QM算法源代码及说明

QM算法说明
一、需求分析
本算法要求输入一最小项和无关项的待化简表达式,通过程序处理输出化简后的结果。
二、算法流程
程序首先要求用户输入待化简表达式的变量数,然后要求用户逐个输入值为1的项,以2表示输入结束,再要求用户逐个输入无关项同样以2结束。程序将用户输入的所有数据储存在一个数据容器vector中,并将相关项单独存在另一个vector中。
然后程序通过循环遍历所有相关项,将相邻的项合并成蕴涵项存入新建的vector中,无法再合并的项显然为本源蕴涵项,存入专门的容器。之后再对新建的vector中的蕴涵项重复上述操作,直到找到所有的本源蕴涵项。由于变量最多为10个,故合并最多进行10次,故所有合并可在一个10元vector数组内完成。
当之前的工作完成时,此时显然已找到所有的本源蕴涵项,此时遍历之前存储的相关项,统计被覆盖的次数并输出只被覆盖一次的项所属的本源蕴涵项(皆为本质本源蕴涵项)。
之后再从vector尾部开始输出其他本源蕴涵项直到所有的相关项都被覆盖为止。
三、运行结果
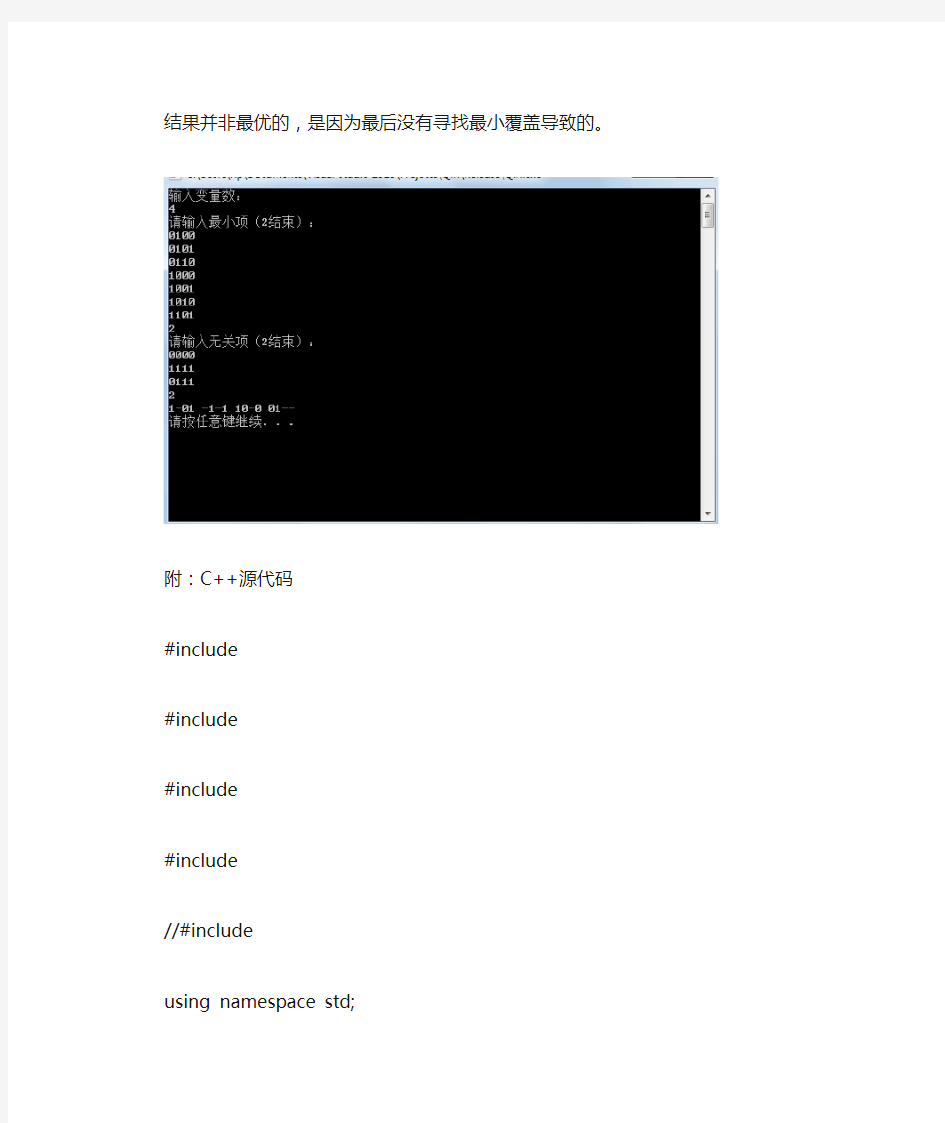
测试数据采用《现代逻辑设计》(第二版)P86的样例,F=Σm(4,5,6,8,9,10,13)+d(0,7,15);
结果并非最优的,是因为最后没有寻找最小覆盖导致的。
附:C++源代码
#include
#include
#include
#include
//#include
using namespace std;
//ofstream out("c://a.log");
bool comp(int n, char* a, char* b)
{
for(int i=0; i { if(a[i]!=b[i] && (a[i]!='-'&&b[i]!='-'))return false; } return true; } int implicant(int n, char*a, char*b) { int count = 0,temp; for(int i=0; i { if(a[i]!=b[i]) { count++; temp = i; } } if(count == 1)return temp; else return -1; } bool cointain(int n, char* a, char* b) { for(int i=0; i { if(a[i]!=b[i] && (a[i]!='-'))return false; } return true; } int main() { int i,j,k,l,n,count,tmp; char *temp,c; vector vector vector vector bool flag[2]; cout<<"输入变量数:"< cin>>n; temp = new char[n]; cout<<"请输入最小项(2结束):"< while(flag[0]) { for(i = 0; i { cin>>temp[i]; if(temp[i]!='0' && temp[i]!='1') { flag[0] = false; break; } } if(flag[0]) { v[0].push_back(new char[n]); relative.push_back(new char[n]); strcpy(v[0].back(),temp); strcpy(relative.back(),temp); } } cout<<"请输入无关项(2结束):"< while(flag[0]) { for(i = 0; i { cin>>temp[i]; if(temp[i]!='0' && temp[i]!='1') { flag[0] = false; break; } } if(flag[0]) { v[0].push_back(new char[n]); strcpy(v[0].back(),temp); } } for(i = 0; i<10; i++) { if(v[i].empty())break; for(j = 0; j { flag[0] = false; for(k = 0; k { if(implicant(n,v[i][j],v[i][k])!=-1) { strcpy(temp,v[i][j]); temp[implicant(n,v[i][j],v[i][k])]='-'; flag[1] = true; flag[0] = true; for(l=0;l { if(!strcmp(v[i+1][l],temp))flag[1] = false; } if(flag[1]) { v[i+1].push_back(new char[n]); strcpy(v[i+1].back(),temp); } } } if(!flag[0]) { prime.push_back(new char[n]); strcpy(prime.back(),v[i][j]); } } } for(i=0;i count = 0; for(j = 0; j { if(comp(n,relative[i],prime[j])) { count++; tmp=j; } } if(count==1) { result.push_back(new char[n]); strcpy(result.back(),prime[tmp]); for(j=0;j { if(comp(n,relative[j],prime[tmp])) { relative.erase(relative.begin()+j); j--; } } prime.erase(prime.begin()+tmp); i--; } } while(!relative.empty()) { strcpy(temp, prime.back()); prime.pop_back(); count = 0; for(i=0;i { if(comp(n,relative[i],temp)) { relative.erase(relative.begin()+i); i--; count++; } } if(count > 0) { result.push_back(new char[n]); strcpy(result.back(),temp); } } while(!result.empty()) { for(i = 0; i < 4; i++) cout<<*(result.back()+i); cout<<" "; result.pop_back(); } cout< system("PAUSE"); } 我伟大的母校 课程设计报告书 实践课题:动态分区分配 姓名:路人甲 学号:20XXXXXX 指导老师:路人乙 学院:计算及科学与技术学院 课程设计实践时间 2013.3.11~2013.3.22 一.课程设计的目的: 二.设计内容: 三.设计要求: 四.程序流程图 Alloc Best_fit Worst_fit Free Show Main 五.源代码 #include typedef struct DuLNode//结构指针 { ElemType data; struct DuLNode *prior; //前趋指针 struct DuLNode *next; //后继指针 } DuLNode,*DuLinkList;//指针链表 DuLinkList block_first; //头结点 DuLinkList block_last; //尾结点 Status alloc(int);//内存分配 Status free(int); //内存回收 Status Best_fit(int); //最佳适应算法 Status Worst_fit(int);//最差适应算法 void show();//查看分配 Status Initblock();//开创空间表 Status Initblock()//开创带头结点的内存空间链表 { block_first=(DuLinkList)malloc(sizeof(DuLNode)); block_last=(DuLinkList)malloc(sizeof(DuLNode)); block_first->prior=NULL; block_first->next=block_last; block_last->prior=block_first; block_last->next=NULL; block_last->data.address=0; block_last->data.size=MAX_length; block_last->data.state=Free; return OK; } //分配主存 Status alloc(int ch) { int request = 0; cout<<"请输入需要分配的主存大小(单位:M):"; cin>>request; if(request<0 ||request==0) { cout<<"分配大小不合适,请重试!"< 操 作 系 统 实 验 报 告 课程名称:操作系统 实验题目:首次适应算法 姓名: **** 专业班级: *********** 学号: ************* 指导老师: ***** 一、实验目的 在计算机系统中,为了提高内存区的利用率,必须给电脑内存区进行合理的分配。本实验通过对内存区分配方法首次适应算法的使用,来了解内存分配的模式。 二、实验要求 1.内存大小初始化 2.可以对内存区进行动态分配,采用首次适应算法来实现 3.可以对已分配的内存块进行回收,并合并相邻的空闲内存块。 三、实验内容 把一个作业装入内存,按照首次适应算法对内存区进行分配,作业结束,回收已分配给该作业的内存块,并合并相邻的空闲内存块。 四、实验结果 运行效果: 1.初始化内存区大小,并添加作业,选择1添加作业 2. 当作业大小超过存储块大小时,分配失败。 3.选择3,可查看内存分配情况 4.选择2回收内存 5.添加新作业 6.回收C作业,相邻的空闲内存块合并。 五、实验总结 首次适应算法要求空闲分区链以地址递增的次序链接。在分配内存时,从链首开始查找,直到找到一个大小能满足要求的空闲分区为止;然后按照作业大小,从该分区中划出一块内存空间分配给请求者,余下的空闲区仍留在空闲链中。若从链首到链尾都不能找到一个能满足要求的分区,则此次分配失败。这里,我采用数组的方式,模拟内存分配首次适应算法,动态的为作业分配内存块。可以根据作业名称回收已分配的内存块,当空闲内存块相邻时,则合并。 通过此次的实验,让我对内存分配中首次适应算法更加熟悉,在此基础上,我也测试最佳适应算法(best_fit)和最坏适应算法(worst_fit),并对其进行了比较分析,从比较中我发现,针对同一个问题,解决的方法不止一种,而且不同的方法所要消耗的资源和时间也不相同,根据不同的要求,方法的优劣也不同,可以说方法是解决问题的一种模式,随环境不同而体现出优越性。 六、实验附录 程序源代码: #include 首次适应算法,最佳适应算法,最坏适应算法源代码[宝典] 首次适应算法,最佳适应算法,最坏适应算法源代码#include void show();//查看分配 Status Initblock();//开创空间表 Status Initblock()//开创带头结点的内存空间链表{ block_first=(DuLinkList)malloc(sizeof(DuLNode)); block_last=(DuLinkList)malloc(sizeof(DuLNode)); block_first->prior=NULL; block_first->next=block_last; block_last->prior=block_first; block_last->next=NULL; block_last->data.address=0; block_last->data.size=MAX_length; block_last->data.state=Free; return OK; } //分配主存 Status alloc(int ch) { int request = 0; cout<<"请输入需要分配的主存大小(单位:KB):"; cin>>request; if(request<0 ||request==0) { cout<<"分配大小不合适,请重试~"< #include )数据挖掘分类算法之决策树(zz Decision tree决策树()以实例为基础的归纳学习算法。决策树是 它从一组无次序、无规则的元组中推理出决策树表示形式的分类规则。它采 并根据不同的用自顶向下的递归方式,在决策树的内部结点进行属性值的比较,该结点向下分支,叶结点是要学习划分的类。从根到叶结点的一条路属性值从径就对应着一条合取规则,整个决策树就对应着一组析取表达式规则。1986年又ID3算法的基础上,1993年QuinlanQuinlan提出了著名的ID3算法。在提出了若干改提出了C4.5算法。为了适应处理大规模数据集的需要,后来又SPRINT (scalable 进的算法,其中SLIQ(super-vised learning in quest)和是比较有代表性的两个算法。parallelizableinduction of decision trees) (1) ID3算法算法的核心是:在决策树各级结点上选择属性时,用信息增益 ID3)作为属性的选择标准,以使得在每一个非叶结点进行测(information gain 检测所有的属性,其具体方法是:试时,能获得关于被测试记录最大的类别信息。再对由该属性的不同取值建立分支,选择信息增益最大的属性产生决策树结点,直到所有子集仅包含同一各分支的子集递归调用该方法建立决策树结点的分支,类别的数据为止。最后得到一棵决策树,它可以用来对新的样本进行分类。某属性的信息增益按下列方法计算。通过计算每个属性的信息增益,并比较 它们的大小,就不难获得具有最大信息增益的属性。个m个不同值,定义mS 设是s个数据样本的集合。假定类标号属性具有中的样本数。对一个给定的样本分类所需si是类Ci不同类Ci(i=1,…,m)。设的期望信息由下式给出:为底,其原2Ci 其中pi=si/s的概率。注意,对数函数以是任意样本属于因是信息用二进制编码。个划分为v可以用属性A将Sv 设属性A具有个不同值{a1,a2,……,av}。aj上具有相同的值A,其中Sj中的样本在属性子集 {S1,S2,……,Sv}(j=1,2,……,v)。设sij是子集Sj中类Ci的样本数。由A 划分成子集的熵或信息期望由下式给出: 熵值越小,子集划分的纯度越高。对于给定的子集Sj,其信息期望为 其中pij=sij/sj 是Sj中样本属于Ci的概率。在属性A上分枝将获得的信息增益是 Gain(A)= I(s1, s2, …,sm)-E(A) ID3算法的优点是:算法的理论清晰,方法简单,学习能力较强。其缺点是:决策树可当训练数据集加大时,且对噪声比较敏感,只对比较小的数据集有效,能会随之改变。算法(2) C4.5 ID3 C4.5算法继承了算法的优点,并在以下几方面对ID3算法进行了改进:用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值1) 实验四操作系统-动态分区分配算法萨斯的发生的v设计程序模拟四种动态分区分配算法:首次适应算法、循环首次适应算法、最佳适应算法和最坏适应算法的工作过程。假设内存中空闲分区个数为n,空闲分区大小分别为P1, … ,P n,在动态分区分配过程中需要分配的进程个数为m(m≤n),它们需要的分区大小分别为S1, … ,S m,分别利用四种动态分区分配算法将m个进程放入n个空闲分区,给出进程在空闲分区中的分配情况。 程序要求如下: 1)利用首次适应算法、循环首次适应算法、最佳适应算法和最坏适应算法四种动态分区分配算法模拟分区分配过程。 2)模拟四种算法的分区分配过程,给出每种算法进程在空闲分区中的分配情况。 3)输入:空闲分区个数n,空闲分区大小P1, …,P n,进程个数m,进程需要的分区大小S1, … ,S m,算法选择1-首次适应算法,2-循环首次适应算法,3-最佳适应算法,4-最坏适应算法。 4)输出:最终内存空闲分区的分配情况。 代码实现: #include int FreePartition[MaxNumber];次适应算法 2.循环首次适应算法 3.最佳适应算法 4.最坏适应算法:"< 1 第七章 习题及解答 7-11如图7.45所示,主存中有两个空白区。现有如下程序序列:程序1要求50KB ;程序2要求60KB ;程序3要求70KB 。若用首次适应算法和最佳适应算法来处理这个程序序列,试问:哪一种算法可以分配得下 ? 简要说明分配过程 (假定分区描述器所占用的字节数已包含在程序所要求的主存容量中) 。 图7.45 答:(1) 首次适应法: 程序1要求50KB ,在起始地址为150KB ,大小为120 KB 的空白区进行分割。120KB -50KB=70KB ,分割后剩70KB 的空白区。 程序2要求60KB ,在剩余的70KB 空白区进行分割。70KB -60KB=10KB ,分割后剩 10KB 的空白区。 程序3要求70KB ,在起始地址为300KB ,大小为78KB 的空白区进行分割。78KB -70KB=8KB ,分割后剩8KB 的空白区。 因此首次适应法可满足该程序序列的需求。 (2) 最佳适应法 程序1要求50KB ,在起始地址为300KB ,大小为78 KB 的空白区进行分割。78KB -50KB=28KB ,分割后剩28KB 的空白区。 程序2要求60KB ,在起始地址为150KB ,大小为120KB 的空白区进行分割。120KB -60KB=60KB ,分割后剩60KB 的空白区。 程序3要求70KB ,。此时系统中有大小为 28KB 和60KB 的两个空白区,它们均不能满足程序3 的需求。 因此最佳适应法不能满足该程序序列的需求。 150K B 300K B 主存 7-12已知主存有256KB 容量,其中OS 占用低址20KB ,可以有这样的一个程序序列。 程序1要求 80KB ;程序2要求16KB ;程序3要求 140KB 。 程序1完成;程序3完成。 程序4要求 80KB ;程序5要求120KB 。 试分别用首次适应算法和最佳适应算法分别处理上述程序序列 (在存储分配时,从空白区高址处分割作为已分配区),并完成以下各步骤。 (1) 画出程序1、2、3进入主存后主存的分配情况。 (2) 画出程序1、3完成后主存分配情况。 (3) 试用上述两种算法中画出程序1、3完成后的空闲区队列结构 (要求画出分区描述器信息,假定分区描述器所需占用的字节数已包含在程序所要求的主存容量中) 。 (4) 哪种算法对该程序序列而言是适合的?简要说明分配过程。 (1) 答:程序1、2和3 进入主存后,主存的分配情况如下图所示。 (2) 答:程序1、3 完成后,主存的分配情况如下图所示: (3) 答:首次适应法下,空闲区队列结构如下图所示。 队列指针 主存 0 256KB -1 160KB 20KB 176KB 主存 0 256KB -1 20KB 160KB 176KB 最佳适应算法源程序代码 #include int flag; //空闲区表登记栏标志,用"0"表示空栏目,用"1"表示未分配}free_table[M]; //空闲区表对象名 //函数声明 void initialize(void); int distribute(int, float); int recycle(int); void show(); //初始化两个表 void initialize(void) { int a; for(a=0; a<=N-1; a++) used_table[a].flag=0; //已分配表的表项全部置为空表项 free_table[0].address=1000; free_table[0].length=1024; free_table[0].flag=1; //空闲区表的表项全部为未分配 } //最优分配算法实现的动态分区 最佳适应算法实验报告 一、实验目的 了解首次适应算法、最佳适应方法、最差适应算法 二、实验方法 修改Minix操作系统的内存分配源码,实现最佳适应算法 三、实验任务 修改Minix操作系统中的内存分配源码,将首次适应算法更改为最佳适应算法。重新编译系统映像文件,观察实验结果。 四、实验要点 内存分配、首次适应算法、最佳适应算法。 五、实验内容 5.1 minix内存分配源码 安装好minix操作系统以后,minix系统的源码位于/usr/src目录中。其中,与内存分配的相关源码则在/usr/src/servers/pm/alloc.c中。minix系统初始的内存分配算法为首次适应算法。 在minix系统中,空闲的内存空间信息采用链表的信息储存起来,而操作系统分配内存空间的过程则是在这个链表中寻找一个合适空间,返回内存空间的地址,再更改链表中的内存空间信息。这就是minix系统分配内存的实质。 5.2分析首次适应算法 首次适应算法,指的从空闲内存块链表的第一个结点开始查找,把最先找到的满足需求的空闲内存块分配出去。这种算法的优点是分配所需的时间较短,但这种算法会形成低地址部分形成很多的空间碎片,高地址区保留大量长度较长的空闲内存块。 内存分配的操作在/usr/src/servers/pm/alloc.c源文件中的alloc_mem函数中完成。在函数的初始位置,定义了两个用于遍历链表的指针变量,两个指针变量的定义如下:registerstruct hole *hp, *prev_ptr; 而hole结构体的定义如下: PRIVATE struct hole { struct hole *h_next; phys_clicksh_base; phys_clicksh_len; } hole[NR_HOLES]; 先分析这个结构体的定义,这个结构体中,有三个变量,h_next是一个指向链表下一个结点的指针变量;h_base则是指向这个链表所表示的空闲内存空间的地址,h_len 则是这个空闲内存空间的长度;phys_clicks的定义可以在/usr/src/include/minix/type.h 中找到,phys_clicks的定义为: typedef unsigned intpyhs_clicks; 学号专业姓名 实验日期教师签字成绩 实验报告 【实验名称】采用可变式分区管理,使用首次获最佳适应算法实现内存分配与回收 【实验目的与原理】 1、理解首次获最佳适应算法的内涵,并熟练掌握该算法。 2、学会可变式分区管理的原理是即在处理作业过程中建立分区,使分区大小正好适合作业的需要,并且分区个数是可以调整的。 3、当有一个新作业要求装入主存时,必须查空闲区说明表,从中找出一个足够大的空闲区没有时应将空闲区一分为二。为了便于快速查找,要不断地对表格进行紧缩,即让“空表目”项留在表的后部。 4、当一个作业执行完成时,作业所占用的分区应归还给系统。作业的释放区与空闲区的邻接分以下四种情况考虑: ①释放区下邻(低地址邻接)空闲区; ②释放区上邻(高地址邻接)空闲区 ③释放区上下都与空闲区邻接; ④释放区与空闲区不邻接。 【实验内容】 #include 数据挖掘分类算法之决策树(zz) 决策树(Decision tree) 决策树是以实例为基础的归纳学习算法。 它从一组无次序、无规则的元组中推理出决策树表示形式的分类规则。它采用自顶向下的递归方式,在决策树的内部结点进行属性值的比较,并根据不同的属性值从该结点向下分支,叶结点是要学习划分的类。从根到叶结点的一条路径就对应着一条合取规则,整个决策树就对应着一组析取表达式规则。1986年Quinlan提出了著名的ID3算法。在ID3算法的基础上,1993年Quinlan又提出了C4.5算法。为了适应处理大规模数据集的需要,后来又提出了若干改进的算法,其中SLIQ(super-vised learning in quest)和SPRINT (scalable parallelizableinduction of decision trees)是比较有代表性的两个算法。 (1) ID3算法 ID3算法的核心是:在决策树各级结点上选择属性时,用信息增益(information gain)作为属性的选择标准,以使得在每一个非叶结点进行测试时,能获得关于被测试记录最大的类别信息。其具体方法是:检测所有的属性,选择信息增益最大的属性产生决策树结点,由该属性的不同取值建立分支,再对各分支的子集递归调用该方法建立决策树结点的分支,直到所有子集仅包含同一类别的数据为止。最后得到一棵决策树,它可以用来对新的样本进行分类。 某属性的信息增益按下列方法计算。通过计算每个属性的信息增益,并比较它们的大小,就不难获得具有最大信息增益的属性。 设S是s个数据样本的集合。假定类标号属性具有m个不同值,定义m个不同类Ci(i=1,…,m)。设si是类Ci中的样本数。对一个给定的样本分类所需的期望信息由下式给出: 其中pi=si/s是任意样本属于Ci的概率。注意,对数函数以2为底,其原因是信息用二进制编码。 设属性A具有v个不同值{a1,a2,……,av}。可以用属性A将S划分为v个子集{S1,S2,……,Sv},其中Sj中的样本在属性A上具有相同的值aj (j=1,2,……,v)。设sij是子集Sj中类Ci的样本数。由A划分成子集的熵或信息期望由下式给出: 熵值越小,子集划分的纯度越高。对于给定的子集Sj,其信息期望为 其中pij=sij/sj 是Sj中样本属于Ci的概率。在属性A上分枝将获得的信息增益是 Gain(A)= I(s1, s2, …,sm)-E(A) ID3算法的优点是:算法的理论清晰,方法简单,学习能力较强。其缺点是:只对比较小的数据集有效,且对噪声比较敏感,当训练数据集加大时,决策树可 编写程序模拟实现内存的动态分区法存储管理。内存空闲区使用自由链管理,采用最坏适应算法从自由链中寻找空闲区进行分配,内存回收时要与相邻空闲区的合并。 初始状态信息:假定系统的内存共640K,初始状态为操作系统本身占用64K。 将要申请内存的作业信息(存储在document/job.txt文件中),当前时间是0。 输入:用户打开document/job.txt文件,输入作业信息。 处理:模拟时间逐歩增加,每次加1.采用先来先服务算法调度作业,模拟作业运行,用最坏适应算法进行内存的分配。且进行内存的回收,注意与空闲分区的合并。直到所以作业运行完成程序结束。 输出:把当前时间为0,为1,为2......的内存分配状况和作业信息写入文件 document/information.txt。 设计思路 4.1 结点定义 //空闲区结点描述 typedef struct FreeNode { int length; // 分区长度 int address; // 分区起始地址 }FreeNode,*PFreeNode; //空闲区自由链表的描述 typedef struct FreeLink { FreeNode freeNode; struct FreeLink * next; }FreeLink,*PFreeLink; //内存占用区链表描述 typedef struct BusyNode { char name[20];//标明此块内存被哪个进程所占用 int length; // 分区长度 int address; // 分区起始地址 }BusyNode,*PBusyNode; //内存占用区忙碌链表的描述 typedef struct BusyLink { BusyNode busyNode; struct BusyLink * next; }BusyLink,*PBusyLink; #include int size,start,end; t=L->next; p=L->next; for(i=0;i 一、判断题 (×)1、分时系统中,时间片设置得越小,则平均响应时间越短。 (√)2、多个进程可以对应于同一个程序,且一个进程也可能会执行多个进程。(×)3、一个进程的状态发生变化总会引起其它一些进程的状态发生变化。(×)4、在引入线程的OS中,线程是资源分配和调度的基本单位。 (√)5、信号量的初值不能为负数。 (×)6、最佳适应算法比首次适应算法具有更好的内存利用率。 (×)7、为提高对换空间的利用率,一般对其使用离散的分配方式。 (×)8、设备独立性是指系统具有使用不同设备的能力。 (√)9、隐士链接结构可以提高文件存储空间的利用率,但不适合文件的随机存取。 (×)10、访问控制矩阵比访问控制表更节约空间。 (×)11、分时系统在响应时间、可靠性及交互作用能力等方面一般都比分时系统要求高。 (√)12、Window XP是一个多用户、多任务的操作系统。 (×)13、一个进程正在临界区中间执行时不能被中断。 (×)14、系统处于不安全状态必然导致系统死锁。 (√)15、请求分段存储管理中,分段的尺寸要受存储空间的限制。 (√)16、属于同一个进程的多个线程可共享进程的程序段、数据段。 (×)17、设备的独立性是指每类设备有自己的设备驱动程序。 (×)18、虚拟设备是指允许用户使用比系统中具有的物理设备更多的设备。(√)19、对物理文件来说,顺序文件必须采用连续分配方式,而链接文件和索引文件可采用离散分配方式。 (×)20、在UNIX文件系统中,文件的路径和磁盘索引节点之间是一一对应的。(×)21、在分时系统中,为使多个用户能够同时与系统交互,最关键的问题是系统能及时连接多个用户的输入。 (×)22、在进程对应的代码中使用wait、signal操作后,可以防止系统发生死锁。 (√)23、在只提供用户级线程的多处理机系统中,一个进程最多仍只能获得一个CPU。 (√)24、竞争可同时共享的资源,不会导致系统进入死锁状态。 (√)25、在没有快表支持的段页式系统中,为了存取一个数据,需三次访问内存。 (×)26、以进程为单位进行整体对换时,每次换出必须将整个进程的内存映像全部换出。 (√)27、请求分页系统中,一条指令执行期间产生的缺页次数可能会超过四次。(×)28、引入缓冲区能使CPU和I/O设备之间速度不匹配的情况得到改善,但并不能减少设备中断CPU的次数。 (×)29、由于设备驱动程序与硬件紧密相关,所以,系统中配备多少个设备就必须配备同样数量的设备驱动程序。 (×)30、文件系统中,所以文件的目录信息集中存放在内存的一个特定区域中。 一、填空题 1、在操作系统中,不可中断执行的操作称为(原语操作)。 2、特权指令能在(内核态)下执行,而不能在(用户态)下执行。动态分区分配 最佳 最坏 适应算法
首次适应算法 内存分配
首次适应算法,最佳适应算法,最坏适应算法源代码[宝典]
首次适应算法和最佳适应算法-C++语言版
C45算法的源代码全解
操作系统-实验四动态分区分配算法源代码最全
第7章习题及答案
最佳适应算法-源程序代码
实验三 最佳适应算法 实验报告
操作系统 首次最佳适应算法
C4.5算法的源代码全解
用C语言模拟内存分区分配管理的最佳适应算法
循环首次适应算法、首次适应算法、最佳适应算法 C语言版
操作系统复习题