二叉树的二叉链表存储及基本操作
DS_第六章树 (用)

T0,T1,…,Tm-1,每个集合又是一棵树,并且称之为根的子树。每棵子树 的根结点有且仅有一个直接前驱,但可以有0个或多个直接后继。
A
B
C
D
E F GHI J
KL
M
2
SUBTREE1
B EF KL
ROOT
A
C
D
GHI J M
15
i/2
i
i+1
…… i
i+1 …… 2i
2i+1
2i 2i+1 2i+2 2i+3 2i+2 2i+3
(a) i和i+1结点在同一层
(b) i和i+1结点不在同一层
3、从(2)和(3)推出(1) 当i=1时,结点是根,因此无双亲。当i>1时,设其双亲结点编号为 p,如果i为左孩子,即i=2p,则p=i/2=i/2;如果i为右孩子, i=2p+1,p=(i-1)/2=i/2 。 证毕。
C E
D
F
G
H
I
J
#define MAX_SIZE 10
typedef struct BiTNode
{ TELemType data;
int
lchild;
int
rchild;
} BiTNode;
typedef BiTNode SqBiTree[MAX_SIZE];
1 2 3 4 5 6 7 8 9 10
第六章 树和二叉树
6.1 树的定义和基本术语 6.2 二叉树 6.3 遍历二叉树和线索二叉树 6.4 树和森林 6.5 赫夫曼树及其与树的应用
动态规划-最优二叉搜索树

动态规划-最优⼆叉搜索树摘要: 本章介绍了⼆叉查找树的概念及操作。
主要内容包括⼆叉查找树的性质,如何在⼆叉查找树中查找最⼤值、最⼩值和给定的值,如何找出某⼀个元素的前驱和后继,如何在⼆叉查找树中进⾏插⼊和删除操作。
在⼆叉查找树上执⾏这些基本操作的时间与树的⾼度成正⽐,⼀棵随机构造的⼆叉查找树的期望⾼度为O(lgn),从⽽基本动态集合的操作平均时间为θ(lgn)。
1、⼆叉查找树 ⼆叉查找树是按照⼆叉树结构来组织的,因此可以⽤⼆叉链表结构表⽰。
⼆叉查找树中的关键字的存储⽅式满⾜的特征是:设x为⼆叉查找树中的⼀个结点。
如果y是x的左⼦树中的⼀个结点,则key[y]≤key[x]。
如果y是x的右⼦树中的⼀个结点,则key[x]≤key[y]。
根据⼆叉查找树的特征可知,采⽤中根遍历⼀棵⼆叉查找树,可以得到树中关键字有⼩到⼤的序列。
介绍了⼆叉树概念及其遍历。
⼀棵⼆叉树查找及其中根遍历结果如下图所⽰:书中给出了⼀个定理:如果x是⼀棵包含n个结点的⼦树的根,则其中根遍历运⾏时间为θ(n)。
问题:⼆叉查找树性质与最⼩堆之间有什么区别?能否利⽤最⼩堆的性质在O(n)时间内,按序输出含有n个结点的树中的所有关键字?2、查询⼆叉查找树 ⼆叉查找树中最常见的操作是查找树中的某个关键字,除了基本的查询,还⽀持最⼤值、最⼩值、前驱和后继查询操作,书中就每种查询进⾏了详细的讲解。
(1)查找SEARCH 在⼆叉查找树中查找⼀个给定的关键字k的过程与⼆分查找很类似,根据⼆叉查找树在的关键字存放的特征,很容易得出查找过程:⾸先是关键字k与树根的关键字进⾏⽐较,如果k⼤⽐根的关键字⼤,则在根的右⼦树中查找,否则在根的左⼦树中查找,重复此过程,直到找到与遇到空结点为⽌。
例如下图所⽰的查找关键字13的过程:(查找过程每次在左右⼦树中做出选择,减少⼀半的⼯作量)书中给出了查找过程的递归和⾮递归形式的伪代码:1 TREE_SEARCH(x,k)2 if x=NULL or k=key[x]3 then return x4 if(k<key[x])5 then return TREE_SEARCH(left[x],k)6 else7 then return TREE_SEARCH(right[x],k)1 ITERATIVE_TREE_SEARCH(x,k)2 while x!=NULL and k!=key[x]3 do if k<key[x]4 then x=left[x]5 else6 then x=right[x]7 return x(2)查找最⼤关键字和最⼩关键字 根据⼆叉查找树的特征,很容易查找出最⼤和最⼩关键字。
树与二叉树h

SBNode nodes[MAXSIZE]; } SBTree;
举例
结点 左子
右子
1
26 34
1
2
6
2
3
4
3
0
4
4
0
0
4
4
0
0
特点:
6
0
0
找子方便,找父 结点不便.
三、二叉链表存储结构
第一层 第二层
( A ( B ( E (K,L),F),C(G),D( H (M),I,J )))
第四层 第三层
二、基本术语
结点:包括一个数据元素及若干个指向其它子树 的分支;例如,A,B,C,D等。
叶结点:无后件结点为叶结点;如K,L,M。 根结点:无前件的结点为根;例如,A结点。
子结点:某结点后件为该结点的子结点;例如,
方法描述: 从根结点a开始访问, 接着访问左子结点b, 最后访问右子结点c。
即:
根
A 访问根结点 B 先序遍历左子树 C 先序遍历右子树
a
左子 右子
bc
二、中序法(InOrder)
方法描述:
从左子结点b开始访问,
接着访问根结点a,
最后访问右子结点c。
即:
根
A 中序遍历左子树 B 访问根结点 C 中序遍历右子树
计算机学院
自动化学院
各种社会组织机构;
在计算机领域中,用树表示源
程序的语法结构;
2101 2102
2103
在OS中,文件系统、目录等组
织结构也是用树来表示的。
数据结构实验指导书(新版)
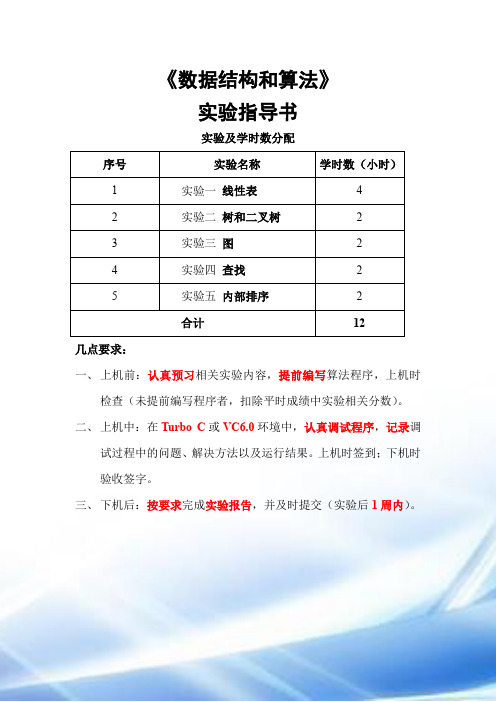
《数据结构和算法》实验指导书实验及学时数分配序号实验名称学时数(小时)1 实验一线性表 42 实验二树和二叉树 23 实验三图 24 实验四查找 25 实验五内部排序 2合计12几点要求:一、上机前:认真预习相关实验内容,提前编写算法程序,上机时检查(未提前编写程序者,扣除平时成绩中实验相关分数)。
二、上机中:在Turbo C或VC6.0环境中,认真调试程序,记录调试过程中的问题、解决方法以及运行结果。
上机时签到;下机时验收签字。
三、下机后:按要求完成实验报告,并及时提交(实验后1周内)。
实验一线性表【实验目的】1、掌握用Turbo c上机调试线性表的基本方法;2、掌握线性表的基本操作,插入、删除、查找以及线性表合并等运算在顺序存储结构和链式存储结构上的运算;3、运用线性表解决线性结构问题。
【实验学时】4 学时【实验类型】设计型【实验内容】1、顺序表的插入、删除操作的实现;2、单链表的插入、删除操作的实现;3、两个线性表合并算法的实现。
(选做)【实验原理】1、当我们在线性表的顺序存储结构上的第i个位置上插入一个元素时,必须先将线性表中第i个元素之后的所有元素依次后移一个位置,以便腾出一个位置,再把新元素插入到该位置。
若是欲删除第i个元素时,也必须把第i个元素之后的所有元素前移一个位置;2、当我们在线性表的链式存储结构上的第i个位置上插入一个元素时,只需先确定第i个元素前一个元素位置,然后修改相应指针将新元素插入即可。
若是欲删除第i个元素时,也必须先确定第i个元素前一个元素位置,然后修改相应指针将该元素删除即可;3、详细原理请参考教材。
【实验步骤】一、用C语言编程实现建立一个顺序表,并在此表中插入一个元素和删除一个元素。
1、通过键盘读取元素建立线性表;(从键盘接受元素个数n以及n个整形数;按一定格式显示所建立的线性表)2、指定一个元素,在此元素之前插入一个新元素;(从键盘接受插入位置i,和要插入的元素值;实现插入;显示插入后的线性表)3、指定一个元素,删除此元素。
数据结构-二叉排序树

二叉排序树操作一、设计步骤1)分析课程设计题目的要求2)写出详细设计说明3)编写程序代码,调试程序使其能正确运行4)设计完成的软件要便于操作和使用5)设计完成后提交课程设计报告(一)程序功能:1)创建二叉排序树2)输出二叉排序树3)在二叉排序树中插入新结点4)在二叉排序树中删除给定的值5)在二叉排序树中查找所给定的值(二)函数功能:1) struct BiTnode 定义二叉链表结点类型包含结点的信息2) class BT 二叉排序树类,以实现二叉排序树的相关操作3) InitBitree() 构造函数,使根节点指向空4) ~BT () 析构函数,释放结点空间5) void InsertBST(&t,key) 实现二叉排序树的插入功能6) int SearchBST(t,key) 实现二叉排序树的查找功能7) int DelBST(&t,key) 实现二叉排序树的删除功能8) void InorderBiTree (t) 实现二叉排序树的排序(输出功能)9) int main() 主函数,用来完成对二叉排序树类中各个函数的测试二、设计理论分析方法(一)二叉排序树定义首先,我们应该明确所谓二叉排序树是指满足下列条件的二叉树:(1)左子树上的所有结点值均小于根结点值;(2)右子数上的所有结点值均不小于根结点值;(3)左、右子数也满足上述两个条件。
根据对上述的理解和分析,我们就可以先创建出一个二叉链表结点的结构体类型(struct BiTNode)和一个二叉排序树类(class BT),以及类中的构造函数、析构函数和其他实现相关功能的函数。
(二)插入函数(void InsertBST(&t,key))首先定义一个与BiTNode<k> *BT同一类型的结点p,并为其申请空间,使p->data=key,p->lchild和p->rchild=NULL。
数据结构第七章 树和森林

7.5 树的应用
➢判定树
在实际应用中,树可用于判定问题的描述和解决。
•设有八枚硬币,分别表示为a,b,c,d,e,f,g,h,其中有一枚且 仅有一枚硬币是伪造的,假硬币的重量与真硬币的重量不同,可能轻, 也可能重。现要求以天平为工具,用最少的比较次数挑选出假硬币, 并同时确定这枚硬币的重量比其它真硬币是轻还是重。
的第i棵子树。 ⑺Delete(t,x,i)在树t中删除结点x的第i棵子树。 ⑻Tranverse(t)是树的遍历操作,即按某种方式访问树t中的每个
结点,且使每个结点只被访问一次。
7.2.2 树的存储结构
顺序存储结构 链式存储结构 不管哪一种存储方式,都要求不但能存储结点本身的数据 信息,还要能够唯一的反映树中各结点之间的逻辑关系。 1.双亲表示法 2.孩子表示法 3.双亲孩子表示法 4.孩子兄弟表示法
21
将二叉树还原为树示意图
A BCD
EF
A
B
C
E
D
F
A
B
C
E
D
F
22
练习:将下图所示二叉树转化为树
1 2
4
5
3
6
2 4
1 53
6
23
7.3.2 森林转换为二叉树
由森林的概念可知,森林是若干棵树的集合,只要将森林中各棵树 的根视为兄弟,森林同样可以用二叉树表示。 森林转换为二叉树的方法如下:
⑴将森林中的每棵树转换成相应的二叉树。 ⑵第一棵二叉树不动,从第二棵二叉树开始,依次把后一棵二叉树 的根结点作为前一棵二叉树根结点的右孩子,当所有二叉树连起来 后,此时所得到的二叉树就是由森林转换得到的二叉树。
相交的集合T1,T2,…,Tm,其中每一个集合Ti(1≤i≤m)本身又是 一棵树。树T1,T2,…,Tm称为这个根结点的子树。 • 可以看出,在树的定义中用了递归概念,即用树来定义树。因此, 树结构的算法类同于二叉树结构的算法,也可以使用递归方法。
C语言递归生成二叉树探讨

@
~
,
saf” ” ) cr(%c, ; &c
c=tr n t rtm U L = e ae eu N L mi )
es le
t 、
‘
.
(
霞
。
蹶 。
≮ 。
■‘ 、
ro=B o e) l cs ef N d) ot(N d ma o(zo( o e ; l i B )
2二 叉 树 递 归 生 成 .
可 以利 用二 叉树 基本 性 质 . 即从 根 结点 开始 。 断 不 给 当前 叶子结点 添加左 、 右新 的子 结 点 , 成整 棵完 整 生 的二叉树 。这里 , 以前序 递归 方法 为例来 介绍 。需要 注 意 的是输 入时按先 序遍 历次 序输入 二 叉树 中结 点 的字 符值 . 同时要 把左 右子树 为空 的结 点也 要表 示 出来 , 该 文用 、 表 示空树 。 下面 给 出几 种 C语 言实 现方案 : 使用 的宏 定 义 :
# e n t r n t d f e e mi a e i
# e n OK df e i 1
# e i e ERROR d fn 0
方法 1 :
B re c t( Te  ̄ac )(
BT e o t NUL rero= L:
c a ; h c r源自④ : 法。 【 关键词 】 二 叉树 ; : C语 言 ; 归 递
1 引言 .
二 叉树 是一 种基 本 的非 线性 数据 结构 .二叉 链 表 是 其常用 的存储形 式 。用 二 叉链 表实 现生 成二 叉树 的 算 法 比较多 .其 中递归 生成 及递 归遍 历二叉 树 属 于二 叉 树的基本 操作 。 目前无 论在 教学或 实用 使用 中 , 大都 采 用 C、 + 或 C C+ #编 程实 现 ,其 中用 面 向过程 基 本 C 语 言编程属 于重要 的基本 实现 方法 。该 文在 基 于基本 C语 言 环 境 下 对 实现 生 成 二 叉 树 及 遍 历 进 行 一 些 探
数据结构第5章课件 中国石油大学(华东)

二叉链表
leftChild
data rightChild
22
二叉树的链表表示(三叉链表)
每个结点增加一个指向双亲的指针parent,使 得查找双亲也很方便。
leftChild data parent rightChild
三叉链表
data
leftChild
27
BinTreeNode *LeftChild (BinTreeNode *current ) { return (current != NULL )? current->leftChild :NULL; } BinTreeNode *RightChild (BinTreeNode *current ) { return ( current!= NULL) ? current->rightChild : NULL; } int Height( ){return Height(root);} int Size( ){return Size(root);} BinTreeNode *GetRoot ( ) const { return root; } void preOrder( ) {preOrder(root);} //前序遍历 void inOrder( ) {inOrder(root);} //中序遍历 void postOrder( ) {postOrder(root);} //后序遍历 void levelOrder( ) ; // 不需要递归,所以直接对外接 口调用即可。层序遍历 28
b
f
c
d
g
6
e
a
b.嵌套集合表示法: b 根据树的集合定义,写出集合划分。 { a, {b,{e},{f}}, {c}, {d,{g}} } e c d
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
二叉树的二叉链表存储及基本操作
《二叉树的二叉链表存储及基本操作》
一、二叉树的二叉链表表示及存储
1.定义
二叉树的二叉链表存储表示是把一个二叉树存放在计算机中的一种表示形式,它是由一组以结点对象为元素的链表构成的,结点对象中包括数据域和结构域。
数据域存放结点的数据元素;结构域由两个指针域组成,其中一个指向左孩子,另一个指向右孩子。
2.存储形式
二叉树的二叉链表存储表示可以用如下的存储形式表示:
typedef struct BTNode {
TElemType data; // 结点的数据域
struct BTNode *lchild; // 指向左孩子的指针域
struct BTNode *rchild; // 指向右孩子的指针域
} BTNode; // 树结点的定义
typedef BTNode *BiTree; // 定义二叉树的指针类型
3.空的二叉树
把一个指向树结点的指针设为NULL,称为一个空的二叉树。
一般在某个树被销毁后,都要把该树设置成空树。
二、二叉树的基本操作
1.求二叉树的结点数
要求二叉树的结点数,可以用递归的方法求解。
求n个结点的二
叉树的结点数,可以先求出它的左子树结点数,右子树结点数,再加上根结点的数量就得到了结点数。
// 求二叉树的结点数
int CountBTNode(BiTree T)
{
if (T == NULL) // 空树,结点数为0
return 0;
else // 左子树结点数 + 右子树结点数 + 1
return CountBTNode(T -> lchild) + CountBTNode(T -> rchild) + 1;
}
2.求二叉树叶结点数
要求二叉树叶结点数,也可以用递归的方法求解。
当一个结点的左子树为空树,右子树也为空树时,它就是一个叶结点,则叶结点数加1;如果结点不是叶结点,则继续求它的左子树叶结点数和右子树叶结点数,再把它们加起来就是该二叉树的叶结点数。
// 求二叉树叶结点数
int CountBTLeaf(BiTree T)
{
if (T == NULL) // 空树,叶结点数为0
return 0;
else if (T -> lchild == NULL && T -> rchild == NULL) //
判读是否是叶结点
return 1;
else // 左子树叶结点数 + 右子树叶结点数
return CountBTLeaf(T -> lchild) + CountBTLeaf(T -> rchild);
}
3.求二叉树深度
要求二叉树深度,也可以用递归的方法求解。
它的深度等于左右子树深度的较大值再加1。