0.382
2.114
Pontiac
-0.614
0.679
0.536
0.145Байду номын сангаас
0.195
Porsche
3.454
-2.215
-0.296
0.618
-1.026
Saab
0.588
0.679
0.246
0.263
0.021
Toyota
-0.059
1.218
0.228
0.736
-0.851
VW
-0.706
-0.128
0.102
0.382
0.195
Volvo
0.219
0.612
0.138
-0.21
0.369
故得到的主成分的表达式为
Y2=-0.54x1+0.21x2+0.73x3-0.37x4
就可以计算得到两个主成分Y1和Y2,然后再次调用Compute命令,调出Compute variable对话框,输入Y=0.88527*Y1+0.0785*Y2,得到综合得分Y(如表4)。
表4各个变量主成分得分
实验环境
表1中Total列为各因子对应的特征根,在本例中采用的是默认的提取的特征根大于1的因子,因此共提取两个公因子;% of Variance列为各因子的方差贡献率;Cumulative %列为累积方差贡献率,由表中可以看出,前两个因子的方差贡献率达到91.289%,即这两个因子已经可以解释原始变量91.289%的信息。
1
3.541
88.527
88.527
3.541
88.527
88.527
2
.313
7.835
96.362
.313
7.835
96.362
3
.079
1.985
98.347
4
.066
1.653
100.000
Extraction Method: Principal Component Analysis.
表2因子载荷阵